寫給大家看的 “不負責任” K8s 入門文件
作者 | 鄧青琳(輕零) 阿里巴巴技術專家
導讀:本文轉載自阿里巴巴技術專家鄧青琳 (輕零) 在內部的分享,他從阿里雲控制檯團隊轉崗到 ECI 研發團隊(Serverless Kubernetes 背後的實現基石),從零開始瞭解 K8s,並從業務發展的視角整理了 K8s 是如何出現的,又是如何工作的。
前言
2019 年下半年,我做了一次轉崗,開始接觸到 Kubernetes,雖然對 K8s 的認識還非常的不全面,但是非常想分享一下自己的一些收穫,希望通過本文能夠幫助大家對 K8s 有一個入門的瞭解。文中有不對的地方,還請各位老司機們幫助指點糾正。
其實介紹 K8s 的文章,網上一搜一大把,而且 Kubernetes 官方文件也寫的非常友好,所以直接上來講 K8s,我覺得我是遠遠不如網上的一些文章講的好的。因此我想換一個角度,通過一個業務發展的故事角度,來講 K8s 是怎麼出現的,它又是如何運作的。
故事開始

隨著中國老百姓生活水平的不斷提高,家家戶戶都有了小汽車,小王預計 5 年後,汽車報廢業務將會迅速發展,而且國家在 2019 年也出臺了新政策《報廢機動車回收管理辦法》,取消了汽車報廢回收的 “特種行業” 屬性,將開放市場化的競爭。
小王覺得這是一個創業的好機會,於是找了幾個志同道合的小夥伴開始了創業,決定做一個叫 “淘車網” 的平臺。
故事發展
淘車網一開始是一個 all in one 的 java 應用,部署在一臺物理機上 (小王同學,現在都啥時候了,你需要了解一下阿里雲),隨著業務的發展,機器越來越扛不住了,就趕緊對伺服器的規格做了升級,從 64c256g 一路升到了 160c1920g,雖然成本高了點,但是系統至少沒出問題。
業務發展了一年後,160c1920g 也扛不住了,不得不進行服務化拆分、分散式改造了。為了解決分散式改造過程中的各種問題,引入了一系列的中介軟體,類似 hsf、tddl、tair、diamond、metaq 等,在艱難的業務架構改造後,我們成功的把 all in one 的 java 應用拆分成了多個小應用,重走了一遍當年阿里中介軟體發展和去 IOE 的道路。
分散式改完後,我們管理的伺服器又多起來了,不同批次的伺服器,硬體規格、作業系統版本等等都不盡相同,於是應用執行和運維的各種問題就出來了。
還好有虛擬機器技術,把底層各種硬體和軟體的差異,通過虛擬化技術都給遮蔽掉了。雖然硬體不同,但是對於應用來說,看到的都是一樣的啦,此時虛擬化又產生了很大的效能開銷。
恩,不如我們使用 docker 吧,因為 docker 基於 cgroup 等 Linux 的原生技術,在遮蔽底層差異的同時,也沒有明顯的效能影響,真是一個好東西。而且基於 docker 映象的業務交付,使得我們 CI/CD 的運作也非常的容易。

不過隨著 docker 容器數量的增長,我們又不得不面對新的難題,就是大量的 docker 如何排程、通訊呢?畢竟隨著業務發展,淘車網已經不是一個小公司了,我們執行著幾千個 docker 容器,並且按照現在的業務發展趨勢,馬上就要破萬了。
不行,我們一定要做一個系統,這個系統能夠自動的管理伺服器(比如是不是健康、剩下多少記憶體和 cpu 可以使用啊等等)、然後根據容器宣告所需的 cpu 和 memory 選擇最優的伺服器進行容器的建立,並且還要能夠控制容器和容器之間的通訊(比如說某個部門的內部服務,當然不希望其他部門的容器也能夠訪問)。
我們給這個系統取一個名字,就叫做容器編排系統吧。
容器編排系統

那麼問題來了,面對一堆的伺服器,我們要怎麼實現一個容器編排系統呢?
先假設我們已經實現了這個編排系統,那麼我們的伺服器就會有一部分會用來執行這個編排系統,剩下的伺服器用來執行我們的業務容器,我們把執行編排系統的伺服器叫做 master 節點,把執行業務容器的伺服器叫做 worker 節點。
既然 master 節點負責管理伺服器叢集,那它就必須要提供出相關的管理介面,一個是方便運維管理員對叢集進行相關的操作,另一個就是負責和 worker 節點進行互動,比如進行資源的分配、網路的管理等。
我們把 master 上提供管理介面的元件稱為 kube apiserver,對應的還需要兩個用於和 api server 互動的客戶端:
- 一個是提供給叢集的運維管理員使用的,我們稱為 kubectl;
- 一個是提供給 worker 節點使用的,我們稱為 kubelet。
現在叢集的運維管理員、master 節點、worker 節點已經可以彼此間進行互動了,比如說運維管理員通過 kubectl 向 master 下發一個命令:“用淘車網使用者中心 2.0 版本的映象建立 1000 個容器”,master 收到這個請求之後,就要根據叢集裡面 worker 節點的資源資訊進行一個計算排程,算出來這 1000 個容器應該在哪些 worker 上進行建立,然後把建立指令下發到相應的 worker 上。我們把這個負責排程的元件稱為 kube scheduler。
那 master 又是怎麼知道各個 worker 上的資源消耗和容器的執行情況的呢?這個簡單,我們可以通過 worker 上的 kubelet 週期性的主動上報節點資源和容器執行的情況,然後 master 把這個資料儲存下來,後面就可以用來做排程和容器的管理使用了。至於資料怎麼儲存,我們可以寫檔案、寫 db 等等,不過有一個開源的儲存系統叫 etcd,滿足我們對於資料一致性和高可用的要求,同時安裝簡單、效能又好,我們就選 etcd 吧。
現在我們已經有了所有 worker 節點和容器執行的資料,我們可以做的事情就非常多了。比如前面所說的,我們使用淘車網使用者中心 2.0 版本的映象建立了 1000 個容器,其中有 5 個容器都是執行在 A 這個 worker 節點上,那如果 A 這個節點突然出現了硬體故障,導致節點不可用了,這個時候 master 就要把 A 從可用 worker 節點中摘除掉,並且還需要把原先執行在這個節點上的 5 個使用者中心 2.0 的容器重新排程到其他可用的 worker 節點上,使得我們使用者中心 2.0 的容器數量能夠重新恢復到 1000 個,並且還需要對相關的容器進行網路通訊配置的調整,使得容器間的通訊還是正常的。我們把這一系列的元件稱為控制器,比如節點控制器、副本控制器、端點控制器等等,並且為這些控制器提供一個統一的執行元件,稱為控制器管理器(kube-controller-manager)。
那 master 又該如何實現和管理容器間的網路通訊呢?首先每個容器肯定需要有一個唯一的 ip 地址,通過這個 ip 地址就可以互相通訊了,但是彼此通訊的容器有可能執行在不同的 worker 節點上,這就涉及到 worker 節點間的網路通訊,因此每個 worker 節點還需要有一個唯一的 ip 地址,但是容器間通訊都是通過容器 ip 進行的,容器並不感知 worker 節點的 ip 地址,因此在 worker 節點上需要有容器 ip 的路由轉發資訊,我們可以通過 iptables、ipvs 等技術來實現。那如果容器 ip 變化了,或者容器數量變化了,這個時候相關的 iptables、ipvs 的配置就需要跟著進行調整,所以在 worker 節點上我們需要一個專門負責監聽並調整路由轉發配置的元件,我們把這個元件稱為 kube proxy。
我們已經解決了容器間的網路通訊,但是在我們編碼的時候,我們希望的是通過域名或者 vip 等方式來呼叫一個服務,而不是通過一個可能隨時會變化的容器 ip。因此我們需要在容器 ip 之上再封裝出一個 service 的概念,這個 service 可以是一個叢集的 vip,也可以是一個叢集的域名,為此我們還需要一個叢集內部的 DNS 域名解析服務。
另外雖然我們已經有了 kubectl,可以很愉快的和 master 進行互動了,但是如果有一個 web 的管理介面,這肯定是一個更好的事情。此處之外,我們可能還希望看到容器的資源資訊、整個叢集相關元件的執行日誌等等。
像 DNS、web 管理介面、容器資源資訊、叢集日誌,這些可以改善我們使用體驗的元件,我們統稱為外掛。
至此,我們已經成功構建了一個容器編排系統,下面我們來簡單總結一下上文提到的各個組成部分:
- Master 元件:kube-apiserver、kube-scheduler、etcd、kube-controller-manager;
- Node 元件:kubelet、kube-proxy;
- 外掛:DNS、使用者介面 Web UI、容器資源監控、叢集日誌。
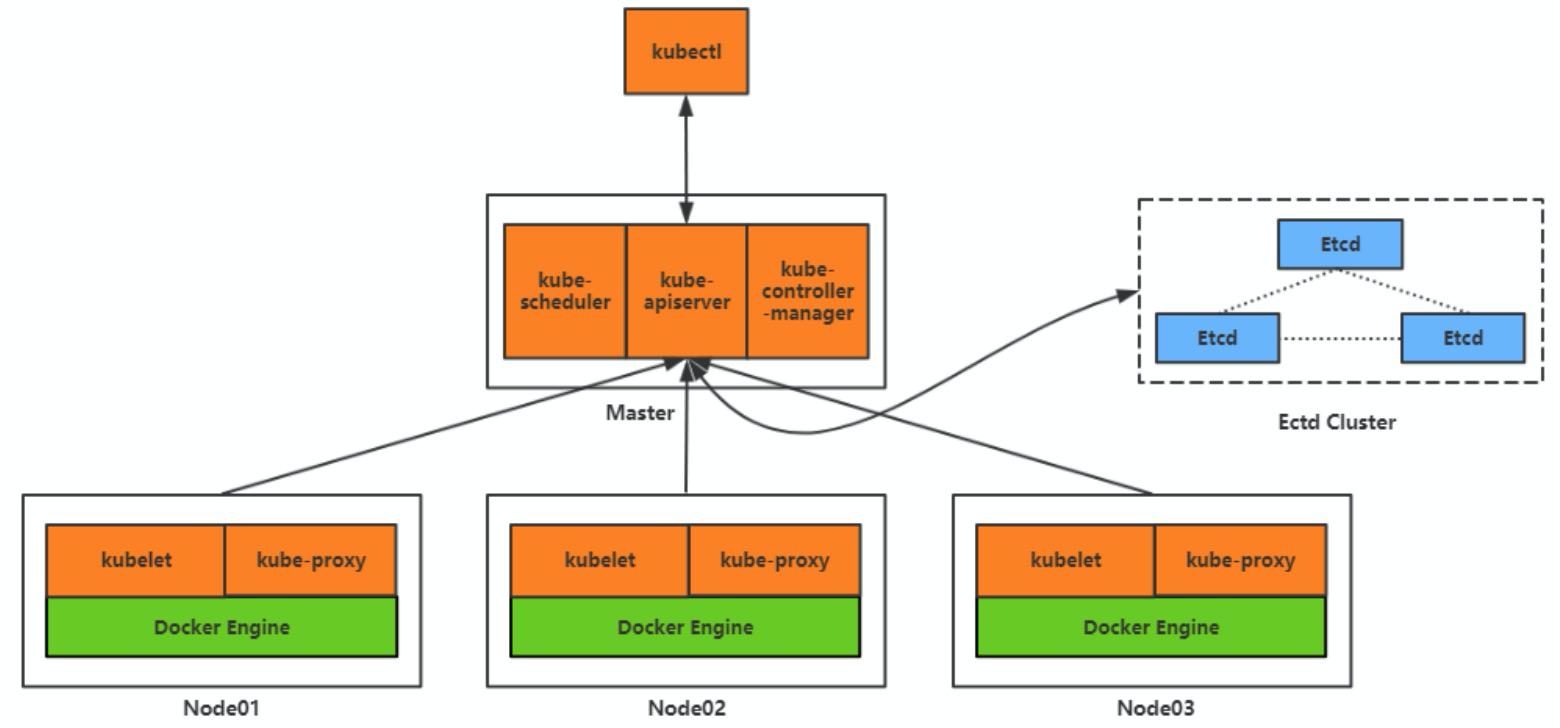
這些也正是 K8s 中的重要組成部分。當然 K8s 作為一個生產級別的容器編排系統,這裡提到的每一個元件都可以拿出來單獨講上很多內容,本文只是一個簡單入門,不再展開講解。
Serverless 的容器編排系統
雖然我們已經成功實現了一個容器編排系統,並且也用的很舒服,但是淘車網的王總裁(已經不是當年的小王了)覺得公司花在這個編排系統上的研發和運維成本實在是太高了,想要縮減這方面的成本。王總想著有沒有一個編排系統,能夠讓員工專注到業務開發上,而不需要關注到叢集的運維管理上,於是他和技術圈的同學瞭解了一下,發現 Serverless 的理念和他的想法不謀而合,於是就在想:啥時候出一個 Serverless 的容器編排系統就好啦。
幸運的是,王總在阿里雲網站上,看到了一款叫做 Serverless Kubernetes 的產品。。。後面的故事就不展開講了,因為到了這個地方,更重要的事情就出現了。
招人啦!
雲原生和 ECI 研發團隊招人啦,讓我們一起打造業界領先的雲原生和彈性計算服務,為社會提供穩定高效的數字經濟基礎設施!
- 3 年以上分散式系統相關經驗,熟悉高併發,分散式通訊,儲存等相關技術;
- 熟練掌握 Golang/Java/Rust 語言開發,具備 Python, Shell 等其它一種或多種語言開發經驗;
- 對容器和基礎設施相關領域的技術充滿熱情,有 PaaS 平臺相關經驗,在相關的領域如 Kubernetes、Serverless 平臺、容器技術、應用管理平臺等有豐富的積累和實踐經驗(如產品落地,創新的技術實現,開源的突出貢獻,領先的學術研究成果等)。
簡歷投遞通道:
- cloudnativehire@list.alibaba-inc.com(雲原生)
- lingzhi.wlz@alibaba-inc.com(ECI)

“阿里巴巴雲原生關注微服務、Serverless、容器、Service Mesh 等技術領域、聚焦雲原生流行技術趨勢、雲原生大規模的落地實踐,做最懂雲原生開發者的公眾號。”

- 加微信實戰群請加微信(註明:實戰群):gocnio
相關文章
- 寫給大家看的“不負責任” K8s 入門文件K8S
- 寫給大家看的PPT設計書
- 一次“不負責任”的 K8s 網路故障排查經驗分享K8S
- [譯] 寫給大家看的 Cache-Control 指令配置
- 《寫給大家看的設計書》讀後記錄
- 負責任AI發展的關鍵AI
- 寫給小白的pySpark入門Spark
- 對蘋果WWDC2018的一些不負責任的猜測蘋果
- 讀 《有人負責,才有質量,寫給集市中迷失的一代》
- 有人負責,才有質量:寫給在集市中迷失的一代
- 寫給新手的MySQL入門指南MySql
- “爆到天際線” - TiDB 2021 Hackathon 決賽不負責任點評TiDB
- [譯] 寫給前端工程師的 Docker 入門前端工程師Docker
- 谷歌拆分搜尋和AI部門:Jeff Dean任AI業務負責人谷歌AI
- 《有人負責,才有質量:寫給在集市中迷失的一代》簡短感言
- 入門指南 | 寫給打算進入IT行業的新人們!行業
- 寫給初入門/半路出家的前端er前端
- 寫給自己看的找素材
- 寫給自己看的Typescript起步TypeScript
- 寫給大家看的量子力學——量子通訊、量子隱形傳輸技術簡介
- 寫給自己看的 Git 命令指北Git
- 寫給自己看的 Flex 佈局Flex
- 給後端程式設計師看的 Vue 快速入門教程後端程式設計師Vue
- 寫給後端的Hadoop初級入門教程:概念篇後端Hadoop
- 不負青春不負你,華瑞用18年給你一個選擇的理由
- Google AI的焦慮:拆分搜尋和人工智慧部門,Jeff Dean任AI業務負責人GoAI人工智慧
- 寫給自己看的命名備忘錄
- 寫給自己看的面試題整理面試題
- gulp入門文件
- Jest入門文件
- 不負責預測:2021手機市場的“雄起”錯覺
- Sentinel併發限流不精確-之責任鏈
- 寫給後端的Nginx初級入門教程:Nginx原理初探後端Nginx
- 寫給後端的Nginx初級入門教程:基礎篇後端Nginx
- Docker 從入門到進階三:構建自己的映象並分享給大家用Docker
- 架構師負責訂規範,你負責執行!架構
- 最高法--建設工程中,質量違約責任與保修責任系兩種制度,不滿足保修責任要件也可能主張違約
- 寫給自己看的三欄佈局的演示