成千上萬的資料科學新手會在不知不覺中犯下一個錯誤,這個錯誤可以一手毀掉你的機器學習模型,這並不誇張。你知道是什麼嗎?
我們現在來討論應用機器學習中最棘手的障礙之一:過擬合(overfitting)。
在本文中,我們將詳細介紹過擬合、如何在模型中識別過擬合,以及如何處理過擬合。最後你會學會如何一勞永逸地處理這個棘手的問題。你將讀到下面這些內容:
過擬合的例子
訊號與噪音
擬合優度
過擬合和欠擬合
如何檢查過擬合
如何避免過擬合
過擬合的例子
如果我們想根據一個學生的簡歷預測她是否會獲得面試機會。現在,假設我們從10000份簡歷的資料集及其結果中訓練模型。接下來,我們在原始資料集上嘗試這個模型,它預測結果的準確率達到99%……哇!但這是個壞訊息。當我們在簡歷的新(“沒見過的”)資料集上執行模型時,我們只能獲得50%的準確度…
我們的模型從訓練資料到新資料的泛化能力並不好。
這被稱為過擬合,也是機器學習和資料科學中的常見問題。事實上,過擬合在現實世界中也一直在發生著。看看這樣的新聞報導:
 訊號與噪音
訊號與噪音
您可能聽說過Nate Silver著名的《訊號與噪音》一書。在預測建模中,您可以將“訊號”視為希望從資料中學習到的真正底層模式。另一方面,“噪音”指的是資料集中無關的資訊或隨機性。例如,假設您正在建模兒童身高與年齡的關係。如果您對大部分人口進行抽樣,您會發現一個非常明確的關係:

這就是是訊號。然而,如果你只能對當地的一所學校進行抽樣調查,這種關係可能會更加複雜。 它會受到異常值(比如,爸爸是NBA球員的孩子)和隨機性(例如在不同年齡段進入青春期的孩子)的影響。
“噪音干擾了訊號”
這成為機器學習的用武之地,一個執行良好的機器學習演算法能將訊號從噪聲中分離出來。
如果演算法過於複雜或靈活(例如,它有太多的輸入特性或它沒有適當的正則化),它最終可能“記住噪音”而不是找到訊號。
這個過擬合模型將基於這些噪聲進行預測。它將在訓練資料上表現得異常出色……但在新的、未見過的資料上表現得非常糟糕。
擬合優度

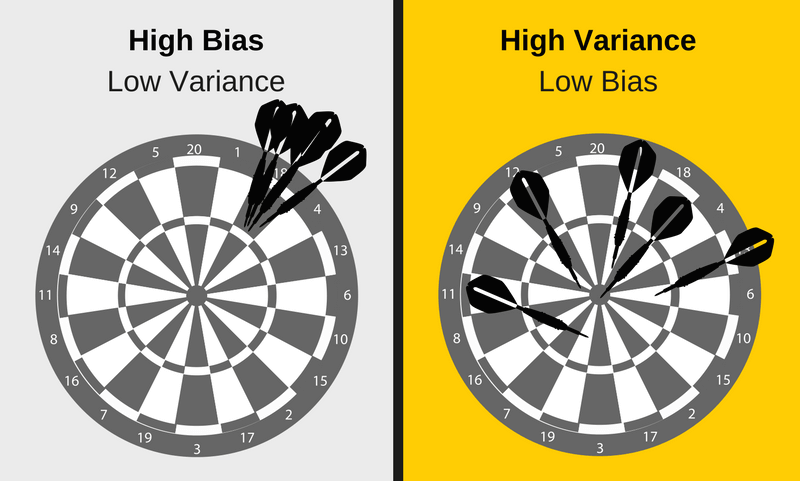
過擬合和欠擬合
偏差和方差都是機器學習中預測誤差的兩種形式。
通常,我們可以減少由偏差引起的誤差,但同時可能會增加由方差帶來的誤差,反之亦然。太簡單(高偏差)與過於複雜(高方差)之間的權衡是統計和機器學習中的關鍵概念,也是影響所有監督學習演算法的關鍵概念。
{kind=link}

如何檢查過擬合
過擬合以及機器學習的一個關鍵挑戰是,在我們實際測試之前,我們無法知道模型對新資料的執行情況。為了解決這個問題,我們可以將初始資料集拆分為單獨的訓練和測試子集。

這種方法可以估計出我們的模型在新資料上的表現。
如果我們的模型在訓練集上比在測試集中表現得好得多,那麼我們很可能會過擬合。
例如,如果我們的模型在訓練集上有99%的準確率,但在測試集上只有55%的準確率,那將是一個很危險的訊號。
另一個建議是從一個非常簡單的模型開始,以此作為基準。
然後,當您嘗試更復雜的演算法時,您將有一個參考基準來檢視額外的複雜性是否值得。這是奧卡姆剃刀試驗。如果兩個模型具有類似的效能,那麼通常應該選擇比較簡單的一個。
如何避免過擬合
檢查過擬合是有用的,但它不能解決問題。幸運的是,有幾個方法您可以嘗試。以下是一些最常用的過擬合解決方案:
交叉驗證
交叉驗證是預防過擬合的一個強有力措施。
將您的初始訓練資料拆分成多個資料集(類似於迷你火車),使用這些拆分子集來調整模型,這是一個聰明的想法。在標準的K-fold交叉驗證中,我們將資料劃分為K個子集,稱為“摺疊(folds)”。然後我們迭代地在K-1個摺疊上訓練演算法,同時使用剩餘的摺疊作為測試集。
交叉驗證允許您僅使用原始訓練集來調整超引數。這使您可以將測試集儲存為真正“未見過”的資料集,以便選擇最終模型。

使用更多資料
它不會每次都有效,但是使用更多資料進行訓練可以幫助演算法更好地檢測到訊號。
在早期的兒童身高與年齡建模的例子中,很明顯如何抽樣更多的學校將有助於您的模型。當然,情況並非總是如此。如果我們只是新增更多的噪聲資料,這種技術將無濟於事。這就是為什麼您應該始終確保您的資料是乾淨和相關的。
刪除無用特徵
有些演算法有內建的特徵選擇。 您可以通過刪除不相關的輸入特性來手動改進它們的通用性。
一種有趣的方法是通過描述每個特性是如何融入模型的。如果很難證明一些特性的存在合理性,說明這些特徵是沒必要的。
及時中止
當您迭代訓練學習演算法時,您可以度量模型的每次迭代的執行情況。
當迭代至一定次數之前,新的迭代會不斷改進模型。然而,在那之後,模型的泛化能力會隨著訓練資料開始過擬合而減弱。

現在,這種方法主要用於深度學習,而其他的方法(如正則化)更適合於經典的機器學習。
正則化
正則化是指人為地迫使模型變得更簡單的一系列技術。這個方法將取決於你使用的模型型別。例如,您可以修剪決策樹,在神經網路上使用dropout,或者在迴歸中向代價函式新增一個懲罰引數。
通常,正則化方法也是一個超引數,這意味著它可以通過交叉驗證進行調優。
整合學習
整合(Ensembling)是一種機器學習方法,用於將多個不同模型的預測組合在一起。
整合有幾種不同的方法,但最常見的兩種是:
Bagging:降低複雜模型過擬合的可能性。
它同時訓練大量“強大”的模型。
一個“強大”的模型是一個相對不受約束的模型。
然後將所有“強大”的模型結合在一起,以“平滑”他們的預測。
Boosting:改進簡單模型的預測能力。
它訓練大量“弱”的模型。
一個“弱”模型是一個受約束的模型(例如,你可以限制每個決策樹的最大深度)。
每個模型都專注於從之前的錯誤中學習。
然後把所有的弱學習者組合成一個強大的學習者。
雖然Bagging和Boosting都是整合方法,但它們從相反的方向解決問題。Bagging使用複雜的基礎模型,試圖“平滑”他們的預測,而Boosting使用簡單的基礎模型,並試圖“提高”他們的總複雜度。
原文連結:《機器學習中的過擬合》