轉載請引用:容量預估/效能壓測思考
1 背景
隨著業務的快速成長,日訪問量越來越高,除了對功能要求很高以外,對效能要求也越來越高。 在實際工作中,我們往往會被一些問題所困擾。
1)線上服務容量是多少?效能痛點在哪裡? 可伸縮性(resilience)和可靠性(reliability)怎樣?預先知道了系統的容量,做到心中有數,才能為最終規劃整個執行環境的配置提供有利的依據。
2)新開發的功能是否滿足效能指標? 重新修改的程式碼會不會帶來效能問題? 對服務或工具的引數修改是否有效果(如jvm引數,mysql或solr配置等)? 如果在上線用前就能進行驗證,那麼不僅能極大降低部署時發生意外的概率,還能為效能優化提供指導。
2 現狀
為嘗試解決上述問題,我們在多個專案上進行過效能測試,使用過的方法主要分成三類。
| 方案 | 具體方式 | 優點 | 缺點 | |
| 人為模擬請求 | 自己寫程式碼或者使用簡單的工具如httpload等去模擬使用者請求進行測試 | 操作簡單,能快速的得到cpu、mem、 load、 qps等極限值。 | 缺少真實使用者互動行為,缺乏真實性 | |
| copy線上流量 | 使用tcpcopy工具實時copy線上流量到某臺機器 | 操作簡單,是真實線上請求,且對線上服務壓力無影響 | 需要準備一套跟線上機器配置、依賴一致的獨立環境,同時如果是服用線上的環境的話,一些寫操作的請求被copy會有問題 | |
| 線上流量切換 | 直接用線上的機器和環境,通過調整nginx配置引數,逐漸將要做壓測的機器的權重增加,然後觀察該機器各個指標效能 | 真實生產線流量,能把使用者行為導向壓測伺服器,是最為真實的使用者行為,能夠把一些需要登陸,有使用者互動行為的效能真實的反映出來 | 因為是用生產系統真實流量來模擬壓測,無法得出最大值,如果閥值設定有誤,也存在一定的風險。此外該效能測試也不能經常進行 |
3 存在的不足
儘管我們在效能測試上做過一些嘗試,但還遠遠不夠,存在以下不足。
3.1 效能測試指標和標準尚未完全確立
不同服務測試指標應該不同,相應的標準也不同,例如接入層服務和後端服務指標是不同的。如果我們能為各個服務制定類似如下的標準,以後再進行效能測試就有了參考依據。 隨著服務的發展,這些標準也會隨之相應改動,要求會越來越嚴格。
|
判斷指標 |
不通過的標準 |
|
超時概率 |
大於萬分之一 |
|
錯誤概率 |
大於萬分之一 |
|
平均響應時間 |
超過100ms |
|
0.99響應時間 |
超過200ms |
|
qpm(每分鐘處理的請求量) |
小於2w |
|
qpm波動範圍(標準差) |
正負3 |
|
cpu使用率 |
平均每核超過75% |
|
負載(load) |
平均每核超過1.5 |
|
jvm記憶體使用率 |
大於80% |
|
gc平均時間 |
超過1s |
|
fullgc頻率 |
頻率高於半小時一次 |
|
... |
...
|
3.2 效能測試不夠全面
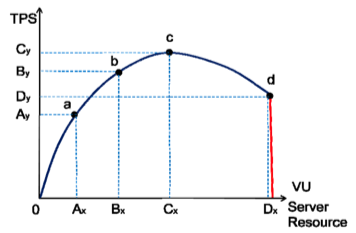
圖1 淘寶效能測試曲線(a點:效能期望值;b點:高於期望,系統資源處於臨界點;c點:高於期望,拐點;d點:超過負載,系統崩潰)
根據上述壓力變化模型,淘寶網將效能測試分成狹義的4種型別:
a)效能測試:a點到b點之間的系統效能
定義:狹義的效能測試,是指以效能預期目標為前提,對系統不斷施加壓力,驗證系統在資源可接受範圍內,是否能達到效能預期。
b)負載測試 :b點的系統效能
定義:狹義的負載測試,是指對系統不斷地增加壓力或增加一定壓力下的持續時間,直到系統的某項或多項效能指標達到極限,例如某種資源已經達到飽和狀態等。
c)壓力測試:b點到d點之間
定義:狹義的壓力測試,是指超過安全負載的情況下,對系統不斷施加壓力,是通過確定一個系統的瓶頸或不能接收使用者請求的效能點,來獲得系統能提供的最大服務級別的測試
d)穩定性測試:a點到b點之間
定義:狹義的穩定性測試,是指被測試系統在特定硬體、軟體、網路環境條件下,給系統載入一定業務壓力,使系統執行一段較長時間,以此檢測系統是否穩定,一般穩定性測試時間為n*12小時
我們現在的效能測試還沒有那麼全面,比如沒有進行長時間的穩定性測試,長時間的測試執行可導致程式發生由於記憶體洩露引起的失敗,揭示程式中的隱含的問題或衝突。
3.3 效能測試手段缺乏
線上流量切換方法不能經常執行,copy線上流量目前只能將所有(包括讀和寫)流量拷貝過來,而自己寫程式模擬使用者請求又缺乏真實性。一種思路是自己實現測試程式將前一天的請求重新跑一遍,其核心在於控制請求頻率,使其與之前請求頻率曲線一致,從而達到近似模擬的目的。
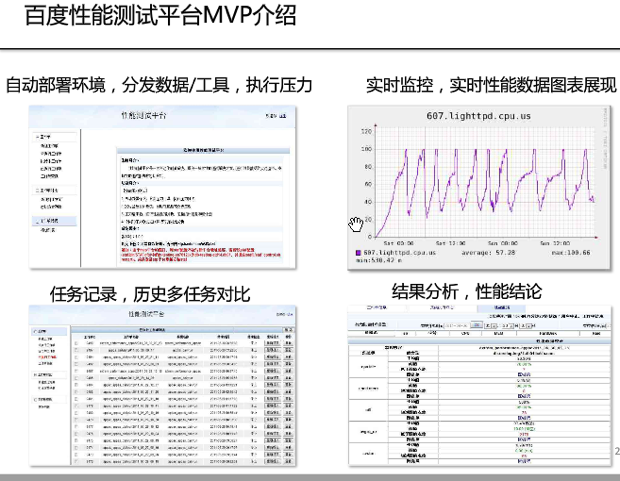
3.4. 缺少效能測試自動化工具或平臺
例如百度有個效能測試平臺,有此平臺後,可以方便地進行效能測試。其可以用於指導程式開發,使得在開發過程不僅關注功能,也關注效能,此外,效能測試納入持續整合,每天出報表,每天都能知道自己服務的處理能力。