一致性hash演算法
先從歷史的角度來一步步分析,探討一下到底什麼是Hash一致性演算法!
一、Redis叢集的使用
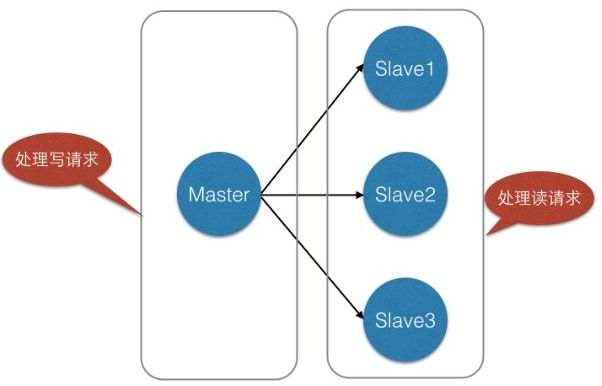
我們在使用Redis的時候,為了保證Redis的高可用,提高Redis的讀寫效能,最簡單的方式我們會做主從複製,組成Master-Master或者Master-Slave的形式,或者搭建Redis叢集,進行資料的讀寫分離,類似於資料庫的主從複製和讀寫分離。如下所示:
同樣類似於資料庫,當單表資料大於500W的時候需要對其進行分庫分表,當資料量很大的時候(標準可能不一樣,要看Redis伺服器容量)我們同樣可以對Redis進行類似的操作,就是分庫分表。
假設,我們有一個社交網站,需要使用Redis儲存圖片資源,儲存的格式為鍵值對,key值為圖片名稱,value為該圖片所在檔案伺服器的路徑,我們需要根據檔名查詢該檔案所在檔案伺服器上的路徑,資料量大概有2000W左右,按照我們約定的規則進行分庫,規則就是隨機分配,我們可以部署8臺快取伺服器,每臺伺服器大概含有500W條資料,並且進行主從複製,示意圖如下:
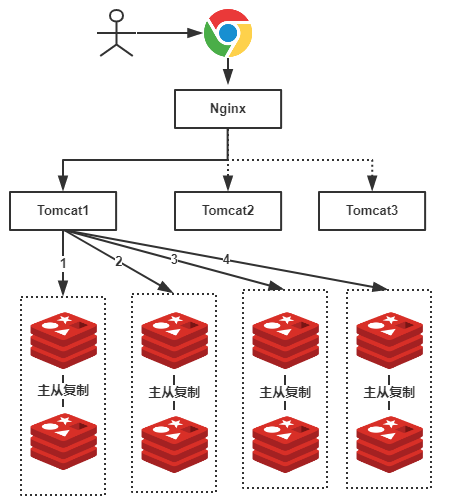
由於規則是隨機的,所有我們的一條資料都有可能儲存在任何一組Redis中,例如上圖我們使用者查詢一張名稱為”a.png”的圖片,由於規則是隨機的,我們不確定具體是在哪一個Redis伺服器上的,因此我們需要進行1、2、3、4,4次查詢才能夠查詢到(也就是遍歷了所有的Redis伺服器),這顯然不是我們想要的結果,有了解過的小夥伴可能會想到,隨機的規則不行,可以使用類似於資料庫中的分庫分表規則:按照Hash值、取模、按照類別、按照某一個欄位值等等常見的規則就可以出來了!好,按照我們的主題,我們就使用Hash的方式。
二、為Redis叢集使用Hash
可想而知,如果我們使用Hash的方式,每一張圖片在進行分庫的時候都可以定位到特定的伺服器,示意圖如下:
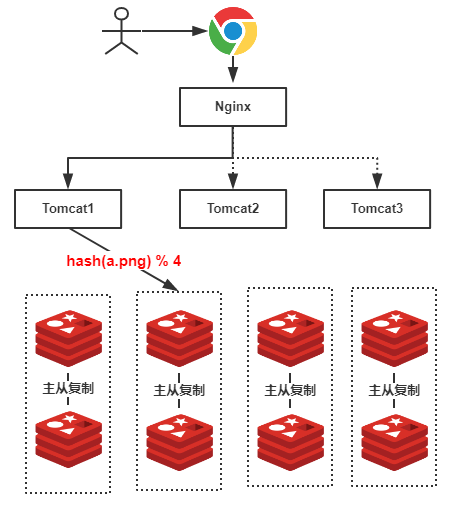
上圖中,假設我們查詢的是”a.png”,由於有4臺伺服器(排除從庫),因此公式為hash(a.png) % 4 = 2 ,可知定位到了第2號伺服器,這樣的話就不會遍歷所有的伺服器,大大提升了效能!
三、使用Hash的問題
上述的方式雖然提升了效能,我們不再需要對整個Redis伺服器進行遍歷!但是,使用上述Hash演算法進行快取時,會出現一些缺陷,主要體現在伺服器數量變動的時候,所有快取的位置都要發生改變!
試想一下,如果4臺快取伺服器已經不能滿足我們的快取需求,那麼我們應該怎麼做呢?很簡單,多增加幾臺快取伺服器不就行了!假設:我們增加了一臺快取伺服器,那麼快取伺服器的數量就由4臺變成了5臺。那麼原本hash(a.png) % 4 = 2 的公式就變成了hash(a.png) % 5 = ? , 可想而知這個結果肯定不是2的,這種情況帶來的結果就是當伺服器數量變動時,所有快取的位置都要發生改變!換句話說,當伺服器數量發生改變時,所有快取在一定時間內是失效的,當應用無法從快取中獲取資料時,則會向後端資料庫請求資料(還記得上一篇的《快取雪崩》嗎?)!
同樣的,假設4臺快取中突然有一臺快取伺服器出現了故障,無法進行快取,那麼我們則需要將故障機器移除,但是如果移除了一臺快取伺服器,那麼快取伺服器數量從4臺變為3臺,也是會出現上述的問題!
所以,我們應該想辦法不讓這種情況發生,但是由於上述Hash演算法本身的緣故,使用取模法進行快取時,這種情況是無法避免的,為了解決這些問題,Hash一致性演算法(一致性Hash演算法)誕生了!
四、一致性Hash演算法的神祕面紗
一致性Hash演算法也是使用取模的方法,只是,剛才描述的取模法是對伺服器的數量進行取模,而一致性Hash演算法是對2^32取模,什麼意思呢?簡單來說,一致性Hash演算法將整個雜湊值空間組織成一個虛擬的圓環,如假設某雜湊函式H的值空間為0-2^32-1(即雜湊值是一個32位無符號整形),整個雜湊環如下:
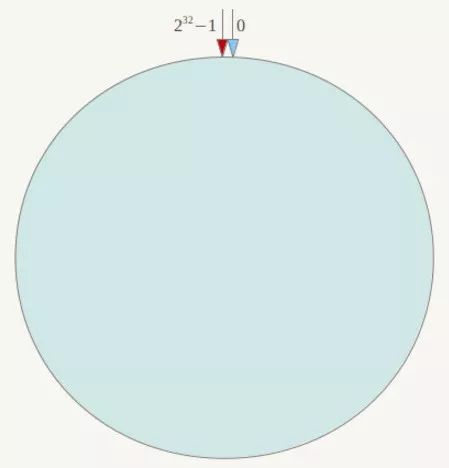
整個空間按順時針方向組織,圓環的正上方的點代表0,0點右側的第一個點代表1,以此類推,2、3、4、5、6……直到2^32-1,也就是說0點左側的第一個點代表2^32-1, 0和2^32-1在零點中方向重合,我們把這個由2^32個點組成的圓環稱為Hash環。
下一步將各個伺服器使用Hash進行一個雜湊,具體可以選擇伺服器的IP或主機名作為關鍵字進行雜湊,這樣每臺機器就能確定其在雜湊環上的位置,這裡假設將上文中四臺伺服器使用IP地址雜湊後在環空間的位置如下:
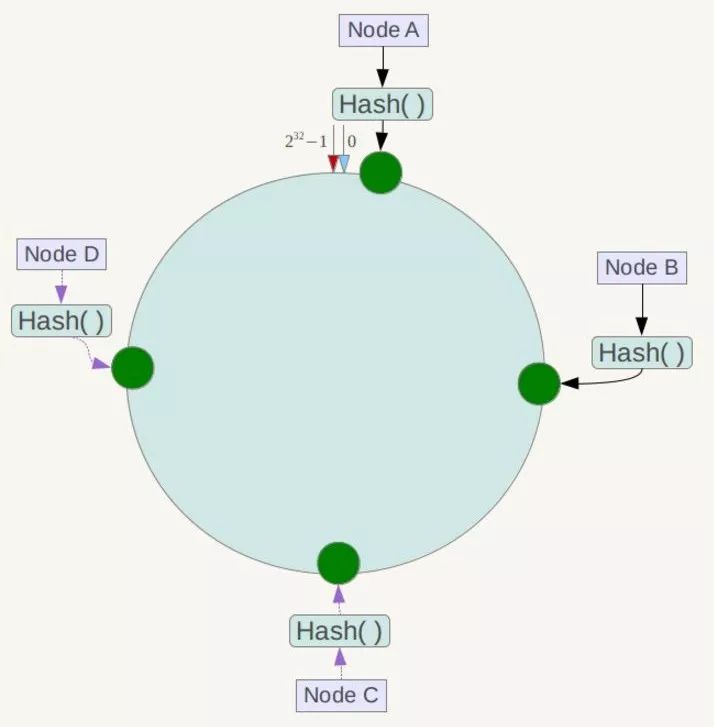
接下來使用如下演算法定位資料訪問到相應伺服器:將資料key使用相同的函式Hash計算出雜湊值,並確定此資料在環上的位置,從此位置沿環順時針“行走”,第一臺遇到的伺服器就是其應該定位到的伺服器!
例如我們有Object A、Object B、Object C、Object D四個資料物件,經過雜湊計算後,在環空間上的位置如下:
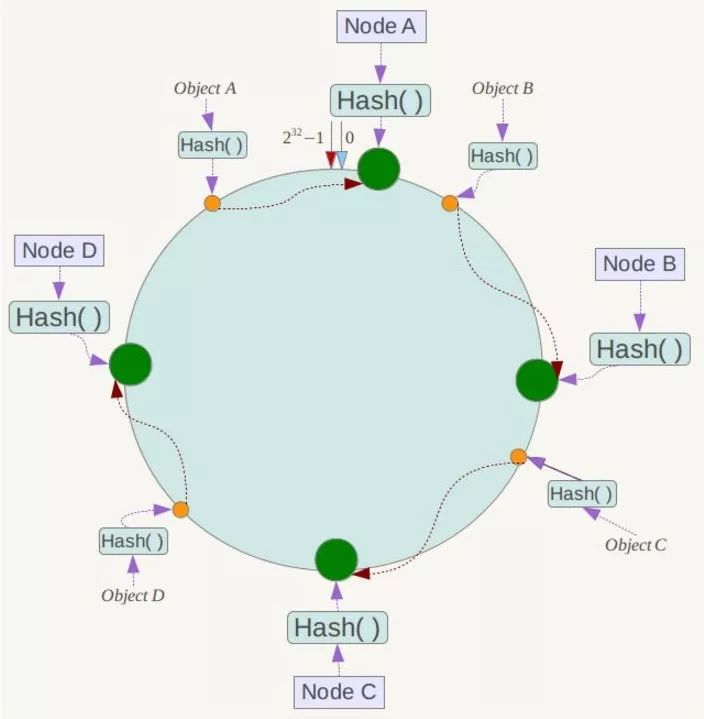
根據一致性Hash演算法,資料A會被定為到Node A上,B被定為到Node B上,C被定為到Node C上,D被定為到Node D上。
五、一致性Hash演算法的容錯性和可擴充套件性
現假設Node C不幸當機,可以看到此時物件A、B、D不會受到影響,只有C物件被重定位到Node D。一般的,在一致性Hash演算法中,如果一臺伺服器不可用,則受影響的資料僅僅是此伺服器到其環空間中前一臺伺服器(即沿著逆時針方向行走遇到的第一臺伺服器)之間資料,其它不會受到影響,如下所示:
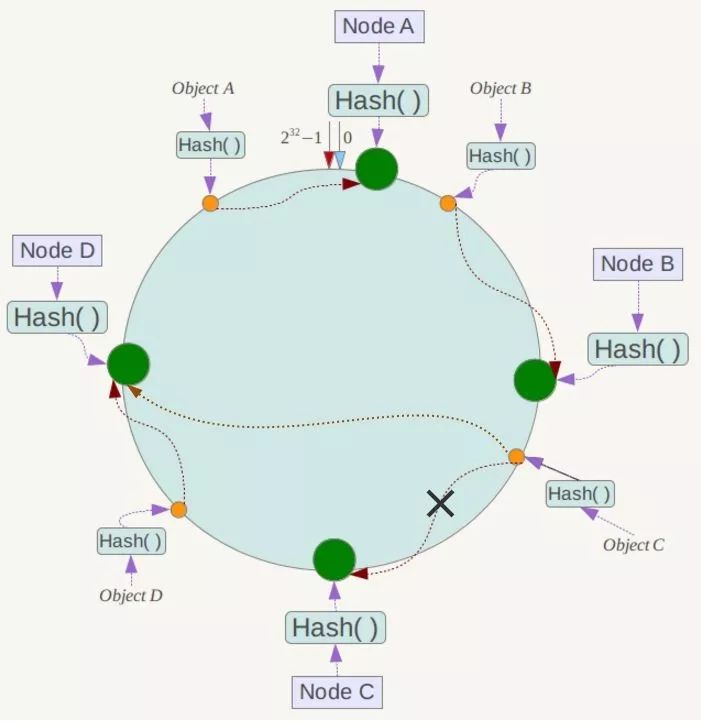
下面考慮另外一種情況,如果在系統中增加一臺伺服器Node X,如下圖所示:
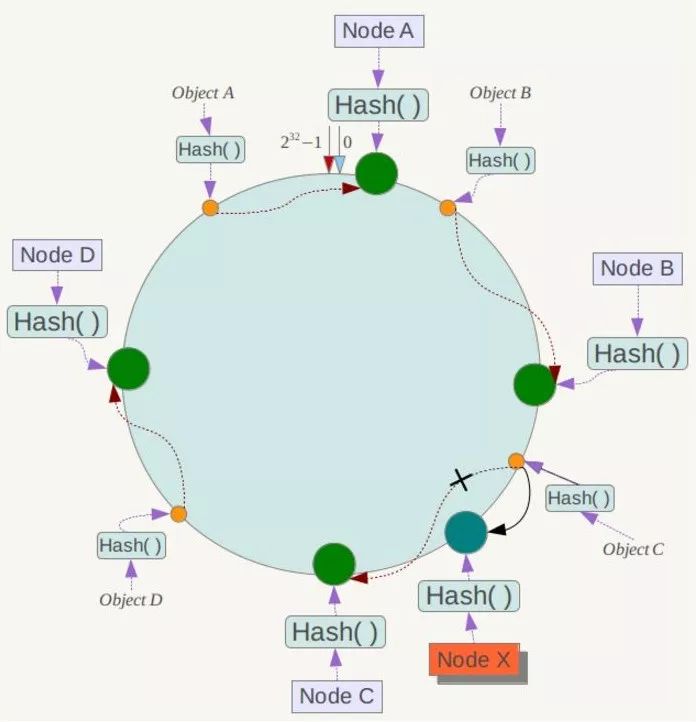
此時物件Object A、B、D不受影響,只有物件C需要重定位到新的Node X !一般的,在一致性Hash演算法中,如果增加一臺伺服器,則受影響的資料僅僅是新伺服器到其環空間中前一臺伺服器(即沿著逆時針方向行走遇到的第一臺伺服器)之間資料,其它資料也不會受到影響。
綜上所述,一致性Hash演算法對於節點的增減都只需重定位環空間中的一小部分資料,具有較好的容錯性和可擴充套件性。
六、Hash環的資料傾斜問題
一致性Hash演算法在服務節點太少時,容易因為節點分部不均勻而造成資料傾斜(被快取的物件大部分集中快取在某一臺伺服器上)問題,例如系統中只有兩臺伺服器,其環分佈如下:
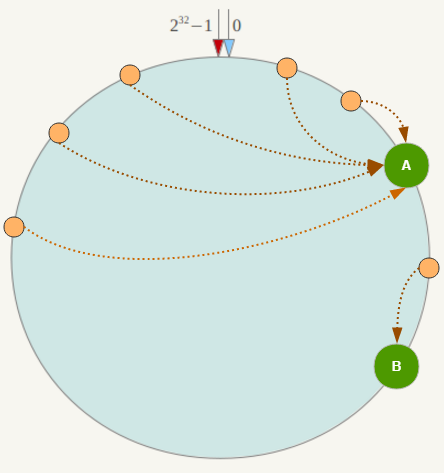
此時必然造成大量資料集中到Node A上,而只有極少量會定位到Node B上。為了解決這種資料傾斜問題,一致性Hash演算法引入了虛擬節點機制,即對每一個服務節點計算多個雜湊,每個計算結果位置都放置一個此服務節點,稱為虛擬節點。具體做法可以在伺服器IP或主機名的後面增加編號來實現。
例如上面的情況,可以為每臺伺服器計算三個虛擬節點,於是可以分別計算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的雜湊值,於是形成六個虛擬節點:
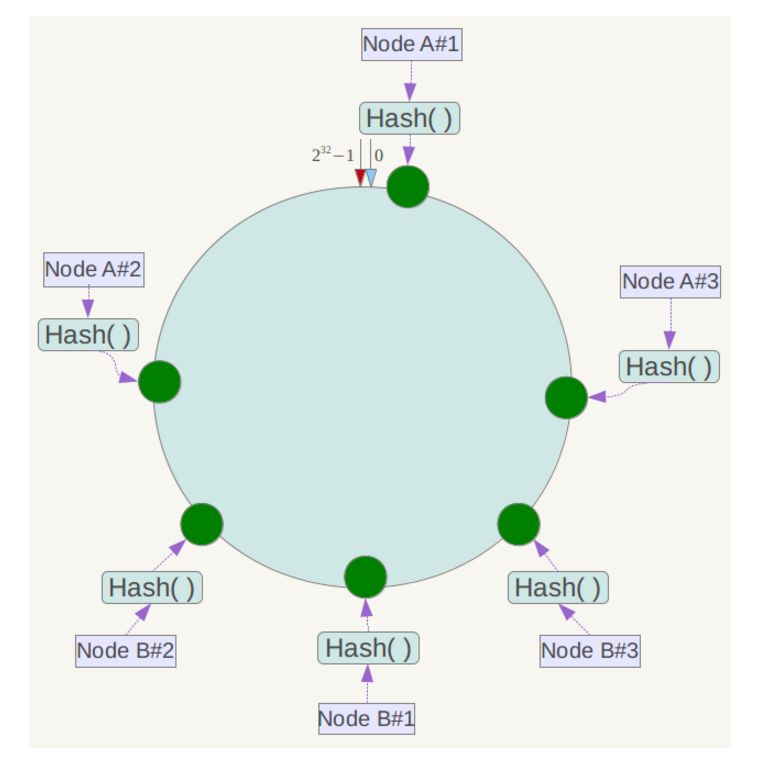
同時資料定位演算法不變,只是多了一步虛擬節點到實際節點的對映,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三個虛擬節點的資料均定位到Node A上。這樣就解決了服務節點少時資料傾斜的問題。在實際應用中,通常將虛擬節點數設定為32甚至更大,因此即使很少的服務節點也能做到相對均勻的資料分佈。
七、總結
上文中,我們一步步分析了什麼是一致性Hash演算法,主要是考慮到分散式系統每個節點都有可能失效,並且新的節點很可能動態的增加進來的情況,如何保證當系統的節點數目發生變化的時候,我們的系統仍然能夠對外提供良好的服務,這是值得考慮的!
注:本文汲取了網上很多優秀的文章以及自己的一點經驗整理而來,為了不影響排版的簡潔與美觀,這裡不再貼上出一大堆的連結地址,為感謝對參考文章作者的辛勤付出與分享,參考文章請點選閱讀原文進行檢視!
相關文章
- 一致性hash演算法的理解演算法
- PHP 之一致性 hash 演算法PHP演算法
- 什麼是一致性Hash演算法?演算法
- 手動實現一致性 Hash 演算法演算法
- 一致性Hash
- 自己實現一個一致性 Hash 演算法演算法
- 一致性 Hash 演算法的實際應用演算法
- 10分鐘瞭解一致性hash演算法演算法
- 一致性hash演算法原理及go實現演算法Go
- 一致性hash演算法的一些理解演算法
- 五分鐘瞭解一致性hash演算法演算法
- 【轉】什麼是一致性hash演算法?(詳解)演算法
- 一致性 hash 環
- 強一致性hash實現java版本及強一致性hash原理Java
- Java教程分享:五分鐘瞭解一致性hash演算法Java演算法
- Hash演算法演算法
- 深入淺出一致性Hash原理
- 一致性Hash的原理與實現
- Hash join演算法原理(轉)演算法
- 一致性Hash在負載均衡中的應用負載
- 一文搞懂一致性hash的原理和實現
- 一文搞懂一致性 hash 的原理和實現
- 一致性hash原理 看這一篇就夠了
- Golang 實現 Redis(7): Redis 叢集與一致性 HashGolangRedis
- 影象相似度中的Hash演算法演算法
- 區塊鏈概念1:Hash演算法區塊鏈演算法
- 分享一種最小 Perfect Hash 生成演算法演算法
- 給面試官講明白:一致性Hash的原理和實踐面試
- 常見一致性演算法演算法
- 短連結演算法實現–加鹽hash演算法
- paxos分散式一致性演算法分散式演算法
- Paxos——分散式一致性演算法分散式演算法
- raft演算法一致性的研究Raft演算法
- day13 一致性hash演算法(快取擴容) redis哨兵機制(高可用) redis叢集(高可用,快取擴容)演算法快取Redis
- 使用模擬退火演算法優化 Hash 函式演算法優化函式
- 識別雜湊演算法型別hash-identifier演算法型別IDE
- HashMap中的hash演算法中的幾個疑問HashMap演算法
- hash