Burpsuite中protobuf資料流的解析
Author:[email protected]
0x00 前言
對於protobuf over-HTTP的資料互動方式Burpsuite不能正確的解析其中的資料結構,需要Burpsuite擴充套件才能解析,筆者使用mwielgoszewski的burp-protobuf-decoder擴充套件實踐了protobuf資料流的解析,供有需要的同學學習交流。筆者實踐使用的環境: burpsuite+python2.7+protobuf2.5.0。
0x01 安裝burp-protobuf-decoder擴充套件
burp-protobuf-decoder擴充套件是基於protobuf庫(2.5.x版本)開發的burpsuite python擴充套件,可用於解析、篡改 request/response中protobuf資料流。從https://github.com/mwielgoszewski/burp-protobuf-decoder下載該擴充套件原始碼,然後解壓。
該擴充套件是基於protobuf和jython實現的。先下載protobuf 2.5.0原始碼進行編譯,編譯方法請參考其README.txt檔案。需求在burpsuite的Extender中配置Jython的路徑:

Burpsuite中新增擴充套件:
在Burpsuite的Extender視窗中點選“Add”按鈕,彈出的“Load Burp Extension”視窗中選擇如下資訊:
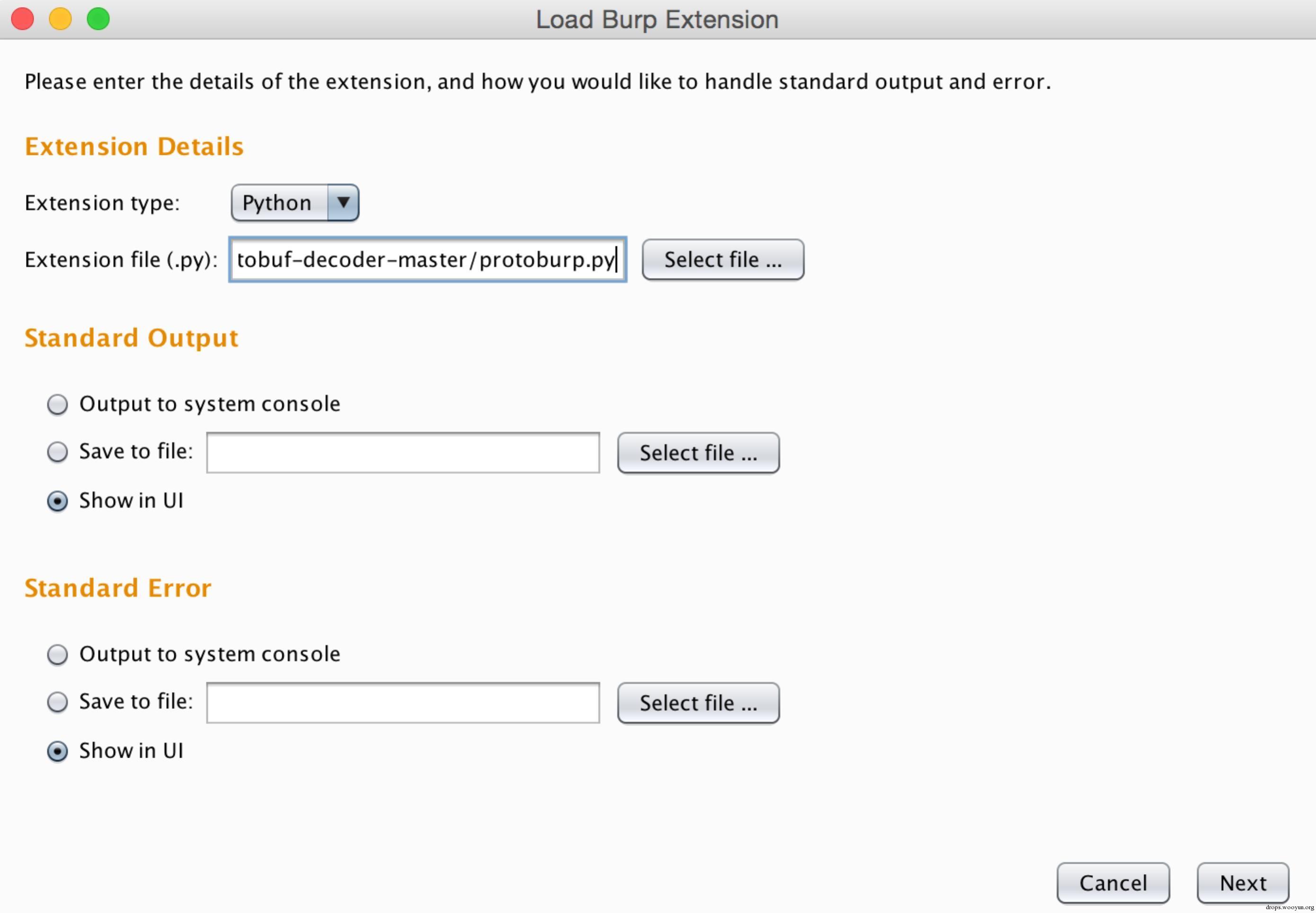
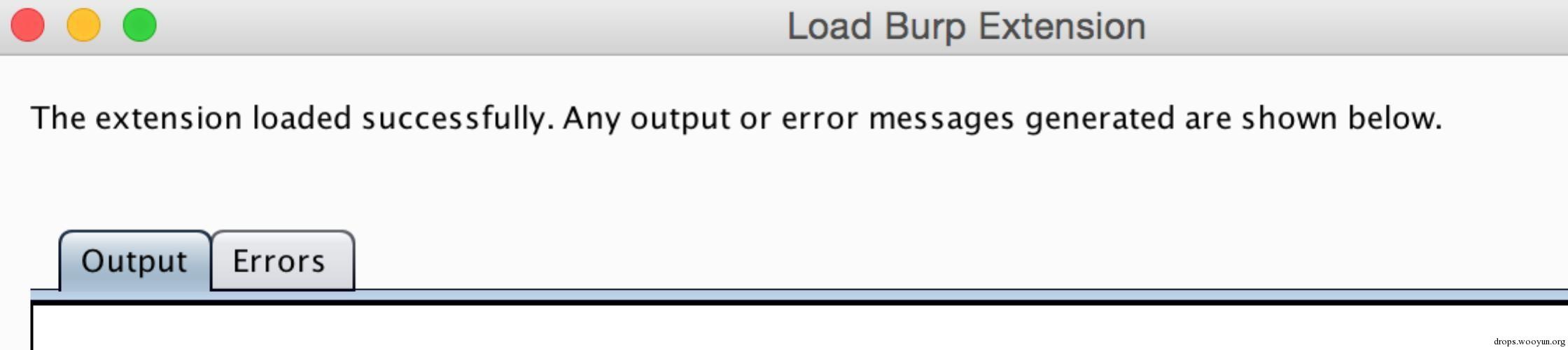
然後Next,當看到如下資訊時表示擴充套件載入成功:
Tips:
載入擴充套件時提示
“Error calling protoc: Cannot run program "protoc" (in directory "******"): error=2, No such file or directory”錯誤解決辦法:修改protoburp.py中呼叫protoc命令的路徑,有多處,如:
將
process = subprocess.Popen(['protoc', '--version']中'protoc'改為'/home/name/protobuf/src/protoc'。載入擴充套件碰到
cannot import name symbol_database錯誤可能是你使用的protoc與擴充套件所使用protobuf python庫版本不一致原因,一種解決辦法是下載protobuf 2.5.0原始碼編譯後,修改protoburp.py中對應的路徑,再載入擴充套件。
擴充套件載入成功了,但不能解析protobuf資料流
該擴充套件透過判斷頭部“content-type”是否為“
'application/x-protobuf'”來決定是否解析資料,你可以修改protoburp.py中的isEnabled()方法讓其工作。
0x02 protobuf簡介
protobuf是Google開源的一個跨平臺的結構化資料儲存格式。可用於通訊協議、資料儲存等領域的語言無關、平臺無關、可擴充套件的序列化結構資料格式。
protobuf透過定義“.proto”檔案來描述資料的結構。.proto檔案中用 “Message”來表示所需要序列化的資料的格式。Message由Field組成,Field類似Java或C++中成員變數,通常一個Field的定義包含修飾符、型別、名稱和ID。下面看一個簡單的.proto檔案的例子:
#!cpp
syntax = "proto2";
package tutorial;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
使用下面的python程式碼生成二進位制資料流:
#!python
import addressbook_pb2
address_book = addressbook_pb2.AddressBook()
person = address_book.person.add()
person.id = 9
person.name = 'Vincent'
person.email = [email protected]'
phone = person.phone.add()
phone.number = '15011111111'
phone.type = 2
f = open('testAb', "wb")
f.write(address_book.SerializeToString())
f.close()
序列化後的二進位制資料流如下:

有關Protobuf的語法網上已有很多文章了,你可以網上搜尋或參考其官網說明。
2.1Varint編碼
Protobuf的二進位制使用Varint編碼。Varint 是一種緊湊的表示數字的方法。它用一個或多個位元組來表示一個數字,值越小的數字使用越少的位元組數。這能減少用來表示數字的位元組數。
Varint 中的每個 byte 的最高位 bit 有特殊的含義,如果該位為 1,表示後續的 byte 也是該數字的一部分,如果該位為 0,則結束。其他的 7 個 bit 都用來表示數字。因此小於 128 的數字都可以用一個 byte 表示。大於 128 的數字,比如 300,會用兩個位元組來表示:1010 1100 0000 0010。
下圖演示了protobuf如何解析兩個 bytes。注意到最終計算前將兩個 byte 的位置相互交換過一次,這是因為protobuf 位元組序採用 little-endian 的方式。
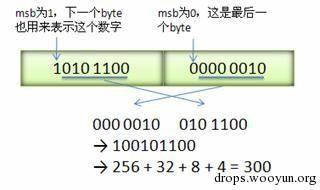 (圖片來自網路)
(圖片來自網路)
2.2數值型別
Protobuf經序列化後以二進位制資料流形式儲存,這個資料流是一系列key-Value對。Key用來標識具體的Field,在解包的時候,Protobuf根據 Key 就可以知道相應的 Value 應該對應於訊息中的哪一個 Field。
Key 的定義如下:
(field_number << 3) | wire_type
Key由兩部分組成。第一部分是 field_number,比如訊息 tutorial .Person中 field name 的 field_number 為 1。第二部分為 wire_type。表示 Value 的傳輸型別。Wire Type 可能的型別如下表所示:
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimi | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | Groups (deprecated) |
| 4 | End group | Groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
以資料流:08 96 01為例分析計算key-value的值:
#!bash
08 = 0000 1000b
=> 000 1000b(去掉最高位)
=> field_num = 0001b(中間4位), type = 000(後3位)
=> field_num = 1, type = 0(即Varint)
96 01 = 1001 0110 0000 0001b
=> 001 0110 0000 0001b(去掉最高位)
=> 1 001 0110b(因為是little-endian)
=> 128+16+4+2=150
最後得到的結構化資料為:
1:150
其中1表示為field_num,150為value。
2.3手動反序列化

以上面例子中序列化後的二進位制資料流進行反序列化分析:
#!bash
0A = 0000 1010b => field_num=1, type=2;
2E = 0010 1110b => value=46;
0A = 0000 1010b => field_num=1, type=2;
07 = 0000 0111b => value=7;
讀取7個字元“Vincent”;
#!bash
10 = 0001 0000 => field_num=2, type=0;
09 = 0000 1001 => value=9;
1A = 0001 1010 => field_num=3, type=2;
10 = 0001 0000 => value=16;
#!bash
22 = 0010 0010 => field_num=4, type=2;
0F = 0000 1111 => value=15;
0A = 0000 1010 => field_num=1, type=2;
0B = 0000 1011 => value=11;
讀取11個字元“15011111111”;
#!bash
10 = 0001 0000 => field_num=2, type=0;
02 = 0000 0010 => value=2;
最後得到的結構化資料為:
#!bash
1 {
1: "Vincent"
2: 9
3: "[email protected]"
4 {
1: "15011111111"
2: 2
}
}
2.4使用protoc反序列化
實現操作經常碰到較複雜、較長的流資料,手動分析確實麻煩,好在protoc加“decode_raw”引數可以解流資料,我實現了一個python指令碼供使用:
#!python
def decode(data):
process = subprocess.Popen(['/usr/local/bin/protoc', '--decode_raw'],
stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
output = error = None
try:
output, error = process.communicate(data)
except OSError:
pass
finally:
if process.poll() != 0:
process.wait()
return output
f = open(sys.argv[1], "rb")
data = f.read()
print 'data:\n',decode(data)
f.close()
使用python decode.py <proto.bin>即可反序列化,其中proto.bin為protobuf二進位制資料流檔案。得到結構化的資料後我們可以逐步分析,猜測每個Field的名稱,輔助協議、資料結構等逆向分析。
0x03 burpsuite+protobuf實戰
用webpy模擬protobuf over-HTTP的web app。
服務端overHttp_server.py內容如下:
#!python
#!/usr/bin/env python
#coding: utf8
#author: Vincent
import web
import time
import os
urls = (
"/", "default",
)
app = web.application(urls, globals())
class default:
def GET(self):
return 'hello world.'
def POST(self):
reqdata = web.data()
print 'client request:'+reqdata
resdata = reqdata.split(':')[-1]
web.header('Content-type', 'application/x-protobuf')
return resdata
if __name__ == "__main__":
app.run()
客戶端overHttp_client.py內容如下:
#!python
#!/usr/bin/env python
#coding: utf8
#author: Vincent
import urllib
import urllib2
import json
import addressbook_pb2
import sys
proxy = 'http://<ip>:8888'
target = "http://<ip>:8080/"
enable_proxy = True
proxy_handler = urllib2.ProxyHandler({"http" : proxy})
null_proxy_handler = urllib2.ProxyHandler({})
if enable_proxy:
opener = urllib2.build_opener(proxy_handler)
else:
opener = urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
def doPostReq():
url = target
address_book = addressbook_pb2.AddressBook()
f = open('testAb', "rb")
address_book.ParseFromString(f.read())
ad_serial = address_book.SerializeToString()
f.close()
data = ad_serial
opener = urllib2.build_opener(proxy_handler, urllib2.HTTPCookieProcessor())
req = urllib2.Request(url, data, headers={'Content-Type': 'application/x-protobuf'})
response = opener.open(req)
return response.read()
resp = doPostReq()
print 'response:',resp
3.1proto檔案逆向分析
啟動服務端:python overHttp_server.py <ip>:8080
客戶端請求:python overHttp_client.py
此時burp中已解析出protobuf資料,如下圖:
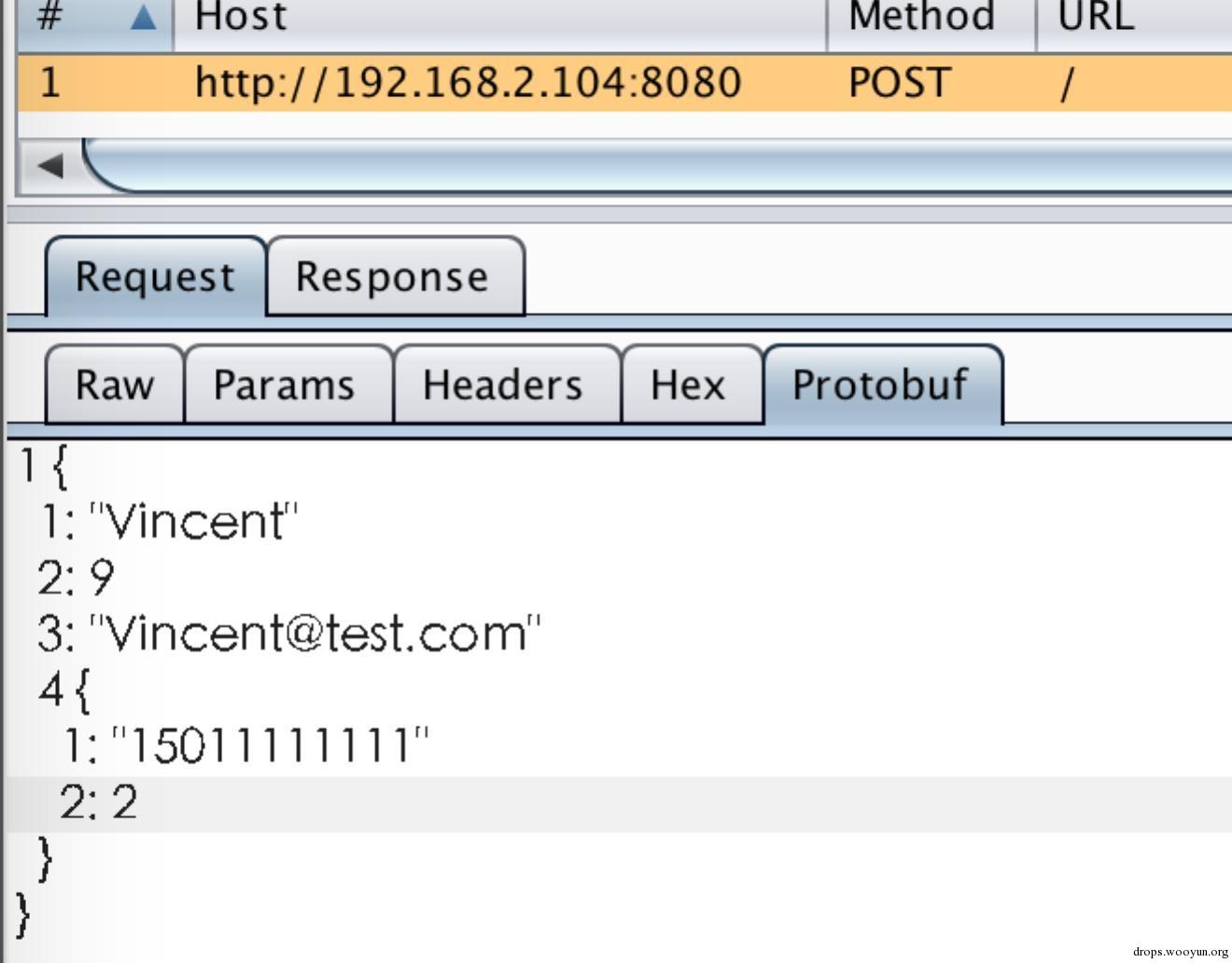
但是這個結構的可讀性還是比較差,我們可以透過逆向分析逐步猜測欄位名稱、型別,然後再解析,方便實現協議的逆向、安全測試等。
對這個結構我們可以還原成以下proto檔案:
#!cpp
syntax = "proto2";
package reversed.proto1;
message Msg {
optional string _name = 1;
optional int32 field2 = 2;
optional string _email = 3;
message subMsg1 {
required string _phone = 1;
optional int32 sub1_field2 = 2;
}
repeated subMsg1 field4 = 4;
}
message Root {
repeated Msg msg = 1;
}
然後使用右鍵的“Load .proto”載入該檔案:
再看解析結果:
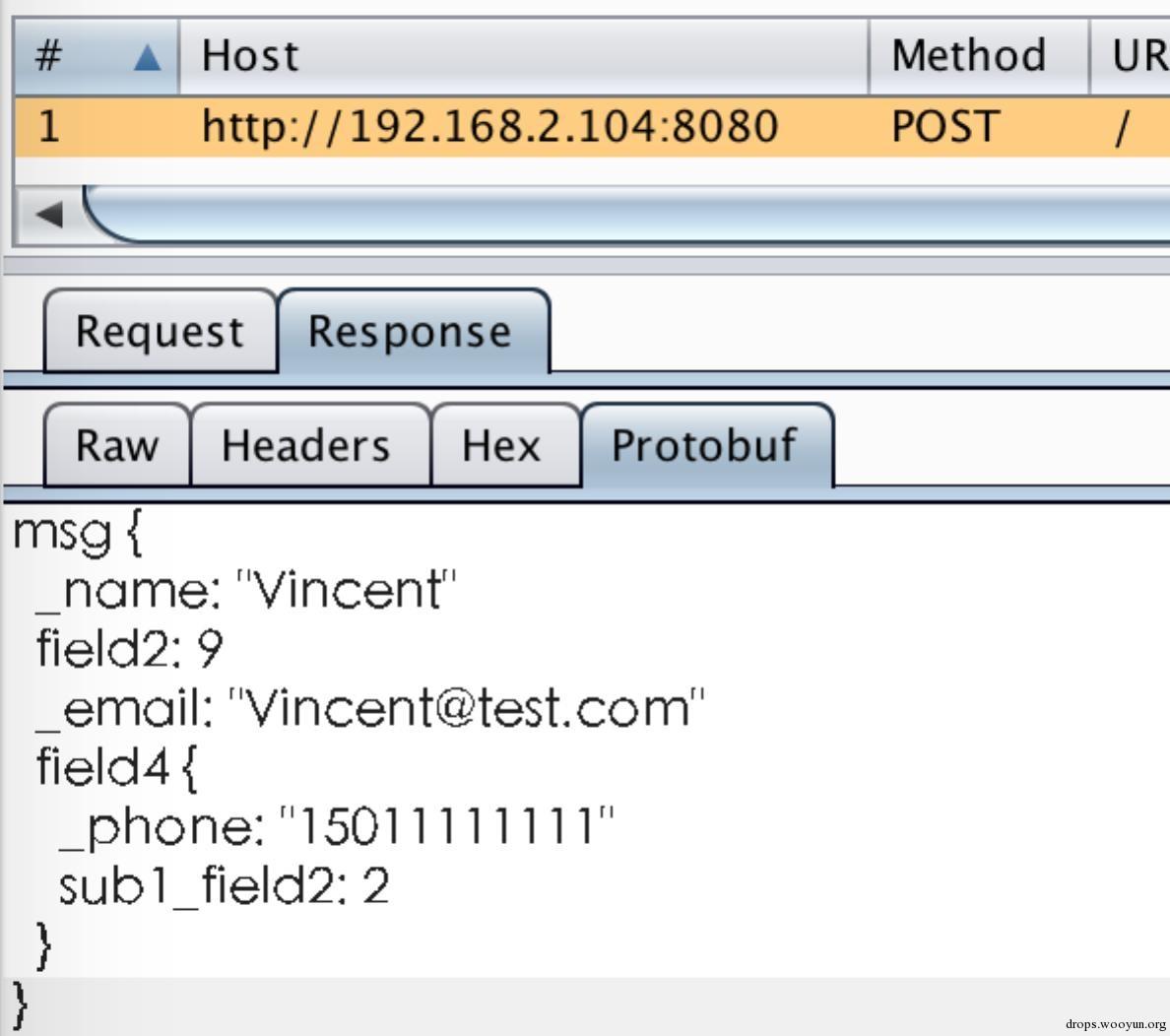
3.2資料篡改
開啟request攔截:

執行python overHttp_client.py傳送請求。攔截到request後,把sub1_field2改為999。
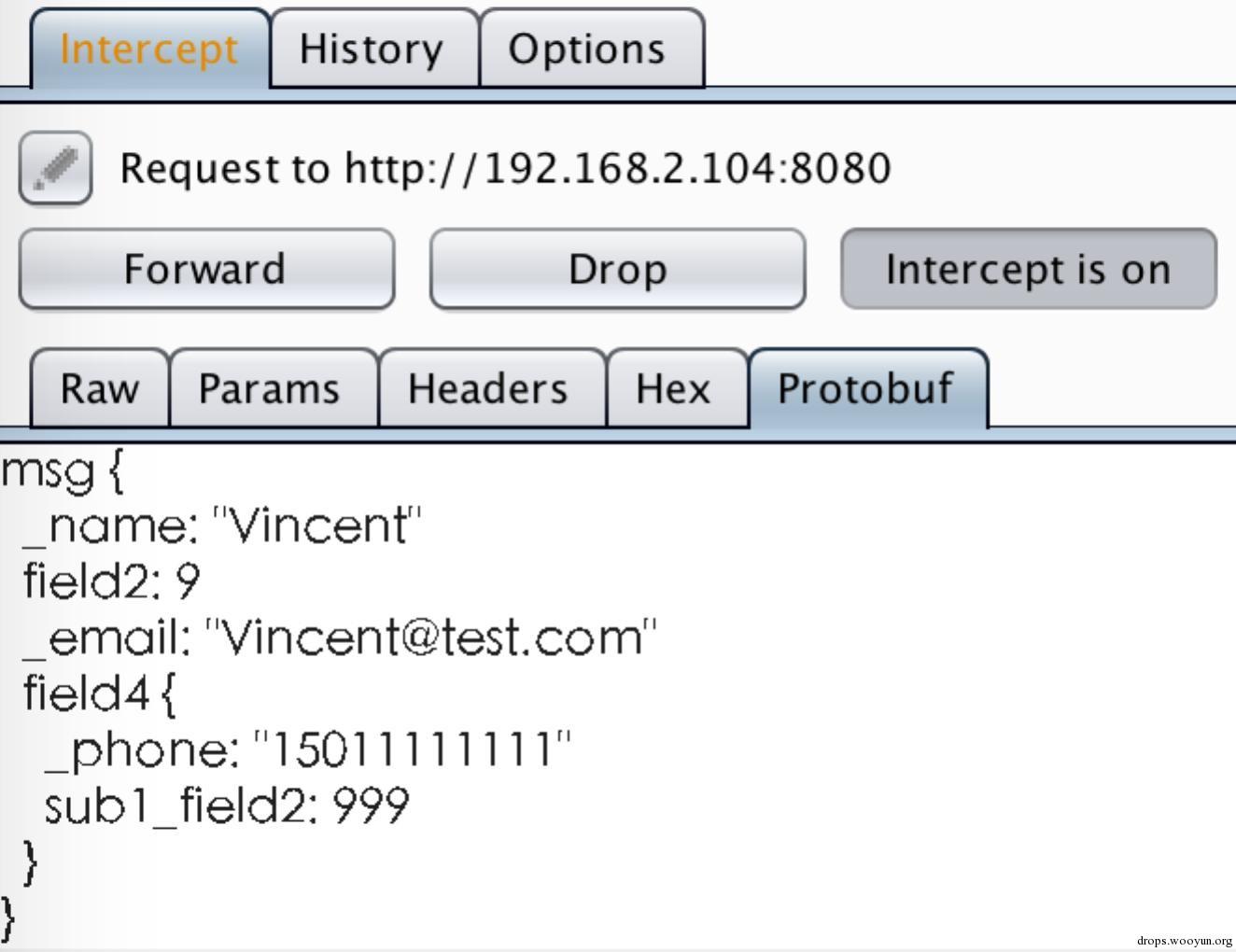
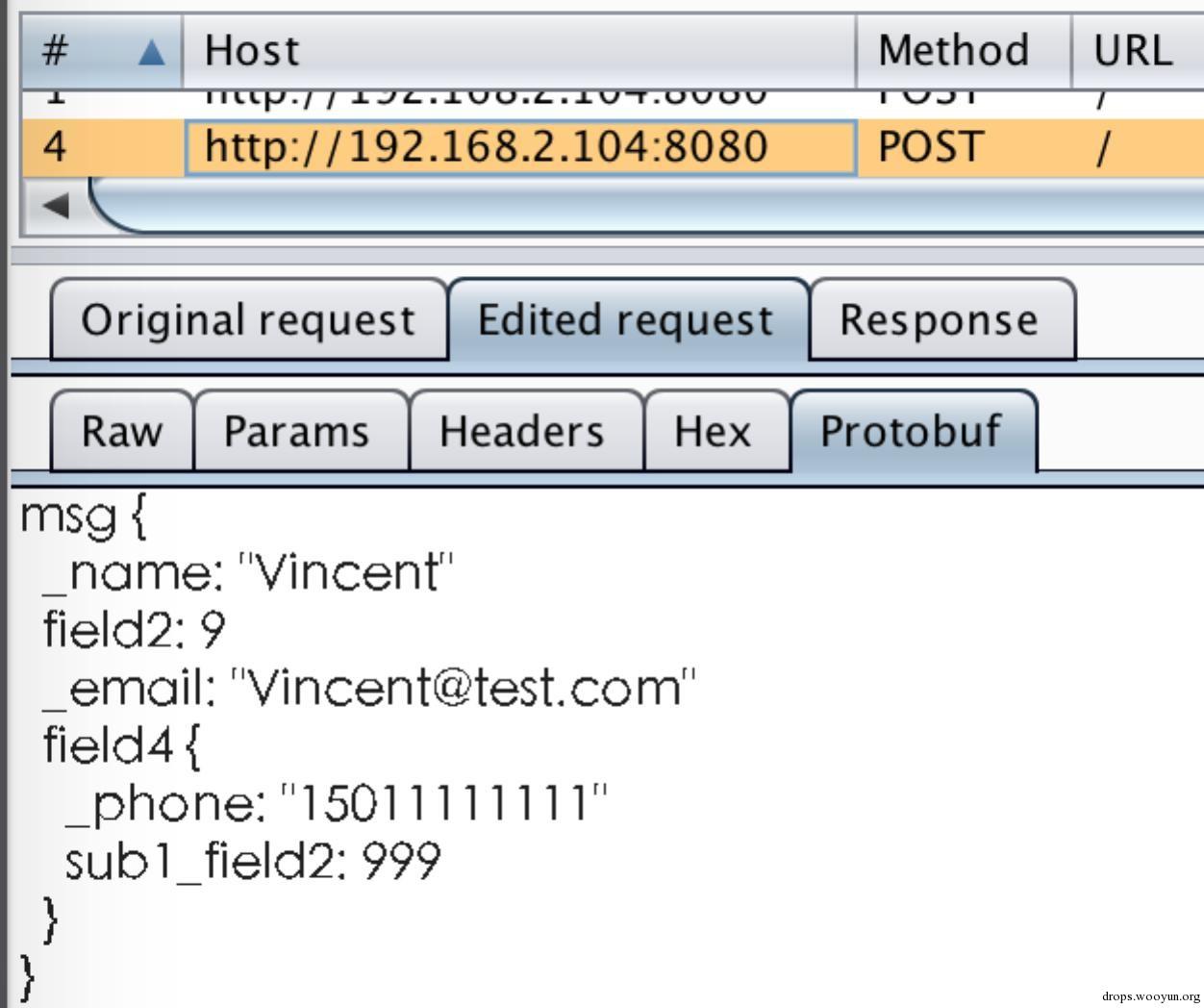
“Forward”後看request資料,已被篡改:
0x04 參考
- 【1】https://github.com/mwielgoszewski/burp-protobuf-decoder
- 【2】https://github.com/google/protobuf/tree/v2.5.0
- 【3】https://wiki.python.org/jython/InstallationInstructions
- 【4】https://developers.google.com/protocol-buffers/docs/proto
- 【5】https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/
- 【6】https://developers.google.com/protocol-buffers/docs/overview
- 【7】http://www.tssci-security.com/archives/2013/05/30/decoding-and-tampering-protobuf-serialized-messages-in-burp/
相關文章
- 資料流中的中位數2020-11-26
- AMF解析遇上XXE,BurpSuite也躺槍2020-08-19UI
- 1202-資料流中的中位數2024-12-02
- JZ-063-資料流中的中位數2022-02-24
- 求資料流中的中位數問題2022-07-14
- 高效的資料壓縮編碼方式 Protobuf2018-05-31
- Protobuf: 高效資料傳輸的秘密武器2023-05-11
- java流的中間操作原始碼解析2018-10-11Java原始碼
- Python中解析json資料2018-08-30PythonJSON
- 如何使用 Protobuf 做資料交換2019-11-22
- 大資料:protobuf是啥玩意兒2019-05-11大資料
- golang讀取檔案的json資料流,並解析到struct,儲存到資料庫2020-10-15GolangJSONStruct資料庫
- 解密Protobuf:高效資料傳輸的秘密武器2024-08-18解密
- gin框架,讀取檔案的json資料流,並解析到struct,儲存到資料庫2020-10-15框架JSONStruct資料庫
- goim 中的 data flow 資料流轉及思考2019-05-07Go
- Protobuf協議逆向解析-APP爬蟲2018-03-04協議APP爬蟲
- 詳解通訊資料協議ProtoBuf2018-03-07協議
- 前後端資料互動利器--Protobuf2021-08-01後端
- Android ListView中複雜資料流的高效渲染(一)2019-02-26AndroidView
- Spring Cloud資料流中的組合函式支援2019-01-21SpringCloud函式
- Spark拉取Kafka的流資料,轉插入HBase中2018-05-07SparkKafka
- ServletRequest一旦讀取了流,流就關閉了,流中的資料一旦被消費就不能再次從流中讀取了,Servlet 是如何還能夠從ServletRequest流中讀取資料的2024-10-28Servlet
- 高效的序列化/反序列化資料方式 Protobuf2018-05-31
- 解析大資料:從流資料攝取到互動式視覺化的完整生態系統2024-03-12大資料視覺化
- 讓資料流動起來,RocketMQ Connect 技術架構解析2022-11-14MQ架構
- Android kotlin中配置protobuf2018-11-18AndroidKotlin
- Protobuf在Cmake中的正確使用2021-03-08
- burpsuite好用的外掛2024-11-30UI
- php資料流中第K大元素的計算方法2021-09-11PHP
- [java]利用IO流中的位元組流和緩衝流寫一個複製資料夾的小程式2019-03-05Java
- 解析機器學習中的資料漂移問題2023-02-06機器學習
- 從rosbag 中解析出圖片資料2020-10-15ROS
- BurpSuite在非Web應用測試中的應用2020-08-19UIWeb
- 資料解析2018-04-08
- 資料流圖 和 資料字典2020-05-25
- Java 中的資料流和函數語言程式設計2020-02-06Java函數程式設計
- 隱私AI框架中的資料流動與工程實現2020-11-12AI框架
- 工作流中的資料持久化詳解!Activiti框架中JPA的使用分析2021-06-08持久化框架