AF_XDP在B站CDN節點QUIC閘道器的應用和落地
01 背景
目前B站已在自建影片CDN下行中全量部署了基於QUIC和HTTP/3協議的閘道器服務(以下簡稱QUIC閘道器)。和TCP閘道器相比,QUIC閘道器在影片首幀、卡頓率以及載入失敗率等常見的QoE/QoS指標方面都有不錯的收益。另一方面,由於QUIC使用了更復雜的協議頭和解析規則,此外Linux核心對UDP收發包的效能也不甚理想,這些方面都使得QUIC佔用了更多的CPU負載,最終導致了更多資源成本的消耗。
為了給B站使用者提供更穩定流暢的影片觀看體驗,同時降低成本,網路協議組團隊透過技術選型,排除了DPU方案,決定使用AF_XDP技術來最佳化QUIC閘道器的收發包效率,減少CPU負載。
02 關於AF_XDP
2.1 概念
介紹AF_XDP,要從BPF說起。在Linux核心中,BPF(BSD Packet Filter)是一種高效靈活的類似虛擬機器的工具,能夠以安全的方式在不同的鉤點執行使用者注入到核心的位元組碼。它提供了一種過濾包的方法,並且避免了從核心空間到使用者空間的無效的資料包複製行為。2013年的時候,Alexei Starovoitov對BPF進行了改造,在功能和效能方面有所改良,這就是eBPF(extended BPF)。
eBPF中包含許多鉤子,因此它可以用於Linux核心中許多子系統中,而XDP就是Linux網路資料處理的一個eBPF hook點。XDP全稱叫做eXPress Data Path,即快速資料路徑,能夠在網路資料包到達網路卡驅動時對其進行處理。
XDP有三種執行模式,分別是generic模式、native模式以及offload模式。其中native模式下,XDP程式掛載在驅動接收路徑上,是最傳統的XDP的模式,需要驅動的支援,目前主流的網路卡驅動,如ixgbe,i40e等都已實現了native XDP;generic是核心模擬出來的一種通用模式,不需要驅動支援,但是XDP掛載點更靠後,在核心協議棧接受路徑上,效能不如native;offload則是直接在網路卡中對XDP程式進行處理,掛載點更靠前,是效能優秀的模式,但是需要硬體特別支援。
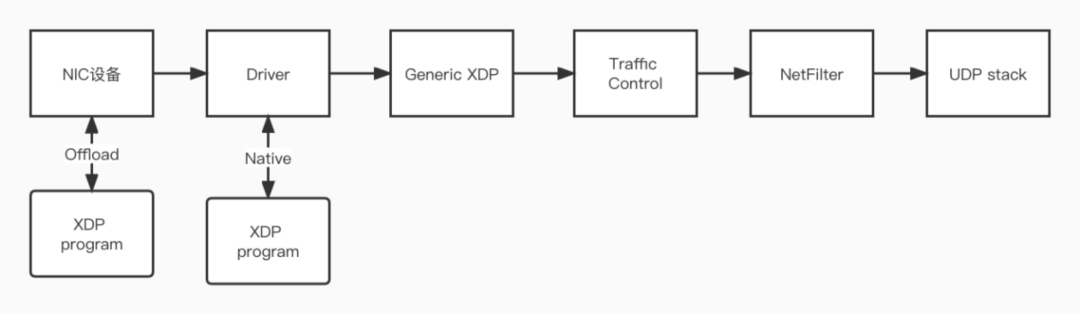
AF_XDP是為高效能資料包處理而生的地址族。在XDP程式中使用XDP_REDIRECT這樣的返回動作,可以使用bpf_redirect_map()將資料幀重定向其他使能了XDP的網路卡,而AF_XDP socket能夠將資料幀重定向到使用者空間的記憶體緩衝區中。
2.2 工作流程
AF_XDP的核心元件主要分為兩個部分:AF_XDP socket和UMEM。其中AF_XDP socket(xsk)的使用方法和傳統的socket類似,AF_XDP支援使用者透過socket()來建立一個xsk。每個xsk包含一個RX ring和TX ring,其中收包是在RX ring上進行的,發包則是在TX ring上面執行。使用者也是透過操作RX ring和TX ring來實現網路資料幀的收發。UMEM是由一組大小相等的資料記憶體塊所組成的。UMEM中每個資料塊的地址可以用一個地址描述符來表述。地址描述符被定義為這些資料塊在UMEM中的相對偏移。使用者空間負責為UMEM分配記憶體,常用的方式是透過mmap進行分配。UMEM也包含兩個ring,分別叫做FILL ring和COMPLETION ring。這些ring中儲存著前面所說的地址描述符。
在收包前,使用者將收包的地址描述符填充到FILL ring,然後核心會消費FILL ring開始收包,完成收包的地址描述符會被放置到xsk的RX ring中,使用者程式消費RX ring即可獲取接收到的資料幀。在發包時,使用者程式向UMEM的地址描述符所引用的記憶體地址寫入資料幀,然後填充到TX ring中,接下來核心開始執行發包。完成發包的地址描述符將被填充到COMPLETION ring中。
為了讓xsk成功地從網路卡中收到網路資料幀,需要將xsk繫結到確定的網路卡和佇列。這樣,從特定網路卡佇列接收到的資料幀,透過XDP_REDIRECT即可重定向到對應已繫結的xsk。
03 利用AF_XDP最佳化QUIC閘道器效能
3.1 QUIC協議效能問題
QUIC是google制定的一種基於UDP的低延時網路傳輸協議。基於QUIC協議的HTTP/3是新一代HTTP協議。目前我們團隊已經在影片下行邊緣CDN上全量部署了基於HTTP/3的QUIC閘道器:quic-server。在實踐過程中,我們發現由於QUIC協議棧本身執行在使用者態,協議邏輯複雜,加之核心對UDP的收發包效率遠不如TCP,所以quic-server會使用更多的cpu負載。這不僅增加了服務的執行成本,在B站訪問高峰期時還會有機器資源不足的風險。
3.2 基於AF_XDP的QUIC閘道器架構
對於quic-server來說,效能最佳化的重中之重就是UDP報文的收發。在這個過程中,我們也使用了不同的最佳化方式,包括UDP發包時使用sendmmsg來代替sendmsg,以及使用GSO來最佳化發包方式。這些方案一定程度上能夠降低quic server的cpu負載,但是效果有限(10%左右),究其原因還是由於這些方案都是基於Linux核心的解決方案。例如我們使用的GSO實際上屬於generic的GSO,還是在核心中實現的一種方案。如果想要進一步提升我們的程式收益,是否可能有kernel bypass的解決方案可用呢?於是,AF_XDP就進入了我們的視線。
AF_XDP是一種半bypass的網路收發包機制。之所以叫做“半bypass”,是因為它的工作流程中還是需要核心的協助,並不能完全繞過核心,但是它的收發報的路徑可以做到對核心協議棧的繞開。前文我們也介紹了AF_XDP的概念和工作流程,這裡我們很容易用一句話來概括quic server如何使能AF_XDP:quic server採用AF_XDP來進行UDP報文的收發來提升其收發報效能,降低CPU負載。
下圖是quic server和AF_XDP具體結合起來的一個網路資料走向示意圖:

上圖主要展示了網路資料的接收流轉路徑。資料幀從網路卡到達驅動處理位置時,會執行掛載的XDP程式。XDP程式可由我們自行編寫,利用XDP程式我們可以對資料幀進行過濾,即把要發給quic-server的HTTP/3請求所對應的資料幀重定向到quic-server維護的xsk中。
下圖展示的是quic-server經過AF_XDP改造之後的架構圖:
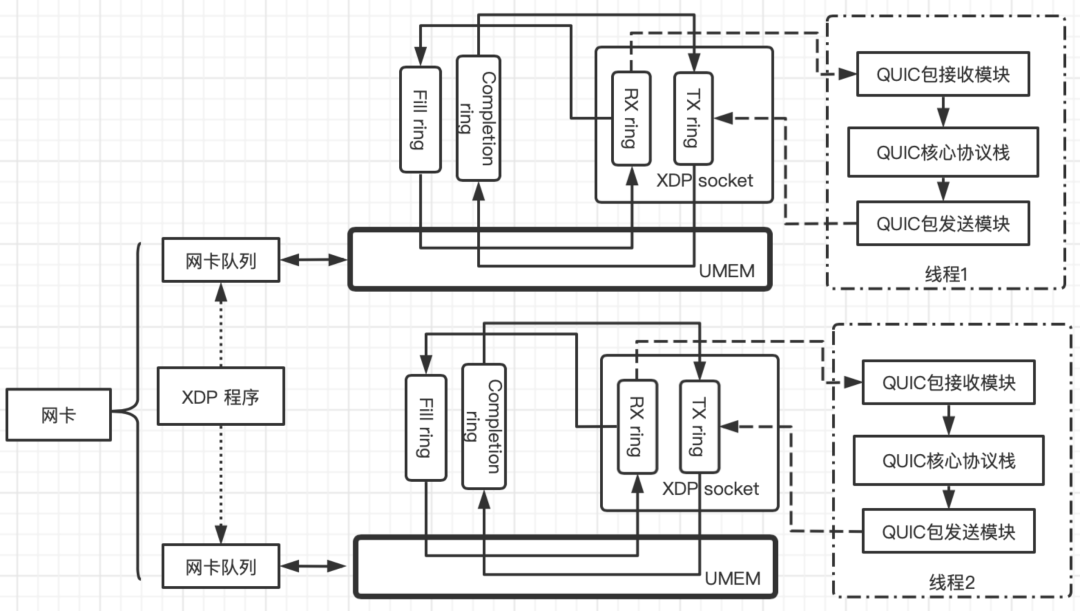
quic-server依然是多執行緒的架構,每個執行緒獨立管理自己的xsk,每個xsk透過xskmap與AF_XDP ring進行繫結。這樣驅動處理資料時,透過XDP程式就將特定佇列的資料幀重定向到特定的xsk,也就可以透過quic-server特定的執行緒進行資料的處理,儘可能保證quic-server多執行緒併發處理資料包的效能。
下面簡要介紹XDP程式的邏輯:

上述程式碼片段是處理網路資料幀的主邏輯。根據TCP/IP協議分層體系,對資料幀進行解封裝操作,檢查資料幀的網路層協議,對於IPv4或IPv6資料方進行下一步處理,其他型別則返回XDP_PASS,這意味著非IPv4或IPv6的資料幀後續仍由核心協議棧進行處理。

handle_ipv4函式對ipv4報文進行處理,繼續解封裝,過濾出傳輸層協議為UDP且目的埠為expect_udp_dport的資料幀,expect_udp_dport即為quic-server繫結的udp埠。最後透過bpf_redirect_map將資料幀重定向到佇列繫結的xsk中。quic-server透過epoll管理xsk的讀事件,透過消費Rx ring獲取到所收到的包,實現了從xsk讀取資料的過程。至此,透過AF_XDP,quic-server完成了網路資料的讀取,這些資料通常包含的是公網HTTP/3請求。
在quic-server內部,UDP報文管理主要是由PacketWriter/BatchWriter模組負責的。我們實現了一個XskPacketWriter/XskBatchWriter,由它來對xsk的寫資料進行管理。基於效能考慮,我們最終採用批次寫的XskBatchWriter進行QUIC資料包的寫管理。
架構圖中QUIC包傳送模組即為quic-server的XskBatchWriter,透過epoll將xsk的寫事件管理起來,當xsk可寫時,透過操作xsk的TX ring進行寫操作,待網路卡驅動完成資料幀的傳送之後,由XskBatchWriter對Completion ring中的地址描述符進行回收。
3.3 效能分析
在不啟用AF_XDP時,quic-server使用核心協議棧UDP socket進行UDP資料的讀寫。這種情況下,UDP資料的收發需要經過Linux核心協議棧,呼叫鏈路較長,同時還涉及到核心態和使用者態的互動,存在比較大的效能開銷。啟用AF_XDP後,quic-server的效能可以得到明顯的提升,具體原因在於:
利用native XDP模式,在驅動早期處理資料時,即可將資料重定向到使用者態維護的xsk中,呼叫鏈路明顯縮短。反之,走核心協議棧的UDP收發報呼叫鏈路較長。
native XDP模式支援ZeroCopy,即驅動維護的RX ring和TX ring所指向的記憶體區域可以直接對映到使用者空間,此空間通常由使用者程式建立的UMEM來維護。這直接減少了資料的記憶體複製的次數,提升了收發包效率。反之,核心協議棧需要構建sk_buff對資料包文進行處理,還需要複製到使用者空間。
3.4 收益
目前基於AF_XDP的QUIC閘道器已經在自建CDN下行中全量部署。我們專門就CPU負載這一指標進行了壓力測試和上線效果對比。單執行緒壓測結果表明,使用AF_XDP方案,在服務同等使用者頻寬的前提下,CPU負載比非AF_XDP方案低50%左右。進一步地,我們又在多執行緒,多range請求的條件下再次進行了兩組壓測,壓測結果如表1和表2所示。兩組測試的差異在於第二組測試採用的請求range範圍更大。
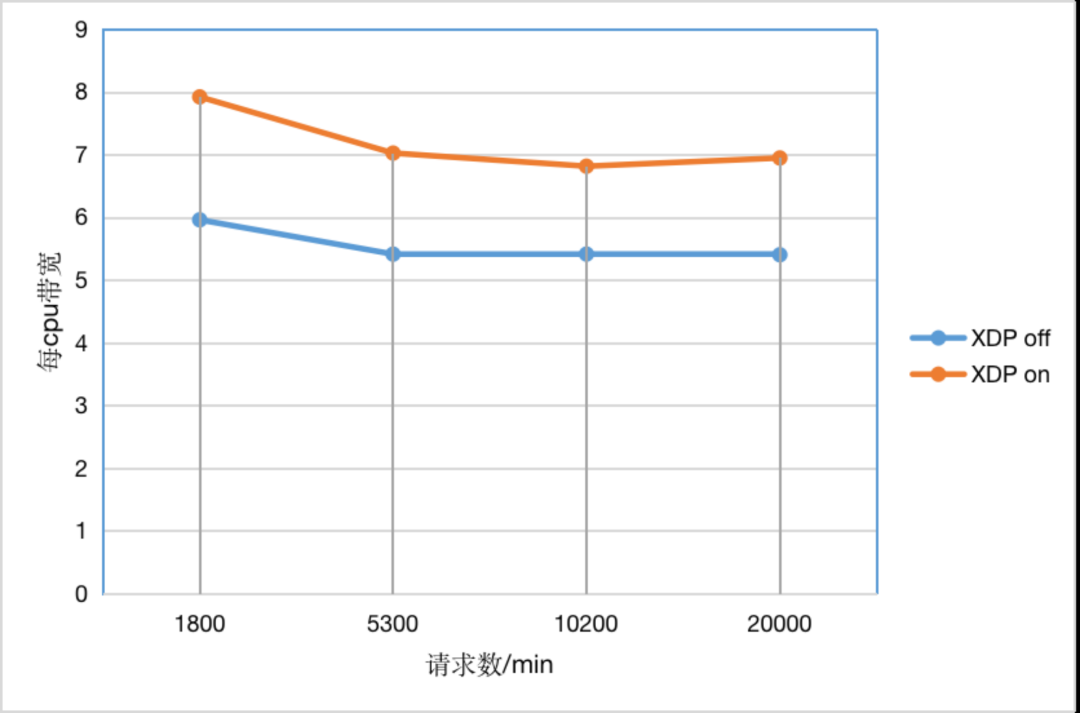
表1 壓測對比結果第一組
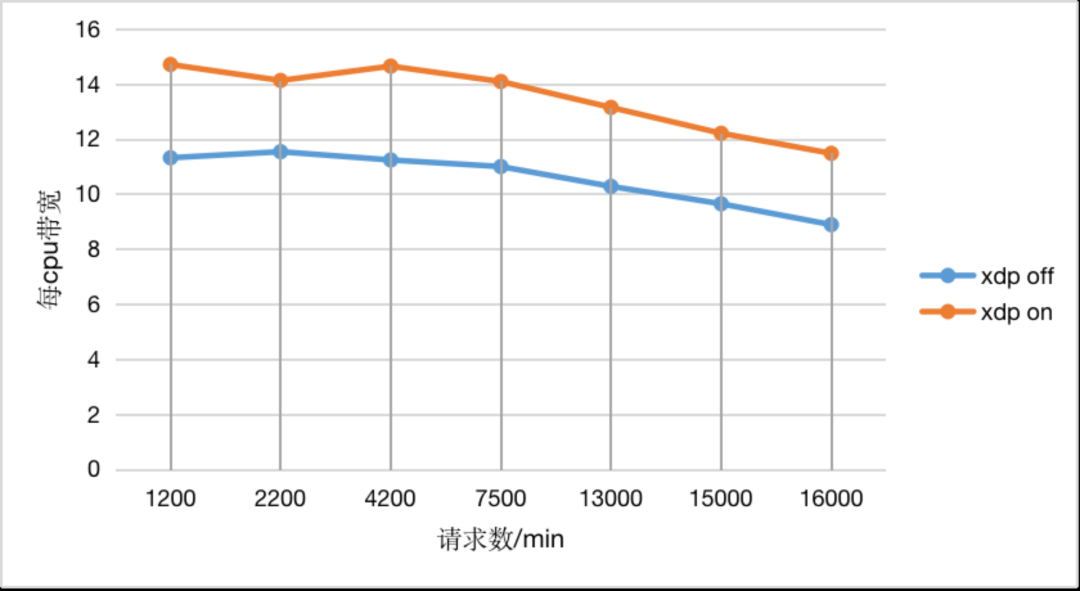
表2 壓測對比結果第二組
可以明顯看到,使用AF_XDP,在同等CPU load的前提下可以服務更多的使用者頻寬。
接下來,在同叢集兩臺機器上進行對比測試,一臺開啟AF_XDP,一臺關閉AF_XDP,對比效果如圖所示。

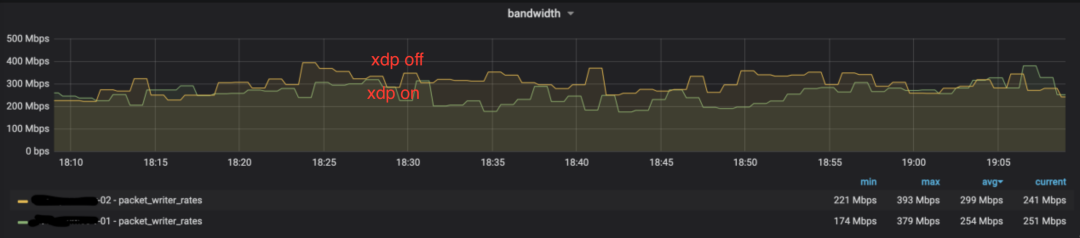
表3 相似平均頻寬,開啟xdp和不開啟xdp,cpu的消耗對比
結論:
壓測結果表明xdp模式下的最大頻寬近9Gbps;非xdp模式下的最大頻寬接近7Gbps(表1,表2)。
xdp模式下的每頻寬CPU比非xdp模式下提升25%~30%左右(表3)
04 未來展望
目前AF_XDP已在自建nCDN的QUIC閘道器上全量上線,且獲得了較大的收益。除了進一步最佳化AF_XDP的效能之外,我們未來的計劃是:
開源AF_XDP的模組程式碼到bilibili/quiche倉庫中。
開發基於AF_XDP的效能分析工具。目前,我們在AF_XDP使能QUIC閘道器之後,通常是在閘道器程式中統計程式的執行狀態,而通用的相關工具如tcpdump、iftop等都已失效。因此,需要完善相關周邊工具,幫助我們更好地瞭解程式執行狀態並針對性地對程式進行最佳化。
賦能AF_XDP到更多業務場景中,如RTP, datachannel等基於UDP協議的傳輸協議。
來自 “ 嗶哩嗶哩技術 ”, 原文作者:陳建&劉宏強;原文連結:http://server.it168.com/a2022/1227/6782/000006782811.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- Janusec應用安全閘道器(WAF閘道器)
- Hystrix斷路器在微服務閘道器中的應用微服務
- CDN閘道器超大range計算方法
- 工業智慧閘道器的功能和應用場景
- 應用閘道器的演進歷程和分類
- AI閘道器在應用整合中起到什麼作用?AI
- sbc(六) Zuul GateWay 閘道器應用ZuulGateway
- SpringCloud系列之閘道器(Gateway)應用篇SpringGCCloudGateway
- PLC和工業閘道器在物聯網數控系統有何應用?
- 長連線閘道器技術專題(八):B站基於微服務的API閘道器從0到1的演進之路微服務API
- 工業智慧閘道器在汙水治理有何智慧應用場景?
- LoRa無線閘道器在工業溫溼度遠端監測的應用
- 微服務閘道器Spring Cloud Gateway的應用實戰微服務SpringCloudGateway
- 什麼是閘道器?閘道器的作用是什麼,閘道器的作用詳解
- 普元EOS 8閘道器設計及應用
- SKYLAB:藍芽閘道器應用場景案例分析藍芽
- 美暢影片接入閘道器(VGate)的應用場景分析
- Ceph物件閘道器,多區域閘道器物件
- Profinet轉ModbusTCP閘道器模組的配置與應用詳解TCP
- 【工業閘道器應用方案】農村汙水處理站線上監控系統
- 【知識分享】安全閘道器的功能特點
- 體驗用yarp當閘道器
- Profibus轉Modbus閘道器在智慧化水處理系統最佳化改造的應用
- 基於Linux和IPSec的VPN閘道器Linux
- 淺析阿里雲API閘道器的產品架構和常見應用場景阿里API架構
- 演算法閘道器影片分析閘道器演算法定製:適合影片分析的深度學習架構及影片分析原理和應用演算法深度學習架構
- ELB Ingress閘道器助力雲原生應用輕鬆管理流量
- LoRa閘道器是什麼?有什麼應用場景?
- Gateway(閘道器)的概述Gateway
- 閘道器GatewayGateway
- gateway 閘道器Gateway
- 微服務技術棧:API閘道器中心,落地實現方案微服務API
- 4G無線數採閘道器在水庫雨情遠端監測中的應用
- API 閘道器的10個最常見用例API
- 在樹莓派上搭建智慧家居閘道器樹莓派
- DWDM技術在B站基礎工程的落地實踐之路
- Centos 7 新增ip地址和閘道器CentOS
- 振動感測器資料採集閘道器的功能及應用場景