在分散式系統中,當機是需要考慮的重要組成部分。日誌技術是當機恢復的重要技術之一。日誌技術應用廣泛,早些更是廣泛應用在資料庫設計實現中。本文先介紹基本原理概念,最後通過redis介紹生產環境中的實現方法。
Redo Log
資料庫設計中,需要滿足ACID,尤其是在支援事務的系統中。當系統遇到未知錯誤時,可以恢復到一個穩定可靠的狀態。有一個很簡單的思路,就是記錄所有對資料庫的寫操作日誌。那麼一旦發生故障,即使丟失掉記憶體中所有資料,當下一次啟動時,通過復現已經記錄的資料庫寫操作日誌,依然可以回到故障之前的狀態(如果在寫操作作日誌的時候發生故障,那麼這次資料庫操作失敗)。
操作流程簡單如下(假設每次資料變化,都提交):
- 更新的操作方式依次記錄到磁碟日誌檔案。
- 更新記憶體中的資料。
- 返回更新成功結果。
- 讀取日誌檔案,依次修改記憶體中的資料。
- 日誌檔案有序,可以通過append的方式寫入磁碟,效能很高。
- 簡單可靠,應用廣泛。可以把記憶體中的資料,做備份在磁碟中。
- 使用時間一長,恢復當機的時間很慢。
先具體化下,如果我們記憶體中保留一個a的值,記錄了寫操作比如 a = 4; a++; a--; 當這些操作上千萬、億之後,恢復非常慢。甚至可能最後一條就是a=0,按照之前的演算法,我們卻跑了很長時間。
那麼根據這個場景,很容易想到一個解決方案。
操作流程:
- 日誌檔案記錄begin check point
- 在某個時刻,把記憶體中的數值,直接snapshot或dump到磁碟上。(比如直接記錄a=4)
- 日誌檔案記錄end check point
- 掃描日誌檔案,找到最後的end check point中配對的begin check point。
- 讀入dump檔案。
- 依次回放記錄的日誌操作。
- 應用廣泛,包括 mysql,oracle。
- 在做snapshot的時候,往往不能停止資料庫的服務,那麼很可能記錄了begin check point之後的日誌。那麼在重新load begin check point之後的日誌時,最後恢復的資料很有可能不對。比如我們記錄的是a++這樣的日誌, 那麼重複一條日誌,就會讓a的值加1。反之如果我們記錄是冪等的,比如一直是 a=5 這種操作,那麼就對最後結果沒有影響。很顯然,設計冪等作業系統很麻煩。
- 設計一個支援snapshot的記憶體資料結構,也比較麻煩。
還有一種支援snapshot的思路是begin check point後,不動老的資料。記憶體中的資料在新的地方,日誌也寫在新的地方。最後在end check point做一次merge。這個實現起來簡單,但是記憶體消耗不小。
Redis是如何解決日誌問題的
Redis 是一個基於記憶體的database,不同於memcached,他支援持久化。另外由於redis處理client request 和 response 都是在一個thread裡面,也沒有搶佔式的排程系統,核心業務都是按照event loop順序執行,而磁碟寫日誌又開銷很大,所以redis實現日誌功能做了很多優化。並且提供2種持久化方案。我們需要在不同的場景下,採用不同的方式配置。
snapshotting
某個時刻,redis會把記憶體中的所有資料snapshot到磁碟檔案。更通俗的說法是fork一個child process,把記憶體中的資料序列化到臨時檔案,然後在main event loop 中原子的更換檔名。redis,利用了作業系統VM的copy-on-write機制,在不阻塞主執行緒的情況下,利用子程式和父程式共享的data segment實現snapshot。具體是程式碼實現在rdb.c, function at rdbSaveBackground
優點:
- 簡單可靠,如果database 不大,執行的效果非常好。
- 如果database size 很大,每一次snapshot時間非常長。不得不配置大的間隔,提高了當機時資料丟失的風險。
Append Only File(AOF)
在database術語中,也被叫做WAL。如果開啟的AOF的配置,redis會記錄所有寫操作到日誌檔案中。那麼redis同樣會遇到之前我們提到過的問題。
- 即便是追加寫,磁碟的操作依然比記憶體慢好幾個數量級,頻繁的操作容易產生瓶頸。
- 如果資料量操作頻繁,會產生大量的重複日誌資料,導致恢復時間太長。比如記錄一條微博的瀏覽量,會記錄大量重複的+1日誌。
- 檔案寫操作消耗的時間很長,redis會先把記錄日誌寫在記憶體buffer中,在每一次event loop 結束之後,根據配置判斷是否做寫操作。每個buffer的大小有限制,這樣每次寫操作時間不會太長。
- 即便是呼叫write操作,OS並沒有立即寫入磁碟,redis 同樣提供了一些方案決定重新整理OS IO buffer的時機(1秒、從不、每次)。
- redis 提供一種AOF重寫的方式rewriteAppendOnlyFile來處理AOF檔案過大情況。
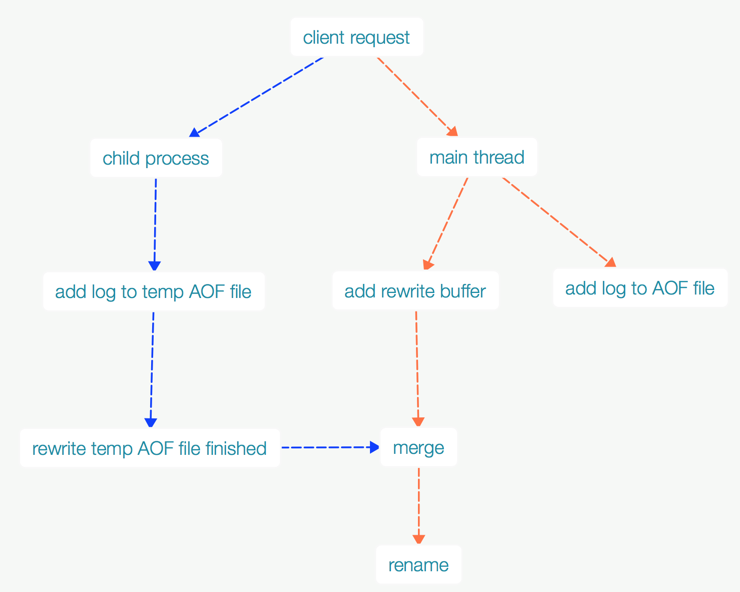
- 為了避免加鎖,redis 依然建立了一個child process,利用VM的copy-on-write,共享資料。同時保證主執行緒依然可以處理client請求。
- 根據KV的型別,先從記憶體讀取資料,然後再寫資料到磁碟,和之前的AOF檔案無關。
- 那麼當子程式rewrite AOF的過程中,main thread依然可以處理新的client request。新增的資料會被放在rewrite buffer中,而且寫到原有的AOF檔案中。
- child process完成後會通知主執行緒。主執行緒有一個定時任務,也就是會不斷輪詢child process是否已經完成(通過訊號量)。
- 主執行緒會merge 變化的資料到temp file。
- 主執行緒原子的rename到一個新的AOF檔案,之前的AOF就不起作用了。
- 除了merge 和 rename需要阻塞主執行緒,rewrite不會阻塞主執行緒。(前提是使用bgrewrite command)。
這些都是效能和穩定性之間做的權衡,根據不同場景需要調整。
參考
- Redis latency problems troubleshooting
- 分散式系統原理介紹
- Thoughts on Redis
相關閱讀
評論(1)