HBase 資料庫檢索效能優化策略
HBase 資料庫是一個基於分散式的、面向列的、主要用於非結構化資料儲存用途的開源資料庫。其設計思路來源於 Google 的非開源資料庫”BigTable”。
HDFS 為 HBase 提供底層儲存支援,MapReduce 為其提供計算能力,ZooKeeper 為其提供協調服務和 failover(失效轉移的備份操作)機制。Pig 和 Hive 為 HBase 提供了高層語言支援,使其可以進行資料統計(可實現多表 join 等),Sqoop 則為其提供 RDBMS 資料匯入功能。
HBase 不能支援 where 條件、Order by 查詢,只支援按照主鍵 Rowkey 和主鍵的 range 來查詢,但是可以通過 HBase 提供的 API 進行條件過濾。
HBase 的 Rowkey 是資料行的唯一標識,必須通過它進行資料行訪問,目前有三種方式,單行鍵訪問、行鍵範圍訪問、全表掃描訪問。資料按行鍵的方式排序儲存,依次按位比較,數值較大的排列在後,例如 int 方式的排序:1,10,100,11,12,2,20…,906,…。
ColumnFamily 是“列族”,屬於 schema 表,在建表時定義,每個列屬於一個列族,列名用列族作為字首“ColumnFamily:qualifier”,訪問控制、磁碟和記憶體的使用統計都是在列族層面進行的。
Cell 是通過行和列確定的一個儲存單元,值以位元組碼儲存,沒有型別。
Timestamp 是區分不同版本 Cell 的索引,64 位整型。不同版本的資料按照時間戳倒序排列,最新的資料版本排在最前面。
Hbase 在行方向上水平劃分成 N 個 Region,每個表一開始只有一個 Region,資料量增多,Region 自動分裂為兩個,不同 Region 分佈在不同 Server 上,但同一個不會拆分到不同 Server。
Region 按 ColumnFamily 劃分成 Store,Store 為最小儲存單元,用於儲存一個列族的資料,每個 Store 包括記憶體中的 memstore 和持久化到 disk 上的 HFile。
圖 1 是 HBase 資料表的示例,資料分佈在多臺節點機器上面。

圖 1. HBase 資料表示例(檢視大圖)
{kind=link}
HBase 呼叫 API 示例
類似於操作關係型資料庫的 JDBC 庫,HBase client 包本身提供了大量可以供操作的 API,幫助使用者快速操作 HBase 資料庫。提供了諸如建立資料表、刪除資料表、增加欄位、存入資料、讀取資料等等介面。清單 1 提供了一個作者封裝的工具類,包括運算元據表、讀取資料、存入資料、匯出資料等方法。
清單 1.HBase API 操作工具類程式碼
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.hbase.HColumnDescriptor;
importorg.apache.hadoop.hbase.HTableDescriptor;
importorg.apache.hadoop.hbase.KeyValue;
importorg.apache.hadoop.hbase.client.Get;
importorg.apache.hadoop.hbase.client.HBaseAdmin;
importorg.apache.hadoop.hbase.client.HTable;
importorg.apache.hadoop.hbase.client.Put;
importorg.apache.hadoop.hbase.client.Result;
importorg.apache.hadoop.hbase.client.ResultScanner;
importorg.apache.hadoop.hbase.client.Scan;
importorg.apache.hadoop.hbase.util.Bytes;
importjava.io.IOException;
importjava.util.ArrayList;
importjava.util.List;
publicclass HBaseUtil {
privateConfiguration conf = null;
privateHBaseAdmin admin = null;
protectedHBaseUtil(Configuration conf) throwsIOException {
this.conf = conf;
this.admin = newHBaseAdmin(conf);
}
publicboolean existsTable(String table)
throwsIOException {
returnadmin.tableExists(table);
}
publicvoid createTable(String table, byte[][] splitKeys, String... colfams)
throwsIOException {
HTableDescriptor desc = newHTableDescriptor(table);
for(String cf : colfams) {
HColumnDescriptor coldef = newHColumnDescriptor(cf);
desc.addFamily(coldef);
}
if(splitKeys != null) {
admin.createTable(desc, splitKeys);
}else{
admin.createTable(desc);
}
}
publicvoid disableTable(String table) throwsIOException {
admin.disableTable(table);
}
publicvoid dropTable(String table) throwsIOException {
if(existsTable(table)) {
disableTable(table);
admin.deleteTable(table);
}
}
publicvoid fillTable(String table, intstartRow, intendRow, intnumCols,
intpad, booleansetTimestamp, booleanrandom,
String... colfams) throwsIOException {
HTable tbl = newHTable(conf, table);
for(introw = startRow; row <= endRow; row++) {
for(intcol = 0; col < numCols; col++) {
Put put = newPut(Bytes.toBytes("row-"));
for(String cf : colfams) {
String colName = "col-";
String val = "val-";
if(setTimestamp) {
put.add(Bytes.toBytes(cf), Bytes.toBytes(colName),
col, Bytes.toBytes(val));
}else{
put.add(Bytes.toBytes(cf), Bytes.toBytes(colName),
Bytes.toBytes(val));
}
}
tbl.put(put);
}
}
tbl.close();
}
publicvoid put(String table, String row, String fam, String qual,
String val) throwsIOException {
HTable tbl = newHTable(conf, table);
Put put = newPut(Bytes.toBytes(row));
put.add(Bytes.toBytes(fam), Bytes.toBytes(qual), Bytes.toBytes(val));
tbl.put(put);
tbl.close();
}
publicvoid put(String table, String row, String fam, String qual, longts,
String val) throwsIOException {
HTable tbl = newHTable(conf, table);
Put put = newPut(Bytes.toBytes(row));
put.add(Bytes.toBytes(fam), Bytes.toBytes(qual), ts, Bytes.toBytes(val));
tbl.put(put);
tbl.close();
}
publicvoid put(String table, String[] rows, String[] fams, String[] quals,
long[] ts, String[] vals) throwsIOException {
HTable tbl = newHTable(conf, table);
for(String row : rows) {
Put put = newPut(Bytes.toBytes(row));
for(String fam : fams) {
intv = 0;
for(String qual : quals) {
String val = vals[v < vals.length ? v : vals.length];
longt = ts[v < ts.length ? v : ts.length - 1];
put.add(Bytes.toBytes(fam), Bytes.toBytes(qual), t,
Bytes.toBytes(val));
v++;
}
}
tbl.put(put);
}
tbl.close();
}
publicvoid dump(String table, String[] rows, String[] fams, String[] quals)
throwsIOException {
HTable tbl = newHTable(conf, table);
List<Get> gets = newArrayList<Get>();
for(String row : rows) {
Get get = newGet(Bytes.toBytes(row));
get.setMaxVersions();
if(fams != null) {
for(String fam : fams) {
for(String qual : quals) {
get.addColumn(Bytes.toBytes(fam), Bytes.toBytes(qual));
}
}
}
gets.add(get);
}
Result[] results = tbl.get(gets);
for(Result result : results) {
for(KeyValue kv : result.raw()) {
System.out.println("KV: " + kv +
", Value: " + Bytes.toString(kv.getValue()));
}
}
}
privatestatic void scan(intcaching, intbatch) throwsIOException {
HTable table = null;
finalint[] counters = {0,0};
Scan scan = newScan();
scan.setCaching(caching);
// co ScanCacheBatchExample-1-Set Set caching and batch parameters.
scan.setBatch(batch);
ResultScanner scanner = table.getScanner(scan);
for(Result result : scanner) {
counters[1]++;
// co ScanCacheBatchExample-2-Count Count the number of Results available.
}
scanner.close();
System.out.println("Caching: " + caching + ", Batch: " + batch +
", Results: " + counters[1] + ", RPCs: " + counters[0]);
}
}操作表的 API 都有 HBaseAdmin 提供,特別講解一下 Scan 的操作部署。
HBase 的表資料分為多個層次,HRegion->HStore->[HFile,HFile,…,MemStore]。
在 HBase 中,一張表可以有多個 Column Family,在一次 Scan 的流程中,每個 Column Family(Store) 的資料讀取由一個 StoreScanner 物件負責。每個 Store 的資料由一個記憶體中的 MemStore 和磁碟上的 HFile 檔案組成,對應的 StoreScanner 物件使用一個 MemStoreScanner 和 N 個 StoreFileScanner 來進行實際的資料讀取。
因此,讀取一行的資料需要以下步驟:
- 按照順序讀取出每個 Store
- 對於每個 Store,合併 Store 下面的相關的 HFile 和記憶體中的 MemStore
這兩步都是通過堆來完成。RegionScanner 的讀取通過下面的多個 StoreScanner 組成的堆完成,使用 RegionScanner 的成員變數 KeyValueHeap storeHeap 表示。一個 StoreScanner 一個堆,堆中的元素就是底下包含的 HFile 和 MemStore 對應的 StoreFileScanner 和 MemStoreScanner。堆的優勢是建堆效率高,可以動態分配記憶體大小,不必事先確定生存週期。
接著呼叫 seekScanners() 對這些 StoreFileScanner 和 MemStoreScanner 分別進行 seek。seek 是針對 KeyValue 的,seek 的語義是 seek 到指定 KeyValue,如果指定 KeyValue 不存在,則 seek 到指定 KeyValue 的下一個。
Scan類常用方法說明:
- scan.addFamily()/scan.addColumn():指定需要的 Family 或 Column,如果沒有呼叫任何 addFamily 或 Column,會返回所有的 Columns;
- scan.setMaxVersions():指定最大的版本個數。如果不帶任何引數呼叫 setMaxVersions,表示取所有的版本。如果不掉用 setMaxVersions,只會取到最新的版本.;
- scan.setTimeRange():指定最大的時間戳和最小的時間戳,只有在此範圍內的 Cell 才能被獲取;
- scan.setTimeStamp():指定時間戳;
- scan.setFilter():指定 Filter 來過濾掉不需要的資訊;
- scan.setStartRow():指定開始的行。如果不呼叫,則從表頭開始;
- scan.setStopRow():指定結束的行(不含此行);
- scan. setCaching():每次從伺服器端讀取的行數(影響 RPC);
- scan.setBatch():指定最多返回的 Cell 數目。用於防止一行中有過多的資料,導致 OutofMemory 錯誤,預設無限制。
HBase 資料表優化
HBase 是一個高可靠性、高效能、面向列、可伸縮的分散式資料庫,但是當併發量過高或者已有資料量很大時,讀寫效能會下降。我們可以採用如下方式逐步提升 HBase 的檢索速度。
預先分割槽
預設情況下,在建立 HBase 表的時候會自動建立一個 Region 分割槽,當匯入資料的時候,所有的 HBase 客戶端都向這一個 Region 寫資料,直到這個 Region 足夠大了才進行切分。一種可以加快批量寫入速度的方法是通過預先建立一些空的 Regions,這樣當資料寫入 HBase 時,會按照 Region 分割槽情況,在叢集內做資料的負載均衡。
Rowkey 優化
HBase 中 Rowkey 是按照字典序儲存,因此,設計 Rowkey 時,要充分利用排序特點,將經常一起讀取的資料儲存到一塊,將最近可能會被訪問的資料放在一塊。
此外,Rowkey 若是遞增的生成,建議不要使用正序直接寫入 Rowkey,而是採用 reverse 的方式反轉 Rowkey,使得 Rowkey 大致均衡分佈,這樣設計有個好處是能將 RegionServer 的負載均衡,否則容易產生所有新資料都在一個 RegionServer 上堆積的現象,這一點還可以結合 table 的預切分一起設計。
減少ColumnFamily 數量
不要在一張表裡定義太多的 ColumnFamily。目前 Hbase 並不能很好的處理超過 2~3 個 ColumnFamily 的表。因為某個 ColumnFamily 在 flush 的時候,它鄰近的 ColumnFamily 也會因關聯效應被觸發 flush,最終導致系統產生更多的 I/O。
快取策略 (setCaching)
建立表的時候,可以通過 HColumnDescriptor.setInMemory(true) 將表放到 RegionServer 的快取中,保證在讀取的時候被 cache 命中。
設定儲存生命期
建立表的時候,可以通過 HColumnDescriptor.setTimeToLive(int timeToLive) 設定表中資料的儲存生命期,過期資料將自動被刪除。
硬碟配置
每臺 RegionServer 管理 10~1000 個 Regions,每個 Region 在 1~2G,則每臺 Server 最少要 10G,最大要 1000*2G=2TB,考慮 3 備份,則要 6TB。方案一是用 3 塊 2TB 硬碟,二是用 12 塊 500G 硬碟,頻寬足夠時,後者能提供更大的吞吐率,更細粒度的冗餘備份,更快速的單盤故障恢復。
分配合適的記憶體給 RegionServer 服務
在不影響其他服務的情況下,越大越好。例如在 HBase 的 conf 目錄下的 hbase-env.sh 的最後新增 export HBASE_REGIONSERVER_OPTS=”-Xmx16000m $HBASE_REGIONSERVER_OPTS”
其中 16000m 為分配給 RegionServer 的記憶體大小。
寫資料的備份數
備份數與讀效能成正比,與寫效能成反比,且備份數影響高可用性。有兩種配置方式,一種是將 hdfs-site.xml 拷貝到 hbase 的 conf 目錄下,然後在其中新增或修改配置項 dfs.replication 的值為要設定的備份數,這種修改對所有的 HBase 使用者表都生效,另外一種方式,是改寫 HBase 程式碼,讓 HBase 支援針對列族設定備份數,在建立表時,設定列族備份數,預設為 3,此種備份數只對設定的列族生效。
WAL(預寫日誌)
可設定開關,表示 HBase 在寫資料前用不用先寫日誌,預設是開啟,關掉會提高效能,但是如果系統出現故障 (負責插入的 RegionServer 掛掉),資料可能會丟失。配置 WAL 在呼叫 Java API 寫入時,設定 Put 例項的 WAL,呼叫 Put.setWriteToWAL(boolean)。
批量寫
HBase 的 Put 支援單條插入,也支援批量插入,一般來說批量寫更快,節省來回的網路開銷。在客戶端呼叫 Java API 時,先將批量的 Put 放入一個 Put 列表,然後呼叫 HTable 的 Put(Put 列表) 函式來批量寫。
客戶端一次從伺服器拉取的數量
通過配置一次拉去的較大的資料量可以減少客戶端獲取資料的時間,但是它會佔用客戶端記憶體。有三個地方可進行配置:
- 在 HBase 的 conf 配置檔案中進行配置 hbase.client.scanner.caching;
- 通過呼叫 HTable.setScannerCaching(int scannerCaching) 進行配置;
- 通過呼叫 Scan.setCaching(int caching) 進行配置。三者的優先順序越來越高。
RegionServer 的請求處理 IO 執行緒數
較少的 IO 執行緒適用於處理單次請求記憶體消耗較高的 Big Put 場景 (大容量單次 Put 或設定了較大 cache 的 Scan,均屬於 Big Put) 或 ReigonServer 的記憶體比較緊張的場景。
較多的 IO 執行緒,適用於單次請求記憶體消耗低,TPS 要求 (每秒事務處理量 (TransactionPerSecond)) 非常高的場景。設定該值的時候,以監控記憶體為主要參考。
在 hbase-site.xml 配置檔案中配置項為 hbase.regionserver.handler.count。
Region 大小設定
配置項為 hbase.hregion.max.filesize,所屬配置檔案為 hbase-site.xml.,預設大小 256M。
在當前 ReigonServer 上單個 Reigon 的最大儲存空間,單個 Region 超過該值時,這個 Region 會被自動 split 成更小的 Region。小 Region 對 split 和 compaction 友好,因為拆分 Region 或 compact 小 Region 裡的 StoreFile 速度很快,記憶體佔用低。缺點是 split 和 compaction 會很頻繁,特別是數量較多的小 Region 不停地 split, compaction,會導致叢集響應時間波動很大,Region 數量太多不僅給管理上帶來麻煩,甚至會引發一些 Hbase 的 bug。一般 512M 以下的都算小 Region。大 Region 則不太適合經常 split 和 compaction,因為做一次 compact 和 split 會產生較長時間的停頓,對應用的讀寫效能衝擊非常大。
此外,大 Region 意味著較大的 StoreFile,compaction 時對記憶體也是一個挑戰。如果你的應用場景中,某個時間點的訪問量較低,那麼在此時做 compact 和 split,既能順利完成 split 和 compaction,又能保證絕大多數時間平穩的讀寫效能。compaction 是無法避免的,split 可以從自動調整為手動。只要通過將這個引數值調大到某個很難達到的值,比如 100G,就可以間接禁用自動 split(RegionServer 不會對未到達 100G 的 Region 做 split)。再配合 RegionSplitter 這個工具,在需要 split 時,手動 split。手動 split 在靈活性和穩定性上比起自動 split 要高很多,而且管理成本增加不多,比較推薦 online 實時系統使用。記憶體方面,小 Region 在設定 memstore 的大小值上比較靈活,大 Region 則過大過小都不行,過大會導致 flush 時 app 的 IO wait 增高,過小則因 StoreFile 過多影響讀效能。
HBase 配置
建議 HBase 的伺服器記憶體至少 32G,表 1 是通過實踐檢驗得到的分配給各角色的記憶體建議值。
| 模組 | 服務種類 | 記憶體需求 |
|---|---|---|
| HDFS | HDFS NameNode | 16GB |
| HDFS DataNode | 2GB | |
| HBase | HMaster | 2GB |
| HRegionServer | 16GB | |
| ZooKeeper | ZooKeeper | 4GB |
表 1. HBase 相關服務配置資訊
HBase 的單個 Region 大小建議設定大一些,推薦 2G,RegionServer 處理少量的大 Region 比大量的小 Region 更快。對於不重要的資料,在建立表時將其放在單獨的列族內,並且設定其列族備份數為 2(預設是這樣既保證了雙備份,又可以節約空間,提高寫效能,代價是高可用性比備份數為 3 的稍差,且讀效能不如預設備份數的時候。
實際案例
專案要求可以刪除儲存在 HBase 資料表中的資料,資料在 HBase 中的 Rowkey 由任務 ID(資料由任務產生) 加上 16 位隨機陣列成,任務資訊由單獨一張表維護。圖 2 所示是資料刪除流程圖。

圖 2. 資料刪除流程圖
最初的設計是在刪除任務的同時按照任務 ID 刪除該任務儲存在 HBase 中的相應資料。但是 HBase 資料較多時會導致刪除耗時較長,同時由於磁碟 I/O 較高,會導致資料讀取、寫入超時。
檢視 HBase 日誌發現刪除資料時,HBase 在做 Major Compaction 操作。Major Compaction 操作的目的是合併檔案,並清除刪除、過期、多餘版本的資料。Major Compaction 時 HBase 將合併 Region 中 StoreFile,該動作如果持續長時間會導致整個 Region 都不可讀,最終導致所有基於這些 Region 的查詢超時。
如果想要解決 Major Compaction 問題,需要檢視它的原始碼。通過檢視 HBase 原始碼發現 RegionServer 在啟動時候,有個 CompactionChecker 執行緒在定期檢測是否需要做 Compact。原始碼如圖 3 所示。

圖 3. CompactionChecker 執行緒程式碼圖
isMajorCompaction 中會根據 hbase.hregion.majorcompaction 引數來判斷是否做 Major Compact。如果 hbase.hregion.majorcompaction 為 0,則返回 false。修改配置檔案 hbase.hregion.majorcompaction 為 0,禁止 HBase 的定期 Major Compaction 機制,通過自定義的定時機制 (在凌晨 HBase 業務不繁忙時) 執行 Major 操作,這個定時可以是通過 Linux cron 定時啟動指令碼,也可以通過 Java 的 timer schedule,在實際專案中使用 Quartz 來啟動,啟動的時間配置在配置檔案中給出,可以方便的修改 Major Compact 啟動的時間。通過這種修改後,我們發現在刪除資料後仍會有 Compact 操作。這樣流程進入 needsCompaction = true 的分支。檢視 needsCompaction 判斷條件為 (storefiles.size() – filesCompacting.size()) > minFilesToCompact 觸發。同時當需緊縮的檔案數等於 Store 的所有檔案數,Minor Compact 自動升級為 Major Compact。但是 Compact 操作不能禁止,因為這樣會導致資料一直存在,最終影響查詢效率。
基於以上分析,我們必須重新考慮刪除資料的流程。對使用者來說,使用者只要在檢索時對於刪除的任務不進行檢索即可。那麼只需要刪除該條任務記錄,對於該任務相關聯的資料不需要立馬進行刪除。當系統空閒時候再去定時刪除 HBase 資料表中的資料,並對 Region 做 Major Compact,清理已經刪除的資料。通過對任務刪除流程的修改,達到專案的需求,同時這種修改也不需要修改 HBase 的配置。

圖 4. 資料刪除流程對比圖(檢視大圖)
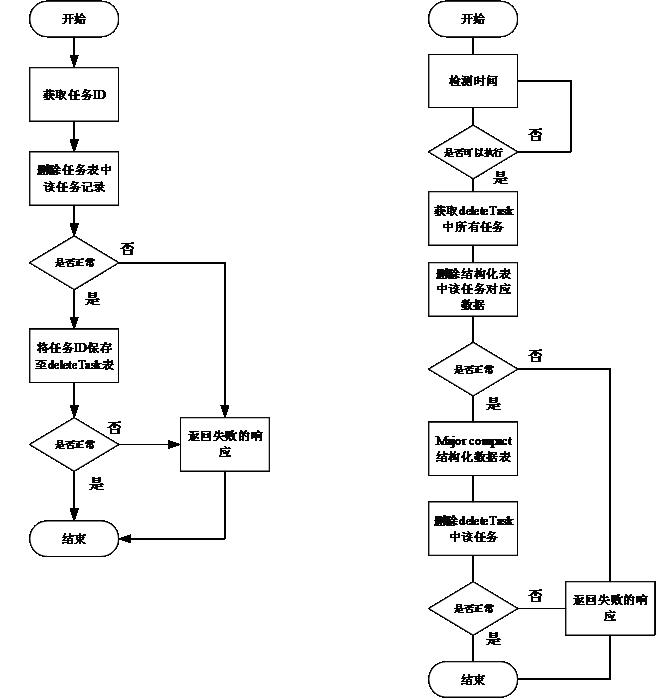{kind=link}
檢索、查詢、刪除 HBase 資料表中的資料本身存在大量的關聯性,需要檢視 HBase 資料表的原始碼才能確定導致檢索效能瓶頸的根本原因及最終解決方案。
結束語
HBase 資料庫的使用及檢索優化方式均與傳統關係型資料庫存在較多不同,本文從資料表的基本定義方式出發,通過 HBase 自身提供的 API 訪問方式入手,舉例說明優化方式及注意事項,最後通過例項來驗證優化方案可行性。檢索效能本身是資料表設計、程式設計、邏輯設計等的結合產物,需要程式設計師深入理解後才能做出正確的優化方案。
相關文章
- HBase資料庫效能調優OW資料庫
- HBase最佳實踐-讀效能優化策略優化
- 資料庫效能優化2資料庫優化
- 資料庫的檢索語句資料庫
- 資料庫效能優化有哪些方式資料庫優化
- Elasticsearch 億級資料檢索效能最佳化案例實戰!Elasticsearch
- 資料庫效能優化-索引與sql相關優化資料庫優化索引SQL
- 學術檢索資料庫總結資料庫
- 資料檢索
- 時序資料庫的秘密 —— 快速檢索資料庫
- 1.2.9. 任務9:資料庫效能優化資料庫優化
- Part II 診斷和優化資料庫效能優化資料庫
- openGausspostgreSQL資料庫效能檢視SQL資料庫
- 桌面端前端效能優化策略前端優化
- 資料庫優化 - SQL優化資料庫優化SQL
- 資料庫的這些效能優化,你做了嗎?資料庫優化
- Oracle效能優化-資料庫CPU使用率100%Oracle優化資料庫
- 後端思維之資料庫效能優化方案後端資料庫優化
- Django資料庫效能優化之 - 使用Python集合操作Django資料庫優化Python
- Spark效能優化:優化資料結構Spark優化資料結構
- Hbase優化優化
- 資料庫優化資料庫優化
- MySQL-檢索資料MySql
- 「MySQL」高效能索引優化策略MySql索引優化
- 效能優化之資料庫篇5-分庫分表與資料遷移優化資料庫
- 資料庫效能優化之冗餘欄位的作用資料庫優化
- 效能優化資料庫篇-從單機到叢集優化資料庫
- 最新IP資料庫 儲存優化 查詢效能優化 每秒解析上千萬資料庫優化
- PostgreSQL一複合查詢SQL優化例子-(多個exists,範圍檢索,IN檢索,模糊檢索組合)SQL優化
- AI Agent實戰:智慧檢索在Kingbase資料庫管理中的優勢應用AI資料庫
- 資料庫優化SQL資料庫優化SQL
- MySQL資料庫優化MySql資料庫優化
- MySQL-12.資料庫其他調優策略MySql資料庫
- 前端效能優化 —— 移動端瀏覽器優化策略前端優化瀏覽器
- Python_json資料檢索與定位之jsonPath類庫PythonJSON
- 效能優化之資料庫篇2-事務與鎖優化資料庫
- 我所知道的 Web 效能優化策略Web優化
- 前端效能優化之HTTP快取策略前端優化HTTP快取
- 全文檢索庫 bluge