TDSQL交易型分散式資料庫背景分析
# 一、背景
隨著各行各業電子資訊化的不斷加深,線上交易資料保持了長時間高速增長的態勢,對資料儲存的需求越來越大,資料庫管理系統(DBMS)面臨越來越大的效能、空間和穩定性壓力。在此過程中,得利於計算&儲存&網路等硬體領域的不斷進步,業界流行的資料庫管理系統逐步從單機架構向分散式架構演變。筆者希冀從梳理資料庫管理系統所面臨的一個又一個實際挑戰及業界所提出的諸多解決方案的過程中,發現片縷靈感以指引未來的資料庫開發工作。
# 二、從單機資料庫到分散式資料庫
業界起步階段誕生的第一代交易型資料庫具有以下主要特點:和程式一起執行在大型機/小型機為代表的高階計算機上; 利用硬體層面大量冗餘設計帶來的強大可靠性來保障資料庫可用性,通過直接升級硬體規格的方式來擴容資料庫效能容量。即使到今天仍然有很多銀行核心系統以這樣的方式執行。 很快,這種堆硬體模式來獲取提升的模式侷限性就暴露出來了。首先,資料庫可用性對硬體層面冗餘的依賴抬高了大型機等儲存型裝置的造價,動輒單臺上千萬美元的價格是諸多中小客戶難以承受的負擔。次之,由於效能擴容只能通過提升硬體規格的方式實現,而硬體規格的10%效能容量提升,往往需要客戶付出成倍的購買成本,且整體效能極限也受限於當時的硬體發展的天花板。由於上述所說的諸多成本原因,業界一直沒有停止過嘗試以x86伺服器為代表的“廉價”硬體替換大型機來提供交易型資料庫服務的努力。
# 三、基於共享儲存的分散式資料庫方案
**1. 共享儲存方案**
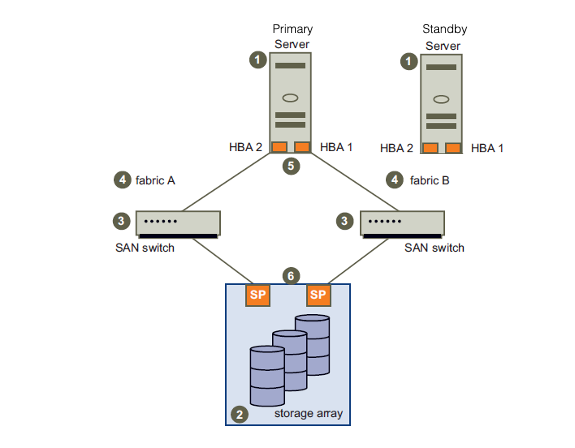
首當其衝要解決的是,如何保障資料庫服務的可用性。由於交易型業務往往都是企業中較為核心的往往會涉及金錢相關的線上業務,因此對資料庫服務的可用性有比較高的要求。最簡單地,通過把資料庫架設在共享儲存系統,將資料檔案儲存在共享儲存,實現資料庫例項和儲存介質的解耦,從而實現資料庫服務的高可用。
當資料庫所在機器出現故障時,另一臺備用機器通過接管共享儲存的資料檔案並快速對外繼續提供資料庫服務,從而保障資料庫可用性。 不過,傳統的共享儲存也是一種高昂的硬體裝置,其本身的成本&可用性&容量同樣面臨著硬體的限制,所以採用共享儲存的資料庫方案一直難以大規模流行開來。直到後來分散式檔案儲存系統的日益成熟,這種資料庫方案才真正地流行開來。時至今日,事實證明雲盤產品能在雲分散式環境提供穩定可靠的儲存服務,以RDS為代表的各類雲資料庫產品普遍通過雲盤的可用性來保障資料庫服務的可用性。
共享儲存方案的缺點也很明顯。一方面,資料放在遠端的共享儲存意味著資料庫需要通過網路才能訪問資料,這導致比單機資料庫更明顯的訪問延遲和效能開銷。資料庫方案引入共享儲存,意味著額外引入了對網路&共享儲存等更多的外部依賴,進而導致整個資料庫的穩定性有所降低。
另一方面,共享儲存方案需要另一臺備用機器時刻等待著接管資料庫服務,意味著一個資料庫服務需要兩臺機器但卻只能有一臺機器在提供服務,無法充分利用備用機器資源。因此,如何更好地將閒置的備用機器利用起來,也是一個重要的技術課題。與此同時,當前網際網路時代流量特點除海量資料/海量吞吐外,還包括寫入修改只佔據請求總覽的一小部分,使用者請求絕大部分都是對內容的查詢展示,內容查詢場景對資料實時性的要求並不高。基於上述特點,既然另一臺備用機器本身空閒又能訪問到所有的資料,那是不是可以讓它也同時提供一些歷史版本的只讀查詢服務呢?是的,雲盤儲存方案就能通過只讀節點的方式把原本災備用的節點對外提供只讀服務,從而提升整個資料庫系統的查詢能力。
**2. 共享儲存方案的演進**
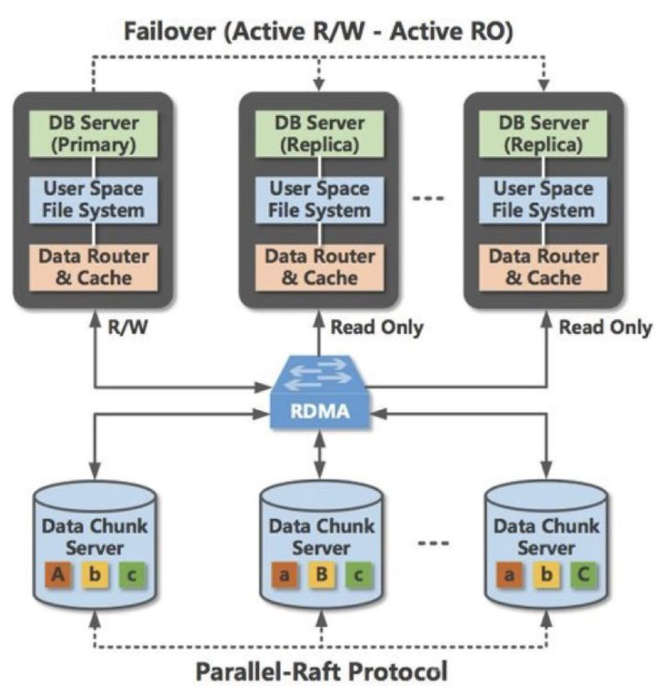
然而,雲盤儲存方案只是相對簡單地將資料庫服務架構在雲盤上,只讀節點無法和讀寫節點同時訪問共享儲存的同一份資料檔案,只能通過單獨使用一份共享儲存檔案後再通過額外機制來和主節點進行同步來實現。共享儲存中的資料檔案本身就是有多副本的,這意味著資料庫層面的多節點會帶來乘法效應,浪費更多的儲存資源。這和提高機器資源利用率的初衷是想違背的,而且沒有利用上共享儲存可以被多個機器訪問到的天然優勢。那麼,有沒有辦法讓資料庫例項的主節點和多個只讀節點同時使用一份共享儲存資料檔案呢?
共享盤儲存方案,通過在資料庫層實現多節點間的協調同步,規避多個節點各自對資料檔案的變更衝突,從而實現一份資料儲存多個節點服務的資料庫架構。共享盤儲存方案在利用儲存產品高可用性保障資料庫可用性之餘,又很好地利用了共享儲存的資料共享優勢提供多節點服務。
**3. 可計算儲存**
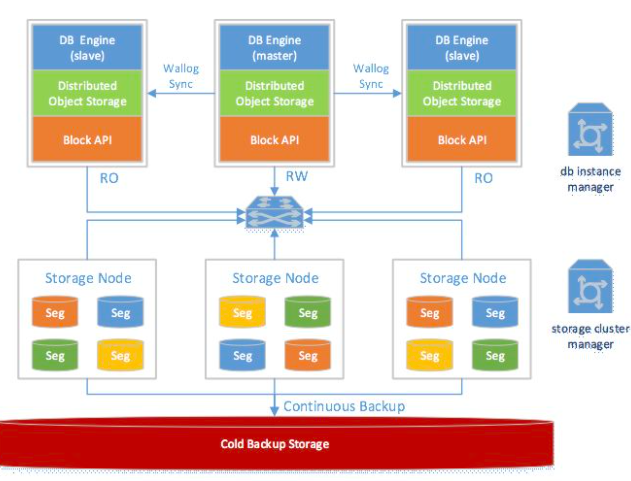
共享盤儲存方案的查詢效能可以通過多個只讀例項進行擴充套件,但寫入請求只有一個讀寫節點可以提供服務。而讀寫節點的效能極限仍然受限於單機硬體的效能上限,特別是網路IO裝置的效能上限,不僅沒從分散式架構中獲得收益,甚至由於共享儲存的額外開銷反而有所下滑。那麼,要怎麼樣才能讓資料庫服務的寫入效能從分散式共享儲存中獲益呢?
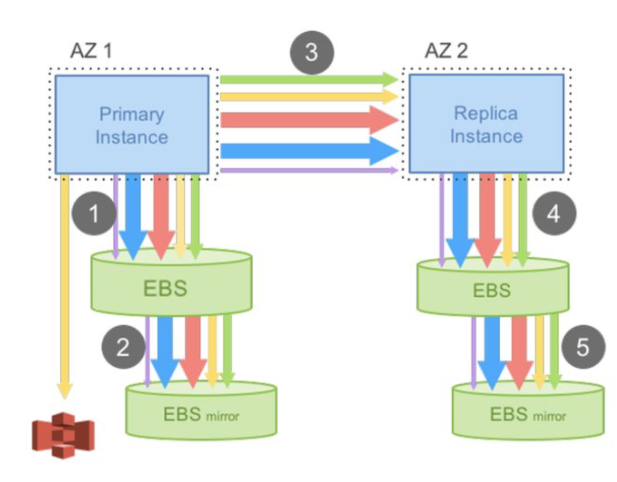
可計算儲存方案即是業界對這一問題給出的一份答卷。經過長時間的觀察研究,工程師們發現線上資料庫服務的寫入效能瓶頸通常都在網路IO。特別是RDS資料庫在執行期間需要不停刷寫預寫日誌(write ahead log)/資料檔案(data file)等多種資料到遠端的分散式共享儲存,佔用了大量機器IO容量。但與此同時,RDS資料庫持久化到分散式共享儲存的預寫日誌/資料檔案等資料中包含了大量的冗餘資訊。比如,針對MySQL/innodb資料庫架構下的binlog/redolog這兩種預寫日誌,雖然日誌格式各不相同(邏輯日誌/物理日誌),但二者都是對同一份資料修改的記錄,卻佔用兩倍IO流量。再比如資料庫以頁為單位持久化資料檔案,而資料檔案的頁大小通常是16KB,意味著即使只修改某一頁中的一行記錄,在寫資料檔案的時候資料庫例項也會產生16KB IO流量,存在比較大的寫放大現象。甚至更近一步地,這一行記錄的資料變更其實已經隨著之前的預寫日誌寫到分散式共享儲存,寫資料檔案的髒頁資料完全沒有必要,是一種浪費!!
單機資料庫之所以採用預寫日誌技術,是為了通過把資料髒頁的隨機寫操作變成預寫日誌的順序寫操作,從而提升單機資料庫整體效能。但預寫日誌技術只能推遲並儘可能合併對資料檔案的隨機寫入操作,卻不能完全避免對資料檔案的隨機寫入。單機資料庫需要不斷地把髒頁逐步刷寫到資料檔案來推進檢查點,從而釋放出更多的日誌容量&控制例項故障的恢復時長。而刷髒頁通常屬於磁碟隨機寫操作,特別在隨機寫入的業務場景下,非常影響資料庫效能,是單機資料庫的一大效能瓶頸點。
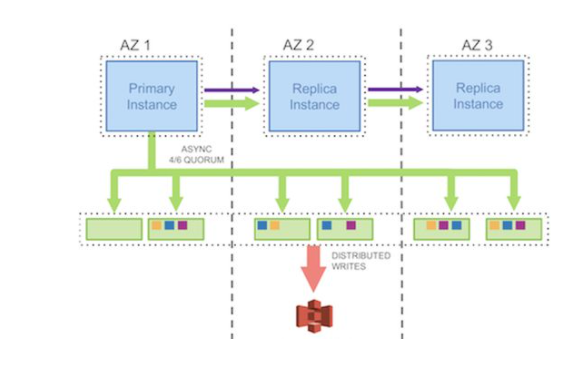
因此,工程師們提出了Log is Database的技術理念,這也是可計算儲存方案的核心理念。資料庫讀寫節點只通過必要的預寫日誌把資料庫資料變更資訊傳遞給分散式共享儲存,而不再需要傳遞資料檔案髒頁等額外資訊,讀寫節點機器的IO開銷大大減少。那麼,資料檔案的資料變更怎麼辦呢?既然預寫日誌裡面已經有所有的資料變更資訊,那分散式共享儲存系統可以直接從預寫日誌裡獲取到資料變更資訊,直接將其更新到相應的資料檔案中。針對MySQL/innodb資料庫架構,更是可以進一步把binlog日誌直接省略,單單傳遞redolog日誌就足以把整個資料庫的資料變更傳遞到共享儲存系統,大大減少了RDS MySQL資料庫例項的IO流量,有效提升了MySQL資料庫的效能上限。
在此方案中,資料庫讀寫節點只需要負責傳遞必要的預寫日誌給儲存系統,不再需要處理資料檔案更新維護的任務。而這部分資料維護任務由於涉及大量緩慢的資料IO操作,往往正是整個資料庫系統的效能瓶頸所在。資料庫讀寫節點從維護資料檔案的高昂開銷中脫身後,也得以擁有了極高的資料寫入效能。而分散式共享儲存系統在處理資料維護任務時,由於自身的分散式架構優勢,天然可以通過新增新節點的方式進行水平擴充套件,不斷提升整個系統的吞吐效能上限。
在海量寫入的場景中,資料庫通常會延緩推進檢查點&保留較多預寫日誌,儘量避免頻繁刷髒頁導致影響資料庫效能。而資料庫在故障恢復時又必須回放在檢查點後的所有預寫日誌,以保障資料一致性。因此,資料庫在海量寫入場景故障恢復中可能會因回放預寫日誌而消耗大量時間,導致資料庫服務較長時間無法服務。由於儲存系統的分散式架構優勢,可計算儲存方案預寫日誌回放操作被打散到多個儲存節點上並行執行,極大提升故障恢復的速度,有效減少資料庫服務的不可用時間。
更進一步的,由於擁有資料庫全量歷史資訊,分散式儲存系統能夠提供歷史版本資料頁內容。在讀取歷史版本資料的時候,資料庫節點只需要在資料頁請求中帶上歷史版本資訊。分散式儲存系統在收到歷史版本請求時,通過讀取該資料頁當前的資料檔案和歷史相關的回滾日誌(undolog),然後將兩者處理生產歷史版本資料頁後返回。由此,資料庫歷史資料處理任務也被下沉到儲存系統,得以利用分散式儲存系統的水平擴充套件優勢來提升資料庫的歷史資料查詢效能。
至此可以看到,與共享盤儲存方案相比,可計算儲存方案雖然寫入請求只有一個讀寫節點可以提供服務,但該讀寫節點只需要負責請求解析、查詢執行、事務管理、快取管理等任務,而資料檔案更新維護、資料頁版本維護這部分資料庫中開銷極重的部分流程卻擁有了水平擴充套件的能力。這意味著可計算儲存方案在保證可用性的基礎上,已經在一定程度上擺脫了傳統單機資料庫面臨的硬體瓶頸,大大提升了服務能力上限。
# 四、總結
文章篇幅所限,本文簡單地介紹了基於共享儲存的架構下資料庫產品從單機資料庫逐步向分散式資料庫眼睛的發展歷程中逐步面對的問題和對應的解決思路。後續文章中,筆者將嘗試探討資料庫的另一條發展路線,即基於獨立儲存的架構下資料庫產品如何從單機資料庫逐步走向分散式資料庫。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69940575/viewspace-2794930/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 分析型資料庫:分散式分析型資料庫資料庫分散式
- 分散式資料庫入門:以國產資料庫 TDSQL 為例分散式資料庫SQL
- 騰訊分散式資料庫TDSQL榮獲技術卓越獎分散式資料庫SQL
- 為資料賦能:騰訊TDSQL分散式金融級資料庫前沿技術SQL分散式資料庫
- 《核心系統分散式資料庫選型指南》選題背景及意義淺談分散式資料庫
- 分散式資料庫Google Spanner原理分析KP分散式資料庫Go
- 基於MySQL的分散式資料庫TDSQL十年鍛造經驗分享MySql分散式資料庫
- 分散式資料庫分散式資料庫
- 資料庫新兵:分散式實時分析記憶體資料庫eSight資料庫分散式記憶體
- 面向金融業的分散式交易型資料庫關鍵技術及發展探討分散式資料庫
- 首例“微服務+國產分散式資料庫”架構,TDSQL助力崑山農商行換“心”微服務分散式資料庫架構SQL
- 直播預告丨騰訊雲分散式資料庫TDSQL:產品設計思路與能力 - 墨讀資料庫專題分散式資料庫SQL
- 分散式關係型資料庫RadonDB體驗歸來分散式資料庫
- openGauss 分散式資料庫能力分散式資料庫
- 分散式資料庫 ZNBase 的分散式計劃生成分散式資料庫
- 「分散式技術專題」事務型、分析型資料資源隔離機制分散式
- 強!分庫分表與分散式資料庫技術選項分析分散式資料庫
- MySQL資料庫分散式事務XA的實現原理分析MySql資料庫分散式
- 《分散式資料庫HBase案例教程》分散式資料庫
- 騰訊雲分散式資料庫TDSQL在銀行傳統核心系統中的應用實踐分散式資料庫SQL
- 商業銀行如何進行分散式資料庫選型思考分散式資料庫
- 金融業分散式資料庫選型及HTAP場景實踐分散式資料庫
- 分散式資料庫火了 開源填補資料庫空白分散式資料庫
- 【大資料】BigTable分散式資料儲存系統分散式資料庫 | 複習筆記大資料分散式資料庫筆記
- 騰訊資料庫tdsql部署與驗證資料庫SQL
- 分散式資料庫系統(DDBS) 概述分散式資料庫
- 聊聊分散式 SQL 資料庫Doris(七)分散式SQL資料庫
- 聊聊分散式 SQL 資料庫Doris(六)分散式SQL資料庫
- 聊聊分散式 SQL 資料庫Doris(八)分散式SQL資料庫
- 聊聊分散式 SQL 資料庫Doris(四)分散式SQL資料庫
- 聊聊分散式 SQL 資料庫Doris(三)分散式SQL資料庫
- 分散式資料庫技術論壇分散式資料庫
- “熱搜”中的分散式資料庫分散式資料庫
- 分散式資料庫排序及優化分散式資料庫排序優化
- 分散式資料庫的健康評估分散式資料庫
- 從 Oracle 轉型 MySQL 分散式事務資料庫的實戰旅途OracleMySql分散式資料庫
- 真正硬核分散式資料庫:開發分散式SQL資料庫的6種技術挑戰 - YugaByte分散式資料庫SQL
- (二) MdbCluster分散式記憶體資料庫——分散式架構1分散式記憶體資料庫架構