Flink原理與實現:Window機制
Flink 認為 Batch 是 Streaming 的一個特例,所以 Flink 底層引擎是一個流式引擎,在上面實現了流處理和批處理。而視窗(window)就是從 Streaming 到 Batch 的一個橋樑。Flink 提供了非常完善的視窗機制,這是我認為的 Flink 最大的亮點之一(其他的亮點包括訊息亂序處理,和 checkpoint 機制)。本文我們將介紹流式處理中的視窗概念,介紹 Flink 內建的一些視窗和 Window API,最後討論下視窗在底層是如何實現的。
什麼是 Window
在流處理應用中,資料是連續不斷的,因此我們不可能等到所有資料都到了才開始處理。當然我們可以每來一個訊息就處理一次,但是有時我們需要做一些聚合類的處理,例如:在過去的1分鐘內有多少使用者點選了我們的網頁。在這種情況下,我們必須定義一個視窗,用來收集最近一分鐘內的資料,並對這個視窗內的資料進行計算。
視窗可以是時間驅動的(Time Window,例如:每30秒鐘),也可以是資料驅動的(Count Window,例如:每一百個元素)。一種經典的視窗分類可以分成:翻滾視窗(Tumbling Window,無重疊),滾動視窗(Sliding Window,有重疊),和會話視窗(Session Window,活動間隙)。
我們舉個具體的場景來形象地理解不同視窗的概念。假設,淘寶網會記錄每個使用者每次購買的商品個數,我們要做的是統計不同視窗中使用者購買商品的總數。下圖給出了幾種經典的視窗切分概述圖:

上圖中,raw data stream 代表使用者的購買行為流,圈中的數字代表該使用者本次購買的商品個數,事件是按時間分佈的,所以可以看出事件之間是有time gap的。Flink 提供了上圖中所有的視窗型別,下面我們會逐一進行介紹。
Time Window
就如名字所說的,Time Window 是根據時間對資料流進行分組的。這裡我們涉及到了流處理中的時間問題,時間問題和訊息亂序問題是緊密關聯的,這是流處理中現存的難題之一,我們將在後續的 EventTime 和訊息亂序處理 中對這部分問題進行深入探討。這裡我們只需要知道 Flink 提出了三種時間的概念,分別是event time(事件時間:事件發生時的時間),ingestion time(攝取時間:事件進入流處理系統的時間),processing time(處理時間:訊息被計算處理的時間)。Flink 中視窗機制和時間型別是完全解耦的,也就是說當需要改變時間型別時不需要更改視窗邏輯相關的程式碼。
-
Tumbling Time Window
如上圖,我們需要統計每一分鐘中使用者購買的商品的總數,需要將使用者的行為事件按每一分鐘進行切分,這種切分被成為翻滾時間視窗(Tumbling Time Window)。翻滾視窗能將資料流切分成不重疊的視窗,每一個事件只能屬於一個視窗。通過使用 DataStream API,我們可以這樣實現:// Stream of (userId, buyCnt) val buyCnts: DataStream[(Int, Int)] = ... val tumblingCnts: DataStream[(Int, Int)] = buyCnts // key stream by userId .keyBy(0) // tumbling time window of 1 minute length .timeWindow(Time.minutes(1)) // compute sum over buyCnt .sum(1) -
Sliding Time Window
但是對於某些應用,它們需要的視窗是不間斷的,需要平滑地進行視窗聚合。比如,我們可以每30秒計算一次最近一分鐘使用者購買的商品總數。這種視窗我們稱為滑動時間視窗(Sliding Time Window)。在滑窗中,一個元素可以對應多個視窗。通過使用 DataStream API,我們可以這樣實現:val slidingCnts: DataStream[(Int, Int)] = buyCnts .keyBy(0) // sliding time window of 1 minute length and 30 secs trigger interval .timeWindow(Time.minutes(1), Time.seconds(30)) .sum(1)
Count Window
Count Window 是根據元素個數對資料流進行分組的。
-
Tumbling Count Window
當我們想要每100個使用者購買行為事件統計購買總數,那麼每當視窗中填滿100個元素了,就會對視窗進行計算,這種視窗我們稱之為翻滾計數視窗(Tumbling Count Window),上圖所示視窗大小為3個。通過使用 DataStream API,我們可以這樣實現:// Stream of (userId, buyCnts) val buyCnts: DataStream[(Int, Int)] = ... val tumblingCnts: DataStream[(Int, Int)] = buyCnts // key stream by sensorId .keyBy(0) // tumbling count window of 100 elements size .countWindow(100) // compute the buyCnt sum .sum(1) -
Sliding Count Window
當然Count Window 也支援 Sliding Window,雖在上圖中未描述出來,但和Sliding Time Window含義是類似的,例如計算每10個元素計算一次最近100個元素的總和,程式碼示例如下。val slidingCnts: DataStream[(Int, Int)] = vehicleCnts .keyBy(0) // sliding count window of 100 elements size and 10 elements trigger interval .countWindow(100, 10) .sum(1)
Session Window
在這種使用者互動事件流中,我們首先想到的是將事件聚合到會話視窗中(一段使用者持續活躍的週期),由非活躍的間隙分隔開。如上圖所示,就是需要計算每個使用者在活躍期間總共購買的商品數量,如果使用者30秒沒有活動則視為會話斷開(假設raw data stream是單個使用者的購買行為流)。Session Window 的示例程式碼如下:
// Stream of (userId, buyCnts)
val buyCnts: DataStream[(Int, Int)] = ...
val sessionCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// session window based on a 30 seconds session gap interval
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(30)))
.sum(1)一般而言,window 是在無限的流上定義了一個有限的元素集合。這個集合可以是基於時間的,元素個數的,時間和個數結合的,會話間隙的,或者是自定義的。Flink 的 DataStream API 提供了簡潔的運算元來滿足常用的視窗操作,同時提供了通用的視窗機制來允許使用者自己定義視窗分配邏輯。下面我們會對 Flink 視窗相關的 API 進行剖析。
剖析 Window API
得益於 Flink Window API 鬆耦合設計,我們可以非常靈活地定義符合特定業務的視窗。Flink 中定義一個視窗主要需要以下三個元件。
-
Window Assigner:用來決定某個元素被分配到哪個/哪些視窗中去。
如下類圖展示了目前內建實現的 Window Assigners:  -
Trigger:觸發器。決定了一個視窗何時能夠被計算或清除,每個視窗都會擁有一個自己的Trigger。
如下類圖展示了目前內建實現的 Triggers:  -
Evictor:可以譯為“驅逐者”。在Trigger觸發之後,在視窗被處理之前,Evictor(如果有Evictor的話)會用來剔除視窗中不需要的元素,相當於一個filter。
如下類圖展示了目前內建實現的 Evictors: 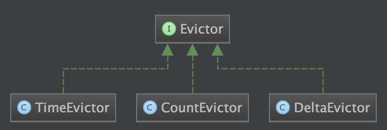
上述三個元件的不同實現的不同組合,可以定義出非常複雜的視窗。Flink 中內建的視窗也都是基於這三個元件構成的,當然內建視窗有時候無法解決使用者特殊的需求,所以 Flink 也暴露了這些視窗機制的內部介面供使用者實現自定義的視窗。下面我們將基於這三者探討視窗的實現機制。
Window 的實現
下圖描述了 Flink 的視窗機制以及各元件之間是如何相互工作的。

首先上圖中的元件都位於一個運算元(window operator)中,資料流源源不斷地進入運算元,每一個到達的元素都會被交給 WindowAssigner。WindowAssigner 會決定元素被放到哪個或哪些視窗(window),可能會建立新視窗。因為一個元素可以被放入多個視窗中,所以同時存在多個視窗是可能的。注意,Window本身只是一個ID識別符號,其內部可能儲存了一些後設資料,如TimeWindow中有開始和結束時間,但是並不會儲存視窗中的元素。視窗中的元素實際儲存在 Key/Value State 中,key為Window,value為元素集合(或聚合值)。為了保證視窗的容錯性,該實現依賴了 Flink 的 State 機制(參見 state 文件)。
每一個視窗都擁有一個屬於自己的 Trigger,Trigger上會有定時器,用來決定一個視窗何時能夠被計算或清除。每當有元素加入到該視窗,或者之前註冊的定時器超時了,那麼Trigger都會被呼叫。Trigger的返回結果可以是 continue(不做任何操作),fire(處理視窗資料),purge(移除視窗和視窗中的資料),或者 fire + purge。一個Trigger的呼叫結果只是fire的話,那麼會計算視窗並保留視窗原樣,也就是說視窗中的資料仍然保留不變,等待下次Trigger fire的時候再次執行計算。一個視窗可以被重複計算多次知道它被 purge 了。在purge之前,視窗會一直佔用著記憶體。
當Trigger fire了,視窗中的元素集合就會交給Evictor(如果指定了的話)。Evictor 主要用來遍歷視窗中的元素列表,並決定最先進入視窗的多少個元素需要被移除。剩餘的元素會交給使用者指定的函式進行視窗的計算。如果沒有 Evictor 的話,視窗中的所有元素會一起交給函式進行計算。
計算函式收到了視窗的元素(可能經過了 Evictor 的過濾),並計算出視窗的結果值,併傳送給下游。視窗的結果值可以是一個也可以是多個。DataStream API 上可以接收不同型別的計算函式,包括預定義的sum(),min(),max(),還有 ReduceFunction,FoldFunction,還有WindowFunction。WindowFunction 是最通用的計算函式,其他的預定義的函式基本都是基於該函式實現的。
Flink 對於一些聚合類的視窗計算(如sum,min)做了優化,因為聚合類的計算不需要將視窗中的所有資料都儲存下來,只需要儲存一個result值就可以了。每個進入視窗的元素都會執行一次聚合函式並修改result值。這樣可以大大降低記憶體的消耗並提升效能。但是如果使用者定義了 Evictor,則不會啟用對聚合視窗的優化,因為 Evictor 需要遍歷視窗中的所有元素,必須要將視窗中所有元素都存下來。
原始碼分析
上述的三個元件構成了 Flink 的視窗機制。為了更清楚地描述視窗機制,以及解開一些疑惑(比如 purge 和 Evictor 的區別和用途),我們將一步步地解釋 Flink 內建的一些視窗(Time Window,Count Window,Session Window)是如何實現的。
Count Window 實現
Count Window 是使用三元件的典範,我們可以在 KeyedStream 上建立 Count Window,其原始碼如下所示:
// tumbling count window
public WindowedStream<T, KEY, GlobalWindow> countWindow(long size) {
return window(GlobalWindows.create()) // create window stream using GlobalWindows
.trigger(PurgingTrigger.of(CountTrigger.of(size))); // trigger is window size
}
// sliding count window
public WindowedStream<T, KEY, GlobalWindow> countWindow(long size, long slide) {
return window(GlobalWindows.create())
.evictor(CountEvictor.of(size)) // evictor is window size
.trigger(CountTrigger.of(slide)); // trigger is slide size
}第一個函式是申請翻滾計數視窗,引數為視窗大小。第二個函式是申請滑動計數視窗,引數分別為視窗大小和滑動大小。它們都是基於 GlobalWindows 這個 WindowAssigner 來建立的視窗,該assigner會將所有元素都分配到同一個global window中,所有GlobalWindows的返回值一直是 GlobalWindow 單例。基本上自定義的視窗都會基於該assigner實現。
翻滾計數視窗並不帶evictor,只註冊了一個trigger。該trigger是帶purge功能的 CountTrigger。也就是說每當視窗中的元素數量達到了 window-size,trigger就會返回fire+purge,視窗就會執行計算並清空視窗中的所有元素,再接著儲備新的元素。從而實現了tumbling的視窗之間無重疊。
滑動計數視窗的各視窗之間是有重疊的,但我們用的 GlobalWindows assinger 從始至終只有一個視窗,不像 sliding time assigner 可以同時存在多個視窗。所以trigger結果不能帶purge,也就是說計算完視窗後視窗中的資料要保留下來(供下個滑窗使用)。另外,trigger的間隔是slide-size,evictor的保留的元素個數是window-size。也就是說,每個滑動間隔就觸發一次視窗計算,並保留下最新進入視窗的window-size個元素,剔除舊元素。
假設有一個滑動計數視窗,每2個元素計算一次最近4個元素的總和,那麼視窗工作示意圖如下所示:

圖中所示的各個視窗邏輯上是不同的視窗,但在物理上是同一個視窗。該滑動計數視窗,trigger的觸發條件是元素個數達到2個(每進入2個元素就會觸發一次),evictor保留的元素個數是4個,每次計算完視窗總和後會保留剩餘的元素。所以第一次觸發trigger是當元素5進入,第三次觸發trigger是當元素2進入,並驅逐5和2,計算剩餘的4個元素的總和(22)併傳送出去,保留下2,4,9,7元素供下個邏輯視窗使用。
Time Window 實現
同樣的,我們也可以在 KeyedStream 上申請 Time Window,其原始碼如下所示:
// tumbling time window
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(TumblingProcessingTimeWindows.of(size));
} else {
return window(TumblingEventTimeWindows.of(size));
}
}
// sliding time window
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size, Time slide) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(SlidingProcessingTimeWindows.of(size, slide));
} else {
return window(SlidingEventTimeWindows.of(size, slide));
}
}在方法體內部會根據當前環境註冊的時間型別,使用不同的WindowAssigner建立window。可以看到,EventTime和IngestTime都使用了XXXEventTimeWindows這個assigner,因為EventTime和IngestTime在底層的實現上只是在Source處為Record打時間戳的實現不同,在window operator中的處理邏輯是一樣的。
這裡我們主要分析sliding process time window,如下是相關原始碼:
public class SlidingProcessingTimeWindows extends WindowAssigner<Object, TimeWindow> {
private static final long serialVersionUID = 1L;
private final long size;
private final long slide;
private SlidingProcessingTimeWindows(long size, long slide) {
this.size = size;
this.slide = slide;
}
@Override
public Collection<TimeWindow> assignWindows(Object element, long timestamp) {
timestamp = System.currentTimeMillis();
List<TimeWindow> windows = new ArrayList<>((int) (size / slide));
// 對齊時間戳
long lastStart = timestamp - timestamp % slide;
for (long start = lastStart;
start > timestamp - size;
start -= slide) {
// 當前時間戳對應了多個window
windows.add(new TimeWindow(start, start + size));
}
return windows;
}
...
}
public class ProcessingTimeTrigger extends Trigger<Object, TimeWindow> {
@Override
// 每個元素進入視窗都會呼叫該方法
public TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) {
// 註冊定時器,當系統時間到達window end timestamp時會回撥該trigger的onProcessingTime方法
ctx.registerProcessingTimeTimer(window.getEnd());
return TriggerResult.CONTINUE;
}
@Override
// 返回結果表示執行視窗計算並清空視窗
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) {
return TriggerResult.FIRE_AND_PURGE;
}
...
}首先,SlidingProcessingTimeWindows會對每個進入視窗的元素根據系統時間分配到(size / slide)個不同的視窗,並會在每個視窗上根據視窗結束時間註冊一個定時器(相同視窗只會註冊一份),當定時器超時時意味著該視窗完成了,這時會回撥對應視窗的Trigger的onProcessingTime方法,返回FIRE_AND_PURGE,也就是會執行視窗計算並清空視窗。整個過程示意圖如下:

如上圖所示橫軸代表時間戳(為簡化問題,時間戳從0開始),第一條record會被分配到[-5,5)和[0,10)兩個視窗中,當系統時間到5時,就會計算[-5,5)視窗中的資料,並將結果傳送出去,最後清空視窗中的資料,釋放該視窗資源。
Session Window 實現
Session Window 是一個需求很強烈的視窗機制,但Session也比之前的Window更復雜,所以 Flink 也是在即將到來的 1.1.0 版本中才支援了該功能。由於篇幅問題,我們將在後續的 Session Window 的實現 中深入探討 Session Window 的實現。
參考資料
- Flink Concepts
- [Introducing Stream Windows in Apache Flink
](https://flink.apache.org/news/2015/12/04/Introducing-windows.html) - Streaming Window Join Rework
- Window Semantics (and Implementation)
- Introduction to Flink Streaming – Part 6 : Anatomy of Window API
- Introduction to Flink Streaming – Part 5 : Window API in Flink
相關文章
- Flink Window基本概念與實現原理
- Kubernetes List-Watch 機制原理與實現 - chunked
- 【Flink入門修煉】2-3 Flink Checkpoint 原理機制
- Android RollBack機制實現原理剖析Android
- 深入詳解Java反射機制與底層實現原理?Java反射
- Flink Window分析及Watermark解決亂序資料機制深入剖析-Flink牛刀小試
- javascript事件機制底層實現原理JavaScript事件
- Android-Handler訊息機制實現原理Android
- Flink Sql Gateway的原理與實踐SQLGateway
- 實時計算框架:Flink叢集搭建與執行機制框架
- 利用反射機制實現依賴注入的原理反射依賴注入
- Nestjs模組機制的概念和實現原理JS
- 流式處理新秀Flink原理與實踐
- Flink Exactly-once 實現原理解析
- Java 併發機制底層實現 —— volatile 原理、synchronize 鎖優化機制Java優化
- flink window詳解
- Fluter訊息機制之微任務實現原理
- Netty原始碼解析 -- 事件迴圈機制實現原理Netty原始碼事件
- Taro cli流程和外掛化機制實現原理
- Flink sql實現原理及Apache Calcite介紹SQLApache
- Android全面解析之Window機制Android
- Flink CDC MongoDB Connector 的實現原理和使用實踐MongoDB
- 微信域名檢測的機制原理以及實現方式
- Tomcat 7 啟動分析(五)Lifecycle 機制和實現原理Tomcat
- 深入理解Java的垃圾回收機制(GC)實現原理JavaGC
- Angular 依賴注入機制實現原理的深入介紹Angular依賴注入
- 深度剖析Spring Boot自動裝配機制實現原理Spring Boot
- Android之window機制token驗證Android
- Flink 狀態管理與checkPoint資料容錯機制深入剖析-Flink牛刀小試
- Flink CheckPoint狀態點恢復與savePoint機制對比剖析-Flink牛刀小試
- MVVM雙向繫結機制的原理和程式碼實現MVVM
- iOS開發·KVO用法,原理與底層實現: runtime模擬實現KVO監聽機制(Blcok及Delgate方式)iOS
- Lombok 原理與實現Lombok
- 隨機森林演算法原理與Python實現隨機森林演算法Python
- Spark SQL外部資料來源與實現機制SparkSQL
- Flink 類載入機制介紹
- Android快取機制-LRU cache原理與用法Android快取
- Netty之DefaultAttributeMap與AttributeKey的機制和原理Netty
- Java進階 | 泛型機制與反射原理Java泛型反射