基於知識圖譜的呼叫鏈分析精準化測試平臺
01 背景
傳統軟體測試技術主要基於測試人員對業務的理解,但由於經驗的侷限性、被測系統的複雜性以及與真實業務資料的差距,肯定存在測試不充分的情況,所以,雖然整個測試流程很規範,但最終軟體質量還是不盡如人意。而隨著分散式、微服務架構、大資料技術的出現,軟體越來越複雜,迭代越來越快,測試的挑戰性越來越大。測試人員急切的需要一套更加精確、高效的測試技術和方法。精準化測試技術就在這種背景下應運而生並快速發展。
精準化測試技術是一種可追溯的軟體測試技術,透過構建一套計算機測試輔助分析系統,對測試過程的活動進行監控,將採集到的監控資料進行分析,得到精準的量化資料,使用這些量化資料進行質量評價,利用這些分析資料可以促進測試過程的不斷完善,形成度量及分析閉環,實現軟體測試從經驗型方法向技術型方法的轉型。
02 定義
在對精準測試下定義之前我們先看幾個精準測試需要解決的問題:
如何刻畫和度量有限測試集合的充分性
如何挑選有限測試集合並充分執行
如何讓上述過程更加自動化、更加精準
那我們可以得到精準測試需要包含的幾個特性:
全不全:透過程式碼覆蓋率度量測試充分性
準不準:透過精準推薦代替人工進行變更影響範圍評估指導用例迴歸
快不快:精準推薦自動化&用例執行失敗快速定位等
然後我們可以將其定義為:精準測試是基於程式碼和用例關聯關係的測試充分性度量和提升手段之一。
03 實現思路
首先貼一張流程圖:
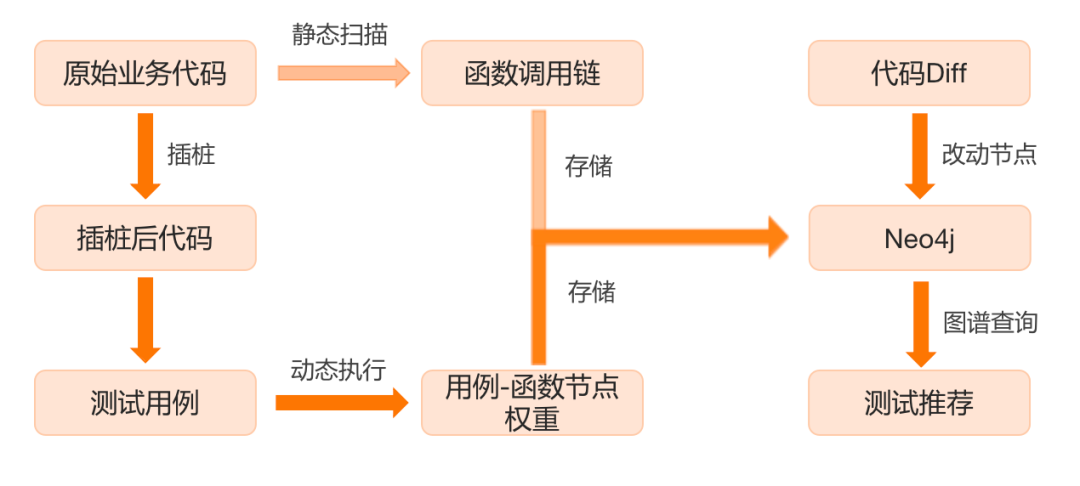
整體使用有兩條鏈路:
1. 靜態掃描+推薦測試範圍,流程如下:
原始程式碼靜態掃描,獲取基礎函式呼叫鏈
原資料解析,掃描結果儲存至Neo4j
程式碼diff獲取版本差異,圖譜查詢影響介面範圍
測試範圍推薦
2. 動態追蹤+推薦測試用例,流程如下:
業務程式碼插樁
插樁後執行業務/自動化測試用例
採集“用例-函式呼叫鏈”權重
程式碼diff獲取版本差異
測試用例推薦
04 技術架構
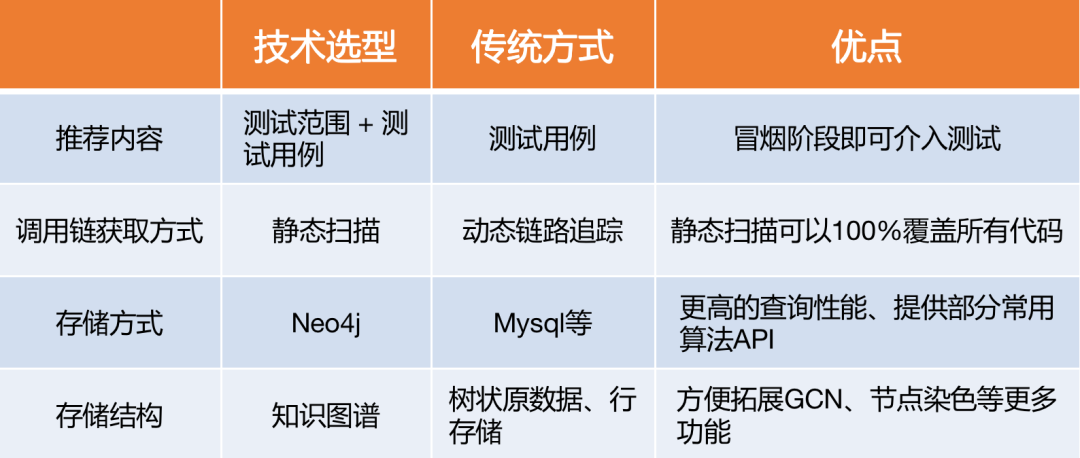
4.1 技術選型
4.2 測試範圍評估實踐
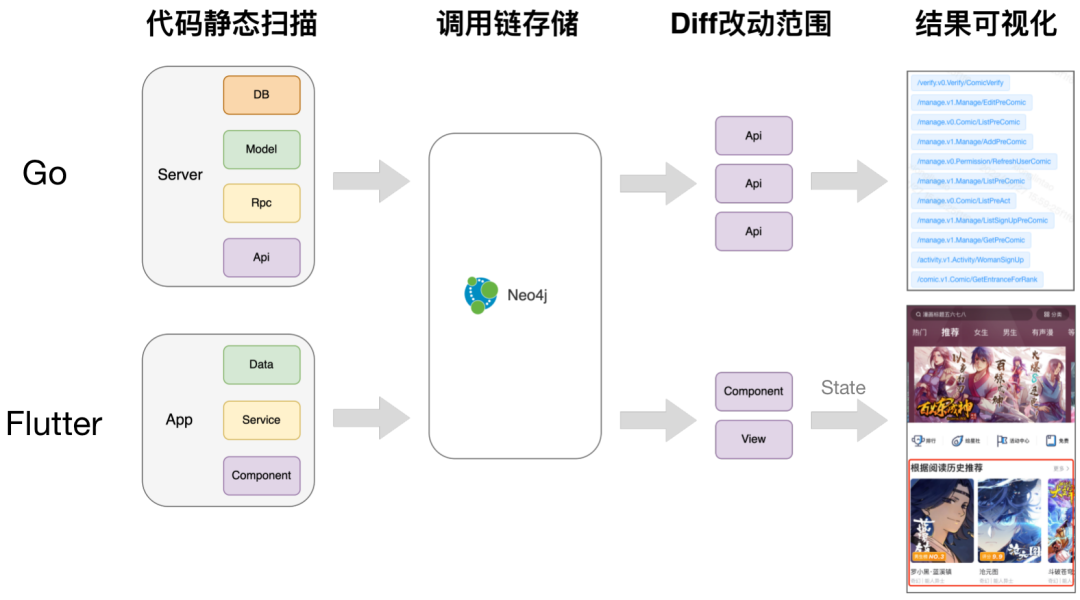
4.2.1
原始程式碼靜態掃描,獲取基礎函式呼叫鏈
首先會有兩輪掃描:
1. 自研演算法獲取函式的基礎呼叫鏈,獲取函式節點及呼叫關係
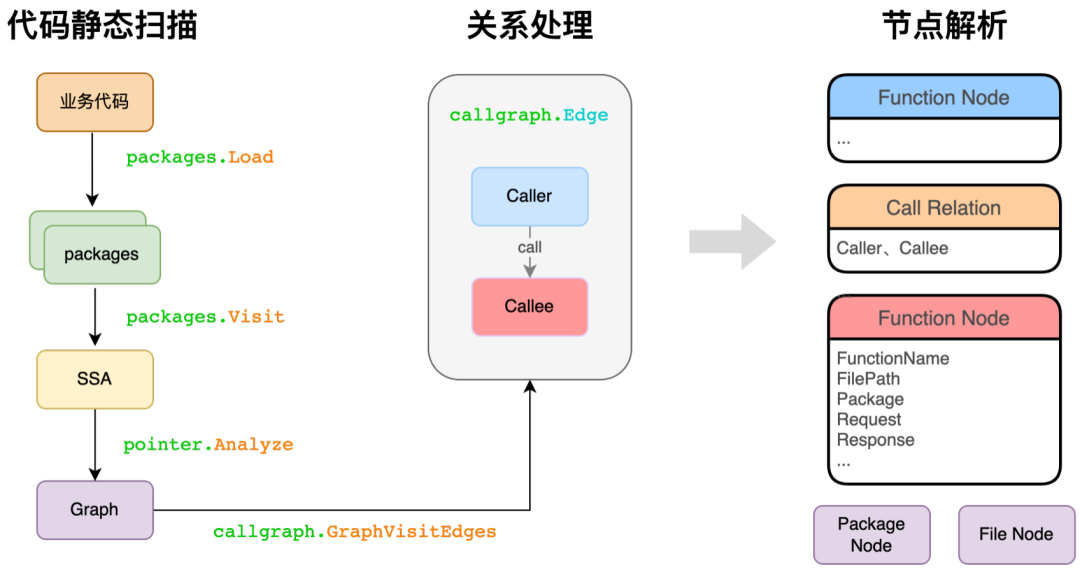
2. AST掃描,獲取函式節點補充資訊

AST是抽象語法樹(Abstract Syntax Tree)的簡稱,AST以樹狀形式表現程式語言的語法結構,樹上每個節點都表示原始碼中的一種結構。
4.2.2
原資料解析,掃描結果儲存至Neo4j
在獲取到呼叫鏈的graph資料後,遍歷轉換成存入Neo4j所需的cypher語句
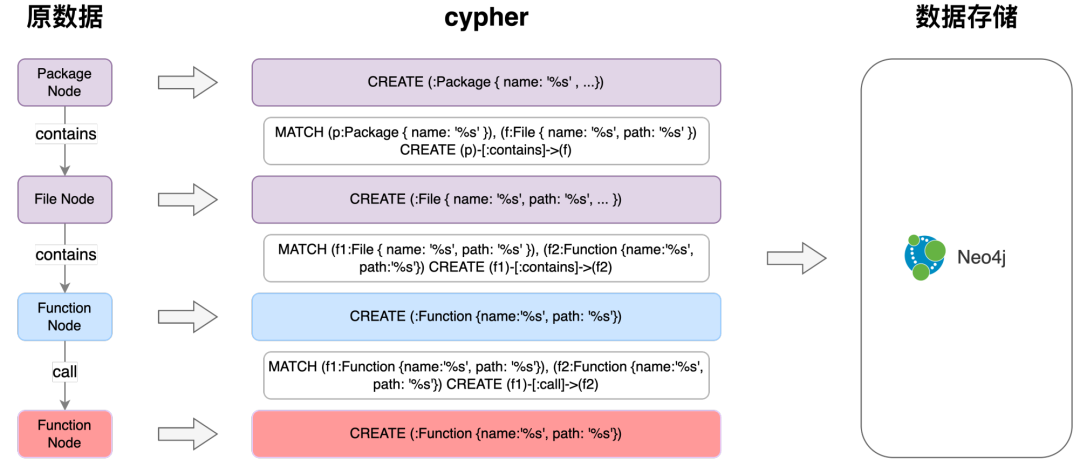
如上圖所示,圖譜最基本的組成單位,存在 (程式碼所屬包)-[包含]->(檔案)-[包含]->(函式)-[呼叫]->(函式)的結構
在獲取專案呼叫鏈原資料後,再深度遍歷每一條呼叫鏈路採集每個包、檔案、函式的對應關係,以及路徑、所處位置、出參入參、註釋、程式碼行等資訊,寫入Neo4j。
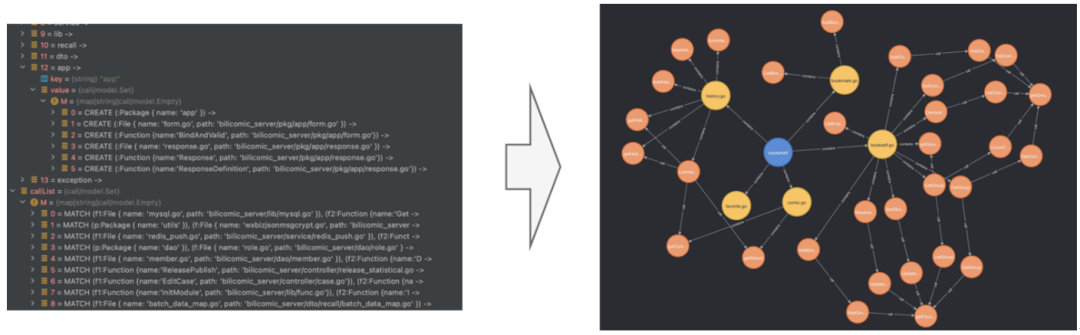
4.2.3
程式碼diff獲取版本差異,圖譜查詢影響介面範圍
透過git開放api,我們可以在git diff內獲取兩次commit對比

透過檔案路徑與函式名,我們可以找到對應的函式節點
然後透過圖譜向上追蹤查詢完整的呼叫鏈路,最終獲取到影響的介面

4.2.4 測試範圍推薦
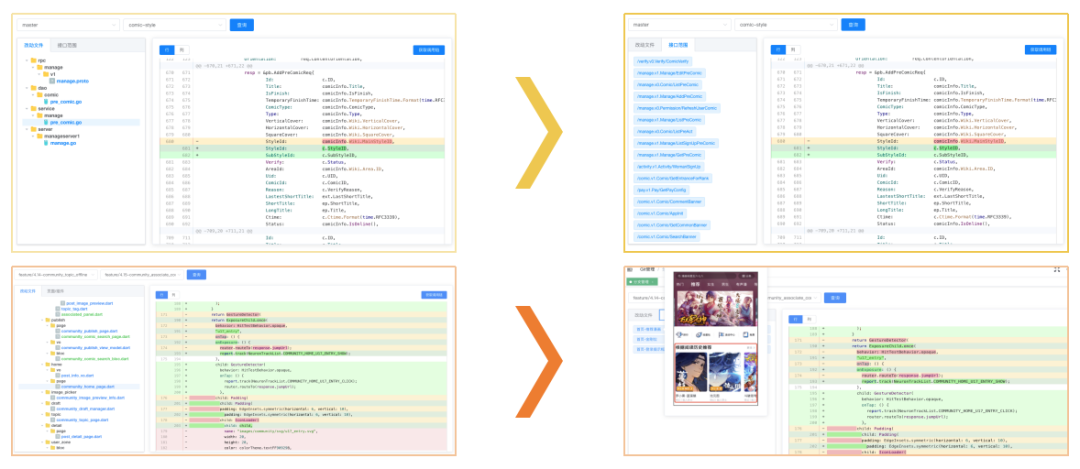
視覺化頁面展示版本程式碼對比,與影響的介面(服務端)、頁面/元件(客戶端)
4.3 測試用例推薦實踐
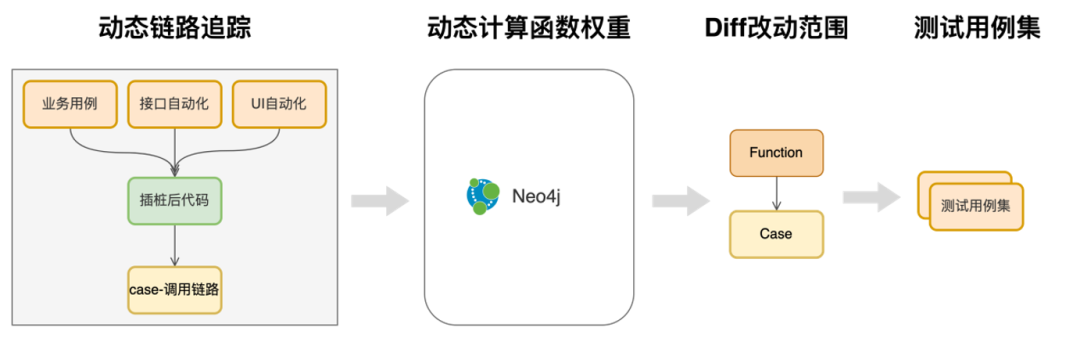
下面主要講解呼叫鏈獲取及加權部分
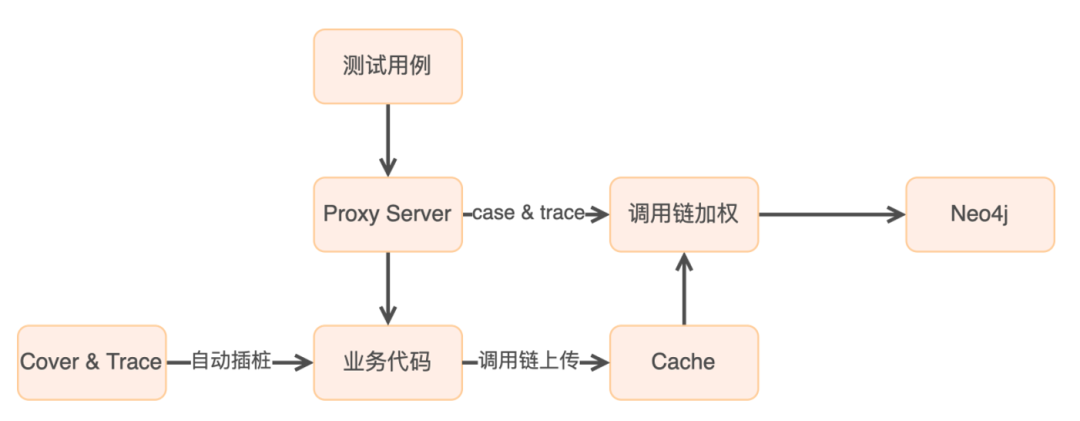
4.3.1 業務程式碼插樁
修改編譯邏輯,在開始編譯前透過AST解析插入覆蓋率和Trace的採集器
4.3.2 用例執行
透過代理服務執行測試用例,採集“用例-呼叫鏈”的對映關係
4.3.3 採集“用例-函式呼叫鏈”權重
對關聯關係進行加權計算後,存入Neo4j。
下面舉例幾種不同的權重計算方式:
呼叫次數加權
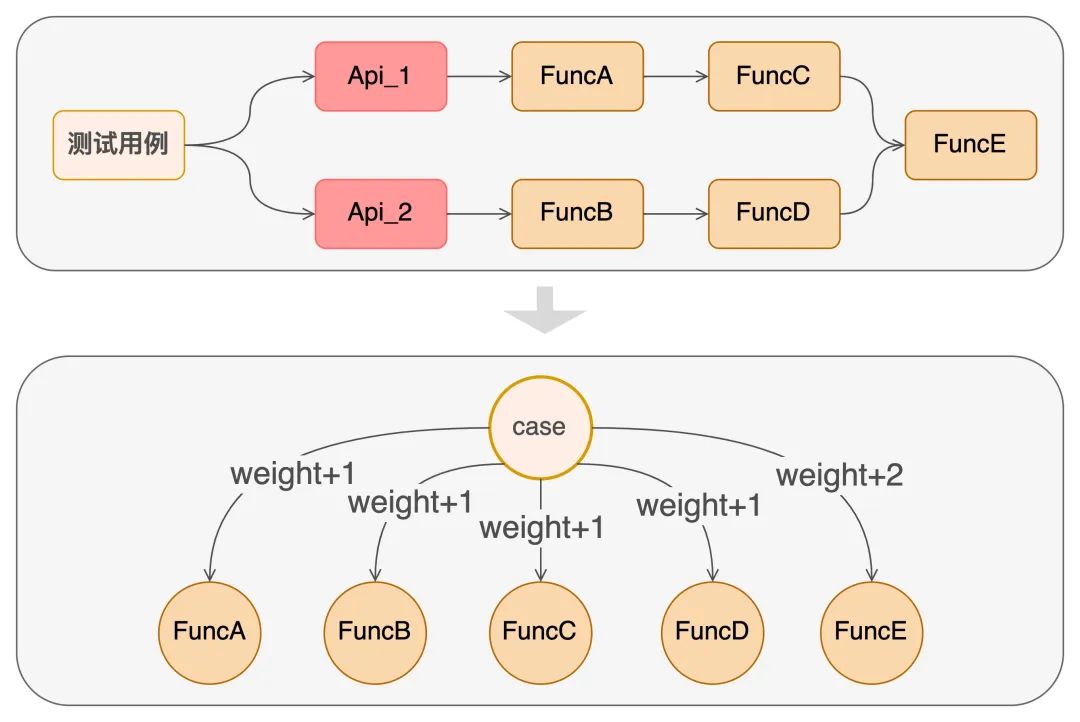
假如有一條測試用例,執行時經過了Api_1和Api_2兩個介面
然後Api_1執行時經過了函式FuncA、FuncC、FuncE
Api_2執行時經過了函式FuncB、FuncD、FuncE
我們可以理解為該條測試用例,對於函式A、B、C、D、E的呼叫次數加權分別為1、1、1、1、2
業務模組加權
這是半手工的方式,如果在用例管理系統中,有一條case屬於“書架”模組,那我們可以將不同層級的程式碼,處於bookshelf目錄下的函式,都與該case繫結一個“同模組(module_weight)”的關係(relationship)

文字相似度加權
透過對測試用例庫內的所有用例,進行分詞、建立詞庫,使用tf-idf的方式計算用例與用例間的文字相似度,來計算用例的相似性
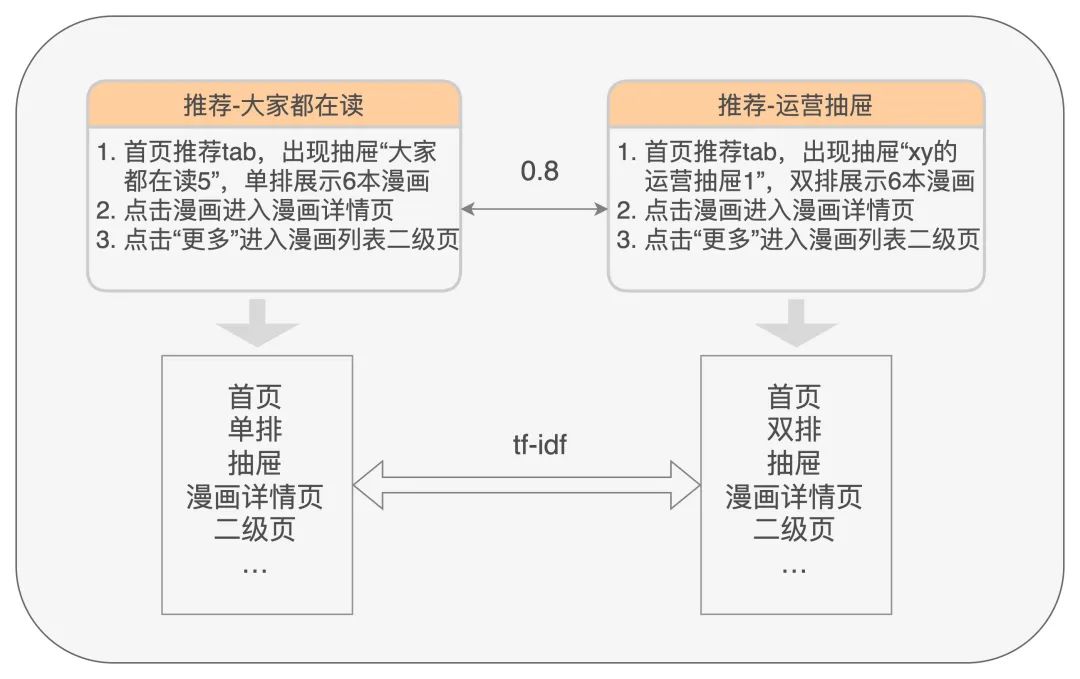
此方案對測試人員編寫用例時的要求較高,如果會有不同的測試人員去測試相同模組,因為書寫習慣不一樣,可能會導致case計算結果不準確,所以我們引入GCN計算case的相似性
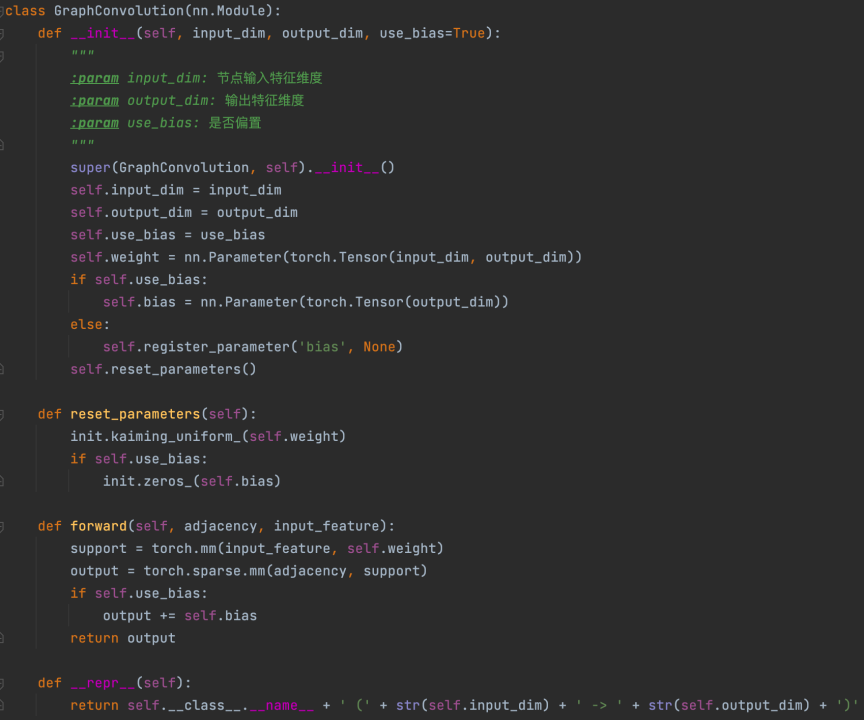
GCN(圖卷積神經網路)計算用例相似性
實際使用中,我們會採取不同的特徵來訓練GCN,用於計算不同場景的結果
在這裡我們舉一個簡單的例子,用於計算case的相似性:
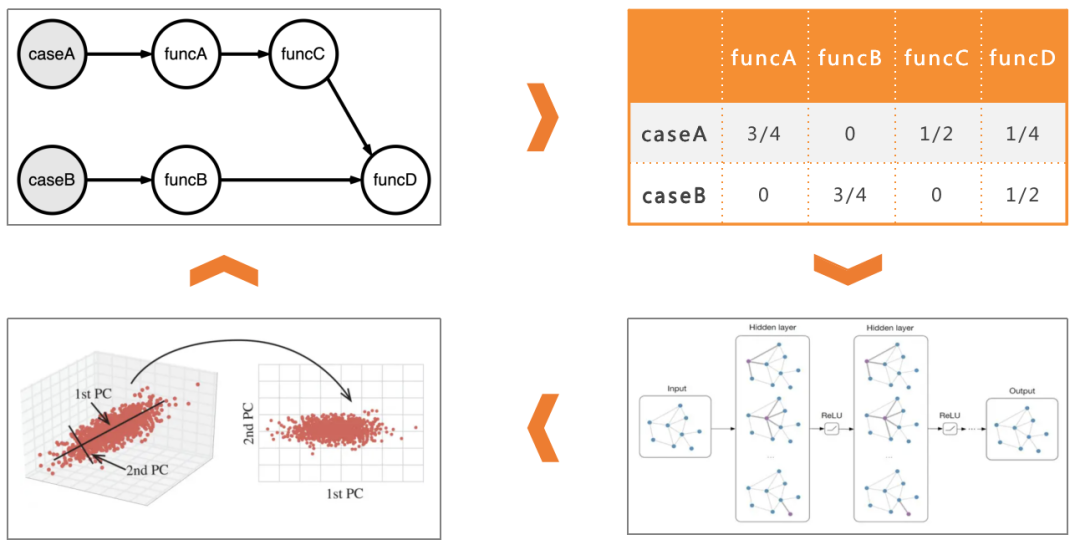
1. 我們透過採集不同case對函式的呼叫層級,構成一個C × N的稀疏矩陣 (C:測試用例個數,N:函式節點數)
2. 將呼叫層級數取反,然後歸一化,得到訓練模型用的矩陣
3. 根據GCN的定義X'=σ(L ̃sym XW)來定義GCN層,然後堆疊兩層GCN構建圖卷積網路
4. 訓練完後,透過TSNE將輸出層的score嵌入進行二維化處理,計算每個節點與節點的歐式距離,再存入Neo4j
4.3.4 程式碼diff獲取版本差異
與步驟4.2.4一樣,透過程式碼diff獲取改動的函式節點,然後透過權重計算獲取測試用例。
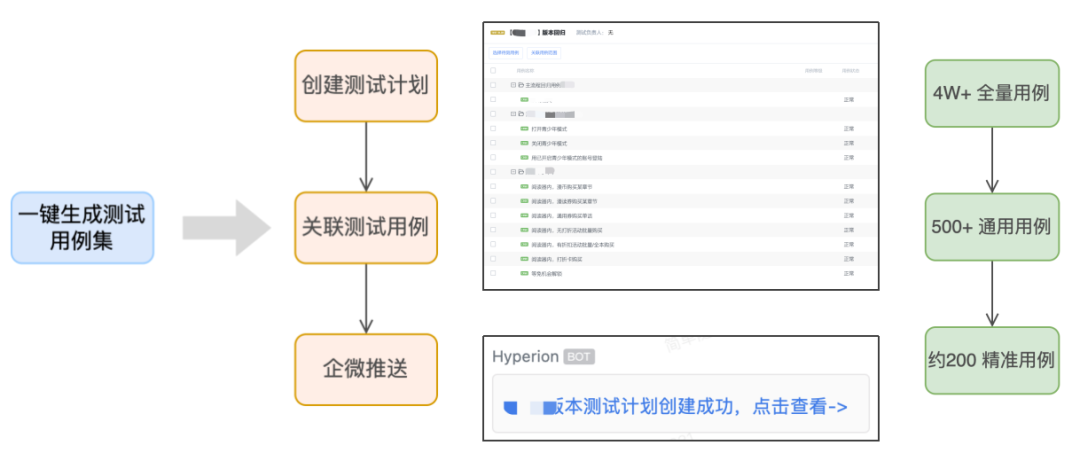
4.3.5 測試用例推薦
如果是業務用例則自動建立測試計劃,並關聯測試用例。
如果是自動化測試用例,則自動匯入用例所處的檔案、函式資訊。
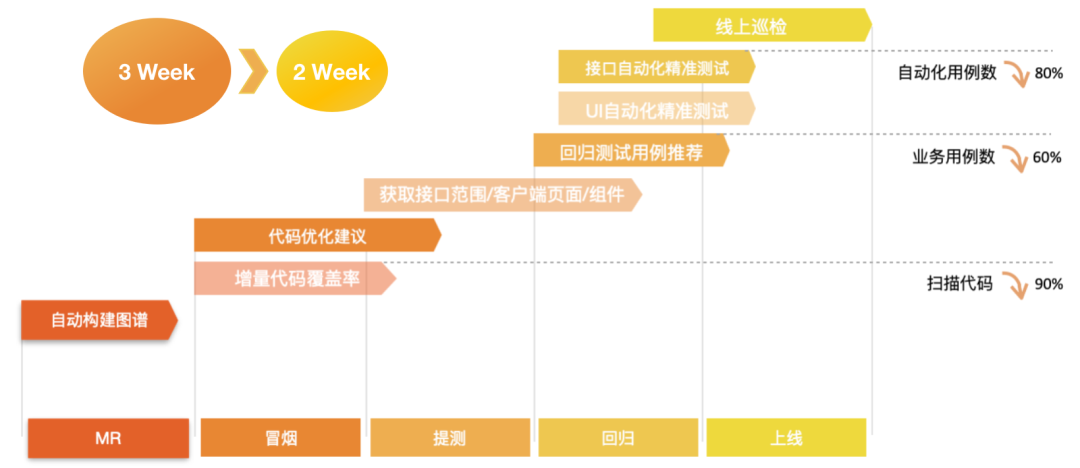
05 落地效果
目前平臺在MR、冒煙、提測、迴歸、上線等不同階段,採取了8種不同的質量保障措施:
迭代時間由3周縮短至2周
版本平均需執行自動化用例數減少80%
迴歸測試階段平均需執行用例數減少60%
覆蓋率需統計程式碼減少90%
06 未來展望
隨著增量用例的增多,資料量提高,進一步提高GCN的計算結果準確度
打造呼叫鏈程式碼染色+頁面視覺化功能,助力測試環境問題定位
來自 “ 嗶哩嗶哩技術 ”, 原文作者:熊林濤;原文連結:http://server.it168.com/a2022/1011/6767/000006767696.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 達觀失效分析知識圖譜平臺重要升級,精準助力製造業故障分析智慧化
- 精準測試:基於 asm+javaparser 呼叫鏈差異化對比實踐ASMJava
- 安全知識圖譜 | 繪製軟體供應鏈知識圖譜,強化風險分析
- jtest 精準測試平臺開源
- 美團基於知識圖譜的劇本殺標準化建設與應用
- VMmark 4.0.1 - 虛擬化平臺基準測試
- 基於知識圖譜的知識泛化讓AI學會“舉一反三”AI
- 基於bert架構的精準知識表徵模型架構模型
- 基於 AI 大模型的精準測試分享AI大模型
- 知識圖譜01:知識圖譜的定義
- 知識圖譜|知識圖譜的典型應用
- 為什麼放棄精準測試平臺?
- NumPy基礎知識圖譜
- 基於知識圖譜的APT組織追蹤治理APT
- 知識圖譜能夠為金融行業實現精準營銷行業
- 基於知識圖譜與異常檢測的PG資料庫故障定位資料庫
- ACL 2019開源論文 | 基於Attention的知識圖譜關係預測
- 攜程程式碼分析平臺實現精準測試與應用瘦身
- 知識圖譜 KnowledgeGraph基礎解析
- 基於知識庫的介面自動化測試——結果模型化方法與裝置的分析模型
- 知識圖譜丨知識圖譜賦能企業數字化轉型
- 面試圖譜:前端基礎技術知識講解面試前端
- 前端基礎技術知識講解-面試圖譜前端面試
- 知識圖譜學習記錄--知識圖譜概述
- 知識圖譜的器與用(一):百萬級知識圖譜實時視覺化引擎視覺化
- 知識圖譜技術的新成果—KGB知識圖譜介紹
- 【知識圖譜】 一個有效的知識圖譜是如何構建的?
- 知識圖譜之知識表示
- 精準送達目標客戶——基於極光平臺優化Android通知優化Android
- 基於 Django 的 Dubbo 介面測試工具平臺Django
- 精準化測試原理簡介
- go 知識圖譜Go
- OI知識圖譜
- 基於知識引入的情感分析
- 關於圖演算法 & 圖分析的基礎知識概覽演算法
- 精準測試
- 基於 HttpRunner 的介面自動化測試平臺宣講 (已落地)HTTP
- 論文入選 CCNIS 2020 | 基於知識圖譜的威脅識別詳解