什麼是儲存過程
簡單說,儲存過程就是一條或多條SQL語句的集合,可視為批檔案,但是起作用不僅限於批處理。本文主要講解如何建立儲存過程和儲存函式以及變數的使用,如何呼叫、檢視、修改、刪除儲存過程和儲存函式等。使用的資料庫和表還是之前寫JDBC用的資料庫和表:
create database school; use school; create table student ( studentId int primary key auto_increment not null, studentName varchar(10) not null, studentAge int, studentPhone varchar(15) ) insert into student values(null,'Betty', '20', '00000000'); insert into student values(null,'Jerry', '18', '11111111'); insert into student values(null,'Betty', '21', '22222222'); insert into student values(null,'Steve', '27', '33333333'); insert into student values(null,'James', '22', '44444444'); commit;
儲存程式可以分為儲存過程和函式,MySQL中建立儲存過程和函式的語句分別是:CREATE PROCEDURE和CREATE FUNCTION。使用CALL語句來呼叫儲存過程,只能用輸出變數返回值。函式可以從語句外呼叫(即通過引用函式名),也能返回標量值。儲存過程也可以呼叫其他儲存過程。
建立儲存過程
建立儲存過程,需要使用CREATE PROCEDURE語句,語句基本格式如下:
CREATE PROCEDURE sp_name([proc_parameter])
[characteristics ...] routine_body
解釋一下:
1、CREATE PROCEDURE為建立儲存過程的關鍵字
2、sp_name為儲存過程的名字
3、proc_parameter為指定儲存過程的引數列表,列表形式為[IN|OUT|INOUT] param_name type。其中,IN表示輸入引數,OUT表示輸出引數,INOUT表示既可以輸入也可以輸出,param_name表示引數名稱,type表示引數型別,該型別可以是MySQL資料庫中的任意型別
4、characteristics指定儲存過程的特性
5、routime_body是SQL程式碼的內容,可以用BEGIN...END來表示SQL程式碼的開始和結束
編寫儲存過程不是簡單的事情,可能儲存過程中需要複雜的SQL語句,並且要有建立儲存過程的許可權;但是使用儲存過程將簡化操作,減少冗餘的操作步驟,同時還可以減少操作過程中的事物,提高效率,因此儲存過程是非常有用的。下面看兩個儲存過程,一個查詢student表中的所有欄位,一個根據student表的Age欄位算一個Age的平均值:
CREATE PROCEDURE proc () BEGIN SELECT * FROM student; END;
CREATE PROCEDURE AvgStudentAge() BEGIN SELECT AVG(studentAge) AS avgAge FROM student; END;
上面都是不帶引數的儲存過程,下面看一個帶引數的儲存過程:
DELIMITER // CREATE PROCEDURE CountStudent(IN sName VARCHAR(10), OUT num INT) BEGIN SELECT COUNT(*) INTO num FROM student WHERE studentName = sName; END //
上述程式碼的作用是建立一個獲取student表記錄條數的儲存過程,名稱為CountStudent,根據傳入的學生姓名COUNT(*)後把結果放入引數num中。
注意另外一個細節,上述程式碼第一行使用了"DELIMITER //",這句語句的作用是把MySQL的結束符設定為"//",因為MySQL預設的語句結束符號為分號";",為了避免與儲存過程中SQL語句結束符相沖突,需要使用DELIMITER改變儲存過程的結束符,並以"END //"結束儲存過程。存過程定義完畢之後再使用"DELIMITER ;"恢復預設結束符。DELIMITER也可以指定其他符號作為結束符。
建立儲存函式
建立儲存函式需要使用CREATE FUNCATION語句,其基本語法如下:
CREATE FUNCTION func_name([func_parameter]) RETURNS type [characteristic ...] routine_body
解釋一下:
1、CREATE_FUNCTION為用來建立儲存函式的關鍵字
2、func_name表示儲存函式的名稱
3、func_parameter為儲存過程的引數列表,引數列表形式為[IN|OUT|INOUT] param_name type,和儲存過程一樣
4、RETURNS type表示函式返回資料的型別
5、characteristic表示儲存函式的特性,和儲存過程一樣
舉個例子:
CREATE FUNCTION NameByZip() RETURNS CHAR(50) RETURN (select studentPhone from student where studentName = 'JAMES');
提兩點:
1、如果在儲存函式中的RETURN語句返回一個型別不同於函式的RETURNS自居指定的型別的值,返回值將被強制為恰當的型別
2、指定引數為IN、OUT或INOUT只對PROCEDURE是合法的(FUNCTION中總是預設為IN引數)。RETURNS子句只能對FUNCTION做指定,對於函式而言這是強制性的,它用來指定函式的返回型別,而且函式體必須包含一個RETURN value語句
變數的使用
變數可以在子程式中宣告並使用,這些變數的作用範圍是在BEGIN...END程式中,在儲存過程中可以使用DECLARE語句定義變數,語法如下:
DECLARE var_name[,varame]... date_type [DEFAULT value]
解釋一下:
1、var_name為區域性變數的名稱
2、DEFAULT value子句給變數提供一個預設值,值除了可以被宣告為一個常數之外,還可以被指定為一個表示式。如果沒有DEFAULT子句,那麼初始值為NULL
定義變數後,為變數賦值可以改變變數的預設值,MySQL使用SET為變數賦值:
SET var_name=expr[, var_name=expr] ...;
舉個例子:
DECLARE var1 INT DEFAULT 100; DECLARE var2, var3, var4 INT; SET var2 = 10, var3 = 20; SET var4 = var2 + var3;
當然,我們使用SELECT語句也可以給變數賦值:
DECLARE t_studentName CHAR(20); DECLARE t_studentAge INT; SELECT studentName, studentId INTO t_studentName, t_studentAge FROM student where studentName = 'Bruce';DECLARE t_studentName CHAR(20); DECLARE t_studentAge INT;
遊標的使用
查詢語句可能返回多條記錄,如果資料量非常大,需要在儲存過程和儲存函式中使用遊標來逐條讀取查詢結果集中的記錄。應用程式可以根據需要滾動或瀏覽器中的程式。
遊標必須在處理程式之前被宣告,並且變數和條件還必須在宣告遊標或處理程式之前被宣告。MySQL中宣告遊標的方法為:
DECLARE cursor_name CURSOR FOR select_statement
解釋一下:
1、cursor_name表示遊標的名稱
2、select_statement表示SELECT語句返回的內容,返回一個用於建立遊標的結果集
定義了遊標,就要開啟遊標,開啟遊標的方法為:
OPEN cursor_name{遊標名稱}
再就是使用遊標了,使用遊標的方法為:
FETCH cursor_name INTO var_name [, var_name] ... {引數名稱}
最後遊標使用完了,要關閉:
CLOSE cursor_name{遊標名稱}
舉個例子:
DECLARE t_studentName CHAR(20); DECLARE t_studentAge INT; DECLARE cur_student CURSOR FOR SELECT studentName, studentId FROM student where studentName = 'Bruce'; OPEN cur_student; FETCH cur_student INTO t_studentName, t_studentAge; ... CLOSE cur_student;
studentName為Bruce的在資料裡面不止一條記錄,建立遊標之後就從student表中查出了studentName和studentId的值。OPEN這個遊標,通過FETCH之後遍歷每一組studentName和studentAge,並放入申明的變數t_studentName和t_studentAge中,之後想怎麼用這兩個欄位怎麼用這兩個欄位了。注意,遊標用完關閉掉。
IF、CASE、LOOP、LEAVE、ITERATE、REPEAT
這六個比較簡單,放在一起講了,簡單說下用法,除了第一個IF寫個例子以外,別的就不寫例子了,可以自己嘗試下。
1、IF
IF語句包含多個判斷條件,根據判斷的結果為TRUE或FALSE執行相應的語句,其格式為:
IF expr_condition THEN statement_list [ELSEIF expr_condition THEN statement_list] [ELSE statement_list] END IF
比如:
IF t_studentName IS NULL THEN SELECT studentName INTO t_studentName FROM student where studentName = 'Bruce'; ELSE UPDATE studentName set student = NULL where studentName = 'Bruce'; END IF;
2、CASE
case是另外一個進行條件判斷的語句,該語句有兩種格式,第一種格式如下:
CASE case_expr WHEN when_value THEN statement_list [WHEN when_value THEN statement_list] ... [ELSE statement_list] END CASE
其中,case_expr參數列示判斷的表示式,決定了哪一個WHEN自居會被執行;when_value表示表示式可能的值,如果某個when_value表示式與case_expr表示式結果相同,則執行對應THEN關鍵字後的statement_list中的語句;statement_list參數列示不同when_value值的執行語句。
CASE語句的第二種格式為:
CASE WHEN expr_condition THEN statement_list [WHEN expr_condition THEN statement_list] ... [ElSE statement_list] END CASE
只是寫法稍微變了一下,引數還是第一種寫法的意思
3、LOOP
LOOP迴圈用來重複執行某些語句,與IF和CASE相比,LOOP只是建立一個迴圈操作的過程,並不進行條件判斷。LOOP內的語句一直被重複執行直到迴圈被退出,跳出迴圈過程,使用LEAVE子句。LOOP語句j的基本格式如下:
[loop_label:] LOOP statement_list END LOOP
其中loop_label表示LOOP語句的標註名稱,該引數可以省略;statement_list參數列示需要迴圈執行的語句
4、LEAVE
LEAVE語句用來退出任何被標註的流程控制構造,LEAVE語句的基本格式如下:
LEAVE label
5、ITERATE
ITERATE語句將執行順序轉到語句段開頭出,語句基本格式如下:
ITERATE label
6、REPEAT
REPEAT語句用來建立一個帶有條件判斷的迴圈過程,每次與局執行完畢之後,會對條件表示式進行判斷,如果表示式為真,則迴圈結束,否則重複執行迴圈中的語句。REPEAT語句的基本格式如下:
[repeat_label:] REPEAT statement_list UNTIL expr_condition END REPEAT
其中,repeat_label為REPEAT語句的標註名稱,該引數可以省略;REPEAT語句內的語句或語句群被重複,直至expr_condition為真
呼叫儲存過程和函式
儲存過程已經定義好了,接下來無非就是呼叫。儲存過程和函式有很多種呼叫方法,儲存過程必須使用CALL語句呼叫,並且儲存過程和資料庫相關,如果要執行其他資料庫中的儲存過程,需要指定資料庫名稱,例如CALL dbname.procname。儲存函式的呼叫與MySQL中預定義的函式呼叫方式相同。
1、呼叫儲存過程
儲存過程是通過CALL語句進行呼叫的,語法如下:
CALL sp_name([parameter[,...]])
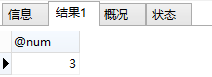
舉個例子,就呼叫最前面那個CountStudent的儲存過程:
CALL CountStudent('Bruce', @num); select @num;
執行結果為:
2、呼叫儲存函式
MySQL中呼叫儲存函式的使用方法和MySQL內部函式的使用方法是一樣的,無非儲存函式是使用者自己定義的,內部函式是MySQL開發者定義的。
我們呼叫一下上面定義的NameByZip那個函式:
select NameByZip();
執行結果為:
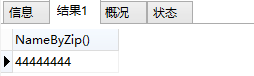
可以對照一下,studenName為"James"這一條,對應的studentPhone就是"44444444",符合SELECT出來的結果
檢視、刪除儲存過程和函式
1、檢視儲存過程和函式的狀態
SHOW STATUS可以檢視儲存過程核函式的狀態,其基本語法結構如下:
SHOW {PROCEDURE | FUNCTIOn} STATUS [LIKE 'pattern'
這個語句是一個MySQL的擴充套件,他返回子程式的特徵,如資料庫、名字、型別、建立者及建立和修改日期。如果沒有指定樣式,根據使用的語句,所有儲存過程或儲存函式的資訊都被列出。PROCEDURE和FUNCTIOn分別表示檢視儲存過程和函式,LIKE語句表示匹配儲存過程或函式的名稱。
舉個例子:
SHOW PROCEDURE STATUS
執行結果為:

後面還有一些欄位,截圖截不全沒辦法。檢視儲存函式也一樣,可以自己試試看。
2、檢視儲存過程和函式的定義
除了SHOW STATUS外,還可以使用SHOW CREATE來檢視儲存過程的定義,基本格式為:
SHOW CREATE {PROCEDURE | FUNCTION} sp_name
比如:
SHOW CREATE FUNCTION NameByZip
我檢視了NameByZip這個函式的定義,結果為:

這個Create Function欄位就是建立的儲存函式的內容
3、刪除儲存過程和函式
刪除儲存過程核函式,可以使用DROP語句,基本語法如下:
DROP {PROCEDURE | FUNCTION} [IF EXISTS] sp_name
這個語句被用來移除一個儲存過程或函式。sp_name為待移除的儲存過程或函式的名稱。
IF EXISTS子句是一個MySQL的擴充套件,如果程式或函式不儲存,它可以防止錯誤發生,產生一個用SHOW WARNINGS檢視的警告。舉個例子:
DROP PROCEDURE CountStudent DROP FUNCTION NameByZip;
這麼簡單就可以了。注意這裡沒有講修改儲存過程和儲存函式,因為修改儲存過程或者函式只能修改儲存過程或者儲存函式的特性,不能直接對已有的儲存過程或函式進行修改,如果必須要改,只能先DROP在重新編寫程式碼,CREATE一個新的。