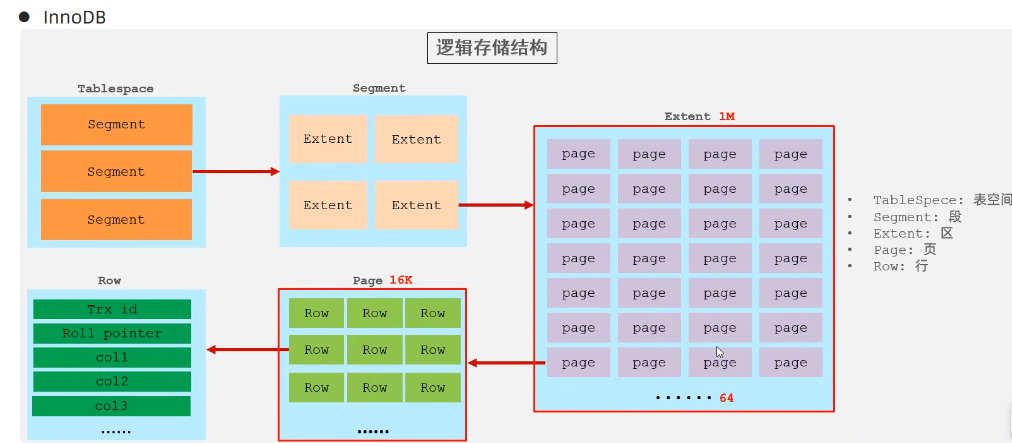
儲存引擎
體系結構
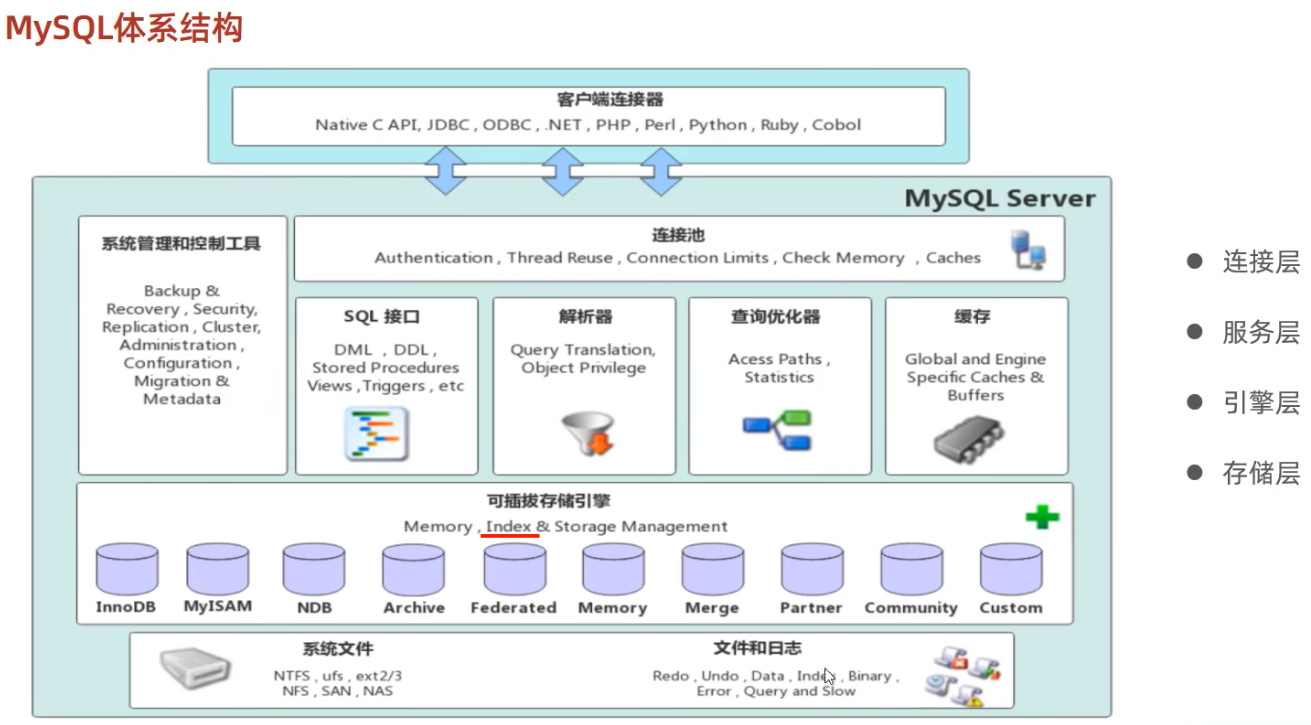
儲存引擎
- 增刪改查,索引的實現方式
- 基於表的,不是基於庫的
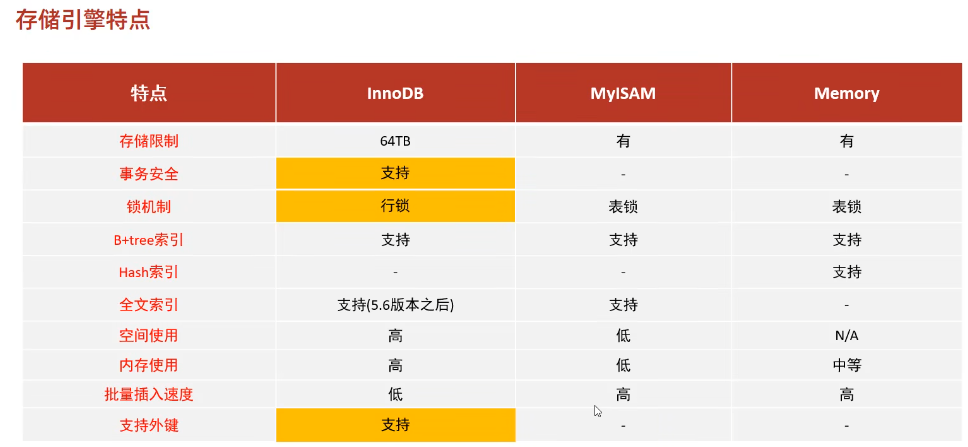
| 儲存引擎 | 檔案 |
|---|---|
| innodb | xxx.idb |
| myisam | xxx.sdi(表結構),xxx.MYD(資料),xxx.MYI(索引) |
| memory | xxx.sdi |
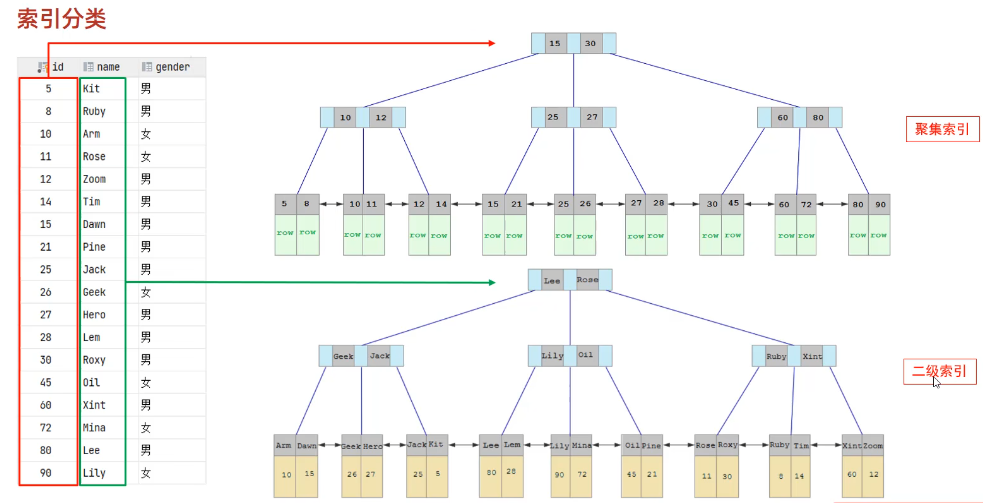
索引
分類
-
按欄位特性分

-
按物理儲存結構分

回表查詢
SQL效能分析
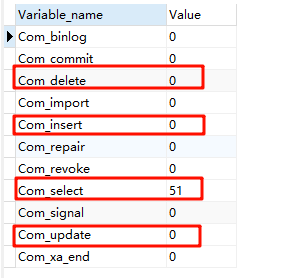
查詢操作頻次
SHOW GLOBAL STATUS LIKE "Com_______"; (7個下劃線)
慢查詢日誌
-- 檢視是否開啟
SHOW VARIABLES LIKE "slow_query_log";
-- 配置檔案中
slow_query_log = 1 --開啟慢查詢日誌
slow_query_log_file = /var/lib/mysql --慢查詢日誌的存放路徑
long_query_time = 2 --超過兩秒的雨具會被記錄
profile詳情
-- 是否支援
SELECT @@profiling
-- 是否開啟
SELECT @@have_profiling;
-- 開啟profile
SET profile = 1;
-- 檢視每一條SQL的耗時基本情況
SHOW profiles;
--檢視指定query_id的SQL語句各個階段的好是情況
SHOW profile for query query_id;
-- 檢視指定query_id的SQL語句CPU的使用情況
SHOW profile cpu for query query_id;
explain執行計劃

| 欄位名 | 含義 |
|---|---|
| id | id相同,執行順序從上到下;id不同,值越大,越先執行 |
| type | NULL、system、const、eq_ref、ref、range、index、all |
| key | 使用的索引 |
使用
- 最左字首法則:如果跳躍某一列,索引將部分失效(後面的欄位索引失效)。【聯合索引】
- 出現範圍查詢(>,<),範圍查詢右側的列索引失效。【聯合索引】
explain select * from tb_user where profession='軟體工程' and age >30 and status ='0';
explain select * from tb_user where profession='軟體工程'and age >=30 and status='O';
-
索引列上運算,索引失效
-
字串不加引號,索引失效
-
後模糊走索引,前模糊不走索引
-
or條件兩側都有索引才會走索引,否則索引失效
-
資料分佈影響,如果mysql評估走索引更慢,就不走索引
-
SQL提示
-- use index() 建議使用索引
explain select * from tb_user use index(idx_user_pro) where profession ='軟體工程';
-- ignore index() 忽略某個索引
explain select * from tb_user ignore index(idx_user_pro) where profession = '軟體工程';
-- force index() 強制使用索引
explain select * from tb_user force index(idx_user_pro) where profession = "軟體工程';
- 索引覆蓋,避免回表查詢 (select xxx)
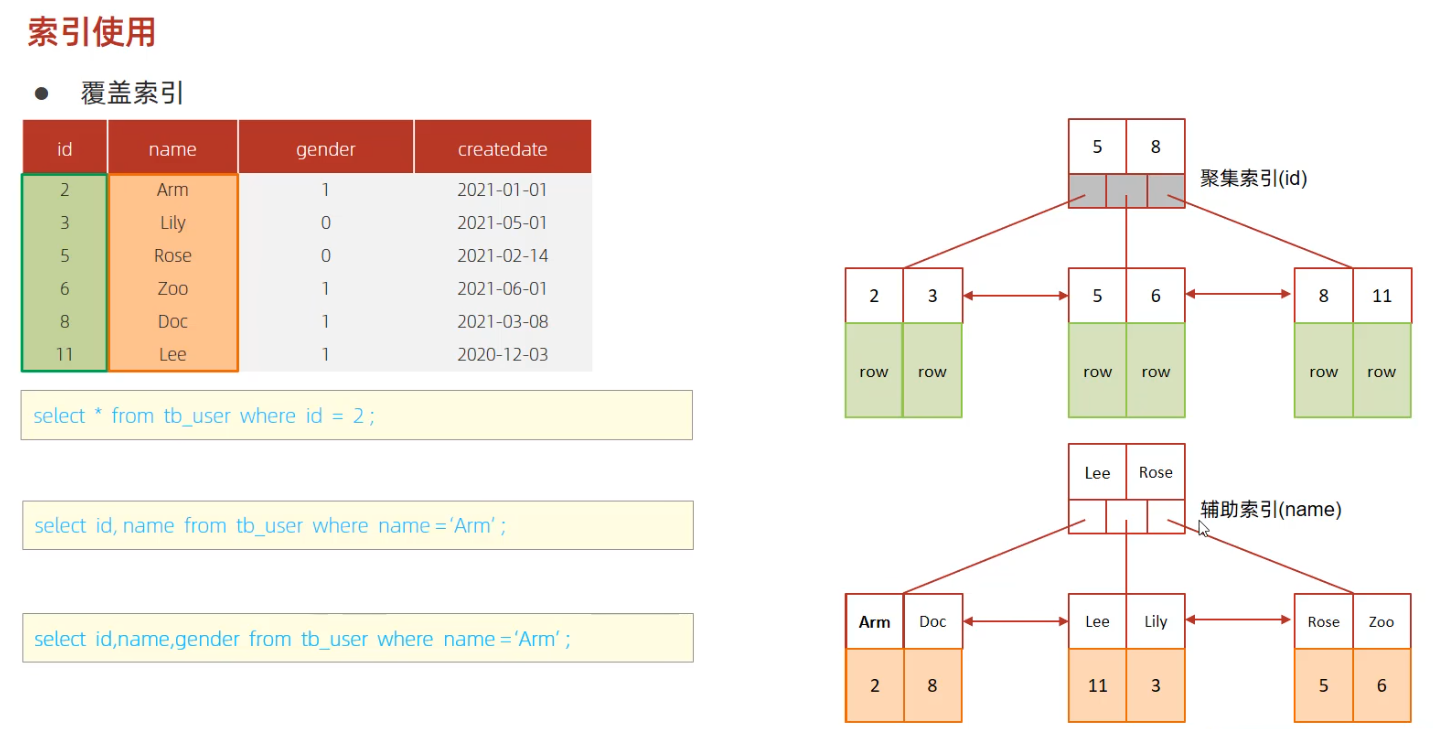
- 字首索引
-- 擷取多長合適:計算選擇性來權衡
select count(distinct substring(email,1,5) / count(*) from tb_user ;
- 儘量使用聯合索引(而非單列索引),進行索引覆蓋,減少回表查詢
索引設計原則
-
針對於資料量較大,且查詢比較頻繁的表建立索引。
-
針對於常作為查詢條件(where)、排序(orderby)、分組(groupby)操作的欄位建立索引。
-
儘量選擇區分度高的列作為索引,儘量建立唯一索引,區分度越高,使用索引的效率越高。
-
如果是字串型別的欄位,欄位的長度較長,可以針對於欄位的特點,建立字首索引。
-
儘量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省儲存空間,避免回表,提高查詢效率。
-
要控制索引的數量,索引並不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率。
-
如果索引列不能儲存NULL值,請在建立表時使用NOTNULL約束它。當最佳化器知道每列是否包含NULL值時,它可以更好地確定哪個索引最有效地用於查詢。
SQL最佳化【加索引】
插入資料
- 批次插入
- 手動提交事務
- 主鍵資料插入
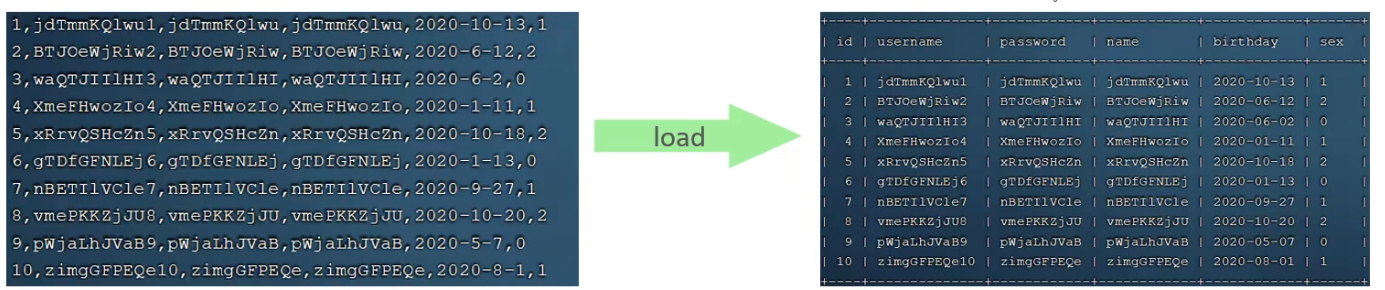
- 大批次查資料:load指令
-- 客戶端連線服務端時,加上引數 --Local-infile
-- 設定全域性引數localinfile為1,開啟從本地載入檔案匯入資料的開關
set global local_infile = 1;
-- 執行load指令將準備好的資料,載入到表結構中
load data local infile '/root/sqll.log' into table 'tb_user fields terminated by', lines terminated by "\n';
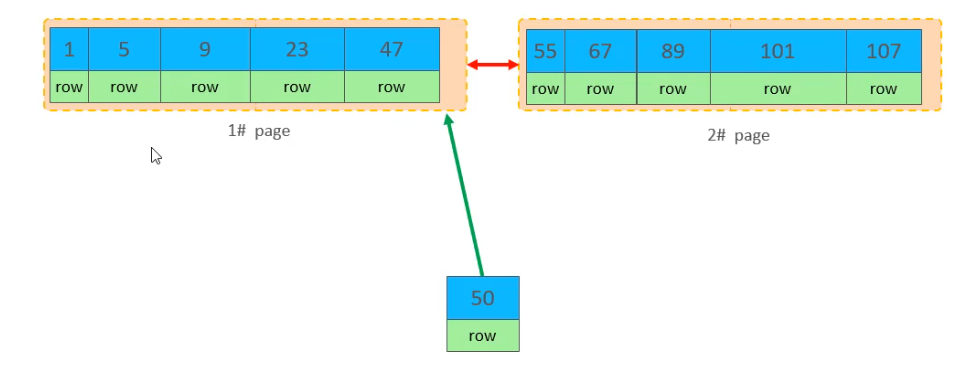
主鍵最佳化
- 滿足業務需求的情況下,儘量降低主鍵的長度。【減少佔用】
- 插入資料時,儘量選擇順序插入,選擇使用
AUTO_INCREMENT自增主鍵。【減少資料頁的分裂與合併】

order by最佳化
Using filesort:透過表的索引或全表掃描,讀取滿足條件的資料行,然後在排序緩衝區sortbuffer中完成排序操作,所有不是透過索引直接返回排序結果的排序都叫FileSort排序。Using index:透過有序索引l順序掃描直接返回有序資料【覆蓋索引】,這種情況即為using index,不需要額外排序,操作效率高。
group by最佳化
滿足最左字首法則即可
limit 最佳化
覆蓋索引+子查詢
-- 全表掃描
select * from tb_sku limit 5000000,10;
-- 子查詢走索引
select s.* from tb_sku s,(select id from tb sku order by id limit 9000000,10) a where s.id = a.id;
count最佳化

updata最佳化
根據索引欄位進行更新,否則行鎖升級為表鎖
InnoDB的行鎖是針對索引加的鎖,不是針對記錄加的鎖。
鎖
全域性鎖
全庫的資料備份
-- 加全域性鎖
flush tables with read lock;
-- 匯出資料庫
mysqldump -uroot -p1234 itcast > itcast.sql;
-- 釋放鎖
unlock tables;
-- innodb快照讀實現備份,不加鎖
mysqldump --single-transaction -uroot -p123456 itcast > itcast.sql
表級鎖
表鎖
共享讀鎖,獨佔寫鎖
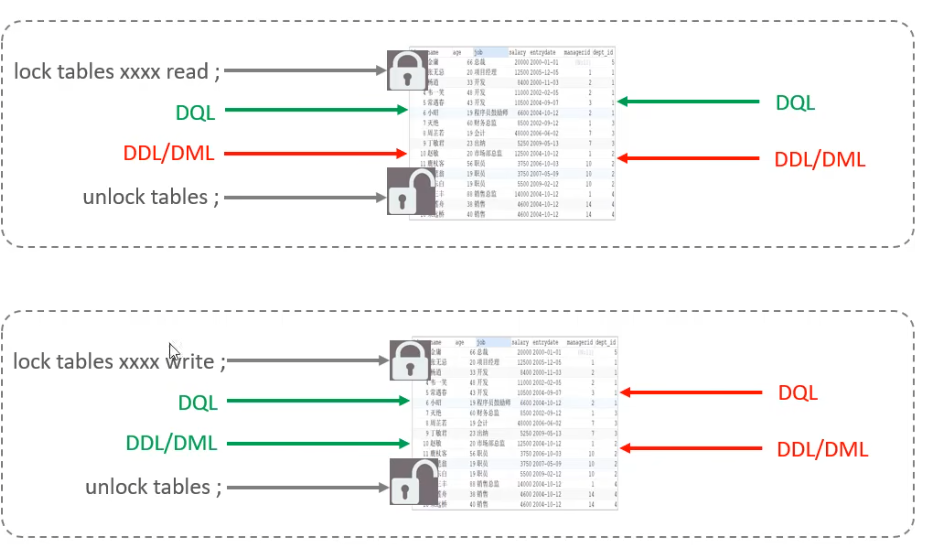
後設資料鎖(meta data lock, MDL)
避免在運算元據時對錶結構(後設資料)進行修改。

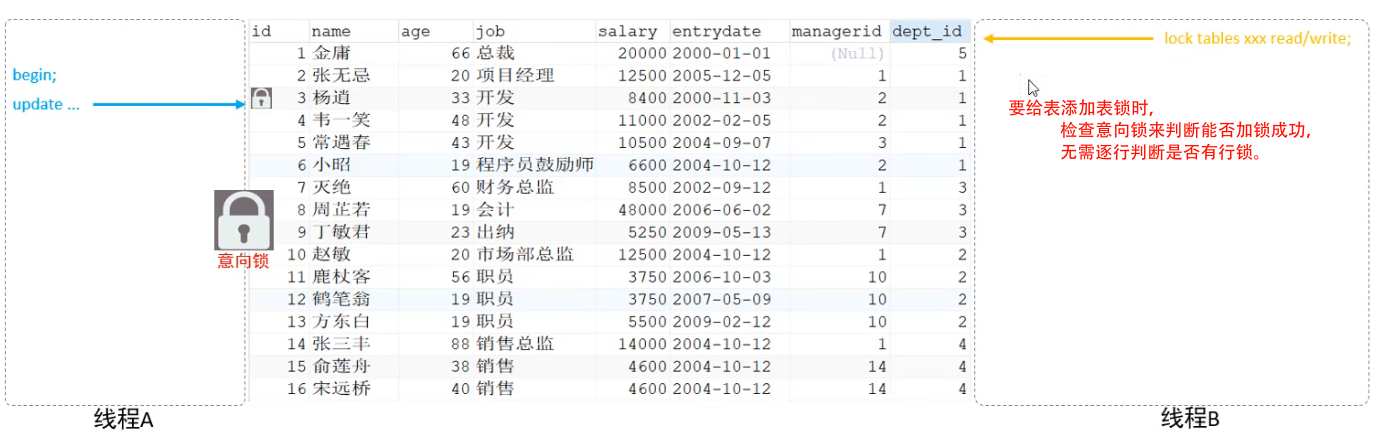
意向鎖
提高行鎖表鎖衝突時的判斷速度。
- 意向共享鎖(IS):與表鎖共享鎖(read)相容,與表鎖寫鎖(write)互斥。
- 意向排他鎖(Ix):與表鎖共享鎖(read)及寫鎖(write)都互斥。意向鎖之間不會互斥。
行級鎖
InnoDB的資料是基於索引組織的,行鎖是透過對索引上的索引項加鎖來實現的,而不是對記錄加的鎖
- 行鎖(RecordLock):鎖定單個行記錄的鎖,防止其他事務對此行進行update和delete。在RC、RR隔離級別下都支援。
- 間隙鎖(GapLock):鎖定索引記錄間隙(不含該記錄),確保索引記錄間隙不變,防止其他事務在這個間隙進行insert,產生幻讀。在RR隔離級別下都支援。
- 臨鍵鎖(Next-KeyLock):行鎖和間隙鎖組合,同時鎖住資料,並鎖住資料前面的間隙Gap。在RR隔離級別下支援。

行鎖
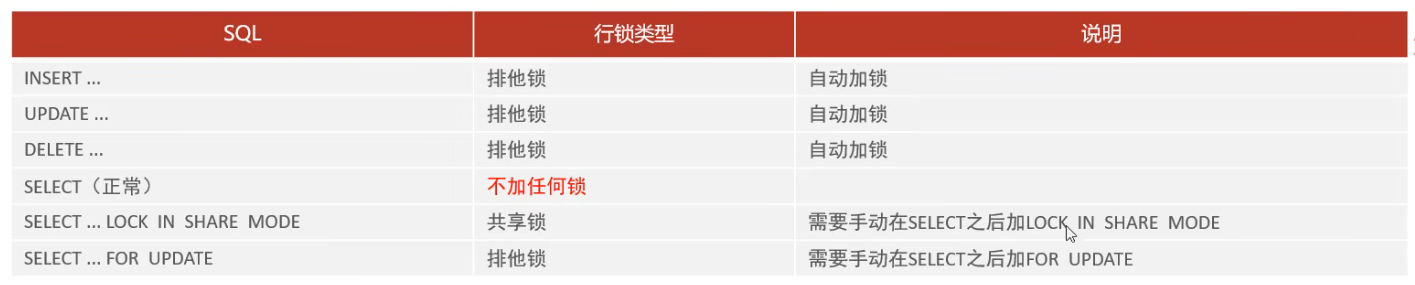
預設情況下,InnoDB在 REPEATABLE READ 事務隔離級別執行,InnoDB使用臨鍵鎖進行搜尋和索引掃描,以防止幻讀。
-
索引上的等值查詢(唯一索引)
- 對已存在的記錄,最佳化為行鎖。
- 不存在的記錄,最佳化為間隙鎖。
-
索引上的等值查詢(普通索引),向右遍歷時最後一個值不滿足查詢需求時,最佳化為間隙鎖

-
索引上的範圍查詢(唯一索引),會鎖到不滿足條件的第一個值為止。
-
InnoDB的行鎖是針對於 索引 加的鎖,不透過索引條件檢索資料,那麼InnoDB將對錶中的所有記錄加鎖,此時就會升級為表鎖。
日誌
錯誤日誌
-- 檢視相關配置
SHOW VARIABLES LIKE "%log_error%";

二進位制日誌
記錄DDL和DML語句
-- 檢視相關配置
SHOW VARIABLES LIKE "%log_bin%";
-- 檢視日誌格式
SHOW VARIABLES LIKE "%binlog_format";

| 日誌格式 | 含義 |
|---|---|
| STATEMENT | 基於SQL語句的日誌記錄,記錄的是SQL語句,對資料進行修改的SQL都會記錄在日誌檔案中。 |
| ROW | 基於行的日誌記錄,記錄的是每一行的資料變更。(預設) |
| MIXED | 混合了STATEMENT和ROW兩種格式,預設採用STATEMENT,在某些特殊情況下會自動切換為ROW進行記錄。 |
mysqlbinlog [引數選項] logfilename
-d : 指定資料庫名稱,只列出指定的資料庫相關操作。
-o : 忽略掉日誌中的前n行命令
-v : 將行事件(資料變更)重構為SQL語句
-vv : 將行事件(資料變更)重構為SQL語句,並輸出註釋資訊
清理二進位制日誌
-- 刪除全部binlog日誌,刪除之後,日誌編號,將從 binlog.000001重新開始
reset master;
-- 刪除******編號之前的所有日誌
purge master logs to 'binlog.***';
-- 刪除日誌為"y-mm-dd hh24:mi:ss"之前產生的所有日誌
purge master logs before 'yyyy-mm-dd hh24:mi:ss';
-- 配置過期時間
SHOW VARIABLES LIKE '%binlog_expire_logs_seconds%';
查詢日誌
-- 檢視相關配置
SHOW VARIABLES LIKE "%general%";
慢查詢日誌
-- 慢查詢日誌
slow_query_log=1
-- 執行時間引數
long_query_time=2
-- 記錄執行較慢的管理語句
log_slow_admin_statements =1
-- 記錄執行較慢的未使用索引的語句
log_queries_not_using_indexes = 1