jmeter學習指南之引數化CSV Data Set Config
今天大家一起來學習一下引數化的一個重要工具,我們在寫指令碼時,經常要用到引數化,而實現引數化最常用的方法之一就是使用CSV Data Set Config元件,使用方便,功能強大。
簡單的使用方法估計大家都會,或者說很容易就會了,但是,如果說是比較複雜的配置,估計就有很多人會被繞暈了(我剛開始也經常暈~),今天我們們就詳細看看,怎麼才能不暈!哈哈
首先來看一眼長啥樣,相信大家都比較熟悉

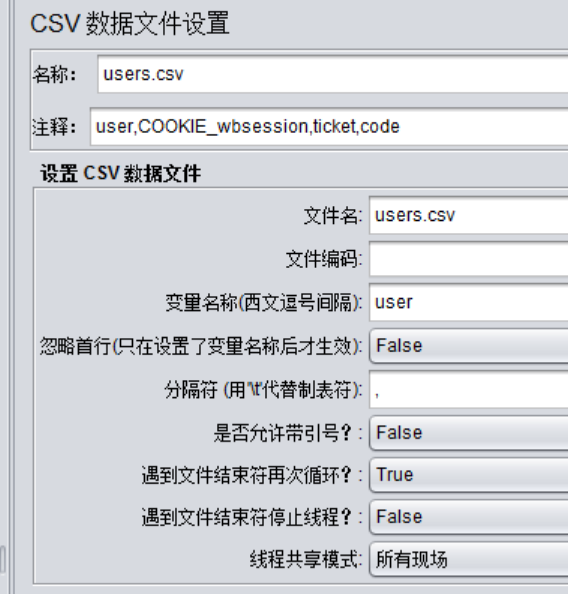
該元件的作用:
從檔案中讀取變數值,用於變數的引數化,可設定多種讀取方式。
各填寫項說明:
1、名稱、註釋:元件的名稱及註釋,可自定義
2、Config the CSV Data Source:配置資料來源
1)Filename:csv檔案的名稱
注意:這裡要包括檔案的路徑,在4.0版本中可以點選右側的瀏覽按鈕選擇檔案,會自動帶上檔案的絕對路徑;
另外,當csv檔案在jmeter的bin目錄或指令碼目錄時,只需給出檔名即可;
使用相對路徑時,jmeter預設先去bin目錄下查詢,然後去指令碼目錄下查詢;
2)File encoding:csv檔案編碼
預設使用當前作業系統的編碼格式;
如果檔案中包含中文亂碼時,可嘗試utf-8、gbk等;
3)Variable Names(comma-delimited):
csv檔案中各列的名字(有多列時,用英文逗號隔開列名);
名字順序要與內容對應,這個變數名稱是在其他處被引用的,所以為必填項。
4)Delimiter(use “t” for tab):csv檔案中的分隔符(用”t”代替tab鍵)
一般情況下,分隔符為英文逗號,保持預設就行
5)Allow quoted data?:是否允許資料內容加引號
6)Recycle on EOF?:
到了檔案尾是否迴圈,True—繼續從檔案第一行開始讀取,False—不再迴圈;
此項與下一項的設定為互斥關係,即true-false,或false-true;
7)Stop thread on EOF?:
到了檔案尾是否停止執行緒,True—停止,False—不停止;
注意:當Recycle on EOF設定為True時,此項設定無效。
8)Sharing mode:共享模式
All threads –所有執行緒,此元件作用範圍內的所有執行緒共享csv資料,每個執行緒依次讀取csv資料,互不重複;
Current thread group—當前執行緒組,在此元件作用範圍內,以執行緒組為單位,每個執行緒組內的執行緒共享csv資料,依次讀取資料,互不重複;
Current thread—當前執行緒,在此元件作用範圍內,每次迴圈中所有執行緒取值一樣;
下面重點分析一下Allow quoted data和Sharing mode:
1、Allow quoted data?:是否允許帶雙引號的資料
此項實際是控制csv檔案中的雙引號是否為有效字元;
如果資料帶有雙引號且此項設定TRUE,則會自動去掉資料中的引號使能夠正常讀取資料,且即使引號之間的內容包含有分隔符時,仍作為一個整體而不進行分隔;
如果資料帶有引號且此項設定為FALSE,則讀取資料包錯;
如果希望雙引號欄位中間再包含雙引號,則需要加兩個雙引號來代表單個雙引號。(啊啊啊,太拗口了!!!)
如下圖所示,此項設定為true時,"2,3"-->2,3;"4""5"-->4"5

2、Sharing mode:共享模式
(1)All threads:針對所有執行緒組的所有執行緒,每個執行緒取值不一樣,依次取csv檔案中的下一行。
假如說有執行緒1到執行緒n (n>1),執行緒1取了一次值後,執行緒2取值時,取到的是csv檔案中的下一行,即與執行緒1取的不是同一行。不管是單個執行緒組還是多個執行緒組,每個執行緒都是依次取下一行。需要注意的是,當一個執行緒組中有多個請求時,對於每個執行緒來說,在一次迴圈中每個請求的取值是一樣的。
下面舉例說明:
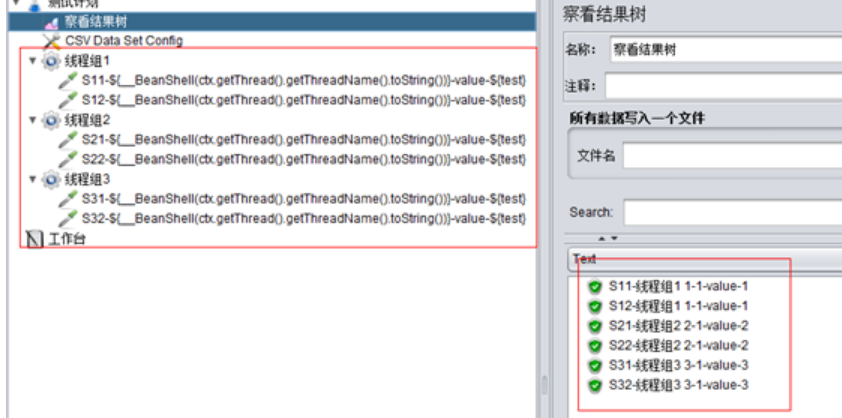
A、設定執行緒組1、2、3分別為1併發、1次迴圈,且各執行緒組按順序執行:
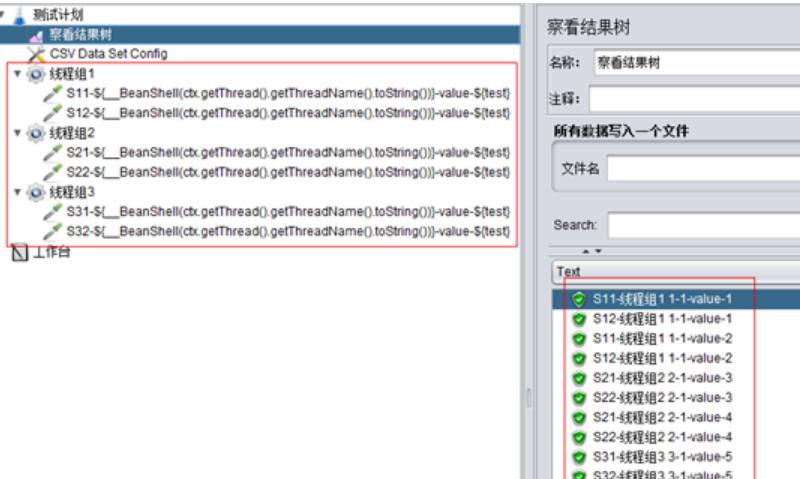
B、設定執行緒組1、2、3分別為1併發、2次迴圈,且各執行緒組按順序執行:
C、設定執行緒組1、2、3分別為2併發、1次迴圈,且各執行緒組按順序執行:
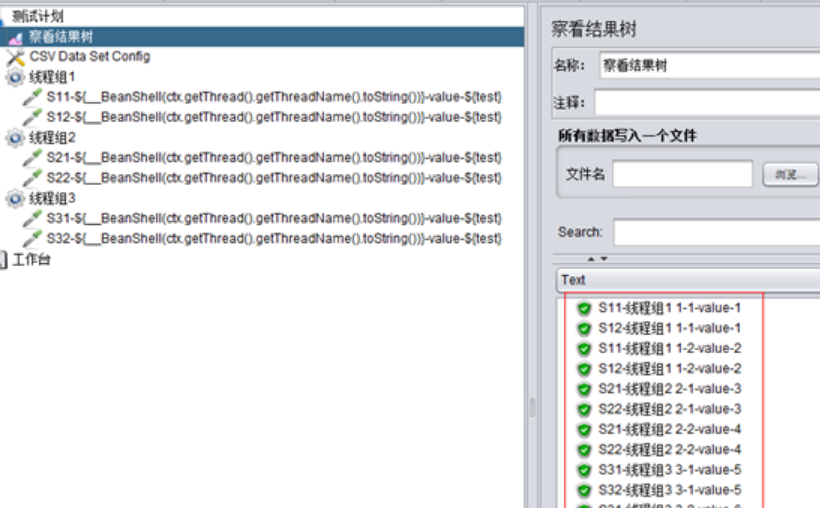
大家可以仔細比較一下上圖和上上圖的區別,乍一看貌似是一樣的,但是實際卻是不同的執行緒,怎麼區分不同執行緒呢?
可以使用一個函式來判斷:
${__BeanShell(ctx.getThread().getThreadName().toString())}
這個函式可以輸出類似這樣的內容:“執行緒組1 1-2“,前面是當前執行緒組的名稱-執行緒組1,後面是執行緒組id,然後是執行緒id,現在再比較上面兩圖中,發現是執行緒id不一樣。
總體來說就是,在All Threads模式下,併發數和迴圈數都會讀取不同的csv資料,但是同一執行緒組內的多個sampler總是取相同的值。
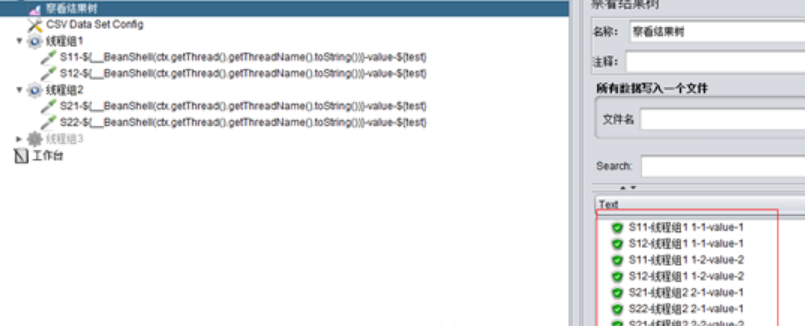
(2)Current thread group:當前執行緒組,
取值情況是:以執行緒組為單位,每個執行緒組內的執行緒都會從第1行開始取值並依次往下進行取值。
舉例如下:
A、設定執行緒組1、2均為2併發、1迴圈:
(3)Current thread:當前執行緒。
取值情況是:每個執行緒都會從第1行開始取值並依次往下進行取值,在同一次迴圈中所有的執行緒取值一樣。
舉例如下:
A、設定執行緒組1、2均為2併發、1迴圈:

上面兩個圖看起來好像是一樣的呀?再仔細看一下,後面的test引數取值是不同的。
為什麼不同呢?本來想認真的解釋一番,但是組織了很久的語言,還是感覺沒說清楚。
這一塊的邏輯是“只可意會,不可言傳”,必須要靠自己親自實驗,慢慢體會才行。
最後,給大家一個小作業:
如何透過設定Sharing moder的方法來實現多個sampler中的引數可以依次不重複的取同一個csv檔案中的值?
jmeter影片:
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69942496/viewspace-2654041/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- jMeter 裡 CSV Data Set Config Sharing Mode 的含義詳解JMeter
- CSV Data Set Config 引數化怎麼從多個檔案中讀取資料?
- jmeter使用csv進行引數化(一)JMeter
- jmeter使用csv進行引數化(二)JMeter
- 『動善時』JMeter基礎 — 22、JMeter中實現引數化(CSV)JMeter
- jmeter學習指南之管理CookiesJMeterCookie
- jmeter學習指南之關聯JMeter
- jmeter學習指南之聚合報告JMeter
- jmeter 引數化 csv外掛的讀取檔案 bin目錄JMeter
- jmeter學習指南之詳解jmeter執行緒組JMeter執行緒
- 軟體測試學習資料——Jmeter引數化2JMeter
- 軟體測試學習資料——Jmeter引數化1JMeter
- jmeter學習指南之Beanshell Sampler 常用方法JMeterBean
- jmeter學習指南之操作 mysql 資料庫JMeterMySql資料庫
- jmeter學習指南之常用函式的使用JMeter函式
- jmeter學習指南之最佳化指令碼JMeter指令碼
- jmeter引數化介紹JMeter
- jmeter學習指南之原始碼匯入 IntelliJ IDEAJMeter原始碼IntelliJIdea
- jmeter學習指南之OOM和監聽器使用JMeterOOM
- 『動善時』JMeter基礎 — 25、JMeter引數化補充練習JMeter
- JMeter四種引數化方式JMeter
- Jmeter的指令碼引數化JMeter指令碼
- jmeter學習指南之結果分析-圖形圖表JMeter
- jmeter學習指南之16個邏輯控制器JMeter
- jmeter學習指南之響應斷言和beanshell斷言JMeterBean
- 引數匹配模型——Python學習之引數(二)模型Python
- Python學習之引數(一)Python
- 聊一聊Jmeter的引數化JMeter
- jmeter學習指南之深入分析跨域傳遞cookieJMeter跨域Cookie
- jmeter學習指南之非GUI命令列執行詳解JMeterGUI命令列
- 引數匹配順序——Python學習之引數(三)Python
- Python學習之set集合Python
- 機器學習之超引數機器學習
- Jmeter模板化引數併發測試JMeter
- Jmeter基礎004----增加引數化JMeter
- jmeter學習指南之Beanshell 呼叫 java 程式碼的三種方式JMeterBeanJava
- jmeter學習指南之Boundary Extractor和正規表示式提取器JMeter
- jmeter 引數理解JMeter