Java虛擬機器執行機制與相關概念
文章目錄
JVM組成
JVM(Java Virtual Machine)是用於執行Java位元組碼的虛擬機器,包括一套位元組碼指令集、一組程式暫存器、一個虛擬機器棧、一個虛擬機器堆、一個方法區和一個垃圾回收器。JVM執行在作業系統之上,不與硬體裝置直接互動。

一個Java檔案的執行過程

1.類載入器子系統將編譯好的.Class檔案載入到JVM中
2.將JVM執行過程中產生的資料,包括程式計數器、方法區、
本地方法去、虛擬機器棧和虛擬機器堆都儲存在執行時資料區
3.將.Class檔案載入到執行引擎中,其中即時編譯器負責將java位元組碼
編成具體的機器碼,垃圾回收期用於回收執行過程中不再使用的物件
4。將執行引擎中得到的機器碼,傳入本地介面庫中,
再呼叫作業系統的本地方法庫完成具體的指令操作
Java程式與jvm虛擬機器的關係
一個Java程式對應一個虛擬機器例項,程式退出或者關閉,則虛擬機器例項小王,在多個虛擬機器例項例項之間資料不能共享
(一個程式對應多個執行緒)
jvm執行緒與系統原生執行緒
1.關係
jvm中的執行緒與作業系統中的執行緒是相互對應的。
當jvm執行緒的本地儲存、緩衝區分配、同步物件、棧、程式計數器等準備工作都完成時,jvm會呼叫作業系統的介面建立一個原生執行緒,遠端執行緒的生命週期與jvm執行緒相同。
作業系統負責排程所有執行緒,併為其分配cpu時間片,在原生執行緒初始化完畢時,就會呼叫Java執行緒的run()執行該執行緒;執行緒結束後,會釋放原生執行緒和Java執行緒所對應的資源。
## 3.jvm主要執行緒 - 虛擬機器執行緒(JVMThread):虛擬機器執行緒在JVM到達安全點(SafePoint)時出現。 - 週期性任務執行緒:通過定時器排程執行緒來實現週期性操作的執行。 - GC執行緒:GC執行緒支援JVM中不同的垃圾回收活動。 - 編譯器執行緒:編譯器執行緒在執行時將位元組碼動態編譯成本地平臺機器碼,是JVM跨平臺的具體實現。 - 訊號分發執行緒:接收傳送到JVM的訊號並呼叫JVM方法。
jvm記憶體區域

1.執行緒私有區域:
生命週期與執行緒相同,隨執行緒的啟動而建立,隨執行緒的結束而銷燬。在JVM內,每個執行緒都與作業系統的本地執行緒直接對映,因此這部分記憶體區域的存在與否和本地執行緒的啟動和銷燬對應。
2.執行緒共享區域:
隨虛擬機器的啟動而建立,隨虛擬機器的關閉而銷燬。
2.直接記憶體
也叫作堆外記憶體,它並不是JVM執行時資料區的一部分,但在併發程式設計中被頻繁使用。JDK的NIO模組提供的基於Channel與Buffer的I/O操作方式就是基於堆外記憶體實現的,NIO模組通過呼叫Native函式庫直接在作業系統上分配堆外記憶體,然後使用DirectByteBuffer物件作為這塊記憶體的引用對記憶體進行操作,Java程式可以通過堆外記憶體技術避免在Java堆和Native堆中來回複製資料帶來的資源佔用和效能消耗,因此堆外記憶體在高併發應用場景下被廣泛使用
(native堆不受gc控制,可用於和外界進行通訊,並且做為快取使用)
程式計數器:執行緒私有,無記憶體溢位問題
程式計數器是一塊很小的記憶體空間,用於儲存當前執行的執行緒所執行的位元組碼的行號指示器。
每個執行中的執行緒都有一個獨立的程式計數器,在方法正在執行時,該方法的程式計數器記錄的是實時虛擬機器位元組碼指令的地址;如果該方法執行的是Native方法,則程式計數器的值為空(Undefined)。
程式計數器屬於“執行緒私有”的記憶體區域,它是唯一沒有Out Of Memory(記憶體溢位)的區域。
虛擬機器棧:執行緒私有,描述Java方法的執行過程

虛擬機器棧是描述Java方法的執行過程的記憶體模型,它在當前棧幀(Stack Frame)中儲存了區域性變數表、運算元棧、動態連結、方法出口等資訊。同時,棧幀用來儲存部分執行時資料及其資料結構,處理動態連結(Dynamic Linking)方法的返回值和異常分派(Dispatch Exception)。
棧幀用來記錄方法的執行過程,在方法被執行時虛擬機器會為其建立一個與之對應的棧幀,方法的執行和返回對應棧幀在虛擬機器棧中的入棧和出棧。無論方法是正常執行完成還是異常完成(丟擲了在方法內未被捕獲的異常),都視為方法執行結束。

這張圖展示了執行緒執行及棧幀變化的過程。執行緒 1在CPU1上執行,執行緒 2在CPU2上執行,在CPU資源不夠時其他執行緒將處於等待狀態(如圖 3-1中等待的執行緒 N),等待獲取CPU時間片。而線上程內部,每個方法的執行和返回都對應一個棧幀的入棧和出棧,每個執行中的執行緒當前只有一個棧幀處於活動狀態。
本地方法區:執行緒私有

本地方法區和虛擬機器棧的作用類似,區別是虛擬機器棧為執行Java方法服務,本地方法棧為Native方法服務。
堆:也叫做執行時資料區,執行緒共享
在JVM執行過程中建立的物件和產生的資料都被儲存在堆中,堆是被執行緒共享的記憶體區域,也是垃圾收集器進行垃圾回收的最主要的記憶體區域。由於現代JVM採用分代收集演算法,因此Java堆從GC(Garbage Collection,垃圾回收)的角度還可以細分為:新生代、老年代和永久代。
方法區:執行緒共享
方法區也被稱為永久代,用於儲存常量、靜態變數、類資訊、即時編譯器編譯後的機器碼、執行時常量池等資料

JVM把GC分代收集擴充套件至方法區,即使用Java堆的永久代來實現方法區,這樣JVM的垃圾收集器就可以像管理Java堆一樣管理這部分記憶體。
永久帶的記憶體回收主要針對常量池的回收和類的解除安裝,因此可回收的物件很少。
常量被儲存在執行時常量池(Runtime Constant Pool)中,是方法區的一部分。
靜態變數也屬於方法區的一部分。在類資訊(Class檔案)中不但儲存了類的版本、欄位、方法、介面等描述資訊,還儲存了常量資訊。
在即時編譯後,程式碼的內容將在執行階段(類載入完成後)被儲存在方法區的執行時常量池中。Java虛擬機器對Class檔案每一部分的格式都有明確的規定,只有符合JVM規範的Class檔案才能通過虛擬機器的檢查,然後被裝載、執行。
JVM的執行記憶體
JVM的執行時記憶體也叫作JVM堆,從GC的角度可以將JVM堆分為新生代、老年代和永久代。
其中新生代預設佔 1/3堆空間,老年代預設佔 2/3堆空間,永久代佔非常少的堆空間。
新生代又分為Eden區、ServivorFrom區和ServivorTo區,Eden區預設佔8/10新生代空間,ServivorFrom區和ServivorTo區預設分別佔 1/10新生代空間。

1.新生代
JVM新建立的物件(除了大物件外)會被存放在新生代,預設佔 1/3堆記憶體空間。由於JVM會頻繁建立物件,所以新生代會頻繁觸發MinorGC進行垃圾回收。
新生代又分為Eden區、ServivorTo區和ServivorFrom區,如下所述。
(1)Eden區:Java新建立的物件首先會被存放在Eden區,如果新建立的物件屬於大物件,則直接將其分配到老年代。大物件的定義和具體的JVM版本、堆大小和垃圾回收策略有關,一般為 2KB~128KB,可通過XX:PretenureSizeThreshold設定其大小。在Eden區的記憶體空間不足時會觸發MinorGC,對新生代進行一次垃圾回收。
(2)ServivorTo區:保留上一次MinorGC時的倖存者。
(3)ServivorFrom區:將上一次MinorGC時的倖存者作為這一次MinorGC的被掃描者。
2.MinorGC:新生代的gc過程
MinorGC是新生代的GC過程,採用複製演算法實現,具體過程如下。
(1)把在Eden區和ServivorFrom區中存活的物件複製到ServivorTo區。如果某物件的年齡達到老年代的標準(物件晉升老年代的標準由XX:MaxTenuringThreshold設定,預設為 15),則將其複製到老年代,同時把這些物件的年齡加 1;如果ServivorTo區的記憶體空間不夠,則也直接將其複製到老年代;如果物件屬於大物件(大小為 2KB~128KB的物件屬於大物件,例如通過XX:PretenureSizeThreshold=2097152設定大物件為 2MB,1024×1024×2Byte=2097152Byte=2MB),則也直接將其複製到老年代。
(2)清空Eden區和ServivorFrom區中的物件。
(3)將ServivorTo區和ServivorFrom區互換,原來的ServivorTo區成為下一次GC時的ServivorFrom區。
3.老年代
老年代主要存放有長生命週期的物件和大物件。
老年代的GC過程叫作MajorGC。在老年代,物件比較穩定,MajorGC不會被頻繁觸發。在進行MajorGC前,JVM會進行一次MinorGC,在MinorGC過後仍然出現老年代空間不足或無法找到足夠大的連續空間分配給新建立的大物件時,會觸發MajorGC進行垃圾回收,釋放JVM的記憶體空間。
MajorGC採用標記清除演算法,該演算法首先會掃描所有物件並標記存活的物件,然後回收未被標記的物件,並釋放記憶體空間。因為要先掃描老年代的所有物件再回收,所以MajorGC的耗時較長。MajorGC的標記清除演算法容易產生記憶體碎片。在老年代沒有記憶體空間可分配時,會丟擲Out Of Memory異常。
永久代
永久代指記憶體的永久儲存區域,主要存放Class和Meta(後設資料)的資訊。Class在類載入時被放入永久代。永久代和老年代、新生代不同,GC不會在程式執行期間對永久代的記憶體進行清理,這也導致了永久代的記憶體會隨著載入的Class檔案的增加而增加,在載入的Class檔案過多時會丟擲Out Of Memory異常,比如Tomcat引用Jar檔案過多導致JVM記憶體不足而無法啟動。
需要注意的是,在Java 8中永久代已經被後設資料區(也叫作元空間)取代。後設資料區的作用和永久代類似,二者最大的區別在於:後設資料區並沒有使用虛擬機器的記憶體,而是直接使用作業系統的本地記憶體。因此,元空間的大小不受JVM記憶體的限制,只和作業系統的記憶體有關。
在Java 8中,JVM將類的後設資料放入本地記憶體(Native Memory)中,將常量池和類的靜態變數放入Java堆中,這樣JVM能夠載入多少後設資料資訊就不再由JVM的最大可用記憶體(MaxPermSize)空間決定,而由作業系統的實際可用記憶體空間決定。
# 垃圾回收與演算法 ## 1.如何確定垃圾 Java採用引用計數法和可達性分析來確定物件是否應該被回收,其中,引用計數法容易產生迴圈引用的問題,可達性分析通過根搜尋演算法(GC Roots Tracing)來實現。
根搜尋演算法以一系列GC Roots的點作為起點向下搜尋,在一個物件到任何GC Roots都沒有引用鏈相連時,說明其已經死亡。

2.垃圾確認方法
引用計數法
在Java中如果要操作物件,就必須先獲取該物件的引用,因此可以通過引用計數法來判斷一個物件是否可以被回收。在為物件新增一個引用時,引用計數加 1;在為物件刪除一個引用時,引進計數減 1;如果一個物件的引用計數為 0,則表示此刻該物件沒有被引用,可以被回收。
引用計數法容易產生迴圈引用問題。迴圈引用指兩個物件相互引用,導致它們的引用一直存在,而不能被回收,如圖 1-7所示,Object1與Object2互為引用,如果採用引用計數法,則Object1和Object2由於互為引用,其引用計數一直為 1,因而無法被回收。

可達性分析
為了解決引用計數法的迴圈引用問題,Java還採用了可達性分析來判斷物件是否可以被回收。具體做法是首先定義一些GC Roots物件,然後以這些GC Roots物件作為起點向下搜尋,如果在GC roots和一個物件之間沒有可達路徑,則稱該物件是不可達的。不可達物件要經過至少兩次標記才能判定其是否可以被回收,如果在兩次標記後該物件仍然是不可達的,則將被垃圾收集器回收。
3.Java中常用的垃圾回收演算法
Java中常用的垃圾回收演算法有標記清除(Mark-Sweep)、複製(Copying)、標記整理(Mark-Compact)和分代收集(Generational Collecting)這 4種垃圾回收演算法

- 標記清除演算法
標記清除演算法是基礎的垃圾回收演算法,其過程分為標記和清除兩個階段。在標記階段標記所有需要回收的物件,在清除階段清除可回收的物件並釋放其所佔用的記憶體空間

由於標記清除演算法在清理物件所佔用的記憶體空間後並沒有重新整理可用的記憶體空間,因此如果記憶體中可被回收的小物件居多,則會引起記憶體碎片化的問題,繼而引起大物件無法獲得連續可用空間的問題。
- 複製演算法
複製演算法是為了解決標記清除演算法記憶體碎片化的問題而設計的。
複製演算法首先將記憶體劃分為兩塊大小相等的記憶體區域,即區域 1和區域 2,新生成的物件都被存放在區域 1中,在區域 1內的物件儲存滿後會對區域 1進行一次標記,並將標記後仍然存活的物件全部複製到區域 2中,這時區域 1將不存在任何存活的物件,直接清理整個區域 1的記憶體即可。

複製演算法的記憶體清理效率高且易於實現,但由於同一時刻只有一個記憶體區域可用,即可用的記憶體空間被壓縮到原來的一半,因此存在大量的記憶體浪費。同時,在系統中有大量長時間存活的物件時,這些物件將在記憶體區域 1和記憶體區域 2之間來回複製而影響系統的執行效率。因此,該演算法只在物件為“朝生夕死”狀態時執行效率較高。
- 標記整理演算法
標記整理演算法結合了標記清除演算法和複製演算法的優點,其標記階段和標記清除演算法的標記階段相同,在標記完成後將存活的物件移到記憶體的另一端,然後清除該端的物件並釋放記憶體

-分帶收集演算法
無論是標記清除演算法、複製演算法還是標記整理演算法,都無法對所有型別(長生命週期、短生命週期、大物件、小物件)的物件都進行垃圾回收。因此,針對不同的物件型別,JVM採用了不同的垃圾回收演算法,該演算法被稱為分代收集演算法。
分代收集演算法根據物件的不同型別將記憶體劃分為不同的區域,JVM將堆劃分為新生代和老年代。新生代主要存放新生成的物件,其特點是物件數量多但是生命週期短,在每次進行垃圾回收時都有大量的物件被回收;老年代主要存放大物件和生命週期長的物件,因此可回收的物件相對較少。因此,JVM根據不同的區域物件的特點選擇了不同的演算法。
目前,大部分JVM在新生代都採用了複製演算法,因為在新生代中每次進行垃圾回收時都有大量的物件被回收,需要複製的物件(存活的物件)較少,不存在大量的物件在記憶體中被來回複製的問題,因此採用複製演算法能安全、高效地回收新生代
大量的短生命週期的物件並釋放記憶體。JVM將新生代進一步劃分為一塊較大的Eden區和兩塊較小的Servivor區,Servivor區又分為ServivorFrom區和ServivorTo區。JVM在執行過程中主要使用Eden區和ServivorFrom區,進行垃圾回收時會將在Eden區和ServivorFrom區中存活的物件複製到ServivorTo區,然後清理Eden區和ServivorFrom區的記憶體空間

老年代主要存放生命週期較長的物件和大物件,因而每次只有少量非存活的物件被回收,因而在老年代採用標記清除演算法。
在JVM中還有一個區域,即方法區的永久代,永久代用來儲存Class類、常量、方法描述等。在永久代主要回收廢棄的常量和無用的類。
JVM記憶體中的物件主要被分配到新生代的Eden區和ServivorFrom區,在少數情況下會被直接分配到老年代。在新生代的Eden區和ServivorFrom區的記憶體空間不足時會觸發一次GC,該過程被稱為MinorGC。在MinorGC後,在Eden區和ServivorFrom區中存活的物件會被複制到ServivorTo區,然後Eden區和ServivorFrom區被清理。如果此時在ServivorTo區無法找到連續的記憶體空間儲存某個物件,則將這個物件直接儲存到老年代。若Servivor區的物件經過一次GC後仍然存活,則其年齡加 1。在預設情況下,物件在年齡達到15時,將被移到老年代。
Java中的四種引用型別

(1)強引用
在Java中最常見的就是強引用。在把一個物件賦給一個引用變數時,這個引用變數就是一個強引用。有強引用的物件一定為可達性狀態,所以不會被垃圾回收機制回收。因此,強引用是造成Java記憶體洩漏(Memory Link)的主要原因。
##(2)軟引用
軟引用通過SoftReference類實現。如果一個物件只有軟引用,則在系統記憶體空間不足時該物件將被回收。
##(3)弱引用
弱引用通過WeakReference類實現,如果一個物件只有弱引用,則在垃圾回收過程中一定會被回收。
##(4)虛引用
虛引用通過PhantomReference類實現,虛引用和引用佇列聯合使用,主要用於跟蹤物件的垃圾回收狀態。
分代收集演算法和分割槽收集演算法
1.分代收集演算法
JVM根據物件存活週期的不同將記憶體劃分為新生代、老年代和永久代,並根據各年代的特點分別採用不同的GC演算法
- 新生代與複製演算法
新生代主要儲存短生命週期的物件,因此在垃圾回收的標記階段會標記大量已死亡的物件及少量存活的物件,因此只需選用複製演算法將少量存活的物件複製到記憶體的另一端並清理原區域的記憶體即可。
- 老年代與標記整理演算法
法老年代主要存放長生命週期的物件和大物件,可回收的物件一般較少,因此JVM採用標記整理演算法進行垃圾回收,直接釋放死亡狀態的物件所佔用的記憶體空間即可。
2…分割槽收集演算法
分割槽演算法將整個堆空間劃分為連續的大小不同的小區域,對每個小區域都單獨進行記憶體使用和垃圾回收,這樣做的好處是可以根據每個小區域記憶體的大小靈活使用和釋放記憶體。
分割槽收集演算法可以根據系統可接受的停頓時間,每次都快速回收若干個小區域的記憶體,以縮短垃圾回收時系統停頓的時間,最後以多次並行累加的方式逐步完成整個記憶體區域的垃圾回收。如果垃圾回收機制一次回收整個堆記憶體,則需要更長的
垃圾收集器
Java堆記憶體分為新生代和老年代:新生代主要儲存短生命週期的物件,適合使用複製演算法進行垃圾回收;老年代主要儲存長生命週期的物件,適合使用標記整理演算法進行垃圾回收。
因此,JVM針對新生代和老年代分別提供了多種不同的垃圾收集器,針對新生代提供的垃圾收集器有Serial、ParNew、Parallel Scavenge,針對老年代提供的垃圾收集器有Serial Old、Parallel Old、CMS,還有針對不同區域的G1分割槽收集演算法

1.Serial垃圾收集器:單執行緒,複製演算法
Serial垃圾收集器基於複製演算法實現,它是一個單執行緒收集器,在它正在進行垃圾收集時,必須暫停其他所有工作執行緒,直到垃圾收集結束。
Serial垃圾收集器採用了複製演算法,簡單、高效,對於單CPU執行環境來說,沒有執行緒互動開銷,可以獲得最高的單執行緒垃圾收集效率,因此Serial垃圾收集器是Java虛擬機器執行在Client模式下的新生代的預設垃圾收集器。
2.ParNew垃圾收集器:多執行緒,複製演算法
ParNew垃圾收集器是Serial垃圾收集器的多執行緒實現,同樣採用了複製演算法,它採用多執行緒模式工作,除此之外和Serial收集器幾乎一樣。ParNew垃圾收集器在垃圾收集過程中會暫停所有其他工作。執行緒,是Java虛擬機器執行在Server模式下的新生代的預設垃圾收集器。
ParNew垃圾收集器預設開啟與CPU同等數量的執行緒進行垃圾回收,在Java應用啟動時可通過-XX:ParallelGCThreads引數調節ParNew垃圾收集器的工作執行緒數。
3.Parallel Scavenge垃圾收集器:多執行緒,複製演算法
Parallel Scavenge收集器是為提高新生代垃圾收集效率而設計的垃圾收集器,基於多執行緒複製演算法實現,在系統吞吐量上有很大的優化,可以更高效地利用CPU儘快完成垃圾回收任務。
Parallel Scavenge通過自適應調節策略提高系統吞吐量,提供了三個引數用於調節、控制垃圾回收的停頓時間及吞吐量,分別是控制最大垃圾收集停頓時間的-XX:MaxGCPauseMillis引數,控制吞吐量大小的-XX:GCTimeRatio引數和控制自適應調節策略開啟與否的UseAdaptive-SizePolicy引數。
4.Serial Old垃圾收集器:單執行緒,標記整理演算法
Serial Old垃圾收集器是Serial垃圾收集器的老年代實現,同Serial一樣採用單執行緒執行,不同的是,Serial Old針對老年代長生命週期的特點基於標記整理演算法實現。Serial Old垃圾收集器是JVM執行在Client模式下的老年代的預設垃圾收集器。
新生代的Serial垃圾收集器和老年代的Serial Old垃圾收集器可搭配使用,分別針對JVM的新生代和老年代進行垃圾回收,其垃圾收集過程如圖 所示。在新生代採用Serial垃圾收集器基於複製演算法進行垃圾回收,未被其回收的物件在老年代被Serial Old垃圾收集器基於標記整理演算法進行垃圾回收。

## 5.Parallel Old垃圾收集器:多執行緒,標記整理演算法 Parallel Old垃圾收集器採用多執行緒併發進行垃圾回收,它根據老年代長生命週期的特點,基於多執行緒的標記整理演算法實現。Parallel Old垃圾收集器在設計上優先考慮系統吞吐量,其次考慮停頓時間等因素,如果系統對吞吐量的要求較高,則可以優先考慮新生代的Parallel Scavenge垃圾收集器和老年代的Parallel Old垃圾收集器的配合使用。 新生代的Parallel Scavenge垃圾收集器和老年代的Parallel Old垃圾收集器的搭配執行過程如圖所示。新生代基於Parallel Scavenge垃圾收集器的複製演算法進行垃圾回收,老年代基於Parallel Old垃圾收集器的標記整理演算法進行垃圾回收。 
## 6.CMS垃圾收集器 CMS(Concurrent Mark Sweep)垃圾收集器是為老年代設計的垃圾收集器,其主要目的是達到最短的垃圾回收停頓時間,基於執行緒的標記清除演算法實現,以便在多執行緒併發環境下以最短的垃圾收集停頓時間提高系統的穩定性。
CMS的工作機制相對複雜,垃圾回收過程包含如下4個步驟。
(1)初始標記
只標記和GC Roots直接關聯的物件,速度很快,需要暫停所有工作執行緒。
###(2)併發標記
和使用者執行緒一起工作,執行GC Roots跟蹤標記過程,不需要暫停工作執行緒。
###(3)重新標記
在併發標記過程中使用者執行緒繼續執行,導致在垃圾回收過程中部分物件的狀態發生變化,為了確保這部分物件的狀態正確性,需要對其重新標記並暫停工作執行緒。
###(4)併發清除
和使用者執行緒一起工作,執行清除GC Roots不可達物件的任務,不需要暫停工作執行緒。
CMS垃圾收集器在和使用者執行緒一起工作時(併發標記和併發清除)不需要暫停使用者執行緒,有效縮短了垃圾回收時系統的停頓時間,同時由於CMS垃圾收集器和使用者執行緒一起工作,因此其並行度和效率也有很大提升。CMS收集器的工作流程如圖所示:

## 7.G1垃圾收集器 G1(Garbage First)垃圾收集器為了避免全區域垃圾收集引起的系統停頓,將堆記憶體劃分為大小固定的幾個獨立區域,獨立使用這些區域的記憶體資源並且跟蹤這些區域的垃圾收集進度,同時在後臺維護一個優先順序列表,在垃圾回收過程中根據系統允許的最長垃圾收集時間,優先回收垃圾最多的區域。G1垃圾收集器通過記憶體區域獨立劃分使用和根據不同優先順序回收各區域垃圾的機制,確保了G1垃圾收集器在有限時間內獲得最高的垃圾收集效率。相對於CMS收集器,G1垃圾收集器兩個突出的改進。 - 基於標記整理演算法,不產生記憶體碎片。 - 可以精確地控制停頓時間,在不犧牲吞吐量的前提下實現短停頓垃圾回收。
Java網路程式設計模型
1.阻塞I/O模型
阻塞I/O模型是常見的I/O模型,在讀寫資料時客戶端會發生阻塞。阻塞I/O模型的工作流程為:在使用者執行緒發出I/O請求之後,核心會檢查資料是否就緒,此時使用者執行緒一直阻塞等待記憶體資料就緒;在記憶體資料就緒後,核心將資料複製到使用者執行緒中,並返回I/O執行結果到使用者執行緒,此時使用者執行緒將解除阻塞狀態並開始處理資料。
典型的阻塞I/O模型的例子為data = socket.read(),如果核心資料沒有就緒,Socket執行緒就會一直阻塞在read()中等待核心資料就緒。
2.非阻塞I/O模型
阻塞I/O模型指使用者執行緒在發起一個I/O操作後,無須阻塞便可以馬上得到核心返回的一個結果。如果核心返回的結果為false,則表示核心資料還沒準備好,需要稍後再發起I/O操作。一旦核心中的資料準備好了,並且再次收到使用者執行緒的請求,核心就會立刻將資料複製到使用者執行緒中並將複製的結果通知使用者執行緒。
在非阻塞I/O模型中,使用者執行緒需要不斷詢問核心資料是否就緒,在記憶體資料還未就緒時,使用者執行緒可以處理其他任務,在核心資料就緒後可立即獲取資料並進行相應的操作。典型的非阻塞I/O模型一般如下:
while(true){
data = socket.read();
if(data == true){ // 1.核心資料就緒
//獲取並處理核心資料
break;
}else{ // 2.核心資料未就緒 使用者現成處理其他任務
}
}
## 3.多路複用I/O模型 多路複用I/O模型是多執行緒併發程式設計用得較多的模型,Java NIO就是基於多路複用I/O模型實現的。在多路複用I/O模型中會有一個被稱為Selector的執行緒不斷輪詢多個Socket的狀態,只有在Socket有讀寫事件時,才會通知使用者執行緒進行I/O讀寫操作。
因為在多路複用I/O模型中只需一個執行緒就可以管理多個Socket(阻塞I/O模型和非阻塞 1/O模型需要為每個Socket都建立一個單獨的執行緒處理該Socket上的資料),並且在真正有Socket讀寫事件時才會使用作業系統的I/O資源,大大節約了系統資源。
Java NIO在使用者的每個執行緒中都通過selector.select()查詢當前通道是否有事件到達,如果沒有,則使用者執行緒會一直阻塞。而多路複用I/O模型通過一個執行緒管理多個Socket通道,在Socket有讀寫事件觸發時才會通知使用者執行緒進行I/O讀寫操作。因此,多路複用I/O模型在連線數眾多且訊息體不大的情況下有很大的優勢。尤其在物聯網領域比如車載裝置實時位置、智慧家電狀態等定時上報狀態且位元組數較少的情況下優勢更加明顯,一般一個經過優化後的16核32GB伺服器能承載約10萬臺裝置連線。
非阻塞I/O模型在每個使用者執行緒中都進行Socket狀態檢查,而在多路複用I/O模型中是在系統核心中進行Socket狀態檢查的,這也是多路複用I/O模型比非阻塞I/O模型效率高的原因。
多路複用I/O模型通過在一個Selector執行緒上以輪詢方式檢測在多個Socket上是否有事件到達,並逐個進行事件處理和響應。因此,對於多路複用I/O模型來說,在事件響應體(訊息體)很大時,Selector執行緒就會成為效能瓶頸,導致後續的事件遲遲得不到處理,影響下一輪的事件輪詢。在實際應用中,在多路複用方法體內一般不建議做複雜邏輯運算,只做資料的接收和轉發,將具體的業務操作轉發給後面的業務執行緒處理。
4.訊號驅動I/O模型
在訊號驅動I/O模型中,在使用者執行緒發起一個I/O請求操作時,系統會為該請求對應的Socket註冊一個訊號函式,然後使用者執行緒可以繼續執行其他業務邏輯;在核心資料就緒時,系統會傳送一個訊號到使用者執行緒,使用者執行緒在接收到該訊號後,會在訊號函式中呼叫對應的I/O讀寫操作完成實際的I/O請求操作。
5.非同步I/O模型
在非同步I/O模型中,使用者執行緒會發起一個asynchronous read操作到核心,核心在接收到synchronous read請求後會立刻返回一個狀態,來說明請求是否成功發起,在此過程中使用者執行緒不會發生任何阻塞。接著,核心會等待資料準備完成並將資料複製到使用者執行緒中,在資料複製完成後核心會傳送一個訊號到使用者執行緒,通知使用者執行緒asynchronous讀操作已完成。
在非同步I/O模型中,使用者執行緒不需要關心整個I/O操作是如何進行的,只需發起一個請求,在接收到核心返回的成功或失敗訊號時說明I/O操作已經完成,直接使用資料即可。在非同步I/O模型中,I/O操作的兩個階段(請求的發起、資料的讀取)都是在核心中自動完成的,最終傳送一個訊號告知使用者執行緒I/O操作已經完成,使用者直接使用記憶體寫好的資料即可,不需要再次呼叫I/O函式進行具體的讀寫操作,因此在整個過程中使用者執行緒不會發生阻塞。
在訊號驅動模型中,使用者執行緒接收到訊號便表示資料已經就緒,需要使用者執行緒呼叫I/O函式進行實際的I/O讀寫操作,將資料讀取到使用者執行緒;而在非同步I/O模型中,使用者執行緒接收到訊號便表示I/O操作已經完成(資料已經被複制到使用者執行緒),使用者可以開始使用該資料了。
非同步I/O需要作業系統的底層支援,在Java 7中提供了Asynchronous I/O操作。
6.Java I/O
在整個Java.io包中最重要的是 5個類和 1個介面。5個類指的是File、OutputStream、InputStream、Writer、Reader,1個介面指的是Serializable。具體的使用方法請參考JDK API。
7.Java NIO
Java NIO的實現主要涉及三大核心內容:Selector(選擇器)、Channel(通道)和Buffer(緩衝區)。Selector用於監聽多個Channel的事件,比如連線開啟或資料到達,因此,一個執行緒可以實現對多個資料Channel的管理。傳統I/O基於資料流進行I/O讀寫操作;而Java NIO基於Channel和Buffer進行I/O讀寫操作,並且資料總是被從Channel讀取到Buffer中,或者從Buffer寫入Channel中。
Java NIO和傳統I/O的最大區別如下。
(1)I/O是面向流的,NIO是面向緩衝區的
在面向流的操作中,資料只能在一個流中連續進行讀寫,資料沒有緩衝,因此位元組流無法前後移動。而在NIO中每次都是將資料從一個Channel讀取到一個Buffer中,再從Buffer寫入Channel中,因此可以方便地在緩衝區中進行資料的前後移動等操作。該功能在應用層主要用於資料的粘包、拆包等操作,在網路不可靠的環境下尤為重要。
###(2)傳統I/O的流操作是阻塞模式的,NIO的流操作是非阻塞模式的。
在傳統I/O下,使用者執行緒在呼叫read()或write()進行I/O讀寫操作時,該執行緒將一直被阻塞,直到資料被讀取或資料完全寫入。NIO通過Selector監聽Channel上事件的變化,在Channel上有資料發生變化時通知該執行緒進行讀寫操作。對於讀請求而言,在通道上有可用的資料時,執行緒將進行Buffer的讀操作,在沒有資料時,執行緒可以執行其他業務邏輯操作。對於寫操作而言,在使用一個執行緒執行寫操作將一些資料寫入某通道時,只需將Channel上的資料非同步寫入Buffer即可,Buffer上的資料會被非同步寫入目標Channel上,使用者執行緒不需要等待整個資料完全被寫入目標Channel就可以繼續執行其他業務邏輯。
非阻塞I/O模型中的Selector執行緒通常將I/O的空閒時間用於執行其他通道上的I/O操作,所以一個Selector執行緒可以管理多個輸入和輸出通道,如圖所示。

- Channel
Channel和I/O中的Stream(流)類似,只不過Stream是單向的(例如InputStream、OutputStream),而Channel是雙向的,既可以用來進行讀操作,也可以用來進行寫操作。
NIO中Channel的主要實現有:FileChannel、DatagramChannel、SocketChannel、ServerSocketChannel,分別對應檔案的I/O、UDP、TCP I/O、Socket Client和Socker Server操作。
#### - Buffer Buffer實際上是一個容器,其內部通過一個連續的位元組陣列儲存I/O上的資料。在NIO中,Channel在檔案、網路上對資料的讀取或寫入都必須經過Buffer。
如圖所示,客戶端在向服務端傳送資料時,必須先將資料寫入Buffer中,然後將Buffer中的資料寫到服務端對應的Channel上。服務端在接收資料時必須通過Channel將資料讀入Buffer中,然後從Buffer中讀取資料並處理。

#### -Selector Selector用於檢測在多個註冊的Channel上是否有I/O事件發生,並對檢測到的I/O事件進行相應的響應和處理。因此通過一個Selector執行緒就可以實現對多個Channel的管理,不必為每個連線都建立一個執行緒,避免執行緒資源的浪費和多執行緒之間的上下文切換導致的開銷。同時,Selector只有在Channel上有讀寫事件發生時,才會呼叫I/O函式進行讀寫操作,可極大減少系統開銷,提高系統的併發量。
# JVM的類載入機制 JVM的類載入分為 5個階段:載入、驗證、準備、解析、初始化。在類初始化完成後就可以使用該類的資訊,在一個類不再被需要時可以從JVM中解除安裝 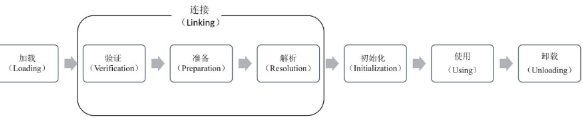
JVM的類載入階段
1.載入
指JVM讀取Class檔案,並且根據Class檔案描述建立java.lang.Class物件的過程。類載入過程主要包含將Class檔案讀取到執行時區域的方法區內,在堆中建立java.lang.Class物件,並封裝類在方法區的資料結構的過程,在讀取Class檔案時既可以通過檔案的形式讀取,也可以通過jar包、war包讀取,還可以通過代理自動生成Class或其他方式讀取。
2. 驗證
主要用於確保Class檔案符合當前虛擬機器的要求,保障虛擬機器自身的安全,只有通過驗證的Class檔案才能被JVM載入。
3. 準備
主要工作是在方法區中為類變數分配記憶體空間並設定類中變數的初始值。初始值指不同資料型別的預設值,這裡需要注意final型別的變數和非final型別的變數在準備階段的資料初始化過程不同。比如一個成員變數的定義如下:
public static long value = 1000;
在以上程式碼中,靜態變數value在準備階段的初始值是 0,將value設定為1000的動作是在物件初始化時完成的,因為JVM在編譯階段會將靜態變數的初始化操作定義在構造器中。但是,如果將變數value宣告為final型別:
public static final int value = 1000;
則JVM在編譯階段後會為final型別的變數value生成其對應的ConstantValue屬性,虛擬機器在準備階段會根據ConstantValue屬性將value賦值為1000。
4.解析
JVM會將常量池中的符號引用替換為直接引用。
5.初始化
主要通過執行類構造器的方法為類進行初始化。方法是在編譯階段由編譯器自動收集類中靜態語句塊和變數的賦值操作組成的。JVM規定,只有在父類的方法都執行成功後,子類中的方法才可以被執行。在一個類中既沒有靜態變數賦值操作也沒有靜態語句塊時,編譯器不會為該類生成方法。
在發生以下幾種情況時,JVM不會執行類的初始化流程。
-
常量在編譯時會將其常量值存入使用該常量的類的常量池中,該過程不需要呼叫常量所在的類,因此不會觸發該常量類的初始化。
-
在子類引用父類的靜態欄位時,不會觸發子類的初始化,只會觸發父類的初始化。
-
定義物件陣列,不會觸發該類的初始化。
-
在使用類名獲取Class物件時不會觸發類的初始化。
-
在使用Class.forName載入指定的類時,可以通過initialize引數設定是否需要對類進行初始化。
-
在使用ClassLoader預設的loadClass方法載入類時不會觸發該類的初始化。
類載入器

JVM提供了 3種類載入器,分別是啟動類載入器、擴充套件類載入器和應用程式類載入器
(1)啟動類載入器
負責載入Java_HOME/lib目錄中的類庫,或通過-Xbootclasspath引數指定路徑中被虛擬機器認可的類庫。
###(2)擴充套件類載入器
負責載入Java_HOME/lib/ext目錄中的類庫,或通過java.ext.dirs系統變數載入指定路徑中的類庫。
###(3)應用程式類載入器
負責載入使用者路徑(classpath)上的類庫。除了上述 3種類載入器,我們也可以通過繼承java.lang.ClassLoader實現自定義的類載入器。
雙親委派機制
JVM通過雙親委派機制對類進行載入。雙親委派機制指一個類在收到類載入請求後不會嘗試自己載入這個類,而是把該類載入請求向上委派給其父類去完成,其父類在接收到該類載入請求後又會將其委派給自己的父類,以此類推,這樣所有的類載入請求都被向上委派到啟動類載入器中。若父類載入器在接收到類載入請求後發現自己也無法載入該類(通常原因是該類的Class檔案在父類的類載入路徑中不存在),則父類會將該資訊反饋給子類並向下委派子類載入器載入該類,直到該類被成功載入,若找不到該類,則JVM會丟擲ClassNotFoud異常。
雙親委派類載入機制的類載入流程如下,如圖所示

(1)將自定義載入器掛載到應用程式類載入器。
(2)應用程式類載入器將類載入請求委託給擴充套件類載入器。
(3)擴充套件類載入器將類載入請求委託給啟動類載入器。
(4)啟動類載入器在載入路徑下查詢並載入Class檔案,如果未找到目標Class檔案,則交由擴充套件類載入器載入。
(5)擴充套件類載入器在載入路徑下查詢並載入Class檔案,如果未找到目標Class檔案,則交由應用程式類載入器載入。
(6)應用程式類載入器在載入路徑下查詢並載入Class檔案,如果未找到目標Class檔案,則交由自定義載入器載入。
(7)在自定義載入器下查詢並載入使用者指定目錄下的Class檔案,如果在自定義載入路徑下未找到目標Class檔案,則丟擲ClassNotFoud異常。
OSGI
OSGI(Open Service Gateway Initiative)是Java動態化模組化系統的一系列規範,旨在為實現Java程式的模組化程式設計提供基礎條件。基於OSGI的程式可以實現模組級的熱插拔功能,在程式升級更新時,可以只針對需要更新的程式進行停用和重新安裝,極大提高了系統升級的安全性和便捷性。
OSGI提供了一種面向服務的架構,該架構為元件提供了動態發現其他元件的功能,這樣無論是加入元件還是解除安裝元件,都能被系統的其他元件感知,以便各個元件之間能更好地協調工作。
OSGI不但定義了模組化開發的規範,還定義了實現這些規範所依賴的服務與架構,市場上也有成熟的框架對其進行實現和應用,但只有部分應用適合採用OSGI方式,因為它為了實現動態模組,不再遵循JVM類載入雙親委派機制和其他JVM規範,在安全性上有所犧牲。
相關文章
- Java 虛擬機器之二:Java語言的執行機制Java虛擬機
- Dalvik虛擬機器、Java虛擬機器與ART虛擬機器虛擬機Java
- 深入學習Java虛擬機器——虛擬機器位元組碼執行引擎Java虛擬機
- Java虛擬機器:記憶體管理與執行引擎Java虛擬機記憶體
- java虛擬機器類載入機制Java虛擬機
- Java 虛擬機器類載入機制Java虛擬機
- Java虛擬機器08——Java記憶體模型與執行緒Java虛擬機記憶體模型執行緒
- Java虛擬機器:Jvm概念和原理詳解以及GC機制的分析Java虛擬機JVMGC
- Java虛擬機器09——執行緒安全與鎖優化Java虛擬機執行緒優化
- [深入理解Java虛擬機器]執行緒Java虛擬機執行緒
- Java虛擬機器-執行時資料區Java虛擬機
- 虛擬機器的概念虛擬機
- Java虛擬機器(六):類載入機制Java虛擬機
- Java 虛擬機器垃圾收集機制詳解Java虛擬機
- Java 虛擬機器之四:Java類載入機制Java虛擬機
- java虛擬機器和Dalvik虛擬機器Java虛擬機
- Android 虛擬機器 Vs Java 虛擬機器Android虛擬機Java
- 弄清Java虛擬機器GC的執行過程Java虛擬機GC
- Java虛擬機器--方法區(執行時常量池)Java虛擬機
- java虛擬機器——執行時資料區域Java虛擬機
- Java虛擬機器系列之垃圾回收機制(2)Java虛擬機
- JVM(三)-java虛擬機器類載入機制JVMJava虛擬機
- linux虛擬機器執行機必安裝Linux虛擬機
- 深入理解虛擬機器之虛擬機器位元組碼執行引擎虛擬機
- Java 虛擬機器執行時資料區詳解Java虛擬機
- 關於Java虛擬機器執行時資料區域的總結Java虛擬機
- 深入理解Java虛擬機器 - 類載入機制Java虛擬機
- 深入理解Java虛擬機器(類載入機制)Java虛擬機
- 深入理解Java虛擬機器 --- 類載入機制Java虛擬機
- 【Java虛擬機器規範】JVM類載入機制Java虛擬機JVM
- 深入理解虛擬機器之虛擬機器類載入機制虛擬機
- 虛擬機器類載入機制虛擬機
- 【Java 虛擬機器筆記】記憶體分配策略相關整理Java虛擬機筆記記憶體
- Java虛擬機器垃圾回收相關知識點全梳理(上)Java虛擬機
- VirtureBox如何執行VM的虛擬機器虛擬機
- 虛擬機器位元組碼執行引擎虛擬機
- Java虛擬機器執行時資料區域劃分Java虛擬機
- Golang實現JAVA虛擬機器-執行時資料區GolangJava虛擬機