什麼是網路爬蟲?有什麼用?怎麼爬?
以前常聽見爬取這個名詞,今天搜了搜,展示如下:
導讀:網路爬蟲也叫做網路機器人,可以代替人們自動地在網際網路中進行資料資訊的採集與整理。在大資料時代,資訊的採集是一項重要的工作,如果單純靠人力進行資訊採集,不僅低效繁瑣,蒐集的成本也會提高。
此時,我們可以使用網路爬蟲對資料資訊進行自動採集,比如應用於搜尋引擎中對站點進行爬取收錄,應用於資料分析與挖掘中對資料進行採集,應用於金融分析中對金融資料進行採集,除此之外,還可以將網路爬蟲應用於輿情監測與分析、目標客戶資料的收集等各個領域。
當然,要學習網路爬蟲開發,首先需要認識網路爬蟲,本文將帶領大家一起認識幾種典型的網路爬蟲,並瞭解網路爬蟲的各項常見功能。
01 什麼是網路爬蟲
隨著大資料時代的來臨,網路爬蟲在網際網路中的地位將越來越重要。網際網路中的資料是海量的,如何自動高效地獲取網際網路中我們感興趣的資訊併為我們所用是一個重要的問題,而爬蟲技術就是為了解決這些問題而生的。
我們感興趣的資訊分為不同的型別:如果只是做搜尋引擎,那麼感興趣的資訊就是網際網路中儘可能多的高質量網頁;如果要獲取某一垂直領域的資料或者有明確的檢索需求,那麼感興趣的資訊就是根據我們的檢索和需求所定位的這些資訊,此時,需要過濾掉一些無用資訊。前者我們稱為通用網路爬蟲,後者我們稱為聚焦網路爬蟲。
1. 初識網路爬蟲
網路爬蟲又稱網路蜘蛛、網路螞蟻、網路機器人等,可以自動化瀏覽網路中的資訊,當然瀏覽資訊的時候需要按照我們制定的規則進行,這些規則我們稱之為網路爬蟲演算法。使用Python可以很方便地編寫出爬蟲程式,進行網際網路資訊的自動化檢索。
搜尋引擎離不開爬蟲,比如百度搜尋引擎的爬蟲叫作百度蜘蛛(Baiduspider)。百度蜘蛛每天會在海量的網際網路資訊中進行爬取,爬取優質資訊並收錄,當使用者在百度搜尋引擎上檢索對應關鍵詞時,百度將對關鍵詞進行分析處理,從收錄的網頁中找出相關網頁,按照一定的排名規則進行排序並將結果展現給使用者。
在這個過程中,百度蜘蛛起到了至關重要的作用。那麼,如何覆蓋網際網路中更多的優質網頁?又如何篩選這些重複的頁面?這些都是由百度蜘蛛爬蟲的演算法決定的。採用不同的演算法,爬蟲的執行效率會不同,爬取結果也會有所差異。
所以,我們在研究爬蟲的時候,不僅要了解爬蟲如何實現,還需要知道一些常見爬蟲的演算法,如果有必要,我們還需要自己去制定相應的演算法,在此,我們僅需要對爬蟲的概念有一個基本的瞭解。
除了百度搜尋引擎離不開爬蟲以外,其他搜尋引擎也離不開爬蟲,它們也擁有自己的爬蟲。比如360的爬蟲叫360Spider,搜狗的爬蟲叫Sogouspider,必應的爬蟲叫Bingbot。
如果想自己實現一款小型的搜尋引擎,我們也可以編寫出自己的爬蟲去實現,當然,雖然可能在效能或者演算法上比不上主流的搜尋引擎,但是個性化的程度會非常高,並且也有利於我們更深層次地理解搜尋引擎內部的工作原理。
大資料時代也離不開爬蟲,比如在進行大資料分析或資料探勘時,我們可以去一些比較大型的官方站點下載資料來源。但這些資料來源比較有限,那麼如何才能獲取更多更高質量的資料來源呢?此時,我們可以編寫自己的爬蟲程式,從網際網路中進行資料資訊的獲取。所以在未來,爬蟲的地位會越來越重要。

2. 為什麼要學網路爬蟲
我們初步認識了網路爬蟲,但是為什麼要學習網路爬蟲呢?要知道,只有清晰地知道我們的學習目的,才能夠更好地學習這一項知識,我們將會為大家分析一下學習網路爬蟲的原因。
當然,不同的人學習爬蟲,可能目的有所不同,在此,我們總結了4種常見的學習爬蟲的原因。
1)學習爬蟲,可以私人訂製一個搜尋引擎,並且可以對搜尋引擎的資料採集工作原理進行更深層次地理解。
有的朋友希望能夠深層次地瞭解搜尋引擎的爬蟲工作原理,或者希望自己能夠開發出一款私人搜尋引擎,那麼此時,學習爬蟲是非常有必要的。
簡單來說,我們學會了爬蟲編寫之後,就可以利用爬蟲自動地採集網際網路中的資訊,採集回來後進行相應的儲存或處理,在需要檢索某些資訊的時候,只需在採集回來的資訊中進行檢索,即實現了私人的搜尋引擎。
當然,資訊怎麼爬取、怎麼儲存、怎麼進行分詞、怎麼進行相關性計算等,都是需要我們進行設計的,爬蟲技術主要解決資訊爬取的問題。
2)大資料時代,要進行資料分析,首先要有資料來源,而學習爬蟲,可以讓我們獲取更多的資料來源,並且這些資料來源可以按我們的目的進行採集,去掉很多無關資料。
在進行大資料分析或者進行資料探勘的時候,資料來源可以從某些提供資料統計的網站獲得,也可以從某些文獻或內部資料中獲得,但是這些獲得資料的方式,有時很難滿足我們對資料的需求,而手動從網際網路中去尋找這些資料,則耗費的精力過大。
此時就可以利用爬蟲技術,自動地從網際網路中獲取我們感興趣的資料內容,並將這些資料內容爬取回來,作為我們的資料來源,從而進行更深層次的資料分析,並獲得更多有價值的資訊。

3)對於很多SEO從業者來說,學習爬蟲,可以更深層次地理解搜尋引擎爬蟲的工作原理,從而可以更好地進行搜尋引擎最佳化。
既然是搜尋引擎最佳化,那麼就必須要對搜尋引擎的工作原理非常清楚,同時也需要掌握搜尋引擎爬蟲的工作原理,這樣在進行搜尋引擎最佳化時,才能知己知彼,百戰不殆。
4)從就業的角度來說,爬蟲工程師目前來說屬於緊缺人才,並且薪資待遇普遍較高,所以,深層次地掌握這門技術,對於就業來說,是非常有利的。
有些朋友學習爬蟲可能為了就業或者跳槽。從這個角度來說,爬蟲工程師方向是不錯的選擇之一,因為目前爬蟲工程師的需求越來越大,而能夠勝任這方面崗位的人員較少,所以屬於一個比較緊缺的職業方向,並且隨著大資料時代的來臨,爬蟲技術的應用將越來越廣泛,在未來會擁有很好的發展空間。
除了以上為大家總結的4種常見的學習爬蟲的原因外,可能你還有一些其他學習爬蟲的原因,總之,不管是什麼原因,理清自己學習的目的,就可以更好地去研究一門知識技術,並堅持下來。
3. 網路爬蟲的組成
接下來,我們將介紹網路爬蟲的組成。網路爬蟲由控制節點、爬蟲節點、資源庫構成。
圖1-1所示是網路爬蟲的控制節點和爬蟲節點的結構關係。
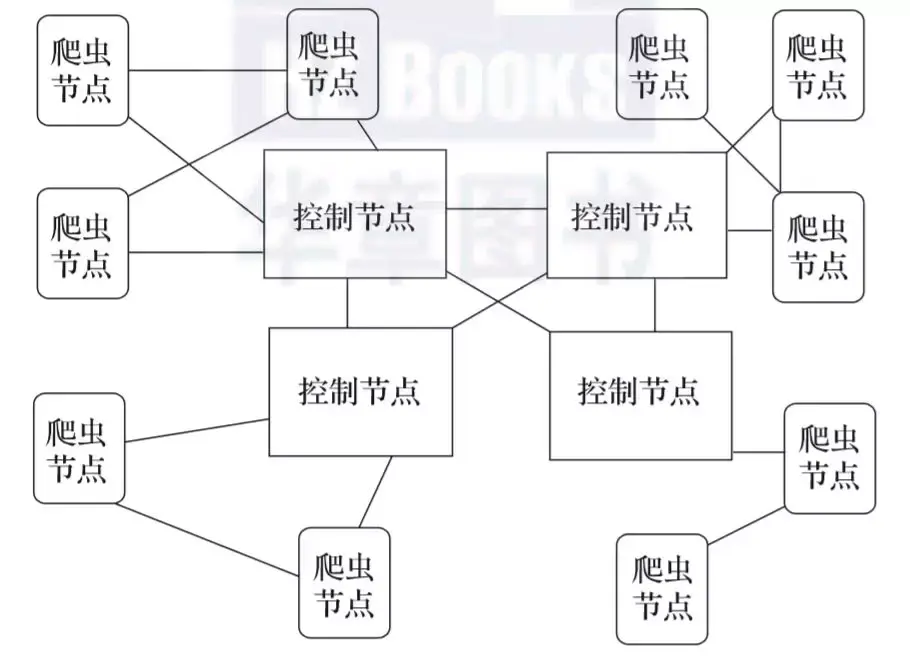
▲圖1-1 網路爬蟲的控制節點和爬蟲節點的結構關係
可以看到,網路爬蟲中可以有多個控制節點,每個控制節點下可以有多個爬蟲節點,控制節點之間可以互相通訊,同時,控制節點和其下的各爬蟲節點之間也可以進行互相通訊,屬於同一個控制節點下的各爬蟲節點間,亦可以互相通訊。
控制節點,也叫作爬蟲的中央控制器,主要負責根據URL地址分配執行緒,並呼叫爬蟲節點進行具體的爬行。
爬蟲節點會按照相關的演算法,對網頁進行具體的爬行,主要包括下載網頁以及對網頁的文字進行處理,爬行後,會將對應的爬行結果儲存到對應的資源庫中。