IDEA使用Maven搭建spark開發環境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark開發環境,並基於scala編寫簡單的spark中wordcount例項。
1.準備工作
首先需要在你電腦上安裝jdk和scala以及開發工具Intellij IDEA,本文中使用的是win7系統,環境配置如下:
jdk1.7.0_15
scala2.10.4
scala官網下載地址:http://www.scala-lang.org/download/
如果是windows請下載msi安裝包。
這兩個可以在官網上下載jdk和scala的安裝包就可以直接雙擊安裝包執行安裝即可。注意:如果以後是在本地編寫好spark程式碼然後上傳到spark叢集上去執行的話,請一定保持兩者的開發環境一致,不然會出現很多錯誤。
Intellij IDEA
在官網上下載一般選擇右下角的Community版本,下載地址https://www.jetbrains.com/idea/download/#section=windows
2.在Intellij IDEA中安裝scala外掛
安裝好Intellij IDEA並進入idea的主介面
(1)找到右下角的Configure選項中Plugins並開啟

(2)點選左下角Browse repositories…
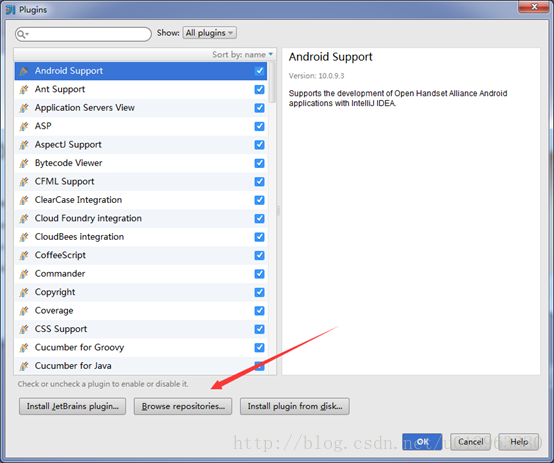
(3)在搜尋框裡搜scala,出現相對於的Scala外掛,這裡面我的已經安裝完成了,沒安裝的會顯示install的字樣以及相對於的版本,這裡面不建議線上安裝外掛,建議根據Updated 2014/12/18去下載離線的scala外掛,比如本文中的IDEA Updated日期是2014/12/18然後找到對應的外掛版本是1.2.1,下載即可。下面是scala外掛的離線下載地址。
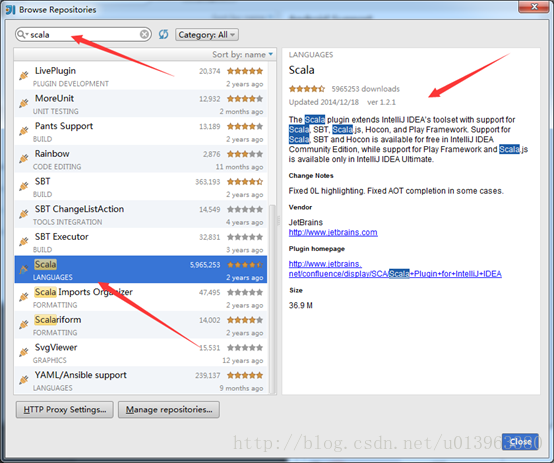
scala外掛離線下載地址:https://plugins.jetbrains.com/plugin/1347-scala
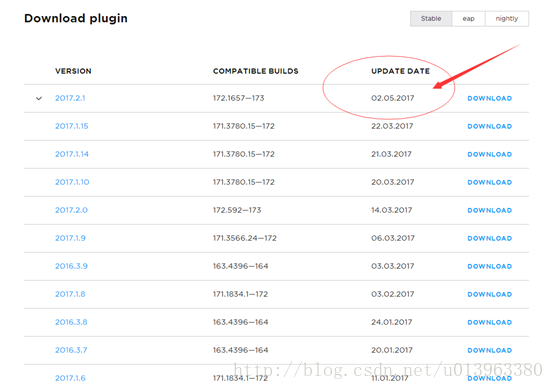
然後根據Update日期去找Intellij IDEA對應得scala外掛,不同版本的IDEA對應的scala外掛不一樣,請務必下載對應的scala外掛否則無法識別。
(4)離線外掛下載完成後,將離線scala外掛通過如下方式加入到IDEA中去:點選Install plugin from disk…,然後找到你scala外掛的zip檔案的本機磁碟位置,點ok即可
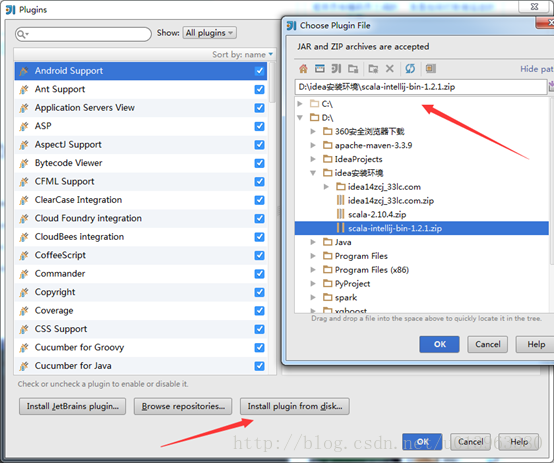
到這裡,在Intellij IDEA中安裝scala外掛的步驟已經全部完成。接下來用IDEA來構建一個Maven工程,用來搭建spark開發環境。
3.Intellij IDEA通過Maven搭建spark環境
(1)開啟IDEA新建一個maven專案,如下圖:
注意:按照我步驟順序即可。
注意:如果是第一次利用maven構建scala開發spark環境的話,這裡面的會有一個選擇scala SDK和Module SDK的步驟,這裡路徑選擇你安裝scala時候的路徑和jdk的路徑就可以了。
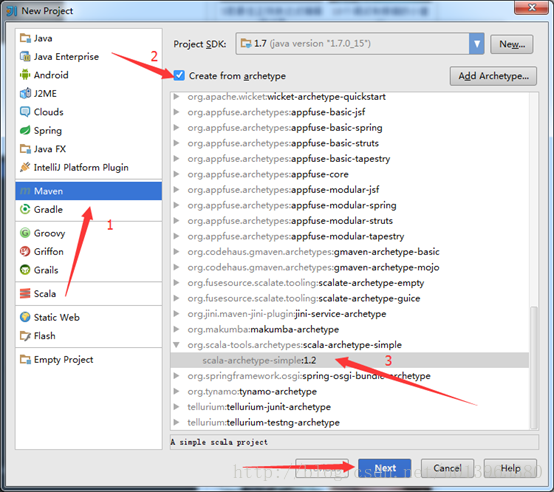
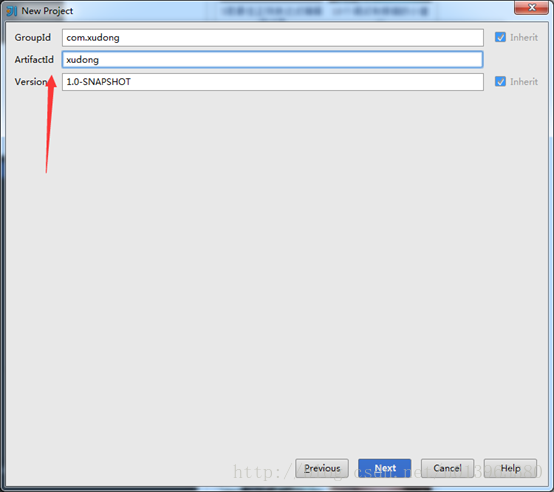
(2)填寫GroupId和ArtifactId這裡我就隨便寫了個名字,如下圖,點Next。
(3)第三步很重要,首先是你的Intellij IDEA裡有Maven,一般的新版本都會自帶maven,而且maven的目錄在IDEA安裝路徑下plugins下就能找到,然後再Maven home directory地址中填寫maven相對應的路徑,本文中的IDEA版本比較老,是自己下的Maven安裝上的(不會的可以百度下,很簡單,建議使用新的IDEA,不需要自己下載maven)。然後這裡面的User settings file是你maven路徑下conf裡面的settings.xml檔案,勾選上override即可,這裡面的Local
repository路徑可以不用修改,預設就好,你也可以新建一個目錄。點選Next。
注意:截圖的時候忘了,把Local repository前面的override也勾選上,不然構建完會報錯,至少我的是這樣。

(4)填寫自己的專案名,隨意即可。點選finish。

(5)到這裡整個流程已經結束,完成後會顯示如下介面:
右上角的import需要點選一下即可。

(6)接下來在pom.xml檔案中加入spark環境所需要的一些依賴包。以程式碼的方式給出,方便複製。
這裡是我的pom檔案程式碼,請各位自行按照自己的需要刪減或新增依賴包。
//注意這裡面的版本一定要對應好,我這裡的spark版本是1.6.0對應的scala是2.10,因為我是通過spark-core_${scala.version}是找spark依賴包的,前些日子有個同事按照這個去搭建,由於版本的不一樣最後spark依賴包載入總是失敗。請大家自行檢查自己的版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xudong</groupId>
<artifactId>xudong</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>1.6.0</spark.version>
<scala.version>2.10</scala.version>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.39</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
<!-- maven官方 http://repo1.maven.org/maven2/ 或 http://repo2.maven.org/maven2/ (延遲低一些) -->
<repositories>
<repository>
<id>central</id>
<name>Maven Repository Switchboard</name>
<layout>default</layout>
<url>http://repo2.maven.org/maven2</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
</build>
</project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
這裡要注意下幾個小問題:
這裡面會有src/main/scala和src/test/scala需要你自己在對應專案目錄下構建這兩個資料夾路徑,若不構建會報錯。

到這裡,基於scala的一個spark開發環境就基本結束了。接下來,用scala編寫一個spark的簡單示例,wordcount程式,如果有的同學編寫過MapReduce一定會很熟悉。
4.Spark簡單示例Wordcount
src/main/scala資料夾下,右鍵新建Package,輸入package的名字,我這裡是com.xudong然後新建Scala class, 然後輸入名字將型別改為object,如下圖:

補充:
如果一開始沒有在專案中加入scala的SDK,這個時候,新建Scala class會發現沒有這個選項,這個時候你新建一個File檔案,然後名字隨便取一個,字尾改成 .scala* ,點ok後檔案中空白區會顯示沒有scala的SDK,這個時候你點選提示資訊就可以新增本地的scala SDK(提前你的電腦上已經安裝了scala,這個時候它會自動的去識別SDK),以後新建Scala class就有這個選項,直接新建即可。*
建立完然後編寫wordcount程式碼,程式碼如下(並註釋了相關的解釋):
package com.xudong
import org.apache.spark.mllib.linalg.{Matrices, Matrix}
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Administrator on 2017/4/20.
* xudong
*/
object WordCountLocal {
def main(args: Array[String]) {
/**
* SparkContext 的初始化需要一個SparkConf物件
* SparkConf包含了Spark叢集的配置的各種引數
*/
val conf=new SparkConf()
.setMaster("local")//啟動本地化計算
.setAppName("testRdd")//設定本程式名稱
//Spark程式的編寫都是從SparkContext開始的
val sc=new SparkContext(conf)
//以上的語句等價與val sc=new SparkContext("local","testRdd")
val data=sc.textFile("e://hello.txt")//讀取本地檔案
data.flatMap(_.split(" "))//下劃線是佔位符,flatMap是對行操作的方法,對讀入的資料進行分割
.map((_,1))//將每一項轉換為key-value,資料是key,value是1
.reduceByKey(_+_)//將具有相同key的項相加合併成一個
.collect()//將分散式的RDD返回一個單機的scala array,在這個陣列上運用scala的函式操作,並返回結果到驅動程式
.foreach(println)//迴圈列印
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
建立資料集hello.txt測試文件如下:

啟動本地spark程式,然後輸出結果,可以在控制檯檢視結果:

如果能正確的列印出結果,說明spark示例執行成功。
到這裡,Intellij IDEA使用Maven構建spark開發環境已經完全結束,如果有疑問或者本文件有什麼錯誤,請指出,不甚感激。
有關如何在本地將spark程式打包上傳到spark叢集,然後在spark叢集裡面去執行,後面會另寫部落格介紹。
相關文章
- spark開發環境搭建intellij+Scala+sbtSpark開發環境IntelliJ
- 搭建scala開發環境開發環境
- Spark開發-spark環境搭建Spark
- 基於 idea+maven 的 jmeter 開發環境搭建IdeaMavenJMeter開發環境
- Scala開發之1:環境搭建
- Spark開發-HA環境的搭建Spark
- TestNG+Maven+IDEA環境搭建+測試MavenIdea
- 使用IntelliJ IDEA 搭建 spring mvc開發環境IntelliJIdeaSpringMVC開發環境
- IDEA開發Spark應用實戰(Scala)IdeaSpark
- spark環境搭建Spark
- Maven 環境搭建Maven
- MAVEN環境搭建Maven
- Learning Spark——使用Intellij Idea開發基於Maven的Spark程式SparkIntelliJIdeaMaven
- 【Hadoop】:Windows下使用IDEA搭建Hadoop開發環境HadoopWindowsIdea開發環境
- [最新]使用 IDEA 從0到1搭建 Scala 開發環境(含打 Jar 包到 Linux 執行)Idea開發環境JARLinux
- idea開發之springboot環境搭建IdeaSpring Boot
- 基於IDEA的JavaWeb開發環境搭建IdeaJavaWeb開發環境
- Spark修煉之道(進階篇)——Spark入門到精通:第三節 Spark Intellij IDEA開發環境搭建SparkIntelliJIdea開發環境
- Spark on Yarn 環境搭建SparkYarn
- struts2 使用Maven搭建Struts2框架的開發環境Maven框架開發環境
- Maven基礎:Maven環境搭建及基本使用(1)Maven
- idea開發環境中maven控制檯亂碼解決Idea開發環境Maven
- VSCode+Maven+Hadoop開發環境搭建VSCodeMavenHadoop開發環境
- 使用 Docker 搭建本地開發環境!Docker開發環境
- 使用 Docker 搭建 PHP 開發環境DockerPHP開發環境
- 使用webpack搭建react開發環境WebReact開發環境
- Scala--執行環境搭建
- 詳解Window10下使用IDEA搭建Hadoop開發環境IdeaHadoop開發環境
- hadoop之旅5-idea通過maven搭建hdfs環境HadoopIdeaMaven
- 使用 PhpStorm + Docker 搭建開發環境PHPORMDocker開發環境
- 使用 Rainbond 搭建本地開發環境AI開發環境
- 使用sublime搭建python開發環境Python開發環境
- Spark學習進度-Spark環境搭建&Spark shellSpark
- windows下使用idea maven配置spark執行環境、執行WordCount例子以及碰到的問題WindowsIdeaMavenSpark
- PHP開發環境 03 - 使用KFKDock搭建PHP專案環境PHP開發環境
- 手把手教你 在IDEA搭建 SparkSQL的開發環境IdeaSparkSQL開發環境
- Maven環境搭建和介紹Maven
- 搭建Maven和Nexus環境Maven