ZooKeeper淺談
1.什麼是Zookeeper
Zookeeper 是一個分散式協調服務的開源框架。主要作用是為分散式系統提供協調服務,包括但不限於:分散式鎖、統一命名服務、配置管理、負載均衡、主控伺服器選舉以及主從切換等。
ZooKeeper本質上是一個分散式的小檔案儲存系統。提供類似與檔案系統目錄樹方式的資料儲存,並且可以對樹中的節點進行有效管理。從而用來維護和監控儲存的資料的狀態變化。透過監控這些資料狀態的變化,實現基於資料的叢集管理。
2.Zookeeper = 檔案系統 + 監聽通知機制 + ACL
2.1 檔案系統
Zookeeper維護一個類似檔案系統的資料結構,每一個子目錄項都被稱作為znode(目錄節點),和檔案系統一樣,我們能夠自由的對一個znode進行CRUD,也可以在znode下進行子znode的CRUD,唯一不同的是,znode是可以儲存資料的。
節點型別:P持久化、PS持久化順序、E臨時、ES臨時順序
2.2 監聽通知機制
簡單來說:client 註冊監聽它所關心的節點,當該節點發生變化(節點被改變、被刪除、其子節點有增刪改情況)時,zkServer會透過watcher監聽機制將訊息推送給client。
2.3 ACL(訪問控制列表)
zookeeper在分散式系統中承擔中介軟體的作用,它管理的每一個節點上都可能儲存著重要的資訊,因為應用可以讀取到任意節點,這就可能造成安全問題,ACL的作用就是幫助zookeeper實現許可權控制。zookeeper的許可權控制基於節點,每個znode可以有不同的許可權。父子節點之間許可權沒有關係。
一個 ACL 許可權設定通常可以分為 3 部分,分別是:許可權模式(Scheme)、授權物件(ID)、許可權資訊(Permission)。最終組成一條例如“scheme :id :permission”格式的 ACL 請求資訊。
3.ZooKeeper Session
client請求和服務端建立連線,服務端會保留和標記當前client的session,包含 session過期時間、sessionId ,然後服務端開始在session過期時間的基礎上倒數計時,在這段時間內,client需要向server傳送心跳包,目的是讓server重置session過期時間。
如果因為網路狀態不好,client和Server失去聯絡,client會停留在當前狀態,會嘗試主動再次連線Zookeeper Server。client不能宣稱自己的session expired,session expired是由Zookeeper Server來決定的,client可以選擇自己主動關閉session。
session狀態變換:
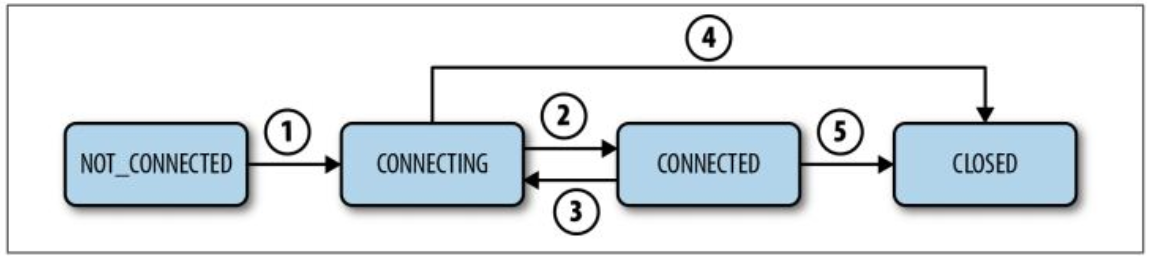
4.Zookeeper Feature
- 最終一致性:client不論連線到哪個Server,展示給它都是同一個檢視,這是zookeeper最重要的效能。
- 可靠性:具有簡單、健壯、良好的效能,如果訊息被一臺伺服器接受,那麼它將被所有的伺服器接受。即如果client對某一臺server上的資料進行了CUD,那麼zookeeper叢集會對其他所有的server資料進行同步。
- 實時性:Zookeeper保證客戶端將在一個時間間隔範圍內獲得伺服器的更新資訊,或者伺服器失效的資訊。但由於網路延時等原因,Zookeeper不能保證兩個客戶端能同時得到剛更新的資料,如果需要最新資料,應該在讀資料之前呼叫sync()介面。
- 等待無關(wait-free):慢的或者失效的client不得干預快速的client的請求,使得每個client都能有效的等待。
- 原子性:更新只能成功或者失敗,沒有中間狀態。
- 順序性:包括全域性有序和偏序兩種:全域性有序是指如果在一臺伺服器上訊息a在訊息b前釋出,則在所有Server上訊息a都將在訊息b前被髮布;偏序是指如果一個訊息b在訊息a後被同一個傳送者釋出,a必將排在b前面。
5.ZooKeeper Data
Zookeeper會維護一個具有層次關係的資料結構,它非常類似於一個標準的檔案系統。
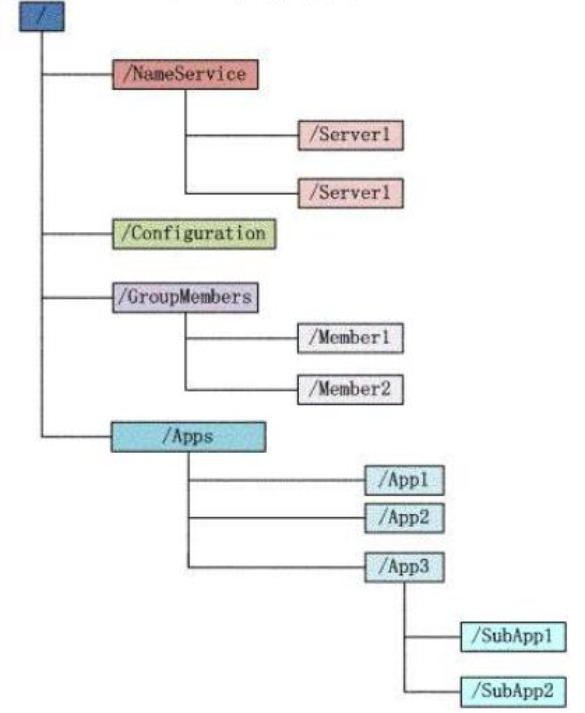
Zookeeper這種資料結構有如下這些特點:
1)每個子目錄項如NameService都被稱作為znode,這個znode是被它所在的路徑唯一標識,如Server1這個znode的標識為/NameService/Server1。
2)znode可以有子節點目錄,並且每個znode可以儲存資料,注意EPHEMERAL(臨時的)型別的目錄節點不能有子節點目錄。
3)znode是有版本的(version),每個znode中儲存的資料可以有多個版本,也就是一個訪問路徑中可以儲存多份資料,version號自動增加。
4)znode的型別:
-
Persistent 節點,一旦被建立,便不會意外丟失,即使伺服器全部重啟也依然存在。每個 Persist 節點即可包含資料,也可包含子節點。
-
Ephemeral 節點,在建立它的客戶端與伺服器間的 Session 結束時自動被刪除。伺服器重啟會導致 Session 結束,因此 Ephemeral 型別的 znode 此時也會自動刪除。
-
Non-sequence 節點,多個客戶端同時建立同一個 Non-sequence 節點時,只有一個可建立成功,其它勻失敗。並且建立出的節點名稱與建立時指定的節點名完全一樣。
-
Sequence 節點,建立出的節點名在指定的名稱之後帶有10位10進位制數的序號。多個客戶端建立同一名稱的節點時,都能建立成功,只是序號不同。
5)znode可以被監控,包括這個目錄節點中儲存的資料的修改,子節點目錄的變化等,一旦變化可以通知設定監控的客戶端,這個是Zookeeper的核心特性,Zookeeper的很多功能都是基於這個特性實現的。
6)ZXID:每次對Zookeeper的狀態的改變都會產生一個zxid(ZooKeeper Transaction Id),zxid是全域性有序的,如果zxid1小於zxid2,則zxid1在zxid2之前發生。
6. ZooKeeper Watch
Zookeeper所有的讀操作getData(), getChildren()和 exists()都可以設定監視(watch),監視事件可以理解為一次性的觸發器。
6.1 一次性觸發
當設定監視的資料發生改變時,該監視事件會被髮送到客戶端,例如,如果客戶端呼叫了getData("/znode1", true) 並且稍後 /znode1 節點上的資料發生了改變或者被刪除了,客戶端將會獲取到 /znode1 發生變化的監視事件,而如果 /znode1 再一次發生了變化,除非客戶端再次對/znode1 設定監視,否則客戶端不會收到事件通知。
6.2 傳送至客戶端
Watch的通知事件是從伺服器傳送給客戶端的,是非同步的,這就表明不同的客戶端收到的Watch的時間可能不同,但是ZooKeeper有保證:當一個客戶端在看到Watch事件之前是不會看到結點資料的變化的。例如:A=3,此時在上面設定了一次Watch,如果A突然變成4了,那麼客戶端會先收到Watch事件的通知,然後才會看到A=4。
Zookeeper客戶端和服務端是透過 socket 進行通訊的,由於網路存在故障,所以監視事件很有可能不會成功地到達客戶端,監視事件是非同步傳送至監視者的,Zookeeper 本身提供了順序保證(ordering guarantee):即客戶端只有首先看到了監視事件後,才會感知到它所設定監視的znode發生了變化。
6.3 被設定 watch 的資料
這意味著znode節點本身具有不同的改變方式。你也可以想象 Zookeeper 維護了兩條監視連結串列:資料監視和子節點監視 getData() 和exists()設定資料監視,getChildren()設定子節點監視。或者你也可以想象 Zookeeper 設定的不同監視返回不同的資料,getData() 和 exists() 返回znode節點的相關資訊,而getChildren() 返回子節點列表。因此,setData() 會觸發設定在某一節點上所設定的資料監視(假定資料設定成功),而一次成功的create() 操作則會出發當前節點上所設定的資料監視以及父節點的子節點監視。一次成功的 delete操作將會觸發當前節點的資料監視和子節點監視事件,同時也會觸發該節點父節點的child watch。
6.4 watch觸發的情況
可以註冊watcher的方法:getData、exists、getChildren。
可以觸發watcher的方法(操作):create、delete、setData。
New ZooKeeper時註冊的watcher叫default watcher,它不是一次性的,只對client的連線狀態變化作出反應。
操作會產生事件,事件會觸發watcher。
操作產生事件的型別:
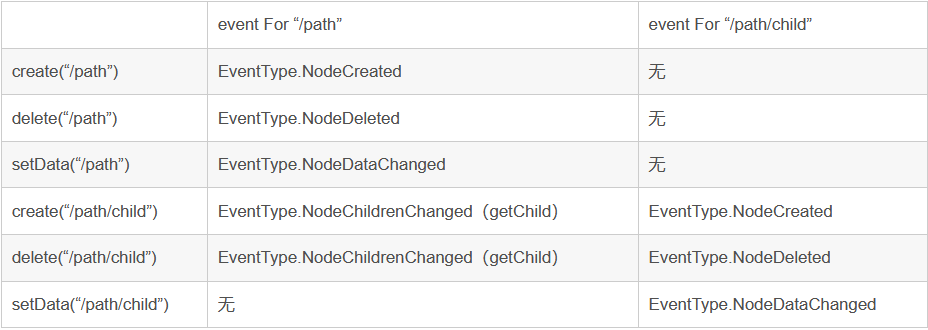
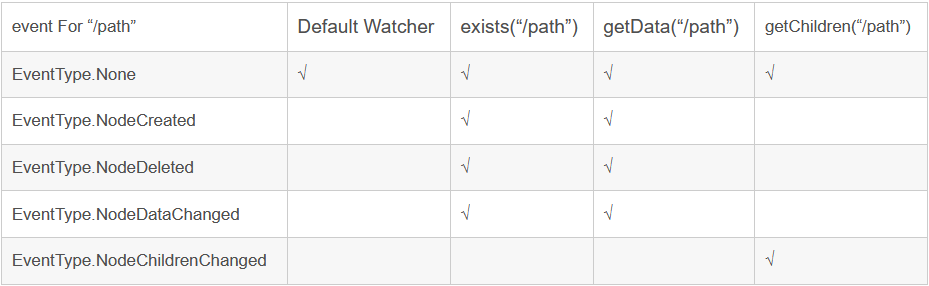
事件觸發對應的watcher:
7. Zookeeper Characher
在zookeeper的叢集中,各個節點共有下面3種角色和4種狀態:
- 角色:leader,follower,observer
- 狀態:leading,following,observing,looking
Zookeeper的核心是原子廣播(Zab),這個機制保證了各個Server之間的同步。實現這個機制的協議叫做Zab協議(ZooKeeper Atomic Broadcast protocol)。Zab協議有兩種模式,它們分別是恢復模式(Recovery選主)和廣播模式(Broadcast同步)。當服務啟動或者在領導者崩潰後,Zab就進入了恢復模式,當領導者被選舉出來,且大多數Server完成了和leader的狀態同步以後,恢復模式就結束了。狀態同步保證了leader和Server具有相同的系統狀態。
為了保證事務的順序一致性,zookeeper採用了遞增的事務id號(zxid)來標識事務。所有的提議(proposal)都在被提出的時候加上了zxid。實現中zxid是一個64位的數字,它高32位是epoch用來標識leader關係是否改變,每次一個leader被選出來,它都會有一個新的epoch,標識當前屬於那個leader的統治時期。低32位用於遞增計數。
Leader
Leader是整個zk叢集的核心,負責響應所有對Zookeeper狀態變更的請求。它會將每個狀態更新請求進行排序和編號,以便保證整個叢集內部訊息處理的FIFO。
- 處理事務請求(CUD)和非事務請求。Leader是zk中唯一一個有權對事務請求進行排程和處理的角色,能夠保證叢集事務處理的順序。
Follower
-
處理client非事務請求,如果client發出的請求是事務請求,會轉發給Leader。
-
參與叢集對Leader選舉投票。
-
參與事務請求 Proposal 的投票(leader發起的提案,要求follower投票,需要半數以上follower節點透過,leader才會commit資料);
在ZooKeeper的實現中,每一個事務請求都需要叢集中過半機器投票才能被真正應用到ZooKeeper的記憶體中去,這個投票與統計過程被稱為Proposal流程。
Observer
Observer除了不參與Leader選舉投票外,與Follower作用相同。Observer通常用於在不影響叢集事務處理能力的前提下,提升叢集的非事務處理能力。簡單來說,observer可以在不影響叢集寫(CUD)效能的情況下,提升叢集讀(R)效能,並且因為它不參與投票,所以他們不屬於ZooKeeper叢集的關鍵部位,即使他們failed,或者從叢集中斷開,也不會影響叢集的可用性。
引入觀察者的一個主要原因是提高讀請求的可擴充套件性。透過加入多個觀察者,我們可以在不犧牲寫操作的吞吐率的前提下服務更多的讀操作。但是引入觀察者也不是完全沒有開銷,每一個新加入的觀察者將對應於每一個已提交事務點引入的一條額外訊息。
採用觀察者的另外一個原因是進行跨多個資料中心部署。由於資料中心之間的網路連結延時,將伺服器分散於多個資料中心將明顯地降低系統的速度。引入觀察者後,更新請求能夠先以高吞吐量和低延遲的方式在一個資料中心內執行,接下來再傳播到異地的其他資料中心得到執行。
每個Server在工作過程中有4種狀態:
- LOOKING:當前Server不知道leader是誰,正在搜尋。
- LEADING:當前Server即為選舉出來的leader。
- FOLLOWING:leader已經選舉出來,當前Server與之同步。
- OBSERVING:observer的行為在大多數情況下與follower完全一致,但是他們不參加選舉和投票,而僅僅接受(observing)選舉和投票的結果。
8. ZooKeeper Election
當leader崩潰或者leader失去大多數的follower,這時候zk進入恢復模式,恢復模式需要重新選舉出一個新的leader,讓所有的Server都恢復到一個正確的狀態。Zk的選舉演算法有兩種:一種是基於basic paxos實現的,另外一種是基於fast paxos演算法實現的。系統預設的選舉演算法為fast paxos。
basic paxos流程:
- 選舉執行緒由當前Server發起選舉的執行緒擔任,其主要功能是對投票結果進行統計,並選出推薦的Server;
- 選舉執行緒首先向所有Server發起一次詢問(包括自己);
- 選舉執行緒收到回覆後,驗證是否是自己發起的詢問(驗證zxid是否一致),然後獲取對方的id(myid),並儲存到當前詢問物件列表中,最後獲取對方提議的leader相關資訊(id,zxid),並將這些資訊儲存到當次選舉的投票記錄表中;
- 收到所有Server回覆以後,就計算出zxid最大的那個Server,並將這個Server相關資訊設定成下一次要投票的Server;
- 執行緒將當前zxid最大的Server設定為當前Server要推薦的Leader,如果此時獲勝的Server獲得n/2 + 1的Server票數,設定當前推薦的leader為獲勝的Server,將根據獲勝的Server相關資訊設定自己的狀態,否則,繼續這個過程,直到leader被選舉出來。
透過流程分析我們可以得出:第一輪發起詢問找出最大的zxid,第二輪詢問投這個最大的zxid的server。比如:zxid為1到7的7個server參與選舉,由5擔任,每個server收到5的zxid和sid,各自比較更新投票資訊,1-4更新為5,6-7保持自己的zxid不變,5經過統計後得到最大zxid為7,再次發起詢問投票7,此時將得到半數以上投票,則選舉結束。
每個Server啟動後都會重複以上流程。在恢復模式下,如果是剛從崩潰狀態恢復的或者剛啟動的server還會從磁碟快照中恢復資料和會話資訊,zk會記錄事務日誌並定期進行快照,方便在恢復時進行狀態恢復。
fast paxos流程是在選舉過程中,某Server首先向所有Server提議自己要成為leader,當其它Server收到提議以後,解決epoch和zxid的衝突,並接受對方的提議,然後向對方傳送接受提議完成的訊息,重複這個流程,最後一定能選舉出Leader。
9. ZooKeeper Work
9.1 Leader工作流程
Leader主要有三個功能:
- 恢復資料;
- 維持與follower的心跳,接收follower請求並判斷follower的請求訊息型別;
- follower的訊息型別主要有PING訊息、REQUEST訊息、ACK訊息、REVALIDATE訊息,根據不同的訊息型別,進行不同的處理。
- PING訊息是指follower的心跳資訊;REQUEST訊息是follower傳送的提議資訊,包括寫請求及同步請求;
- ACK訊息是follower的對提議的回覆,超過半數的follower透過,則commit該提議;
- REVALIDATE訊息是用來延長SESSION有效時間。
9.2 Follower工作流程
Follower主要有四個功能:
- 向Leader傳送請求(PING訊息、REQUEST訊息、ACK訊息、REVALIDATE訊息);
- 接收Leader訊息並進行處理;
- 接收Client的請求,如果為寫請求,傳送給Leader進行投票;
- 返回Client結果。
Follower的訊息迴圈處理如下幾種來自Leader的訊息:
- PING訊息:心跳訊息
- PROPOSAL訊息:Leader發起的提案,要求Follower投票
- COMMIT訊息:伺服器端最新一次提案的資訊
- UPTODATE訊息:表明同步完成
- REVALIDATE訊息:根據Leader的REVALIDATE結果,關閉待revalidate的session還是允許其接受訊息
- SYNC訊息:返回SYNC結果到客戶端,這個訊息最初由客戶端發起,用來強制得到最新的更新。
Zab協議
Zookeeper Server接收到一次request,如果是follower,會轉發給leader,Leader執行請求並透過Transaction的形式廣播這次執行。Zookeeper叢集如何決定一個Transaction是否被commit執行?
透過“兩段提交協議”(a two-phase commit):
- Leader給所有的follower傳送一個PROPOSAL訊息。
- 一個follower接收到這次PROPOSAL訊息,寫到磁碟,傳送給leader一個ACK訊息,告知已經收到。
- 當Leader收到法定人數(quorum)的follower的ACK時候,傳送commit訊息執行。
Zab協議保證:
- 如果leader以T1和T2的順序廣播,那麼所有的Server必須先執行T1,再執行T2。
- 如果任意一個Server以T1、T2的順序commit執行,其他所有的Server也必須以T1、T2的順序執行。
“兩段提交協議”最大的問題是如果Leader傳送了PROPOSAL訊息後crash或暫時失去連線,會導致整個叢集處在一種不確定的狀態(follower不知道該放棄這次提交還是執行提交)。Zookeeper這時會選出新的leader,請求處理也會移到新的leader上,不同的leader由不同的epoch標識。切換Leader時,需要解決下面兩個問題:
-
不要忘記已傳送的資訊
Leader在COMMIT投遞到任何一臺follower之前crash,只有它自己commit了。新Leader必須保證這個事務也必須commit。
-
放棄跳過的訊息
Leader產生某個proposal,但是在crash之前,沒有follower看到這個proposal。該server恢復時,必須丟棄這個proposal。
Zookeeper會盡量保證不會同時有2個活動的Leader,因為2個不同的Leader會導致叢集處在一種不一致的狀態,所以Zab協議同時保證:
- 在新的leader廣播Transaction之前,先前Leader commit的Transaction都會先執行。
- 在任意時刻,都不會有2個Server同時有法定人數(quorum)的支持者。
這裡的quorum是一半以上的Server數目,確切的說是有投票權力的Server(不包括Observer)。
讀寫流程
1)讀流程分析
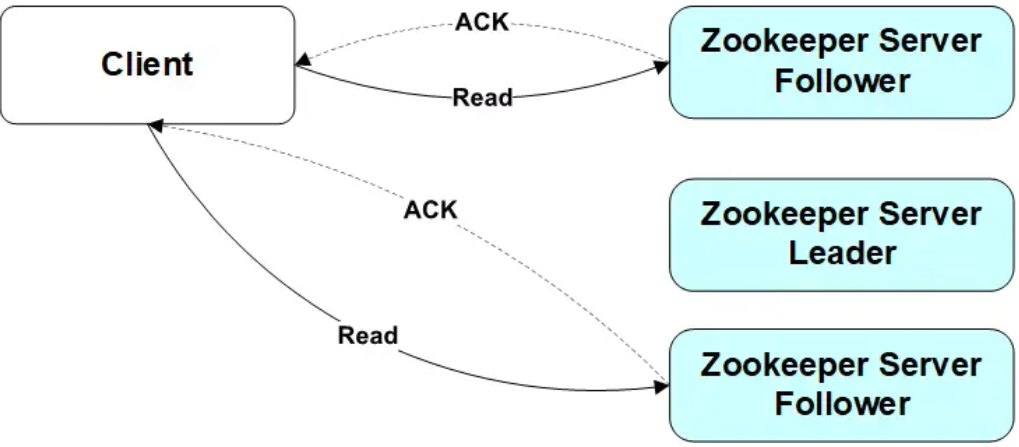
因為ZooKeeper叢集中所有的server節點都擁有相同的資料,所以讀的時候可以在任意一臺server節點上,客戶端連線到叢集中某一節點,讀請求,然後直接返回。當然因為ZooKeeper協議的原因(一半以上的server節點都成功寫入了資料,這次寫請求便算是成功),讀資料的時候可能會讀到資料不是最新的server節點,所以比較推薦使用watch機制,在資料改變時,及時感應到。
2)寫流程分析
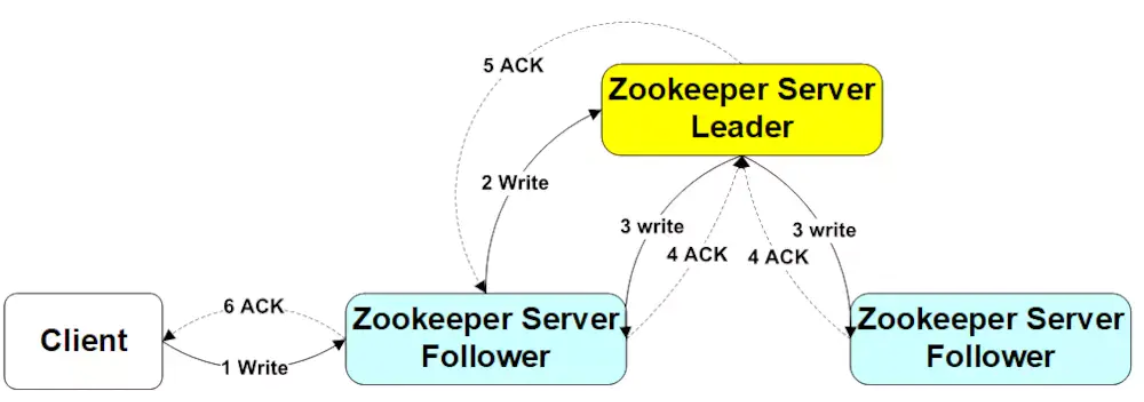
當一個客戶端進行寫資料請求時,會指定ZooKeeper叢集中的一個server節點,如果該節點為Follower,則該節點會把寫請求轉發給Leader,Leader透過內部的協議進行原子廣播,直到一半以上的server節點都成功寫入了資料,這次寫請求便算是成功,然後Leader便會通知相應Follower節點寫請求成功,該節點向client返回寫入成功響應。
併發讀寫分析
ZooKeeper的資料模型是層次型,類似檔案系統,不過ZooKeeper的設計目標定位是簡單、高可靠、高吞吐、低延遲的記憶體型儲存系統,因此它的value不像檔案系統那樣適合儲存大的值,官方建議儲存的value大小要小於1M,key為路徑。
ZooKeeper的層次模型是透過ConcurrentHashMap實現的,key為path,value為DataNode,DataNode儲存了znode中的value、children、 stat等資訊。
對於ZooKeeper來講,ZooKeeper的寫請求由Leader處理,Leader能夠保證併發寫入的有序性,即同一時刻,只有一個寫操作被批准,然後對該寫操作進行全域性編號,最後進行原子廣播寫入,所以ZooKeeper的併發寫請求是順序處理的,而底層又是用了ConcurrentHashMap,理所當然寫請求是執行緒安全的。而對於併發讀請求,同理,因為用了ConcurrentHashMap,當然也是執行緒安全的了。總結來說,ZooKeeper的併發讀寫是執行緒安全的。
但是對於ZooKeeper的客戶端來講,如果使用了watch機制,在進行了讀請求但是watch znode前這段時間中,如果znode的資料變化了,客戶端是無法感知到的,這段時間客戶端的資料就有一定的滯後性了,只有當下次資料變化後,客戶端才能感知到,所以對於客戶端來說,資料是最終一致性。
10. Zookeeper Cluster
為什麼是奇數臺servers,之前介紹中經常有說到一個關鍵詞(半數以上)。在zookeeper中,半數以上機制比較重要。例如:半數以上伺服器存活,該叢集才可正常執行;半數以上投票,本次事務請求才可透過等。
配置檔案修改:
tickTime=2000 #通訊心跳時間,Zookeeper伺服器與客戶端心跳時間,單位毫秒
initLimit=10 #Leader和Follower初始連線時能容忍的最多心跳數(tickTime的數量),這裡表示為10*2s
syncLimit=5 #Leader和Follower之間同步通訊的超時時間,這裡表示如果超過5*2s,Leader認為Follwer死掉,並從伺服器列表中刪除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定儲存Zookeeper中的資料的目錄,目錄需要單獨建立
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●新增,指定存放日誌的目錄,目錄需要單獨建立
clientPort=2181 #客戶端連線埠
#新增叢集資訊
server.1=192.168.40.10:3188:3288
server.2=192.168.40.20:3188:3288
server.3=192.168.40.30:3188:3288
#叢集節點通訊時使用埠3188,選舉leader時使用的埠3288
-------------------------------------------------------------------------------------
server.A=B:C:D
●A是一個數字,表示這個是第幾號伺服器。叢集模式下需要在zoo.cfg中dataDir指定的目錄下建立一個檔案myid,這個檔案裡面有且只有一個資料就是A的值,Zookeeper啟動時讀取此檔案,拿到裡面的資料與zoo.cfg裡面的配置資訊比較從而判斷到底是哪個server。
●B是這個伺服器的地址。
●C是這個叢集中server之間資料同步的埠。
●D是叢集中選舉新的Leader時伺服器相互通訊的埠
10.1 ZooKeeper Reconfig
zk動態配置可解決之前zk叢集日常擴縮容過程中的如下問題:
-
zk叢集短時間內不可用:zk節點滾動重啟導致重新選舉,選舉週期內zk叢集對外不可用;
-
依賴zk client端重連:zk節點滾動重啟導致已建立的客戶端連線被斷開,客戶端需主動重連其他節點;
-
擴縮容過程繁瑣易出錯:在靜態配置版本下,擴容操作包括:配置新節點、啟動新節點、配置老節點、滾動重啟老節點。操作繁瑣,步驟冗長,依賴人工容易出錯。
10.1.1 為什麼不能簡單的擴容
假設現在有三臺機器組成的ZooKeeper叢集。但是一兩個月後,你會發現使用ZooKeeper的客戶端越來越多,並且成為一個關鍵的服務,因此你想要把伺服器擴容到五臺,你可以在深夜停止叢集,重新配置所有伺服器,並在不到一分鐘的時間裡恢復服務。如果你的應用程式恰當處理了Disconnected事件,使用者可能不會感知到服務中斷。但事實證明,情況要複雜得多。請看下圖中的場景,三個伺服器(A、B、C)組成的叢集。伺服器C因網路擁塞稍稍落後於整個叢集,因此伺服器C剛剛瞭解事務到(1,3)(其中1為時間戳,3為對應該時間戳的事務標識)。因為伺服器A和B的通訊良好,所以伺服器C稍稍落後並不會導致整個系統變慢,因此伺服器A和B已經提交事務到(1,6)。
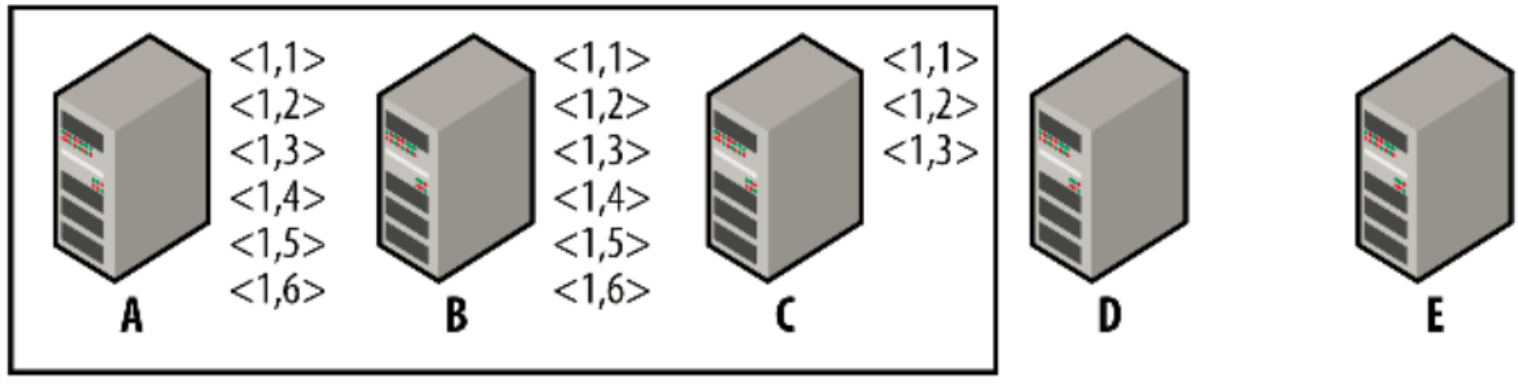
現在假設我們將所有zookeeper服務停止,把伺服器D和E新增到叢集中,當然這兩臺新伺服器並不存在任何狀態資訊。我們重新配置A、B、C、D和E伺服器,使它們成為一個更大的叢集,然後重新啟動服務。因為我們現在有五臺伺服器,因此至少需要臺伺服器組成法定人數。C、D和E三臺伺服器就能夠構成法定人數,因此當這些伺服器(下圖)構成法定人數並開始同步時會發生什麼。這個場景可以簡單實現,比如讓A和B比其他三個伺服器晚啟動一些。一旦新的法定人數開始同步,伺服器D和E就會與伺服器C進行同步,因為法定人數中伺服器C的狀態為最新狀態,法定人數的三個成員伺服器會同步到最後的事務(1,3),而不會同步(1,4)、(1,5)和(1,6)這三個事務,因為伺服器A和B並不是構成法定人數的成員。
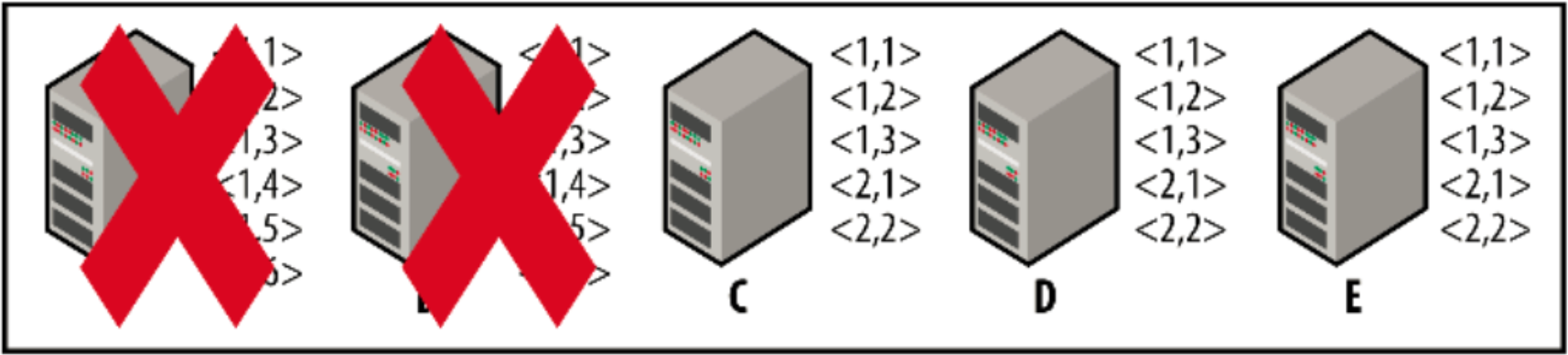
因為C、D和E三臺伺服器已經構成一個活躍的法定人數,這些伺服器可以開始提交新事務。我們假設有兩個事務:(2,1)和(2,2)。如下圖所示,當伺服器A和B啟動後連線到伺服器C後,伺服器C作為leader歡迎它們加入到叢集中,並在收到事務(2,1)和(2,2)後,立即告知伺服器A和B刪除事務(1,4)、(1,5)和(16)
重配置不僅可以讓我們改變叢集成員配置,還可以修改網路引數配置。因為ZooKeeper中配置資訊的變化,需要將重配置引數與靜態的配置檔案分離,並將其單獨儲存為一個配置檔案(reconfig命令會自動更新該檔案)。
10.1.2 如何做zookeeper的重配置
假如現在有一個三臺伺服器組成的zookeeper叢集,每臺zkServer的配置如下:
tickTime=2000
#投票選舉新leader的初始化時間
initLimit=10
#leader與fo1lower心跳檢測最大容忍時間,響應超過syncLimit*tickTime,leader認為follower“死掉”,從伺服器列表中刪除fo1lowei
syncLimit=5
#ZooKeeper對外服務埠
clientPort=2181
#快照目錄
dataDir=/tmp/zookeeper/data
#事務日誌目錄
dataLogDir=/tmp/zookeeper/log
#ZooKeeper叢集中伺服器的列表
server.1=10.1.1.11:2888:3888
server.2=10.1.1.12:2888:3888
server.3=10.1.1.13:2888:3888
#允許執行reconfig命令
reconfigEnabled=true
#允許執行四字母命令
4lw.commands.whitelist=*
#禁止leader為客戶端提供服務
leaderServes=no
在啟動zk服務後,配置檔案會被拆分為兩個檔案:
Zoo.cfg
initLimit=10
syncLimit=5
leaderServes=no
4lw.commands.whitelist=*
clientPort=2181
tickTime=2000
dataDir=/tmp/zookeeper/data
reconfigEnabled=true
dataLogDir=/tmp/zookeeper/log
dynamicConfigFile=/usr/local/apache-zookeeper-3.5.9-bin/conf/zoo.cfg.dynamic.100000000
zoo.cfg.dynamic.100000000
server.1=10.1.1.11:2888:3888:participant
server.2=10.1.1.12:2888:3888:participant
server.3=10.1.1.13:2888:3888:participant
然後修改zoo.cfg檔案,並分發到所有zkServer:
initLimit=10
syncLimit=5
leaderServes=no
4lw.commands.whitelist=*
tickTime=2000
dataDir=/tmp/zookeeper/data
reconfigEnabled=true
dataLogDir=/tmp/zookeeper/log
dynamicConfigFile=/usr/local/apache-zookeeper-3.5.9-bin/conf/zoo.cfg.dynamic.100000000
新的zkServer配置,並啟動:
server.1=10.1.1.11:2888:3888:participant
server.2=10.1.1.12:2888:3888:participant
server.3=10.1.1.13:2888:3888:participant
server.4=10.1.1.13:2888:3888:participant;0.0.0.0:2181
然後執行:
mkdir -p /tmp/zookeeper/{data,log}
echo'4'>/tmp/zookeeper/data/myid
zkServer.sh start
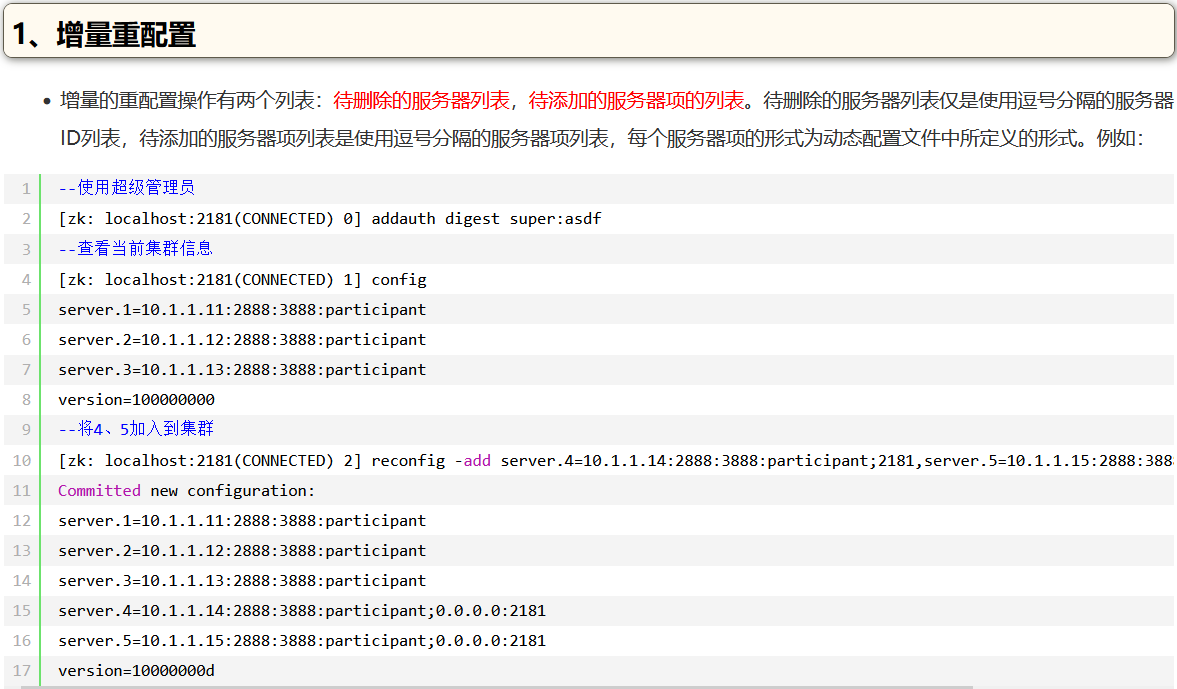
reconfig -add server.4=10.1.1.14:2888:3888:participant;2181,server.5=10.1.1.15:2888:3888:participant;2181
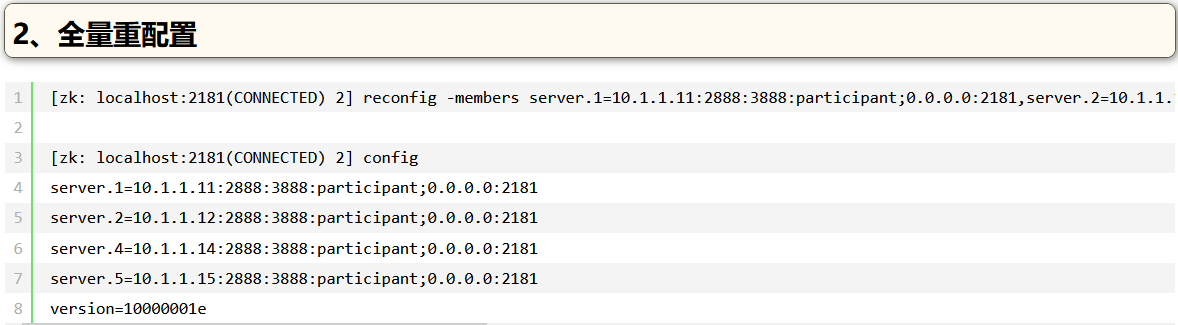
reconfig -members server.1=10.1.1.11:2888:3888:participant;0.0.0.0:2181,server.2=10.1.1.12:2888:3888:participant;0.0.0.0:2181,server.4=10.1.1.14:2888:3888:participant;0.0.0.0:2181,server.5=10.1.1.15:2888:3888:participant;0.0.0.0:2181
10.2 Zookeeper Brain-Split
ZooKeeper 內部透過心跳機制來確定 leader 的狀態,一旦 leader 節點出現問題,叢集內部就能立即獲悉並迅速通知其他 follower 節點來選出新的 leader。
設想這樣一種情況:
-
叢集中網路通訊不好,導致心跳監測超時 —— follower 認為 leader 節點由於某種原因掛掉了,可其實 leader 節點並未真正掛掉 —— 這就是假死現象。
-
leader 節點假死後,ZooKeeper 通知所有 follower 節點進行新的選舉 ==> 某個 follower 節點升級為新的 leader —— 此時叢集中存在2個leader節點。
-
如果部分 client 獲得了新 leader 節點的資訊,而部分沒有獲得,恰好此時 client 向 ZooKeeper 發起讀寫請求,ZooKeeper 內部的不一致就會導致:部分 client 連線到了新的 leader 節點,而部分 client 連線到了舊的 leader節點 —— 服務中出現了2個leader,client 不知道聽誰好。
10.2.1 如何解決
(1) Quorums(法定人數)
透過設定法定人數,進而確定叢集的容忍度,當叢集中存活的節點少於法定人數,叢集將不可用。比如:
3個節點的叢集中,Quorums = 2 —— 叢集可以容忍 (3 - 2 = 1) 個節點失敗,這時候還能選舉出 leader,叢集仍然可用;
4個節點的叢集中,Quorums = 3 —— 叢集同樣可以容忍 1 個節點失敗,如果2個節點失敗,那整個叢集就不可用了。
(2) Redundant communications(冗餘通訊)
叢集中採用多種通訊方式,防止一種通訊方式失效導致叢集中的節點無法通訊。
(3) Fencing(隔離,即共享資源)
透過隔離的方式,將所有共享資源隔離起來,能對共享資源進行寫操作(即加鎖)的節點就是 leader 節點。
10.2.2 ZooKeeper的解決方案
ZooKeeper 預設採用了Quorums 的方式:只有獲得超過半數節點的投票,才能選舉出 leader。
假設leader 發生了假死,followers 選舉出了一個新的 leader。
當舊的 leader 復活並認為自己仍然是 leader,它向其他 followers 發出寫請求時,會被拒絕。
因為 ZooKeeper 維護了一個叫 epoch 的變數,每當新 leader 產生時,epoch 就會遞增,followers 如果確認了新的 leader,同時也會知道其 epoch 的值。它們會拒絕所有 epoch 小於現任 leader 的 epoch 的舊 leader 的請求。
注意:仍然會存在有部分 followers 不知道新 leader 的存在,但肯定不是大多數,否則新 leader 將無法產生。
本部落格內容僅供個人學習使用,禁止用於商業用途。轉載需註明出處並連結至原文。