什麼是垃圾回收?
垃圾回收,Garbage Collection,簡稱GC。
在我們日常生活中的垃圾,我們會丟入垃圾桶,等待清潔工處理掉。
Java中的垃圾,指存在於記憶體中,不會再被使用的物件,需要把這些無用的物件進行清理掉,那麼,這些垃圾物件所佔用的空間就可以被騰出來被其他物件使用,對記憶體空間管理來說,識別和清理垃圾是非常重要的。
而怎樣找出並清理這些垃圾呢?這裡介紹幾種垃圾收集演算法。
引用計數演算法
引用計數法是最簡單的一種方法。
它的實現很簡單:給物件配備一個整型的引用計數器,每當有一個地方引用這個物件時,計數器值就加1,當引用失效時,計數器值就減1,只要該物件的計數器的值為0,那麼這個物件就是不可能再被使用的,就可以視作垃圾處理。
引用計數法的實現簡單,判斷效率也高,但是,在java虛擬機器內卻沒有使用引用計數法來管理記憶體,最主要的原因是它無法解決物件之間互相引用的問題。
當然,引用計數法還有一個缺點,就是每次因引用的產生和消除的時候,需要伴隨一個計數器的加法操作和減法操作,對系統的效能會有一定影響。但是這一點並不是致命的。
致命的是引用迴圈問題,示例如下:
public class Test { public Object obj = null; public static void main(String[] args) throws Exception{ Test a = new Test(); Test b = new Test(); a.obj = b; b.obj = a; a = null; b = null; System.gc(); } }
如果使用引用計數法,a和b兩個物件是無法被回收的。
可達性分析演算法
在java中,判斷物件是否存活,是通過可達性分析來實現的,在後續的各種垃圾收集的演算法中,幾乎都是通過可達性分析來標記垃圾的。
它的思路是通過一些稱作“GC Roots”的物件作為起始點,從這些節點開始往下搜尋,搜尋走過的路徑叫做引用鏈,當一個物件到GC Roots沒有引用鏈相連線的時候,就可以叫做這個物件到GC Roots不可達,則此物件就可以定為不可用。
如圖所示:

儘管obj5、obj6、obj7之間互相引用,但是他們到GC Roots都是不可達的,所以他們將會被判定為可回收垃圾。
在Java中,GC Roots包括下面幾種:
1.Java棧(棧幀中的本地變數表)裡面引用的物件。
2.方法區中靜態屬性引用的物件。
3.方法區中常量引用的物件。
4.本地方法棧中JNI引用的物件。
標記清除演算法
標記清除演算法將垃圾回收分為標記、清除兩個階段,這種分步執行的思路奠定了現代垃圾收集演算法的思想基礎。
和引用計數法不同的是,標記清除演算法不需要執行環境檢測每一次記憶體分配和指標操作,只需要在標記階段中根據可達性分析演算法就可以找出所有存活物件,進行標記,未標記的物件即視為垃圾。在清除階段,清除所有未被標記的物件。
如圖:
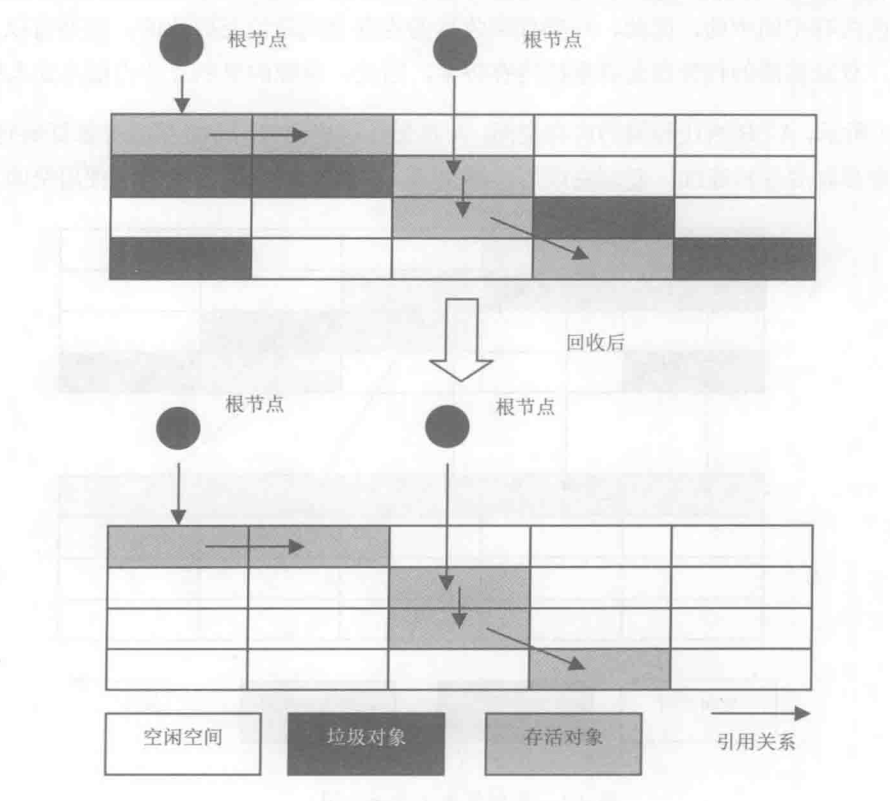
標記清除演算法最大的問題就是會產生空間碎片,由於被執行記憶體回收的物件佔用的記憶體有可能是一些不連續的記憶體塊,清除之後就會產生大量的不連續的記憶體碎片,空間碎片太多可能會導致以後在程式執行過程中需要給較大物件分配記憶體時,無法找到足夠的連續記憶體。
複製演算法
為了解決標記清除演算法的缺陷,JVM後來引入了複製演算法。
複製演算法的核心思想是:將原有的記憶體空間分為兩塊,每次只使用其中一塊,在垃圾回收時,將正在使用的記憶體中的存活物件複製到另一塊記憶體空間去,然後,清除這一塊記憶體空間中的所有物件,交換兩個記憶體塊的角色,完成垃圾回收。
如果系統中垃圾物件很多,那麼複製演算法需要複製的存活物件數量就不會太大,在真正需要回收垃圾的時候,複製演算法的效率是很高的。
並且物件在垃圾回收過程中統一被複制到新的記憶體空間中,因此可以確保回收後的記憶體空間是沒有碎片的。
如圖:
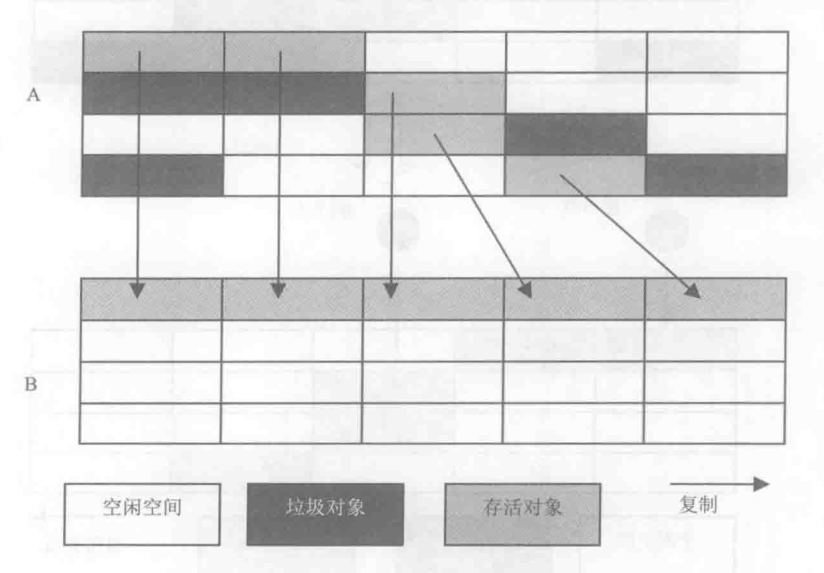
複製演算法的缺陷是將系統記憶體摺半。
在Java的新生代序列垃圾回收器中,就使用了複製演算法的思想。
(存放年輕物件的堆空間就叫新生代,年輕物件是指剛剛建立的或者沒怎麼經歷過垃圾回收的物件,同樣的,存放老年物件的堆空間叫做老年代,老年物件指經歷過多次垃圾回收依然還沒死的物件)
新生代分為eden空間、from空間和to空間3個部分,其中from和to空間可以視為用於複製的兩塊大小相同、地位相等、並且可以進行角色互換的空間塊。from空間和to空間也稱為survivor空間,即倖存者空間,用來存放沒有被回收的物件。
看圖理解:
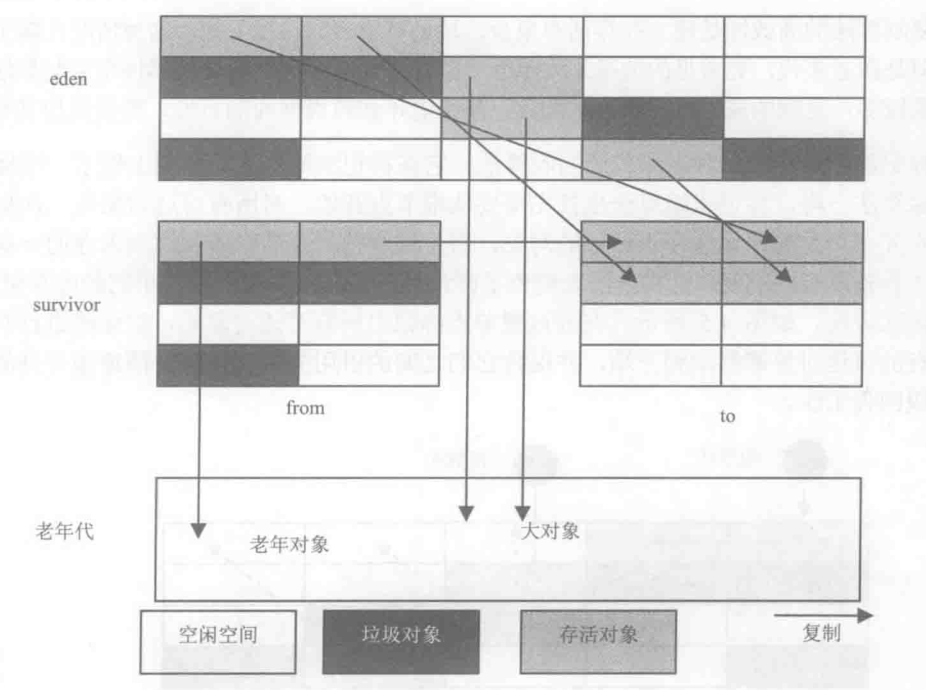
在垃圾回收時,Eden空間中的存活物件會被複制到未使用的survivor空間中(假設是To),正在使用的survivor空間(假設是from)中的年輕物件也會被複制到to空間中(大物件、或者老年物件會直接進入老年代,如果to空間已滿,則物件也會直接進入老年代),這時候eden空間和from空間中剩餘物件就是垃圾物件,可以直接清空,接下來,from空間和to空間將會互換位置,to空間則存放此次回收後的存活物件,這種趕緊的複製演算法既保證了空間的連續性,又避免了大量的記憶體空間浪費。
其實複製演算法無非就是使用to空間作為一個臨時的空間交換角色。
複製演算法比較適用於新生代,因為在新生代,垃圾物件通常會多於存活物件,複製演算法的效果會比較好。
標記壓縮演算法
複製演算法的高效性是建立在存活物件少,垃圾物件多的前提下的,這種情況在新生代經常發生,但是在老年代更常見的情況是大部分物件都是存活物件,如果依然使用複製演算法,那麼複製的成本會很高,所以基於老年代垃圾的特性,需要使用其他的演算法。
標記壓縮演算法就是老年代使用的演算法,也可以叫做標記整理演算法,他其實是在標記清除演算法上做了相應的優化,標記階段依然是使用可達性分析對所有存活物件進行標記,但之後並不是簡單的清理未標記的物件,而是將所有標記的物件壓縮到記憶體的另一端,之後,再清理邊界外的所有空間。
如圖所示:
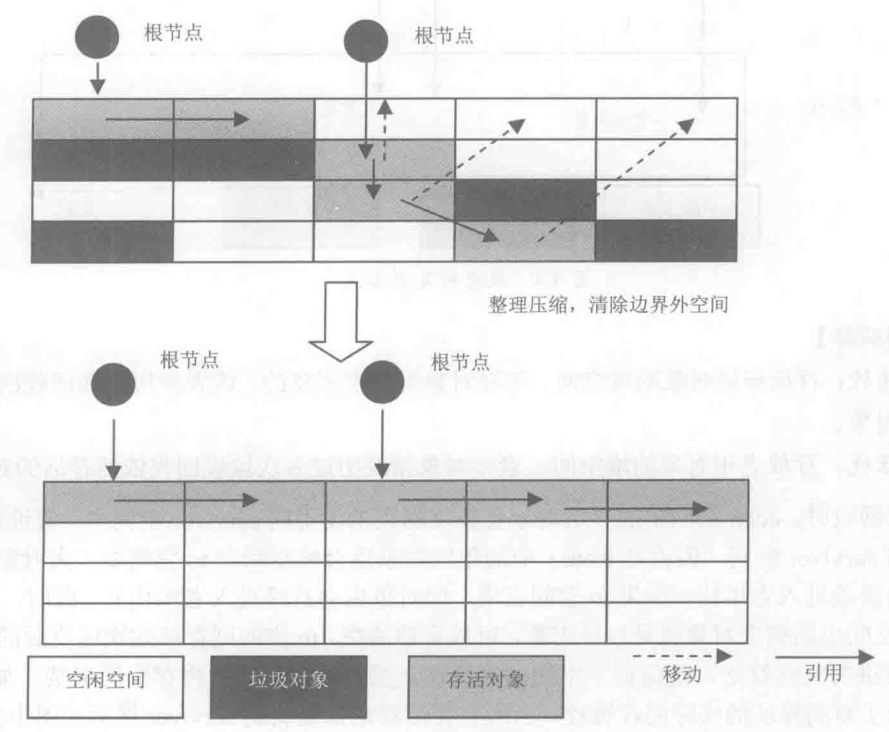
標記壓縮演算法的最終效果相當於標記清除演算法執行完成後,再進行一次記憶體碎片整理,這種方法既避免了碎片的產生,又不需要兩塊相同的記憶體空間,價效比相對於來說較高。
分割槽演算法
在垃圾回收過程中,應用程式所有的執行緒都會處於一種掛起狀態,暫停一切正常工作,等待垃圾回收結束。
如果垃圾回收時間過長,將嚴重影響使用者的體驗或者系統穩定性,為了解決這個問題,所以誕生了一個叫分割槽演算法的概念,也可以叫做增量演算法。
它的基本思想是,如果一次性將所有的垃圾進行處理,需要造成系統長時間的停頓,那麼就可以讓垃圾收集執行緒和應用程式執行緒交替執行。將java堆的記憶體空間分割成多個小片區域,每次垃圾收集執行緒只收集一小片區域的記憶體空間,接著切換到應用程式執行緒,依次反覆,直到垃圾收集完成。
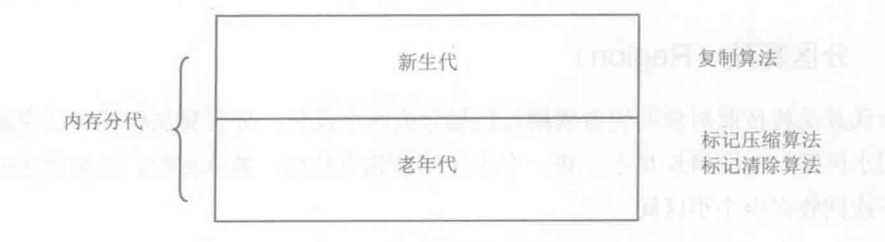
分代收集演算法
分代收集演算法並沒有什麼新的思想,它只是根據物件存活週期的不同特點將記憶體劃分為幾塊,一般是把java堆分為新生代和老年代,這樣可以根據各個年代的特點採用最適合的垃圾收集演算法。
一般來說,java虛擬機器會把所有新建的物件都放入稱為新生代的記憶體區域,新生代的特點是物件會很快被回收,所以,在新生代就選擇效率較高的複製演算法。
當一個物件經過幾次垃圾回收後依然存活,物件就會被放入老年代區域,在老年代中幾乎所有的物件都是經過幾次垃圾回收後依然存活的,可以認為這些物件在一段時期內,甚至在應用程式的整個生命週期中,都是常駐記憶體的,如果依然要用複製演算法回收老年代,將要複製大量物件,所以這種做法是不可取的。
根據分代的思想,需要對老年代的回收使用與新生代不同的標記清除或標記壓縮演算法,可以提高垃圾回收的效率。
分代收集的思想被現有的虛擬機器廣泛使用,幾乎目前所有的商業虛擬機器的垃圾回收器都採用了這種思想。
見下圖: