sift
sift特徵簡介
SIFT(Scale-Invariant Feature Transform)特徵,即尺度不變特徵變換,是一種計算機視覺的特徵提取演算法,用來偵測與描述影象中的區域性性特徵。
實質上,它是在不同的尺度空間上查詢關鍵點(特徵點),並計算出關鍵點的方向。SIFT所查詢到的關鍵點是一些十分突出、不會因光照、仿射變換和噪音等因素而變化的點,如角點、邊緣點、暗區的亮點及亮區的暗點等。
sift特徵提取步驟
1. 尺度空間的極值檢測: 尺度空間指一個變化尺度(σ)的二維高斯函式G(x,y,σ)與原影象I(x,y)卷積(即高斯模糊)後形成的空間,尺度不變特徵應該既是空間域上又是尺度域上的區域性極值。極值檢測的大致原理是根據不同尺度下的高斯模糊化影象差異(Difference of Gaussians,DoG)尋找區域性極值,這些找到的極值所對應的點被稱為關鍵點或特徵點。
2. 關鍵點定位: 在不同尺寸空間下可能找出過多的關鍵點,有些關鍵點可能相對不易辨識或易受噪聲干擾。該步藉由關鍵點附近畫素的資訊、關鍵點的尺寸、關鍵點的主曲率來定位各個關鍵點,藉此消除位於邊上或是易受噪聲干擾的關鍵點。
3. 方向定位: 為了使描述符具有旋轉不變性,需要利用影象的區域性特徵為給每一個關鍵點分配一個基準方向。通過計算關鍵點區域性鄰域的方向直方圖,尋找直方圖中最大值的方向作為關鍵點的主方向。
4. 關鍵點描述子: 找到關鍵點的位置、尺寸並賦予關鍵點方向後,將可確保其移動、縮放、旋轉的不變性。此外還需要為關鍵點建立一個描述子向量,使其在不同光線與視角下皆能保持其不變性。SIFT描述子是關鍵點鄰域高斯影象梯度統計結果的一種表示,見下圖。通過對關鍵點周圍影象區域分塊,計算塊內梯度直方圖,生成具有獨特性的向量,這個向量是該區域影象資訊的一種抽象,具有唯一性。Lowe在原論文中建議描述子使用在關鍵點尺度空間內44的視窗中計算的8個方向的梯度資訊,共44*8=128維向量表徵。(opencv中實現的也是128維)
具體可以參考這篇部落格:https://www.cnblogs.com/liuchaogege/p/5155739.html
surf
surf特徵簡介
SURF(Speeded Up Robust Features, 加速穩健特徵) 是一種穩健的影象識別和描述演算法。它是SIFT的高效變種,也是提取尺度不變特徵,演算法步驟與SIFT演算法大致相同,但採用的方法不一樣,要比SIFT演算法更高效(正如其名)。SURF使用海森(Hesseian)矩陣的行列式值作特徵點檢測並用積分圖加速運算;SURF 的描述子基於 2D 離散小波變換響應並且有效地利用了積分圖。
surf特徵提取步驟
1. 特徵點檢測: SURF使用Hessian矩陣來檢測特徵點,該矩陣是x,y方向的二階導數矩陣,可測量一個函式的區域性曲率,其行列式值代表畫素點周圍的變化量,特徵點需取行列式值的極值點。用方型濾波器取代SIFT中的高斯濾波器,利用積分圖(計算位於濾波器方型的四個角落值)大幅提高運算速度。
2.特徵點定位: 與SIFT類似,通過特徵點鄰近資訊插補來定位特徵點。
3. 方向定位: 通過計算特徵點周圍畫素點x,y方向的哈爾小波變換,並將x,y方向的變換值在xy平面某一角度區間內相加組成一個向量,在所有的向量當中最長的(即x、y分量最大的)即為此特徵點的方向。
4. 特徵描述子: 選定了特徵點的方向後,其周圍相素點需要以此方向為基準來建立描述子。此時以55個畫素點為一個子區域,取特徵點周圍2020個畫素點的範圍共16個子區域,計運算元區域內的x、y方向(此時以平行特徵點方向為x、垂直特徵點方向為y)的哈爾小波轉換總和Σdx、ΣdyΣdx、Σdy與其向量長度總和Σ|dx|、Σ|dy|Σ|dx|、Σ|dy|共四個量值,共可產生一個64維的描述子。
具體可以參考這篇部落格:
https://www.cnblogs.com/zyly/p/9531907.html
orb
orb特徵簡介
ORB(Oriented FAST and Rotated BRIEF)該特徵檢測演算法是在著名的FAST特徵檢測和BRIEF特徵描述子的基礎上提出來的,其執行時間遠遠優於SIFT和SURF,可應用於實時性特徵檢測。ORB特徵檢測具有尺度和旋轉不變性,對於噪聲及其透視變換也具有不變性,良好的效能是的利用ORB在進行特徵描述時的應用場景十分廣泛。ORB特徵檢測主要分為以下兩個步驟:(1)方向FAST特徵點檢測(2)BRIEF特徵描述。
orb特徵提取演算法
- FAST特徵點檢測:https://www.cnblogs.com/ronny/p/4078710.html
- BRIEF特徵描述子:https://www.cnblogs.com/ronny/p/4081362.html
程式碼實現
接下來的程式碼採用的庫如下圖所示

紅色框的那兩個庫非常重要!版本請使用3.4.2.16的,而不是最新的,否則在特徵提取的時候會報錯。
錯誤提示:sift = cv2.xfeatures2d.SIFT_create()
cv2.error: OpenCV(3.4.3) C:\projects\opencv-python\opencv_contrib\modules\xfeatures2d\src\sift.cpp:1207: error: (-213:The function/feature is not implemented) This algorithm is patented and is excluded in this configuration; Set OPENCV_ENABLE_NONFREE CMake option and rebuild the library in function ‘cv::xfeatures2d::SIFT::create’如果你在使用cv2.xfeatures2d.SIFT_create()這個函式的時候出現了上面的錯誤,就是因為你的庫版本太新。把版本退回去就可以了。
特徵提取
def sift(filename):
img = cv2.imread(filename) # 讀取檔案
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 轉化為灰度圖
sift = cv2.xfeatures2d_SIFT.create()
keyPoint, descriptor = sift.detectAndCompute(img, None) # 特徵提取得到關鍵點以及對應的描述符(特徵向量)
return img,keyPoint, descriptordef surf(filename):
img = cv2.imread(filename) # 讀取檔案
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 轉化為灰度圖
sift = cv2.xfeatures2d_SURF.create()
keyPoint, descriptor = sift.detectAndCompute(img, None) # 特徵提取得到關鍵點以及對應的描述符(特徵向量)
return img, keyPoint, descriptordef orb(filename):
img = cv2.imread(filename) # 讀取檔案
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 轉化為灰度圖
sift = cv2.ORB_create()
keyPoint, descriptor = sift.detectAndCompute(img, None) # 特徵提取得到關鍵點以及對應的描述符(特徵向量)
return img, keyPoint, descriptor這裡解釋一下為什麼要進行轉化為灰度圖?
- 識別物體,最關鍵的因素是梯度(SIFT/HOG),梯度意味著邊緣,這是最本質的部分,而計算梯度,自然就用到灰度影象了,可以把灰度理解為影象的強度。
- 顏色,易受光照影響,難以提供關鍵資訊,故將影象進行灰度化,同時也可以加快特徵提取的速度。
比較一下提取的結果看看
def compare(filename):
imgs = []
keyPoint = []
descriptor = []
img, keyPoint_temp, descriptor_temp = sift(filename)
keyPoint.append(keyPoint_temp)
descriptor.append(descriptor_temp)
imgs.append(img)
img, keyPoint_temp, descriptor_temp = surf(filename)
keyPoint.append(keyPoint_temp)
descriptor.append(descriptor_temp)
imgs.append(img)
img, keyPoint_temp, descriptor_temp = orb(filename)
keyPoint.append(keyPoint_temp)
descriptor.append(descriptor_temp)
imgs.append(img)
return imgs, keyPoint, descriptor
def main():
method = ['sift','surf','orb']
imgs, kp, des = compare('./pic/doraemon1.jpg')
for i in range(3):
img = cv2.drawKeypoints(imgs[i], kp[i], None)
cv2.imshow(method[i], img)
cv2.waitKey()
cv2.destroyAllWindows()
print("sift len of des: %d, size of des: %d" % (len(des[0]), len(des[0][0])))
print("surf len of des: %d, size of des: %d" % (len(des[1]), len(des[1][0])))
print("orb len of des: %d, size of des: %d" % (len(des[2]), len(des[2][0])))下圖是提取的結果,從左到右分別是原圖、sift、surf、orb

sift len of des: 458, size of des: 128
surf len of des: 1785, size of des: 64
orb len of des: 500, size of des: 32可以看出:
- sift雖然提取的特徵點最少,但是效果最好。
- sift提取的特徵點維度是128維,surf是64維,orb是32維。
特徵匹配
BruteForce匹配和FLANN匹配是opencv二維特徵點匹配常見的兩種辦法,分別對應BFMatcher(BruteForceMatcher)和FlannBasedMatcher。
二者的區別在於BFMatcher總是嘗試所有可能的匹配,從而使得它總能夠找到最佳匹配,這也是Brute Force(暴力法)的原始含義。而FlannBasedMatcher中FLANN的含義是Fast Library forApproximate Nearest Neighbors,從字面意思可知它是一種近似法,演算法更快但是找到的是最近鄰近似匹配,所以當我們需要找到一個相對好的匹配但是不需要最佳匹配的時候往往使用FlannBasedMatcher。當然也可以通過調整FlannBasedMatcher的引數來提高匹配的精度或者提高演算法速度,但是相應地演算法速度或者演算法精度會受到影響。
本文是進行最優特徵點匹配,因此選用BruteForce Matcher。
def match(filename1, filename2, method):
if(method == 'sift'):
img1, kp1, des1 = sift(filename1)
img2, kp2, des2 = sift(filename2)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True) # sift的normType應該使用NORM_L2或者NORM_L1
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
knnMatches = bf.knnMatch(des1, des2, k=1) # drawMatchesKnn
if (method == 'surf'):
img1, kp1, des1 = surf(filename1)
img2, kp2, des2 = surf(filename2)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True) # surf的normType應該使用NORM_L2或者NORM_L1
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
knnMatches = bf.knnMatch(des1, des2, k=1) # drawMatchesKnn
if(method == 'orb'):
img1, kp1, des1 = orb(filename1)
img2, kp2, des2 = orb(filename2)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck = True) # orb的normType應該使用NORM_HAMMING
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
knnMatches = bf.knnMatch(des1, des2, k = 1) # drawMatchesKnn
# 過濾
for m in matches:
for n in matches:
if(m != n and m.distance >= n.distance*0.75):
matches.remove(m)
break
img = cv2.drawMatches(img1, kp1, img2, kp2, matches[:50], img2, flags=2)
cv2.imshow("matches", img)
cv2.waitKey()
cv2.destroyAllWindows()
def main():
method = ['sift','surf','orb']
for i in range(3):
match('./pic/wechat1.jpg', './pic/wechat2.png', method[i])
if __name__ == '__main__':
main()介紹一下幾個關鍵函式。
首先是cv2.BFMatcher(normType, corssCheck)函式。它有兩個引數。
- 第一個引數是用來指定要使用的距離測試型別。預設值為 cv2.Norm_L2。這很適合 SIFT 和 SURF 等(cv2.NORM_L1 也可以)。對於使用二進位制描述符的 ORB,BRIEF,BRISK演算法等,要使用cv2.NORM_HAMMING,這樣就會返回兩個測試物件之間的漢明距離。
- 第二個引數是布林變數 crossCheck,預設值為 False。如果設定為True,匹配條件就會更加嚴格,只有到 A 中的第 i 個特徵點與 B 中的第 j 個特徵點距離最近,並且 B 中的第 j 個特徵點到 A 中的第 i 個特徵點也是最近(A 中沒有其他點到 j 的距離更近)時才會返回最佳匹配(i,j)。也就是這兩個特徵點要互相匹配才行。
然後是bf.match()。它也有兩個引數。前面一個是查詢用的向量,後面一個是匹配用的向量。
sorted()函式是用來對匹配得到的結果進行排序,按照距離排序。
knnMatch() 是BFMatcher 物件的另一個方法, BFMatcher.match()方法會返回最佳匹配。而該方法為每個關鍵點返回 k 個最佳匹配(降序排列之後取前 k 個),其中 k 是由使用者設定的。
(注意:knnMatch()和match()得到的返回並不是一樣的結果)
這裡還對匹配得到的結果做了過濾,排除一些不好的匹配結果。
- img1 – 源影象1
- keypoints1 –源影象1的特徵點.
- img2 – 源影象2.
- keypoints2 – 源影象2的特徵點
- matches1to2 – 源影象1的特徵點匹配源影象2的特徵點
- outImg – 輸出影象具體由flags決定.
- matchColor – 匹配的顏色(特徵點和連線),若matchColor==Scalar::all(-1),顏色隨機.
- singlePointColor – 單個點的顏色,即未配對的特徵點,若matchColor==Scalar::all(-1),顏色隨機.
- matchesMask – Mask決定哪些點將被畫出,若為空,則畫出所有匹配點.
- flags – Fdefined by DrawMatchesFlags.
接下來看一下上面的程式碼執行的結果。從上到底依次是原圖、sift、surf、orb
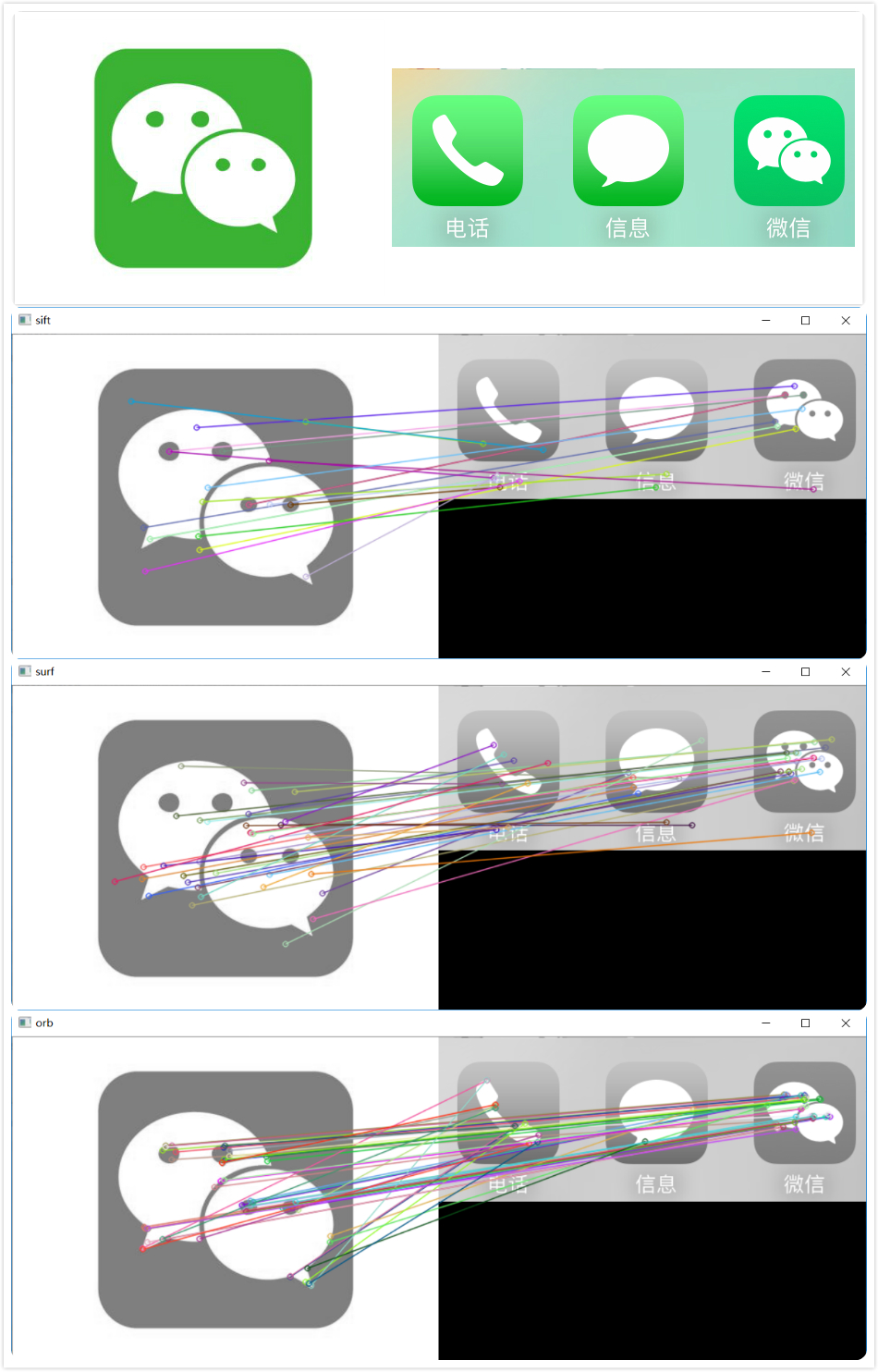
sift size of kp: 59, after filtering: 20
surf size of kp: 197, after filtering: 35
orb size of kp: 390, after filtering: 47
從輸出的結果來看,orb的效果最好。感興趣的話還可以用其他圖片看看效果,pic資料夾還提供其他兩組比較的圖片。
# 總結
基於特徵的匹配分為特徵點提取和匹配兩個步驟,本篇主要針對特徵點提取三種方法進行比較,分別是SIFT,SURF以及ORB三種方法,這三種方法在OpenCV裡面都已實現。SURF基本就是SIFT的全面升級版,有 SURF基本就不用考慮SIFT,而ORB的強點在於計算時間,以下具體比較:計算速度: ORB>>SURF>>SIFT(各差一個量級)
旋轉魯棒性:SURF>ORB~SIFT(表示差不多)
模糊魯棒性:SURF>ORB~SIFT
尺度變換魯棒性: SURF>SIFT>ORB(ORB並不具備尺度變換性)
```
所以結論就是,如果對計算實時性要求非常高,可選用ORB演算法,但基本要保證正對拍攝;如果對實行性要求稍高,可以選擇SURF;基本不用SIFT。
參考:https://blog.csdn.net/zilanpotou182/article/details/66478915
不過上面那篇部落格的評論提出了不同的看法,正確性有待驗證。
附錄
GitHub:https://github.com/Professorchen/Computer-Vision/tree/master/feature-extraction