目錄
- 1. 前言
- 2. 問題的提出
- 3. 模板引擎和 Virtual-DOM 結合 —— Virtual-Template
- 4. Virtual-Template 的實現
- 4.1 編譯原理相關
- 4.2 模版引擎的EBNF
- 4.3 詞法分析
- 4.4 語法分析與抽象語法樹
- 4.5 程式碼生成
- 5. 完整的 Virtual-Template
- 6. 結語
1. 前言
本文嘗試構建一個 Web 前端模板引擎,並且把這個引擎和 Virtual-DOM 進行結合。把傳統模板引擎編譯成 HTML 字串的方式改進為編譯成 Virtual-DOM 的 render 函式,可以有效地結合模板引擎的便利性和 Virtual-DOM 的效能。類似 ReactJS 中的 JSX。
閱讀本文需要一些關於 ReactJS 實現原理或者 Virtual-DOM 的相關知識,可以先閱讀這篇部落格:深度剖析:如何實現一個 Virtual DOM 演算法 , 進行相關知識的瞭解。
同時還需要對編譯原理相關知識有基本的瞭解,包括 EBNF,LL(1),遞迴下降的方法等。
2. 問題的提出
本人在就職的公司維護一個比較樸素的系統,前端渲染有兩種方式:
- 後臺直接根據模板和資料直接把頁面吐到前端。
- 後臺只吐資料,前端用前端模板引擎渲染資料,動態塞到頁面。
當資料狀態變更的時候,前端用 jQuery 修改頁面元素狀態,或者把區域性介面用模板引擎重新渲染一遍。當頁面狀態很多的時候,用 jQuery 程式碼中會就混雜著很多的 DOM 操作,編碼複雜且不便於維護;而重新渲染雖然省事,但是會導致一些效能、焦點消失的問題(具體可以看這篇部落格介紹)。
因為習慣了 MVVM 資料繫結的編碼方式,對於用 jQuery 選擇器修改 wordings 等細枝末節的勞力操作個人感覺不甚習慣。於是就構思能否在這種樸素的編碼方式上做一些改進,解放雙手,提升開發效率。其實只要加入資料狀態 -> 檢視的 one-way data-binding 開發效率就會有較大的提升。
而這種已經在運作多年的多人維護系統,引入新的 MVVM 框架並不是一個非常好的選擇,在相容性和風險規避上大家都有諸多的考慮。於是就構思了一個方案,在前端模板引擎上做手腳。可以在幾乎零學習成本的情況下,做到 one-way data-binding,大量減少 jQuery DOM 操作,提升開發效率。
3. 模板引擎和 Virtual-DOM 結合 —— Virtual-Template
考慮以下模板語法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<div> <h1>{title}</h1> <ul> {each users as user i} <li class="user-item"> <img src="/avatars/{user.id}" /> <span>NO.{i + 1} - {user.name}</span> {if user.isAdmin} I am admin {elseif user.isAuthor} I am author {else} I am nobody {/if} </li> {/each} </ul> </div> |
這隻一個普通的模板引擎語法(類似 artTemplate),支援迴圈語句(each)、條件語句(if elseif else ..)、和文字填充({…}), 應該比較容易看懂,這裡就不解釋。當用下面資料渲染該模板的時候:
|
1 2 3 4 5 6 7 8 |
var data = { title: 'Users List', users: [ {id: 'user0', name: 'Jerry', isAdmin: true}, {id: 'user1', name: 'Lucy', isAuthor: true}, {id: 'user2', name: 'Tomy'} ] } |
會得到下面的 HTML 字串:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<div> <h1>Users List</h1> <ul> <li class="user-item"> <img src="/avatars/user0" /> <span>NO.1 - Jerry</span> I am admin </li> <li class="user-item"> <img src="/avatars/user1" /> <span>NO.2 - Lucy</span> I am author </li> <li class="user-item"> <img src="/avatars/user2" /> <span>NO.3 - Tomy</span> I am nobody </li> </ul> </div> |
把這個字串塞入文件當中就可以生成 DOM 。但是問題是如果資料變更了,例如data.title由Users List修改成Users,你只能用 jQuery 修改 DOM 或者直接重新渲染一個新的字串塞入文件當中。
然而我們可以參考 ReactJS 的 JSX 的做法,不把模板編譯成 HTML, 而是把模板編譯成一個返回 Virtual-DOM 的 render 函式。render 函式會根據傳入的 state 不同返回不一樣的 Virtual-DOM ,然後就可以根據 Virtual-DOM 演算法進行 diff 和 patch:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
// setup codes // ... var render = template(tplString) // template 把模板編譯成 render 函式而不是 HTML 字串 var root1 = render(state1) // 根據初始狀態返回的 virtual-dom var dom = root.render() // 根據 virtual-dom 構建一個真正的 dom 元素 document.body.appendChild(dom) var root2 = render(state2) // 狀態變更,重新渲染另外一個 virtual-dom var patches = diff(root1, root2) // virtual-dom 的 diff 演算法 patch(dom, patches) // 更新真正的 dom 元素 |
這樣做好處就是:既保留了原來模板引擎的語法,又結合了 Virtual-DOM 特性:當狀態改變的時候不再需要 jQuery 了,而是跑一遍 Virtual-DOM 演算法把真正的 DOM 給patch了,達到了 one-way data-binding 的效果,總結流程就是:
- 先把模板編譯成一個 render 函式,這個函式會根據資料狀態返回 Virtual-DOM
- 用 render 函式構建 Virtual-DOM;並根據這個 Virtual-DOM 構建真正的 DOM 元素,塞入文件當中
- 當資料變更的時候,再用 render 函式渲染一個新的 Virtual-DOM
- 新舊的 Virtual-DOM 進行 diff,然後 patch 已經在文件中的 DOM 元素
(恩,其實就是一個類似於 JSX 的東西)
這裡重點就是,如何能把模板語法編譯成一個能夠返回 Virtual-DOM 的 render 函式?例如上面的模板引擎,不再返回 HTML 字串了,而是返回一個像下面那樣的 render 函式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function render (state) { return el('div', {}, [ el('h1', {}, [state.title]), el('ul', {}, state.users.map(function (user, i) { return el('li', {"class": "user-item"}, [ el('img', {"src": "/avatars/" + user.id}, []), el('span', {}, ['No.' + (i + 1) + ' - ' + user.name], (user.isAdmin ? 'I am admin' : uesr.isAuthor ? 'I am author' : '') ]) })) ]) } |
前面的模板和這個 render 函式在語義上是一樣的,只要能夠實現“模板 -> render 函式”這個轉換,就可以跑上面所說的 Virtual-DOM 的演算法流程,這樣就把模板引擎和 Virtual-DOM結合起來。為了方便起見,這裡把這個結合體稱為 Virtual-Template 。
4. Virtual-Template 的實現
網上關於模板引擎的實現原理介紹非常多。如果語法不是太複雜的話,可以直接通過對語法標籤和程式碼片段進行分割,識別語法標籤內的內容(迴圈、條件語句)然後拼裝程式碼,具體可以參考這篇部落格。其實就是正規表示式使用和字串的操作,不需要對語法標籤以外的內容做識別。
但是對於和 HTML 語法已經差別較大的模板語法(例如 Jade ),單純的正則和字串操作已經不夠用了,因為其語法標籤以外的程式碼片段根本不是合法的 HTML 。這種情況下一般需要編譯器相關知識發揮用途:模板引擎本質上就是把一種語言編譯成另外一種語言。
而對於 Virtual-Template 的情況,雖然其除了語法標籤以外的程式碼都是合法的 HTML 字串,但是我們的目的是把它編譯成返回 Virtual-DOM 的 render 函式,在構建 Virtual-DOM 的時候,你需要知道元素的 tagName、屬性等資訊,所以就需要對 HTML 元素本身做識別。
因此 Virtual-Template 也需要藉助編譯原理(編譯器前端)相關的知識,把一種語言(模板語法)編譯成另外一種語言(一個叫 render 的 JavaScript 函式)。
4.1 編譯原理相關
CS 本科都教過編譯原理,本文會用到編譯器前端的一些概念。在實現模板到 render 函式的過程中,要經過幾個步驟:
- 詞法分析:把輸入的模板分割成詞法單元(tokens stream)
- 語法分析:讀入 tokens stream ,根據文法規則轉化成抽象語法樹(Abstract Syntax Tree)
- 程式碼生成:遍歷 AST,生成 render 函式體程式碼
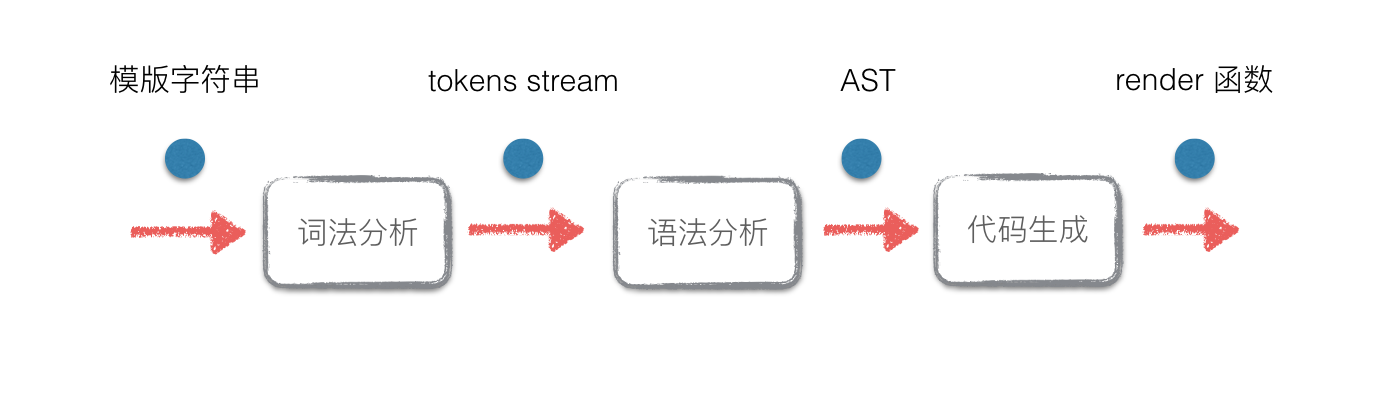
所以這個過程可以分成幾個主要模組:tokenizer(詞法分析器),parser(語法分析器),codegen(程式碼生成)。在此之前,還需要對模板的語法做文法定義,這是構建詞法分析和語法分析的基礎。
4.2 模板引擎的 EBNF
在計算機領域,對某種語言進行語法定義的時候,幾乎都會用到 EBNF(擴充套件的巴科斯正規化)。在定義模板引擎的語法的時候,也可以用到 EBNF。Virtual-Template 擁有非常簡單的語法規則,支援上面所提到的 each、if 等語法:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{each users as user i } <div> {user.name} </div> ... {/each} {if user.isAdmin} ... {elseif user.isAuthor} ... {elseif user.isXXX} ... {/if} |
對於 {user.name} 這樣的表示式插入,可以簡單地看成是字串,在程式碼生成的時候再做處理。這樣我們的詞法和語法分析就會簡化很多,基本只需要對 each、if、HTML 元素進行處理。
Virtual-Template 的 EBNF:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Stat -> Frag Stat | ε Frag -> IfStat | EachStat | Node | text IfStat -> '{if ...}' Stat {ElseIf} [Else] '{/if}' ElseIf -> '{elseif ...}' Stat Else -> '{else}' Stat|e EachStat -> '{each ...}' Stat '{/each}' Node -> OpenTag NodeTail OpenTag -> '/[\w\-\d]+/' {Attr} NodeTail -> '>' Stat '/\<[\w\d]+\>/' | '/>' Attr -> '/[\w\-\d]/+' Value Value -> '=' '/"[\s\S]+"/' | ε |
可以把該文法轉換成 LL(1) 文法,方便我們寫遞迴下降的 parser。這個語法還是比較簡單的,沒有出現複雜的左遞迴情況。簡單進行展開和提取左公因子消除衝突獲得下面的 LL(1) 文法。
LL(1) 文法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Stat -> Frag Stat | ε Frag -> IfStat | EachStat | Node | text IfStat -> '{if ...}' Stat ElseIfs Else '{/if}' ElseIfs -> ElseIf ElseIfs | ε ElseIf -> '{elseif ...}' Stat Else -> '{else}' Stat | ε EachStat -> '{each ...}' Stat '{/each}' Node -> OpenTag NodeTail OpenTag -> '/[\w\-\d]+/' Attrs NodeTail -> '>' Stat '/\<[\w\d]+\>/' | '/>' Attrs -> Attr Attrs | ε Attr -> '/[\w\-\d]/+' Value Value -> '=' '/"[\s\S]+"/' | ε |
4.3 詞法分析
根據上面獲得的 EBNF ,單引號包含的都是非終結符,可以知道有以下幾種詞法單元:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
module.exports = { TK_TEXT: 1, // 文字節點 TK_IF: 2, // {if ...} TK_END_IF: 3, // {/if} TK_ELSE_IF: 4, // {elseif ...} TK_ELSE: 5, // {else} TK_EACH: 6, // {each ...} TK_END_EACH: 7, // {/each} TK_GT: 8, // > TK_SLASH_GT: 9, // /> TK_TAG_NAME: 10, // <div|<span|<img|... TK_ATTR_NAME: 11, // 屬性名 TK_ATTR_EQUAL: 12, // = TK_ATTR_STRING: 13, // "string" TK_CLOSE_TAG: 13, // </div>|</span>|</a>|... TK_EOF: 100 // end of file } |
使用 JavaScript 自帶的正規表示式引擎編寫 tokenizer 很方便,把輸入的模板字串從左到右進行掃描,按照上面的 token 的型別進行分割:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
function Tokenizer (input) { this.input = input this.index = 0 this.eof = false } var pp = Tokenizer.prototype pp.nextToken = function () { this.eatSpaces() return ( this.readCloseTag() || this.readTagName() || this.readAttrName() || this.readAttrEqual() || this.readAttrString() || this.readGT() || this.readSlashGT() || this.readIF() || this.readElseIf() || this.readElse() || this.readEndIf() || this.readEach() || this.readEndEach() || this.readText() || this.readEOF() || this.error() ) } // read token methods // ... |
Tokenizer 會儲存一個 index,標記當前識別到哪個字元位置。每次呼叫 nextToken 會先跳過所有的空白字元,然後嘗試某一種型別的 token ,識別失敗就會嘗試下一種,如果成功就直接返回,並且把 index 往前移;所有型別都試過都無法識別那麼就是語法錯誤,直接丟擲異常。
具體每個識別的函式其實就是正規表示式的使用,這裡就不詳細展開,有興趣可以閱讀原始碼 tokenizer.js
最後會把這樣的文章開頭的模板例子轉換成下面的 tokens stream:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
{ type: 10, label: 'div' } { type: 8, label: '>' } { type: 10, label: 'h1' } { type: 8, label: '>' } { type: 1, label: '{title}' } { type: 13, label: '</h1>' } { type: 10, label: 'ul' } { type: 8, label: '>' } { type: 6, label: '{each users as user i}' } { type: 10, label: 'li' } { type: 11, label: 'class' } { type: 12, label: '=' } { type: 13, label: 'user-item' } { type: 8, label: '>' } { type: 10, label: 'img' } { type: 11, label: 'src' } { type: 12, label: '=' } { type: 13, label: '/avatars/{user.id}' } { type: 9, label: '/>' } { type: 10, label: 'span' } { type: 8, label: '>' } { type: 1, label: 'NO.' } { type: 1, label: '{i + 1} - ' } { type: 1, label: '{user.name}' } { type: 13, label: '</span>' } { type: 2, label: '{if user.isAdmin}' } { type: 1, label: 'I am admin\r\n ' } { type: 4, label: '{elseif user.isAuthor}' } { type: 1, label: 'I am author\r\n ' } { type: 5, label: '{else}' } { type: 1, label: 'I am nobody\r\n ' } { type: 3, label: '{/if}' } { type: 13, label: '</li>' } { type: 7, label: '{/each}' } { type: 13, label: '</ul>' } { type: 13, label: '</div>' } { type: 100, label: '$' } |
4.4 語法分析與抽象語法樹
拿到 tokens 以後就可以就可以按順序讀取 token,根據模板的 LL(1) 文法進行語法分析。語法分析器,也就是 parser,一般可以採取遞迴下降的方式來進行編寫。LL(1) 不允許語法中有衝突( conflicts ),需要對文法中的產生式求解 FIRST 和 FOLLOW 集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
FIRST(Stat) = {TK_IF, TK_EACH, TK_TAG_NAME, TK_TEXT} FOLLOW(Stat) = {TK_ELSE_IF, TK_END_IF, TK_ELSE, TK_END_EACH, TK_CLOSE_TAG, TK_EOF} FIRST(Frag) = {TK_IF, TK_EACH, TK_TAG_NAME, TK_TEXT} FIRST(IfStat) = {TK_IF} FIRST(ElseIfs) = {TK_ELSE_IF} FOLLOW(ElseIfs) = {TK_ELSE, TK_ELSE} FIRST(ElseIf) = {TK_ELSE_IF} FIRST(Else) = {TK_ELSE} FOLLOW(Else) = {TK_END_IF} FIRST(EachStat) = {TK_EACH} FIRST(OpenTag) = {TK_TAG_NAME} FIRST(NodeTail) = {TK_GT, TK_SLASH_GT} FIRST(Attrs) = {TK_ATTR_NAME} FOLLOW(Attrs) = {TK_GT, TK_SLASH_GT} FIRST(Value) = {TK_ATTR_EQUAL} FOLLOW(Value) = {TK_ATTR_NAME, TK_GT, TK_SLASH_GT} |
上面只求出了一些必要的 FIRST 和 FOLLOW 集,對於一些不需要預測的產生式就省略求解了。有了 FIRST 和 FOLLOW 集,剩下的編寫遞迴下降的 parser 只是填空式的體力活。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
var Tokenizer = require('./tokenizer') var types = require('./tokentypes') function Parser (input) { this.tokens = new Tokenizer(input) this.parse() } var pp = Parser.prototype pp.is = function (type) { return (this.tokens.peekToken().type === type) } pp.parse = function () { this.tokens.index = 0 this.parseStat() this.eat(types.TK_EOF) } pp.parseStat = function () { if ( this.is(types.TK_IF) || this.is(types.TK_EACH) || this.is(types.TK_TAG_NAME) || this.is(types.TK_TEXT) ) { this.parseFrag() this.parseStat() } else { // end } } pp.parseFrag = function () { if (this.is(types.TK_IF)) return this.parseIfStat() else if (this.is(types.TK_EACH)) return this.parseEachStat() else if (this.is(types.TK_TAG_NAME)) return this.parseNode() else if (this.is(types.TK_TEXT)) { var token = this.eat(types.TK_TEXT) return token.label } else { this.parseError('parseFrag') } } // ... |
完整的 parser 可以檢視 parser.js。
抽象語法樹(Abstract Syntax Tree)
遞迴下降進行語法分析的時候,可以同時構建模版語法的樹狀表示結構——抽象語法樹,模板語法有以下的抽象語法樹的節點型別:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
Stat: { type: 'Stat' members: [IfStat | EachStat | Node | text, ...] } IfStat: { type: 'IfStat' label: <string>, body: Stat elifs: [ElseIf, ...] elsebody: Stat } ElseIf: { type: 'ElseIf' label: <string>, body: Stat } EachStat: { type: 'EachStat' label: <string>, body: Stat } Node: { type: 'Node' name: <string>, attributes: <object>, body: Stat } |
因為 JavaScript 語法的靈活性,可以用字面量的 JavaScript 物件和陣列直接表示語法樹的樹狀結構。語法樹構的建過程可以在語法分析階段同時進行。最後,可以獲取到如下圖的語法樹結構:
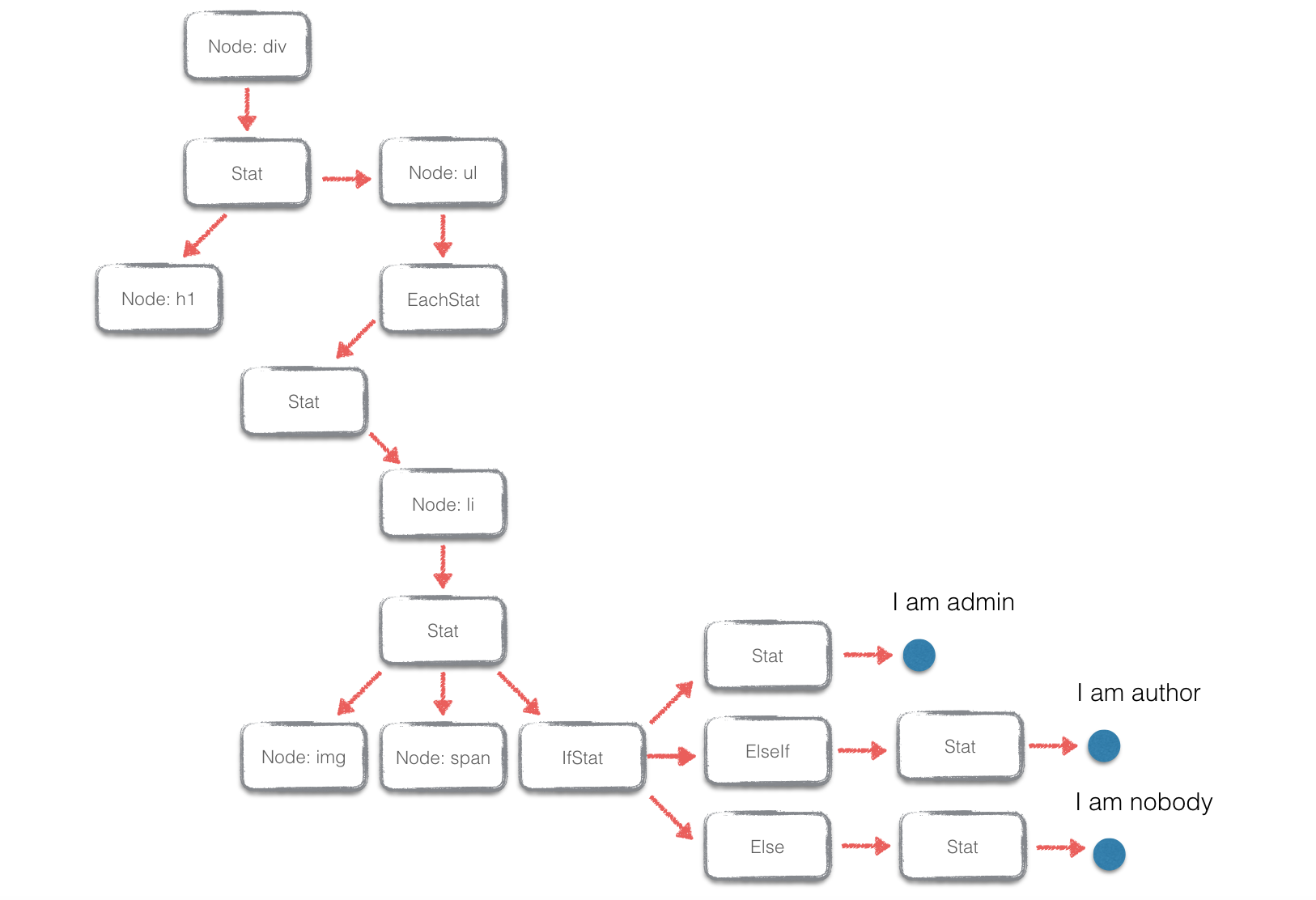
完整的語法樹構建過程,可以檢視 parser.js 。
從模版字串到 tokens stream 再到 AST ,這個過程只需要對文字進行一次掃描,整個演算法的時間複雜度為 O(n)。
至此,Virtual-Template 的編譯器前端已經完成了。
4.5 程式碼生成
JavaScript 從字串中構建一個新的函式可以直接用 new Function 即可。例如:
|
1 2 |
var newFunc = new Function('a', 'b', 'return a + b') newFunc(1, 2) // => 3 |
這裡需要通過語法樹來還原 render 函式的函式體的內容,也就是 new Function 的第三個引數。
拿到模版語法的抽象語法樹以後,生成相應的 JavaScript 函式程式碼就很好辦了。只需要地對生成的 AST 進行深度優先遍歷,遍歷的同時維護一個陣列,這個陣列儲存著 render 函式的每一行的程式碼:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
function CodeGen (ast) { this.lines = [] this.walk(ast) this.body = this.lines.join('n') } var pp = CodeGen.prototype pp.walk = function (node) { if (node.type === 'IfStat') { this.genIfStat(node) } else if (node.type === 'Stat') { this.genStat(node) } else if (node.type === 'EachStat') { ... } ... } pp.genIfStat = function (node) { var expr = node.label.replace(/(^{s*ifs*)|(s*}$)/g, '') this.lines.push('if (' + expr + ') {') if (node.body) { this.walk(node.body) } if (node.elseifs) { var self = this _.each(node.elseifs, function (elseif) { self.walk(elseif) }) } if (node.elsebody) { this.lines.push(indent + '} else {') this.walk(node.elsebody) } this.lines.push('}') } // ... |
CodeGen 類接受已經生成的 AST 的根節點,然後 this.walk(ast) 會對不同的節點型別進行解析。例如對於 IfStat 型別的節點:
|
1 2 3 4 5 6 7 |
{ type: 'IfStat', label: '{if user.isAdmin}' body: {...} elseifs: [{...}, {...}, {...}], elsebody: {...} } |
genIfStat 會把 '{if user.isAdmin}' 中的 user.isAdmin 抽離出來,然後拼接 JavaScript 的 if 語句,push 到 this.lines 中:
|
1 2 |
var expr = node.label.replace(/(^{s*ifs*)|(s*}$)/g, '') this.lines.push('if (' + expr + ') {') |
然後會遞迴的對 elseifs 和 elsebody 進行遍歷和解析,最後給 if 語句補上 }。所以如果 elseifs 和 elsebody 都不存在,this.lines 上就會有:
|
1 |
['if (user.isAdmin) {', body>, '}'] |
其它的結構和 IfStat 同理的解析和拼接方式,例如 EachStat:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
pp.genEachStat = function (node) { var expr = node.label.replace(/(^{s*eachs*)|(s*}$)/g, '') var tokens = expr.split(/s+/) var list = tokens[0] var item = tokens[2] var key = tokens[3] this.lines.push( 'for (var ' + key + ' = 0, len = ' + list + '.length; ' + key + ' ' + key + '++) {' ) this.lines.push('var ' + item + ' = ' + list + '[' + key + '];') if (node.body) { this.walk(node.body) } this.lines.push('}') } |
最後遞迴構造完成以後,this.lines.join('n') 就把整個函式的體構建起來:
|
1 2 3 4 5 6 7 |
if (user.isAdmin) { ... } for (var ...) { ... } |
這時候 render 函式的函式體就有了,直接通過 new Function 構建 render 函式:
|
1 2 |
var code = new CodeGen(ast) var render = new Function('el', 'data', code.body) |
el 是需要注入的構建 Virtual-DOM 的構建函式,data 需要渲染的資料狀態:
|
1 2 |
var svd = require('simple-virtual-dom') var root = render(svd.el, {users: [{isAdmin: true}]}) |
從模版 -> Virtual-DOM 的 render 函式 -> Virtual-DOM 的過程就完成了。完整的程式碼生成的過程可以參考:codegen.js
5. 完整的 Virtual-Template
其實拿到 render 函式以後,每次手動進行 diff 和 patch 都是重複操作。可以把 diff 和 patch 也封裝起來,只暴露一個 setData 的 API 。每次資料變更的時候,只需要 setData 就可以更新到 DOM 元素上(就像 ReactJS 的 setState):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
// vTemplate.compile 編譯模版字串,返回一個函式 var usersListTpl = vTemplate.compile(tplStr) // userListTpl 傳入初始資料狀態,返回一個例項 var usersList = usersListTpl({ title: 'Users List', users: [ {id: 'user0', name: 'Jerry', isAdmin: true}, {id: 'user1', name: 'Lucy', isAuthor: true}, {id: 'user2', name: 'Tomy'} ] }) // 返回的例項有 dom 元素和一個 setData 的 API document.appendChild(usersList.dom) // 需要變更資料的時候,setData 一下即可 usersList.setData({ title: 'Users', users: [ {id: 'user1', name: 'Lucy', isAuthor: true}, {id: 'user2', name: 'Tomy'} ] }) |
完整的 Virtual-Template 原始碼託管在 github 。
6. 結語
這個過程其實和 ReactJS 的 JSX 差不多。就拿 Babel 的 JSX 語法實現而言,它的 parser 叫 babylon。而 babylon 基於一個叫 acorn 的 JavaScript 編寫的 JavaScript 直譯器和它的 JSX 外掛 acorn-jsx。其實就是利用 acorn 把文字分割成 tokens,而 JSX 語法分析部分由 acorn-jsx 完成。
Virtual-Template 還不能應用於實際的生產環境,需要完善的東西還有很多。本文記錄基本的分析和實現的過程,也有助於更好地理解和學習 ReactJS 的實現。
(全文完)