介紹
在大型系統開發除錯中,跨系統之間聯調開始變得不好使了。莫名其妙一個錯誤爆出來了,日誌雖然有記錄,但到底是哪裡出問題了呢?
是Ios端引數傳的不對?還是A系統或B系統提供的介面導致?相信有不少人遇到這種情況,大多數問題往往不大,但排查起來比較費勁。
下面介紹下怎麼通過上下文跟蹤的方法,最快定位到其問題。
閱讀目錄:
概述
簡單介紹就是,通過一個TraceId把整個業務請求邏輯相關聯起來,根據時間順序形成一個完整的呼叫鏈。
這樣無論任何地方報錯,只要拿TraceId去日誌系統簡查下,根據上下文的順序就知道是哪一步、哪個函式、哪個引數出錯了,能以最快速度定位處理BUG。
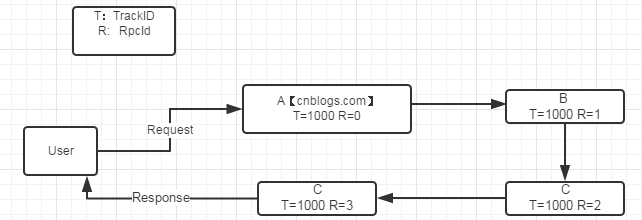
如圖以部落格園為例。當部落格園收到一個請求後,自動為生產個唯一ID 1000,之後所有處理工作都是用這個1000。
每個處理模組都維持一個上下文ID自增,rpcid++。
其處理模組可以是函式級,邏輯層級,伺服器級等都可以。
一旦發現有異常後,自動將TraceId發給部落格園。這樣程式設計師們,就能根據TraceId最快定位問題了。
關於各種環境下具體的程式碼實現:
web環境
定義跟蹤日誌需要的引數,進行上下文傳遞。
public class LogBody
{
/// <summary>
/// 跟蹤ID
/// </summary>
public string TraceId { get; set; }
/// <summary>
/// 上下文ID
/// </summary>
public int RpcId { get; set; }
/// <summary>
/// 處理時間
/// </summary>
public DateTime LastTime { get; set; }
}
在global.asax全域性Application_BeginRequest函式中,使用HttpContext.Current上下文,開始進行埋點(跟蹤),設定rpc 0。
void Application_BeginRequest(object sender, EventArgs e)
{
var lb = new LogBody();
lb.TraceId = Guid.NewGuid().ToString("N");
lb.RpcId=0;
lb.LastTime = DateTime.Now;
HttpContext.Current.Response.AppendHeader("traceID", lb.TraceId);
HttpContext.Current.Items.Add(lb.TraceId, lb);
//記錄日誌,例:使用者請求引數,userAgent等。
}
在default頁開始業務邏輯,設定rpc 1。
protected void Page_Load(object sender, EventArgs e)
{
var traceID = HttpContext.Current.Response.Headers["traceID"];
LogBody logbody = HttpContext.Current.Items[traceID] as LogBody;
logbody.RpcId++;
logbody.LastTime = DateTime.Now;
//業務邏輯。
//記錄日誌。。。
}
如上就完成上下文的傳遞。
Application_BeginRequest 中在實際使用中,只需要對有用的頁面(例:aspx,ashx)進行埋點。
日誌記錄的時候,可以把logbody都儲存起來。
儲存到Headers可以讓前端通過JS也能拿到TraceId,方便去排查問題。
LastTime這個欄位,可以與上一次的相減,這樣就得出中間邏輯處理所花費的時間了。
多執行緒環境
在web程式中可以用httpcontext的上下文傳遞。
在單執行緒的程式中,按照線性順序即可。
多執行緒中利用用threadlocal傳遞。
public static ThreadLocal<LogBody> Body = new ThreadLocal<LogBody>(); static void Main(string[] args) { var t1 = new Thread(() => { Body.Value = new LogBody() { LastTime = DateTime.Now, RpcId = 0, TraceId = Guid.NewGuid().ToString("N") }; //業務1 Console.WriteLine("Thread1 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime); Thread.Sleep(5000); Body.Value.RpcId++; Body.Value.LastTime = DateTime.Now; //業務2 Console.WriteLine("Thread1 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime); }); t1.Start(); var t2 = new Thread(() => { Body.Value = new LogBody() { LastTime = DateTime.Now, RpcId = 0, TraceId = Guid.NewGuid().ToString("N") }; //業務1 Console.WriteLine("Thread2 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime); Thread.Sleep(5000); Body.Value.RpcId++; Body.Value.LastTime = DateTime.Now; //業務2 Console.WriteLine("Thread2 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime); }); t2.Start(); }
執行如下:

非同步環境
往往在生產環境中,會有大量的非同步操作。如果有非同步行為的話,打亂上下文怎麼辦?這時候需要引入另外一個概念,父節點Id。
這樣非同步操作的行為就父節點之下,最終在日誌後臺展示的是一個倒著的樹形結構。
如圖可以看到業務2非同步派生出來的子節點。
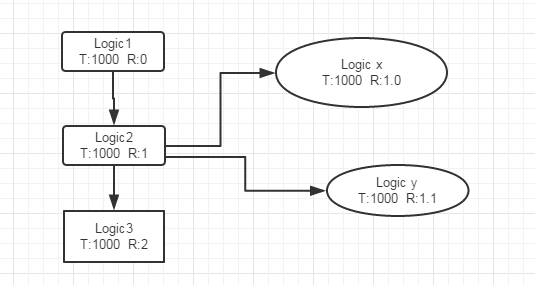
把上下文rpcid修改成double型別。
static void Main(string[] args)
{
var t2 = new Thread(() =>
{
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = 1,
TraceId = Guid.NewGuid().ToString("N")
};
var t1 = new Thread((lb) =>
{
var temp = lb as LogBody;
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = temp.RpcId,
TraceId = temp.TraceId
};
Body.Value.RpcId += 0.1;
//業務x
Console.WriteLine("async Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime );
Thread.Sleep(5000);
Body.Value.RpcId+=0.1;
Body.Value.LastTime = DateTime.Now;
//業務y
Console.WriteLine("async Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t1.Start(Body.Value);
//業務1
Console.WriteLine("sync Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
Thread.Sleep(2000);
Body.Value.RpcId+=1;
Body.Value.LastTime = DateTime.Now;
//業務2
Console.WriteLine("sync Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t2.Start();
}
程式碼中用引數傳遞給了非同步執行緒中,執行如下:

效能,大資料量,隱私安全
關於效能
從程式碼中可以看出,這種方式對程式效能影響可以忽略不計。
需要注意是:如果在生產環境跑的話,不論是寫檔案,還是資料庫,或寫統一日誌平臺。都會導致大量IO讀寫,網路資源消耗。
如果伺服器都消耗這上面,就得不償失了。
可以用記憶體佇列+佇列+批量push或pull的方式,並且注意設定閥值。
關於大資料量
大量的請求,其實多數是無效的。這裡引入取樣率的概念。 例如按求餘取,或者按地區,時間等。也可以單獨寫取樣規則。
日誌可以只記錄error以上的級別,只有在排查生產環境的時候才開啟debug,info級別資訊。
儲存這塊,可以根據實際需要選擇sql server,mongodb,hbase hdfs。
關於隱私安全
如果有敏感資料,可根據安全級別進行加密。
總結
本文是基於Google dapper論文的思路展開,基於此進行很多擴充套件。
示例中採用的是手動記錄,在實際使用中,可以簡化呼叫,封裝成自動構建的,有興趣的可以看前2篇自動注入的相關介紹。
參考資源
Google dapper論文
淘寶EagleEye系統