【讀書筆記】Java併發程式設計的藝術
第一章:併發程式設計的挑戰
上下文切換
-
上下文切換概述
- 切出:一個執行緒被剝奪處理器的使用權而暫定執行
- 切入:一個執行緒被選中佔用處理器或者繼續執行
- 上下文:在這種切入切出的過程中,作業系統需要儲存和恢復相應的進度資訊,這個進度資訊就是上下文
-
上下文切換實現
- 在 Linux 系統中(Windows是搶佔式的,即設定優先順序),CPU 通過給每個執行緒分配 CPU 時間片來實現這個機制。時間片是 CPU 分配給各個執行緒的時間,因為時間片非常短,所以 CPU 通過不停地切換執行緒執行,讓我們感覺多個執行緒是同時執行的,時間片一般是幾十毫秒(ms)。CPU 通過時間片分配演算法來迴圈執行任務,當前任務執行一個時間片後會切換到下一個任務。但是,在切換前會儲存上一個任務的狀態,以便下次切換回這個任務時,可以再載入這個任務的狀態
- 因為 CPU 的實現方式,單核處理器也支援多執行緒執行程式碼
- 執行緒有建立和上下文切換的開銷,在執行任務較少時,單執行緒會比多執行緒快
- 在 Linux 系統中(Windows是搶佔式的,即設定優先順序),CPU 通過給每個執行緒分配 CPU 時間片來實現這個機制。時間片是 CPU 分配給各個執行緒的時間,因為時間片非常短,所以 CPU 通過不停地切換執行緒執行,讓我們感覺多個執行緒是同時執行的,時間片一般是幾十毫秒(ms)。CPU 通過時間片分配演算法來迴圈執行任務,當前任務執行一個時間片後會切換到下一個任務。但是,在切換前會儲存上一個任務的狀態,以便下次切換回這個任務時,可以再載入這個任務的狀態
-
如何避免上下文切換:
- 無鎖併發程式設計:多執行緒競爭鎖時,會引起上下文切換,所以多執行緒處理資料時,可以用將資料的 ID 按照 Hash 演算法取模分段,不同的執行緒處理不同段的資料
- CAS演算法:Java 的 Atomic 包使用 CAS 演算法來更新資料,而不需要加鎖(CAS在Linux中對應的是cmpxchg指令)
- 使用最少執行緒:避免建立不需要的執行緒
- 協程:在單執行緒裡實現多工的排程,並在單執行緒裡維持多個任務間的切換(由於 Go 語言從語言層面原生支援協程,所以 GO 在處理多執行緒時很具有優勢)
死鎖
-
什麼是死鎖
- 死鎖是指兩個或兩個以上的程式(執行緒)在執行過程中因爭奪資源而造成的一種僵局(Deadly-Embrace) ) ,若無外力作用,這些程式(執行緒)都將無法向前推進
-
死鎖產生的四個必要條件(只要有一個條件不滿足就不會產生死鎖)
- 互斥條件。一個資源每次只能被一個程式使用
- 不可剝奪條件。程式已獲得的資源,在末使用完之前,不能強行剝奪
- 請求和保持條件。申請了某個資源後,繼續再申請別的資源,那之前的資源除非親自釋放掉,否則不可被別的執行緒使用
- 迴圈等待條件。若干程式之間形成一種頭尾相接的迴圈等待資源關係
-
死鎖產生的原因
- 系統資源不足
- 程式執行推進的順序不合適
- 資源分配不當等
-
避免死鎖的辦法
- 避免一個執行緒同時獲取多個鎖
- 避免一個執行緒在鎖內同時佔用多個資源,儘量保證每個鎖只佔用一個資源
- 嘗試使用定時鎖,使用 lock.tryLock(timeout) 來替代使用內部鎖機制
- 對於資料庫鎖,加鎖和解鎖必須在一個資料庫連線裡,否則會出現解鎖失敗的情況
-
飢餓與死鎖
- 飢餓可以認為是一個或一個以上執行緒或是程式在無限的等待另外兩個或多個執行緒或程式佔有的但是不會往外釋放的資源
- 飢餓還可以認為是多執行緒執行中有執行緒優先順序這個東西,優先順序高的執行緒能夠插隊並優先執行,這樣如果優先順序高的執行緒一直搶佔優先順序低執行緒的資源,導致低優先順序執行緒無法得到執行,這就是飢餓
- 看一些原始碼時候經常看到在迴圈中有 Thread.Sleep(0) 的寫法, 這麼做的作用就是觸發作業系統立刻重新進行一次 CPU 競爭
- Windows 是一個搶佔式的多工作業系統
- 它會在前後臺切換的時候調整優先順序
- 它會為 I/O 操作動態提升優先順序
- 它會使用 “飢餓” 的時間片分配策略來動態調整。即如果有執行緒一直渴望得到時間片但是很長時間都沒有獲得時間片,Windows 就會臨時將這個執行緒的優先順序提高,並一次分配給 2 倍的時間片來執行,當用完 2 倍的時間片後,優先順序又會恢復到之前的水平
資源限制的挑戰
-
什麼是資源挑戰
- 資源限制是指在進行併發程式設計時,程式的執行速度受限於計算機硬體資源或軟體資源
-
資源限制引發的問題
- 在併發程式設計中,將程式碼執行速度加快的原則是將程式碼中序列執行的部分變成併發執行,但是如果將某段序列的程式碼併發執行,因為受限於資源,仍然在序列執行,這時候程式不僅不會加快執行,反而會更慢,因為增加了上下文切換和資源排程的時間
-
資源限制的解決
- 對於硬體的限制,可以增加機器的方式
- 對於軟體資源限制,可以考慮使用資源池將資源複用。例如:Java 在呼叫資料庫時,禁止在 for 迴圈裡寫 sql 就是為了減少資料庫連線的資源消耗
第二章:Java 併發機制的底層實現原理
Java 程式碼在編譯後會變成 Java 位元組碼,位元組碼被類載入器載入到 JVM 裡,JVM 執行位元組碼,最終需要轉化為彙編指令在 CPU 上執行,Java 中所使用的併發機制依賴於 JVM 的實現和 CPU 的指令本
volatile 的應用
-
volatile 定義
- Java程式語言允許執行緒訪問共享變數,為了確保共享變數能被準確和一致地更新,執行緒應該確保通過排他鎖單獨獲得這個變數
-
volatile 實現原理
- 為了提高處理速度,處理器不直接和記憶體進行通訊,而是先將系統記憶體的資料讀到內部快取(L1,L2或其他)後再進行操作,但操作完不知道何時會寫到記憶體
- 如果對宣告瞭 volatile 的變數進行寫操作,JVM 就會向處理器傳送一條 Lock 字首的指令,將這個變數所在快取行的資料寫回到系統記憶體。但是,就算寫回到記憶體,如果其他處理器快取的值還是舊的,再執行計算操作就會有問題。所以在多處理器下,為了保證各個處理器的快取是一致的,就會實現快取一致性協議,即每個處理器通過嗅探在匯流排上傳播的資料來檢查自己快取的值是不是過期了,當處理器發現自己快取行對應的記憶體地址被修改,就會將當前處理器的快取行設定成無效狀態,當處理器對這個資料進行修改操作的時候,會重新從系統記憶體中把資料讀到處理器快取裡
synchronized 的實現原理與應用
-
Java 中的每一個物件都可以作為鎖,具體表現為以下 3 種形式
- 對於普通同步方法,鎖是當前例項物件
- 對於靜態同步方法,鎖是當前類的 Class 物件
- 對於同步方法塊,鎖是 Synchonized 括號裡配置的物件
-
synchronized 鎖的實現
- 程式碼塊同步:每個物件有一個監視器鎖(monitor)。當 monitor 被佔用時就會處於鎖定狀態,執行緒執行 monitorenter 指令時嘗試獲取 monitor 的所有權,過程如下
- 如果 monitor 的進入數為 0,則該執行緒進入 monitor,然後將進入數設定為 1,該執行緒即為 monitor 的所有者
- 如果執行緒已經佔有該 monitor,只是重新進入,則進入 monitor 的進入數加 1
- 如果其他執行緒已經佔用了 monitor,則該執行緒進入阻塞狀態,直到 monitor 的進入數為0,再重新嘗試獲取 monitor 的所有權
- 其實 wait/notify 等方法也依賴於 monitor 物件,這就是隻有在同步的塊或者方法中才能呼叫 wait/notify 等方法的原因
- 普通方法:對於普通方法,其常量池中多了 ACC_SYNCHRONIZED 標示符。JVM 就是根據該標示符來實現方法的同步的。當方法呼叫時,呼叫指令將會檢查方法的 ACC_SYNCHRONIZED 訪問標誌是否被設定,如果設定了,執行執行緒將先獲取 monitor,獲取成功之後才能執行方法體,方法執行完後再釋放 monitor。在方法執行期間,其他任何執行緒都無法再獲得同一個 monitor 物件。 其實本質上沒有區別,只是方法的同步是一種隱式的方式來實現,無需通過位元組碼來完成
- 無論 synchronized 關鍵字加在方法上還是物件上,如果它作用的物件是非靜態的,則它取得的鎖是物件;如果 synchronized 作用的物件是一個靜態方法或一個類,則它取得的鎖是對類,該類所有的物件同一把鎖
- 程式碼塊同步:每個物件有一個監視器鎖(monitor)。當 monitor 被佔用時就會處於鎖定狀態,執行緒執行 monitorenter 指令時嘗試獲取 monitor 的所有權,過程如下
-
物件頭
-
在 Hotspot 虛擬機器中,物件在記憶體中的佈局分為三塊區域:物件頭、例項資料和對齊填充
-
Java 物件頭是實現 synchronized 的鎖物件的基礎,一般而言,synchronized 使用的鎖物件是儲存在 Java 物件頭裡。如果物件是陣列型別,則虛擬機器用 3 個字寬(Word)儲存物件頭,如果物件是非陣列型別,則用 2 字寬儲存物件頭。在 32 位虛擬機器中,1 字寬等於 4 位元組,即 32bit
-
Java 物件頭裡的 Mark Word 裡預設儲存物件的 HashCode、分代年齡和鎖標記位。32位 JVM 的 Mark Word 的預設儲存結構如下:
鎖狀態 25bit 4bit 1bit是否是偏向鎖 2bit鎖標誌位 無鎖狀態 物件的hashcode 物件分代年齡 0 01 -
在執行期間,Mark Word 裡儲存的資料會隨著鎖標誌位的變化而變化。Mark Word可能變化為儲存以下4種資料
鎖狀態 25bit 4bit 1bit是否是偏向鎖 2bit鎖標誌位 輕量級鎖 指向棧中鎖記錄的指標(佔用30bit) – – 00 重量級鎖 指向互斥量(重量級鎖)的指標(佔用30bit) – – 10 GC標誌 空(佔用30bit) – – 00 偏向鎖 執行緒ID(23bit)+Epoch+物件分代年齡 1 01 -
在64位虛擬機器下,Mark Word 是 64bit 大小的,其儲存結構如下
鎖狀態 25bit 31bit 1bit(cms_free) 4bit(分代年齡) 1bit是否是偏向鎖 2bit鎖標誌位 無鎖 unused hashcode – – 0 00 偏向鎖 執行緒ID(54bit)+Epoch(2bit) – – – 1 01
-
-
鎖的升級與對比
- 鎖的狀態
- 在 Java SE 1.6 中,鎖一共有 4 種狀態,級別從低到高
- 無鎖狀態
- 偏向鎖狀態
- 輕量級鎖狀態
- 重量級鎖狀態
- 這幾個狀態會隨著競爭情況逐漸升級。鎖可以升級但不能降級,意味著偏向鎖升級成輕量級鎖後不能降級成偏向鎖。這種鎖升級卻不能降級的策略,目的是為了提高獲得鎖和釋放鎖的效率
- 在 Java SE 1.6 中,鎖一共有 4 種狀態,級別從低到高
- 偏向鎖
- 偏向鎖的概念
- 當一個執行緒訪問同步塊並獲取鎖時,會在物件頭和棧幀中的鎖記錄裡儲存鎖偏向的執行緒 ID,以後該執行緒在進入和退出同步塊時不需要進行 CAS 操作來加鎖和解鎖,只需測試物件頭的 Mark Word 裡是否儲存著指向當前執行緒的偏向鎖。如果測試成功,表示執行緒已經獲得了鎖。如果測試失敗,則需要再測試一下 Mark Word 中偏向鎖的標識是否設定成 1(表示當前是偏向鎖):如果沒有設定,則使用 CAS 競爭鎖;如果設定了,則嘗試使用 CAS 將物件頭的偏向鎖指向當前執行緒
- 偏向鎖的撤銷
- 偏向鎖使用了一種等到競爭出現才釋放鎖的機制,所以當其他執行緒嘗試競爭偏向鎖時,持有偏向鎖的執行緒才會釋放鎖。偏向鎖的撤銷,需要等待全域性安全點(在這個時間點上沒有正在執行的位元組碼)。它會首先暫停擁有偏向鎖的執行緒,然後檢查持有偏向鎖的執行緒是否活著,如果執行緒不處於活動狀態,則將物件頭設定成無鎖狀態;如果執行緒仍然活著,擁有偏向鎖的棧會被執行,遍歷偏向物件的鎖記錄,棧中的鎖記錄和物件頭的 MarkWord 要麼重新偏向於其他執行緒,要麼恢復到無鎖或者標記物件不適合作為偏向鎖,最後喚醒暫停的執行緒

- 偏向鎖使用了一種等到競爭出現才釋放鎖的機制,所以當其他執行緒嘗試競爭偏向鎖時,持有偏向鎖的執行緒才會釋放鎖。偏向鎖的撤銷,需要等待全域性安全點(在這個時間點上沒有正在執行的位元組碼)。它會首先暫停擁有偏向鎖的執行緒,然後檢查持有偏向鎖的執行緒是否活著,如果執行緒不處於活動狀態,則將物件頭設定成無鎖狀態;如果執行緒仍然活著,擁有偏向鎖的棧會被執行,遍歷偏向物件的鎖記錄,棧中的鎖記錄和物件頭的 MarkWord 要麼重新偏向於其他執行緒,要麼恢復到無鎖或者標記物件不適合作為偏向鎖,最後喚醒暫停的執行緒
- 關閉偏向鎖
- 偏向鎖在 Java 6 以後是預設啟用的,但是它在應用程式啟動幾秒鐘之後才啟用
// 關閉偏向鎖延遲啟用 -XX:BiasedLockingStartupDelay=0 // 關閉偏向鎖,系統預設進入輕量級鎖(在存在大量鎖物件的建立並高度併發的環境下禁用偏向鎖能夠帶來一定的效能優化) -XX:-UseBiasedLocking=false
- 偏向鎖在 Java 6 以後是預設啟用的,但是它在應用程式啟動幾秒鐘之後才啟用
- 偏向鎖的概念
- 輕量級鎖
- 輕量級鎖加鎖
- 執行緒在執行同步塊之前,JVM 會先在當前執行緒的棧楨中建立用於儲存鎖記錄的空間,並將物件頭中的 Mark Word 複製到鎖記錄中,官方稱為Displaced Mark Word。然後執行緒嘗試使用 CAS 將物件頭中的 Mark Word 替換為指向鎖記錄的指標。如果成功,當前執行緒獲得鎖,如果失敗,表示其他執行緒競爭鎖,當前執行緒便嘗試使用自旋來獲取鎖
- 輕量級鎖解鎖
- 輕量級解鎖時,會使用原子的 CAS 操作將 Displaced Mark Word 替換回到物件頭,如果成功,則表示沒有競爭發生。如果失敗,表示當前鎖存在競爭,鎖就會膨脹成重量級鎖

- 輕量級解鎖時,會使用原子的 CAS 操作將 Displaced Mark Word 替換回到物件頭,如果成功,則表示沒有競爭發生。如果失敗,表示當前鎖存在競爭,鎖就會膨脹成重量級鎖
- 因為自旋會消耗CPU,為了避免無用的自旋(比如獲得鎖的執行緒被阻塞住了),一旦鎖升級成重量級鎖,就不會再恢復到輕量級鎖狀態。當鎖處於這個狀態下,其他執行緒試圖獲取鎖時,都會被阻塞住,當持有鎖的執行緒釋放鎖之後會喚醒這些執行緒,被喚醒的執行緒就會進行新一輪的奪鎖之爭
- 輕量級鎖加鎖
- 鎖的優缺點對比
鎖 優點 缺點 適用場景 偏向鎖 加鎖和解鎖不需要額外消耗,和執行非同步方法相比僅存在納秒級別的差距 如果執行緒間存在競爭,會帶來額外所撤銷的消耗 適用只有執行緒訪問同步程式碼塊的場景 輕量級鎖 競爭的執行緒不會阻塞,提高了執行緒的響應速度 始終得不到鎖競爭的執行緒會使用自旋從而消耗 CPU 追求響應時間,同步程式碼塊執行速度非常快 重量級鎖 執行緒競爭不使用自旋,不會消耗 CPU 執行緒阻塞,響應時間緩慢 追求吞吐量,同步程式碼塊執行速度較慢 - 附一張偷來的總圖

- 鎖的狀態
第三章: Java 記憶體模型
Java 記憶體模型的基礎
-
併發程式設計模型的兩個關鍵問題
- 執行緒之間如何通訊
- 在指令式程式設計中,執行緒之間的通訊機制有兩種:共享記憶體和訊息傳遞
- 在共享記憶體的併發模型裡,執行緒之間共享程式的公共狀態,通過寫-讀記憶體中的公共狀態進行隱式通訊
- 在訊息傳遞的併發模型裡,執行緒之間沒有公共狀態,執行緒之間必須通過傳送訊息來顯式進行通訊
- 執行緒之間如何同步
- 同步是指程式中用於控制不同執行緒間操作發生相對順序的機制
- 在共享記憶體併發模型裡,同步是顯式進行的。程式設計師必須顯式指定某個方法或某段程式碼需要線上程之間互斥執行
- 在訊息傳遞的併發模型裡,由於訊息的傳送必須在訊息的接收之前,因此同步是隱式進行的
- Java 的併發採用的是共享記憶體模型,Java 執行緒之間的通訊總是隱式進行,整個通訊過程對程式設計師完全透明
- 執行緒之間如何通訊
-
Java 記憶體模型的抽象結構
-
在 Java 中,所有例項域、靜態域和陣列元素都儲存在堆記憶體中,堆記憶體線上程之間共享。區域性變數、方法定義引數和異常處理器引數不會線上程之間共享,它們不會有記憶體可見性問題,也不受記憶體模型的影響
-
Java 執行緒之間的通訊由 Java 記憶體模型控制(本文簡稱為JMM),JMM 決定一個執行緒對共享變數的寫入何時對另一個執行緒可見
- JMM 規定執行緒之間的所有共享變數都儲存在主記憶體中
- JMM 規定每個執行緒都有一個私有的工作記憶體,執行緒的工作記憶體中儲存了被該執行緒使用到的變數的主記憶體副本拷貝,執行緒對變數的所有操作(讀取、賦值等)都必須在工作記憶體中進行,而不能直接讀寫主記憶體中的變數。不同的執行緒之間也無法直接訪問對方工作記憶體中的變數,執行緒間變數的值的傳遞均需要通過主記憶體來完成
- 工作記憶體是 JMM 的一個抽象概念,並不真實存在。它涵蓋了快取、寫緩衝區、暫存器以及其他的硬體和編譯器優化

-
A 寫資料進入主記憶體,B 從主記憶體讀取資料。從整體來看,這兩個步驟實質上是執行緒 A 在向執行緒 B 傳送訊息,而且這個通訊過程必須要經過主記憶體。JMM 通過控制主記憶體與每個執行緒的本地記憶體之間的互動,來為 Java 程式設計師提供記憶體可見性保證
-
-
工作記憶體與主記憶體互動
- java 記憶體中執行緒的工作記憶體和主記憶體的互動是由 java 虛擬機器定義了的 8 種操作來完成的
- 每種操作必須是原子性的(double和long型別在某些平臺有例外,參考volatile詳解和非原子性協定),java 虛擬機器中主記憶體和工作記憶體互動,就是一個變數如何從主記憶體傳輸到工作記憶體中,如何把修改後的變數從工作記憶體同步回主記憶體
操作 含義 lock(鎖定) 作用於主記憶體的變數,一個變數在同一時間只能一個執行緒鎖定,該操作表示這條線成獨佔這個變數 unlock(解鎖) 作用於主記憶體的變數,表示這個變數的狀態由處於鎖定狀態被釋放,這樣其他執行緒才能對該變數進行鎖定 read(讀取) 作用於主記憶體變數,表示把一個主記憶體變數的值傳輸到執行緒的工作記憶體,以便隨後的 load 操作使用 load(載入) 作用於執行緒的工作記憶體的變數,表示把 read 操作從主記憶體中讀取的變數的值放到工作記憶體的變數副本中(副本是相對於主記憶體的變數而言的) use(使用) 作用於執行緒的工作記憶體中的變數,表示把工作記憶體中的一個變數的值傳遞給執行引擎,每當虛擬機器遇到一個需要使用變數的值的位元組碼指令時就會執行該操作 assign(賦值) 作用於執行緒的工作記憶體的變數,表示把執行引擎返回的結果賦值給工作記憶體中的變數,每當虛擬機器遇到一個給變數賦值的位元組碼指令時就會執行該操作 store(儲存) 作用於執行緒的工作記憶體中的變數,把工作記憶體中的一個變數的值傳遞給主記憶體,以便隨後的 write 操作使用 write(寫入) 作用於主記憶體的變數,把store操作從工作記憶體中得到的變數的值放入主記憶體的變數中 - 在執行這 8 中操作的時候必須遵循如下的規則:
- 不允許 read 和 load、store 和 write 操作之一單獨出現,也就是不允許從主記憶體讀取了變數的值但是工作記憶體不接收的情況,或者不允許從工作記憶體將變數的值回寫到主記憶體但是主記憶體不接收的情況
- 不允許一個執行緒丟棄最近的 assign 操作,也就是不允許執行緒在自己的工作執行緒中修改了變數的值卻不同步/回寫到主記憶體
- 不允許一個執行緒回寫沒有修改的變數到主記憶體,也就是如果執行緒工作記憶體中變數沒有發生過任何 assign 操作,是不允許將該變數的值回寫到主記憶體
- 變數只能在主記憶體中產生,不允許在工作記憶體中直接使用一個未被初始化的變數,也就是沒有執行 load 或者 assign 操作。也就是說在執行 use、store 之前必須對相同的變數執行了 load、assign 操作
- 一個變數在同一時刻只能被一個執行緒對其進行 lock 操作,也就是說一個執行緒一旦對一個變數加鎖後,在該執行緒沒有釋放掉鎖之前,其他執行緒是不能對其加鎖的,但是同一個執行緒對一個變數加鎖後,可以繼續加鎖,同時在釋放鎖的時候釋放鎖次數必須和加鎖次數相同
- 對變數執行 lock 操作,就會清空工作空間該變數的值,執行引擎使用這個變數之前,需要重新 load 或者 assign 操作初始化變數的值
- 不允許對沒有 lock 的變數執行 unlock 操作,如果一個變數沒有被 lock 操作,那也不能對其執行 unlock 操作,當然一個執行緒也不能對被其他執行緒 lock 的變數執行 unlock 操作
- 對一個變數執行 unlock 之前,必須先把變數同步回主記憶體中,也就是執行 store 和 write 操作
- 在執行這 8 中操作的時候必須遵循如下的規則:
可見性與重排序
-
可見性
- 可見性的定義常見於各種併發場景中,以多執行緒為例:當一個執行緒修改了執行緒共享變數的值,其它執行緒能夠立即得知這個修改
- 從效能角度考慮,沒有必要在修改後就立即同步修改的值——如果多次修改後才使用,那麼只需要最後一次同步即可,在這之前的同步都是效能浪費。因此,實際的可見性定義要弱一些,只需要保證:當一個執行緒修改了執行緒共享變數的值,其它執行緒在使用前,能夠得到最新的修改值
- 可見性可以認為是最弱的“一致性”(弱一致),只保證使用者見到的資料是一致的,但不保證任意時刻,儲存的資料都是一致的(強一致)
-
重排序
- 重排序是指編譯器和處理器為了優化程式效能而對指令序列進行重新排序的一種手段
-
重排序的場景
- 編譯器優化的重排序(JVM)
- 編譯器在不改變單執行緒程式語義的前提下,可以重新安排語句的執行順序
- 處理器執行的重排序 (CPU)
- 現代處理器採用了指令級並行技術來將多條指令重疊執行。如果不存在資料依賴性,處理器可以改變語句對應機器指令的執行順序
- 記憶體系統的重排序/快取同步順序(JVM/CPU)
- 由於處理器使用快取和讀/寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行,其本質為可見性問題
- 編譯器優化的重排序(JVM)
-
解決快取同步順序的方式
- 快取一致性 - MESI 協議
- 處理器上有一套完整的協議,來保證快取的一致性,比較經典的應該就是 MESI 協議了,其實現方法是在 CPU 快取中儲存一個標記位,以此來標記四種狀態。另外,每個 Core 的 Cache 控制器不僅知道自己的讀寫操作,也監聽其它 Cache 的讀寫操作,就是嗅探(snooping)協議
- M:被修改的。處於這一狀態的資料,只在本 CPU 核中有快取資料,而其他核中沒有。同時其狀態相對於記憶體中的值來說,是已經被修改的,只是沒有更新到記憶體中
- 一個處於 M 狀態的快取行,必須時刻監聽所有試圖讀取該快取行對應的主存地址的操作,如果監聽到,則必須在此操作執行前把其快取行中的資料寫回 CPU
- E:獨佔的。處於這一狀態的資料,只有在本 CPU 中有快取,且其資料沒有修改,即與記憶體中一致
- 一個處於 E 狀態的快取行,必須時刻監聽其他試圖讀取該快取行對應的主存地址的操作,如果監聽到,則必須把其快取行狀態設定為 S
- S:共享的。處於這一狀態的資料在多個 CPU 中都有快取,且與記憶體一致
- 一個處於 S 狀態的快取行,必須時刻監聽使該快取行無效或者獨享該快取行的請求,如果監聽到,則必須把其快取行狀態設定為 I
- I:無效的。本 CPU 中的這份快取已經無效
- M:被修改的。處於這一狀態的資料,只在本 CPU 核中有快取資料,而其他核中沒有。同時其狀態相對於記憶體中的值來說,是已經被修改的,只是沒有更新到記憶體中
- 當 CPU 需要讀取資料時,如果其快取行的狀態是 I 的,則需要從記憶體中讀取,並把自己狀態變成 S,如果不是 I,則可以直接讀取快取中的值,但在此之前,必須要等待其他 CPU 的監聽結果,如其他 CPU 也有該資料的快取且狀態是 M,則需要等待其把快取更新到記憶體之後,再讀取
- 當 CPU 需要寫資料時,只有在其快取行是 M 或者 E 的時候才能執行,否則需要發出特殊的 RFO 指令(Read Or Ownership,這是一種匯流排事務),通知其他 CPU 置快取無效 (I),這種情況下效能開銷是相對較大的。在寫入完成後,修改其快取狀態為 M
- 處理器上有一套完整的協議,來保證快取的一致性,比較經典的應該就是 MESI 協議了,其實現方法是在 CPU 快取中儲存一個標記位,以此來標記四種狀態。另外,每個 Core 的 Cache 控制器不僅知道自己的讀寫操作,也監聽其它 Cache 的讀寫操作,就是嗅探(snooping)協議
- 快取一致性 - MESI 協議
-
解決 CPU 重排序的方式
- 通過記憶體屏障可以解決硬體層面的可見性與重排序問題
- 介紹
- 記憶體屏障是硬體之上、作業系統或 JVM 之下,對併發作出的最後一層支援。再向下是是硬體提供的支援;向上是作業系統或 JVM 對記憶體屏障作出的各種封裝。記憶體屏障是一種標準,各廠商可能採用不同的實現
- 兩個指令
- Store:將處理器快取的資料重新整理到記憶體中
- Load:將記憶體儲存的資料拷貝到處理器的快取中
- 記憶體屏障
屏障型別 指令示例 說明 LoadLoad Barriers Load1;LoadLoad;Load2 該屏障確保 Load1 資料的裝載先於 Load2 及其後所有裝載指令的的操作 StoreStore Barriers Store1;StoreStore;Store2 該屏障確保 Store1 立刻重新整理資料到記憶體(使其對其他處理器可見)的操作先於 Store2 及其後所有儲存指令的操作 LoadStore Barriers Load1;LoadStore;Store2 確保 Load1 的資料裝載先於 Store2 及其後所有的儲存指令重新整理資料到記憶體的操作 StoreLoad Barriers Store1;StoreLoad;Load2 該屏障確保 Store1 立刻重新整理資料到記憶體的操作先於 Load2 及其後所有裝載裝載指令的操作。它會使該屏障之前的所有記憶體訪問指令(儲存指令和訪問指令)完成之後,才執行該屏障之後的記憶體訪問指令 - StoreLoad Barriers 同時具備其他三個屏障的效果,因此也稱之為全能屏障(mfence),是目前大多數處理器所支援的;但是相對其他屏障,該屏障的開銷相對昂貴
- 介紹
- 通過記憶體屏障可以解決硬體層面的可見性與重排序問題
-
解決 JVM 重排序的方式
- JVM 解決可見性和重排序的方式
- volatile
- final
- cas
- 鎖
- volatile
- volatile 簡介
- 通過 volatile 標記,可以解決編譯器層面的可見性與重排序問題
- volatile 的特性
- 可見性。對一個 volatile 變數的讀,總是能看到(任意執行緒)對這個 volatile 變數最後的寫入
- 原子性。對任意單個 volatile 變數的讀/寫具有原子性,但類似於 volatile++ 這種複合操作不具有原子性
- volatile 的記憶體語義
- volatile的寫-讀與鎖的釋放-獲取有相同的記憶體效果:volatile 寫和鎖的釋放有相同的記憶體語義;volatile 讀與鎖的獲取有相同的記憶體語義
- volatile 寫的記憶體語義:當寫一個 volatile 變數時,JMM 會把該執行緒對應的本地記憶體中的共享變數值重新整理到主記憶體
- volatile 讀的記憶體語義:當讀一個 volatile 變數時,JMM 會把該執行緒對應的本地記憶體置為無效。執行緒接下來將從主記憶體中讀取共享變數
- volatile 記憶體語義的體現
第一個操作 第二個操作 第二個操作 第二個操作 是否能重排序 普通讀寫 volatile讀 volatile寫 普通讀寫 NO volatile讀 NO NO NO volatile寫 NO NO - 從表中可以看出:
- 當第二個操作是 volatile 寫時,不管第一個操作是什麼,都不能重排序。這個規則確保從 volatile 寫之前的操作不會被編譯器重排序到 volatile 寫之後
- 當第一個操作是 volatile 讀時,不管第二個操作是什麼,都不能重排序。這個規則確保 volatile 讀之後的操作不會被編譯器重排序到 volatile 讀之前
- 當第一個操作是 volatile 寫,第二個操作是 volatile 讀時,不能重排序
- 從表中可以看出:
- volatile 記憶體語義的實現
- 在編譯器層面,僅將 volatile 作為標記使用,取消編譯層面的快取和重排序
- 如果硬體架構本身已經保證了記憶體可見性(如單核處理器、一致性足夠的記憶體模型等),那麼 volatile 就是一個空標記,不會插入相關語義的記憶體屏障
- 如果硬體架構本身不進行處理器重排序、有更強的重排序語義(能夠分析多核間的資料依賴)、或在單核處理器上重排序,那麼 volatile 就是一個空標記,不會插入相關語義的記憶體屏障
- 如果不保證,仍以 x86 架構為例,JVM 對 volatile 變數的處理如下
- 在寫 volatile 變數 v 之後,插入一個 sfence(StoreStore Barriers)。這樣,sfence 之前的所有 store(包括寫v)不會被重排序到 sfence 之後,sfence 之後的所有 store 不會被重排序到 sfence 之前,禁用跨 sfence 的 store 重排序;且 sfence 之前修改的值都會被寫回快取,並標記其他 CPU 中的快取失效
- 在讀 volatile 變數 v 之前,插入一個 lfence(LoadLoad Barriers)。這樣,lfence 之後的 load(包括讀v)不會被重排序到 lfence 之前,lfence 之前的 load 不會被重排序到 lfence 之後,禁用跨 lfence 的 load 重排序;且 lfence 之後,會首先重新整理無效快取,從而得到最新的修改值,與 sfence 配合保證記憶體可見性
- 在另外一些平臺上,JVM 使用 mfence 代替 sfence 與 lfence,實現更強的語義
- volatile 存在的意義
- 由於 JMM 屬於語言級的記憶體模型,為了確保在不同的編譯器和不同的處理器平臺之上都能為程式設計師提供一致的記憶體可見性保證,它必須有自己一套的方式(volatile)禁止特定型別的編譯器重排序和處理器重排序
- volatile 簡介
- final 域的記憶體語義
- final 域的處理器語義
- 寫 final 域的重排序規則會要求編譯器在 final 域的寫之後,建構函式 return 之前插入一個 sfence 障屏
- 讀 final 域的重排序規則要求編譯器在讀 final 域的操作前面插入一個 lfence 屏障
- 對於 final 域,編譯器和處理器要遵守兩個重排序規則
- 在建構函式內對一個 final 域的寫入,與隨後把這個被構造物件的引用賦值給一個引用變數,這兩個操作之間不能重排序
- 初次讀一個包含 final 域的物件的引用,與隨後初次讀這個 final 域,這兩個操作之間不能重排序
- 類的 final 欄位在 <clinit>() 方法中初始化,其可見性由 JVM 的類載入過程保證,對於被正確構造的物件,所有執行緒都能看到建構函式給物件的各個 final 欄位設定的正確值,而不管採用何種方式來發布物件
- final 域的處理器語義
- CAS
- 簡介
- 在 x86 架構上,CAS 被翻譯為"lock cmpxchg…"。cmpxchg 是 CAS 的彙編指令。在 CPU 架構中依靠 lock 訊號保證可見性並禁止重排序
- lock 字首是一個特殊的訊號,執行過程
- 對匯流排和快取上鎖
- 強制所有 lock 訊號之前的指令,都在此之前被執行,並同步相關快取
- 執行 lock 後的指令(如cmpxchg)
- 釋放對匯流排和快取上的鎖
- 強制所有 lock 訊號之後的指令,都在此之後被執行,並同步相關快取
- 匯流排鎖
- 當一個 CPU 對其快取中的資料進行操作的時候,往匯流排中傳送一個 Lock 訊號。其他處理器的請求將會被阻塞,那麼該處理器可以獨佔共享記憶體。匯流排鎖相當於把 CPU 和記憶體之間的通訊鎖住了,所以這種方式會導致 CPU 的效能下降
- 快取鎖
- P6 系列以後的處理器,LOCK 訊號一般不鎖匯流排,而是鎖快取。即如果快取在處理器快取行中的記憶體區域在 LOCK 操作期間被鎖定,當它執行鎖操作回寫記憶體時,處理不在匯流排上宣告 LOCK 訊號,而是修改內部的快取地址,然後通過快取一致性機制來保證操作的原子性,因為快取一致性機制會阻止同時修改被兩個以上處理器快取的記憶體區域的資料,當其他處理器回寫已經被鎖定的快取行的資料時會導致該快取行無效
- 與記憶體屏障相比,lock 訊號要額外對匯流排和快取上鎖,成本更高
- JVM使用 CAS 實現原子操作的三大問題
- ABA 問題
- 如果一個值的變化是 A -> B -> A,那麼使用 CAS 進行檢查時會發現它的值沒有發生變化,但是實際上卻變化了。ABA 問題的解決思路就是使用版本號。例如 1A -> 2B -> 3A。從 Java 1.5 開始,JDK的 Atomic 包裡提供了一個類 AtomicStampedReference 來解決 ABA 問題
- 迴圈時間長開銷大
- 自旋 CAS 如果長時間不成功,會給 CPU 帶來非常大的執行開銷
- 只能保證一個共享變數的原子操作
- 當對一個共享變數執行操作時,我們可以使用迴圈 CAS 的方式來保證原子操作,但是對多個共享變數操作時,迴圈 CAS 就無法保證操作的原子性,這個時候就可以用鎖。還有一個取巧的辦法,就是把多個共享變數合併成一個共享變數來操作。比如,有兩個共享變數 i=2,j=a,合併一下 ij=2a,然後用 CAS 來操作 ij。從Java 1.5 開始,JDK 提供了 AtomicReference 類來保證引用物件之間的原子性,就可以把多個變數放在一個物件裡來進行 CAS 操作
- ABA 問題
- 簡介
- 鎖
- JVM 的內建鎖通過作業系統的管程實現。且不論管程的實現原理,由於管程是一種互斥資源,修改互斥資源至少需要一個 CAS 操作。因此,鎖必然也使用了 lock 訊號,具有 mfence 的語義
- 鎖的 mfence 語義實現了 Happens-Before 關係中的監視器鎖規則
- 鎖機制保證了只有獲得鎖的執行緒才能夠操作鎖定的記憶體區域。JVM 內部實現了很多種鎖機制,有偏向鎖、輕量級鎖和互斥鎖。有意思的是除了偏向鎖,JVM 實現鎖的方式都用了迴圈 CAS,即當一個執行緒想進入同步塊的時候使用迴圈 CAS 的方式來獲取鎖,當它退出同步塊的時候使用迴圈 CAS 釋放鎖
- 鎖的記憶體語義:
- 當執行緒釋放鎖時,JMM 會把該執行緒對應的本地記憶體中的共享變數重新整理到主記憶體中
- 當執行緒獲取鎖時,JMM 會把該執行緒對應的本地記憶體置為無效
- 鎖記憶體語義的實現
- 公平鎖和非公平鎖釋放時,最後都要寫一個 volatile 變數 state
- 公平鎖獲取時,首先會去讀 volatile 變數
- 非公平鎖獲取時,首先會用 CAS 更新 volatile 變數,這個操作同時具有 volatile 讀和 volatile 寫的記憶體語義
- 鎖釋放-獲取的記憶體語義的實現至少有下面兩種方式
- 利用 volatile 變數的寫-讀所具有的記憶體語義
- 利用 CAS 所附帶的 volatile 讀和 volatile 寫的記憶體語義
- 由於 Java 的 CAS 同時具有 volatile 讀和 volatile 寫的記憶體語義,因此 Java 執行緒之間的通訊現在有了下面 4種方式
- A 執行緒寫 volatile 變數,隨後 B 執行緒讀這個 volatile 變數
- A 執行緒寫 volatile 變數,隨後 B 執行緒用 CAS 更新這個 volatile 變數
- A 執行緒用 CAS 更新一個 volatile 變數,隨後 B 執行緒用 CAS 更新這個 volatile 變數
- A 執行緒用 CAS 更新一個 volatile 變數,隨後 B 執行緒讀這個 volatile 變數

- JVM 解決可見性和重排序的方式
as-if-serial 語義
- 不管怎麼重排序(編譯器和處理器為了提高並行度),(單執行緒)程式的執行結果不能被改變。編譯器、runtime 和處理器都必須遵守 as-if-serial 語義
double pi = 3.14; // A double r = 1.0; // B double area = pi * r * r; // C // A 和 B 可以重排序執行,只要 C 最後執行就好了。這就是 as-if-serial - 在單執行緒程式中,對存在控制依賴的操作重排序,不會改變執行結果(這也是as-ifserial語義允許對存在控制依賴的操作做重排序的原因);但在多執行緒程式中,對存在控制依賴的操作重排序,可能會改變程式的執行結果
happens-before
-
happens-before 產生的原因
- 因為 jvm 會對程式碼進行編譯優化,指令會出現重排序的情況,為了避免編譯優化對併發程式設計安全性的影響,需要 happens-before 規則定義一些禁止編譯優化的場景,保證併發程式設計的正確性
public class VolatileExample { int x = 0 ; volatile boolean v = false; public void writer(){ x = 42; v = true; } public void reader(){ if (v == true){ // 這裡x會是多少呢 // jdk1.5 之前 x等於0或者42 // jdk1.5 之後 x等於42 } } }
- 因為 jvm 會對程式碼進行編譯優化,指令會出現重排序的情況,為了避免編譯優化對併發程式設計安全性的影響,需要 happens-before 規則定義一些禁止編譯優化的場景,保證併發程式設計的正確性
-
happens-before 簡介
- JSR-133 使用 happens-before 的概念來闡述操作之間的記憶體可見性 在 JMM 中,如果一個操作執行的結果需要對另一個操作可見,那麼這兩個操作之間必須要存在 happens-before 關係
-
JMM 把 happens-before 要求禁止的重排序分為兩類
- 會改變程式執行結果的重排序,JMM 要求編譯器和處理器必須禁止這種重排序
- 不會改變程式執行結果的重排序,JMM 對編譯器和處理器不做要求(JMM 允許這種重排序)
-
happens-before 的定義
- 如果一個操作 happens-before 另一個操作,那麼第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前
- 兩個操作之間存在 happens-before 關係,並不意味著 Java 平臺的具體實現必須要按照 happens-before 關係指定的順序來執行。happens-before 僅僅要求前一個操作(執行的結果)對後一個操作可見,且前一個操作按順序排在第二個操作之前,如果重排序之後的執行結果,與按 happens-before 關係來執行的結果一致,那麼這種重排序並不非法(也就是說,JMM允許這種重排序)
-
happens-before 規則
規則 內容 程式順序規則(最基本規則) 一個執行緒中的每個操作 happens-before 於該執行緒中的任意後續操作 監視器鎖規則 對一個鎖的解鎖,happens-before 於隨後對這個鎖的加鎖 volatile 變數規則 對一個 volatile 域的寫,happens-before 於任意後續對這個 volatile 域的讀 傳遞規則 如果 A happens-before B,且B happens-before C,那麼A happens-before C 執行緒啟動規則 Thread 物件的 start() 方法先行發生於此執行緒的每個一個動作 執行緒中斷規則 對執行緒 interrupt() 方法的呼叫先行發生於被中斷執行緒的程式碼檢測到中斷事件的發生 執行緒終結規則 執行緒中所有的操作都先行發生於執行緒的終止檢測,我們可以通過 Thread.join() 方法結束、Thread.isAlive() 的返回值手段檢測到執行緒已經終止執行 物件終結規則 一個物件的初始化完成先行發生於他的 finalize() 方法的開始 - 兩個操作之間具有 happens-before 關係,並不意味著前一個操作必須要在後一個操作之前執行!
-
happens-before 和 as-if-serial
- happens-before 關係本質上和 as-if-serial 語義是一回事
- as-if-serial 語義保證單執行緒內程式的執行結果不被改變,happens-before 關係保證正確同步的多執行緒程式的執行結果不被改變
- as-if-serial 語義給編寫單執行緒程式的程式設計師創造了一個幻境:單執行緒程式是按程式的順序來執行的。happens-before 關係給編寫正確同步的多執行緒程式的程式設計師創造了一個幻境:正確同步的多執行緒程式是按 happens-before 指定的順序來執行的
- as-if-serial 語義和 happens-before 這麼做的目的,都是為了在不改變程式執行結果的前提下,儘可能地提高程式執行的並行度
順序一致性
-
順序一致性簡介
- 順序一致性記憶體模型是一個理論參考模型,在設計的時候,處理器的記憶體模型和程式語言的記憶體模型都會以順序一致性記憶體模型作為參照
-
順序一致性記憶體模型特性
- 一個執行緒中的所有操作必須按照程式的順序來執行

- (不管程式是否同步)所有執行緒都只能看到一個單一的操作執行順序。在順序一致性記憶體模型中,每個操作都必須原子執行且立刻對所有執行緒可見

- 一個執行緒中的所有操作必須按照程式的順序來執行
-
JMM 的順序一致性
- 在 JMM 中就沒有這個保證。未同步程式在 JMM 中不但整體的執行順序是無序的,而且所有執行緒看到的操作執行順序也可能不一致。比如,在當前執行緒把寫過的資料快取在本地記憶體中,在沒有重新整理到主記憶體之前,這個寫操作僅對當前執行緒可見;從其他執行緒的角度來觀察,會認為這個寫操作根本沒有被當前執行緒執行。只有當前執行緒把本地記憶體中寫過的資料重新整理到主記憶體之後,這個寫操作才能對其他執行緒可見。在這種情況下,當前執行緒和其他執行緒看到的操作執行順序將不一致
class SynchronizedExample { int a = 0; boolean flag = false; public synchronized void writer() { // 獲取鎖 a = 1; flag = true; } // 釋放鎖 public synchronized void reader() { // 獲取鎖 if (flag) { int i = a; …… } // 釋放鎖 } }
- 在 JMM 中就沒有這個保證。未同步程式在 JMM 中不但整體的執行順序是無序的,而且所有執行緒看到的操作執行順序也可能不一致。比如,在當前執行緒把寫過的資料快取在本地記憶體中,在沒有重新整理到主記憶體之前,這個寫操作僅對當前執行緒可見;從其他執行緒的角度來觀察,會認為這個寫操作根本沒有被當前執行緒執行。只有當前執行緒把本地記憶體中寫過的資料重新整理到主記憶體之後,這個寫操作才能對其他執行緒可見。在這種情況下,當前執行緒和其他執行緒看到的操作執行順序將不一致

* 從這裡我們可以看到,JMM 在具體實現上的基本方針為:在不改變(正確同步的)程式執行結果的前提下,儘可能地為編譯器和處理器的優化開啟方便之門
-
未同步程式的執行特性
- 對於未同步或未正確同步的多執行緒程式,JMM 只提供最小安全性:執行緒執行時讀取到的值,要麼是之前某個執行緒寫入的值,要麼是預設值(0,Null,False),JMM 保證執行緒讀操作讀取到的值不會無中生有的冒出來。為了實現最小安全性,JVM 在堆上分配物件時,首先會對記憶體空間進行清零,然後才會在上面分配物件(JVM內部會同步這兩個操作)。因此,在已清零的記憶體空間分配物件時,域的預設初始化已經完成了。所以未同步程式在 JMM 中的執行時,整體上是無序的,其執行結果無法預知
-
未同步程式在兩個模型中的執行特性
- 順序一致性模型保證單執行緒內的操作會按程式的順序執行,而 JMM 不保證單執行緒內的操作會按程式的順序執行
- 順序一致性模型保證所有執行緒只能看到一致的操作執行順序,而 JMM 不保證所有執行緒能看到一致的操作執行順序
- JMM 不保證對 64 位的 long 型和 double 型變數的寫操作具有原子性,而順序一致性模型保證對所有的記憶體讀/寫操作都具有原子性
- 原因:假設處理器 A 寫一個 long 型變數,同時處理器 B 要讀這個 long 型變數。處理器 A 中 64 位的寫操作被拆分為兩個 32 位的寫操作,且這兩個 32 位的寫操作被分配到不同的寫事務中執行。同時,處理器 B 中 64 位的讀操作被分配到單個的讀事務中執行。處理器 B 可能只讀到處理器 A 寫了一半的無效值。從 JSR-133 記憶體模型開始(即從JDK5開始),僅僅只允許把一個 64 位 long/double 型變數的寫操作拆分為兩個 32 位的寫操作來執行,任意的讀操作在JSR-133 中都必須具有原子性(即任意讀操作必須要在單個讀事務中執行)
雙重檢查鎖定與延遲初始化
- 例子
public class DoubleCheckedLocking { // 1 private static Instance instance; // 2 public static Instance getInstance() { // 3 if (instance == null) { // 4:第一次檢查 synchronized (DoubleCheckedLocking.class) { // 5:加鎖 if (instance == null) // 6:第二次檢查 instance = new Instance(); // 7:問題的根源出在這裡 } // 8 } // 9 return instance; // 10 } } - 問題所在
- 線上程執行到第 4 行,程式碼讀取到 instance 不為 null 時,instance 引用的物件有可能還沒有完成初始化
- 問題根源
-
第 7 行可以分為虛擬碼
memory = allocate(); // 1:分配物件的記憶體空間 ctorInstance(memory); // 2:初始化物件 instance = memory; // 3:設定instance指向剛分配的記憶體地址 -
由於 2 和 3 之間可以重排序,只要保證訪問這個物件的時候 2 執行完畢,在單執行緒下就不會影響結果,但是多執行緒下是會有執行緒安全問題的
時間 執行緒A 執行緒B t1 A1:分配物件的內容空間 t2 A3:設定 instance 指向記憶體空間 t3 B1:判斷 instance 是否為空 t4 B2:由於 instance 不為空,執行緒 B 將訪問 instance 引用的物件 t5 A2:初始化物件 t6 A4:訪問 insatnce 引用的物件
-
- 解決
- 禁止 2 和 3 之間的重排序
- 2 和 3 重排序時,禁止其他執行緒看到
- 方案
- 方案一:
public class SafeDoubleCheckedLocking { private volatile static Instance instance; public static Instance getInstance() { if (instance == null) { synchronized (SafeDoubleCheckedLocking.class) { if (instance == null) instance = new Instance(); // instance為volatile,現在沒問題了 } } return instance; } } - 方案二
public class InstanceFactory { private static class InstanceHolder { public static Instance instance = new Instance(); } public static Instance getInstance() { return InstanceHolder.instance ; // 這裡將導致InstanceHolder類 被初始化 注意這裡是靜態內部類 // JVM在類初始化期間會獲取這個初始化鎖,並且每個執行緒至少獲取一次鎖來確保這個類已經被初始化過了 } } - 方案三
public class SingleInstance { private static final SingleInstance instance = new SingleInstance(); // 藉助final的記憶體語義 private SingleInstance() { } public static SingleInstance getInstance() { return instance; } }
- 方案一:
- 類初始化過程
-
第1階段:通過 在Class 物件上同步(即獲取 Class 物件的初始化鎖),來控制類或介面的初始化。這個獲取鎖的執行緒會一直等待,直到當前執行緒能夠獲取到這個初始化鎖
-
第2階段:執行緒 A 執行類的初始化,同時執行緒 B 在初始化鎖對應的 condition 上等待
-
第3階段:執行緒 A 設定 state=initialized,然後喚醒在 condition 中等待的所有執行緒。此時已經完成類的初始化!
-
第4階段:執行緒 B 結束類的初始化處理
-
第5階段:執行緒 C 執行類的初始化的處理
時間 執行緒A 執行緒B(或者C) t1 A1:嘗試獲取 class 物件的初始化鎖。這裡假設執行緒 A 獲取到了初始化鎖 B1:嘗試獲取 class 物件的初始化鎖,由於 A 獲取到鎖,執行緒 B 將一直等待獲取初始化鎖 t2 A2:執行緒 A 看到執行緒還未被初始化(state = NoInitialization),設定執行緒為 state = initializing t3 A3:執行緒 A 釋放初始化鎖 t4 A4:執行類的靜態初始化和初始化類中宣告的靜態欄位 B2:獲取到初始化鎖 t5 B3:讀取到 state = initializing t6 B4:釋放初始化鎖 t7 B5:在初始化鎖的 condition 中等待 t8 A5:獲取初始化鎖 t9 A6:設定 state = initialized t10 A7:喚醒在 condition 中等待的所有執行緒 t11 A8:釋放初始化鎖 t12 B6:獲取初始化鎖 t13 B7:讀取到 state = initialized t14 B8:釋放初始化鎖 t15 B9:執行緒 B 的類初始化處理過程完成 t16 C1:獲取初始化鎖 t17 C2:讀取到 state = initialized t18 C3:釋放初始化鎖 t19 C4:執行緒 C 的類初始化處理過程完成
-
第四章:Java 併發程式設計基礎
執行緒的簡介
-
程式和執行緒簡介
- 現代作業系統在執行一個程式時,會為其建立一個程式。例如,啟動一個 Java 程式,作業系統就會建立一個 Java 程式
- 現代作業系統排程的最小單元是執行緒,也叫輕量級程式,在一個程式裡可以建立多個執行緒,這些執行緒都擁有各自的計數器、堆疊和區域性變數等屬性,並且能夠訪問共享的記憶體變數。處理器在這些執行緒上高速切換,讓使用者感覺到這些執行緒在同時執行
- 程式和執行緒都是一個時間段的描述,是 CPU 工作時間段的描述,不過是顆粒大小不同
- 程式就是上下文切換之間的程式執行的部分。但程式的顆粒度太大,每次的執行都要進行程式上下文的切換。如果我們把程式比喻為一個執行在電腦上的軟體,那麼一個軟體的執行不可能是一條邏輯執行的,必定有多個分支和多個程式段,就好比要實現程式 A,實際分成 a,b,c 等多個塊組合而成。那麼這裡具體的執行就可能變成:程式 A 得到 CPU =》CPU 載入上下文,開始執行程式 A 的 a 小段,然後執行 A 的 b 小段,然後再執行 A 的 c 小段,最後 CPU 儲存 A 的上下文。這裡 a,b,c 的執行是共享了 A 程式的上下文,CPU 在執行的時候僅僅切換執行緒的上下文,而沒有進行程式上下文切換的。程式的上下文切換的時間開銷是遠遠大於執行緒上下文時間的開銷。這樣就讓 CPU 的有效使用率得到提高。這裡的 a,b,c 就是執行緒,也就是說執行緒是共享了程式的上下文環境,的更為細小的 CPU 時間段。執行緒主要共享的是程式的地址空間
-
程式、執行緒和協程的對比
程式 執行緒 協程 英文 Process Thread fiber/co-routine 解釋 cpu 執行的時間段 更細粒度的程式 fiber 約等於 Thread,co-routine 代表協作式排程(非搶佔式) 常見作業系統實現 核心級:程式是資源的一個單元,程式內有多個執行緒。程式包含了:1.虛擬地址空間;2.可執行程式碼;3.安全的上下文;4.唯一的程式標識;5.環境變數;6.系統物件的引用、檔案、裝置、socket、視窗;7.一個程式裡至少一個執行緒 核心級執行緒:執行緒是程式內排程和執行的單元;使用者級程式:如果記憶體空間並且搶佔式排程,這叫做使用者級執行緒,即當前的執行緒可能會被打斷並被另一個執行緒搶佔,執行緒包含了:1.分析程式的虛擬地址空間;2.分析程式的系統資源;3.有自己的異常處理;4.排程優先順序;5.本地現場儲存;6.唯一的執行緒表示;7.執行緒上下文。使用者級執行緒:1.實現方是使用者;2.不能被作業系統識別;3.實現難度簡單;4.上下文切換少;5.如果執行緒阻塞則所在程式阻塞;6.案例為:Java Thread/POXISthread。核心級執行緒:1.實現方是系統;2.作業系統可以識別;3.實現難度難;4.上下文切換鎖;5.如果執行緒阻塞所在程式不阻塞;6.Windows/Solaris 使用者級別執行緒:如果記憶體空間且非搶佔式排程,這叫做即協程 排程 1.排程方是作業系統核心;2.基於時鐘中斷;3.系統呼叫 1.呼叫方是作業系統核心;2.基於始終中斷;3.搶佔式 1.排程方是使用者級;2.非搶佔式;3.僅當執行緒讓出執行體的時候才被打斷 對比 相比程式:1.響應度好。一個執行緒完成後立即可以輸出;2.上下文切換速度塊,初始化和銷燬一個程式成本比執行緒要高;3.多核利用率高,可以安排同一個程式的不同執行緒到不同的 cpu 執行;4.同一個程式內執行緒資源共享;5.系統吞吐量大;6.執行緒和執行緒通訊成本高 相比執行緒:1.上下文切換速度塊;2.比較適用於事件驅動的程式設計;3.IO密集型處理量非常大 -
Java 程式與執行緒的區別
- 程式之間共享資訊可通過 TCP/IP 協議,執行緒間共享資訊可通過共用記憶體
- 程式是資源分配的最小單位,執行緒是 CPU 排程的最小單位
- 程式是搶佔處理機的排程單位;執行緒屬於某個程式,共享其資源
- 執行緒是程式的多個順序的流動態執行
- 執行緒不能夠獨立執行,必須依存在應用程式中,由應用程式提供多個執行緒執行控制
- 程式有獨立的地址空間,相互不影響,執行緒只是程式的不同執行路徑
- 執行緒沒有自己獨立的地址空間,多程式的程式比多執行緒的程式健壯
- 程式的切換比執行緒的切換開銷大
-
為什麼要使用多執行緒
- 更多的處理器核心
- 更快的響應時間
- 更好的程式設計模型
-
執行緒優先順序
- 現代作業系統基本採用時分的形式排程執行的執行緒,作業系統會分出一個個時間片,執行緒會分配到若干時間片,當執行緒的時間片用完了就會發生執行緒排程,並等待著下次分配。執行緒分配到的時間片多少也就決定了執行緒使用處理器資源的多少,而執行緒優先順序就是決定執行緒需要多或者少分配一些處理器資源的執行緒屬性
- 在 Java 執行緒中,通過一個整型成員變數 priority 來控制優先順序,優先順序的範圍從 1~10,線上程構建的時候可以通過 setPriority(int) 方法來修改優先順序,預設優先順序是 5,優先順序高的執行緒分配時間片的數量要多於優先順序低的執行緒。設定執行緒優先順序時,針對頻繁阻塞(休眠或者I/O操作)的執行緒需要設定較高優先順序,而偏重計算(需要較多CPU時間或者偏運算)的執行緒則設定較低的優先順序,確保處理器不會被獨佔。在不同的JVM以及作業系統上,執行緒規劃會存在差異,有些作業系統甚至會忽略對執行緒優先順序的設定
-
執行緒的狀態
狀態名稱 說明 NEW 初始狀態,執行緒被構建,但是還沒有呼叫start()方法 RUNNABLE 執行狀態,Java執行緒將作業系統中的就緒和執行兩種狀態籠統的稱為“執行中” BLOCKED 阻塞狀態,表示執行緒阻塞於鎖 WAITING 等待狀態,表示執行緒進入等待狀態,進入該狀態表示當前執行緒需要等待其他執行緒做出一些特定工作(通知或中斷) TIME_WAITING 超時等待狀態,該狀態不同於WAITING,它可以在指定的時間自行返回 TERMINATED 終止狀態,表示當前執行緒已經執行完畢 - Java 將作業系統中的執行和就緒兩個狀態合併稱為執行狀態。阻塞狀態是執行緒阻塞在進入 synchronized 關鍵字修飾的方法或程式碼塊(獲取鎖)時的狀態,但是阻塞在 java.concurrent 包中 Lock 介面的執行緒狀態卻是等待狀態,因為 java.concurrent 包中 Lock 介面對於阻塞的實現均使用了 LockSupport 類中的相關方法
-
Daemon 執行緒
- Daemon 執行緒是一種支援型執行緒,因為它主要被用作程式中後臺排程以及支援性工作。這意味著,當一個 Java 虛擬機器中不存在非 Daemon 執行緒的時候,Java 虛擬機器將會退出。可以通過呼叫Thread.setDaemon(true) 將執行緒設定為 Daemon 執行緒。注意 Daemon 屬性需要在啟動執行緒之前設定,不能在啟動執行緒之後設定。在構建 Daemon 執行緒時,不能依靠 finally 塊中的內容來確保執行關閉或清理資源的邏輯
啟動和終止執行緒
-
構造執行緒
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc) { if (name == null) { throw new NullPointerException("name cannot be null"); } // 當前執行緒就是該執行緒的父執行緒 Thread parent = currentThread(); this.group = g; // 將daemon、priority屬性設定為父執行緒的對應屬性 this.daemon = parent.isDaemon(); this.priority = parent.getPriority(); this.name = name.toCharArray(); this.target = target; setPriority(priority); // 將父執行緒的InheritableThreadLocal複製過來 if (parent.inheritableThreadLocals != null) this.inheritableThreadLocals=ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); // 分配一個執行緒ID tid = nextThreadID(); }在上述過程中,一個新構造的執行緒物件是由其 parent 執行緒來進行空間分配的,而 child 執行緒繼承了 parent 是否為 Daemon、優先順序和載入資源的 contextClassLoader 以及可繼承的 ThreadLocal,同時還會分配一個唯一的 ID 來標識這個 child 執行緒。至此,一個能夠執行的執行緒物件就初始化好了,在堆記憶體中等待著執行
-
啟動執行緒
- 執行緒物件在初始化完成之後,呼叫 start() 方法就可以啟動這個執行緒。執行緒 start() 方法的含義是:當前執行緒(即 parent 執行緒)同步告知 Java 虛擬機器,只要執行緒規劃器空閒,應立即啟動呼叫 start() 方法的執行緒
- 啟動一個執行緒前,最好為這個執行緒設定執行緒名稱,因為這樣在使用 jstack 分析程式或者進行問題排查時,就會給開發人員提供一些提示,自定義的執行緒最好能夠起個名字
-
理解中斷
- 中斷可以理解為執行緒的一個標識位屬性,它表示一個執行中的執行緒是否被其他執行緒進行了中斷操作
- 執行緒通過檢查自身是否被中斷來進行響應,執行緒通過方法 isInterrupted() 來進行判斷是否被中斷,也可以呼叫靜態方法 Thread.interrupted() 對當前執行緒的中斷標識位進行復位。如果該執行緒已經處於終結狀態,即使該執行緒被中斷過,在呼叫該執行緒物件的 isInterrupted() 時依舊會返回 false
執行緒間通訊
-
volatile 和 synchronized 關鍵字
- 關鍵字 volatile 可以用來修飾欄位(成員變數),就是告知程式任何對該變數的訪問均需要從共享記憶體中獲取,而對它的改變必須同步重新整理回共享記憶體,它能保證所有執行緒對變數訪問的可見性
- 關鍵字 synchronized 可以修飾方法或者以同步塊的形式來進行使用,它主要確保多個執行緒在同一個時刻,只能有一個執行緒處於方法或者同步塊中,它保證了執行緒對變數訪問的可見性和排他性

-
等待/通知機制
- 等待/通知機制,是指一個執行緒 A 呼叫了物件 O 的 wait() 方法進入等待狀態,而另一個執行緒 B 呼叫了物件 O 的 notify() 或者 notifyAll() 方法,執行緒 A 收到通知後從物件 O 的 wait() 方法返回,進而執行後續操作。上述兩個執行緒通過物件 O 來完成互動,而物件上的 wait() 和 notify/notifyAll() 的關係就如同開關訊號一樣,用來完成等待方和通知方之間的互動工作
- 需要注意的細節
- 使用 wait()、notify() 和 notifyAll() 時需要先對呼叫物件加鎖
- 呼叫 wait() 方法後,執行緒狀態由 RUNNIN 變為 WAITING,並將當前執行緒放置到物件的等待佇列
- notify() 或 notifyAll() 方法呼叫後,等待執行緒依舊不會從 wait() 返回,需要呼叫 notify() 或 notifAll() 的執行緒釋放鎖之後,等待執行緒才有機會從 wait() 返回
- notify() 方法將等待佇列中的一個等待執行緒從等待佇列中移到同步佇列中,而 notifyAll() 方法則是將等待佇列中所有的執行緒全部移到同步佇列,被移動的執行緒狀態由 WAITING 變為BLOCKED
- 從 wait() 方法返回的前提是獲得了呼叫物件的鎖

-
等待/通知的經典正規化
- 等待方遵循如下原則:
- 獲取物件的鎖
- 如果條件不滿足,那麼呼叫物件的 wait() 方法,被通知後仍要檢查條件
- 條件滿足則執行對應的邏輯
- 通知方遵循如下原則:
- 獲得物件的鎖
- 改變條件
- 通知所有等待在物件上的執行緒
- 等待方遵循如下原則:
-
管道輸入/輸出流
- 管道輸入/輸出流和普通的檔案輸入/輸出流或者網路輸入/輸出流不同之處在於,它主要用於執行緒之間的資料傳輸,而傳輸的媒介為記憶體
- 管道輸入/輸出流主要包括瞭如下4種具體實現:PipedOutputStream、PipedInputStream、PipedReader和PipedWriter,前兩種面向位元組,而後兩種面向字元
-
Thread.join() 的使用
- 如果一個執行緒 A 執行了 thread.join() 語句,其含義是:當前執行緒 A 等待 thread 執行緒終止之後才從 thread.join() 返回
// 加鎖當前執行緒物件 public final synchronized void join() throws InterruptedException { // 條件不滿足,繼續等待 while (isAlive()) { wait(0); } // 條件符合,方法返回 } -
ThreadLocal 的使用
- ThreadLocal 介紹
- ThreadLocal,很多地方叫做執行緒本地變數,也有些地方叫做執行緒本地儲存,是一個以 ThreadLocal 物件為鍵、任意物件為值的儲存結構。這個結構被附帶線上程上,也就是說一個執行緒可以根據一個 ThreadLocal 物件查詢到繫結在這個執行緒上的一個值。可以通過 set(T) 方法來設定一個值,在當前執行緒下再通過 get() 方法獲取到原先設定的值
- ThreadLocal 的常用方法
- void set(T value):設定當前執行緒的執行緒區域性變數的值
- public T get():該方法返回當前執行緒所對應的執行緒區域性變數
- public void remove():將當前執行緒區域性變數的值刪除。當執行緒結束後,對應該執行緒的區域性變數將自動被垃圾回收,所以顯式呼叫該方法清除執行緒的區域性變數並不是必須的操作,但它可以加快記憶體回收的速度
- protected T initialValue():返回該執行緒區域性變數的初始值,該方法是一個 protected 的方法,顯然是為了讓子類覆蓋而設計的。這個方法是一個延遲呼叫方法,線上程第 1 次呼叫 get() 或 set(T) 時才執行,並且僅執行 1 次。ThreadLocal 中的預設實現直接返回一個 null
- ThreadLocal 建立本地變數的過程
- 首先,在每個執行緒 Thread 內部有一個 ThreadLocal.ThreadLocalMap 型別的成員變數 threadLocals,這個 threadLocals 就是用來儲存實際的變數副本的,鍵值為當前 ThreadLocal 變數,value 為變數副本(即T型別的變數)
- 初始時,在 Thread 裡面,threadLocals 為空,當通過 ThreadLocal 變數呼叫 get() 方法或者 set() 方法,就會對 Thread 類中的 threadLocals 進行初始化,並且以當前 ThreadLocal 變數為鍵值,以ThreadLocal 要儲存的副本變數為 value,存到 threadLocals
- 然後在當前執行緒裡面,如果要使用副本變數,就可以通過 get() 方法在 threadLocals 裡面查詢
- 注意
- ThreadLocalMap 中的 Entry 的 key 使用的是 ThreadLocal 物件的弱引用,在沒有其他地方對 ThreadLocal 依賴,ThreadLocalMap 中的 ThreadLocal 物件就會被回收掉,但是對應的不會被回收,這個時候 Map 中就可能存在 key 為 null 但是 value 不為 null 的項,這需要實際的時候使用完畢及時呼叫 remove 方法避免記憶體洩漏
- JDK 建議 ThreadLocal 定義為 private static,這樣 ThreadLocal 的弱引用問題則不存在了
- ThreadLocal 介紹
第五章:Java 中的鎖
Lock 介面
-
Lock 介紹
- 鎖是用來控制多個執行緒訪問共享資源的方式。在 Lock 介面出現之前,Java 程式是靠 synchronized 關鍵字實現鎖功能的,而 Java SE 5 之後,併發包中新增了 Lock 介面(以及相關實現類)用來實現鎖功能,它提供了與 synchronized 關鍵字類似的同步功能,只是在使用時需要顯式地獲取和釋放鎖。雖然它缺少了(通過 synchronized 塊或者方法所提供的)隱式獲取釋放鎖的便捷性,但是卻擁有了鎖獲取與釋放的可操作性、可中斷的獲取鎖以及超時獲取鎖等多種 synchronized 關鍵字所不具備的同步特性
-
Lock 的簡單實用方法
Lock lock = new ReentrantLock(); lock.lock(); try { } finally { lock.unlock(); } -
Lock 的API
public interface Lock { // 獲取鎖 void lock(); // 響應中斷地獲取鎖 void lockInterruptibly() throws InterruptedException; // 嘗試獲取鎖,若獲取鎖失敗,方法立即返回 boolean tryLock(); // 在給定的時間內嘗試獲取鎖,在此時間段內仍未獲取到鎖,最終方法還是將返回 boolean tryLock(long time, TimeUnit unit) throws InterruptedException; // 釋放鎖 void unlock(); /** * 返回一個與當前鎖繫結的新Condition例項,可以繫結多個Condition例項<br/> * 此Condition例項用作執行緒通訊,類似於Object的nofify()/wait() */ Condition newCondition(); }
佇列同步器-AQS
-
AQS 簡介
- 佇列同步器 AbstractQueuedSynchronizer(以下簡稱同步器或 AQS),是用來構建鎖或者其他同步元件的基礎框架,它使用了一個 int 成員變數表示同步狀態,通過內建的 FIFO 佇列來完成資源獲取執行緒的排隊工作
- AQS 自身沒有實現任何同步介面,它僅僅是定義了若干同步狀態獲取和釋放的方法來供自定義同步元件使用,AQS 既可以支援獨佔式地獲取同步狀態,也可以支援共享式地獲取同步狀態
-
AQS 和鎖的區別
- 鎖是面向使用者的,它定義了使用者與鎖互動的介面(比如可以允許兩個執行緒並行訪問),隱藏了實現細節
- AQS 面向的是鎖的實現者,它簡化了鎖的實現方式,遮蔽了同步狀態管理、執行緒的排隊、等待與喚醒等底層操作
-
AQS的介面與示例
- AQS 的設計是基於模板方法模式的,也就是說,使用者需要繼承 AQS 並重寫指定的方法,隨後將同步器組合在自定義同步元件的實現中,並呼叫 AQS 提供的模板方法,而這些模板方法將會呼叫使用者重寫的方法
- 實現了 AQS 的鎖有:自旋鎖、互斥鎖、讀鎖寫鎖、條件產量、訊號量、柵欄
- 重寫 AQS 指定的方法時,需要使用 AQS 提供的如下 3 個方法來訪問或修改同步狀態
- getState():獲取當前同步狀態
- setState(int newState):設定當前同步狀態
- compareAndSetState(int expect,int update):使用 CAS 設定當前狀態,該方法能夠保證狀態設定的原子性
- AQS 可重寫的方法
方法名稱 描述 tryAcquire(int arg) 獨佔獲取同步狀態,實現該方法需要查詢當前狀態,並判斷同步狀態是否符合預期狀態,然後再進行 CAS 設定同步狀態 treRelease(int arg) 獨佔式釋放同步狀態,等待獲取同步狀態的執行緒將有機會獲取同步狀態 tryAcquireShared(int arg) 共享式獲取同步狀態,返回大於等於 0 的值,表示獲取成功,反之失敗 tryReleaseShared(int arg) 共享式釋放同步狀態 isHeldExclusively() 當前同步器是否在獨佔模式下被執行緒佔用,一般該方法表示是否被當前執行緒所獨佔 - 實現自定義同步元件時,將會呼叫 AQS 提供的模板方法,AQS 提供的模版方法基本上分為 3 類
- 獨佔式獲取與釋放同步狀態
- 共享式獲取與釋放同步狀態
- 查詢同步佇列中的等待執行緒情況
- AQS 的設計是基於模板方法模式的,也就是說,使用者需要繼承 AQS 並重寫指定的方法,隨後將同步器組合在自定義同步元件的實現中,並呼叫 AQS 提供的模板方法,而這些模板方法將會呼叫使用者重寫的方法
-
AQS 的實現分析
-
同步佇列
- AQS 依賴內部的同步佇列(一個FIFO雙向佇列)來完成同步狀態的管理,當前執行緒獲取同步狀態失敗時,AQS 會將當前執行緒以及等待狀態等資訊構造成為一個節點(Node)並將其加入同步佇列,同時會阻塞當前執行緒,當同步狀態釋放時,會把首節點中的執行緒喚醒,使其再次嘗試獲取同步狀態。同步佇列中的節點(Node)用來儲存獲取同步狀態失敗的執行緒引用、等待狀態以及前驅和後繼節點
- 節點是構成同步佇列的基礎,AQS 擁有首節點(head)和尾節點(tail),沒有成功獲取同步狀態的執行緒將會成為節點加入該佇列的尾部。同步佇列遵循 FIFO,首節點是獲取同步狀態成功的節點,首節點的執行緒在釋放同步狀態時,將會喚醒後繼節點,而後繼節點將會在獲取同步狀態成功時將自己設定為首節點
屬性型別與名稱 描述 int waitStatus 等待狀態:1.CANCELLED,值為1,由於在同步佇列中等待的執行緒等待超時獲取被中斷,需要從同步佇列中取消等待,節點進入該狀態將不會變化;2.SIGNAL,值為-1,後繼節點的執行緒處於等待狀態,而當前節點的執行緒如果釋放了同步狀態或者被取消,將會通知後繼節點,使後繼節點執行緒得以執行;3.CONDITION,值為-2,節點在等待佇列中,節點執行緒等待在Condition上,當其他執行緒對Condition呼叫了signal()方法後,該節點將會從等待佇列中轉移到同步佇列中,加入到對同步狀態的獲取中;4.PROPAGATE,值為-3,表示下一次共享式同步狀態獲取將會無條件地被傳播下去;5.INITIAl ,值為0,初始狀態 Node prev 前驅節點,當節點加入同步佇列時被設定(尾部新增) Node next 後繼節點 Node nextWaiter 等待佇列中的後繼節點,如果當前節點時共享的,那麼這個欄位將是一個SHARED常量,也就是節點型別(獨佔和共享)和等待佇列中的後繼節點公用同一個欄位 Thread thread 獲取同步狀態的執行緒
-
獨佔式同步狀態獲取與釋放
- 首先呼叫自定義同步器實現的 tryAcquire(int arg) 方法,該方法保證執行緒安全的獲取同步狀態,如果同步狀態獲取失敗,則構造同步節點(獨佔式Node.EXCLUSIVE,同一時刻只能有一個執行緒成功獲取同步狀態)並通過 addWaiter(Nodenode) 方法將該節點加入到同步佇列的尾部,最後呼叫 acquireQueued(Node node,int arg) 方法,使得該節點以“死迴圈”的方式獲取同步狀態。如果獲取不到則阻塞節點中的執行緒,而被阻塞執行緒的喚醒主要依靠前驅節點的出隊或阻塞執行緒被中斷來實現
// 該方法主要完成了同步狀態獲取、節點構造、加入同步佇列以及在同步佇列中自旋等待的相關工作 public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); } private Node addWaiter(Node mode) { Node node = new Node(Thread.currentThread(), mode); // 快速嘗試在尾部新增 Node pred = tail; if (pred != null) { node.prev = pred; // 用compareAndSetTail(Node expect,Node update)方法來確保節點能夠被執行緒安全新增 if (compareAndSetTail(pred, node)) { pred.next = node; return node; } } enq(node); return node; } // 同步器通過“死迴圈”來保證節點的正確新增,在“死迴圈”中只有通過CAS將節點設定成為尾節點之後,當前執行緒才能從該方法返回,否則,當前執行緒不斷地嘗試設定 private Node enq(final Node node) { for (;;) { Node t = tail; if (t == null) { // Must initialize if (compareAndSetHead(new Node())) tail = head; } else { node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } } //當前執行緒在“死迴圈”中嘗試獲取同步狀態,而只有前驅節點是頭節點才能夠嘗試獲取同步狀態 // 第一,頭節點是成功獲取到同步狀態的節點,而頭節點的執行緒釋放了同步狀態之後,將會喚醒其後繼節點,後繼節點的執行緒被喚醒後需要檢查自己的前驅節點是否是頭節點。 // 第二,維護同步佇列的FIFO原則 final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } ```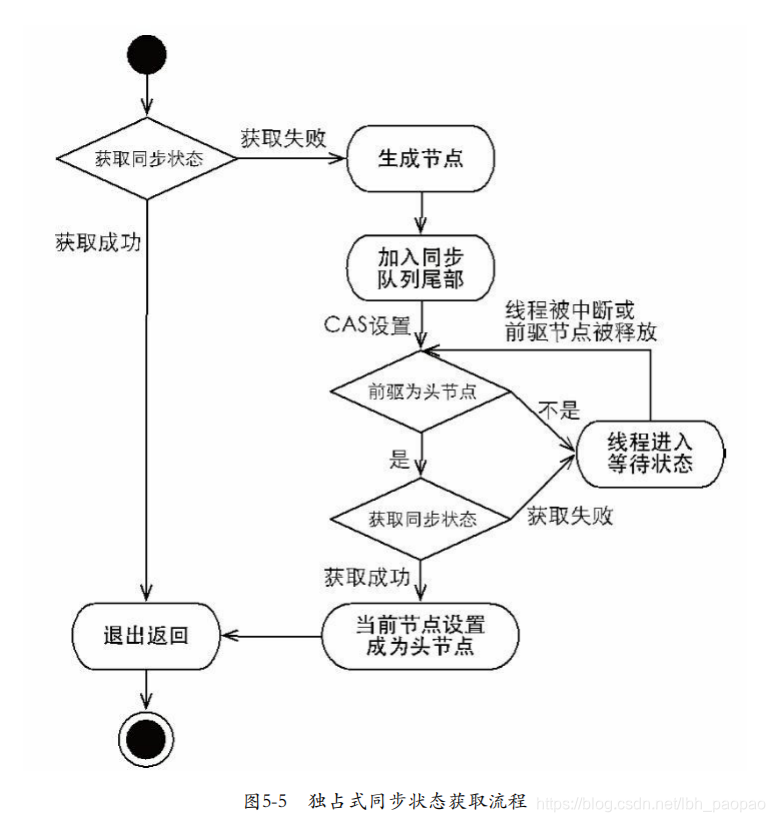 - 當前執行緒獲取同步狀態並執行了相應邏輯之後,就需要釋放同步狀態,使得後續節點能夠繼續獲取同步狀態。通過呼叫同步器的 release(int arg) 方法可以釋放同步狀態,該方法在釋放了同步狀態之後,會喚醒其後繼節點(進而使後繼節點重新嘗試獲取同步狀態)
public final boolean release(int arg) { if (tryRelease(arg)) { Node h = head; if (h != null && h.waitStatus != 0) unparkSuccessor(h); return true; } return false; } - 在獲取同步狀態時,同步器維護一個同步佇列,獲取狀態失敗的執行緒都會被加入到佇列中並在佇列中進行自旋;移出佇列(或停止自旋)的條件是前驅節點為頭節點且成功獲取了同步狀態。在釋放同步狀態時,同步器呼叫 tryRelease(int arg) 方法釋放同步狀態,然後喚醒頭節點的後繼節點
- 首先呼叫自定義同步器實現的 tryAcquire(int arg) 方法,該方法保證執行緒安全的獲取同步狀態,如果同步狀態獲取失敗,則構造同步節點(獨佔式Node.EXCLUSIVE,同一時刻只能有一個執行緒成功獲取同步狀態)並通過 addWaiter(Nodenode) 方法將該節點加入到同步佇列的尾部,最後呼叫 acquireQueued(Node node,int arg) 方法,使得該節點以“死迴圈”的方式獲取同步狀態。如果獲取不到則阻塞節點中的執行緒,而被阻塞執行緒的喚醒主要依靠前驅節點的出隊或阻塞執行緒被中斷來實現
-
共享式同步狀態獲取與釋放
- 共享式獲取與獨佔式獲取最主要的區別在於同一時刻能否有多個執行緒同時獲取到同步狀態,例如檔案的讀寫
- 在 acquireShared(int arg) 方法中,同步器呼叫 tryAcquireShared(int arg) 方法嘗試獲取同步狀態,tryAcquireShared(int arg) 方法返回值為 int 型別,當返回值大於等於 0 時,表示能夠獲取到同步狀態。因此,在共享式獲取的自旋過程中,成功獲取到同步狀態並退出自旋的條件就是 tryAcquireShared(int arg) 方法返回值大於等於 0。可以看到,在 doAcquireShared(int arg) 方法的自旋過程中,如果當前節點的前驅為頭節點時,嘗試獲取同步狀態,如果返回值大於等於 0,表示該次獲取同步狀態成功並從自旋過程中退出
public final void acquireShared(int arg) { if (tryAcquireShared(arg) < 0) doAcquireShared(arg); } private void doAcquireShared(int arg) { final Node node = addWaiter(Node.SHARED); boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head) { int r = tryAcquireShared(arg); if (r >= 0) { setHeadAndPropagate(node, r); p.next = null; if (interrupted) selfInterrupt(); failed = false; return; } } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } - 共享式通過呼叫 releaseShared(int arg) 方法可以釋放同步狀態,該方法在釋放同步狀態之後,將會喚醒後續處於等待狀態的節點。對於能夠支援多個執行緒同時訪問的併發元件(比如Semaphore),它和獨佔式主要區別在於 tryReleaseShared(int arg) 方法必須確保同步狀態(或者資源數)執行緒安全釋放,一般是通過迴圈和 CAS 來保證的,因為釋放同步狀態的操作會同時來自多個執行緒
public final boolean releaseShared(int arg) { if (tryReleaseShared(arg)) { doReleaseShared(); return true; } return false; }
-
獨佔式超時獲取同步狀態
- 通過呼叫同步器的 doAcquireNanos(int arg,long nanosTimeout) 方法可以超時獲取同步狀態,即在指定的時間段內獲取同步狀態,如果獲取到同步狀態則返回 true,否則,返回 false
- 在 Java 5 之前,當一個執行緒獲取不到鎖而被阻塞在 synchronized 之外時,對該執行緒進行中斷操作,此時該執行緒的中斷標誌位會被修改,但執行緒依舊會阻塞在 synchronized 上,等待著獲取鎖。在 Java 5 中,同步器提供了 acquireInterruptibly(int arg) 方法,這個方法在等待獲取同步狀態時,如果當前執行緒被中斷,會立刻返回,並丟擲 InterruptedException
- 超時獲取同步狀態過程可以被視作響應中斷獲取同步狀態過程的“增強版”,doAcquireNanos(int arg,long nanosTimeout) 方法在支援響應中斷的基礎上,增加了超時獲取的特性。針對超時獲取,主要需要計算出需要睡眠的時間間隔 nanosTimeout,為了防止過早通知,nanosTimeout 計算公式為:nanosTimeout-=now-lastTime,其中 now 為當前喚醒時間,lastTime 為上次喚醒時間,如果 nanosTimeout 大於 0 則表示超時時間未到,需要繼續睡眠 nanosTimeout 納秒,反之,表示已經超時
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException { long lastTime = System.nanoTime(); final Node node = addWaiter(Node.EXCLUSIVE); boolean failed = true; try { for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return true; } if (nanosTimeout <= 0) return false; if (shouldParkAfterFailedAcquire(p, node) && nanosTimeout > spinForTimeoutThreshold) LockSupport.parkNanos(this, nanosTimeout); long now = System.nanoTime(); //計算時間,當前時間now減去睡眠之前的時間lastTime得到已經睡眠 //的時間delta,然後被原有超時時間nanosTimeout減去,得到了 //還應該睡眠的時間 nanosTimeout -= now - lastTime; lastTime = now; if (Thread.interrupted()) throw new InterruptedException(); } } finally { if (failed) cancelAcquire(node); } } - 該方法在自旋過程中,當節點的前驅節點為頭節點時嘗試獲取同步狀態,如果獲取成功則從該方法返回,這個過程和獨佔式同步獲取的過程類似,但是在同步狀態獲取失敗的處理上有所不同。如果當前執行緒獲取同步狀態失敗,則判斷是否超時(nanosTimeout 小於等於 0 表示已經超時),如果沒有超時,重新計算超時間隔 nanosTimeout,然後使當前執行緒等待 nanosTimeout 納秒(當已到設定的超時時間,該執行緒會從 LockSupport.parkNanos(Object locker,long nanos) 方法返回)。如果 nanosTimeout 小於等於 spinForTimeoutThreshold(1000納秒) 時,將不會使該執行緒進行超時等待,而是進入快速的自旋過程。原因在於,非常短的超時等待無法做到十分精確,如果這時再進行超時等待,相反會讓 nanosTimeout 的超時從整體上表現得反而不精確。因此,在超時非常短的場景下,同步器會進入無條件的快速自旋

-
自定義同步元件-TwinsLock
- 在前面的章節中,對 AQS 進行了實現層面的分析,本節通過編寫一個自定義同步元件來加深對 AQS 的理解
- 設計一個同步工具:該工具在同一時刻,只允許至多兩個執行緒同時訪問,超過兩個執行緒的訪問將被阻塞,我們將這個同步工具命名為 TwinsLock
- 首先,確定訪問模式。TwinsLock 能夠在同一時刻支援多個執行緒的訪問,這顯然是共享式訪問,因此,需要使用同步器提供的 acquireShared(int args) 方法等和 Shared 相關的方法,這就要求 TwinsLock 必須重寫 tryAcquireShared(int args) 方法和 tryReleaseShared(int args) 方法,這樣才能保證同步器的共享式同步狀態的獲取與釋放方法得以執行
- 其次,定義資源數。TwinsLock 在同一時刻允許至多兩個執行緒的同時訪問,表明同步資源數為 2,這樣可以設定初始狀態 status 為 2,當一個執行緒進行獲取,status 減 1,該執行緒釋放,則 status 加 1,狀態的合法範圍為 0、1 和 2,其中 0 表示當前已經有兩個執行緒獲取了同步資源,此時再有其他執行緒對同步狀態進行獲取,該執行緒只能被阻塞。在同步狀態變更時,需要使用 compareAndSet(int expect,int update) 方法做原子性保障
- 最後,組合自定義同步器。前面的章節提到,自定義同步元件通過組合自定義同步器來完成同步功能,一般情況下自定義同步器會被定義為自定義同步元件的內部類
// 實現 public class TwinsLock implements Lock { private final Sync sync = new Sync(2); private static final class Sync extends AbstractQueuedSynchronizer { Sync(int count) { if (count <= 0) { throw new IllegalArgumentException("count must large than zero."); } setState(count); } public int tryAcquireShared(int reduceCount) { for (;;) { int current = getState(); int newCount = current - reduceCount; if (newCount < 0 || compareAndSetState(current, newCount)) { return newCount; } } } public boolean tryReleaseShared(int returnCount) { for (;;) { int current = getState(); int newCount = current + returnCount; if (compareAndSetState(current, newCount)) { return true; } } } } public void lock() { sync.acquireShared(1); } public void unlock() { sync.releaseShared(1); } // 其他介面方法略 } // 測試 public class TwinsLockTest { @Test public void test() { final Lock lock = new TwinsLock(); class Worker extends Thread { public void run() { while (true) { lock.lock(); try { SleepUtils.second(1); System.out.println(Thread.currentThread().getName()); SleepUtils.second(1); } finally { lock.unlock(); } } } } // 啟動10個執行緒 for (int i = 0; i < 10; i++) { Worker w = new Worker(); w.setDaemon(true); w.start(); } // 每隔1秒換行 for (int i = 0; i < 10; i++) { SleepUtils.second(1); System.out.println(); } } }
-
重入鎖
-
重入鎖 ReentrantLock,顧名思義,就是支援重進入的鎖,它表示該鎖能夠支援一個執行緒對資源的重複加鎖。除此之外,該鎖的還支援獲取鎖時的公平和非公平性選擇
- synchronized 關鍵字隱式的支援重進入,比如一個 synchronized 修飾的遞迴方法,在方法執行時,執行執行緒在獲取了鎖之後仍能連續多次地獲得該鎖,ReentrantLock 雖然沒能像 synchronized 關鍵字一樣支援隱式的重進入,但是在呼叫 lock() 方法時,已經獲取到鎖的執行緒,能夠再次呼叫 lock() 方法獲取鎖而不被阻塞
- 這裡提到一個鎖獲取的公平性問題,如果在絕對時間上,先對鎖進行獲取的請求一定先被滿足,那麼這個鎖是公平的,反之,是不公平的。公平的獲取鎖,也就是等待時間最長的執行緒最優先獲取鎖,也可以說鎖獲取是順序的。ReentrantLock 提供了一個建構函式,能夠控制鎖是否是公平的。事實上,公平的鎖機制往往沒有非公平的效率高,但是,並不是任何場景都是以 TPS 作為唯一的指標,公平鎖能夠減少“飢餓”發生的概率,等待越久的請求越是能夠得到優先滿足
-
實現重進入:重進入是指任意執行緒在獲取到鎖之後能夠再次獲取該鎖而不會被鎖所阻塞,該特性的實現需要解決以下兩個問題
- 執行緒再次獲取鎖。鎖需要去識別獲取鎖的執行緒是否為當前佔據鎖的執行緒,如果是,則再次成功獲取
- 鎖的最終釋放。執行緒重複 n 次獲取了鎖,隨後在第 n 次釋放該鎖後,其他執行緒能夠獲取到該鎖。鎖的最終釋放要求鎖對於獲取進行計數自增,計數表示當前鎖被重複獲取的次數,而鎖被釋放時,計數自減,當計數等於 0 時表示鎖已經成功釋放
- ReentrantLock 是通過組合自定義同步器來實現鎖的獲取與釋放,預設非公平性,該方法增加了再次獲取同步狀態的處理邏輯:通過判斷當前執行緒是否為獲取鎖的執行緒來決定獲取操作是否成功,如果是獲取鎖的執行緒再次請求,則將同步狀態值進行增加並返回 true,表示獲取同步狀態成功
final boolean nonfairTryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; } - 成功獲取鎖的執行緒再次獲取鎖,只是增加了同步狀態值,這也就要求 ReentrantLock 在釋放同步狀態時減少同步狀態值
protected final boolean tryRelease(int releases) { int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) throw new IllegalMonitorStateException(); boolean free = false; if (c == 0) { free = true; setExclusiveOwnerThread(null); } setState(c); return free; }
-
公平與非公平獲取鎖的區別
- 公平性與否是針對獲取鎖而言的,如果一個鎖是公平的,那麼鎖的獲取順序就應該符合請求的絕對時間順序,也就是 FIFO,對於非公平鎖,只要 CAS 設定同步狀態成功,則表示當前執行緒獲取了鎖,而公平鎖則不同,該實現增加了 hasQueuedPredecessors() 方法,即加入了同步佇列中當前節點是否有前驅節點的判斷,如果該方法返回true,則表示有執行緒比當前執行緒更早地請求獲取鎖,因此需要等待前驅執行緒獲取並釋放鎖之後才能繼續獲取鎖
protected final boolean tryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; } - 公平性鎖保證了鎖的獲取按照 FIFO 原則,而代價是進行大量的執行緒切換。非公平性鎖雖然可能造成執行緒“飢餓”,但極少的執行緒切換,保證了其更大的吞吐量
- 公平性與否是針對獲取鎖而言的,如果一個鎖是公平的,那麼鎖的獲取順序就應該符合請求的絕對時間順序,也就是 FIFO,對於非公平鎖,只要 CAS 設定同步狀態成功,則表示當前執行緒獲取了鎖,而公平鎖則不同,該實現增加了 hasQueuedPredecessors() 方法,即加入了同步佇列中當前節點是否有前驅節點的判斷,如果該方法返回true,則表示有執行緒比當前執行緒更早地請求獲取鎖,因此需要等待前驅執行緒獲取並釋放鎖之後才能繼續獲取鎖
讀寫鎖
-
讀寫鎖概述
- 讀寫鎖在同一時刻可以允許多個讀執行緒訪問,但是在寫執行緒訪問時,所有的讀執行緒和其他寫執行緒均被阻塞。讀寫鎖維護了一對鎖,一個讀鎖和一個寫鎖,通過分離讀鎖和寫鎖,使得併發性相比一般的排他鎖有了很大提升。Java 併發包提供讀寫鎖的實現是 ReentrantReadWriteLock
- ReentrantReadWriteLock 的特性
- 公平性選擇:支援非公平(預設)和公平的鎖獲取方式,吞吐量還是非公平優於公平
- 重進入:該鎖支援重進入,以讀寫執行緒為例,讀執行緒在獲取了鎖之後,能夠再次獲取讀鎖。而寫執行緒在獲取了寫鎖之後能夠再次獲得寫鎖,同時也可以或獲取讀鎖
- 鎖降級:遵循獲取寫鎖,獲取讀鎖,再釋放寫鎖的次序,寫鎖能夠降級成為讀鎖
-
讀寫鎖的介面與示例
- ReadWriteLock 僅定義了獲取讀鎖和寫鎖的兩個方法,即 readLock() 方法和 writeLock() 方法,而其實現——ReentrantReadWriteLock,除了介面方法之外,還提供了一些便於外界監控其內部工作狀態的方法
- int getReadLockCount():返回當前讀鎖被獲取的次數
- int getReadHoldCount():獲取當前執行緒獲取讀鎖的次數
- boolean isWriteLocked():判斷讀鎖是否被獲取
- int getWriteHoldCount():獲取當前執行緒獲取寫鎖的次數
public class Cache { static Map<String, Object> map = new HashMap<String, Object>(); static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); static Lock r = rwl.readLock(); static Lock w = rwl.writeLock(); // 獲取一個key對應的value public static final Object get(String key) { r.lock(); try { return map.get(key); } finally { r.unlock(); } } // 設定key對應的value,並返回舊的value public static final Object put(String key, Object value) { w.lock(); try { return map.put(key, value); } finally { w.unlock(); } } // 清空所有的內容 public static final void clear() { w.lock(); try { map.clear(); } finally { w.unlock(); } } } - ReadWriteLock 僅定義了獲取讀鎖和寫鎖的兩個方法,即 readLock() 方法和 writeLock() 方法,而其實現——ReentrantReadWriteLock,除了介面方法之外,還提供了一些便於外界監控其內部工作狀態的方法
-
讀寫鎖的實現分析
- 接下來分析 ReentrantReadWriteLock 的實現,主要包括:讀寫狀態的設計、寫鎖的獲取與釋放、讀鎖的獲取與釋放以及鎖降級(以下沒有特別說明讀寫鎖均可認為是 ReentrantReadWriteLock)
- 讀寫狀態的設計
- 讀寫鎖同樣依賴自定義同步器來實現同步功能,而讀寫狀態就是其同步器的同步狀態。回想 ReentrantLock 中自定義同步器的實現,同步狀態表示鎖被一個執行緒重複獲取的次數,而讀寫鎖的自定義同步器需要在同步狀態(一個整型變數)上維護多個讀執行緒和一個寫執行緒的狀態,使得該狀態的設計成為讀寫鎖實現的關鍵
- 如果在一個整型變數上維護多種狀態,就一定需要“按位切割使用”這個變數,讀寫鎖將變數切分成了兩個部分,高 16 位表示讀,低 16 位表示寫
- 讀寫鎖狀態的劃分方式當前同步狀態表示一個執行緒已經獲取了寫鎖,且重進入了兩次,同時也連續獲取了兩次讀鎖。讀寫鎖是如何迅速確定讀和寫各自的狀態呢?答案是通過位運算。假設當前同步狀態值為 S,寫狀態等於 S&0x0000FFFF(將高 16 位全部抹去),讀狀態等於 S>>>16 (無符號補 0 右移 16 位)。當寫狀態增加 1 時,等於 S+1,當讀狀態增加 1 時,等於 S+(1<<16),也就是 S0x00010000。根據狀態的劃分能得出一個推論:S 不等於 0 時,當寫狀態(S&0x0000FFFF) 等於 0 時,則讀狀態(S>>>16)大於 0,即讀鎖已被獲取
- 寫鎖的獲取與釋放
- 寫鎖是一個支援重進入的排它鎖。如果當前執行緒已經獲取了寫鎖,則增加寫狀態。如果當前執行緒在獲取寫鎖時,讀鎖已經被獲取(讀狀態不為 0)或者該執行緒不是已經獲取寫鎖的執行緒,則當前執行緒進入等待狀態。讀寫鎖要確保寫鎖的操作對讀鎖可見,如果允許讀鎖在已被獲取的情況下對寫鎖的獲取,那麼正在執行的其他讀執行緒就無法感知到當前寫執行緒的操作。因此,只有等待其他讀執行緒都釋放了讀鎖,寫鎖才能被當前執行緒獲取,而寫鎖一旦被獲取,則其他讀寫執行緒的後續訪問均被阻塞
- 寫鎖的釋放與 ReentrantLock 的釋放過程基本類似,每次釋放均減少寫狀態,當寫狀態為 0 時表示寫鎖已被釋放,從而等待的讀寫執行緒能夠繼續訪問讀寫鎖,同時前次寫執行緒的修改對後續讀寫執行緒可見
protected final boolean tryAcquire(int acquires) { Thread current = Thread.currentThread(); int c = getState(); int w = exclusiveCount(c); if (c != 0) { // 存在讀鎖或者當前獲取執行緒不是已經獲取寫鎖的執行緒 if (w == 0 || current != getExclusiveOwnerThread()) return false; if (w + exclusiveCount(acquires) > MAX_COUNT) throw new Error("Maximum lock count exceeded"); setState(c + acquires); return true; } if (writerShouldBlock() || !compareAndSetState(c, c + acquires)) { return false; } setExclusiveOwnerThread(current); return true; }
- 讀鎖的獲取與釋放
- 讀鎖是一個支援重進入的共享鎖,它能夠被多個執行緒同時獲取,在沒有其他寫執行緒訪問(或者寫狀態為0)時,讀鎖總會被成功地獲取,而所做的也只是(執行緒安全的)增加讀狀態。如果當前執行緒已經獲取了讀鎖,則增加讀狀態。如果當前執行緒在獲取讀鎖時,寫鎖已被其他執行緒獲取,則進入等待狀態
- 讀狀態是所有執行緒獲取讀鎖次數的總和,而每個執行緒各自獲取讀鎖的次數只能選擇儲存在 ThreadLocal 中,由執行緒自身維護,這使獲取讀鎖的實現變得複雜。因此,這裡將獲取讀鎖的程式碼做了刪減,保留必要的部分
- 在 tryAcquireShared(int unused) 方法中,如果其他執行緒已經獲取了寫鎖,則當前執行緒獲取讀鎖失敗,進入等待狀態。如果當前執行緒獲取了寫鎖或者寫鎖未被獲取,則當前執行緒(執行緒安全,依靠 CAS 保證)增加讀狀態,成功獲取讀鎖。讀鎖的每次釋放(執行緒安全的,可能有多個讀執行緒同時釋放讀鎖)均減少讀狀態,減少的值是(1<<16)
protected final int tryAcquireShared(int unused) { for (;;) { int c = getState(); int nextc = c + (1 << 16); if (nextc < c) throw new Error("Maximum lock count exceeded"); if (exclusiveCount(c) != 0 && owner != Thread.currentThread()) return -1; if (compareAndSetState(c, nextc)) return 1; } }
- 鎖降級
- 鎖降級指的是寫鎖降級成為讀鎖。如果當前執行緒擁有寫鎖,然後將其釋放,最後再獲取讀鎖,這種分段完成的過程不能稱之為鎖降級。鎖降級是指把持住(當前擁有的)寫鎖,再獲取到讀鎖,隨後釋放(先前擁有的)寫鎖的過程
- 接下來看一個鎖降級的示例。因為資料不常變化,所以多個執行緒可以併發地進行資料處理,當資料變更後,如果當前執行緒感知到資料變化,則進行資料的準備工作,同時其他處理執行緒被阻塞,直到當前執行緒完成資料的準備工作。當資料發生變更後,update 變數(布林型別且 volatile 修飾)被設定為 false,此時所有訪問 processData() 方法的執行緒都能夠感知到變化,但只有一個執行緒能夠獲取到寫鎖,其他執行緒會被阻塞在讀鎖和寫鎖的 lock() 方法上。當前執行緒獲取寫鎖完成資料準備之後,再獲取讀鎖,隨後釋放寫鎖,完成鎖降級
- 鎖降級中讀鎖的獲取是否必要呢?答案是必要的。主要是為了保證資料的可見性,如果當前執行緒不獲取讀鎖而是直接釋放寫鎖,假設此刻另一個執行緒(記作執行緒T)獲取了寫鎖並修改了資料,那麼當前執行緒無法感知執行緒 T 的資料更新。如果當前執行緒獲取讀鎖,即遵循鎖降級的步驟,則執行緒 T 將會被阻塞,直到當前執行緒使用資料並釋放讀鎖之後,執行緒 T 才能獲取寫鎖進行資料更新。RentrantReadWriteLock 不支援鎖升級(把持讀鎖、獲取寫鎖,最後釋放讀鎖的過程)。目的也是保證資料可見性,如果讀鎖已被多個執行緒獲取,其中任意執行緒成功獲取了寫鎖並更新了資料,則其更新對其他獲取到讀鎖的執行緒是不可見的
public void processData() { readLock.lock(); if (!update) { // 必須先釋放讀鎖 readLock.unlock(); // 鎖降級從寫鎖獲取到開始 writeLock.lock(); try { if (!update) { // 準備資料的流程(略) update = true; } readLock.lock(); } finally { writeLock.unlock(); } // 鎖降級完成,寫鎖降級為讀鎖 } try { // 使用資料的流程(略) } finally { readLock.unlock(); } }
LockSupport 工具類
-
LockSupport 工具類介紹
- 當需要阻塞或喚醒一個執行緒的時候,都會使用 LockSupport 工具類來完成相應工作。LockSupport 定義了一組的公共靜態方法,這些方法提供了最基本的執行緒阻塞和喚醒功能,而 LockSupport 也成為構建同步元件的基礎工具
-
LockSupport 常用方法
- LockSupport 定義了一組以 park 開頭的方法用來阻塞當前執行緒,以及 unpark(Thread thread) 方法來喚醒一個被阻塞的執行緒
- static void park(Object blocker):阻塞當前執行緒
- static void parkNanos(Object blocker, long nanos):阻塞當前執行緒,不過有超時時間的限制
- static void parkUntil(Object blocker, long deadline):阻塞當前執行緒,直到某個時間
- static void park():阻塞當前執行緒,如果呼叫 unpark(Thread thread) 方法或當前執行緒被中斷,才能用 park() 方法返回
- static void parkNanos(long nanos):阻塞當前執行緒,不過有超時時間的限制
- static void parkUntil(long deadline):阻塞當前執行緒,直到某個時間(1970年開始的毫秒數)
- static void unpark(Thread thread):喚醒處於阻塞狀態的執行緒 thread
- static Object getBlocker(Thread t);
- LockSupport 定義了一組以 park 開頭的方法用來阻塞當前執行緒,以及 unpark(Thread thread) 方法來喚醒一個被阻塞的執行緒
-
LockSupport 的實現
- LockSupport 是通過控制變數 _counter 來對執行緒阻塞喚醒進行控制的。原理有點類似於訊號量機制
- 當呼叫 park() 方法時,會將 _counter 置為 0,同時判斷前值,小於 1 說明前面被 unpark 過,則直接退出,否則將使該執行緒阻塞
- 當呼叫 unpark() 方法時,會將 _counter 置為 1,同時判斷前值,小於 1 會進行執行緒喚醒,否則直接退出
- LockSupport 是通過控制變數 _counter 來對執行緒阻塞喚醒進行控制的。原理有點類似於訊號量機制
-
LockSupport 總結
- park 和 unpark 可以實現類似 wait 和 notify 的功能,但是並不和 wait 和 notify 交叉,也就是說 unpark 不會對 wait 起作用,notify 也不會對 park 起作用
- wait 和 notify 都是 Object 中的方法,在呼叫這兩個方法前必須先獲得鎖物件,但是 park 不需要獲取某個物件的鎖就可以鎖住執行緒
- park 和 unpark 的使用不會出現死鎖的情況
- blocker 的作用是在 dump 執行緒的時候看到阻塞物件的資訊
Condition 介面
-
Condition 介紹
- 任意一個 Java 物件,都擁有一組監視器方法(定義在 java.lang.Object 上),主要包括 wait()、wait(long timeout)、notify() 以及 notifyAll() 方法,這些方法與 synchronized 同步關鍵字配合,可以實現等待/通知模式。Condition 介面也提供了類似 Object 的監視器方法,與 Lock 配合可以實現等待/通知模式,但是這兩者在使用方式以及功能特性上還是有差別的
- Object 的監視器方法與 Condition 介面的對比
對比項 Object monitor Methods Condition 前置條件 獲取鎖的物件 呼叫Lock.losk()獲取鎖,呼叫Lock.newCondition()獲取condition物件 呼叫方式 直接呼叫,例如object.wait() 直接呼叫,例如:condition.await() 等待佇列個數 一個 多個 當前執行緒釋放鎖並進入等待狀態 支援 支援 當前執行緒釋放鎖並進入等待狀態,在等待狀態中不響應中斷 不支援 支援 當前執行緒釋放鎖並進入超時等待狀態 支援 支援 當前執行緒釋放鎖並進入等待狀態到將來的某個時刻 不支援 支援 喚醒等待佇列中的一個執行緒 支援 支援 喚醒等待佇列中的所有執行緒 支援 支援
-
Condition 介面與示例
- Condition 定義了等待/通知兩種型別的方法,當前執行緒呼叫這些方法時,需要提前獲取到 Condition 物件關聯的鎖。Condition 物件是由 Lock 物件(呼叫Lock物件的newCondition()方法)建立出來的,換句話說,Condition 是依賴 Lock 物件的
Lock lock = new ReentrantLock(); Condition condition = lock.newCondition(); public void conditionWait() throws InterruptedException { lock.lock(); try { condition.await(); } finally { lock.unlock(); } } public void conditionSignal() throws InterruptedException { lock.lock(); try { condition.signal(); } finally { lock.unlock(); } } - Condition 的(部分)方法以及描述
方法名稱 描述 void await() throws InterruptedException 當前執行緒進入等待狀態知道被通知或中斷,當前執行緒將進入執行狀態且從 await() 方法返回的情況,包括:其他執行緒呼叫該 Conditioncn 的 signal() 或 signalAll() 方法,而當前執行緒被選中喚醒;其他執行緒(呼叫 interrupt() 方法)中斷當前執行緒;如果當前等待執行緒從 await() 方法返回,那麼表明該執行緒已經獲取了 Condition 物件所對應的鎖 void awaitUninterruptibly() 當前執行緒進入等待狀態直到被通知,該方法對中斷不敏感,也就是在等待狀態中不能被中斷 long awaitNanos(long nanosTimeout) throws InterruptedException 當前執行緒進入等待狀態,直到被通知,中斷,或者超時。返回值表示剩餘時間,如果返回值為 0 或者負數,說明已經超時了。如果在 nanosTimeout 之前就被喚醒了,那麼返回值就是 nanosTimeout-實際耗時 boolean await(long time, TimeUnit unit) throws InterruptedException 當前執行緒進入等待狀態,直到被通知,中斷,或者超時。支援自定義時間單位,false:表示方法超時之後自動返回的,true:表示等待還未超時時,await 方法就返回了(超時之前,被其他執行緒喚醒了) boolean awaitUntil(Date deadline) throws InterruptedException 當前執行緒進入等待狀態,直到被通知,中斷,或者到將來某個時間,如果沒有到指定時間就被通知,返回 true,如果到了某個時間,還未被喚醒,就返回 false void signal() 喚醒一個等待在 Condition 上的執行緒,該執行緒從等待方法返回前必須獲得與 Condition 相關聯的鎖 void signalAll() 喚醒所有等待在 Condition 上的執行緒,能夠從等待方法返回的執行緒必須是獲得了與 Condition 相關聯的鎖 - 獲取一個 Condition 必須通過 Lock 的 newCondition() 方法。下面通過一個有界佇列的示例來深入瞭解 Condition 的使用方式。有界佇列是一種特殊的佇列,當佇列為空時,佇列的獲取操作將會阻塞獲取執行緒,直到佇列中有新增元素,當佇列已滿時,佇列的插入操作將會阻塞插入執行緒,直到佇列出現“空位”
public class BoundedQueue<T> { private Object[] items; // 新增的下標,刪除的下標和陣列當前數量 private int addIndex, removeIndex, count; private Lock lock = new ReentrantLock(); private Condition notEmpty = lock.newCondition(); private Condition notFull = lock.newCondition(); public BoundedQueue(int size) { items = new Object[size]; } // 新增一個元素,如果陣列滿,則新增執行緒進入等待狀態,直到有"空位" public void add(T t) throws InterruptedException { lock.lock(); try { while (count == items.length) notFull.await(); items[addIndex] = t; if (++addIndex == items.length) addIndex = 0; ++count; notEmpty.signal(); } finally { lock.unlock(); } } // 由頭部刪除一個元素,如果陣列空,則刪除執行緒進入等待狀態,直到有新新增元素 @SuppressWarnings("unchecked") public T remove() throws InterruptedException { lock.lock(); try { while (count == 0) notEmpty.await(); Object x = items[removeIndex]; if (++removeIndex == items.length) removeIndex = 0; --count; notFull.signal(); return (T) x; } finally { lock.unlock(); } } } - 以新增方法為例。首先需要獲得鎖,目的是確保陣列修改的可見性和排他性。當陣列數量等於陣列長度時,表示陣列已滿,則呼叫 notFull.await(),當前執行緒隨之釋放鎖並進入等待狀態。如果陣列數量不等於陣列長度,表示陣列未滿,則新增元素到陣列中,同時通知等待在 notEmpty 上的執行緒,陣列中已經有新元素可以獲取。在新增和刪除方法中使用 while 迴圈而非 if 判斷,目的是防止過早或意外的通知,只有條件符合才能夠退出迴圈。回想之前提到的等待/通知的經典正規化,二者是非常類似的
- Condition 定義了等待/通知兩種型別的方法,當前執行緒呼叫這些方法時,需要提前獲取到 Condition 物件關聯的鎖。Condition 物件是由 Lock 物件(呼叫Lock物件的newCondition()方法)建立出來的,換句話說,Condition 是依賴 Lock 物件的
-
Condition 的實現分析
- 介紹
- ConditionObject 是同步器 AbstractQueuedSynchronizer 的內部類
- 等待佇列
- 等待佇列是一個 FIFO 的佇列,在佇列中的每個節點都包含了一個執行緒引用,該執行緒就是在 Condition 物件上等待的執行緒,如果一個執行緒呼叫了 Condition.await() 方法,那麼該執行緒將會釋放鎖、構造成節點加入等待佇列並進入等待狀態。事實上,節點的定義複用了同步器中節點的定義,也就是說,同步佇列和等待佇列中節點型別都是同步器的靜態內部類 AbstractQueuedSynchronizer.Node
- 一個 Condition 包含一個等待佇列,Condition 擁有首節點(firstWaiter)和尾節點(lastWaiter)。當前執行緒呼叫 Condition.await() 方法,將會以當前執行緒構造節點,並將節點從尾部加入等待佇列

Condition 擁有首尾節點的引用,而新增節點只需要將原有的尾節點 nextWaiter 指向它,並且更新尾節點即可。上述節點引用更新的過程並沒有使用 CAS 保證,原因在於呼叫 await() 方法的執行緒必定是獲取了鎖的執行緒,也就是說該過程是由鎖來保證執行緒安全的 - 在 Object 的監視器模型上,一個物件擁有一個同步佇列和等待佇列,而併發包中的 Lock(更確切地說是同步器)擁有一個同步佇列和多個等待佇列

Condition 的實現是同步器的內部類,因此每個 Condition 例項都能夠訪問同步器提供的方法,相當於每個 Condition 都擁有所屬同步器的引用
- 等待
- 呼叫 Condition 的 await() 方法(或者以 await 開頭的方法),會使當前執行緒進入等待佇列並釋放鎖,同時執行緒狀態變為等待狀態。當從 await() 方法返回時,當前執行緒一定獲取了 Condition 相關聯的鎖。如果從佇列(同步佇列和等待佇列)的角度看 await() 方法,當呼叫 await() 方法時,相當於同步佇列的首節點(獲取了鎖的節點)移動到 Condition 的等待佇列中
public final void await() throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); // 當前執行緒加入等待佇列 Node node = addConditionWaiter(); // 釋放同步狀態,也就是釋放鎖 int savedState = fullyRelease(node); int interruptMode = 0; while (!isOnSyncQueue(node)) { LockSupport.park(this); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; } if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null) unlinkCancelledWaiters(); if (interruptMode != 0) reportInterruptAfterWait(interruptMode); }
- 呼叫 Condition 的 await() 方法(或者以 await 開頭的方法),會使當前執行緒進入等待佇列並釋放鎖,同時執行緒狀態變為等待狀態。當從 await() 方法返回時,當前執行緒一定獲取了 Condition 相關聯的鎖。如果從佇列(同步佇列和等待佇列)的角度看 await() 方法,當呼叫 await() 方法時,相當於同步佇列的首節點(獲取了鎖的節點)移動到 Condition 的等待佇列中
- 通知
- 呼叫 Condition 的 signal() 方法,將會喚醒在等待佇列中等待時間最長的節點(首節點),在喚醒節點之前,會將節點移到同步佇列中
呼叫該方法的前置條件是當前執行緒必須獲取了鎖,可以看到 signal() 方法進行了 isHeldExclusively()查,也就是當前執行緒必須是獲取了鎖的執行緒。接著獲取等待佇列的首節點,將其移動到同步佇列並使用 LockSupport 喚醒節點中的執行緒public final void signal() { if (!isHeldExclusively()) throw new IllegalMonitorStateException(); Node first = firstWaiter; if (first != null) doSignal(first); } - 節點從等待佇列移動到同步佇列的過程

- 通過呼叫同步器的 enq(Node node) 方法,等待佇列中的頭節點執行緒安全地移動到同步佇列。當節點移動到同步佇列後,當前執行緒再使用 LockSupport 喚醒該節點的執行緒。被喚醒後的執行緒,將從 await() 方法中的 while 迴圈中退出(isOnSyncQueue(Node node) 方法返回 true,節點已經在同步佇列中),進而呼叫同步器的 acquireQueued() 方法加入到獲取同步狀態的競爭中。成功獲取同步狀態(或者說鎖)之後,被喚醒的執行緒將從先前呼叫的 await() 方法返回,此時該執行緒已經成功地獲取了鎖。Condition 的 signalAll() 方法,相當於對等待佇列中的每個節點均執行一次 signal() 方法,效果就是將等待佇列中所有節點全部移動到同步佇列中,並喚醒每個節點的執行緒
- 呼叫 Condition 的 signal() 方法,將會喚醒在等待佇列中等待時間最長的節點(首節點),在喚醒節點之前,會將節點移到同步佇列中
- 介紹
第六章 Java併發容器和框架
ConcurrentHashMap 的實現原理與使用
-
注意
- 書中 ConcurrentHashMap 使用的是jdk 1.7。但 ConcurrentHashMap 在1.8 發生了比較大的變化。這裡只是讀書筆記,所以參照原書來筆記
-
ConcurrentHashMap 介紹
- ConcurrentHashMap 是執行緒安全且高效的 HashMap
-
為什麼要使用 ConcurrentHashMap
- 執行緒不安全的 HashMap
- 效率低下的 HashTable
- ConcurrentHashMap 的鎖分段技術可有效提升併發訪問率
-
ConcurrentHashMap 的結構
- ConcurrentHashMap 是由 Segment 陣列結構和 HashEntry 陣列結構組成。Segment 是一種可重入鎖(ReentrantLock),在 ConcurrentHashMap 裡扮演鎖的角色;HashEntry 則用於儲存鍵值對資料。一個 ConcurrentHashMap 裡包含一個 Segment 陣列。Segment 的結構和 HashMap 類似,是一種陣列和連結串列結構。一個 Segment 裡包含一個 HashEntry 陣列,每個 HashEntry 是一個連結串列結構的元素,每個 Segment 守護著一個 HashEntry 陣列裡的元素,當對 HashEntry 陣列的資料進行修改時,必須首先獲得與它對應的 Segment 鎖
-
ConcurrentHashMap 的初始化
- ConcurrentHashMap 初始化方法是通過 initialCapacity、loadFactor 和 concurrencyLevel 等幾個引數來初始化 segment 陣列、段偏移量 segmentShift、段掩碼 segmentMask 和每個 segment 裡的 HashEntry 陣列來實現的
- 初始化 segments 陣列
- segments 陣列的長度 ssize 是通過 concurrencyLevel 計算得出的。為了能通過按位與的雜湊演算法來定位 segments 陣列的索引,必須保證 segments 陣列的長度是 2 的 N 次方(power-of-two size),所以必須計算出一個大於或等於 concurrencyLevel 的最小的 2 的 N 次方值來作為 segments 陣列的長度。假如 concurrencyLevel 等於 14、15 或 16,ssize 都會等於 16,即容器裡鎖的個數也是 16,注意 concurrencyLevel 的最大值是 65535,這意味著 segments 陣列的長度最大為 65536,對應的二進位制是 16 位
if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } segmentShift = 32 - sshift; segmentMask = ssize - 1; this.segments = Segment.newArray(ssize); - 初始化 segmentShift 和 segmentMask
- 這兩個全域性變數需要在定位 segment 時的雜湊演算法裡使用,sshift 等於 ssize 從 1 向左移位的次數,在預設情況下 concurrencyLevel 等於 16,1 需要向左移位移動 4 次,所以 sshift 等於 4。segmentShift 用於定位參與雜湊運算的位數,segmentShift 等於 32 減 sshift,所以等於 28,這裡之所以用 32 是因為 ConcurrentHashMap 裡的 hash() 方法輸出的最大數是 32 位的,後面的測試中我們可以看到這點。segmentMask 是雜湊運算的掩碼,等於 ssize 減 1,即 15,掩碼的二進位制各個位的值都是 1。因為 ssize 的最大長度是 65536,所以 segmentShift 最大值是 16,segmentMask 最大值是 65535,對應的二進位制是 16 位,每個位都是 1
- 初始化每個 segment
- 輸入引數 initialCapacity 是 ConcurrentHashMap 的初始化容量,loadfactor 是每個 segment 的負載因子,在構造方法裡需要通過這兩個引數來初始化陣列中的每個 segment
if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = 1; while (cap < c) cap <<= 1; for (int i = 0; i < this.segments.length; ++i) this.segments[i] = new Segment<K,V>(cap, loadFactor); - 上面程式碼中的變數 cap 就是 segment 裡 HashEntry 陣列的長度,它等於 initialCapacity 除以 ssize 的倍數 c,如果 c 大於 1,就會取大於等於 c 的 2 的 N 次方值,所以 cap 不是 1,就是 2 的 N 次方。segment 的容量 threshold=(int)cap*loadFactor,預設情況下initialCapacity 等於 16,loadfactor 等於 0.75,通過運算 cap 等於 1,threshold 等於零
- 輸入引數 initialCapacity 是 ConcurrentHashMap 的初始化容量,loadfactor 是每個 segment 的負載因子,在構造方法裡需要通過這兩個引數來初始化陣列中的每個 segment
-
定位 Segment
- 既然 ConcurrentHashMap 使用分段鎖 Segment 來保護不同段的資料,那麼在插入和獲取元素的時候,必須先通過雜湊演算法定位到 Segment。可以看到 ConcurrentHashMap 會首先使用 Wang/Jenkins hash 的變種演算法對元素的 hashCode 進行一次再雜湊,之所以進行再雜湊,目的是減少雜湊衝突,使元素能夠均勻地分佈在不同的 Segment 上,從而提高容器的存取效率。假如雜湊的質量差到極點,那麼所有的元素都在一個 Segment 中,不僅存取元素緩慢,分段鎖也會失去意義
private static int hash(int h) { h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10); h += (h << 3); h ^= (h >>> 6); h += (h << 2) + (h << 14); return h ^ (h >>> 16); } - ConcurrentHashMap 通過以下雜湊演算法定位 segment
final Segment<K,V> segmentFor(int hash) { return segments[(hash >>> segmentShift) & segmentMask]; }
- 既然 ConcurrentHashMap 使用分段鎖 Segment 來保護不同段的資料,那麼在插入和獲取元素的時候,必須先通過雜湊演算法定位到 Segment。可以看到 ConcurrentHashMap 會首先使用 Wang/Jenkins hash 的變種演算法對元素的 hashCode 進行一次再雜湊,之所以進行再雜湊,目的是減少雜湊衝突,使元素能夠均勻地分佈在不同的 Segment 上,從而提高容器的存取效率。假如雜湊的質量差到極點,那麼所有的元素都在一個 Segment 中,不僅存取元素緩慢,分段鎖也會失去意義
-
ConcurrentHashMap 的操作
- get 操作
- Segment 的 get 操作實現非常簡單和高效。先經過一次再雜湊,然後使用這個雜湊值通過雜湊運算定位到 Segment,再通過雜湊演算法定位到元素
public V get(Object key) { int hash = hash(key.hashCode()); return segmentFor(hash).get(key, hash); } - get 操作的高效之處在於整個 get 過程不需要加鎖,除非讀到的值是空才會加鎖重讀。它的 get 方法裡將要使用的共享變數都定義成 volatile 型別,如用於統計當前 Segement 大小的 count 欄位和用於儲存值的 HashEntry 的 value。定義成 volatile 的變數,能夠線上程之間保持可見性,能夠被多執行緒同時讀,並且保證不會讀到過期的值,但是隻能被單執行緒寫(有一種情況可以被多執行緒寫,就是寫入的值不依賴於原值),在 get 操作裡只需要讀不需要寫共享變數 count 和 value,所以可以不用加鎖。之所以不會讀到過期的值,是因為根據 Java 記憶體模型的 happen before 原則,對 volatile 欄位的寫入操作先於讀操作,即使兩個執行緒同時修改和獲取 volatile 變數,get 操作也能拿到最新的值,這是用 volatile 替換鎖的經典應用場景
transient volatile int count; volatile V value; - 在定位元素的程式碼裡我們可以發現,定位 HashEntry 和定位 Segment 的雜湊演算法雖然一樣,都與陣列的長度減去 1 再相“與”,但是相“與”的值不一樣,定位 Segment 使用的是元素的 hashcode 通過再雜湊後得到的值的高位,而定位 HashEntry 直接使用的是再雜湊後的值。其目的是避免兩次雜湊後的值一樣,雖然元素在 Segment 裡雜湊開了,但是卻沒有在 HashEntry 裡雜湊開
hash >>> segmentShift) & segmentMask // 定位Segment所使用的hash演算法 int index = hash & (tab.length - 1); // 定位HashEntry所使用的hash演算法
- Segment 的 get 操作實現非常簡單和高效。先經過一次再雜湊,然後使用這個雜湊值通過雜湊運算定位到 Segment,再通過雜湊演算法定位到元素
- put 操作
- 由於 put 方法裡需要對共享變數進行寫入操作,所以為了執行緒安全,在操作共享變數時必須加鎖。put 方法首先定位到 Segment,然後在 Segment 裡進行插入操作。插入操作需要經歷兩個步驟,第一步判斷是否需要對 Segment 裡的 HashEntry 陣列進行擴容,第二步定位新增元素的位置,然後將其放在 HashEntry 陣列裡
- 是否需要擴容。在插入元素前會先判斷 Segment 裡的 HashEntry 陣列是否超過容量(threshold),如果超過閾值,則對陣列進行擴容。值得一提的是,Segment 的擴容判斷比 HashMap 更恰當,因為 HashMap 是在插入元素後判斷元素是否已經到達容量的,如果到達了就進行擴容,但是很有可能擴容之後沒有新元素插入,這時 HashMap 就進行了一次無效的擴容
- 如何擴容。在擴容的時候,首先會建立一個容量是原來容量兩倍的陣列,然後將原陣列裡的元素進行再雜湊後插入到新的陣列裡。為了高效,concurrentHashMap 不會對整個容器進行擴容,而只對某個 segment 進行擴容
- size 操作
- 如果要統計整個 ConcurrentHashMap 裡元素的大小,就必須統計所有 Segment 裡元素的大小後求和。Segment 裡的全域性變數 count 是一個 volatile 變數,那麼在多執行緒場景下,是不是直接把所有 Segment 的 count 相加就可以得到整個 ConcurrentHashMap 大小了呢?不是的,雖然相加時可以獲取每個 Segment 的 count 的最新值,但是可能累加前使用的 count 發生了變化,那麼統計結果就不準了。所以,最安全的做法是在統計 size 的時候把所有 Segment 的 put、remove 和 clean 方法全部鎖住,但是這種做法顯然非常低效
- 因為在累加 count 操作過程中,之前累加過的 count 發生變化的機率非常小,所以 ConcurrentHashMap 的做法是先嚐試 2 次通過不鎖住 Segment 的方式來統計各個 Segment 大小,如果統計的過程中,容器的 count 發生了變化,則再採用加鎖的方式來統計所有 Segment 的大小
- 那麼 ConcurrentHashMap 是如何判斷在統計的時候容器是否發生了變化呢?使用 modCount 變數,在 put、remove 和 clean 方法裡操作元素前都會將變數 modCount 進行加 1,那麼在統計 size 前後比較 modCount 是否發生變化,從而得知容器的大小是否發生變化
- get 操作
ConcurrentLinkedQueue
-
介紹
- 如果要實現一個執行緒安全的佇列有兩種方式
- 一種是使用阻塞演算法,使用阻塞演算法的佇列可以用一個鎖(入隊和出隊用同一把鎖)或兩個鎖(入隊和出隊用不同的鎖)等方式來實現
- 一種是使用非阻塞演算法。非阻塞的實現方式則可以使用迴圈 CAS 的方式來實現
- ConcurrentLinkedQueue 是一個基於連結節點的無界執行緒安全佇列,它採用先進先出規則對節點進行排序,當我們新增一個元素的時候,它會新增到佇列的尾部;當我們獲取一個元素時,它會返回佇列頭部的元素。它採用了 “wait-free” 演算法(即 CAS 演算法)來實現,該演算法在 Michael&Scott 演算法上進行了一些修改
- 如果要實現一個執行緒安全的佇列有兩種方式
-
ConcurrentLinkedQueue 的結構
- ConcurrentLinkedQueue 由 head 節點和 tail 節點組成,每個節點(Node)由節點元素(item)和指向下一個節點(next)的引用組成,節點與節點之間就是通過這個 next 關聯起來,從而組成一張連結串列結構的佇列。預設情況下 head 節點儲存的元素為空,tail 節點等於 head 節點
private transient volatile Node<E> tail = head;
- ConcurrentLinkedQueue 由 head 節點和 tail 節點組成,每個節點(Node)由節點元素(item)和指向下一個節點(next)的引用組成,節點與節點之間就是通過這個 next 關聯起來,從而組成一張連結串列結構的佇列。預設情況下 head 節點儲存的元素為空,tail 節點等於 head 節點
-
入佇列
- 入佇列就是將入隊節點新增到佇列的尾部
- 入佇列的過程
- 新增元素1。佇列更新 head 節點的 next 節點為元素1節點。又因為 tail 節點預設情況下等於 head 節點,所以它們的 next 節點都指向元素1節點
- 新增元素2。佇列首先設定元素1節點的 next 節點為元素2節點,然後更新 tail 節點指向元素2節點
- 新增元素3,設定 tail 節點的 next 節點為元素3節點
- 新增元素4,設定元素3的 next 節點為元素4節點,然後將 tail 節點指向元素4節點
- 整個入隊過程主要做兩件事情:第一是定位出尾節點;第二是使用 CAS 演算法將入隊節點設定成尾節點的 next 節點,如不成功則重試
public boolean offer(E e) { if (e == null) throw new NullPointerException(); // 入隊前,建立一個入隊節點 Node<E> n = new Node<E>(e); retry: // 死迴圈,入隊不成功反覆入隊。 for (;;) { // 建立一個指向tail節點的引用 Node<E> t = tail; // p用來表示佇列的尾節點,預設情況下等於tail節點。 Node<E> p = t; for (int hops = 0; ; hops++) { // 獲得p節點的下一個節點。 Node<E> next = succ(p); // next節點不為空,說明p不是尾節點,需要更新p後在將它指向next節點 if (next != null) { // 迴圈了兩次及其以上,並且當前節點還是不等於尾節點 if (hops > HOPS && t != tail) continue retry; p = next; } // 如果p是尾節點,則設定p節點的next節點為入隊節點。 else if (p.casNext(null, n)) { // 如果tail節點有大於等於1個next節點,則將入隊節點設定成tail節點,更新失敗了也沒關係,因為失敗了表示有其他執行緒成功更新了tail節點 if (hops >= HOPS) // 更新tail節點,允許失敗 casTail(t, n); return true; } // p有next節點,表示p的next節點是尾節點,則重新設定p節點 else { p = succ(p); } } } } - 定位尾節點
- tail 節點並不總是尾節點,所以每次入隊都必須先通過 tail 節點來找到尾節點。尾節點可能是 tail 節點,也可能是 tail 節點的 next 節點。程式碼中迴圈體中的第一個 if 就是判斷 tail 是否有 next 節點,有則表示 next 節點可能是尾節點。獲取 tail 節點的 next 節點需要注意的是 p 節點等於 p 的 next 節點的情況,只有一種可能就是 p 節點和 p 的 next 節點都等於空,表示這個佇列剛初始化,正準備新增節點,所以需要返回 head 節點。獲取 p 節點的 next 節點程式碼如下
final Node<E> succ(Node<E> p) { Node<E> next = p.getNext(); return (p == next) head : next; }
- tail 節點並不總是尾節點,所以每次入隊都必須先通過 tail 節點來找到尾節點。尾節點可能是 tail 節點,也可能是 tail 節點的 next 節點。程式碼中迴圈體中的第一個 if 就是判斷 tail 是否有 next 節點,有則表示 next 節點可能是尾節點。獲取 tail 節點的 next 節點需要注意的是 p 節點等於 p 的 next 節點的情況,只有一種可能就是 p 節點和 p 的 next 節點都等於空,表示這個佇列剛初始化,正準備新增節點,所以需要返回 head 節點。獲取 p 節點的 next 節點程式碼如下
- 設定入隊節點為尾節點
- p.casNext(null,n) 方法用於將入隊節點設定為當前佇列尾節點的 next 節點,如果 p 是 null,表示 p 是當前佇列的尾節點,如果不為 null,表示有其他執行緒更新了尾節點,則需要重新獲取當前佇列的尾節點
-
出佇列
- 出佇列的就是從佇列裡返回一個節點元素,並清空該節點對元素的引用
- 並不是每次出隊時都更新 head 節點,當 head 節點裡有元素時,直接彈出 head 節點裡的元素,而不會更新 head 節點。只有當 head 節點裡沒有元素時,出隊操作才會更新 head 節點。這種做法也是通過 hops 變數來減少使用 CAS 更新 head 節點的消耗,從而提高出隊效率
- 首先獲取頭節點的元素,然後判斷頭節點元素是否為空,如果為空,表示另外一個執行緒已經進行了一次出隊操作將該節點的元素取走,如果不為空,則使用 CAS 的方式將頭節點的引用設定成 null,如果 CAS 成功,則直接返回頭節點的元素,如果不成功,表示另外一個執行緒已經進行了一次出隊操作更新了 head 節點,導致元素髮生了變化,需要重新獲取頭節點
public E poll() { Node<E> h = head; // p表示頭節點,需要出隊的節點 Node<E> p = h; for (int hops = 0;; hops++) { // 獲取p節點的元素 E item = p.getItem(); // 如果p節點的元素不為空,使用CAS設定p節點引用的元素為null, // 如果成功則返回p節點的元素。 if (item != null && p.casItem(item, null)) { if (hops >= HOPS) { // 將p節點下一個節點設定成head節點 Node<E> q = p.getNext(); updateHead(h, (q != null) q : p); } return item; } // 如果頭節點的元素為空或頭節點發生了變化,這說明頭節點已經被另外一個執行緒修改了。那麼獲取p節點的下一個節點 Node<E> next = succ(p); // 如果p的下一個節點也為空,說明這個佇列已經空了 if (next == null) { // 更新頭節點。 updateHead(h, p); break; } // 如果下一個元素不為空,則將頭節點的下一個節點設定成頭節點 p = next; } return null; }
Java 中的阻塞佇列
-
什麼是阻塞佇列
- 阻塞佇列(BlockingQueue)是一個支援兩個附加操作的佇列。這兩個附加的操作支援阻塞的插入和移除方法。阻塞佇列常用於生產者和消費者的場景,生產者是向佇列裡新增元素的執行緒,消費者是從佇列裡取元素的執行緒。阻塞佇列就是生產者用來存放元素、消費者用來獲取元素的容器
- 支援阻塞的插入方法:意思是當佇列滿時,佇列會阻塞插入元素的執行緒,直到佇列不滿
- 支援阻塞的移除方法:意思是在佇列為空時,獲取元素的執行緒會等待佇列變為非空
- 在阻塞佇列不可用時,這兩個附加操作提供了4種處理方式
方法/處理方式 丟擲異常 返回特殊值 一直阻塞 超時退出 插入方法 add(e) offer(e) put(e) offer(e,time,unit) 移除方法 remove() poll() take() poll(time,unit) 檢查方法 element() peek() 不可用 不可用 - 丟擲異常:當佇列滿時,如果再往佇列裡插入元素,會丟擲 IllegalStateException(“Queue full”) 異常。當佇列空時,從佇列裡獲取元素會丟擲 NoSuchElementException 異常
- 返回特殊值:當往佇列插入元素時,會返回元素是否插入成功,成功返回 true。如果是移除方法,則是從佇列裡取出一個元素,如果沒有則返回 null
- 一直阻塞:當阻塞佇列滿時,如果生產者執行緒往佇列裡 put 元素,佇列會一直阻塞生產者執行緒,直到佇列可用或者響應中斷退出。當佇列空時,如果消費者執行緒從佇列裡 take 元素,佇列會阻塞住消費者執行緒,直到佇列不為空
- 超時退出:當阻塞佇列滿時,如果生產者執行緒往佇列裡插入元素,佇列會阻塞生產者執行緒一段時間,如果超過了指定的時間,生產者執行緒就會退出
- 注意 如果是無界阻塞佇列,佇列不可能會出現滿的情況,所以使用 put 或 offer 方法永遠不會被阻塞,而且使用 offer 方法時,該方法永遠返回 true
- 阻塞佇列(BlockingQueue)是一個支援兩個附加操作的佇列。這兩個附加的操作支援阻塞的插入和移除方法。阻塞佇列常用於生產者和消費者的場景,生產者是向佇列裡新增元素的執行緒,消費者是從佇列裡取元素的執行緒。阻塞佇列就是生產者用來存放元素、消費者用來獲取元素的容器
-
Java 裡的阻塞佇列
- JDK 7 提供了 7 個阻塞佇列,如下:
- ArrayBlockingQueue:底層實現陣列、先入先出、有界佇列,構造是需指定陣列長度且不可變,ReentrantLock、Condition 實現執行緒安全
- LinkedBlockingQueue:底層實現連結串列,先入先出、無界佇列,ReentrantLock、Condition 實現執行緒安全
- PriorityBlockingQueue:底層陣列實現二叉堆,陣列可變,所以是支援優先順序無界阻塞佇列,ReentrantLock、Condition實現執行緒安全
- DelayQueue:底層資料是 PriorityQueue(無鎖無阻塞無界優先順序佇列),ReentrantLock、Condition 實現執行緒安全,儲存元素必須實現 Delayed 介面,可以指定元素出隊時間
- SynchronousQueue:沒有容量,不管是 take 還是 put 進來的執行緒,如果沒有匹配就阻塞,等待異類執行緒交換資料並喚醒,支援公平與非公平模式,無鎖通過 CAS 實現
- LinkedTransferQueue:連結串列實現無界阻塞佇列,put 方法不阻塞,take 方法先進可以佔位置,後面的 put 會先給到它,transfer 方法與 SynchronousQueue 的公平模式一樣,無鎖通過 CAS 實現
- LinkedBlockingDeque:雙向連結串列、無界阻塞佇列,可實現先入先出、先入後出、優先進出,ReentrantLock、Condition 實現執行緒安全

- JDK 7 提供了 7 個阻塞佇列,如下:
-
ArrayBlockingQueue
- ArrayBlockingQueue 是一個用陣列實現的有界阻塞佇列。此佇列按照先進先出(FIFO)的原則對元素進行排序。預設情況下不保證執行緒公平的訪問佇列,所謂公平訪問佇列是指阻塞的執行緒,可以按照阻塞的先後順序訪問佇列,即先阻塞執行緒先訪問佇列。非公平性是對先等待的執行緒是非公平的,當佇列可用時,阻塞的執行緒都可以爭奪訪問佇列的資格,有可能先阻塞的執行緒最後才訪問佇列。為了保證公平性,通常會降低吞吐量。我們可以使用以下程式碼建立一個公平的阻塞佇列
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true); 訪問者的公平性是使用可重入鎖實現的,程式碼如下。 public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); }
- ArrayBlockingQueue 是一個用陣列實現的有界阻塞佇列。此佇列按照先進先出(FIFO)的原則對元素進行排序。預設情況下不保證執行緒公平的訪問佇列,所謂公平訪問佇列是指阻塞的執行緒,可以按照阻塞的先後順序訪問佇列,即先阻塞執行緒先訪問佇列。非公平性是對先等待的執行緒是非公平的,當佇列可用時,阻塞的執行緒都可以爭奪訪問佇列的資格,有可能先阻塞的執行緒最後才訪問佇列。為了保證公平性,通常會降低吞吐量。我們可以使用以下程式碼建立一個公平的阻塞佇列
-
LinkedBlockingQueue
- LinkedBlockingQueue 是一個用連結串列實現的有界阻塞佇列。此佇列的預設和最大長度為 Integer.MAX_VALUE。此佇列按照先進先出的原則對元素進行排序
-
PriorityBlockingQueue
- PriorityBlockingQueue 是一個支援優先順序的無界阻塞佇列。預設情況下元素採取自然順序升序排列。也可以自定義類實現compareTo()方法來指定元素排序規則,或者初始化PriorityBlockingQueue時,指定構造引數Comparator來對元素進行排序。需要注意的是不能保證同優先順序元素的順序
-
DelayQueue
- DelayQueue 是一個支援延時獲取元素的無界阻塞佇列。佇列使用 PriorityQueue 來實現。佇列中的元素必須實現 Delayed 介面,在建立元素時可以指定多久才能從佇列中獲取當前元素。只有在延遲期滿時才能從佇列中提取元素。DelayQueue 非常有用,可以將 DelayQueue 運用在以下應用場景
- 快取系統的設計:可以用 DelayQueue 儲存快取元素的有效期,使用一個執行緒迴圈查詢 DelayQueue,一旦能從 DelayQueue 中獲取元素時,表示快取有效期到了
- 定時任務排程:使用 DelayQueue 儲存當天將會執行的任務和執行時間,一旦從 DelayQueue 中獲取到任務就開始執行,比如 TimerQueue 就是使用 DelayQueue 實現的
- 如何實現 Delayed 介面
- DelayQueue 佇列的元素必須實現 Delayed 介面。我們可以參考 ScheduledThreadPoolExecutor 裡 ScheduledFutureTask 類的實現,一共有三步
- 第一步:在物件建立的時候,初始化基本資料。使用 time 記錄當前物件延遲到什麼時候可以使用,使用 sequenceNumber 來標識元素在佇列中的先後順序。程式碼如下
private static final AtomicLong sequencer = new AtomicLong(0); ScheduledFutureTask(Runnable r, V result, long ns, long period) { super(r, result); this.time = ns; this.period = period; this.sequenceNumber = sequencer.getAndIncrement(); } - 第二步:實現 getDelay 方法,該方法返回當前元素還需要延時多長時間,單位是納秒,程式碼如下:通過建構函式可以看出延遲時間引數 ns 的單位是納秒,自己設計的時候最好使用納秒,因為實現 getDelay() 方法時可以指定任意單位,一旦以秒或分作為單位,而延時時間又精確不到納秒就麻煩了。使用時請注意當 time 小於當前時間時,getDelay 會返回負數
public long getDelay(TimeUnit unit) { return unit.convert(time - now(), TimeUnit.NANOSECONDS); } - 第三步:實現 compareTo 方法來指定元素的順序。例如,讓延時時間最長的放在佇列的末尾。實現程式碼如下。
public int compareTo(Delayed other) { if (other == this) // compare zero ONLY if same object return 0; if (other instanceof ScheduledFutureTask) { ScheduledFutureTask<> x = (ScheduledFutureTask<>)other; long diff = time - x.time; if (diff < 0) return -1; else if (diff > 0) return 1; else if (sequenceNumber < x.sequenceNumber) return -1; else return 1; } long d = (getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS)); return (d == 0) 0 : ((d < 0) -1 : 1); }
- 如何實現延時阻塞佇列
- 延時阻塞佇列的實現很簡單,當消費者從佇列裡獲取元素時,如果元素沒有達到延時時間,就阻塞當前執行緒
- 程式碼中的變數 leader 是一個等待獲取佇列頭部元素的執行緒。如果 leader 不等於空,表示已經有執行緒在等待獲取佇列的頭元素。所以,使用 await() 方法讓當前執行緒等待訊號。如果 leader 等於空,則把當前執行緒設定成 leader,並使用 awaitNanos() 方法讓當前執行緒等待接收訊號或等待 delay 時間
long delay = first.getDelay(TimeUnit.NANOSECONDS); if (delay <= 0) return q.poll(); else if (leader != null) available.await(); else { Thread thisThread = Thread.currentThread(); leader = thisThread; try { available.awaitNanos(delay); } finally { if (leader == thisThread) leader = null; } }
- DelayQueue 是一個支援延時獲取元素的無界阻塞佇列。佇列使用 PriorityQueue 來實現。佇列中的元素必須實現 Delayed 介面,在建立元素時可以指定多久才能從佇列中獲取當前元素。只有在延遲期滿時才能從佇列中提取元素。DelayQueue 非常有用,可以將 DelayQueue 運用在以下應用場景
-
SynchronousQueue
- SynchronousQueue 是一個不儲存元素的阻塞佇列。每一個 put 操作必須等待一個 take 操作,否則不能繼續新增元素。它支援公平訪問佇列。預設情況下執行緒採用非公平性策略訪問佇列。使用以下構造方法可以建立公平性訪問的 SynchronousQueue,如果設定為 true,則等待的執行緒會採用先進先出的順序訪問佇列
- SynchronousQueue 可以看成是一個傳球手,負責把生產者執行緒處理的資料直接傳遞給消費者執行緒。佇列本身並不儲存任何元素,非常適合傳遞性場景。SynchronousQueue 的吞吐量高於LinkedBlockingQueue 和 ArrayBlockingQueue
public SynchronousQueue(boolean fair) { transferer = fair new TransferQueue() : new TransferStack(); }
-
LinkedTransferQueue
- LinkedTransferQueue 是一個由連結串列結構組成的無界阻塞 TransferQueue 佇列。相對於其他阻塞佇列,LinkedTransferQueue 多了 tryTransfer 和 transfer 方法
- transfer方法
- 如果當前有消費者正在等待接收元素(消費者使用 take() 方法或帶時間限制的 poll() 方法時),transfer 方法可以把生產者傳入的元素立刻 transfer(傳輸)給消費者。如果沒有消費者在等待接收元素,transfer 方法會將元素存放在佇列的 tail 節點,並等到該元素被消費者消費了才返回。transfer 方法的關鍵程式碼如下
- 第一行程式碼是試圖把存放當前元素的s節點作為 tail 節點。第二行程式碼是讓 CPU 自旋等待消費者消費元素。因為自旋會消耗 CPU,所以自旋一定的次數後使用 Thread.yield() 方法來暫停當前正在執行的執行緒,並執行其他執行緒
Node pred = tryAppend(s, haveData); return awaitMatch(s, pred, e, (how == TIMED), nanos);
- tryTransfer 方法
- tryTransfer 方法是用來試探生產者傳入的元素是否能直接傳給消費者。如果沒有消費者等待接收元素,則返回 false。和 transfer 方法的區別是 tryTransfer 方法無論消費者是否接收,方法立即返回,而 transfer 方法是必須等到消費者消費了才返回。對於帶有時間限制的 tryTransfer(E e,long timeout,TimeUnit unit)方法,試圖把生產者傳入的元素直接傳給消費者,但是如果沒有消費者消費該元素則等待指定的時間再返回,如果超時還沒消費元素,則返回 false,如果在超時時間內消費了元素,則返回 true
-
LinkedBlockingDeque
- LinkedBlockingDeque 是一個由連結串列結構組成的雙向阻塞佇列。所謂雙向佇列指的是可以從佇列的兩端插入和移出元素。雙向佇列因為多了一個操作佇列的入口,在多執行緒同時入隊時,也就減少了一半的競爭。相比其他的阻塞佇列,LinkedBlockingDeque 多了 addFirst、addLast、offerFirst、offerLast、peekFirst 和 peekLast 等方法,以 First 單詞結尾的方法,表示插入、獲取(peek)或移除雙端佇列的第一個元素。以 Last 單詞結尾的方法,表示插入、獲取或移除雙端佇列的最後一個元素。另外,插入方法 add 等同於 addLast,移除方法 remove 等效於 removeFirst。但是 take 方法卻等同於 takeFirst,不知道是不是 JDK 的 bug,使用時還是用帶有 First 和 Last 字尾的方法更清楚。在初始化 LinkedBlockingDeque 時可以設定容量防止其過度膨脹。另外,雙向阻塞佇列可以運用在“工作竊取”模式中
-
阻塞佇列的實現原理
- 通知模式實現。所謂通知模式,就是當生產者往滿的佇列裡新增元素時會阻塞住生產者,當消費者消費了一個佇列中的元素後,會通知生產者當前佇列可用
private final Condition notFull; private final Condition notEmpty; public ArrayBlockingQueue(int capacity, boolean fair) { // 省略其他程式碼 notEmpty = lock.newCondition(); notFull = lock.newCondition(); } public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); insert(e); } finally { lock.unlock(); } } public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == 0) notEmpty.await(); return extract(); } finally { lock.unlock(); } } private void insert(E x) { items[putIndex] = x; putIndex = inc(putIndex); ++count; notEmpty.signal(); } - 當往佇列裡插入一個元素時,如果佇列不可用,那麼阻塞生產者主要通過 LockSupport.park(this) 來實現
public final void await() throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); Node node = addConditionWaiter(); int savedState = fullyRelease(node); int interruptMode = 0; while (!isOnSyncQueue(node)) { LockSupport.park(this); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; } if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null) // clean up if cancelled unlinkCancelledWaiters(); if (interruptMode != 0) reportInterruptAfterWait(interruptMode); } - 繼續進入原始碼,發現呼叫 setBlocker 先儲存一下將要阻塞的執行緒,然後呼叫 unsafe.park 阻塞當前執行緒
public static void park(Object blocker) { Thread t = Thread.currentThread(); setBlocker(t, blocker); unsafe.park(false, 0L); setBlocker(t, null); } - unsafe.park 是個 native 方法,程式碼如下。
public native void park(boolean isAbsolute, long time); - park這個方法會阻塞當前執行緒,只有以下4種情況中的一種發生時,該方法才會返回
- 與 park 對應的 unpark 執行或已經執行時。“已經執行”是指 unpark 先執行,然後再執行 park 的情況
- 執行緒被中斷時
- 等待完 time 引數指定的毫秒數時
- 異常現象發生時,這個異常現象沒有任何原因
- park 在不同的作業系統中使用不同的方式實現
- 通知模式實現。所謂通知模式,就是當生產者往滿的佇列裡新增元素時會阻塞住生產者,當消費者消費了一個佇列中的元素後,會通知生產者當前佇列可用
Fork/Join 框架
-
什麼是 Fork/Join 框架
- Fork/Join 框架是 Java 7 提供的一個用於並行執行任務的框架,是一個把大任務分割成若干個小任務,最終彙總每個小任務結果後得到大任務結果的框架
- Fork 就是把一個大任務切分為若干子任務並行的執行
- Join 就是合併這些子任務的執行結果
-
工作竊取演算法
- 工作竊取(work-stealing)演算法是指某個執行緒從其他佇列裡竊取任務來執行。例如建立多個執行緒,被竊取任務執行緒永遠從雙端佇列的頭部拿任務執行,而竊取任務的執行緒永遠從雙端佇列的尾部拿任務執行。可以加快任務執行效率
- 工作竊取演算法的優點:充分利用執行緒進行平行計算,減少了執行緒間的競爭
- 工作竊取演算法的缺點:在某些情況下還是存在競爭,比如雙端佇列裡只有一個任務時。並且該演算法會消耗了更多的系統資源,比如建立多個執行緒和多個雙端佇列
-
Fork/Join 框架的設計
- Fork/Join 框架的設計
- 分割任務。首先我們需要有一個 fork 類來把大任務分割成子任務,有可能子任務還是很大,所以還需要不停地分割,直到分割出的子任務足夠小
- 執行任務併合並結果。分割的子任務分別放在雙端佇列裡,然後幾個啟動執行緒分別從雙端佇列裡獲取任務執行。子任務執行完的結果都統一放在一個佇列裡,啟動一個執行緒從佇列裡拿資料,然後合併這些資料
- Fork/Join 使用的兩個類
- ForkJoinTask:我們要使用 ForkJoin 框架,必須首先建立一個 ForkJoin 任務。它提供在任務中執行 fork() 和 join() 操作的機制。通常情況下,我們不需要直接繼承 ForkJoinTask 類,只需要繼承它的子類,Fork/Join 框架提供了以下兩個子類
- RecursiveAction:用於沒有返回結果的任務
- RecursiveTask:用於有返回結果的任務
- ForkJoinPool:ForkJoinTask 需要通過 ForkJoinPool 來執行
- ForkJoinTask:我們要使用 ForkJoin 框架,必須首先建立一個 ForkJoin 任務。它提供在任務中執行 fork() 和 join() 操作的機制。通常情況下,我們不需要直接繼承 ForkJoinTask 類,只需要繼承它的子類,Fork/Join 框架提供了以下兩個子類
- 任務分割出的子任務會新增到當前工作執行緒所維護的雙端佇列中,進入佇列的頭部。當一個工作執行緒的佇列裡暫時沒有任務時,它會隨機從其他工作執行緒的佇列的尾部獲取一個任務
- Fork/Join 框架的設計
-
使用 Fork/Join 框架
package fj; import java.util.concurrent.ExecutionException; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Future; import java.util.concurrent.RecursiveTask; public class CountTask extends RecursiveTask<Integer> { private static final int THRESHOLD = 2; // 閾值 private int start; private int end; public CountTask(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; // 如果任務足夠小就計算任務 boolean canCompute = (end - start) <= THRESHOLD; if (canCompute) { for (int i = start; i <= end; i++) { sum += i; } } else { // 如果任務大於閾值,就分裂成兩個子任務計算 int middle = (start + end) / 2; CountTask leftTask = new CountTask(start, middle); CountTask rightTask = new CountTask(middle + 1, end); // 執行子任務 leftTask.fork(); rightTask.fork(); // 等待子任務執行完,並得到其結果 int leftResult=leftTask.join(); int rightResult=rightTask.join(); // 合併子任務 sum = leftResult + rightResult; } return sum; } public static void main(String[] args) { ForkJoinPool forkJoinPool = new ForkJoinPool(); // 生成一個計算任務,負責計算1+2+3+4 CountTask task = new CountTask(1, 4); // 執行一個任務 Future<Integer> result = forkJoinPool.submit(task); try { System.out.println(result.get()); } catch (InterruptedException e) { } catch (ExecutionException e) { } } } -
Fork/Join 框架的異常處理
- ForkJoinTask 在執行的時候可能會丟擲異常,但是我們沒辦法在主執行緒裡直接捕獲異常,所以 ForkJoinTask 提供了 isCompletedAbnormally() 方法來檢查任務是否已經丟擲異常或已經被取消了,並且可以通過 ForkJoinTask 的 getException 方法獲取異常。使用如下程式碼
- getException 方法返回 Throwable 物件,如果任務被取消了則返回 CancellationException。如果任務沒有完成或者沒有丟擲異常則返回 null
if(task.isCompletedAbnormally()){ System.out.println(task.getException()); }
-
Fork/Join 框架的實現原理
- ForkJoinPool 由 ForkJoinTask 陣列和 ForkJoinWorkerThread 陣列組成,ForkJoinTask 陣列負責將存放程式提交給 ForkJoinPool 的任務,而 ForkJoinWorkerThread 陣列負責執行這些任務
- ForkJoinTask 的 fork 方法實現原理
- 當我們呼叫 ForkJoinTask 的 fork 方法時,程式會呼叫 ForkJoinWorkerThread 的 pushTask 方法非同步地執行這個任務,然後立即返回結果
public final ForkJoinTask<V> fork() { ((ForkJoinWorkerThread) Thread.currentThread()).pushTask(this); return this; } - pushTask 方法把當前任務存放在 ForkJoinTask 陣列佇列裡。然後再呼叫 ForkJoinPool 的 signalWork() 方法喚醒或建立一個工作執行緒來執行任務
final void pushTask(ForkJoinTask<> t) { ForkJoinTask<>[] q; int s, m; if ((q = queue) != null) { // ignore if queue removed long u = (((s = queueTop) & (m = q.length - 1)) << ASHIFT) + ABASE; UNSAFE.putOrderedObject(q, u, t); // or use putOrderedInt queueTop = s + 1; if ((s -= queueBase) <= 2) pool.signalWork(); else if (s == m) growQueue(); } }
- 當我們呼叫 ForkJoinTask 的 fork 方法時,程式會呼叫 ForkJoinWorkerThread 的 pushTask 方法非同步地執行這個任務,然後立即返回結果
- ForkJoinTask 的 join 方法實現原理
- Join 方法的主要作用是阻塞當前執行緒並等待獲取結果。讓我們一起看看 ForkJoinTask 的 join 方法的實現
public final V join() { if (doJoin() != NORMAL) return reportResult(); else return getRawResult(); } private V reportResult() { int s; Throwable ex; if ((s = status) == CANCELLED) throw new CancellationException(); if (s == EXCEPTIONAL && (ex = getThrowableException()) != null) UNSAFE.throwException(ex); return getRawResult(); } - 首先,它呼叫了 doJoin() 方法,通過 doJoin() 方法得到當前任務的狀態來判斷返回什麼結果,任務狀態有4種:已完成(NORMAL)、被取消(CANCELLED)、訊號(SIGNAL)和出現異常(EXCEPTIONAL)
- 如果任務狀態是已完成,則直接返回任務結果
- 如果任務狀態是被取消,則直接丟擲 CancellationException
- 如果任務狀態是丟擲異常,則直接丟擲對應的異常
- 在 doJoin() 方法裡,首先通過檢視任務的狀態,看任務是否已經執行完成,如果執行完成,則直接返回任務狀態;如果沒有執行完,則從任務陣列裡取出任務並執行。如果任務順利執行完成,則設定任務狀態為 NORMAL,如果出現異常,則記錄異常,並將任務狀態設定為 EXCEPTIONAL
private int doJoin() { Thread t; ForkJoinWorkerThread w; int s; boolean completed; if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) { if ((s = status) < 0) return s; if ((w = (ForkJoinWorkerThread)t).unpushTask(this)) { try { completed = exec(); } catch (Throwable rex) { return setExceptionalCompletion(rex); } if (completed) return setCompletion(NORMAL); } return w.joinTask(this); } else return externalAwaitDone(); }
- Join 方法的主要作用是阻塞當前執行緒並等待獲取結果。讓我們一起看看 ForkJoinTask 的 join 方法的實現
第七章 Java 中的 13 個原子操作類
原子更新基本型別類
-
原子更新基本型別,Atomic 包提供了以下 3 個類
- AtomicBoolean:原子更新布林型別
- AtomicInteger:原子更新整型
- AtomicLong:原子更新長整型
-
AtomicInteger 的常用方法
- int addAndGet(int delta):以原子方式將輸入的數值與例項中的值(AtomicInteger裡的value)相加,並返回結果
- boolean compareAndSet(int expect,int update):如果輸入的數值等於預期值,則以原子方式將該值設定為輸入的值
- int getAndIncrement():以原子方式將當前值加1,注意,這裡返回的是自增前的值
- void lazySet(int newValue):最終會設定成 newValue,使用 lazySet 設定值後,可能導致其他執行緒在之後的一小段時間內還是可以讀到舊的值
- int getAndSet(int newValue):以原子方式設定為 newValue 的值,並返回舊值
- private volatile int value; volatile 標記的屬性
-
示例
public class AtomicIntegerTest { static AtomicInteger ai = new AtomicInteger(1); public static void main(String[] args) { System.out.println(ai.getAndIncrement()); System.out.println(ai.get()); } } -
getAndIncrement() 解析
- 原始碼中 for 迴圈體的第一步先取得 AtomicInteger 裡儲存的數值,第二步對 AtomicInteger 的當前數值進行加 1 操作,關鍵的第三步呼叫 compareAndSet 方法來進行原子更新操作,該方法先檢查當前數值是否等於 current,等於意味著 AtomicInteger 的值沒有被其他執行緒修改過,則將 AtomicInteger 的當前數值更新成 next 的值,如果不等 compareAndSet 方法會返回 false,程式會進入 for 迴圈重新進行 compareAndSet 操作
- jdk1.8 使用 do…while 做的迴圈,效果是一樣的
-
Unsafe 只提供了 3 種 CAS 方法:compareAndSwapObject、compare-AndSwapInt 和 compareAndSwapLong,再看 AtomicBoolean 原始碼,發現它是先把 Boolean 轉換成整型,再使用compareAndSwapInt 進行 CAS,所以原子更新 char、float 和 double 變數也可以用類似的思路來實現
public final int getAndIncrement() { for (;;) { int current = get(); int next = current + 1; if (compareAndSet(current, next)) return current; } } public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
原子更新陣列
-
通過原子的方式更新陣列裡的某個元素,Atomic 包提供了以下 3 個類
- AtomicIntegerArray:原子更新整型陣列裡的元素
- AtomicLongArray:原子更新長整型陣列裡的元素
- AtomicReferenceArray:原子更新引用型別陣列裡的元素
-
AtomicIntegerArray 類主要是提供原子的方式更新陣列裡的整型
- int addAndGet(int i,int delta):以原子方式將輸入值與陣列中索引 i 的元素相加
- boolean compareAndSet(int i,int expect,int update):如果當前值等於預期值,則以原子方式將陣列位置i的元素設定成 update 值
-
示例
public class AtomicIntegerArrayTest { static int[] value = new int[] { 1, 2 }; static AtomicIntegerArray ai = new AtomicIntegerArray(value); public static void main(String[] args) { ai.getAndSet(0, 3); System.out.println(ai.get(0)); System.out.println(value[0]); } } -
陣列 value 通過構造方法傳遞進去,然後 AtomicIntegerArray 會將當前陣列複製一份,所以當 AtomicIntegerArray 對內部的陣列元素進行修改時,不會影響傳入的陣列
原子更新引用型別
-
原子更新基本型別的 AtomicInteger,只能更新一個變數,如果要原子更新多個變數,就需要使用這個原子更新引用型別提供的類。Atomic 包提供了以下 3 個類
- AtomicReference:原子更新引用型別
- AtomicReferenceFieldUpdater:原子更新引用型別裡的欄位
- AtomicMarkableReference:原子更新帶有標記位的引用型別。可以原子更新一個布林型別的標記位和引用型別。構造方法是 AtomicMarkableReference(V initialRef,boolean initialMark)
-
示例
public class AtomicReferenceTest { public static AtomicReference<user> atomicUserRef = new AtomicReference<user>(); public static void main(String[] args) { User user = new User("conan", 15); atomicUserRef.set(user); User updateUser = new User("Shinichi", 17); atomicUserRef.compareAndSet(user, updateUser); System.out.println(atomicUserRef.get().getName()); System.out.println(atomicUserRef.get().getOld()); } static class User { private String name; private int old; public User(String name, int old) { this.name = name; this.old = old; } public String getName() { return name; } public int getOld() { return old; } } } -
程式碼中首先構建一個 user 物件,然後把 user 物件設定進 AtomicReferenc 中,最後呼叫 compareAndSet 方法進行原子更新操作,實現原理同 AtomicInteger 裡的 compareAndSet 方法
原子更新欄位類
-
如果需原子地更新某個類裡的某個欄位時,就需要使用原子更新欄位類,Atomic 包提供了以下 3 個類進行原子欄位更新
- AtomicIntegerFieldUpdater:原子更新整型的欄位的更新器
- AtomicLongFieldUpdater:原子更新長整型欄位的更新器
- AtomicStampedReference:原子更新帶有版本號的引用型別。該類將整數值與引用關聯起來,可用於原子的更新資料和資料的版本號,可以解決使用 CAS 進行原子更新時可能出現的 ABA 問題
-
要想原子地更新欄位類需要兩步。第一步,因為原子更新欄位類都是抽象類,每次使用的時候必須使用靜態方法 newUpdater() 建立一個更新器,並且需要設定想要更新的類和屬性。第二步,更新類的欄位(屬性)必須使用 public volatile 修飾符
-
示例
public class AtomicIntegerFieldUpdaterTest { // 建立原子更新器,並設定需要更新的物件類和物件的屬性 private static AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater. newUpdater(User.class, "old"); public static void main(String[] args) { // 設定柯南的年齡是10歲 User conan = new User("conan", 10); // 柯南長了一歲,但是仍然會輸出舊的年齡 System.out.println(a.getAndIncrement(conan)); // 輸出柯南現在的年齡 System.out.println(a.get(conan)); } public static class User { private String name; public volatile int old; public User(String name, int old) { this.name = name; this.old = old; } public String getName() { return name; } public int getOld() { return old; } } }
第八章 Java中的併發工具類
等待多執行緒完成的 CountDownLatch
-
CountDownLatch 概述
- CountDownLatch 是一個同步工具類,用來協調多個執行緒之間的同步,或者說起到執行緒之間的通訊(而不是用作互斥的作用)。CountDownLatch 能夠使一個執行緒在等待另外一些執行緒完成各自工作之後,再繼續執行
-
CountDownLatch 實現方式
- CountDownLatch 的建構函式接收一個 int 型別的引數作為計數器,如果你想等待 N 個點完成,這裡就傳入 N。當我們呼叫 CountDownLatch 的 countDown 方法時,N 就會減 1,CountDownLatch 的 await 方法會阻塞當前執行緒,直到 N 變成零。由於 countDown 方法可以用在任何地方,所以這裡說的 N 個點,可以是 N 個執行緒,也可以是 1 個執行緒裡的 N 個執行步驟。用在多個執行緒時,只需要把這個 CountDownLatch 的引用傳遞到執行緒裡即可
-
CountDownLatch 應用場景
- 典型應用場景就是啟動一個服務時,主執行緒需要等待多個元件載入完畢,之後再繼續執行
- 如果有某個解析 sheet 的執行緒處理得比較慢,我們不可能讓主執行緒一直等待,所以可以使用另外一個帶指定時間的 await 方法——await(long time,TimeUnit unit),這個方法等待特定時間後,就會不再阻塞當前執行緒。join 也有類似的方法
- 注意 計數器必須大於等於 0,只是等於 0 時候,計數器就是零,呼叫 await 方法時不會阻塞當前執行緒。CountDownLatch 不可能重新初始化或者修改 CountDownLatch 物件的內部計數器的值。一個執行緒呼叫 countDown 方法 happen-before,另外一個執行緒呼叫 await 方法
-
示例
public class CountDownLatchTest { staticCountDownLatch c = new CountDownLatch(2); public static void main(String[] args) throws InterruptedException { new Thread(new Runnable() { @Override public void run() { System.out.println(1); c.countDown(); System.out.println(2); c.countDown(); } }).start(); c.await(); System.out.println("3"); } }
同步屏障 CyclicBarrier
-
CyclicBarrier 概述
- CyclicBarrier 的字面意思是可迴圈使用(Cyclic)的屏障(Barrier)。它要做的事情是,讓一組執行緒到達一個屏障(也可以叫同步點)時被阻塞,直到最後一個執行緒到達屏障時,屏障才會開門,所有被屏障攔截的執行緒才會繼續執行
-
CyclicBarrier 簡介
- CyclicBarrier 預設的構造方法是 CyclicBarrier(int parties),其參數列示屏障攔截的執行緒數量,每個執行緒呼叫 await 方法告訴 CyclicBarrier 我已經到達了屏障,然後當前執行緒被阻塞。如果把 new CyclicBarrier(2) 修改成 new CyclicBarrier(3),則主執行緒和子執行緒會永遠等待,因為沒有第三個執行緒執行 await 方法,所以之前到達屏障的兩個執行緒都不會繼續執行
-
示例一
public class CyclicBarrierTest { staticCyclicBarrier c = new CyclicBarrier(2); public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { try { c.await(); } catch (Exception e) { } System.out.println(1); } }).start(); try { c.await(); } catch (Exception e) { } System.out.println(2); } } // 輸出 1 2 或2 1 // 因為主執行緒和子執行緒的排程是由CPU決定的,兩個執行緒都有可能先執行,所以會產生兩種輸出 -
示例二
- CyclicBarrier 還提供一個更高階的建構函式 CyclicBarrier(int parties,Runnable barrierAction),用於線上程到達屏障時,優先執行 barrierAction,方便處理更復雜的業務場景。因為 CyclicBarrier 設定了攔截執行緒的數量是 2,所以必須等程式碼中的第一個執行緒和執行緒 A 都執行完之後,才會繼續執行主執行緒,然後輸出 2
import java.util.concurrent.CyclicBarrier; public class CyclicBarrierTest2 { static CyclicBarrier c = new CyclicBarrier(2, new A()); public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { try { c.await(); } catch (Exception e) { } System.out.println(1); } }).start(); try { c.await(); } catch (Exception e) { } System.out.println(2); } static class A implements Runnable { @Override public void run() { System.out.println(3); } } } // 輸出 3 1 2
- CyclicBarrier 還提供一個更高階的建構函式 CyclicBarrier(int parties,Runnable barrierAction),用於線上程到達屏障時,優先執行 barrierAction,方便處理更復雜的業務場景。因為 CyclicBarrier 設定了攔截執行緒的數量是 2,所以必須等程式碼中的第一個執行緒和執行緒 A 都執行完之後,才會繼續執行主執行緒,然後輸出 2
-
CyclicBarrier 的應用場景
- CyclicBarrier 可以用於多執行緒計算資料,最後合併計算結果的場景。例如,用一個 Excel 儲存了使用者所有銀行流水,每個 Sheet 儲存一個賬戶近一年的每筆銀行流水,現在需要統計使用者的日均銀行流水,先用多執行緒處理每個 sheet 裡的銀行流水,都執行完之後,得到每個 sheet 的日均銀行流水,最後,再用 barrierAction 用這些執行緒的計算結果,計算出整個 Excel 的日均銀行流水
publicclass BankWaterService implements Runnable { /** * 建立4個屏障,處理完之後執行當前類的run方法 */ private CyclicBarrier c = new CyclicBarrier(4, this); /** * 假設只有4個sheet,所以只啟動4個執行緒 */ private Executor executor = Executors.newFixedThreadPool(4); /** * 儲存每個sheet計算出的銀流結果 */ private ConcurrentHashMap<String, Integer>sheetBankWaterCount = new ConcurrentHashMap<String, Integer>(); privatevoid count() { for (inti = 0; i< 4; i++) { executor.execute(new Runnable() { @Override publicvoid run() { // 計算當前sheet的銀流資料,計算程式碼省略 sheetBankWaterCount.put(Thread.currentThread().getName(), 1); // 銀流計算完成,插入一個屏障 try { c.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } } }); } } @Override publicvoid run() { intresult = 0; // 彙總每個sheet計算出的結果 for (Entry<String, Integer>sheet : sheetBankWaterCount.entrySet()) { result += sheet.getValue(); } // 將結果輸出 sheetBankWaterCount.put("result", result); System.out.println(result); } publicstaticvoid main(String[] args) { BankWaterService bankWaterCount = new BankWaterService(); bankWaterCount.count(); } } //輸出 4 -
CyclicBarrier 和 CountDownLatch 的區別
- CountDownLatch 的計數器只能使用一次,而 CyclicBarrier 的計數器可以使用 reset() 方法重置。所以 CyclicBarrier 能處理更為複雜的業務場景。例如,如果計算髮生錯誤,可以重置計數器,並讓執行緒重新執行一次
- CyclicBarrier 還提供其他有用的方法,比如 getNumberWaiting 方法可以獲得 CyclicBarrier 阻塞的執行緒數量。isBroken() 方法用來了解阻塞的執行緒是否被中斷
控制併發執行緒數的 Semaphore
-
Semaphore 概述
- Semaphore(訊號量)是用來控制同時訪問特定資源的執行緒數量,它通過協調各個執行緒,以保證合理的使用公共資源
-
Semaphore 應用場景
- Semaphore 可以用於做流量控制,特別是公用資源有限的應用場景,比如資料庫連線
- 在程式碼中,雖然有 30 個執行緒在執行,但是隻允許 10 個併發執行。Semaphore 的構造方法 Semaphore(int permits)接受一個整型的數字,表示可用的許可證數量。Semaphore(10)表示允許 10 個執行緒獲取許可證,也就是最大併發數是 10。Semaphore 的用法也很簡單,首先執行緒使用 Semaphore 的 acquire() 方法獲取一個許可證,使用完之後呼叫 release() 方法歸還許可證。還可以用 tryAcquire() 方法嘗試獲取許可證
-
示例
public class SemaphoreTest { private static final int THREAD_COUNT = 30; private static ExecutorServicethreadPool = Executors.newFixedThreadPool(THREAD_COUNT); private static Semaphore s = new Semaphore(10); public static void main(String[] args) { for (inti = 0; i< THREAD_COUNT; i++) { threadPool.execute(new Runnable() { @Override public void run() { try { s.acquire(); System.out.println("save data"); s.release(); } catch (InterruptedException e) { } } }); } threadPool.shutdown(); } } -
其他方法
- intavailablePermits():返回此訊號量中當前可用的許可證數
- intgetQueueLength():返回正在等待獲取許可證的執行緒數
- booleanhasQueuedThreads():是否有執行緒正在等待獲取許可證
- void reducePermits(int reduction):減少 reduction 個許可證,是個 protected 方法
- Collection getQueuedThreads():返回所有等待獲取許可證的執行緒集合,是個 protected 方法
執行緒間交換資料的 Exchange
-
Exchange 概述
- Exchanger(交換者)是一個用於執行緒間協作的工具類。Exchanger 用於進行執行緒間的資料交換。它提供一個同步點,在這個同步點,兩個執行緒可以交換彼此的資料。這兩個執行緒通過 exchange 方法交換資料,如果第一個執行緒先執行 exchange() 方法,它會一直等待第二個執行緒也執行 exchange 方法,當兩個執行緒都到達同步點時,這兩個執行緒就可以交換資料,將本執行緒生產出來的資料傳遞給對方
-
Exchange 應用場景
- Exchanger 可以用於遺傳演算法,遺傳演算法裡需要選出兩個人作為交配物件,這時候會交換兩人的資料,並使用交叉規則得出 2 個交配結果。Exchanger 也可以用於校對工作,比如我們需要將紙製銀行流水通過人工的方式錄入成電子銀行流水,為了避免錯誤,採用 AB 崗兩人進行錄入,錄入到 Excel 之後,系統需要載入這兩個 Excel,並對兩個 Excel 資料進行校對,看看是否錄入一致
- 如果兩個執行緒有一個沒有執行 exchange() 方法,則會一直等待,如果擔心有特殊情況發生,避免一直等待,可以使用 exchange(V x,longtimeout,TimeUnit unit) 設定最大等待時長
-
示例
public class ExchangerTest { private static final Exchanger<String>exgr = new Exchanger<String>(); private static ExecutorServicethreadPool = Executors.newFixedThreadPool(2); public static void main(String[] args) { threadPool.execute(new Runnable() { @Override public void run() { try { String A = "銀行流水A"; // A錄入銀行流水資料 exgr.exchange(A); } catch (InterruptedException e) { } } }); threadPool.execute(new Runnable() { @Override public void run() { try { String B = "銀行流水B"; // B錄入銀行流水資料 String A = exgr.exchange("B"); System.out.println("A和B資料是否一致:" + A.equals(B) + ",A錄入的是:" + A + ",B錄入是:" + B); } catch (InterruptedException e) { } } }); threadPool.shutdown(); } }
第九章 Java中的執行緒池
執行緒池的優勢
- 降低資源消耗。通過重複利用已建立的執行緒降低執行緒建立和銷燬造成的消耗
- 提高響應速度。當任務到達時,任務可以不需要等到執行緒建立就能立即執行
- 提高執行緒的可管理性。執行緒是稀缺資源,如果無限制地建立,不僅會消耗系統資源,還會降低系統的穩定性,使用執行緒池可以進行統一分配、調優和監控
執行緒池的實現原理
- 執行緒的處理流程
- 執行緒池判斷核心執行緒池裡的執行緒是否都在執行任務。如果不是,則建立一個新的工作執行緒來執行任務。如果核心執行緒池裡的執行緒都在執行任務,則進入下個流程
- 執行緒池判斷工作佇列是否已經滿。如果工作佇列沒有滿,則將新提交的任務儲存在這個工作佇列裡。如果工作佇列滿了,則進入下個流程
- 執行緒池判斷執行緒池的執行緒是否都處於工作狀態。如果沒有,則建立一個新的工作執行緒來執行任務。如果已經滿了,則交給飽和策略來處理這個任務


- ThreadPoolExecutor 執行 execute 方法分下面4種情況
- 如果當前執行的執行緒少於 corePoolSize,則建立新執行緒來執行任務(注意,執行這一步驟需要獲取全域性鎖)
- 如果執行的執行緒等於或多於 corePoolSize,則將任務加入 BlockingQueue
- 如果無法將任務加入 BlockingQueue(佇列已滿),則建立新的執行緒來處理任務(注意,執行這一步驟需要獲取全域性鎖)
- 如果建立新執行緒將使當前執行的執行緒超出 maximumPoolSize,任務將被拒絕,並呼叫 RejectedExecutionHandler.rejectedExecution() 方法
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); // 如果執行緒數小於基本執行緒數,則建立執行緒並執行當前任務 if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) { // 如執行緒數大於等於基本執行緒數或執行緒建立失敗,則將當前任務放到工作佇列中。 if (runState == RUNNING && workQueue.offer(command)) { if (runState != RUNNING || poolSize == 0) ensureQueuedTaskHandled(command); } // 如果執行緒池不處於執行中或任務無法放入佇列,並且當前執行緒數量小於最大允許的執行緒數量, // 則建立一個執行緒執行任務。 else if (!addIfUnderMaximumPoolSize(command)) // 丟擲RejectedExecutionException異常 reject(command); // is shutdown or saturated } }
- 工作執行緒
- 執行緒池建立執行緒時,會將執行緒封裝成工作執行緒 Worker,Worker 在執行完任務後,還會迴圈獲取工作佇列裡的任務來執行
public void run() { try { Runnable task = firstTask; firstTask = null; while (task != null || (task = getTask()) != null) { runTask(task); task = null; } } finally { workerDone(this); } }
- 執行緒池建立執行緒時,會將執行緒封裝成工作執行緒 Worker,Worker 在執行完任務後,還會迴圈獲取工作佇列裡的任務來執行
- 執行緒池中的執行緒執行任務分兩種情況
- 在 execute() 方法中建立一個執行緒時,會讓這個執行緒執行當前任務
- 這個執行緒執行完任務後,會反覆從 BlockingQueue 獲取任務來執行
執行緒池的使用
-
執行緒池的建立
- 我們可以通過 ThreadPoolExecutor 來建立一個執行緒池
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime,milliseconds,runnableTaskQueue, handler); - 建立一個執行緒池時需要的引數
- corePoolSize(執行緒池的基本大小):當提交一個任務到執行緒池時,執行緒池會建立一個執行緒來執行任務,即使其他空閒的基本執行緒能夠執行新任務也會建立執行緒,等到需要執行的任務數大於執行緒池基本大小時就不再建立。如果呼叫了執行緒池的prestartAllCoreThreads()方法,執行緒池會提前建立並啟動所有基本執行緒
- runnableTaskQueue(任務佇列):用於儲存等待執行的任務的阻塞佇列
- ArrayBlockingQueue:是一個基於陣列結構的有界阻塞佇列,此佇列按 FIFO (先進先出)原則對元素進行排序
- LinkedBlockingQueue:一個基於連結串列結構的阻塞佇列,此佇列按 FIFO 排序元素,吞吐量通常要高於 ArrayBlockingQueue。靜態工廠方法 Executors.newFixedThreadPool()使 用了這個佇列
- SynchronousQueue:一個不儲存元素的阻塞佇列。每個插入操作必須等到另一個執行緒呼叫移除操作,否則插入操作一直處於阻塞狀態,吞吐量通常要高於 LinkedBlockingQueue,靜態工廠方法 Executors.newCachedThreadPool 使用了這個佇列
- PriorityBlockingQueue:一個具有優先順序的無限阻塞佇列
- maximumPoolSize(執行緒池最大數量):執行緒池允許建立的最大執行緒數。如果佇列滿了,並且已建立的執行緒數小於最大執行緒數,則執行緒池會再建立新的執行緒執行任務。值得注意的是,如果使用了無界的任務佇列這個引數就沒什麼效果
- ThreadFactory:用於設定建立執行緒的工廠,可以通過執行緒工廠給每個建立出來的執行緒設定更有意義的名字。使用開源框架 guava 提供的 ThreadFactoryBuilder 可以快速給執行緒池裡的執行緒設定有意義的名字
new ThreadFactoryBuilder().setNameFormat("XX-task-%d").build(); - RejectedExecutionHandler(飽和策略):當佇列和執行緒池都滿了,說明執行緒池處於飽和狀態,那麼必須採取一種策略處理提交的新任務。這個策略預設情況下是 AbortPolicy,表示無法處理新任務時丟擲異常。可以根據應用場景需要來實現 RejectedExecutionHandler 介面自定義策略。在 JDK 1.5 中 Java 執行緒池框架提供了以下 4 種策略
- AbortPolicy:直接丟擲異常
- CallerRunsPolicy:只用呼叫者所線上程來執行任務
- DiscardOldestPolicy:丟棄佇列裡最近的一個任務,並執行當前任務
- DiscardPolicy:不處理,丟棄掉
- keepAliveTime(執行緒活動保持時間):執行緒池的工作執行緒空閒後,保持存活的時間。所以,如果任務很多,並且每個任務執行的時間比較短,可以調大時間,提高執行緒的利用率
- TimeUnit(執行緒活動保持時間的單位):可選的單位有天(DAYS)、小時(HOURS)、分鐘(MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和納秒(NANOSECONDS,千分之一微秒)
- 我們可以通過 ThreadPoolExecutor 來建立一個執行緒池
-
向執行緒池提交任務
- 可以使用兩個方法向執行緒池提交任務,分別為execute()和submit()方法
- execute() 方法用於提交不需要返回值的任務,所以無法判斷任務是否被執行緒池執行成功
- submit() 方法用於提交需要返回值的任務。執行緒池會返回一個 future 型別的物件,可以通過 future 的 get() 方法來獲取返回值,get() 方法會阻塞當前執行緒直到任務完成,而使用 get(long timeout,TimeUnit unit) 方法則會阻塞當前執行緒一段時間後立即返回,這時候有可能任務沒有執行完
threadsPool.execute(new Runnable() { @Override public void run() { // TODO Auto-generated method stub } }); Future<Object> future = executor.submit(harReturnValuetask); try { Object s = future.get(); } catch (InterruptedException e) { // 處理中斷異常 } catch (ExecutionException e) { // 處理無法執行任務異常 } finally { // 關閉執行緒池 executor.shutdown(); }
-
關閉執行緒池
- 可以通過呼叫執行緒池的 shutdown 或 shutdownNow 方法來關閉執行緒池。它們的原理是遍歷執行緒池中的工作執行緒,然後逐個呼叫執行緒的 interrupt 方法來中斷執行緒,所以無法響應中斷的任務可能永遠無法終止
- shutdownNow 首先將執行緒池的狀態設定成 STOP,然後嘗試停止所有的正在執行或暫停任務的執行緒,並返回等待執行任務的列表
- shutdown 只是將執行緒池的狀態設定成 SHUTDOWN 狀態,然後中斷所有沒有正在執行任務的執行緒
- 只要呼叫了這兩個關閉方法中的任意一個,isShutdown 方法就會返回 true。當所有的任務都已關閉後,才表示執行緒池關閉成功,這時呼叫 isTerminaed 方法會返回 true。至於應該呼叫哪一種方法來關閉執行緒池,應該由提交到執行緒池的任務特性決定,通常呼叫 shutdown 方法來關閉執行緒池,如果任務不一定要執行完,則可以呼叫 shutdownNow 方法
-
合理地配置執行緒池
- 任務的性質
- CPU 密集型任務:CPU 密集型任務應配置儘可能小的執行緒,如配置 Ncpu+1 個執行緒的執行緒池
- IO 密集型任務:由於 IO 密集型任務執行緒並不是一直在執行任務,則應配置儘可能多的執行緒,如 2*Ncpu
- 混合型任務:如果可以拆分,將其拆分成一個 CPU 密集型任務和一個 IO 密集型任務,只要這兩個任務執行的時間相差不是太大,那麼分解後執行的吞吐量將高於序列執行的吞吐量。如果這兩個任務執行時間相差太大,則沒必要進行分解
- 可以通過 Runtime.getRuntime().availableProcessors() 方法獲得當前裝置的 CPU 個數
- 任務的優先順序
- 高、中和低。優先順序不同的任務可以使用優先順序佇列 PriorityBlockingQueue 來處理。它可以讓優先順序高的任務先執行。注意 如果一直有優先順序高的任務提交到佇列裡,那麼優先順序低的任務可能永遠不能執行
- 任務的執行時間
- 長、中和短。執行時間不同的任務可以交給不同規模的執行緒池來處理,或者可以使用優先順序佇列,讓執行時間短的任務先執行
- 任務的依賴性
- 是否依賴其他系統資源,如資料庫連線。依賴資料庫連線池的任務,因為執行緒提交SQL後需要等待資料庫返回結果,等待的時間越長,則CPU空閒時間就越長,那麼執行緒數應該設定得越大,這樣才能更好地利用CPU
- 建議使用有界佇列
- 有界佇列能增加系統的穩定性和預警能力,可以根據需要設大一點兒,比如幾千。有一次,我們系統裡後臺任務執行緒池的佇列和執行緒池全滿了,不斷丟擲拋棄任務的異常,通過排查發現是資料庫出現了問題,導致執行SQL變得非常緩慢,因為後臺任務執行緒池裡的任務全是需要向資料庫查詢和插入資料的,所以導致執行緒池裡的工作執行緒全部阻塞,任務積壓線上程池裡。如果當時我們設定成無界佇列,那麼執行緒池的佇列就會越來越多,有可能會撐滿記憶體,導致整個系統不可用,而不只是後臺任務出現問題。當然,我們的系統所有的任務是用單獨的伺服器部署的,我們使用不同規模的執行緒池完成不同型別的任務,但是出現這樣問題時也會影響到其他任務
- 任務的性質
-
執行緒池的監控
- 如果在系統中大量使用執行緒池,則有必要對執行緒池進行監控,方便在出現問題時,可以根據執行緒池的使用狀況快速定位問題。可以通過執行緒池提供的引數進行監控,在監控執行緒池的時候可以使用以下屬性
- taskCount:執行緒池需要執行的任務數量
- completedTaskCount:執行緒池在執行過程中已完成的任務數量,小於或等於 taskCount
- largestPoolSize:執行緒池裡曾經建立過的最大執行緒數量。通過這個資料可以知道執行緒池是否曾經滿過。如該數值等於執行緒池的最大大小,則表示執行緒池曾經滿過
- getPoolSize:執行緒池的執行緒數量。如果執行緒池不銷燬的話,執行緒池裡的執行緒不會自動銷燬,所以這個大小隻增不減
- getActiveCount:獲取活動的執行緒數
- 通過擴充套件執行緒池進行監控。可以通過繼承執行緒池來自定義執行緒池,重寫執行緒池的 beforeExecute、afterExecute 和 terminated 方法,也可以在任務執行前、執行後和執行緒池關閉前執行一些程式碼來進行監控。例如,監控任務的平均執行時間、最大執行時間和最小執行時間等。這幾個方法線上程池裡是空方法
protected void beforeExecute(Thread t, Runnable r) { }
- 如果在系統中大量使用執行緒池,則有必要對執行緒池進行監控,方便在出現問題時,可以根據執行緒池的使用狀況快速定位問題。可以通過執行緒池提供的引數進行監控,在監控執行緒池的時候可以使用以下屬性
第十章 Executor框架
Executor 框架
Java 的執行緒既是工作單元,也是執行機制。從 JDK 5 開始,把工作單元與執行機制分離開來。工作單元包括 Runnable 和 Callable,而執行機制由 Executor 框架提供
Executor 框架簡介
- Executor 框架的兩級排程模型
- 在 HotSpot VM 的執行緒模型中,Java 執行緒(java.lang.Thread)被一對一對映為本地作業系統執行緒。Java 執行緒啟動時會建立一個本地作業系統執行緒;當該 Java 執行緒終止時,這個作業系統執行緒也會被回收。作業系統會排程所有執行緒並將它們分配給可用的 CPU。在上層,Java 多執行緒程式通常把應用分解為若干個任務,然後使用使用者級的排程器(Executor框架)將這些任務對映為固定數量的執行緒;在底層,作業系統核心將這些執行緒對映到硬體處理器上

- 在 HotSpot VM 的執行緒模型中,Java 執行緒(java.lang.Thread)被一對一對映為本地作業系統執行緒。Java 執行緒啟動時會建立一個本地作業系統執行緒;當該 Java 執行緒終止時,這個作業系統執行緒也會被回收。作業系統會排程所有執行緒並將它們分配給可用的 CPU。在上層,Java 多執行緒程式通常把應用分解為若干個任務,然後使用使用者級的排程器(Executor框架)將這些任務對映為固定數量的執行緒;在底層,作業系統核心將這些執行緒對映到硬體處理器上
- Executor框架的結構與成員
- Executor 框架的結構
- Executor 框架主要由 3 大部分組成
- 任務。包括被執行任務需要實現的介面:Runnable 介面或 Callable 介面
- 任務的執行。包括任務執行機制的核心介面 Executor,以及繼承自 Executor 的 ExecutorService 介面。Executor 框架有兩個關鍵類實現了 ExecutorService 介面(ThreadPoolExecutor和ScheduledThreadPoolExecutor)
- 非同步計算的結果。包括介面 Future 和實現 Future 介面的 FutureTask 類
- Executor 框架包含的主要的類與介面
- Executor 是一個介面,它是 Executor 框架的基礎,它將任務的提交與任務的執行分離開來
- ThreadPoolExecutor 是執行緒池的核心實現類,用來執行被提交的任務
- ScheduledThreadPoolExecutor 是一個實現類,可以在給定的延遲後執行命令,或者定期執行命令。ScheduledThreadPoolExecutor 比 Timer 更靈活,功能更強大
- Future 介面和實現 Future 介面的 FutureTask 類,代表非同步計算的結果
- Runnable 介面和 Callable 介面的實現類,都可以被 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 執行


- Executor 框架工作方式
- 主執行緒首先要建立實現 Runnable 或者 Callable 介面的任務物件。工具類 Executors 可以把一個 Runnable 物件封裝為一個 Callable 物件(Executors.callable(Runnable task)或 Executors.callable(Runnable task,Object resule))
- 然後可以把 Runnable 物件直接交給 ExecutorService 執行(ExecutorService.execute(Runnable command));或者也可以把 Runnable 物件或 Callable 物件提交給ExecutorService 執行(Executor-Service.submit(Runnable task)或 ExecutorService.submit(Callabletask))
- 如果執行 ExecutorService.submit(…),ExecutorService 將返回一個實現 Future 介面的物件(到目前為止的JDK中,返回的是 FutureTask 物件)。由於 FutureTask 實現了 Runnable,程式設計師也可以建立 FutureTask,然後直接交給 ExecutorService 執行
- 最後,主執行緒可以執行 FutureTask.get() 方法來等待任務執行完成。主執行緒也可以執行 FutureTask.cancel(boolean mayInterruptIfRunning) 來取消此任務的執行
- Executor 框架主要由 3 大部分組成
- Executor 框架的成員
- ThreadPoolExecutor
- ThreadPoolExecutor 通常使用工廠類 Executors 來建立。Executors 可以建立 3 種型別的 ThreadPoolExecutor、SingleThreadExecutor、FixedThreadPoolCachedThreadPool
- FixedThreadPool
- FixedThreadPool 適用於為了滿足資源管理的需求,而需要限制當前執行緒數量的應用場景,它適用於負載比較重的伺服器
public static ExecutorService newFixedThreadPool(int nThreads) public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactorythreadFactory)
- FixedThreadPool 適用於為了滿足資源管理的需求,而需要限制當前執行緒數量的應用場景,它適用於負載比較重的伺服器
- SingleThreadExecutor
- SingleThreadExecutor 適用於需要保證順序地執行各個任務;並且在任意時間點,不會有多個執行緒是活動的應用場景
public static ExecutorService newSingleThreadExecutor() public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory)
- SingleThreadExecutor 適用於需要保證順序地執行各個任務;並且在任意時間點,不會有多個執行緒是活動的應用場景
- CachedThreadPool
- CachedThreadPool 是大小無界的執行緒池,適用於執行很多的短期非同步任務的小程式,或者是負載較輕的伺服器
public static ExecutorService newCachedThreadPool() public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory)
- CachedThreadPool 是大小無界的執行緒池,適用於執行很多的短期非同步任務的小程式,或者是負載較輕的伺服器
- ScheduledThreadPoolExecutor
- ScheduledThreadPoolExecutor 通常使用工廠類 Executors 來建立
- ScheduledThreadPoolExecutor
- ScheduledThreadPoolExecutor 適用於需要多個後臺執行緒執行週期任務,同時為了滿足資源管理的需求而需要限制後臺執行緒的數量的應用場景
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize,ThreadFactory threadFactory)
- ScheduledThreadPoolExecutor 適用於需要多個後臺執行緒執行週期任務,同時為了滿足資源管理的需求而需要限制後臺執行緒的數量的應用場景
- SingleThreadScheduledExecutor
- SingleThreadScheduledExecutor 適用於需要單個後臺執行緒執行週期任務,同時需要保證順序地執行各個任務的應用場景
public static ScheduledExecutorService newSingleThreadScheduledExecutor() public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory)
- SingleThreadScheduledExecutor 適用於需要單個後臺執行緒執行週期任務,同時需要保證順序地執行各個任務的應用場景
- Future 介面
- Future 介面和實現 Future 介面的 FutureTask 類用來表示非同步計算的結果。當我們把 Runnable 介面或 Callable 介面的實現類提交(submit)給 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 時,ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 會向我們返回一個 FutureTask 物件
<T> Future<T> submit(Callable<T> task) <T> Future<T> submit(Runnable task, T result) Future<> submit(Runnable task)
- Future 介面和實現 Future 介面的 FutureTask 類用來表示非同步計算的結果。當我們把 Runnable 介面或 Callable 介面的實現類提交(submit)給 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 時,ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 會向我們返回一個 FutureTask 物件
- Runnable 介面和 Callable 介面
- Runnable 介面和 Callable 介面的實現類,都可以被 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 執行。它們之間的區別是 Runnable 不會返回結果,而 Callable 可以返回結果
- 除了可以自己建立實現 Callable 介面的物件外,還可以使用工廠類 Executors 來把一個 Runnable 包裝成一個 Callable
public static Callable<Object> callable(Runnable task) // 假設返回物件Callable1 public static <T> Callable<T> callable(Runnable task, T result) // 假設返回物件Callable2 - 前面講過,當我們把一個 Callable 物件(比如上面的Callable1或Callable2)提交給 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 執行時,submit(…) 會向我們返回一個 FutureTask 物件。我們可以執行 FutureTask.get() 方法來等待任務執行完成。當任務成功完成後 FutureTask.get() 將返回該任務的結果。例如,如果提交的是物件 Callable1,FutureTask.get() 方法將返回 null;如果提交的是物件 Callable2,FutureTask.get() 方法將返回 result 物件
- ThreadPoolExecutor
- Executor 框架的結構
ThreadPoolExecutor詳解
-
Executor 框架最核心的類是 ThreadPoolExecutor,它是執行緒池的實現類,主要由下列 4 個元件構成
- corePool:核心執行緒池的大小
- maximumPool:最大執行緒池的大小
- BlockingQueue:用來暫時儲存任務的工作佇列
- RejectedExecutionHandler:當 ThreadPoolExecutor 已經關閉或 ThreadPoolExecutor 已經飽和時(達到了最大執行緒池大小且工作佇列已滿),execute() 方法將要呼叫的 Handler
-
通過 Executor 框架的工具類 Executors,可以建立 3 種型別的 ThreadPoolExecutor
- FixedThreadPool
- FixedThreadPool 被稱為可重用固定執行緒數的執行緒池
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } - FixedThreadPool 的 corePoolSize 和 maximumPoolSize 都被設定為建立 FixedThreadPool 時指定的引數 nThreads
- 執行流程
- 當執行緒池中的執行緒數大於 corePoolSize 時,keepAliveTime 為多餘的空閒執行緒等待新任務的最長時間,超過這個時間後多餘的執行緒將被終止。這裡把 keepAliveTime 設定為 0L,意味著多餘的空閒執行緒會被立即終止

- 如果當前執行的執行緒數少於 corePoolSize,則建立新執行緒來執行任務
- 線上程池完成預熱之後(當前執行的執行緒數等於 corePoolSize ),將任務加入 LinkedBlockingQueue
- 執行緒執行完 1 中的任務後,會在迴圈中反覆從 LinkedBlockingQueue 獲取任務來執行
- 當執行緒池中的執行緒數大於 corePoolSize 時,keepAliveTime 為多餘的空閒執行緒等待新任務的最長時間,超過這個時間後多餘的執行緒將被終止。這裡把 keepAliveTime 設定為 0L,意味著多餘的空閒執行緒會被立即終止
- FixedThreadPool 使用無界佇列 LinkedBlockingQueue 作為執行緒池的工作佇列(佇列的容量為 Integer.MAX_VALUE)。使用無界佇列作為工作佇列會對執行緒池帶來如下影響
- 當執行緒池中的執行緒數達到 corePoolSize 後,新任務將在無界佇列中等待,因此執行緒池中的執行緒數不會超過 corePoolSize
- 由於 1,使用無界佇列時 maximumPoolSize 將是一個無效引數
- 由於 1 和 2,使用無界佇列時 keepAliveTime 將是一個無效引數
- 由於使用無界佇列,執行中的 FixedThreadPool(未執行方法shutdown()或shutdownNow())不會拒絕任務(不會呼叫 RejectedExecutionHandler.rejectedExecution 方法)
- FixedThreadPool 被稱為可重用固定執行緒數的執行緒池
- SingleThreadExecutor
- SingleThreadExecutor 是使用單個 worker 執行緒的 Executor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } ``` * SingleThreadExecutor 的 corePoolSize 和 maximumPoolSize 被設定為 1。其他引數與 FixedThreadPool 相同。SingleThreadExecutor 使用無界佇列 LinkedBlockingQueue 作為執行緒池的工作佇列(佇列的容量為Integer.MAX_VALUE) - SingleThreadExecutor 使用無界佇列作為工作佇列對執行緒池帶來的影響與 FixedThreadPool 相同
- 執行流程
- 如果當前執行的執行緒數少於 corePoolSize(即執行緒池中無執行的執行緒),則建立一個新執行緒來執行任務
- 線上程池完成預熱之後(當前執行緒池中有一個執行的執行緒),將任務加入 LinkedBlockingQueue
- 執行緒執行完 1 中的任務後,會在一個無限迴圈中反覆從 LinkedBlockingQueue 獲取任務來執行
- SingleThreadExecutor 是使用單個 worker 執行緒的 Executor
- CachedThreadPool
- CachedThreadPool 是一個會根據需要建立新執行緒的執行緒池
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); } - CachedThreadPool 的 corePoolSize 被設定為 0,即 corePool 為空;maximumPoolSize 被設定為 Integer.MAX_VALUE,即 maximumPool 是無界的。這裡把 keepAliveTime 設定為 60L,意味著 CachedThreadPool 中的空閒執行緒等待新任務的最長時間為 60 秒,空閒執行緒超過 60 秒後將會被終止
- FixedThreadPool 和 SingleThreadExecutor 使用無界佇列 LinkedBlockingQueue 作為執行緒池的工作佇列。CachedThreadPool 使用沒有容量的 SynchronousQueue 作為執行緒池的工作佇列,但 CachedThreadPool 的 maximumPool 是無界的。這意味著,如果主執行緒提交任務的速度高於 maximumPool 中執行緒處理任務的速度時,CachedThreadPool 會不斷建立新執行緒。極端情況下,CachedThreadPool 會因為建立過多執行緒而耗盡 CPU 和記憶體資源
- 執行流程
- 首先執行 SynchronousQueue.offer(Runnable task)。如果當前 maximumPool 中有空閒執行緒正在執行 SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS),那麼主執行緒執行 offer 操作與空閒執行緒執行的 poll 操作配對成功,主執行緒把任務交給空閒執行緒執行,execute() 方法執行完成;否則執行下面的步驟
- 當初始 maximumPool 為空,或者 maximumPool 中當前沒有空閒執行緒時,將沒有執行緒執行 SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)。這種情況下,步驟1)將失敗。此時 CachedThreadPool 會建立一個新執行緒執行任務,execute() 方法執行完成
- 在步驟2)中新建立的執行緒將任務執行完後,會執行 SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)。這個 poll 操作會讓空閒執行緒最多在 SynchronousQueue 中等待 60 秒鐘。如果 60 秒鐘內主執行緒提交了一個新任務(主執行緒執行步驟1)),那麼這個空閒執行緒將執行主執行緒提交的新任務;否則,這個空閒執行緒將終止。由於空閒 60 秒的空閒執行緒會被終止,因此長時間保持空閒的 CachedThreadPool 不會使用任何資源
- SynchronousQueue 是一個沒有容量的阻塞佇列。每個插入操作必須等待另一個執行緒的對應移除操作,反之亦然。CachedThreadPool 使用 SynchronousQueue,把主執行緒提交的任務傳遞給空閒執行緒執行

- CachedThreadPool 是一個會根據需要建立新執行緒的執行緒池
- FixedThreadPool
ScheduledThreadPoolExecutor詳解
-
概述
- ScheduledThreadPoolExecutor 繼承自 ThreadPoolExecutor。它主要用來在給定的延遲之後執行任務,或者定期執行任務。ScheduledThreadPoolExecutor 的功能與 Timer 類似,但ScheduledThreadPoolExecutor 功能更強大、更靈活。Timer 對應的是單個後臺執行緒,而 ScheduledThreadPoolExecutor 可以在建構函式中指定多個對應的後臺執行緒數
-
ScheduledThreadPoolExecutor 的執行機制
- DelayQueue 是一個無界佇列,所以 ThreadPoolExecutor 的 maximumPoolSize 在 Scheduled-ThreadPoolExecutor 中沒有什麼意義(設定 maximumPoolSize 的大小沒有什麼效果)
- 執行流程
- 當呼叫 ScheduledThreadPoolExecutor 的 scheduleAtFixedRate() 方法或者 scheduleWith-FixedDelay() 方法時,會向 ScheduledThreadPoolExecutor 的 DelayQueue 新增一個實現了 RunnableScheduledFutur 介面的 ScheduledFutureTask
- 執行緒池中的執行緒從 DelayQueue 中獲取 ScheduledFutureTask,然後執行任務

- ScheduledThreadPoolExecutor 為了實現週期性的執行任務,對 ThreadPoolExecutor 做了如下的修改
- 使用 DelayQueue 作為任務佇列
- 獲取任務的方式不同(後文會說明)
- 執行週期任務後,增加了額外的處理(後文會說明)
-
ScheduledThreadPoolExecutor 的實現
- ScheduledFutureTask
- ScheduledThreadPoolExecutor 會把待排程的任務(ScheduledFutureTask)放到一個 DelayQueue 中
- ScheduledFutureTask 主要包含 3 個成員變數
- long 型成員變數 time,表示這個任務將要被執行的具體時間
- long 型成員變數 sequenceNumber,表示這個任務被新增到 ScheduledThreadPoolExecutor 中的序號
- long 型成員變數 period,表示任務執行的間隔週期
- DelayQueue 封裝了一個 PriorityQueue,這個 PriorityQueue 會對佇列中的 ScheduledFutureTask 進行排序。排序時,time 小的排在前面(時間早的任務將被先執行)。如果兩個ScheduledFutureTask 的 time 相同,就比較 sequenceNumber,sequenceNumber 小的排在前面(也就是說,如果兩個任務的執行時間相同,那麼先提交的任務將被先執行)

- 執行流程
- 執行緒 1 從 DelayQueue 中獲取已到期的 ScheduledFutureTask(DelayQueue.take()),到期任務是指 ScheduledFutureTask 的 time 大於等於當前時間
- 執行緒 1 執行這個 ScheduledFutureTask
- 執行緒 1 修改 ScheduledFutureTask 的 time 變數為下次將要被執行的時間
- 執行緒 1 把這個修改 time 之後的 ScheduledFutureTask 放回 DelayQueue 中(DelayQueue.add())
- DelayQueue.take() 方法
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); // 1 try { for (;;) { E first = q.peek(); if (first == null) { available.await(); // 2.1 } else { long delay = first.getDelay(TimeUnit.NANOSECONDS); if (delay > 0) { long tl = available.awaitNanos(delay); // 2.2 } else { E x = q.poll(); // 2.3.1 assert x != null; if (q.size() != 0) available.signalAll(); // 2.3.2 return x; } } } } finally { lock.unlock(); // 3 } } ```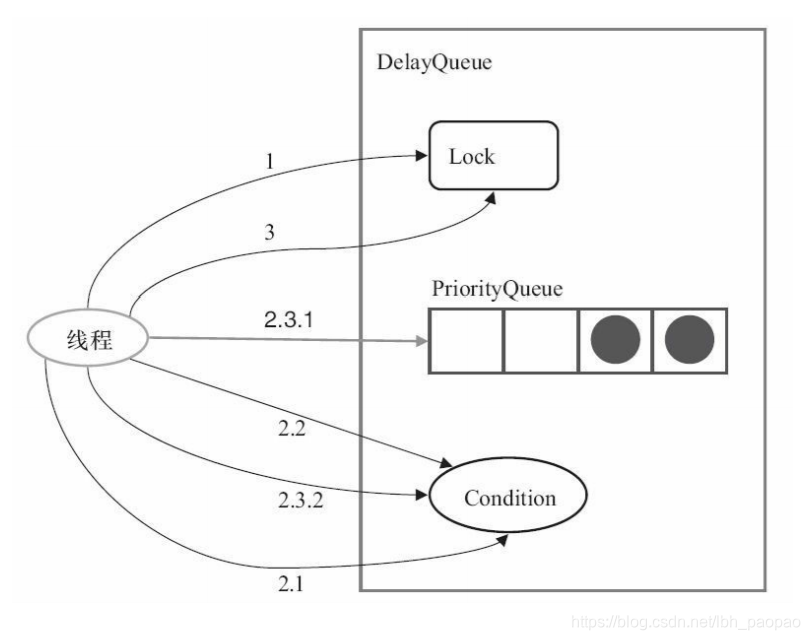 * 執行流程 1. 獲取 Lock 2. 獲取週期任務 * 如果 PriorityQueue 為空,當前執行緒到 Condition 中等待;否則執行下面的2.2 * 如果 PriorityQueue 的頭元素的 time 時間比當前時間大,到 Condition 中等待到 time 時間;否則執行下面的 2.3 * 獲取 PriorityQueue 的頭元素(2.3.1);如果 PriorityQueue 不為空,則喚醒在Condition中等待的所有執行緒(2.3.2) 3 釋放 Lock - DelayQueue.add() 方法
public boolean offer(E e) { final ReentrantLock lock = this.lock; lock.lock(); // 1 try { E first = q.peek(); q.offer(e); // 2.1 if (first == null || e.compareTo(first) < 0) available.signalAll(); // 2.2 return true; } finally { lock.unlock(); // 3 } } ``` * 執行流程 1. 獲取 Lock 2. 新增任務 * 向 PriorityQueue 新增任務 * 如果在上面 2.1 中新增的任務是 PriorityQueue 的頭元素,喚醒在 Condition 中等待的所有執行緒 3. 釋放 Lock
- ScheduledFutureTask
FutureTask詳解
-
FutureTask簡介
- FutureTask 除了實現 Future 介面外,還實現了 Runnable 介面。因此,FutureTask 可以交給 Executor 執行,也可以由呼叫執行緒直接執行(FutureTask.run())
- 根據 FutureTask.run() 方法被執行的時機,FutureTask 可以處於下面 3 種狀態
- 未啟動。FutureTask.run() 方法還沒有被執行之前,FutureTask 處於未啟動狀態。當建立一個 FutureTask,且沒有執行 FutureTask.run() 方法之前,這個 FutureTask 處於未啟動狀態
- 已啟動。FutureTask.run() 方法被執行的過程中,FutureTask 處於已啟動狀態
- 已完成。FutureTask.run() 方法執行完後正常結束,或被取消(FutureTask.cancel(…)),或執行 FutureTask.run() 方法時丟擲異常而異常結束,FutureTask 處於已完成狀態
- 當 FutureTask 處於未啟動或已啟動狀態時,執行 FutureTask.get() 方法將導致呼叫執行緒阻塞;當 FutureTask 處於已完成狀態時,執行 FutureTask.get() 方法將導致呼叫執行緒立即返回結果或丟擲異常
- 當 FutureTask 處於未啟動狀態時,執行 FutureTask.cancel() 方法將導致此任務永遠不會被執行;當 FutureTask 處於已啟動狀態時,執行 FutureTask.cancel(true) 方法將以中斷執行此任務執行緒的方式來試圖停止任務;當 FutureTask 處於已啟動狀態時,執行 FutureTask.cancel(false) 方法將不會對正在執行此任務的執行緒產生影響(讓正在執行的任務執行完成);當FutureTask 處於已完成狀態時,執行FutureTask.cancel(…)方法將返回 false
-
FutureTask的使用
- 可以把 FutureTask 交給 Executor 執行;也可以通過 ExecutorService.submit(…)方法返回一個 FutureTask,然後執行 FutureTask.get() 方法或 FutureTask.cancel(…) 方法。除此以外,還可以單獨使用 FutureTask
- 當一個執行緒需要等待另一個執行緒把某個任務執行完後它才能繼續執行,此時可以使用 FutureTask。假設有多個執行緒執行若干任務,每個任務最多隻能被執行一次。當多個執行緒試圖同時執行同一個任務時,只允許一個執行緒執行任務,其他執行緒需要等待這個任務執行完後才能繼續執行
- 當兩個執行緒試圖同時執行同一個任務時,如果 Thread 1 執行 1.3 後 Thread 2 執行 2.1,那麼接下來 Thread 2 將在 2.2 等待,直到 Thread 1 執行完 1.4 後 Thread 2 才能從 2.2 (FutureTask.get()) 返回
private final ConcurrentMap<Object, Future<String>> taskCache = new ConcurrentHashMap<Object, Future<String>>(); private String executionTask(final String taskName) throws ExecutionException, InterruptedException { while (true) { Future<String> future = taskCache.get(taskName); // 1.1,2.1 if (future == null) { Callable<String> task = new Callable<String>() { public String call() throws InterruptedException { return taskName; } }; // 1.2建立任務 FutureTask<String> futureTask = new FutureTask<String>(task); future = taskCache.putIfAbsent(taskName, futureTask); // 1.3 if (future == null) { future = futureTask; futureTask.run(); // 1.4執行任務 } } try { return future.get(); // 1.5,2.2執行緒在此等待任務執行完成 } catch (CancellationException e) { taskCache.remove(taskName, future); } } }
-
FutureTask的實現
- FutureTask 的實現基於 AbstractQueuedSynchronizer(以下簡稱為AQS)。java.util.concurrent 中的很多可阻塞類(比如ReentrantLock)都是基於 AQS 來實現的。AQS 是一個同步框架,它提供通用機制來原子性管理同步狀態、阻塞和喚醒執行緒,以及維護被阻塞執行緒的佇列。JDK 6 中 AQS 被廣泛使用,基於 AQS 實現的同步器包括:ReentrantLock、Semaphore、ReentrantReadWriteLock、CountDownLatch和FutureTask
- 每一個基於 AQS 實現的同步器都會包含兩種型別的操作
- 至少一個 acquire 操作。這個操作阻塞呼叫執行緒,除非/直到 AQS 的狀態允許這個執行緒繼續執行。FutureTask 的 acquire 操作為 get()/get(long timeout,TimeUnit unit) 方法呼叫
- 至少一個 release 操作。這個操作改變 AQS 的狀態,改變後的狀態可允許一個或多個阻塞執行緒被解除阻塞。FutureTask 的 release 操作包括 run() 方法和 cancel(…) 方法
- 基於“複合優先於繼承”的原則,FutureTask 宣告瞭一個內部私有的繼承於 AQS 的子類 Sync,對 FutureTask 所有公有方法的呼叫都會委託給這個內部子類。AQS 被作為“模板方法模式”的基礎類提供給 FutureTask 的內部子類 Sync,這個內部子類只需要實現狀態檢查和狀態更新的方法即可,這些方法將控制 FutureTask 的獲取和釋放操作。具體來說,Sync 實現了 AQS 的 tryAcquireShared(int) 方法和 tryReleaseShared(int) 方法,Sync 通過這兩個方法來檢查和更新同步狀態

- Sync 是 FutureTask 的內部私有類,它繼承自 AQS。建立 FutureTask 時會建立內部私有的成員物件 Sync,FutureTask 所有的的公有方法都直接委託給了內部私有的 Sync
- FutureTask.get() 方法會呼叫 AQS.acquireSharedInterruptibly(int arg) 方法,這個方法的執行過程如下
- 呼叫 AQS.acquireSharedInterruptibly(int arg) 方法,這個方法首先會回撥在子類 Sync 中實現的 tryAcquireShared() 方法來判斷 acquire 操作是否可以成功。acquire 操作可以成功的條件為:state 為執行完成狀態 RAN 或已取消狀態 CANCELLED,且 runner 不為 null
- 如果成功則 get() 方法立即返回。如果失敗則到執行緒等待佇列中去等待其他執行緒執行 release 操作
- 當其他執行緒執行 release 操作(比如FutureTask.run()或FutureTask.cancel(…)) 喚醒當前執行緒後,當前執行緒再次執行tryAcquireShared()將返回正值1,當前執行緒將離開執行緒等待佇列並喚醒它的後繼執行緒(這裡會產生級聯喚醒的效果,後面會介紹)
- 最後返回計算的結果或丟擲異常
- FutureTask.run()的執行過程如下。
- 執行在建構函式中指定的任務(Callable.call())
- 以原子方式來更新同步狀態(呼叫AQS.compareAndSetState(int expect,in update),設定 state 為執行完成狀態RAN)。如果這個原子操作成功,就設定代表計算結果的變數 result 的值為 Callable.call() 的返回值,然後呼叫 AQS.releaseShared(int arg)
- AQS.releaseShared(int arg) 首先會回撥在子類 Sync 中實現的 tryReleaseShared(arg) 來執行 release 操作(設定執行任務的執行緒runner為null,然會返回true);AQS.releaseShared(int arg),然後喚醒執行緒等待佇列中的第一個執行緒
- 呼叫FutureTask.done()
- 當執行 FutureTask.get() 方法時,如果 FutureTask 不是處於執行完成狀態 RAN 或已取消狀態 CANCELLED,當前執行執行緒將到 AQS 的執行緒等待佇列中等待(見下圖的執行緒A、B、C和D)。當某個執行緒執行 FutureTask.run() 方法或 FutureTask.cancel(…) 方法時,會喚醒執行緒等待佇列的第一個執行緒
- 假設開始時 FutureTask 處於未啟動狀態或已啟動狀態,等待佇列中已經有 3 個執行緒(A、B和C)在等待。此時,執行緒 D 執行 get() 方法將導致執行緒 D 也到等待佇列中去等待。當執行緒 E 執行 run() 方法時,會喚醒佇列中的第一個執行緒 A。執行緒 A 被喚醒後,首先把自己從佇列中刪除,然後喚醒它的後繼執行緒 B,最後執行緒 A 從 get() 方法返回。執行緒 B、C 和 D 重複 A 執行緒的處理流程。最終,在佇列中等待的所有執行緒都被級聯喚醒並從 get() 方法返回
第十一章 Java 併發程式設計實踐
生產者和消費者模式
-
概述
- 在併發程式設計中使用生產者和消費者模式能夠解決絕大多數併發問題
- 生產者和消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而是通過阻塞佇列來進行通訊,所以生產者生產完資料之後不用等待消費者處理,直接扔給阻塞佇列,消費者不找生產者要資料,而是直接從阻塞佇列裡取,阻塞佇列就相當於一個緩衝區,平衡了生產者和消費者的處理能力。這個阻塞佇列就是用來給生產者和消費者解耦的。縱觀大多數設計模式,都會找一個第三者出來進行解耦,如工廠模式的第三者是工廠類,模板模式的第三者是模板類。在學習一些設計模式的過程中,先找到這個模式的第三者,能幫助我們快速熟悉一個設計模式
-
生產者消費者模式實戰
// 修改前 public void extract() { logger.debug("開始" + getExtractorName() + "。。"); // 抽取郵件 List<Article> articles = extractEmail(); // 新增文章 for (Article article : articles) { addArticleOrComment(article); } // 清空郵件 cleanEmail(); logger.debug("完成" + getExtractorName() + "。。"); } // 修改後 public class QuickEmailToWikiExtractor extends AbstractExtractor { private ThreadPoolExecutor threadsPool; private ArticleBlockingQueue<ExchangeEmailShallowDTO> emailQueue; public QuickEmailToWikiExtractor() { emailQueue= new ArticleBlockingQueue<ExchangeEmailShallowDTO>(); int corePoolSize = Runtime.getRuntime().availableProcessors() * 2; threadsPool = new ThreadPoolExecutor(corePoolSize, corePoolSize, 10l, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(2000)); } public void extract() { logger.debug("開始" + getExtractorName() + "。。"); long start = System.currentTimeMillis(); // 抽取所有郵件放到佇列裡 new ExtractEmailTask().start(); // 把佇列裡的文章插入到Wiki insertToWiki(); long end = System.currentTimeMillis(); double cost = (end - start) / 1000; logger.debug("完成" + getExtractorName() + ",花費時間:" + cost + "秒"); } /** * 把佇列裡的文章插入到Wiki */ private void insertToWiki() { // 登入Wiki,每間隔一段時間需要登入一次 confluenceService.login(RuleFactory.USER_NAME, RuleFactory.PASSWORD); while (true) { // 2秒內取不到就退出 ExchangeEmailShallowDTO email = emailQueue.poll(2, TimeUnit.SECONDS); if (email == null) { break; } threadsPool.submit(new insertToWikiTask(email)); } } protected List<Article> extractEmail() { List<ExchangeEmailShallowDTO> allEmails = getEmailService().queryAllEmails(); if (allEmails == null) { return null; } for (ExchangeEmailShallowDTO exchangeEmailShallowDTO : allEmails) { emailQueue.offer(exchangeEmailShallowDTO); } return null; } /** * 抽取郵件任務 * * @author tengfei.fangtf */ public class ExtractEmailTask extends Thread { public void run() { extractEmail(); } } }- 程式碼的執行邏輯是,生產者啟動一個執行緒把所有郵件全部抽取到佇列中,消費者啟動 CPU*2 個執行緒數處理郵件,從之前的單執行緒處理郵件變成了現在的多執行緒處理,並且抽取郵件的執行緒不需要等處理郵件的執行緒處理完再抽取新郵件,所以使用了生產者和消費者模式後,郵件的整體處理速度比以前要快了幾倍
-
多生產者和多消費者場景

/** * 總訊息佇列管理 * * @author tengfei.fangtf */ public class MsgQueueManager implements IMsgQueue{ private static final Logger LOGGER = LoggerFactory.getLogger(MsgQueueManager.class); /** * 訊息總佇列 */ public final BlockingQueue<Message> messageQueue; private MsgQueueManager() { messageQueue = new LinkedTransferQueue<Message>(); } public void put(Message msg) { try { messageQueue.put(msg); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } public Message take() { try { return messageQueue.take(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } return null; } } /** * 分發訊息,負責把訊息從大佇列塞到小佇列裡 * * @author tengfei.fangtf */ static class DispatchMessageTask implements Runnable { @Override public void run() { BlockingQueue<Message> subQueue; for (;;) { // 如果沒有資料,則阻塞在這裡 Message msg = MsgQueueFactory.getMessageQueue().take(); // 如果為空,則表示沒有Session機器連線上來, // 需要等待,直到有Session機器連線上來 while ((subQueue = getInstance().getSubQueue()) == null) { try { Thread.sleep(1000); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } // 把訊息放到小佇列裡 try { subQueue.put(msg); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } } } /** * 均衡獲取一個子佇列。 * * @return */ public BlockingQueue<Message> getSubQueue() { int errorCount = 0; for (;;) { if (subMsgQueues.isEmpty()) { return null; } int index = (int) (System.nanoTime() % subMsgQueues.size()); try { return subMsgQueues.get(index); } catch (Exception e) { // 出現錯誤表示,在獲取佇列大小之後,佇列進行了一次刪除操作 LOGGER.error("獲取子佇列出現錯誤", e); if ((++errorCount) < 3) { continue; } } } } // 往訊息佇列裡新增一條訊息 // 使用 IMsgQueue messageQueue = MsgQueueFactory.getMessageQueue(); Packet msg = Packet.createPacket(Packet64FrameType. TYPE_DATA, "{}".getBytes(), (short) 1); messageQueue.put(msg); -
執行緒池與生產消費者模式
- Java中的執行緒池類其實就是一種生產者和消費者模式的實現方式,但是我覺得其實現方式更加高明。生產者把任務丟給執行緒池,執行緒池建立執行緒並處理任務,如果將要執行的任務數大於執行緒池的基本執行緒數就把任務扔到阻塞佇列裡,這種做法比只使用一個阻塞佇列來實現生產者和消費者模式顯然要高明很多,因為消費者能夠處理直接就處理掉了,這樣速度更快,而生產者先存,消費者再取這種方式顯然慢一些
線上問題定位
- 查詢程式
- top 命令檢視程式佔用資源情況
- 查詢執行緒
- 使用 top -H -p <pid> 檢視執行緒佔用情況
- 查詢 java 的堆疊資訊
- 使用 printf %x <pid> 將執行緒 id 轉換成十六進位制
- 然後再使用 jstack 查詢執行緒的堆疊資訊
- 語法:jstack | grep -a 執行緒id(十六進位制)
- 這樣就找出了有問題的程式碼了。剩下的就是分析原因和修改程式碼了
效能測試
-
檢視網路流量
cat /proc/net/dev -
檢視系統平均負載
cat /proc/loadavg -
檢視系統記憶體情況
cat /proc/meminfo -
檢視CPU的利用率
cat /proc/stat
非同步任務池
- Java 中的執行緒池設計
- Java 中的執行緒池設計得非常巧妙,可以高效併發執行多個任務,但是在某些場景下需要對執行緒池進行擴充套件才能更好地服務於系統。例如,如果一個任務仍進執行緒池之後,執行執行緒池的程式重啟了,那麼執行緒池裡的任務就會丟失。另外,執行緒池只能處理本機的任務,在叢集環境下不能有效地排程所有機器的任務
- 任務池的主要處理流程
- 每臺機器會啟動一個任務池,每個任務池裡有多個執行緒池,當某臺機器將一個任務交給任務池後,任務池會先將這個任務儲存到資料中,然後某臺機器上的任務池會從資料庫中獲取待執行的任務,再執行這個任務
- 任務狀態
- 每個任務有幾種狀態,分別是建立(NEW)、執行中(EXECUTING)、RETRY(重試)、掛起(SUSPEND)、中止(TEMINER)和執行完成(FINISH)
- 建立:提交給任務池之後的狀態
- 執行中:任務池從資料庫中拿到任務執行時的狀態
- 重試:當執行任務時出現錯誤,程式顯式地告訴任務池這個任務需要重試,並設定下一次執行時間
- 掛起:當一個任務的執行依賴於其他任務完成時,可以將這個任務掛起,當收到訊息後,再開始執行
- 中止:任務執行失敗,讓任務池停止執行這個任務,並設定錯誤訊息告訴呼叫端
- 執行完成:任務執行結束
- 每個任務有幾種狀態,分別是建立(NEW)、執行中(EXECUTING)、RETRY(重試)、掛起(SUSPEND)、中止(TEMINER)和執行完成(FINISH)
- 任務池的任務隔離
- 非同步任務有很多種型別,比如抓取網頁任務、同步資料任務等,不同型別的任務優先順序不一樣,但是系統資源是有限的,如果低優先順序的任務非常多,高優先順序的任務就可能得不到執行,所以必須對任務進行隔離執行。使用不同的執行緒池處理不同的任務,或者不同的執行緒池處理不同優先順序的任務,如果任務型別非常少,建議用任務型別來隔離,如果任務型別非常多,比如幾十個,建議採用優先順序的方式來隔離
- 任務池的重試策略
- 根據不同的任務型別設定不同的重試策略,有的任務對實時性要求高,那麼每次的重試間隔就會非常短,如果對實時性要求不高,可以採用預設的重試策略,重試間隔隨著次數的增加,時間不斷增長,比如間隔幾秒、幾分鐘到幾小時。每個任務型別可以設定執行該任務型別執行緒池的最小和最大執行緒數、最大重試次數
- 使用任務池的注意事項
- 任務必須無狀態:任務不能在執行任務的機器中儲存資料,比如某個任務是處理上傳的檔案,任務的屬性裡有檔案的上傳路徑,如果檔案上傳到機器1,機器2獲取到了任務則會處理失敗,所以上傳的檔案必須存在其他的叢集裡,比如 OSS 或 SFTP
- 非同步任務的屬性
- 包括任務名稱、下次執行時間、已執行次數、任務型別、任務優先順序和執行時的報錯資訊(用於快速定位問題)
參考
免責宣告:本文僅用於個人學習、交流,非商業用途;版權均屬於原出品公司及原作者!
免責宣告:本文禁止轉載!
個人建議買本正版書,這是本值得反覆翻看反覆學習的書
相關文章
- 【Java併發程式設計的藝術】第二章讀書筆記之原子操作Java程式設計筆記
- Java 併發程式設計實踐 讀書筆記四Java程式設計筆記
- CSAPP 併發程式設計讀書筆記APP程式設計筆記
- 《JavaScript Dom程式設計藝術》讀書筆記(一)JavaScript程式設計筆記
- Java併發程式設計的藝術,解讀併發程式設計的優缺點Java程式設計
- Java併發程式設計藝術Java程式設計
- 《java併發程式設計的藝術》記憶體模型Java程式設計記憶體模型
- 《java併發程式設計的藝術》併發工具類Java程式設計
- JavaScript DOM 程式設計藝術(第2版) 讀書筆記JavaScript程式設計筆記
- 如何評價《Java 併發程式設計藝術》這本書?Java程式設計
- 《java併發程式設計的藝術》Executor框架Java程式設計框架
- 《java併發程式設計的藝術》併發容器和框架Java程式設計框架
- 《java併發程式設計的藝術》原子操作類Java程式設計
- Java併發程式設計的藝術(五)——中斷Java程式設計
- 《java併發程式設計的藝術》併發底層實現原理Java程式設計
- 《Java程式設計思想》讀書筆記一Java程式設計筆記
- 讀書筆記-Java程式設計思想-03筆記Java程式設計
- 《java併發程式設計的藝術》執行緒池Java程式設計執行緒
- Java併發程式設計藝術第二章-----第二遍讀後記錄Java程式設計
- 《Go 語言程式設計》讀書筆記 (六) 基於共享變數的併發Go程式設計筆記變數
- JavaScript DOM程式設計藝術筆記1JavaScript程式設計筆記
- go併發程式設計筆記Go程式設計筆記
- 《JavaScript程式設計精解》--讀書筆記JavaScript程式設計筆記
- 反應式程式設計讀書筆記程式設計筆記
- 《程式設計師的自我修養》-讀書筆記程式設計師筆記
- Java併發程式設計筆記6:執行緒池的使用Java程式設計筆記執行緒
- 深入理解併發程式設計藝術之計算機記憶體模型程式設計計算機記憶體模型
- JavaScript DOM 程式設計藝術 學習筆記01JavaScript程式設計筆記
- JavaScript DOM 程式設計藝術 學習筆記 02JavaScript程式設計筆記
- 《Javacript DOM 程式設計藝術》筆記(一)JavaScript Syntax程式設計筆記JavaScript
- Java併發程式設計-讀寫鎖(ReentrantReadWriteLock)Java程式設計
- python高階程式設計讀書筆記(一)Python程式設計筆記
- C#高階程式設計 讀書筆記C#程式設計筆記
- 《程式設計師自我修養》讀書筆記程式設計師筆記
- 《程式設計師修煉之道》讀書筆記程式設計師筆記
- Java併發程式設計學習筆記----執行緒池Java程式設計筆記執行緒
- 《重構:改善既有程式碼的設計》讀書筆記筆記
- 《重構-改善既有程式碼的設計》讀書筆記筆記