Redis
REmote DIctionary Server(Redis) 是一個由Salvatore Sanfilippo寫的key-value儲存系統。
Redis是一個開源的使用ANSI C語言編寫、遵守BSD協議、支援網路、可基於記憶體亦可持久化的日誌型、Key-Value資料庫,並提供多種語言的API。
它通常被稱為資料結構伺服器,因為值(value)可以是 字串(String), 雜湊(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等型別。
NoSQL
Redis:nosql(非關係型資料庫)。
NoSQL演變史參考:https://www.cnblogs.com/lukelook/p/11135209.html
NoSQL 概述
NoSQL(NoSQL = Not Only SQL ),意即“不僅僅是SQL”,
泛指非關係型的資料庫。隨著網際網路web2.0網站的興起,傳統的關聯式資料庫在應付web2.0網站,特別是超大規模和高併發的SNS型別的web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關係型的資料庫則由於其本身的特點得到了非常迅速的發展。NoSQL資料庫的產生就是為了解決大規模資料集合多重資料種類帶來的挑戰,尤其是大資料應用難題,包括超大規模資料的儲存。
(例如谷歌或Facebook每天為他們的使用者收集萬億位元的資料)。這些型別的資料儲存不需要固定的模式,無需多餘操作就可以橫向擴充套件。
MySQL的擴充套件性瓶頸:MySQL資料庫也經常儲存一些大文字欄位,導致資料庫表非常的大,在做資料庫恢復的時候就導致非常的慢,不容易快速恢復資料庫。比如1000萬4KB大小的文字就接近40GB的大小,如果能把這些資料從MySQL省去,MySQL將變得非常的小。關聯式資料庫很強大,但是它並不能很好的應付所有的應用場景。MySQL的擴充套件性差(需要複雜的技術來實現),大資料下IO壓力大,表結構更改困難,正是當前使用MySQL的開發人員面臨的問題。
NoSQL代表:MongDB、 Redis、Memcache
NoSQL特點:解耦!
-
方便擴充(資料之間沒有關係,很好擴充!)
-
大資料量高效能(redis一秒讀11完次,一秒寫8完次,NoSQL是快取記錄級。是一種細粒度的快取,效能比較高)
-
資料型別是多樣的(不需要實現設計資料庫,隨取隨用)
-
傳統的RDBMS和NoSQL
傳統的RDBMS -結構化組織 -SQL -資料和關係都存在單獨的表中 -運算元據,資料定義語言 -嚴格的一致性 -...NoSQL -不僅僅是資料 -沒有固定的查詢語言 -鍵值對儲存,列儲存,文件儲存,圖資料庫 -最終一致性 -CAP定理和BASE理論(異地多活) -高效能,高可用,高擴充套件 -...
NoSQL的四大分類
KV鍵值對:
- 新浪:Redis
- 美團:Redis+Tair
- 阿里,百度:Redis + memcache
文件型資料庫(bson格式 和json一樣):
- MongoDB
- MongoDB是一個基於分散式檔案儲存的資料庫,C++編寫,主要用於處理大量的文件。
- MongoDB是一個基於關係型資料庫和非關係型資料庫中間的產品。MongoDB是非關係型資料庫中最豐富,最像關係型資料庫的。
- ConthDB
列儲存資料庫
- HBase
- 分散式檔案系統
圖關聯式資料庫
- 放的是關係,不是圖,比如朋友圈社交網路
- Neo4j,infoGrid
| 分類 | Examples舉例 | 典型應用場景 | 資料模型 | 優點 | 缺點 |
|---|---|---|---|---|---|
| 鍵值(key-value)[3] | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 內容快取,主要用於處理大量資料的高訪問負載,也用於一些日誌系統等等。[3] | Key 指向 Value 的鍵值對,通常用hash table來實現[3] | 查詢速度快 | 資料無結構化,通常只被當作字串或者二進位制資料[3] |
| 列儲存資料庫[3] | Cassandra, HBase, Riak | 分散式的檔案系統 | 以列簇式儲存,將同一列資料存在一起 | 查詢速度快,可擴充套件性強,更容易進行分散式擴充套件 | 功能相對侷限 |
| 文件型資料庫[3] | CouchDB, MongoDb | Web應用(與Key-Value類似,Value是結構化的,不同的是資料庫能夠了解Value的內容) | Key-Value對應的鍵值對,Value為結構化資料 | 資料結構要求不嚴格,表結構可變,不需要像關係型資料庫一樣需要預先定義表結構 | 查詢效能不高,而且缺乏統一的查詢語法。 |
| 圖形(Graph)資料庫[3] | Neo4J, InfoGrid, Infinite Graph | 社交網路,推薦系統等。專注於構建關係圖譜 | 圖結構 | 利用圖結構相關演算法。比如最短路徑定址,N度關係查詢等 | 很多時候需要對整個圖做計算才能得出需要的資訊,而且這種結構不太好做分散式的叢集方案。[3] |
Redis入門
概述
Redis(Remote Dictionary Server ),即遠端字典服務,是一個開源的使用ANSI C語言編寫、支援網路、可基於記憶體亦可持久化的日誌型、Key-Value資料庫,並提供多種語言的API。
redis與memcached一樣,為了保證效率,資料都是快取在記憶體中。區別的是redis會週期性的把更新的資料寫入磁碟或者把修改操作寫入追加的記錄檔案,並且在此基礎上實現了master-slave(主從)同步。
免費,開源,是當下最熱門的NoSQL技術之一,也被稱之為結構化資料庫。
Redis能幹什麼:
- 記憶體儲存,持久化,記憶體中是斷電即失的,所以持久化非常重要(RDB,AOF)。
- 效率高,可以用於快取記憶體。
- 釋出訂閱系統。
- 地圖資訊分析。
- 計時器,計數器(瀏覽量)。
- ...
特點:
- 支援多種語言
- 持久化
- 叢集
- 事務
- ...
Redis中文網:https://www.redis.net.cn/
Windows安裝
- 下載安裝包(github上)
- 解壓壓縮包
- 開啟Redis,直接雙擊服務執行即可
- 使用Redis客戶端來連線服務端(ping 測試連線,存值:set name zr,取值:get name)
Windows下使用非常簡單,但是Redis推薦我們使用Redis去開發使用。
Linux安裝
-
下載安裝包(官網下載)
-
解壓Redis的安裝包到指定包
-
進入解壓後的檔案,可以看到Redis的配置檔案(redis.conf)
-
環境安裝
[root@zhourui redis-6.0.9]# yum install gcc-c++ [root@zhourui redis-6.0.9]# make make install再次make
make install
-
Redis的預設安裝路徑:/usr/local/bin

-
將redis的配置檔案(redis.conf)複製到當前目錄下
[root@zhourui bin]# mkdir zconfig [root@zhourui bin]# cp /www/server/redis/redis-6.0.9/redis.conf zconfig/ -
redis預設不是後臺啟動的,修改配置檔案將 no 改為 yes
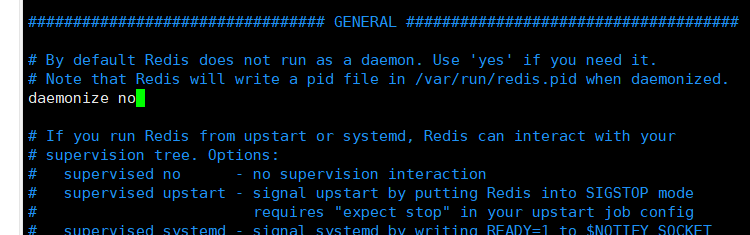
-
啟動Redis服務,通過指定的配置檔案啟動服務
[root@zhourui bin]# redis-server zconfig/redis.conf -
啟動客戶端redis-cli
[root@zhourui bin]# redis-cli -p 6379 127.0.0.1:6379> ping #測試連線 PONG 127.0.0.1:6379> set name zr #存值 OK 127.0.0.1:6379> get name #取值 "zr" 127.0.0.1:6379> keys * #檢視所有的key 1) "name" 127.0.0.1:6379> -
檢視redis的程式是否開啟

-
關閉redis服務,在連線的客戶端輸入 shutdown

-
再次檢視程式是否存在,ps -ef|grep redis
-
單機多redis修改埠即可
效能測試
redis-benchmark 是一個壓力測試工具。
官方自帶的效能測試工具。
redis-benchmark 命令引數!
redis 效能測試工具可選引數如下所示:
| 序號 | 選項 | 描述 | 預設值 |
|---|---|---|---|
| 1 | -h | 指定伺服器主機名 | 127.0.0.1 |
| 2 | -p | 指定伺服器埠 | 6379 |
| 3 | -s | 指定伺服器 socket | |
| 4 | -c | 指定併發連線數 | 50 |
| 5 | -n | 指定請求數 | 10000 |
| 6 | -d | 以位元組的形式指定 SET/GET 值的資料大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用隨機 key, SADD 使用隨機值 | |
| 9 | -P | 通過管道傳輸 |
1 |
| 10 | -q | 強制退出 redis。僅顯示 query/sec 值 | |
| 11 | --csv | 以 CSV 格式輸出 | |
| 12 | -l | 生成迴圈,永久執行測試 | |
| 13 | -t | 僅執行以逗號分隔的測試命令列表。 | |
| 14 | -I | Idle 模式。僅開啟 N 個 idle 連線並等待。 |
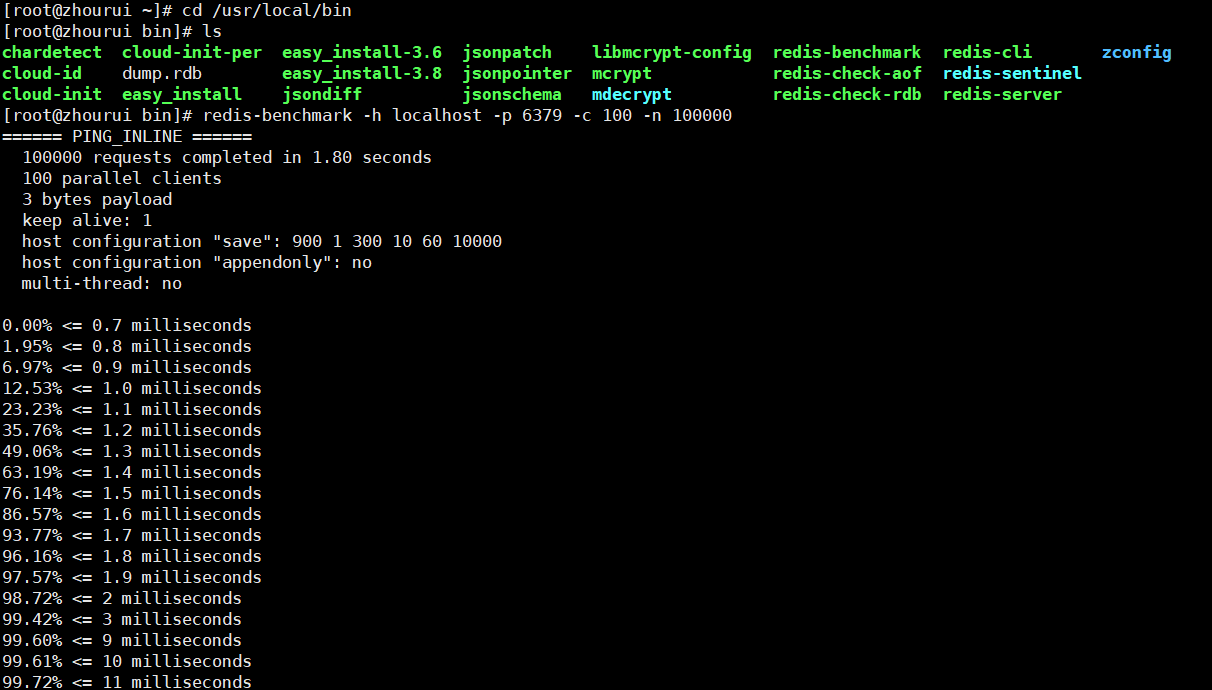
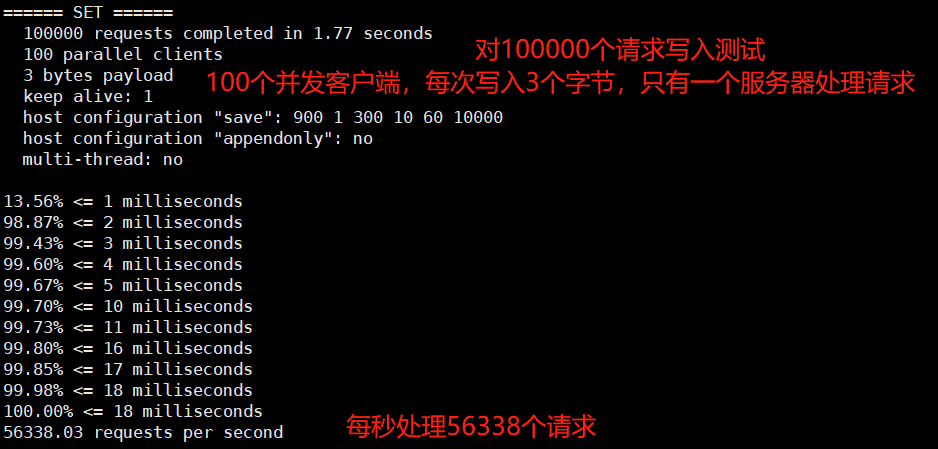
測試:啟動redis後新開一個視窗,執行
# 測試:100個併發連線,100000個請求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
基礎的知識
redis預設有16個資料庫(從 redis.conf 中可以看到)。
預設使用的是第 0 個。
可以使用 select 進行切換。
flushdb:清空當前資料庫,flushall:清空所有的資料庫,dbsize :資料庫的大小,keys * :檢視所有的key。
127.0.0.1:6379> select 3 #切換資料庫
OK
127.0.0.1:6379[3]> dbsize
(integer) 0
127.0.0.1:6379[3]> set name zhou
OK
127.0.0.1:6379[3]> dbsize #資料庫的大小
(integer) 1
127.0.0.1:6379[3]> select 6
OK
127.0.0.1:6379[6]> dbsize
(integer) 0
127.0.0.1:6379[6]> get name
(nil)
127.0.0.1:6379[6]> select 3
OK
127.0.0.1:6379[3]> get name
"zhou"
127.0.0.1:6379[3]> flushdb #清空資料庫
OK
127.0.0.1:6379[3]> get name
(nil)
127.0.0.1:6379> flushall #清空所有的資料庫
OK
127.0.0.1:6379[3]>
Redis是單執行緒的!
官方表示,Redis是基於記憶體操作的,CPU不是Redis的效能瓶頸,Redis的效能瓶頸是根據機器的記憶體和網路的頻寬,既然可以使用單執行緒來實現,就使用單執行緒了。
Redis是C語言寫的,官方提供的資料100000+的QPS,這個完全不比同樣是使用 key-value 的Memcache差!
Redis是單執行緒為什麼還這麼快?
誤區1:認為高效能的伺服器一定是多執行緒的.
誤區2:多執行緒(cpu會上下文切換)一定比單執行緒效率高。
核心:Redis是將所有的資料放在記憶體中的,所以使用單執行緒去操作效率就是最高的,多執行緒(cpu會上下文切換,耗時的操作),對於記憶體系統來說沒有上下文的切換效率就是最高的,多次讀寫都是在一個CPU上的,在記憶體情況下,這個就是最佳方案。
五大資料型別
Redis 是一個開源(BSD許可)的,記憶體中的資料結構儲存系統,它可以用作資料庫、快取和訊息中介軟體。 它支援多種型別的資料結構,如 字串(strings), 雜湊(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 與範圍查詢, bitmaps, hyperloglogs 和 地理空間(geospatial) 索引半徑查詢。 Redis 內建了 複製(replication),LUA指令碼(Lua scripting), LRU驅動事件(LRU eviction),事務(transactions) 和不同級別的 磁碟持久化(persistence), 並通過 Redis哨兵(Sentinel)和自動 分割槽(Cluster)提供高可用性(high availability)。
Redis-Key
127.0.0.1:6379> exists name #判斷鍵是否存在
(integer) 1
127.0.0.1:6379> move name 1 #移除1資料庫的name鍵
(integer) 1
127.0.0.1:6379> set name zzrr
OK
127.0.0.1:6379> keys * #檢視所有的key
1) "name"
2) "age"
127.0.0.1:6379> expire name 10 #設定key過期時間 單位是秒
(integer) 1
127.0.0.1:6379> keys *
1) "name"
2) "age"
127.0.0.1:6379> ttl name #檢視當前key的剩餘時間
(integer) 6
127.0.0.1:6379> ttl name
(integer) 2
127.0.0.1:6379> keys *
1) "age"
127.0.0.1:6379> type name #檢視當前key的型別
string
127.0.0.1:6379> type age
string
127.0.0.1:6379>
String(字串)
###############################################################################
127.0.0.1:6379> set name zr #設定值
OK
127.0.0.1:6379> get name
"zr"
127.0.0.1:6379> keys * #檢視所有的key
1) "name"
127.0.0.1:6379> append name "hello" #追加字串,如果當前的key不存在,就相當於 set key
(integer) 7
127.0.0.1:6379> get name
"zrhello"
127.0.0.1:6379> strlen name #檢視字串的長度
(integer) 7
127.0.0.1:6379>
###############################################################################
# 增量
127.0.0.1:6379> set views 0 #初始值為0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views #自增1
(integer) 1
127.0.0.1:6379> incr views
(integer) 2
127.0.0.1:6379> get views
"2"
127.0.0.1:6379>
127.0.0.1:6379> decr views #自減1
(integer) 1
127.0.0.1:6379> get views
"1"
127.0.0.1:6379> incrby views 10 #設定步長,指定增量
(integer) 11
127.0.0.1:6379> decrby views 10 #設定步長,指定減量
(integer) 1
127.0.0.1:6379>
###############################################################################
# 字串範圍 range
127.0.0.1:6379> flushdb #清空資料庫
OK
127.0.0.1:6379> set name zhour #設定值
OK
127.0.0.1:6379> get name #獲取值
"zhour"
127.0.0.1:6379> getrange name 0 3 #擷取字串 [0,3]
"zhou"
127.0.0.1:6379> getrange name 0 -1 #獲得全部的字串,和getkey是一樣的
"zhour"
127.0.0.1:6379>
# 替換
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> setrange key2 1 xx #替換指定位置開始的字串
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
###############################################################################
# setex (set with expire) 設定過期時間
# setnx (set if not exist) 不存在再設定 在分散式鎖中常使用
127.0.0.1:6379> setex key3 30 "hello" #設定key3的值為hello,30秒後過期
OK
127.0.0.1:6379> ttl key3 #檢視還有多長時間過期
(integer) 25
127.0.0.1:6379> setnx key4 "redis" #如果key4不存在,就建立key4
(integer) 1
127.0.0.1:6379> setnx key4 "MongoDB" #如果key4存在,就建立失敗
(integer) 0
127.0.0.1:6379> get key4
"redis"
127.0.0.1:6379>
###############################################################################
# mset
# mget
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 #同時設定多個值
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> mget k1 k2 k3 #同時獲取多個值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 #msetnx是個原子性的操作,要麼一起成功,要麼一起失敗
(integer) 0
127.0.0.1:6379> get k4
(nil)
# 物件
set user:1 {name:zhour,age:3} #設定一個user:1物件 值為json字串來儲存一個物件
# user:{id}:{filed},這樣設計在redis中是可以的
127.0.0.1:6379> mset user:1:name zhour user:1:age 3
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "zhour"
2) "3"
127.0.0.1:6379>
###############################################################################
# getset 先get再set
127.0.0.1:6379> getset db redis #如果不存在值就返回 nil
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongodb #如果存在值,獲取原來的值,並設定新的值
"redis"
127.0.0.1:6379> get db
"mongodb"
127.0.0.1:6379>
String 型別的使用場景:value除了是字串還可以是數字。
- 計數器
- 統計多單位的數量
- 粉絲數
- 物件快取儲存
List(列表)
基本的資料型別,列表。
在redis中,可以把list玩出成,棧,佇列,阻塞佇列。
所有的 list 命令都是以 l 開頭的。Redis不區分大小寫命令。
###############################################################################
# lpush
127.0.0.1:6379> lpush list one #將一個值或者多個值插入到列表的頭部(左)
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1 #獲取list的值
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> lrange list 0 1 #獲取區間內具體的值
1) "three"
2) "two"
127.0.0.1:6379> rpush list right #將一個值或者多個值插入到列表的尾部(右)
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "right"
127.0.0.1:6379>
###############################################################################
# lpop
# rpop
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "right"
127.0.0.1:6379> lpop list #移除列表的第一個元素
"three"
127.0.0.1:6379> rpop list #移除列表的最後一個元素
"right"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
127.0.0.1:6379>
###############################################################################
# lindex
127.0.0.1:6379> lindex list 0 #通過下標獲取指定下標的值
"two"
127.0.0.1:6379> lindex list 1
"one"
127.0.0.1:6379>
###############################################################################
# llen
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> llen list #獲取列表的長度
(integer) 2
127.0.0.1:6379>
###############################################################################
# lrem 移除指定的值
127.0.0.1:6379> lrange list 0 -1
1) "four"
2) "four"
3) "three"
4) "two"
5) "one"
127.0.0.1:6379> lrem list 1 one #移除list集合中指定個數的value,精確匹配
(integer) 1
127.0.0.1:6379> lrem list 1 four
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "four"
2) "three"
3) "two"
127.0.0.1:6379> lpush list four
(integer) 4
127.0.0.1:6379> lrem list 2 four #移除list中的兩個four
(integer) 2
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
###############################################################################
# ltrim 袖箭
127.0.0.1:6379> rpush mylist hello
(integer) 1
127.0.0.1:6379> rpush mylist hello1
(integer) 2
127.0.0.1:6379> rpush mylist hello12
(integer) 3
127.0.0.1:6379> rpush mylist hello13
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2 #通過下標擷取指定的長度,只剩下擷取的元素
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "hello1"
2) "hello12"
127.0.0.1:6379>
###############################################################################
# rpoplpush 移除列表的最後一個元素,並將它新增到一個新的列表中
127.0.0.1:6379> rpush mylist hello
(integer) 1
127.0.0.1:6379> rpush mylist hello1
(integer) 2
127.0.0.1:6379> rpush mylist hello2
(integer) 3
127.0.0.1:6379> rpoplpush mylist myotherlist #移除列表的最後一個元素,並將它新增到一個新的列表中
"hello2"
127.0.0.1:6379> lrange mylist 0 -1 #檢視原來的列表
1) "hello"
2) "hello1"
127.0.0.1:6379> lrange myotherlist 0 -1 #檢視新的列表
1) "hello2"
127.0.0.1:6379>
###############################################################################
# lset 將列表中指定下標的值替換為另外一個值
127.0.0.1:6379> exists list #判斷這個列表是否存在
(integer) 0
127.0.0.1:6379> lset list 0 item #如果不存在列表,去更新就會報錯
(error) ERR no such key
127.0.0.1:6379> lpush list value1
(integer) 1
127.0.0.1:6379> lrange list 0 0
1) "value1"
127.0.0.1:6379> lset list 0 item #如果存在,會更新當前下標的值
OK
127.0.0.1:6379> lrange list 0 0
1) "item"
127.0.0.1:6379> lset list 1 other #不存在這個下標,會報錯
(error) ERR index out of range
###############################################################################
# linsert 將某個具體的value插入到某個元素的前面或者後面
127.0.0.1:6379> rpush mylist hello
(integer) 1
127.0.0.1:6379> rpush mylist world
(integer) 2
127.0.0.1:6379> linsert mylist before world other
(integer) 3
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
127.0.0.1:6379> linsert mylist after world new
(integer) 4
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
4) "new"
list:實際上是一個連結串列,before Node after,left,right都可以插入值。
- 如果key不存在,建立新的列表
- 如果key存在,新增內容
- 如果移除了所有值,空連結串列,代表不存在
- 在兩邊插入或者改動值效率最高,中間元素,相對來說,效率低一點
訊息佇列(Lpush,Rpop),棧(Lpush,Lpop)。
Set(集合)
set中的值是不能重複的!
###############################################################################
# 存值,取值
127.0.0.1:6379> sadd myset hello #set中存值
(integer) 1
127.0.0.1:6379> sadd myset hellozr
(integer) 1
127.0.0.1:6379> sadd myset hellozhou
(integer) 1
127.0.0.1:6379> smembers myset #檢視指定set的所有值
1) "hellozr"
2) "hello"
3) "hellozhou"
127.0.0.1:6379> sismember myset hello #判斷某一個元素是否在set中,存在返回 1
(integer) 1
127.0.0.1:6379> sismember myset world #不存在這個元素會返回 0
(integer) 0
127.0.0.1:6379>
###############################################################################
127.0.0.1:6379> scard myset #獲取set中元素的個數
(integer) 3
###############################################################################
# srem
127.0.0.1:6379> srem myset hello # 移除set中的指定元素
(integer) 1
127.0.0.1:6379> scard myset
(integer) 2
127.0.0.1:6379> smembers myset #檢視set中的元素
1) "hellozr"
2) "hellozhou"
127.0.0.1:6379>
###############################################################################
# set 無序不重複集合
127.0.0.1:6379> sadd myset zhourr
(integer) 1
127.0.0.1:6379> smembers myset
1) "zhourr"
2) "hellozr"
3) "hellozhou"
127.0.0.1:6379> srandmember myset #隨機抽選出一個元素
"hellozr"
127.0.0.1:6379> srandmember myset
"hellozhou"
127.0.0.1:6379> srandmember myset
"hellozr"
127.0.0.1:6379> srandmember myset
"hellozr"
127.0.0.1:6379>
###############################################################################
# 刪除指定的key 隨機刪除key
127.0.0.1:6379> smembers myset
1) "zhourr"
2) "hellozr"
3) "hellozhou"
127.0.0.1:6379> spop myset #隨機移除元素
"hellozr"
127.0.0.1:6379> spop myset
"hellozhou"
127.0.0.1:6379> smembers myset
1) "zhourr"
127.0.0.1:6379>
###############################################################################
# 將一個指定的值移動到另外一個set集合中
127.0.0.1:6379> sadd myset hello
(integer) 1
127.0.0.1:6379> sadd myset world
(integer) 1
127.0.0.1:6379> sadd myset zhour
(integer) 1
127.0.0.1:6379> sadd myset2 set2
(integer) 1
127.0.0.1:6379> smove myset myset2 zhour # 將一個指定的值移動到另外一個set集合中
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
2) "world"
127.0.0.1:6379> SMEMBERS myset2
1) "zhour"
2) "set2"
127.0.0.1:6379>
###############################################################################
# 共同關注(交集)
# SDIFF 差集
# SINTER 交集
# SUNION 並集
127.0.0.1:6379> sadd key1 a
(integer) 1
127.0.0.1:6379> sadd key1 b
(integer) 1
127.0.0.1:6379> sadd key1 c
(integer) 1
127.0.0.1:6379> sadd key2 c
(integer) 1
127.0.0.1:6379> sadd key2 d
(integer) 1
127.0.0.1:6379> sadd key2 e
(integer) 1
127.0.0.1:6379> SDIFF key1 key2 # 差集
1) "a"
2) "b"
127.0.0.1:6379> SINTER key1 key2 # 交集 共同好友
1) "c"
127.0.0.1:6379> SUNION key1 key2 # 並集
1) "a"
2) "b"
3) "c"
4) "e"
5) "d"
127.0.0.1:6379>
可以將 A 的所有關注放在一個集合中,將它的粉絲放在另一個集合中!
共同好友,共同愛好,二度好友,推薦好友!(六度分割理論)
Hash(雜湊)
Map集合,key-map集合,value變成了map集合!本質和String型別沒有太大的區別,還是一個簡單的key-value。
127.0.0.1:6379> hset myhash field1 zhourr # set一個具體的 key value
(integer) 1
127.0.0.1:6379> hget myhash field1 # 獲取一個欄位值
"zhourr"
127.0.0.1:6379> hmset myhash field1 hello field2 world # set 多個 key value
OK
127.0.0.1:6379> hmget myhash field1 field2 # 獲取多個欄位值
1) "hello"
2) "world"
127.0.0.1:6379> hgetall myhash # 獲取全部的資料 key value
1) "field1"
2) "hello"
3) "field2"
4) "world"
127.0.0.1:6379>
###############################################################################
127.0.0.1:6379> hdel myhash field1 # 刪除hash指定的key欄位,對應的value值也被刪除
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "world"
127.0.0.1:6379>
###############################################################################
# hlen
127.0.0.1:6379> hmset myhash field1 hello field2 world
OK
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "world"
3) "field1"
4) "hello"
127.0.0.1:6379> hlen myhash # 獲取hash 表的欄位數量
(integer) 2
127.0.0.1:6379>
###############################################################################
# 判斷 hash 中指定的key是否存在
127.0.0.1:6379> HEXISTS myhash field1 #判斷 hash 中指定的key是否存在
(integer) 1
127.0.0.1:6379> HEXISTS myhash field3
(integer) 0
###############################################################################
#只獲得所有的field
#只獲得所有的value
127.0.0.1:6379> hkeys myhash #只獲得所有的field
1) "field2"
2) "field1"
127.0.0.1:6379> hvals myhash #只獲得所有的value
1) "world"
2) "hello"
127.0.0.1:6379>
###############################################################################
# hincrby
127.0.0.1:6379> hset myhash field3 5 # 指定增量
(integer) 1
127.0.0.1:6379> HINCRBY myhash field3 2
(integer) 7
127.0.0.1:6379> HINCRBY myhash field3 -3
(integer) 4
127.0.0.1:6379> hsetnx myhash field4 hello # 如果不存在,則可以設定
(integer) 1
127.0.0.1:6379> hsetnx myhash field4 world # 如果存在,則不可用設定
(integer) 0
127.0.0.1:6379>
hash 變更的資料 user name age ,尤其是使用者資訊的儲存,或經常變動的資訊。hash更適合物件的儲存,string更適合字串的儲存。
Zset(有序集合)
在set的基礎上增加了一個值,set k1 v1 , zset k1 score1 v1.
###############################################################################
127.0.0.1:6379> zadd myset 1 one #新增一個值
(integer) 1
127.0.0.1:6379> zadd myset 2 two 3 three # 新增多個值
(integer) 2
127.0.0.1:6379> zrange myset 0 -1 # 獲取所有的值
1) "one"
2) "two"
3) "three"
127.0.0.1:6379>
###############################################################################
# 排序
127.0.0.1:6379> zadd salary 2500 xiaohong # 新增三個使用者
(integer) 1
127.0.0.1:6379> zadd salary 5000 zhangsan
(integer) 1
127.0.0.1:6379> zadd salary 4000 zhour
(integer) 1
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf #顯示全部使用者,從負無窮到正無窮排序
1) "xiaohong"
2) "zhour"
3) "zhangsan"
127.0.0.1:6379> ZREVRANGE salary 0 -1 # 從大到小排序
1) "zhangsan"
2) "zhour"
3) "xiaohong"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores # 從小到大顯示,並附帶成績
1) "xiaohong"
2) "2500"
3) "zhour"
4) "4000"
5) "zhangsan"
6) "5000"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 4000 withscores # 4000以下的員工的排序
1) "xiaohong"
2) "2500"
3) "zhour"
4) "4000"
127.0.0.1:6379> ZREVRANGEBYSCORE salary +inf -inf # 從大到小排序
1) "zhangsan"
2) "zhour"
3) "xiaohong"
###############################################################################
# 移除元素
127.0.0.1:6379> zrange salary 0 -1
1) "xiaohong"
2) "zhour"
3) "zhangsan"
127.0.0.1:6379> zrem salary xiaohong # 移除元素
(integer) 1
127.0.0.1:6379> zrange salary 0 -1
1) "zhour"
2) "zhangsan"
127.0.0.1:6379> zcard salary # 獲取有序集合中的個數
(integer) 2
127.0.0.1:6379>
###############################################################################
# 獲取指定區間的成員數量
127.0.0.1:6379> zadd myset 1 hello
(integer) 1
127.0.0.1:6379> zadd myset 2 world 3 zhour
(integer) 2
127.0.0.1:6379> zcount myset 1 3 # 獲取指定區間的成員數量
(integer) 3
set 排序 :班級成績表,工資表,帶權重判斷資料重要性,排行榜取top N。
其它更多操作,檢視官方文件!!!
三種特殊資料型別
Geospatial(地理位置)
朋友的位置,附件的人,叫車距離計算。
Redis的geo在3.2版本就推出了!這個功能可以推算地理位置資訊,兩地之間的距離,附近的人。
線上地理位置資訊:http://www.jsons.cn/lngcode/
相關命令
geoadd:
# 新增地理位置
# 兩級無法直接新增,我們一般會下載城市資料,通過java程式一次性匯入!
# 將指定的地理空間位置(經度、緯度、名稱)新增到指定的key中
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqin 114.05 22.52 shengzhen
(integer) 2
127.0.0.1:6379> geoadd china:city 120.16 30.34 hangzhou 108.96 34.26 xian
(integer) 2
127.0.0.1:6379>
- 有效的經度從-180度到180度。
- 有效的緯度從-85.05112878度到85.05112878度。
當座標位置超出上述指定範圍時,該命令將會返回一個錯誤。
geopos:獲得當前的定位,一定是一個座標值
# 獲取指定城市的經度和緯度
127.0.0.1:6379> geopos china:city beijing
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> geopos china:city beijing chongqin
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379>
deodist:
返回兩個給定位置之間的距離。
如果兩個位置之間的其中一個不存在, 那麼命令返回空值。
指定單位的引數 unit 必須是以下單位的其中一個:
- m 表示單位為米。
- km 表示單位為千米。
- mi 表示單位為英里。
- ft 表示單位為英尺。
如果使用者沒有顯式地指定單位引數, 那麼 GEODIST 預設使用米作為單位。
127.0.0.1:6379> geodist china:city beijing shanghai # 北京到上海的直線距離 單位 米
"1067378.7564"
127.0.0.1:6379> geodist china:city beijing shanghai km # 北京到上海的直線距離 單位 千米
"1067.3788"
127.0.0.1:6379> geodist china:city beijing chongqin km # 北京到重慶的直線距離 單位 千米
"1464.0708"
127.0.0.1:6379>
georadius:以給定的經度緯度為中心,找出某一半徑內的元素。
附近的人(獲得附近的人的地址,定位)通過半徑來查詢。
127.0.0.1:6379> georadius china:city 110 30 1000 km # 獲取以110,30為中心,1000km為半徑內的城市
1) "chongqin"
2) "xian"
3) "shengzheng"
4) "hangzhou"
127.0.0.1:6379> georadius china:city 110 30 500 km # 獲取以110,30為中心,500km為半徑內的城市
1) "chongqin"
2) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist # 顯示到中心點的距離
1) 1) "chongqin"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord # 顯示範圍內城市的位置資訊
1) 1) "chongqin"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist withcoord count 1 # 篩選出1個結果
1) 1) "chongqin"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379>
GEORADIUSBYMEMBER:
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 1000 km #指定位置範圍內的其它位置
1) "beijing"
2) "xian"
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 400 km
1) "hangzhou"
2) "shanghai"
127.0.0.1:6379>
geohash:返回一個或多個位置元素的 Geohash 表示。
該命令將返回11個字元的Geohash字串。
# 將二維的經緯度轉化為一維的字串(如果兩個字串越接近則距離越接近)
127.0.0.1:6379> geohash china:city beijing chongqin
1) "wx4fbxxfke0"
2) "wm5xzrybty0"
geo的底層實現原理其實是 zset!我們可以使用zset來操作geo。
127.0.0.1:6379> zrange china:city 0 -1 #檢視全部的元素
1) "chongqin"
2) "xian"
3) "shengzheng"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379> zrem china:city chongqin #刪除元素
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1
1) "xian"
2) "shengzheng"
3) "hangzhou"
4) "shanghai"
5) "beijing"
127.0.0.1:6379>
Hyperloglog
基數:不重複元素的個數。
Redis在2.8.9版本就更新了hyperloglog資料結構。
Redis hyperloglog 基數統計的演算法。
優點:佔用的記憶體是固定的,2^64不同元素的基數,只需要12kb的記憶體!從記憶體的角度來比較的話,hyperloglog是首選。
網頁的訪問量(UV)(同一個人多次訪問,還是算作一個人)
傳統的方式,set儲存使用者的id,就可以統計set元素中的數量作為判斷。
這個方式如果儲存大量的使用者id,就會比較麻煩!主要是為了計數,而不是儲存使用者的id。
0.81%的錯誤率,統計UA任務,可以忽略不計的。
127.0.0.1:6379> pfadd myket a b c d e f g h i j # 存一組值
(integer) 1
127.0.0.1:6379> pfcount myket # 統計一組元素的基數數量
(integer) 10
127.0.0.1:6379> pfadd myket2 i j z x c v b n m
(integer) 1
127.0.0.1:6379> pfcount myket2
(integer) 9
127.0.0.1:6379> pfmerge mykey3 myket myket2 # 合併兩組 並集
OK
127.0.0.1:6379> pfcount mykey3 # 檢視合併後的數量
(integer) 15
127.0.0.1:6379>
如果允許容錯,就可以使用hyperloglog。
Bitmap
位儲存。
統計使用者資訊,活躍,不活躍!登入,未登入 !打卡!兩個狀態的都可以使用Bitmap。
Bitmap 點陣圖,資料結構!都是操作二進位制位來記錄,就只有 0 和 1 兩個狀態。
# 使用 bitmaps 記錄週一到週日的打卡,1為打卡,0為未打卡
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 0
(integer) 0
127.0.0.1:6379>
檢視某一天是否有打卡
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 5
(integer) 0
127.0.0.1:6379>
統計打卡的天數
127.0.0.1:6379> bitcount sign
(integer) 3
127.0.0.1:6379>
事務
Redis的單條命令是保證原子性的,但是事務是不保證原子性的。
Redis事務沒有隔離級別的概念,所有的命令在事務中並沒有被直接執行,只有發起執行命令的時候才會被執行。
Redis 事務本質:一組命令的集合。一個事務中的所有命令都會被序列化,在事務執行的過程中,會按照順序執行。
一次性,順序性,排它性!執行一系列的命令。
==========佇列 set set set 執行=================
Redis 事務:
- 開啟事務(multi)
- 命令入隊(......)
- 執行事務(exec)
正常執行事務!
127.0.0.1:6379> multi # 開啟事務
OK
127.0.0.1:6379> set k1 v1 # 命令入隊
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec # 執行事務
1) OK
2) OK
3) "v2"
4) OK
127.0.0.1:6379>
放棄事務!
127.0.0.1:6379> multi # 開啟事務
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> DISCARD # 取消事務 事務佇列中的命令都不會被執行
OK
127.0.0.1:6379> get k4
(nil)
127.0.0.1:6379>
編譯型異常!(程式碼中有問題,命令錯誤,事務中所有的命令都不會被執行)
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> getset k3 # 錯誤的命令
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> exec # 執行事務也是報的 所有的命令都不會執行
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k5
(nil)
127.0.0.1:6379>
執行時異常!(如果事務佇列中存在語法性的錯誤,那麼執行的時候,其它命令是可以正常執行的,錯誤命令會丟擲異常)這裡的事務就無法保證原子性!!!
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr k1 # 字串不能遞增,執行的時候會失敗
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> get k3
QUEUED
127.0.0.1:6379> exec # 第一條命令報錯了,但是其它的命令執行成功了
1) (error) ERR value is not an integer or out of range
2) OK
3) OK
4) "v3"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379>
監控!Watch
樂觀鎖:很樂觀,認為什麼時候都不會出問題,所以無論做什麼都不會加鎖。更新資料的時候去判斷一下,在此期間是否有人修改過這個資料,version。獲取version,更新的時候比較version。
悲觀鎖:很悲觀,認為什麼時候都會出問題,所以無論做什麼都加鎖。
Redis的監視測試:
# 正常執行成功
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money # 監視money
OK
127.0.0.1:6379> multi # 事務正常結束,資料期間沒有發生變動
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> incrby out 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
127.0.0.1:6379>
測試多執行緒修改值,使用watch,可以當作redis的樂觀鎖操作。
127.0.0.1:6379> watch money # 監視money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 10
QUEUED
127.0.0.1:6379> incrby out 10
QUEUED
127.0.0.1:6379> exec # 執行之前,另外一個執行緒修改了money值,就會導致事務執行失敗
(nil)
127.0.0.1:6379>
如果事務執行失敗,就先解鎖 unwatch ,再watch money,再開啟事務執行後面的操作。
Jedis
使用Java來操作redis。
Jedis是 Redis 官方推薦的 Java 連線開發工具!使用 Java 操作Redis的中介軟體!如果要用Java操作Redis,那麼一定要對Jedis十分熟悉。
測試:
- 匯入對應的依賴
<!-- 匯入 jedis的包-->
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<!-- fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.74</version>
</dependency>
</dependencies>
-
編碼測試
-
連線資料庫
-
操作命令
-
斷開連線
package com.zr; import redis.clients.jedis.Jedis; public class TestPing { public static void main(String[] args) { // new jedis物件 Jedis jedis = new Jedis("39.105.48.232",6379); System.out.println(jedis.ping()); } }
-
輸出:

常用API
package com.zr;
import redis.clients.jedis.Jedis;
import java.util.Set;
public class TestKey {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
System.out.println("清空資料:"+jedis.flushDB());
System.out.println("判斷某個鍵是否存在:"+jedis.exists("username"));
System.out.println("新增鍵值對:"+jedis.set("username","zr"));
System.out.println("新增鍵值對:"+jedis.set("password","813794474"));
System.out.println("系統中的鍵如下:");
Set<String> keys = jedis.keys("*");
System.out.println(keys);
System.out.println("刪除鍵"+jedis.del("password"));
System.out.println("判斷password鍵是否存在:"+jedis.exists("password"));
System.out.println("判斷username的型別:"+jedis.type("username"));
System.out.println("隨機返回:"+jedis.randomKey());
System.out.println("隨機返回:"+jedis.rename("username","name"));
System.out.println("取出值:"+jedis.get("name"));
System.out.println("索引查詢:"+jedis.select(0));
System.out.println("刪除當前資料庫:"+jedis.flushDB());
System.out.println("返回當前資料庫的key數量:"+jedis.dbSize());
System.out.println("刪除所有:"+jedis.flushAll());
}
}
String
package com.zr;
import redis.clients.jedis.Jedis;
import java.util.Set;
import java.util.concurrent.TimeUnit;
public class TestString {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
System.out.println("清空資料:"+jedis.flushDB());
System.out.println("=======增加資料========");
System.out.println(jedis.set("k1","v1"));
System.out.println(jedis.set("k2","v2"));
System.out.println(jedis.set("k3","v3"));
System.out.println("刪除:"+jedis.del("k2"));
System.out.println("取值:"+jedis.get("k2"));
System.out.println("修改k1:"+jedis.set("k1","v111"));
System.out.println("k3後增加:"+jedis.append("k3","zhour"));
System.out.println("k3:"+jedis.get("k3"));
System.out.println("增加多個:"+jedis.mset("k4","v4","k5","v5","k6","v6"));
System.out.println("獲取多個:"+jedis.mget("k4","k5","k6"));
jedis.flushDB();
System.out.println("=======新增鍵值防止覆蓋======");
System.out.println(jedis.setnx("k1","v1"));
System.out.println(jedis.setnx("k2","v2"));
System.out.println(jedis.setnx("k3","v3"));
System.out.println("=======新增鍵並設定有效時間======");
System.out.println(jedis.setex("k3",6,"v3"));
System.out.println(jedis.get("k3"));
try{
TimeUnit.SECONDS.sleep(6);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(jedis.get("k3"));
System.out.println("=======獲取原值,更新為新值=======");
System.out.println(jedis.getSet("k2","k222gdsg"));
System.out.println(jedis.get("k2"));
System.out.println("擷取:"+jedis.getrange("k2",2,5));
}
}
list
package com.zr;
import redis.clients.jedis.Jedis;
public class TestList {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.flushDB();
System.out.println("=========增加list=====");
jedis.lpush("collection","Aeeaylist","Vector","Stack","HashMap","WeakHashMap","LinkHashMap");
jedis.lpush("collection","HashSet");
jedis.lpush("collection","TreeSet");
System.out.println("collection:"+jedis.lrange("collection",0,-1));
System.out.println("collection中0-3區間:"+jedis.lrange("collection",0,3));
System.out.println("=========================");
System.out.println("刪除:"+jedis.lrem("collection",2,"HashMap"));
System.out.println("collection:"+jedis.lrange("collection",0,-1));
System.out.println("刪除指定區間:"+jedis.ltrim("collection",0,2));
System.out.println("collection:"+jedis.lrange("collection",0,-1));
System.out.println("出棧 左端"+jedis.lpop("collection"));
System.out.println("出棧 右端"+jedis.rpop("collection"));
System.out.println("右端新增元素"+jedis.rpush("collection","right"));
System.out.println("左端新增元素"+jedis.lpush("collection","left"));
System.out.println("修改指定下標:"+jedis.lset("collection",1,"LinkHashMap"));
System.out.println("========長度==========");
System.out.println("collection:"+jedis.lrange("collection",0,-1));
System.out.println(jedis.llen("collection"));
}
}
Set,Hash,Zset例子參考 五大基本資料型別!!!!!
事務!
package com.zr;
import com.alibaba.fastjson.JSONObject;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class TestTX {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","zhour");
//開啟事務
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
//jedis.watch(result);
try {
multi.set("user1",result);
multi.set("user2",result);
//int i = 1/0; //程式碼異常,執行失敗
multi.exec(); //執行事務
} catch (Exception e) {
multi.discard(); //放棄事務
e.printStackTrace();
}finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close(); //關閉連線
}
}
}
SpringBoot整合
SpringBoot 運算元據:spring-data :jpa jdbc redis等!
SpringData也是和SpringBoot齊名的專案。
說明:在spring2.X之後,jedis被替換為了 lettuce!
jedis:採用的是直連,多個執行緒操作的話,是不安全的,如果想避免不安全,就要使用jedis pool連線池!更像 BIO 模式
lettuce:採用netty,例項可以在多個執行緒中共享,不存線上程不安全的情況!更像 NIO 模式
原始碼解析:
@Bean
@ConditionalOnMissingBean(
name = {"redisTemplate"} //不存在才生效,我們可以自己定義一個來替換這個預設的
)
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
//預設的RedisTemplate沒有過多的設定,redis物件都是需要序列化的
//兩個泛型都是Object的型別,後面使用需要強制轉換
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean //由於String是redis中最常使用的一個方法,所以單獨提出來了一個bean
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
整合測試
-
匯入依賴
<!--操作redis--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> -
配置連線
# springboot的所有配置類,都有一個自動配置類 # 自動配置類都會繫結一個 properties的配置檔案 RedisAutoConfiguration #配置redis spring.redis.host=127.0.0.1 spring.redis.port=6379 spring.red -
測試
package com.zr; @SpringBootTest class Redis02SpringbootApplicationTests { @Autowired private RedisTemplate redisTemplate; @Test void contextLoads() { //opsForValue 操作字串的。類似string //opsForList 操作list //opsForSet //opsForHash //opsForZSet //opsForGeo //除了基本的操作,其它的方法都可以使用redisTemplat來操作,比如事務,和基本的CRUD //獲取redis的連線物件 // RedisConnection connection= redisTemplate.getConnectionFactory().getConnection(); // connection.flushDb(); // connection.flushAll(); redisTemplate.opsForValue().set("mykey","zhour"); System.out.println(redisTemplate.opsForValue().get("mykey")); } }
序列化配置(再點進去可以看到預設的是jdk序列化,我們可以使用json序列化)

測試:
User
package com.zr.config.pojo;
@Component
@Data
@AllArgsConstructor
@NoArgsConstructor
//在企業開發中,所有的pojo都會序列化
public class User implements Serializable {
private String name;
private Integer age;
}
@Test
void test() throws JsonProcessingException {
//真實開發一般使用json來傳遞物件
User user = new User("週週", 8);
// String jsonUser = new ObjectMapper().writeValueAsString(user);
// redisTemplate.opsForValue().set("user",jsonUser);
redisTemplate.opsForValue().set("user",user); //這裡直接傳遞物件,會報錯,需要將物件序列化
System.out.println(redisTemplate.opsForValue().get("user"));
}
編寫自己的RedisTemplate
package com.zr.config;
@Configuration
public class RedisConfig {
//編寫我們自己的redisTemplate
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<String,Object>();
template.setConnectionFactory(factory);
//json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
//String序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//key採用String序列化方式
template.setKeySerializer(stringRedisSerializer);
//hash的key也採用String序列化方式
template.setHashKeySerializer(stringRedisSerializer);
//value的序列化方式採用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
//hash的value的序列化方式採用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
測試
@Autowired
@Qualifier("redisTemplate")
private RedisTemplate redisTemplate;
@Test
void test() throws JsonProcessingException {
//真實開發一般使用json來傳遞物件
User user = new User("週週", 8);
// String jsonUser = new ObjectMapper().writeValueAsString(user);
// redisTemplate.opsForValue().set("user",jsonUser);
redisTemplate.opsForValue().set("user",user); //這裡直接傳遞物件,會報錯,需要將物件序列化
System.out.println(redisTemplate.opsForValue().get("user"));
}
可以將redis的所有操作封裝成一個工具類,類似以前的jdbcUtils。
所有的redis操作十分簡單,重要的是我們要理解redis的思和每一種資料結構的具體應用場景!!
Redis.conf詳解
啟動的時候,就是通過配置檔案來啟動的!
配置檔案,unit單位對大小寫不敏感!
包含:include,可以包含其它配置檔案
網路:NETWORK
bind 127.0.0.1 # 繫結的ip
protected-mode yes # 保護模式
port 6379 # 埠設定
通用:GENERAL
daemonize yes # 以守護程式的方式執行,預設是no,我們自己開啟為yes
pidfile /var/run/redis_6379.pid # 如果以後臺的方式執行,就需要繫結一個 pid 檔案
# 日誌
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably) #生產環境使用
# warning (only very important / critical messages are logged)
loglevel notice
# 日誌檔案的位置名
logfile ""
databases 16 # 預設有16個資料庫
always-show-logo yes # 是否總是顯示log
快照
持久化,在規定的時間內,執行了多少次操作,則會持久化到檔案 .rdb .aof
redis是記憶體資料庫,如果沒有持久化,資料則斷電即失。
# 900秒內,如果至少有一個key進行了修改,我們就進行持久化操作
save 900 1
# 300秒內,如果至少有10個key進行了修改,我們就進行持久化操作
save 300 10
# 60秒內,如果至少有10000個key進行了修改,我們就進行持久化操作
save 60 10000
# 可自己定義設定
stop-writes-on-bgsave-error yes # 持久化出錯了是否還需要繼續工作
rdbcompression yes # 是否壓縮rdb檔案,需要消耗一些cpu資源
rdbchecksum yes # 儲存rdb檔案的時候,進行錯誤校驗
dir ./ # rdb檔案儲存的目錄
REPLICATION:複製,與主從複製相關,主從複製中解釋。
SECURITY:安全
可以在這裡設定redis的密碼,預設是沒有密碼的,
config get requirepass # 獲取密碼
config set requirepass "123456" # 設定密碼, config set requirepass "" 不設定密碼
config get requirepass # 此時顯示沒有許可權
auth 123456 # 密碼登入
config get requirepass # 現在可以獲取到設定的密碼
限制:CLIENTS
# maxclients 10000 # 設定能連線上redis客戶端的最大連線數量
# maxmemory <bytes> # 最大記憶體容量
# maxmemory-policy noeviction # 記憶體達到上限之後的處理策略
redis.conf中的預設的過期策略是 volatile-lru
maxmemory-policy 六種方式
1、volatile-lru:只對設定了過期時間的key進行LRU(預設值)
2、allkeys-lru : 刪除lru演算法的key
3、volatile-random:隨機刪除即將過期key
4、allkeys-random:隨機刪除
5、volatile-ttl : 刪除即將過期的
6、noeviction : 永不過期,返回錯誤
APPEND ONLY MODEl:aof配置
appendonly no # 預設是不開啟aof模式的,預設是使用rdb的方式持久化的,在大部分情況下,rdb完全夠用
appendfilename "appendonly.aof" # 持久化的檔案的名字
# appendfsync always # 每次修改都sync,消耗效能
appendfsync everysec # 每秒執行一次sync(同步),可能會丟失1秒的資料
# appendfsync no # 不執行sync,這個時候作業系統自動同步資料,速度最快
Redis持久化
Redis是記憶體資料庫,如果不將記憶體中的資料庫持久化到磁碟中,那麼一旦服務終止,資料就會消失,所以Redis提供了持久化的功能!
RDB(Redis DataBase)
在指定的時間間隔內,將記憶體中的資料集體寫入磁碟。也就是Snapshot快照,恢復時將快照檔案直接讀到記憶體中。
Redis會單獨建立(fork)一個子程式來進行持久化,會先將資料寫入一個臨時檔案中,待持久化過程都結束,再用這個臨時檔案替換上次持久化好的檔案,整個過程中,主程式是不進行任何IO操作的,這就確保了極高的效能。如果需要進行大規模的資料恢復,且對恢復資料的完整性不是非常敏感,則RDB的方式比AOF的方式更加高效。RDB的缺點是最後一次持久的資料可能丟失。我們預設的就是RDB,一般不需要更改。
一般生產環境會將dump.rdb檔案備份!!主從複製中,rdb備用,在從機上面。
rdb儲存的檔案是:dump.rdb,在配置檔案快照中進行配置的。

觸發機制(生成dump.rdb)
- save規則滿足的情況下,會自動觸發rdb規則
- 執行 flushall 命令,也會觸發rdb規則
- 退出redis,也會生成rdb檔案
備份就會自動生成一個dump.rdb。
如何恢復rdb檔案
只需要將dump.rdb檔案放在redis的啟動目錄下就可以,redis啟動的時候會自動檢查dump.rdb檔案。
檢視需要存放的位置
127.0.0.1:6379> config get dir
1) "dir"
2) "/usr/local/bin" # 如果在這個目錄下存在dump.rdb檔案,啟動就會自動恢復其中的資料
優點:
- 適合大規模的資料恢復!dump.rdb
- 對資料線完整性的要求不高
缺點:
- 需要一定的時間間隔進行操作!意外當機,最後一次的資料會丟失。
- fork程式的時候,會佔用一定的程式空間!
AOF(Append Only File)
將我們的所有命令都記錄下來,history,恢復的時候將這個檔案全部都執行一遍。
以日誌的形式去記錄每一個寫操作,將redis執行的所有命令記錄下來(讀操作不記錄),只許追加檔案但不可以改寫檔案,redis啟動會讀取該檔案重構資料庫。也就是,redis啟動會根據日誌檔案的內容將寫指令從前到後執行一次以完成資料恢復的工作。
aof儲存的是 appendonly.aof檔案。
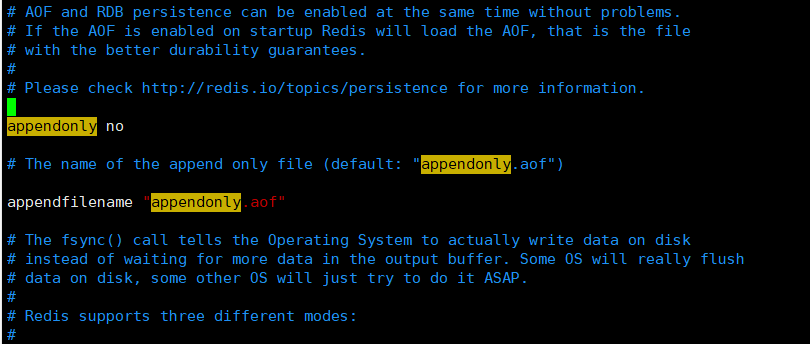
預設是不開啟的,使用需要手動配置!只需要將appendonly no改為yes開啟即可!
重啟redis就可以生效了!
如果 appendonly.aof 檔案有錯誤,redis是啟動不起來的,我們需要修復這個aof檔案。
redis給我們提供了一個工具,redis-check-aof --fix
修復成功後,重啟即可!
重寫規則
預設的是檔案的無限追加,會越來越大。

如果aof檔案大於64mb,就會fork一個程式來將檔案進行重寫。
優點和缺點:
appendonly no # 預設是不開啟aof模式的,預設是使用rdb的方式持久化的,在大部分情況下,rdb完全夠用
appendfilename "appendonly.aof" # 持久化的檔案的名字
# appendfsync always # 每次修改都sync,消耗效能
appendfsync everysec # 每秒執行一次sync(同步),可能會丟失1秒的資料
# appendfsync no # 不執行sync,這個時候作業系統自動同步資料,速度最快
優點:
- 每一次修改都同步,檔案的完整性會更好!
- 預設的是每秒同步一次,可能會丟失一秒的資料
- 從不同步,效率是最高的
缺點:
- 相對於資料檔案來說,aof遠大於rdb,修復的速度也比rdb慢
- aof的執行效率也要比rdb慢,所以redis的預設配置是使用rdb持久化
Redis釋出訂閱
Redis釋出訂閱(pub/sub)是一種訊息通訊模式:傳送者(pub)傳送訊息,訂閱者(sub)接收訊息。公眾號,微博等關注系統!
Redis客戶端可以訂閱任意數量的頻道。
下圖展示了頻道 channel1 , 以及訂閱這個頻道的三個客戶端 —— client2 、 client5 和 client1 之間的關係

當有新訊息通過 PUBLISH 命令傳送給頻道 channel1 時, 這個訊息就會被髮送給訂閱它的三個客戶端:

Redis 釋出訂閱命令
下表列出了 redis 釋出訂閱常用命令:
| 序號 | 命令及描述 |
|---|---|
| 1 | [PSUBSCRIBE pattern pattern ...] 訂閱一個或多個符合給定模式的頻道。 |
| 2 | [PUBSUB subcommand argument [argument ...]] 檢視訂閱與釋出系統狀態。 |
| 3 | PUBLISH channel message 將資訊傳送到指定的頻道。 |
| 4 | [PUNSUBSCRIBE pattern [pattern ...]] 退訂所有給定模式的頻道。 |
| 5 | [SUBSCRIBE channel channel ...] 訂閱給定的一個或多個頻道的資訊。 |
| 6 | [UNSUBSCRIBE channel [channel ...]] 指退訂給定的頻道。 |
測試:
訂閱端
127.0.0.1:6379> SUBSCRIBE zhour # 訂閱一個頻道
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "zhour"
3) (integer) 1
# 等待接收推送的資訊
1) "message" #訊息
2) "zhour" #哪個頻道的訊息
3) "hello,zhour" #訊息的具體內容
1) "message"
2) "zhour"
3) "hello,redis"
傳送端
127.0.0.1:6379> PUBLISH zhour "hello,zhour" # 釋出訊息到頻道
(integer) 1
127.0.0.1:6379> PUBLISH zhour "hello,redis" # 釋出訊息到頻道
(integer) 1
127.0.0.1:6379>
Redis是使用C實現的,通過分析redis原始碼裡的pubsub.c檔案,瞭解釋出和訂閱機制的底層實現,可加深對redis的理解。
通過subscribe命令訂閱某頻道後,redis-server中維護了一個字典,字典的鍵就是一個個頻道,而字典的值則是一個連結串列,連結串列中儲存了所有訂閱這個channel的客戶端,subscribe命令的關鍵,就是將客戶端新增到給的的channel的訂閱連結串列中。
通過publish命令向訂閱者傳送訊息,redis-server會使用指定的頻道作為鍵,在它所維護的channel字典中查詢記錄了訂閱這個頻道的所有客戶端的連結串列,遍歷所有的連結串列,將訊息發給所有的訂閱者。
Pub/Sub從字面來理解就是釋出(publish)與訂閱(subscribe),在redis中,可以設定對某一個key值進行訊息釋出及訊息訂閱,當一個key上進行了訊息釋出後,所有訂閱它的客戶端都會收到相應的資訊,這一功能的最明顯的用法就是實時訊息系統,即時聊天,群聊等功能。
稍微複雜的場景可以使用訊息中介軟體MQ來做。
Redis主從複製
主從複製,是指將一臺redis伺服器上的資料,複製到其它redis伺服器上,前者稱為主節點(master/leader),後者稱為從節點(slave/follower);資料複製是單向的,只能從主節點到從節點,Master以寫為主,Slave以讀為主。
預設情況下,每臺redis伺服器都是主節點,且一個主節點可以有多個從節點或沒有從節點,但一個從節點只能由一個主節點。
主從複製的作用主要包括:
- 資料冗餘:主從複製實現了資料的熱備份,是持久化之外的一種資料冗餘方式。
- 故障恢復:當主節點出問題時,可由從節點提供服務,實現快速的故障恢復,實際上是一種服務的冗餘。
- 負載均衡:在主從複製的基礎上,配合讀寫分離,可以有主節點提供寫服務,由從節點提供讀服務(即寫redis資料時應用連線主節點,讀redis資料時應用連線從節點),分擔伺服器負載,尤其是在寫少讀多的場景下,通過多個從節點分擔負載,可以大大提高redis伺服器的併發量。
- 高可用(叢集)基石:除了上述的作用外,主從複製還是哨兵和叢集能夠實施的基礎,因此說主從複製是redis高可用的基礎。
一般來說,要將redis運用於工程專案中,只使用一臺redis是萬萬不能的,原因如下:
- 從結構上,單個redis伺服器會發生單點故障,並且一臺伺服器需要處理所有的請求負載,壓力較大。
- 從容量上,單個redis伺服器記憶體容量有限,就算一套伺服器記憶體容量256g,也不能將所有的記憶體用作redis的記憶體,一般來說,單臺redis最大使用記憶體不超過20g。
電商網站上的商品,一般都是一次上傳,無數次瀏覽的,也就是”多讀少寫“。
環境配置
只配置從庫,不用配置主庫!
127.0.0.1:6379> info replication #檢視當前庫的資訊
# Replication
role:master # 角色
connected_slaves:0 # 美喲從機
master_replid:df9e0065e32fd82d44fc257454f2101cecd2aa10
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
複製3個配置檔案,然後修改對應的資訊。
- 埠號
- pid 名字
- 日誌名字
- dump.rdb 名字
修改完後啟動三個redis服務,檢視程式資訊

一主二從
預設情況下,每臺redis伺服器都是主節點,我們只用配置從機。
認老大!一主(79)二從(80,81)
從機中進行配置 SLAVEOF (80,81都這樣配置)
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 # SLAVEOF host 6379
OK
127.0.0.1:6380> info replication
# Replication
role:slave # 當前角色 從機
master_host:127.0.0.1 # 主機的資訊
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:0
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:d07d76bbf57965ec5eb6dfa2696c7fb50a1dab70
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:0
127.0.0.1:6380>
在主機中檢視
127.0.0.1:6379> info replication
# Replication
role:master # 主機
connected_slaves:2 #連個從機
slave0:ip=127.0.0.1,port=6380,state=online,offset=294,lag=0 # 從機的資訊
slave1:ip=127.0.0.1,port=6381,state=online,offset=294,lag=0 # 從機的資訊
master_replid:d07d76bbf57965ec5eb6dfa2696c7fb50a1dab70
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:294
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:294
127.0.0.1:6379>
真實的主從配置應該在配置檔案中配置,才會是永久的,這裡使用的是命令,就是暫時的。
# 配置檔案中配置
# replicaof <masterip> <masterport>
主機可以寫,從機不能寫只能讀!主機中的所有資料都會被從機儲存。
主機
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379>
從機
127.0.0.1:6380> get k1
"v1"
127.0.0.1:6380> set k2 v2
(error) READONLY You can't write against a read only replica.
127.0.0.1:6380>
測試:主機斷開連線,從機依舊是連線主機的,但是沒有寫操作,這個時候,如果主機回來了,從機依然可以獲取主機寫進去的資訊。
如果是使用命令列配置的從機,重啟後就會變回主機。只要變為從機,就會立即從主機中獲取值!
複製原理
Slave啟動成功連線到Master後會傳送一個sync同步命令。
Master接到命令,啟動後臺的存檔程式,同時收集所有接收到的用於修改資料集命令,在後臺程式執行完畢後,master將傳送整個資料檔案到slave,並完成一次完全同步。
全量複製:slave在接收到資料後,將其存檔並載入到記憶體中。
增量複製:master繼續將新的所有收集到的修改命令依次傳給slave,完成同步。
但是隻要重新連線master,一次完全同步(全量複製)將被自動執行。
層層鏈路
6379---6380---6381,三個節點依次連線,此時6380依舊是從節點。
這時候也可以完成主從複製!
這種情況下,如果6379掛掉,就需要手動配置一個主節點,使用 slaveof no one 使自己成為主節點。其它節點就可以手動連線到這個主節點(手動)。如果6379恢復了,就需要重新連線配置。
哨兵模式
自動選舉老大的模式!
主從切換技術的方法是:當主伺服器當機後,需要手動把一臺伺服器切換為主伺服器,這就需要人工干預,費時費力,而且還會造成一段時間的服務不可用,這種方式在實際中不太可取,所以,就有了哨兵模式,Redis從2.8開始正式提供了Sentinel(哨兵)架構來解決這個問題。
手動設定主節點的自動版, 能夠監控後臺主機是否故障,如果故障了可以根據投票數選舉一個從節點變為主節點。
哨兵是一種特殊的模式,Redis提供了哨兵的命令,哨兵是一個獨立的程式,可以獨立執行,其原理是 哨兵通過傳送命令,等待Redis伺服器響應,從而監控執行的多哦個Redis例項。
一個哨兵對服務監控可能會出現問題,對此,我們可以使用多個哨兵進行監控,各個哨兵之間也會互相監控,這樣就會形成多哨兵的模式。

哨兵程式的工作方式
- 每個Sentinel(哨兵)程式以每秒鐘一次的頻率向整個叢集中的Master主伺服器,Slave從伺服器以及其他Sentinel(哨兵)程式傳送一個 PING 命令。
- 如果一個例項(instance)距離最後一次有效回覆 PING 命令的時間超過 down-after-milliseconds 選項所指定的值,則這個例項會被 Sentinel(哨兵)程式標記為主觀下線(SDOWN)。
- 如果一個Master主伺服器被標記為主觀下線(SDOWN),則正在監視這個Master主伺服器的所有Sentinel(哨兵)程式要以每秒一次的頻率確認Master主伺服器的確進入了主觀下線狀態。
- 當有足夠數量的 Sentinel(哨兵)程式(大於等於配置檔案指定的值)在指定的時間範圍內確認Master主伺服器進入了主觀下線狀態(SDOWN), 則Master主伺服器會被標記為客觀下線(ODOWN)。
- 在一般情況下, 每個Sentinel(哨兵)程式會以每 10 秒一次的頻率向叢集中的所有Master主伺服器、Slave從伺服器傳送 INFO 命令。
- 當Master主伺服器被 Sentinel(哨兵)程式標記為客觀下線(ODOWN)時,Sentinel(哨兵)程式向下線的 Master主伺服器的所有 Slave從伺服器傳送 INFO 命令的頻率會從 10 秒一次改為每秒一次。
- 若沒有足夠數量的 Sentinel(哨兵)程式同意 Master主伺服器下線, Master主伺服器的客觀下線狀態就會被移除。若 Master主伺服器重新向 Sentinel(哨兵)程式傳送 PING 命令返回有效回覆,Master主伺服器的主觀下線狀態就會被移除。
測試:
我們目前的模式是一主二從。
配置失敗配置檔案
# sentinel monitor 被監控的名稱(名稱自己設定) host port 達到多少票數後開始選舉(即客觀下線)
sentinel monitor myredis 127.0.0.1 6379 1
啟動哨兵
[root@zhourui bin]# redis-sentinel zconfig/sentinel.conf
1971005:X 06 Jan 2021 20:41:13.713 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1971005:X 06 Jan 2021 20:41:13.713 # Redis version=6.0.9, bits=64, commit=00000000, modified=0, pid=1971005, just started
1971005:X 06 Jan 2021 20:41:13.713 # Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 6.0.9 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 1971005
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
1971005:X 06 Jan 2021 20:41:13.714 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1971005:X 06 Jan 2021 20:41:13.717 # Sentinel ID is bc602d0d0bcb457a46c117f1b87970ec13b67f73
1971005:X 06 Jan 2021 20:41:13.717 # +monitor master myredis 127.0.0.1 6379 quorum 1
1971005:X 06 Jan 2021 20:41:13.717 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:41:13.719 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
# 主機掛掉後重新選取主機的日誌,新選舉的主節點是 6381
1971005:X 06 Jan 2021 20:44:12.650 # +sdown master myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:12.650 # +odown master myredis 127.0.0.1 6379 #quorum 1/1
1971005:X 06 Jan 2021 20:44:12.650 # +new-epoch 1
1971005:X 06 Jan 2021 20:44:12.650 # +try-failover master myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:12.653 # +vote-for-leader bc602d0d0bcb457a46c117f1b87970ec13b67f73 1
1971005:X 06 Jan 2021 20:44:12.653 # +elected-leader master myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:12.653 # +failover-state-select-slave master myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:12.719 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:12.719 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:12.785 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:13.054 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:13.054 # +failover-state-reconf-slaves master myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:13.110 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:14.082 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:14.082 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:14.153 # +failover-end master myredis 127.0.0.1 6379
1971005:X 06 Jan 2021 20:44:14.153 # +switch-master myredis 127.0.0.1 6379 127.0.0.1 6381
1971005:X 06 Jan 2021 20:44:14.154 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6381
1971005:X 06 Jan 2021 20:44:14.154 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381
1971005:X 06 Jan 2021 20:44:44.157 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381
如果主機此時回來了,只能歸併到新的主機下當作從機,這就是哨兵模式的規則!
哨兵模式
優點:
- 哨兵模式,基於主從複製模式,所有的主從配置的優點,它都有
- 主從可以切換,故障可以轉移,系統的可用性就會更好
- 哨兵模式就是主從模式的升級,從手動到自動,更加健壯
缺點:
- Redis不好線上擴容,叢集容量一旦達到上線,線上擴容就十分困難
- 哨兵模式的配置比較繁瑣,裡面由很多的配置
哨兵模式的全部配置:
# 哨兵sentinel例項的埠 預設 26379 哨兵叢集需配置每個哨兵的埠
port 26379
# 哨兵的工作目錄
dir /tmp
#哨兵sentinel監控 redis 主節點的 ip port
#master-name 自己命名主節點的名字
#quorum 配置多少個sentinel統一認為master節點失聯,就客觀認為主節點失聯了
#sentinel moniter <host> <port> <quorum>
sentinel monitor 127.0.0.1 6379 1
#當redis中開啟了requirepass foobared授權密碼 這樣所有連線redis例項的客戶端都需要提供密碼
#設定哨兵連線主從的密碼 注意必須為主從設定一樣的密碼
#sentinel auth-pass <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
#設定多少秒之後,主節點沒有應答哨兵,此時,哨兵主觀認為主節點下線 預設是30秒
#sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
#這個配置指定了在發生failover主裝置切換時最對哦可以有多少個slave同時對新的master進行同步
這個數字越小,完成failover的時間越長
但是如果這個數字越大,就意味著,有很多的slave因為replication而不可用
可將這個值設為1,可保證每次只有一個slave處於不能處理命令請求的狀態
#sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
#故障轉移超時時間,預設3分鐘
#sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
#配置當某一事件發生時所需要執行的指令碼,可以通過指令碼來通知管理員,例如當系統執行不正常時發郵件給管理員
#sentinel notification-script <master-name> <script-name>
sentinal notification-script mymaster /var/redis/notify.sh
#客戶端重新配置主節點引數指令碼
#當一個master因為failover而發生改變時,這個指令碼會被呼叫,通知相關客戶端關於master地址已經發生改變的資訊
#sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
Redis快取穿透和雪崩
服務的高可用問題!
Redis快取的使用,極大地提高了應用程式的效率和效能,特別是資料查詢方面,但同時,它也帶來了一些問題,其中,最緊要的問題,就是資料一致性的問題,從嚴格意義上講,這個問題無解。如果對資料的一致性要求很高,那麼就不能使用快取。
另外的一些典型問題就是,快取穿透,快取雪崩和快取擊穿,目前,業界都有比較流行的解決方案。
快取穿透(查不到)
快取穿透:使用者想要查詢一個資料,發現redis記憶體資料庫中沒有,也就是快取沒有命中,於是向持久層資料庫中查詢,發現也沒有,於是查詢失敗。當使用者很多的時候,快取都沒有命中(秒殺),於是都去請求了持久層資料庫,這會給持久層資料庫造成很大的壓力,也就是出現了快取穿透!
解決方案:
布隆過濾器:布隆過濾器是一種資料結構,對所有可能查詢的引數用hash儲存,在控制層先進行校驗,不符合則丟棄,從而避免了對底層儲存系統的儲存壓力。
快取空物件:當儲存層未命中後,即返回的空物件也將它儲存起來,同時設定一個過期時間,之後再訪問這個資料將會從快取中讀取,保護了後端資料來源。
但是這種方法會存在以下問題:
如果空值能被快取起來,這就意味著快取需要更多的空間來儲存空值的鍵。
即使對空值設定了過期時間,還是會存在快取層和儲存層的資料有一段時間不一致,這對需要保證一致性的業務會有影響。
快取擊穿(量太大,快取過期)
快取擊穿:是指一個key非常熱點,在不停的扛著大併發,大併發集中對這一個點進行訪問,當這個key在失效的瞬間,持續的大併發就會擊穿快取,直接請求資料庫,就像在一個屏障上鑿開了一個洞。
當某個key在過期的瞬間,有大量的請求併發訪問,這類資料一般是熱點資料,由於快取過期,會同時訪問資料庫來查詢最新資料,並且回寫快取,會導致資料庫瞬間壓力增大。
解決方案:
設定熱點資料永不過期:
從快取層面來看,沒有設定過期時間,所以不會出現熱點key過期產生的問題。
加互斥鎖:
分散式鎖:使用分散式鎖 ,保證對每個key只有一個執行緒去查詢後端服務,其它執行緒沒有獲得分散式鎖的許可權,因此只需要等待即可,這種方式將高併發的壓力轉移到了分散式鎖,因此對分散式鎖的考驗很大。
快取雪崩
快取雪崩:是指在某一個時間段,快取集中過期失效,redis當機。
比如,雙十一時,將一批商品集中放入了快取,假設快取一小時,這批商品的快取過期,那麼對這批商品的訪問查詢,都落到了資料庫上,對於資料庫而言,就會產生週期性的壓力峰波,於是所有的請求都會到達儲存層,儲存層的呼叫量會暴增,造成資料庫掛掉的情況。
其實集中過期,倒不是非常致命,比較致命的快取雪崩,是快取伺服器某個節點當機或斷網,因為自然形成的快取雪崩,一定是在某個時間段集中建立快取,這個時候,資料庫也是可以頂住壓力的,無非是對資料產生週期性的壓力而已,而快取服務節點的當機,對資料庫伺服器造成的壓力是不可預知的,很有可能瞬間把資料庫壓垮。
解決方案
redis高可用
這個思想的含義是,既然redis有可能掛掉,那就多設幾臺redis,這樣一臺掛掉後其它的還可以繼續工作,其實就是搭建叢集。(異地多活)
限流降級
這個解決方案的思想是,在快取失效後,通過加鎖或者佇列來控制讀資料庫寫快取的執行緒數量,比如某個key只允許一個執行緒查詢資料寫快取,其它執行緒等待。
資料預熱
資料預熱的含義就是在正式部署前,把可能的資料預先訪問一遍,這樣部分可能大量訪問的資料就會載入到快取中,在即將發生大併發訪問前手動觸發載入快取不同的key,設定不同的過期時間,讓快取失效的時間儘量均勻。