在使用sklean處理一個機器學習例項時,可能會經過資料縮放、特徵合併以及模型學習擬合等過程;並且,當問題更為複雜時,所應用到的演算法以及模型則較為繁雜。
與此同時,經過實踐發現,在忽略一些細節的前提下,可以通過將這些資料處理步驟結合成一條演算法鏈,以更加高效地完成整個機器學習流程;由此,管道(pipeline)概念與機制應運而生。
pipeline概念
所謂管道,即由一系列資料轉換步驟或待擬合模型(如果有,則模型必須處於管道末端)構成的加工鏈條。
下面以例項釋之:
未使用管道(pipeline)前

從上圖小例項中可以看出,程式中著重有兩個資料處理流程,一個是資料縮放MinMaxScaler(),另一個是模型擬合svm.fit(X_train_scaled, y_train),並且兩個步驟具有明顯的先後順序,還是分開操作。
使用管道(pipeline)後

從上圖中可以看出,程式將之前的兩個步驟結合到一個管道(pipe)中,此後只需將訓練資料與測試資料流經管道,則相應的資料轉換和模型擬合與應用流程會更加高效且簡潔地完成。
為什麼使用管道
可能有同學指出,管道只是能簡化程式碼,但也不是缺其不可。實際上,管道的作用不僅在於簡化程式碼,更在於一些關鍵的資料轉換步驟需要管道機制加持,比如交叉驗證。
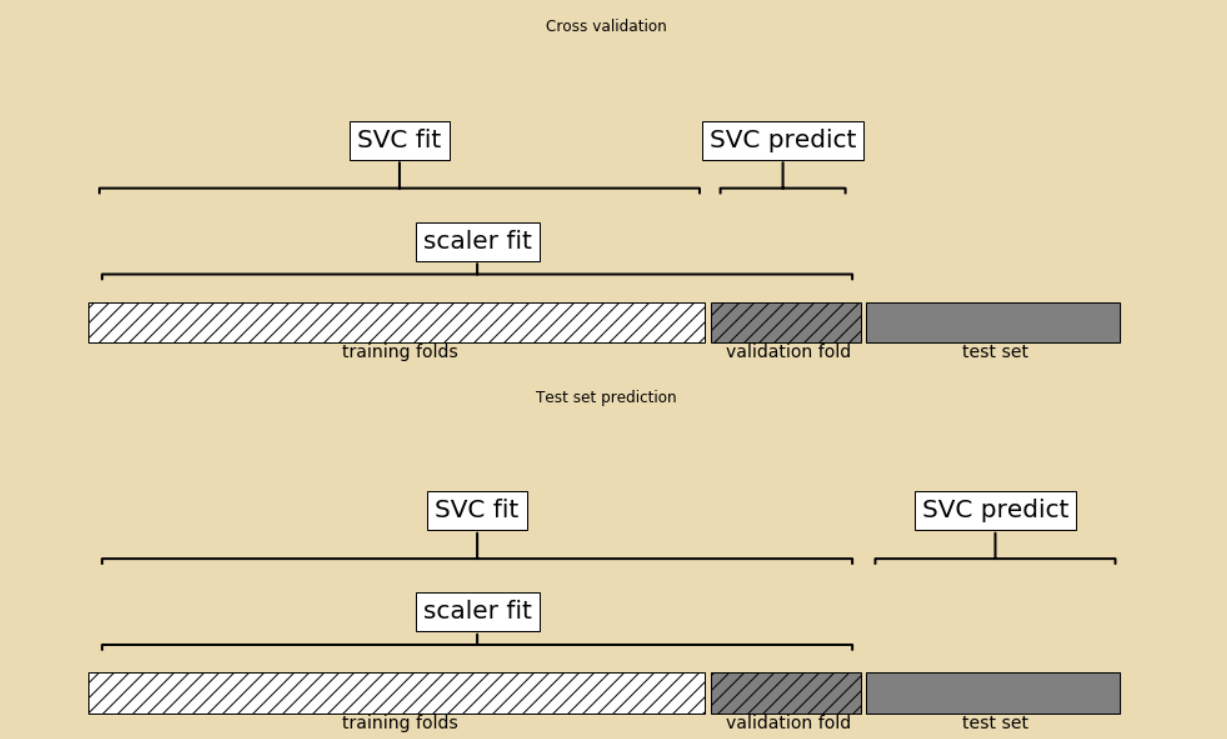
看下圖,是使用傳統處理流程進行交叉驗證的圖示;
可以看到,在圖的上半部分表示交叉驗證區域中,進行資料縮放處理時,同時用到了訓練資料與驗證資料,但是這是不符合要求的;
即使是驗證資料的縮放,也要使用經訓練資料擬合過後的MinMaxScaler(),而驗證資料本身不應該參與到MinMaxScaler()擬閤中,這樣會洩露驗證資料包含的資訊,從而導致驗證結果偏離實際。
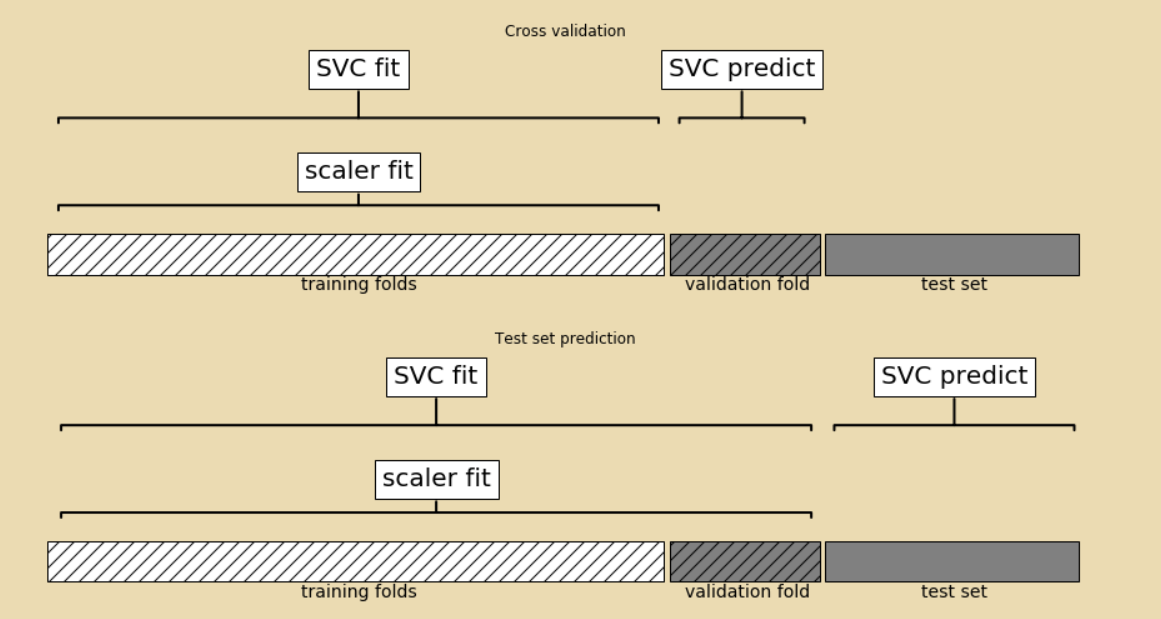
所以,符合要求的交叉驗證圖示應類似於下圖
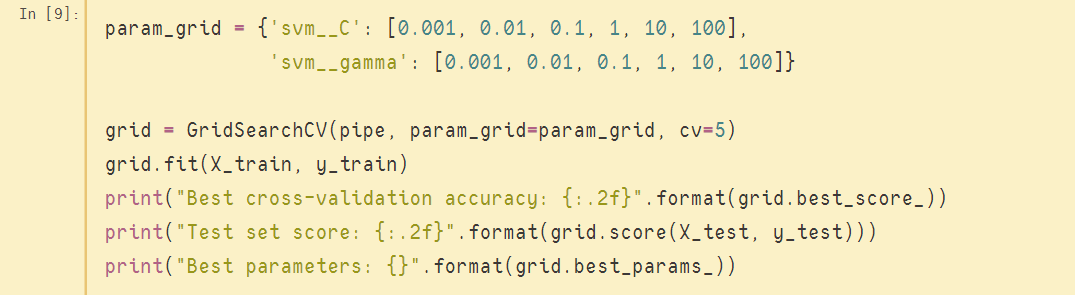
如果要手動實現上述劃分是異常麻煩的,因為需要人工干預每一次的交叉驗證操作;但如果用到pipeline,則實現的程式碼非常簡潔,只不過把網格搜尋的估計器置換成構建的管道(pipe),部分關鍵程式碼如下圖: