Learning Spark——使用Intellij Idea開發基於Maven的Spark程式
本文主要講解如何使用Idea開發Spark程式,使用Maven作為依賴管理,當然也可以使用SBT,但是由於一直寫Java程式習慣用Maven了,所以這裡使用Maven。
1、下載安裝Jdk、Scala、Mave
Jdk、Maven安裝方法略過,搞Java的應該都會,這裡講一下Scala的安裝,其實和Java差不多。
首先下載:https://www.scala-lang.org/download/
按步驟安裝,安裝完成以後配置Scala的環境變數即可:
SCALA_HOME=D:\scala
PATH=......;%SCALA_HOME%\bin進入CMD輸入:scala -version

2、下載Idea並安裝Scala外掛
下載地址隨便上網找一下就可以,不建議官網下載,速度太慢。
老哥用的是2016版本的,需要的在這下載,裡面有安裝包和破解方法,請叫我雷鋒
連結:http://pan.baidu.com/s/1gfvG3R1 密碼:9p3y
下載完成以後按照提示進行配置。
偏好暗黑主題
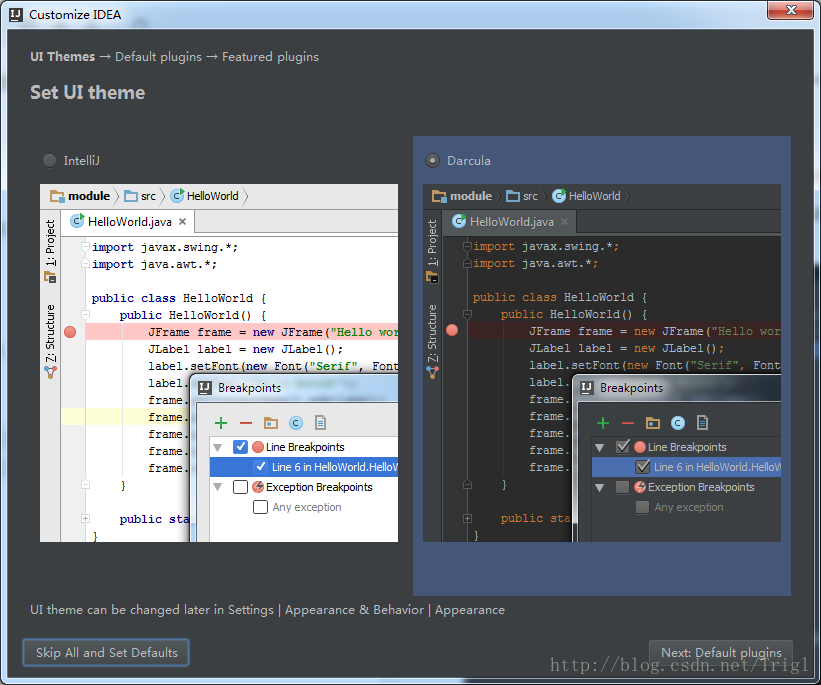
預設
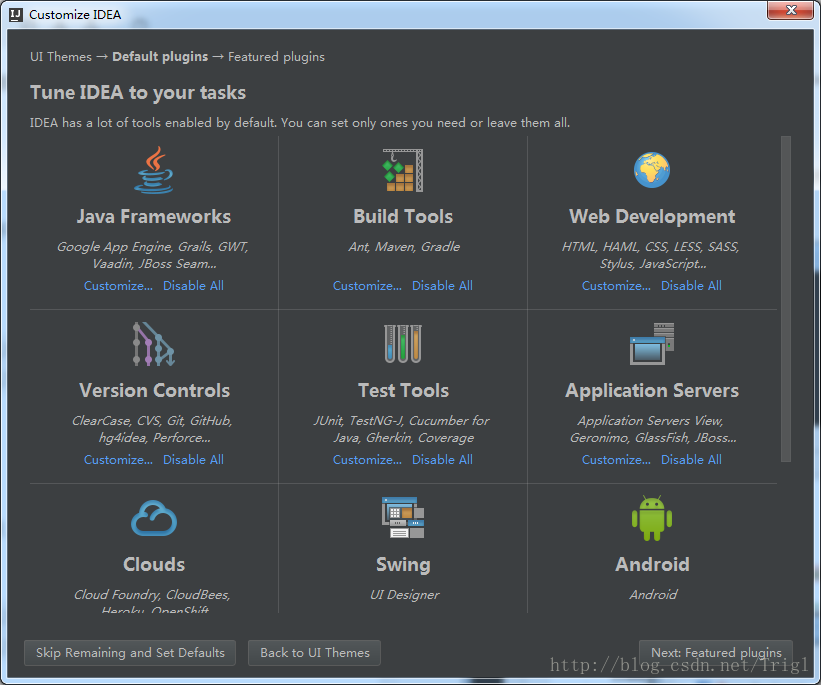
下載Scala外掛
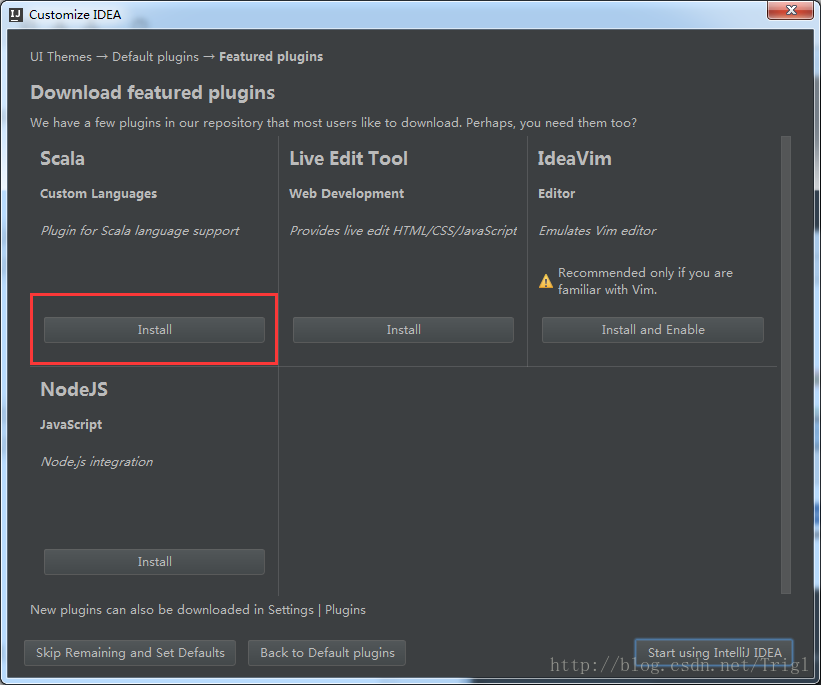
設定Jdk
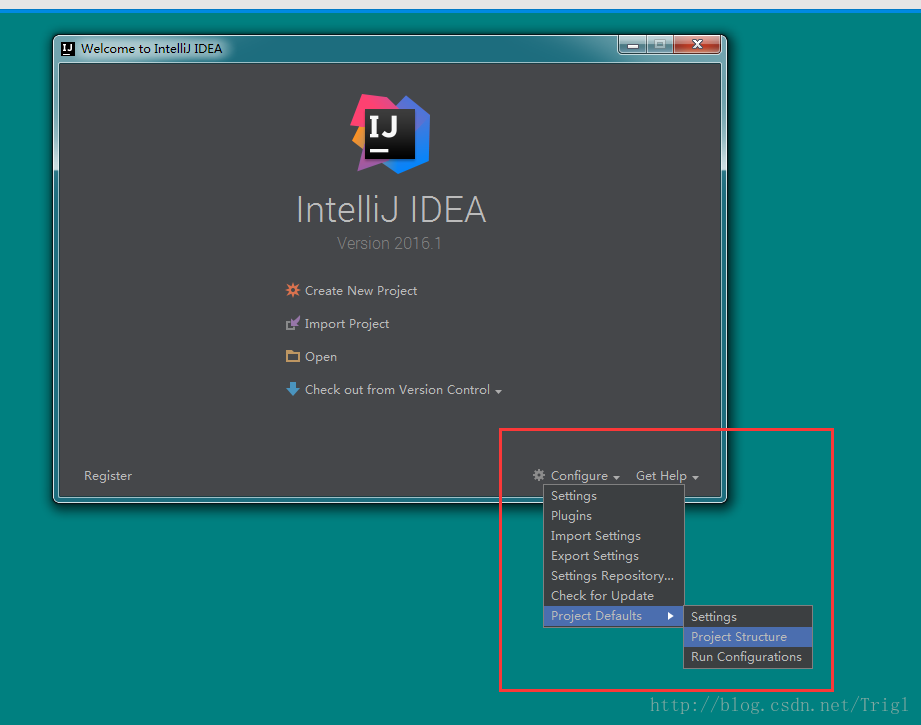
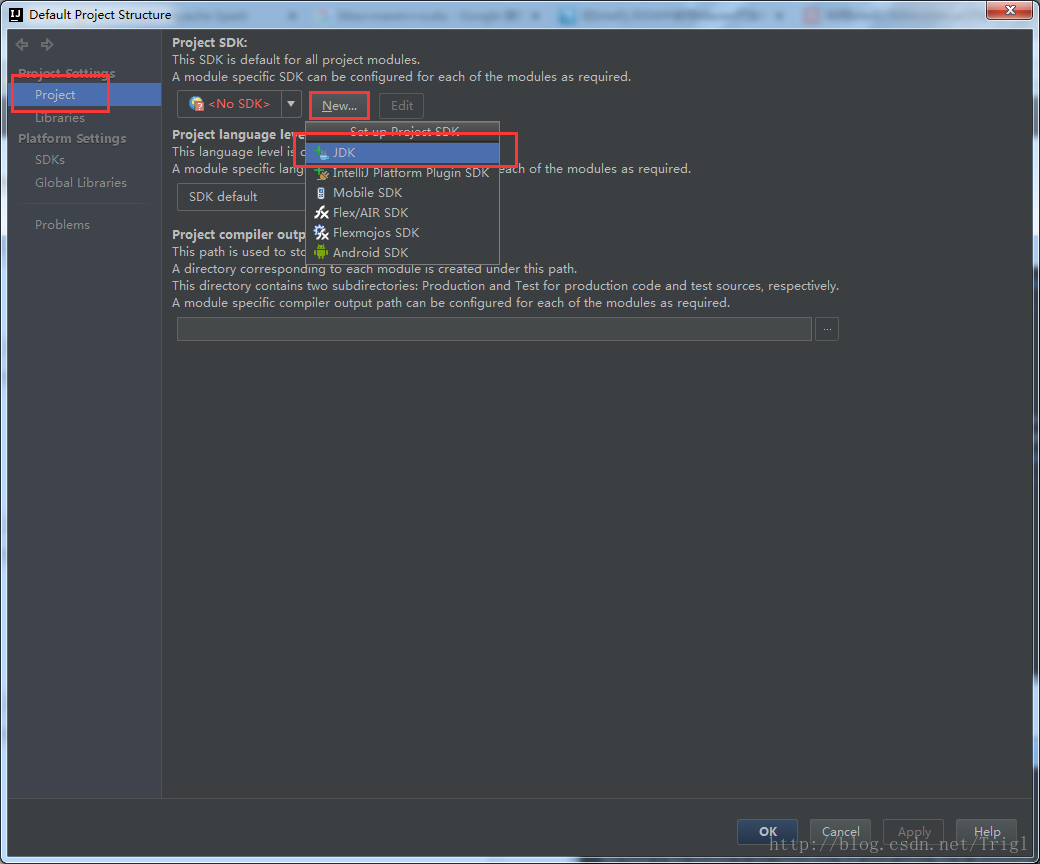
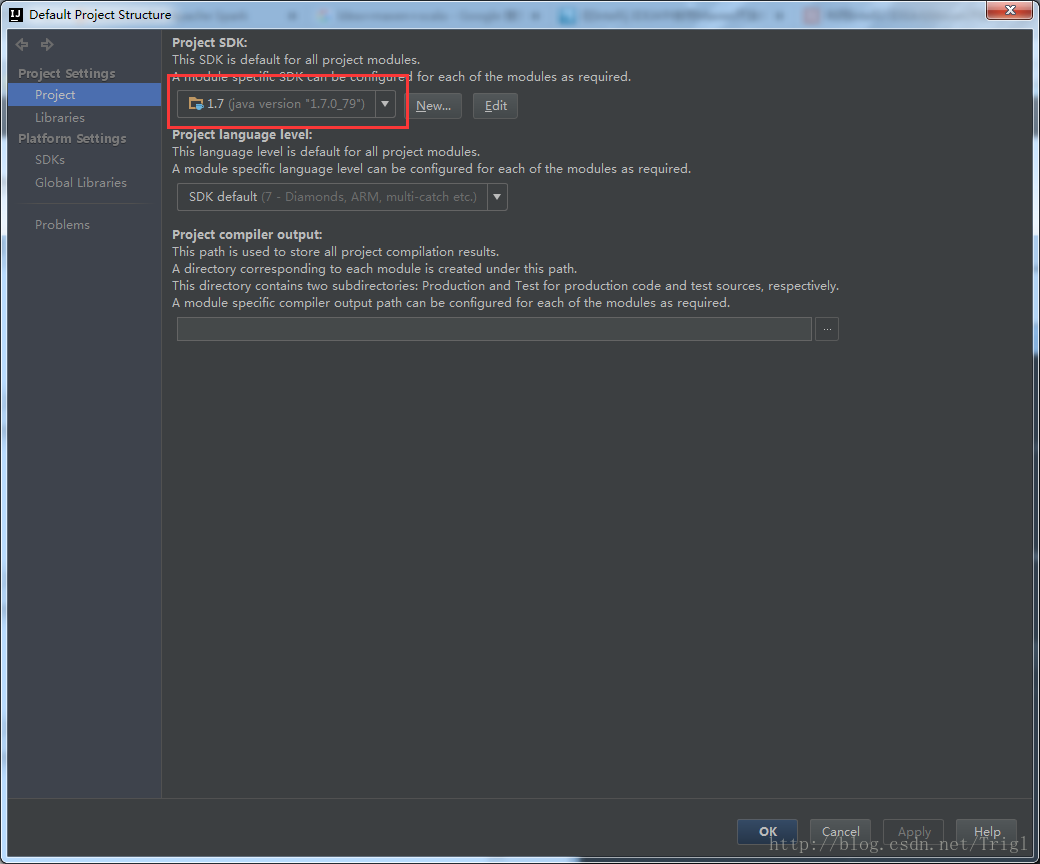
設定Scala
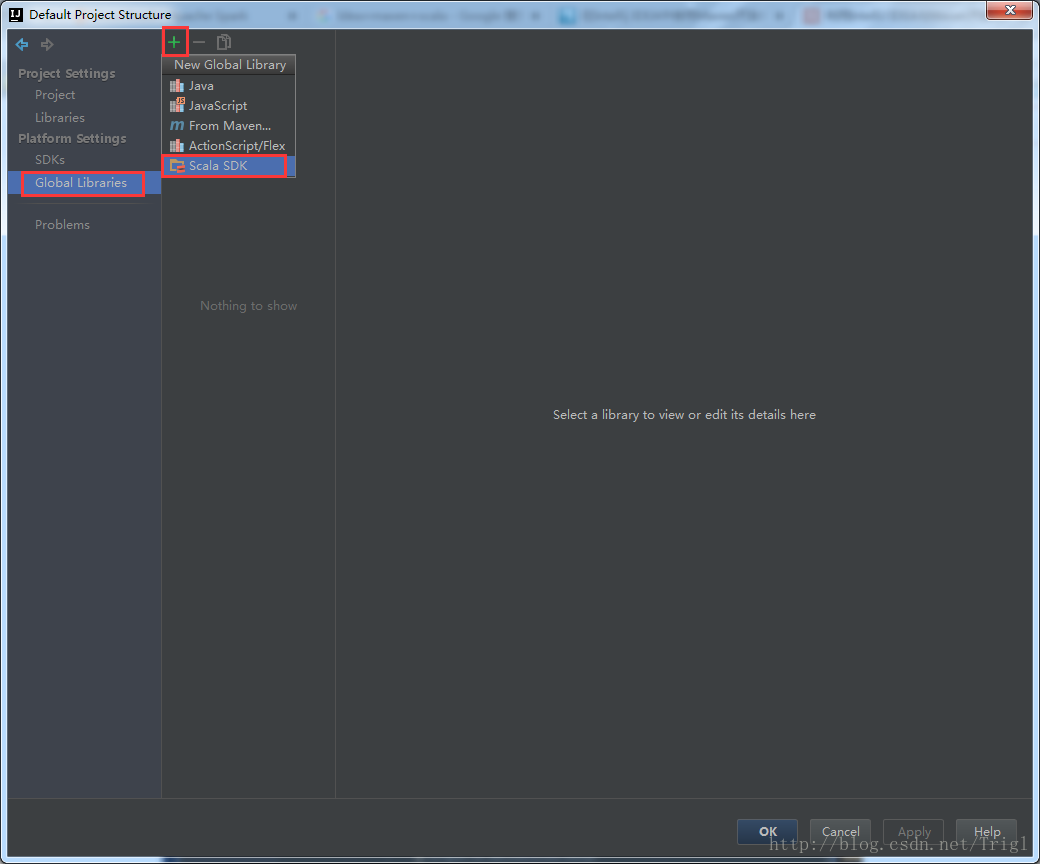
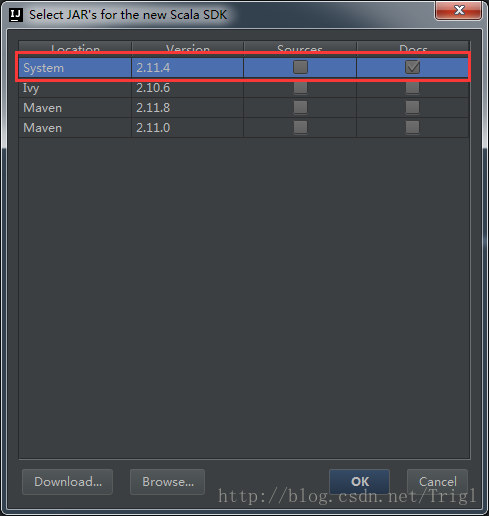
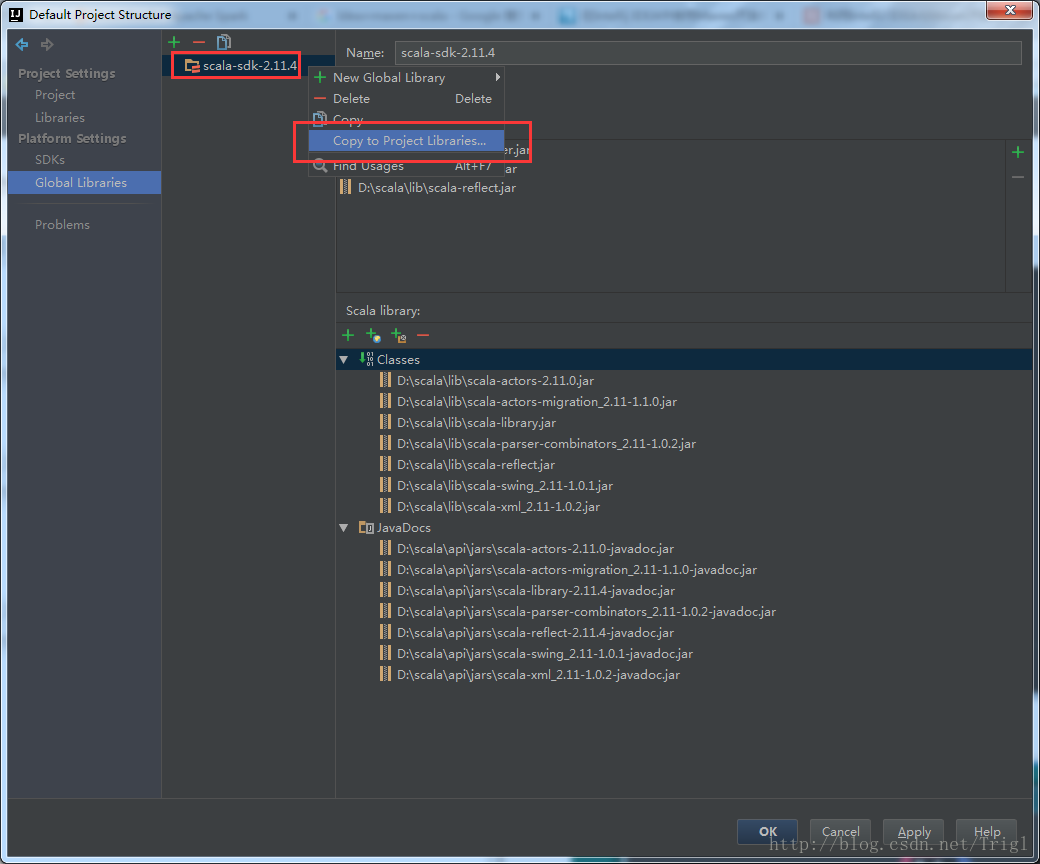
3、建立一個maven-scala工程

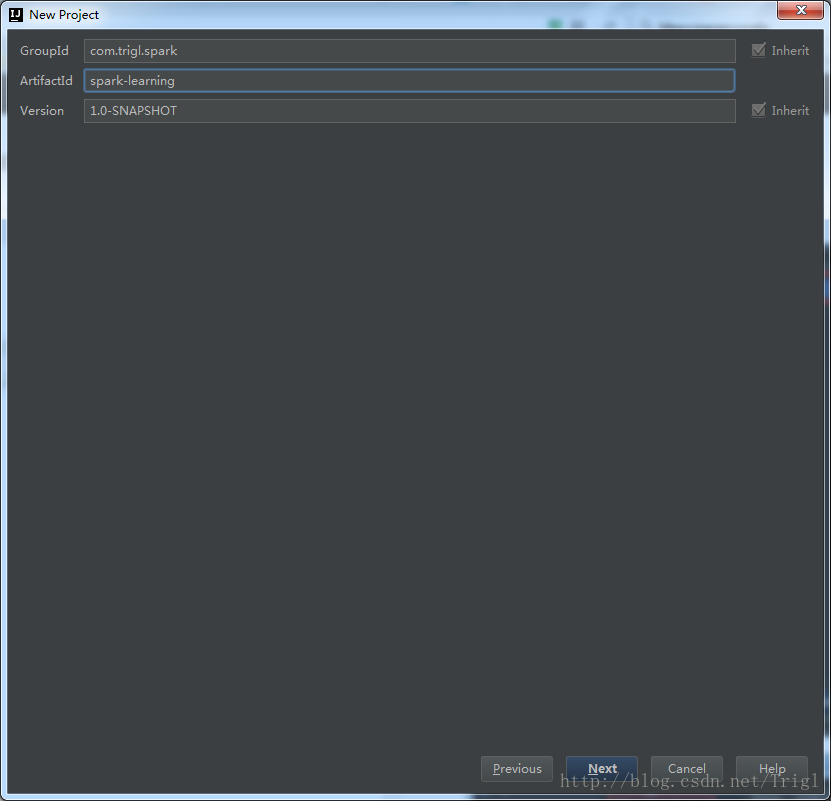
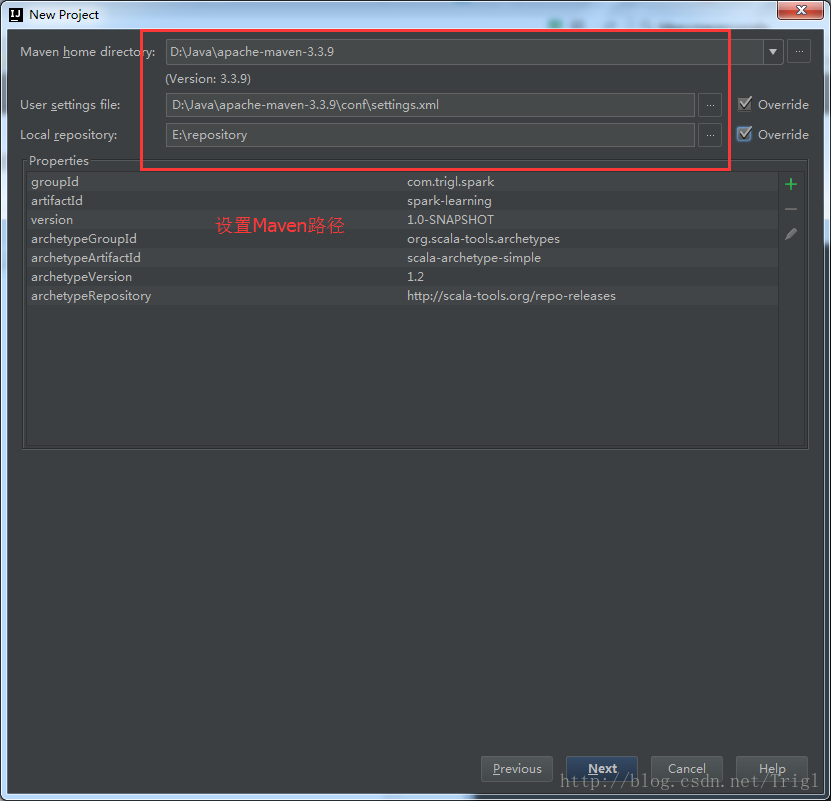
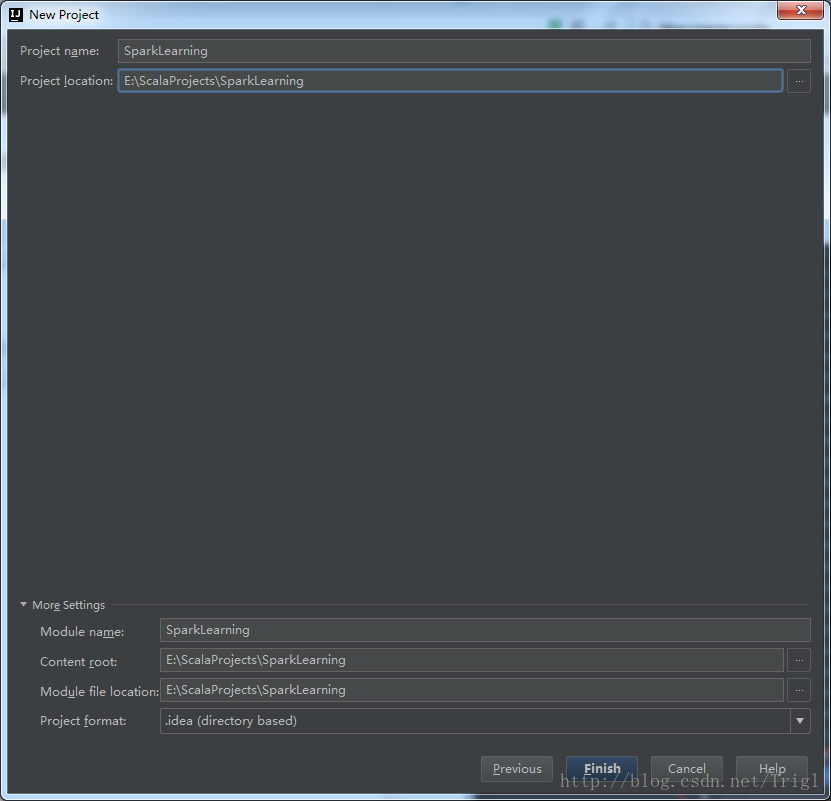
4、修改pom.xml
首先將scala.version修改成本機安裝的Scala版本,其次加入hadoop以及spark所需要的依賴,完整的內容如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trigl.spark</groupId>
<artifactId>spark-learning</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.4</scala.version>
<spark.version>2.0.0</spark.version>
<spark.artifact>2.11</spark.artifact>
<hbase.version>1.2.2</hbase.version>
<dependency.scope>compile</dependency.scope>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>5、寫Spark測試程式
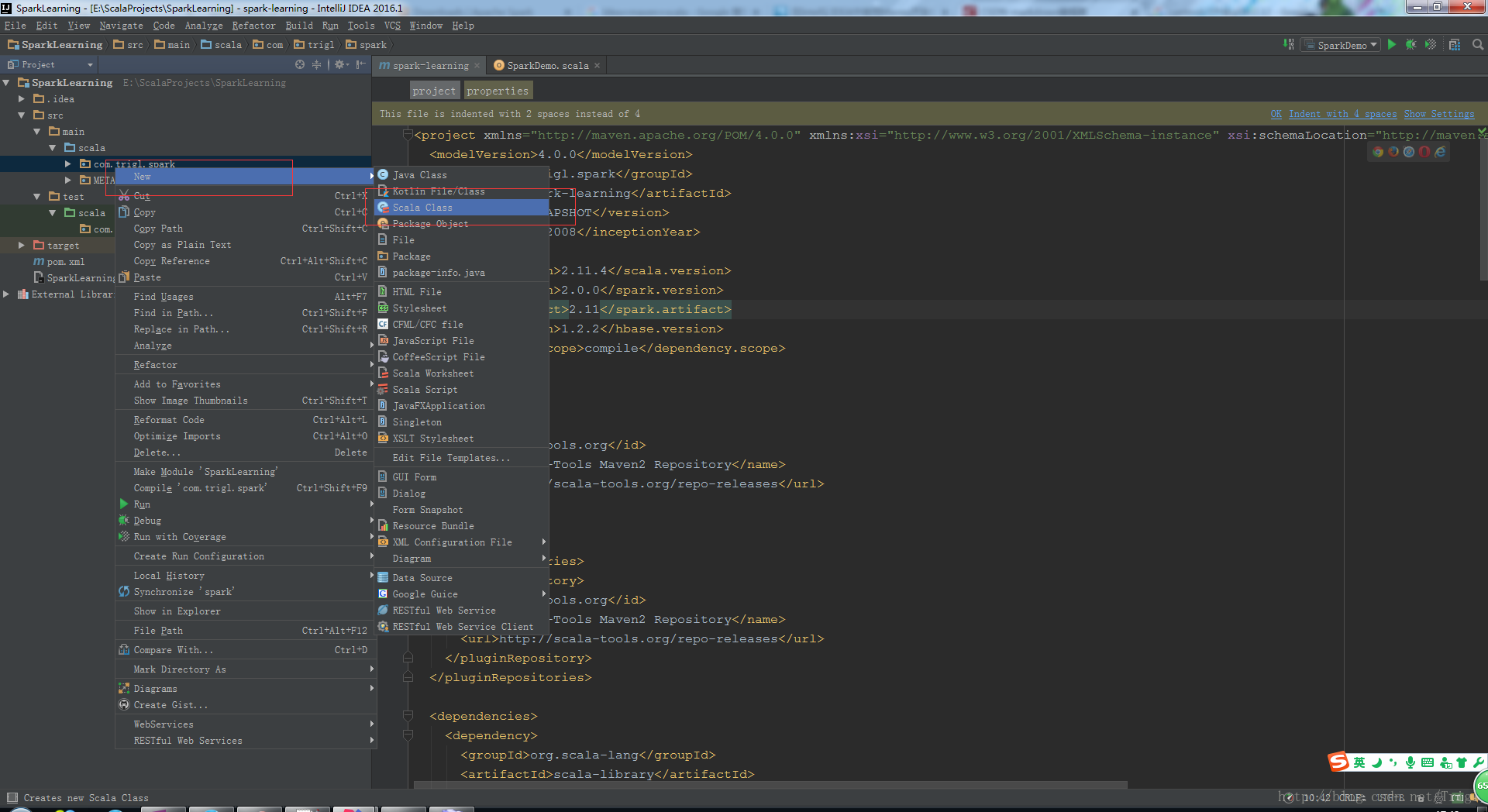
將系統生成的Scala程式碼刪除,我們自己新建一個Scala Object
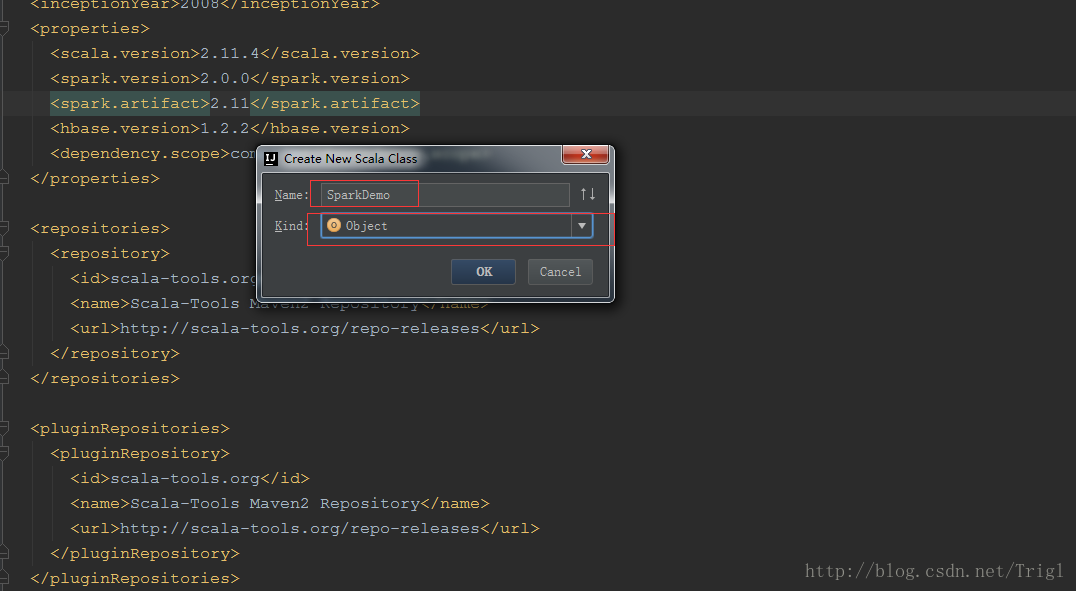
SparkDemo.scala程式碼如下:
package com.trigl.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* 統計hdfs檔案行數
* Created by Trigl on 2017/4/20.
*/
object SparkDemo {
// args:/test/test.log
def main(args: Array[String]) {
// 設定Spark的序列化方式
System.setProperty("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 初始化Spark
val sparkConf = new SparkConf().setAppName("CountDemo")
val sc = new SparkContext(sparkConf)
// 讀取檔案
val rdd = sc.textFile(args(0))
println(args(0) + "的行數為:" + rdd.count())
sc.stop()
}
}6、打包執行
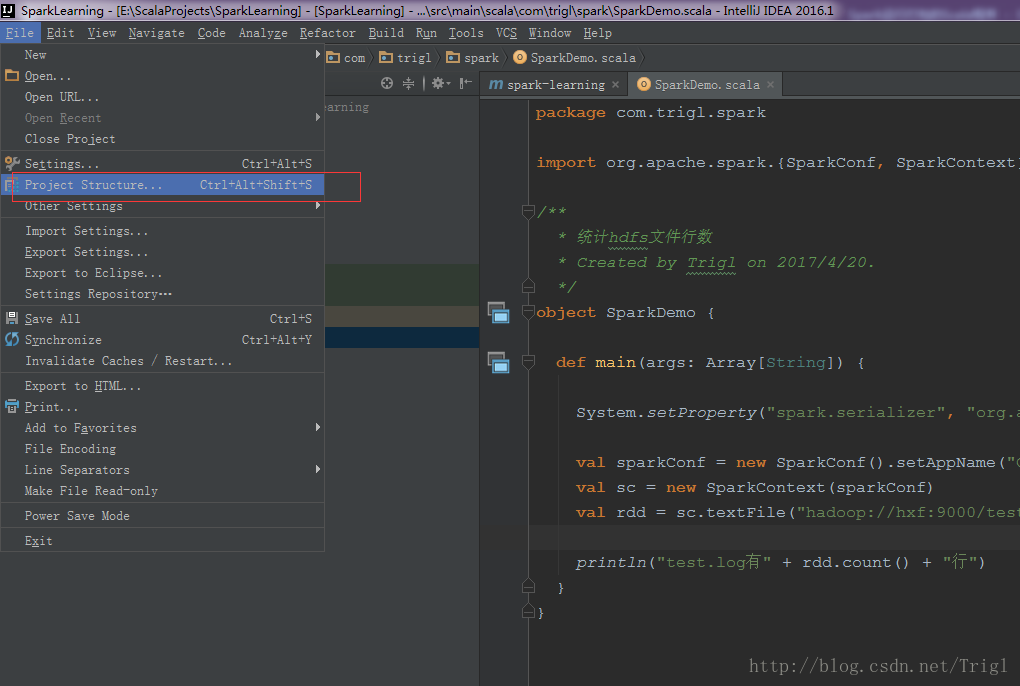
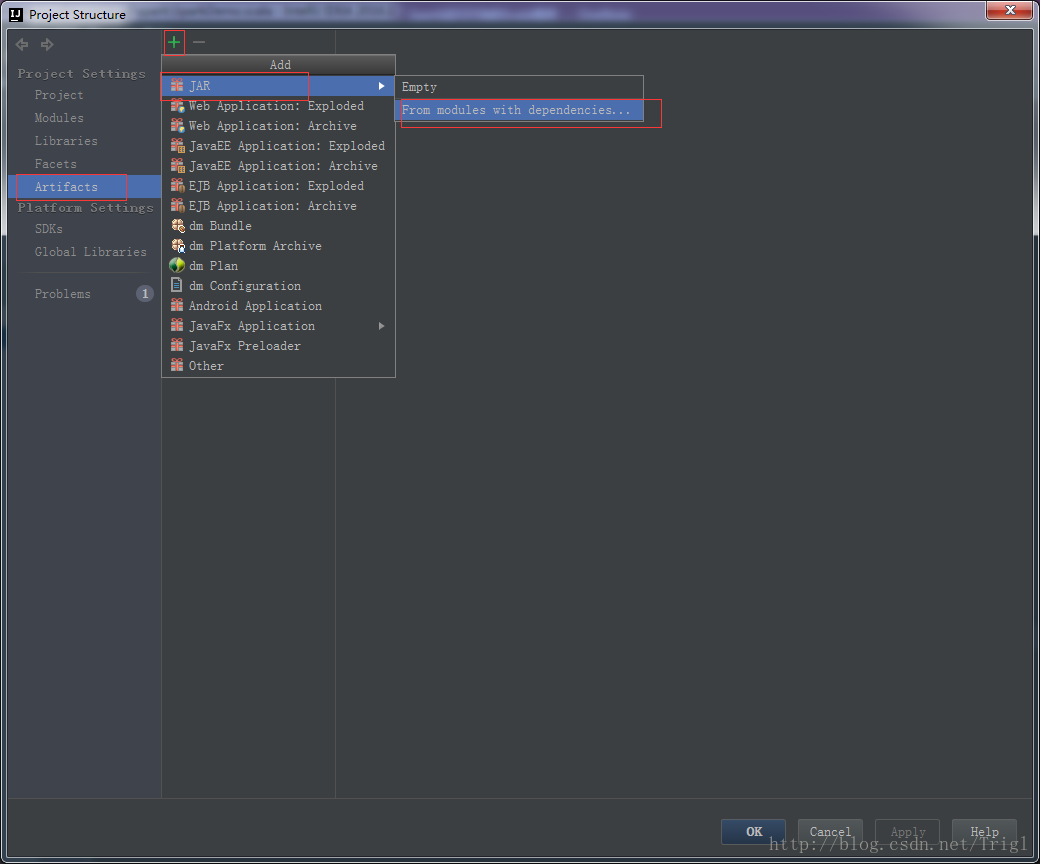
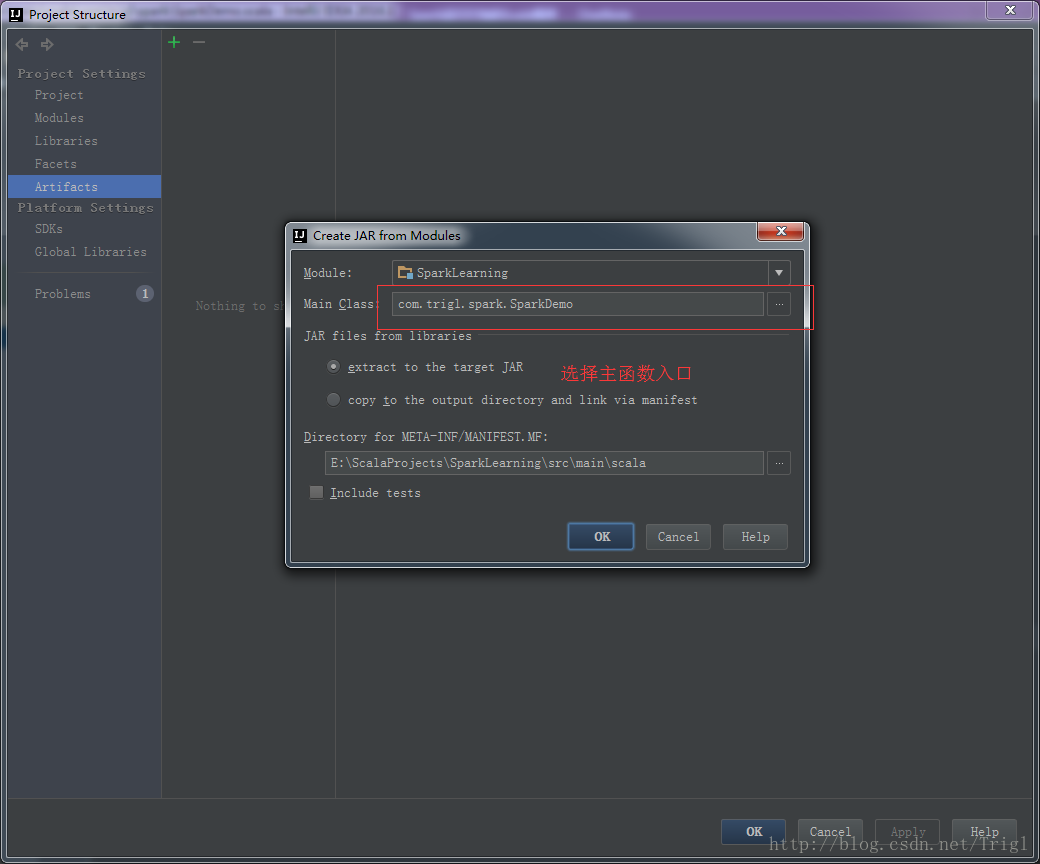
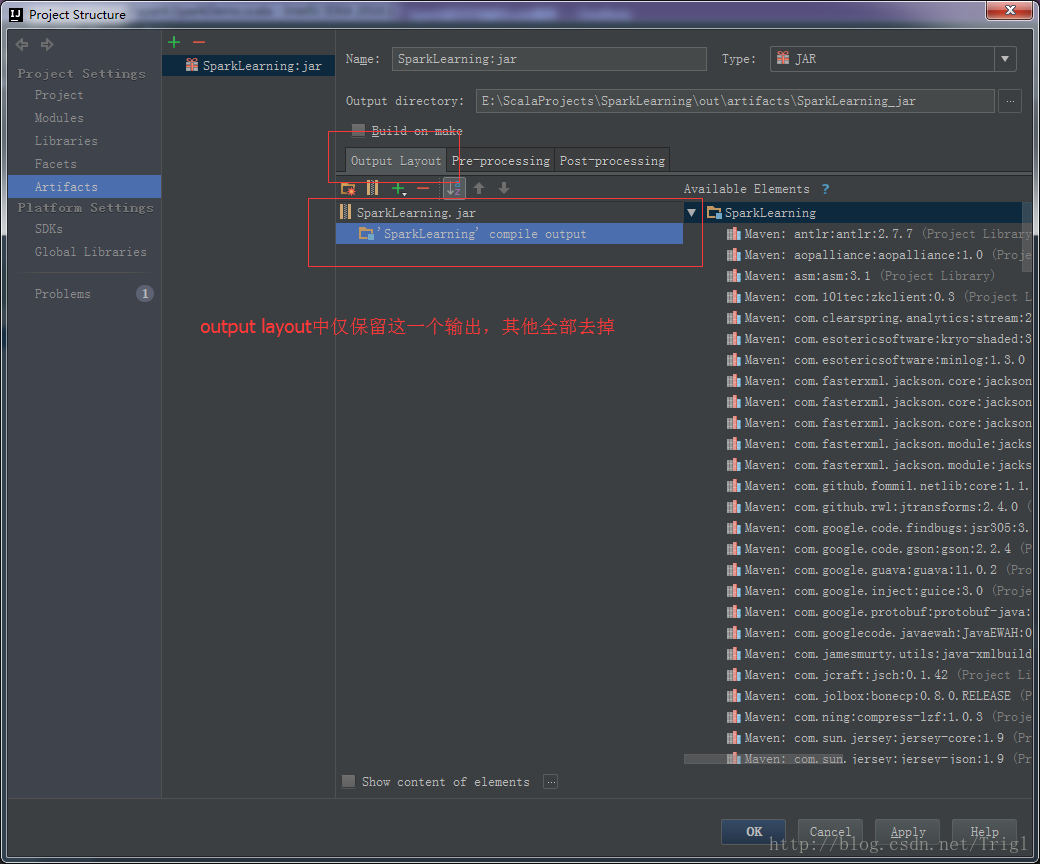
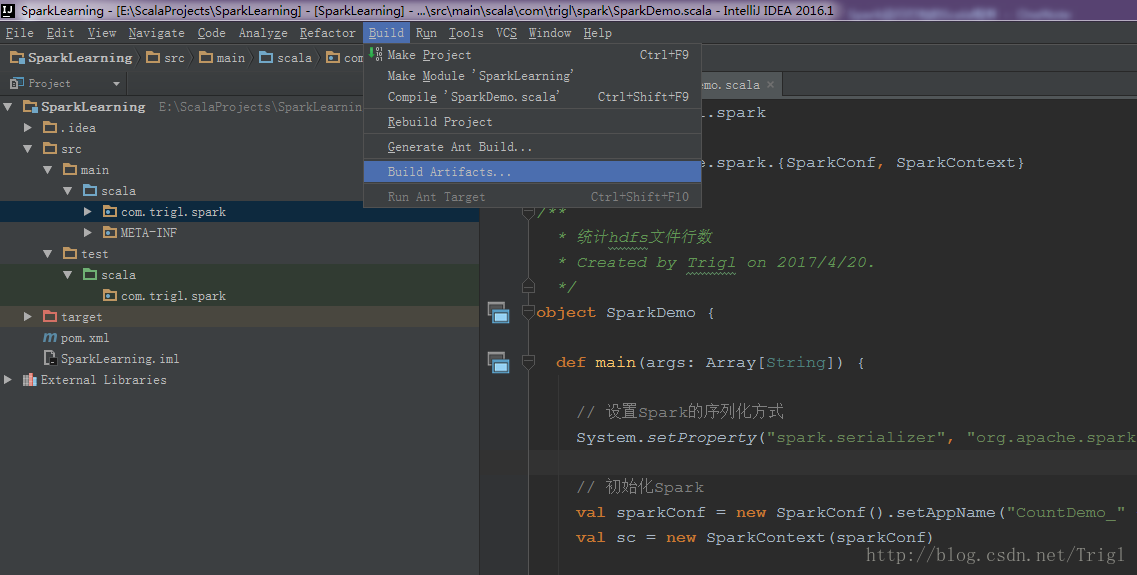
輸出打包檔案:點選選單Build->Build Artifacts,彈出選擇動作,選擇Build或者Rebuild動作
打包後的jar包在專案的out目錄下面,將此jar包複製到執行Spark所在的主機上,然後在該機器執行以下命令即可:
nohup /data/install/spark-2.0.0-bin-hadoop2.7/bin/spark-submit --master spark://hxf:7077 --executor-memory 1G --executor-cores 4 --class com.trigl.spark.SparkDemo /home/hadoop/jar/SparkLearning.jar /test/test.log >> /home/hadoop/logs/sparkDemo.log &結果如下:
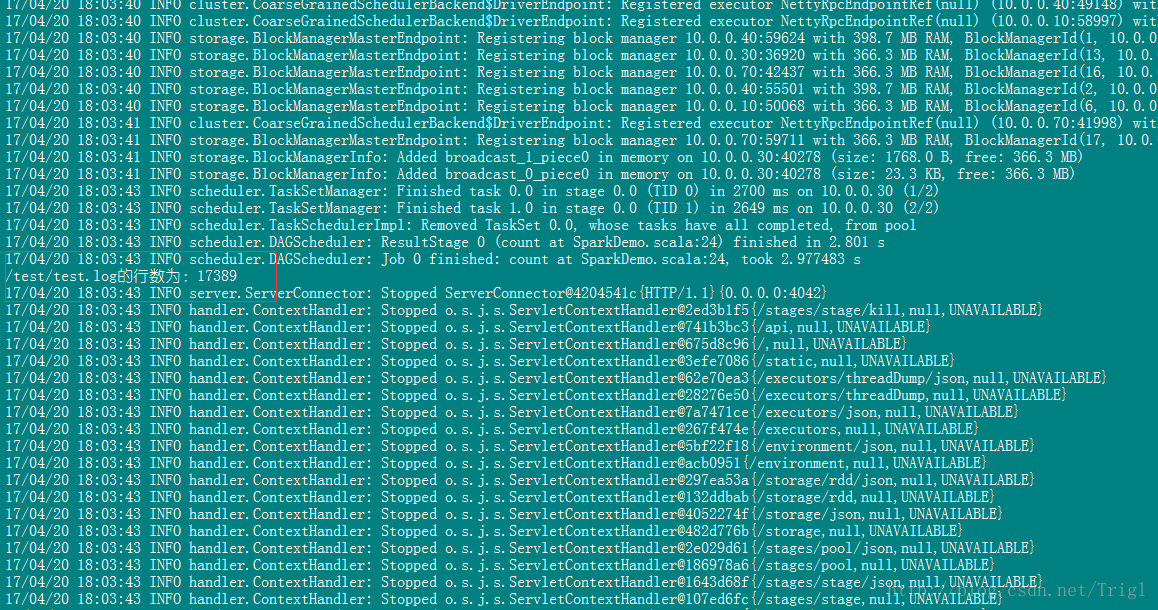
這就是我們編寫的第一個Spark程式,非常簡單,大牛勿噴,但這是萬里長征第一步,至少程式已經能跑了不是嗎?後續我會循序漸進介紹Spark的知識,歡迎交流指正。
相關文章
- IDEA使用Maven搭建spark開發環境(scala)IdeaMavenSpark開發環境
- 使用Intellij IDEA遠端除錯Spark程式IntelliJIdea除錯Spark
- 使用Intellij Idea編寫Spark應用程式(Scala+SBT)IntelliJIdeaSpark
- Spark Machine Learning 04 構建基於Spark的推薦引擎 (待完善)SparkMac
- Spark修煉之道(進階篇)——Spark入門到精通:第三節 Spark Intellij IDEA開發環境搭建SparkIntelliJIdea開發環境
- 【spark筆記】在idea用maven匯入spark原始碼Spark筆記IdeaMaven原始碼
- 本地開發spark程式碼上傳spark叢集服務並執行(基於spark官網文件)Spark
- 在Intellij中開發Spark--demoIntelliJSpark
- IDEA開發Spark應用並提交本地Spark 2.1.0 standIdeaSpark
- 使用IntelliJ IDEA編寫Scala在Spark中執行IntelliJIdeaSpark
- 在IntelliJ IDEA中建立和執行java/scala/spark程式IntelliJIdeaJavaSpark
- Spark面試題(七)——Spark程式開發調優Spark面試題
- spark開發環境搭建intellij+Scala+sbtSpark開發環境IntelliJ
- IDEA開發Spark應用實戰(Scala)IdeaSpark
- 使用 IntelliJ IDEA 匯入 Spark 最新原始碼及編譯 Spark 原始碼(博主強烈推薦)IntelliJIdeaSpark原始碼編譯
- Spark開發-Spark核心細說Spark
- Spark開發-spark環境搭建Spark
- 基於 idea+maven 的 jmeter 開發環境搭建IdeaMavenJMeter開發環境
- Intellij IDEA開發Scala程式IntelliJIdea
- Spark開發-SparkSql的開發SparkSQL
- Spark開發-spark執行原理和RDDSpark
- 基於RDD的Spark應用程式開發案列講解(詞頻統計)Spark
- Spark開發-RDD介面程式設計Spark程式設計
- Spark之HiveSupport連線(spark-shell和IDEA)SparkHiveIdea
- spark 基礎開發 Tips總結Spark
- CS190 Scalable Machine Learning Spark - Introduction SparkMacSpark
- Spark開發-Spark執行模式及原理一Spark模式
- Spark開發-Local模式Spark模式
- Spark開發-Standalone模式Spark模式
- Spark開發-控制操作Spark
- Spark開發-transformations操作SparkORM
- Spark開發-Action操作Spark
- Intellij idea開發Hadoop MapReduce程式IntelliJIdeaHadoop
- ubuntu下使用IntelliJ idea開發scalaUbuntuIntelliJIdea
- Mac下使用IntelliJ IDEA開發ScalaMacIntelliJIdea
- Spark 從零到開發(五)初識Spark SQLSparkSQL
- 基於 Spark 的資料分析實踐Spark
- (課程)基於Spark的機器學習經驗Spark機器學習