標籤:SQL SERVER/MSSQL SERVER/資料庫/DBA/索引/統計資訊
概述
無論何時對基礎資料執行插入、更新或刪除操作,SQL Server 資料庫引擎都會自動維護索引。隨著時間的推移,這些修改可能會導致索引中的資訊分散在資料庫中(含有碎片)。當索引包含的頁中的邏輯排序(基於鍵值)與資料檔案中的物理排序不匹配時,就存在碎片。碎片非常多的索引可能會降低查詢效能,導致應用程式響應緩慢,所以在日常的維護工作當中就需要對索引進行檢查對那些填充度很低碎片量大的索引進行重新生成或重新組織,但是在這個過程也需要注意一些小的細節,否則會產生錯誤。
一、語法
語法內容載自SQL Server聯機叢書,標記出了需要注意的內容,最後分享自己平時用的維護索引的語句供參考。
ALTER INDEX { index_name | ALL } ON <object> { REBUILD [ [PARTITION = ALL] [ WITH ( <rebuild_index_option> [ ,...n ] ) ] | [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> [ ,...n ] ) ] ] ] | DISABLE | REORGANIZE [ PARTITION = partition_number ] [ WITH ( LOB_COMPACTION = { ON | OFF } ) ] | SET ( <set_index_option> [ ,...n ] ) } [ ; ] <object> ::= { [ database_name. [ schema_name ] . | schema_name. ] table_or_view_name } <rebuild_index_option > ::= { PAD_INDEX = { ON | OFF } | FILLFACTOR = fillfactor | SORT_IN_TEMPDB = { ON | OFF } | IGNORE_DUP_KEY = { ON | OFF } | STATISTICS_NORECOMPUTE = { ON | OFF } | ONLINE = { ON | OFF } | ALLOW_ROW_LOCKS = { ON | OFF } | ALLOW_PAGE_LOCKS = { ON | OFF } | MAXDOP = max_degree_of_parallelism | DATA_COMPRESSION = { NONE | ROW | PAGE } [ ON PARTITIONS ( { <partition_number_expression> | <range> } [ , ...n ] ) ] } <range> ::= <partition_number_expression> TO <partition_number_expression> } <single_partition_rebuild_index_option> ::= { SORT_IN_TEMPDB = { ON | OFF } | MAXDOP = max_degree_of_parallelism | DATA_COMPRESSION = { NONE | ROW | PAGE } } } <set_index_option>::= { ALLOW_ROW_LOCKS = { ON | OFF } | ALLOW_PAGE_LOCKS = { ON | OFF } | IGNORE_DUP_KEY = { ON | OFF } | STATISTICS_NORECOMPUTE = { ON | OFF } }
- index_name
-
索引的名稱。索引名稱在表或檢視中必須唯一,但在資料庫中不必唯一。索引名稱必須符合識別符號的規則。
- ALL
-
指定與表或檢視相關聯的所有索引,而不考慮是什麼索引型別。如果有一個或多個索引離線或不允許對一個或多個索引型別執行只讀檔案組操作或指定操作,則指定 ALL 將導致語句失敗。下表列出了索引操作和不允許使用的索引型別。
已分割槽表和已分割槽索引。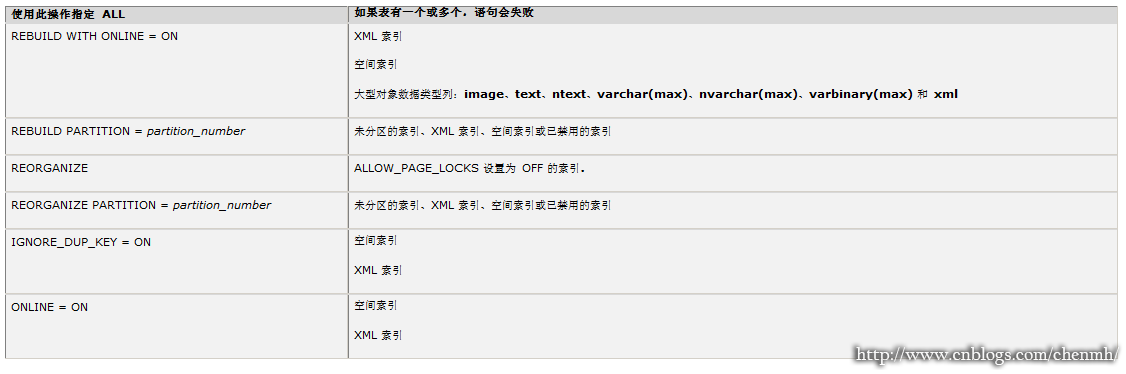
- database_name
-
資料庫的名稱。
- schema_name
-
表或檢視所屬架構的名稱。
- table_or_view_name
-
與該索引關聯的表或檢視的名稱。若要顯示物件的索引報表,請使用 sys.indexes 目錄檢視。
- REBUILD [ WITH (<rebuild_index_option> [ ,...n]) ]
-
指定將使用相同的列、索引型別、唯一性屬性和排序順序重新生成索引。此子句等同於 DBCC DBREINDEX。REBUILD 啟用已禁用的索引。重新生成聚集索引並不重新生成關聯的非聚集索引,除非指定了關鍵字 ALL。如果未指定索引選項,則應用儲存在 sys.indexes 中的現有索引選項值。對於未在 sys.indexes 中儲存值的任何索引選項,應用該選項的引數定義中指示的預設值。
重新生成 XML 索引或空間索引時,選項 ONLINE = ON 和 IGNORE_DUP_KEY = ON 無效。
如果指定 ALL 且基礎表為堆,則重新生成操作對錶沒有任何影響。重新生成與表相關聯的所有非聚集索引。
如果資料庫恢復模式設定為大容量日誌記錄或簡單,則可以對重新生成操作進行最小日誌記錄。
- PARTITION
-
指定只重新生成或重新組織索引的一個分割槽。如果 index_name 不是已分割槽索引,則不能指定 PARTITION。
PARTITION = ALL 重新生成所有分割槽。當指定PARTITION = ALL時不能使用ONLINE = ON
- partition_number
-
要重新生成或重新組織已分割槽索引的分割槽數。partition_number 是可以引用變數的常量表示式。其中包括使用者定義型別變數或函式以及使用者定義函式,但不能引用 Transact-SQL 語句。partition_number 必須存在,否則,該語句將失敗。
- WITH (<single_partition_rebuild_index_option>)
-
SORT_IN_TEMPDB、MAXDOP 和 DATA_COMPRESSION 是在重新生成單個分割槽 (PARTITION = n) 時可以指定的選項。不能在單個分割槽重新生成操作中指定 XML 索引。
不能聯機重新生成分割槽索引。在此操作過程中將鎖定整個表。
- DISABLE
-
將索引標記為已禁用,從而不能由 資料庫引擎使用。任何索引均可被禁用。已禁用的索引的索引定義保留在沒有基礎索引資料的系統目錄中。禁用聚集索引將阻止使用者訪問基礎表資料。若要啟用索引,請使用 ALTER INDEX REBUILD 或 CREATE INDEX WITH DROP_EXISTING。
- REORGANIZE
-
指定將重新組織的索引葉級。此子句等同於 DBCC INDEXDEFRAG。ALTER INDEX REORGANIZE 語句始終聯機執行。這意味著不保留長期阻塞的表鎖,且對基礎表的查詢或更新可以在 ALTER INDEX REORGANIZE 事務處理期間繼續。不能為已禁用的索引或 ALLOW_PAGE_LOCKS 設定為 OFF 的索引指定 REORGANIZE。
- WITH ( LOB_COMPACTION = { ON | OFF } )
-
指定壓縮所有包含大型物件 (LOB) 資料的頁。LOB 資料型別包括 image、text、ntext、varchar(max)、nvarchar(max)、varbinary(max) 和 xml。壓縮此資料可以改善磁碟空間使用情況。預設值為 ON。
- ON
-
壓縮所有包含大型物件資料的頁。
重新組織指定的聚集索引將壓縮聚集索引中包含的所有 LOB 列。重新組織非聚集索引將壓縮作為索引中非鍵(已包括)列的所有 LOB 列。有關詳細資訊,請參閱建立帶有包含列的索引。
指定 ALL 時,將重新組織與指定表或檢視相關聯的所有索引,並且壓縮與聚集索引、基礎表或具有包含列的非聚集索引相關聯的所有 LOB 列。
- OFF
-
不壓縮包含大型物件資料的頁。
OFF 對堆沒有影響。
如果 LOB 列不存在,則忽略 LOB_COMPACTION 子句。
- SET ( <set_index option> [ ,...n] )
-
指定不重新生成或重新組織索引的索引選項。不能為已禁用的索引指定 SET。
- PAD_INDEX = { ON | OFF }
-
指定索引填充。預設值為 OFF。
- ON
-
FILLFACTOR 指定的可用空間百分比應用於索引的中間級頁。如果在 PAD_INDEX 設定為 ON 的同時不指定 FILLFACTOR,則使用 sys.indexes 中儲存的填充因子值。
- OFF 或不指定 fillfactor
-
中間級頁已填充到接近容量限制。這樣將至少為索引可以基於中間頁中的鍵集擁有的最大大小的一行留出足夠的空間。
- FILLFACTOR = fillfactor
-
指定一個百分比,指示在建立或更改索引期間,資料庫引擎對各索引頁的葉級填充的程度。fillfactor 必須為介於 1 至 100 之間的整數值。預設值為 0。
填充因子的值 0 和 100 在所有方面都是相同的。
顯式的 FILLFACTOR 設定只是在索引首次建立或重新生成時應用。資料庫引擎並不會在頁中動態保持指定的可用空間百分比。有關詳細資訊,請參閱 CREATE INDEX (Transact-SQL)。
若要檢視填充因子設定,請使用 sys.indexes。
使用 FILLFACTOR 值建立或更改聚集索引會影響資料佔用的儲存空間量,因為資料庫引擎在建立聚集索引時會再分發資料。
- SORT_IN_TEMPDB = { ON | OFF }
-
指定是否在 tempdb 中儲存排序結果。預設值為 OFF。
- ON
-
在 tempdb 中儲存用於生成索引的中間排序結果。如果 tempdb 位於不同於使用者資料庫的磁碟集中,這樣可能會縮短建立索引所需的時間。但是,這會增加索引生成期間所使用的磁碟空間量。
- OFF
-
中間排序結果與索引儲存在同一資料庫中。
如果不需要執行排序操作,或者可以在記憶體中進行排序,則忽略 SORT_IN_TEMPDB 選項。
- IGNORE_DUP_KEY = { ON | OFF }
-
指定在插入操作嘗試向唯一索引插入重複鍵值時的錯誤響應。IGNORE_DUP_KEY 選項僅適用於建立或重新生成索引後發生的插入操作。當執行 CREATE INDEX、ALTER INDEX 或 UPDATE 時,該選項無效。預設值為 OFF。
- ON
-
向唯一索引插入重複鍵值時將出現警告訊息。只有違反唯一性約束的行才會失敗。
- OFF
-
向唯一索引插入重複鍵值時將出現錯誤訊息。整個 INSERT 操作將被回滾。
對於對檢視建立的索引、非唯一索引、XML 索引、空間索引以及篩選的索引,IGNORE_DUP_KEY 不能設定為 ON。
若要檢視 IGNORE_DUP_KEY,請使用 sys.indexes。
在向後相容的語法中,WITH IGNORE_DUP_KEY 等效於 WITH IGNORE_DUP_KEY = ON。
- STATISTICS_NORECOMPUTE = { ON | OFF }
-
指定是否重新計算分發統計資訊。預設值為 OFF。
- ON
-
不會自動重新計算過時的統計資訊。
- OFF
-
啟用統計資訊自動更新功能。
若要恢復統計資訊自動更新,請將 STATISTICS_NORECOMPUTE 設定為 OFF,或執行 UPDATE STATISTICS 但不包含 NORECOMPUTE 子句。
如果禁用分發統計資訊的自動重新計算,可能會阻止查詢優化器為涉及該表的查詢挑選最佳執行計劃。
- ONLINE = { ON | OFF }
-
指定在索引操作期間基礎表和關聯的索引是否可用於查詢和資料修改操作。預設值為 OFF。
對於 XML 索引或空間索引,僅支援 ONLINE = OFF。如果 ONLINE 設定為 ON,則會引發錯誤。
聯機索引操作僅在 SQL Server Enterprise Edition、Developer Edition 和 Evaluation Edition 中可用。
- ON
-
在索引操作期間不持有長期表鎖。在索引操作的主要階段,源表上只使用意向共享 (IS) 鎖。這樣,即可繼續對基礎表和索引進行查詢或更新。操作開始時,將對源物件保持極短時間的共享 (S) 鎖。操作結束時,如果建立非聚集索引,將對源持有極短時間的 S 鎖;當聯機建立或刪除聚集索引時,或者重新生成聚集或非聚集索引時,將獲取 SCH-M(架構修改)鎖。對本地臨時表建立索引時,ONLINE 不能設定為 ON。
- OFF
-
在索引操作期間應用表鎖。建立、重新生成或刪除聚集索引、空間索引或 XML 索引或者重新生成或刪除非聚集索引的離線索引操作將獲得對錶的架構修改 (Sch-M) 鎖。這樣可以防止所有使用者在操作期間訪問基礎表。建立非聚集索引的離線索引操作將對錶獲取共享 (S) 鎖。這樣可以防止更新基礎表,但允許讀操作(如 SELECT 語句)。
有關詳細資訊,請參閱聯機索引操作的工作方式。有關鎖的詳細資訊,請參閱鎖模式。
索引(包括全域性臨時表中的索引)可以聯機重新生成,但以下索引除外:
- 禁用的索引
- XML 索引
- 本地臨時表中的索引
- 分割槽索引
- 聚集索引(如果基礎表包含 LOB 資料型別)。
- 使用 LOB 資料型別列定義的非聚集索引
如果表包含 LOB 資料型別,但這些列中沒有任何列在索引定義中用作鍵列或非鍵列,則可以聯機重新生成非聚集索引。
- ALLOW_ROW_LOCKS = { ON | OFF }
-
指定是否允許行鎖。預設值為 ON。
- ON
-
在訪問索引時允許使用行鎖。資料庫引擎確定何時使用行鎖。
- OFF
-
不使用行鎖。
- ALLOW_PAGE_LOCKS = { ON | OFF }
-
指定是否允許使用頁鎖。預設值為 ON。
- ON
-
訪問索引時允許使用頁鎖。資料庫引擎確定何時使用頁鎖。
- OFF
-
不使用頁鎖。
ALLOW_PAGE_LOCKS 設定為 OFF 時,無法重新組織索引。
- MAXDOP = max_degree_of_parallelism
-
在索引操作期間覆蓋“最大並行度”配置選項。有關詳細資訊,請參閱 max degree of parallelism 選項。使用 MAXDOP 可以限制在執行並行計劃的過程中使用的處理器數量。最大數量為 64 個處理器。
雖然從語法上講所有 XML 索引都支援 MAXDOP 選項,但對於空間索引或主 XML 索引,ALTER INDEX 當前只使用一個處理器。
max_degree_of_parallelism 可以是:
- 1
-
取消生成並行計劃。
- >1
-
將並行索引操作中使用的最大處理器數量限制為指定數量。
- 0(預設值)
-
根據當前系統工作負荷使用實際的處理器數量或更少數量的處理器。
並行索引操作僅在 SQL Server Enterprise Edition、Developer Edition 和 Evaluation Edition 中可用。
- DATA_COMPRESSION
-
為指定的索引、分割槽號或分割槽範圍指定資料壓縮選項。選項如下所示:
- NONE
-
不壓縮索引或指定的分割槽。
- ROW
-
使用行壓縮來壓縮索引或指定的分割槽。
- PAGE
-
使用頁壓縮來壓縮索引或指定的分割槽。
有關壓縮的詳細資訊,請參閱建立壓縮表和索引。
- ON PARTITIONS ( { <partition_number_expression> | <range> } [,...n] )
-
指定對其應用 DATA_COMPRESSION 設定的分割槽。如果索引未分割槽,則 ON PARTITIONS 引數將產生錯誤。如果不提供 ON PARTITIONS 子句,則 DATA_COMPRESSION 選項將應用於分割槽索引的所有分割槽。
可以按以下方式指定 <partition_number_expression>:
- 提供一個分割槽號,例如:ON PARTITIONS (2)。
- 提供若干單獨分割槽的分割槽號並用逗號將它們隔開,例如:ON PARTITIONS (1, 5)。
- 同時提供範圍和單獨的分割槽:ON PARTITIONS (2, 4, 6 TO 8)。
<range> 可以指定為以單詞 TO 隔開的分割槽號,例如:ON PARTITIONS (6 TO 8)。
若要為不同分割槽設定不同的資料壓縮型別,請多次指定 DATA_COMPRESSION 選項,例如:
REBUILD WITH ( DATA_COMPRESSION = NONE ON PARTITIONS (1), DATA_COMPRESSION = ROW ON PARTITIONS (2, 4, 6 TO 8), DATA_COMPRESSION = PAGE ON PARTITIONS (3, 5) )
- 提供一個分割槽號,例如:ON PARTITIONS (2)。
ALTER INDEX 不能用於對索引重新分割槽或將索引移到其他檔案組。此語句不能用於修改索引定義,如新增或刪除列,或更改列的順序。使用帶有 DROP_EXISTING 子句的 CREATE INDEX 執行這些操作。
未顯式指定選項時,則應用當前設定。例如,如果未在 REBUILD 子句中指定 FILLFACTOR 設定,將在重新生成過程中使用系統目錄中儲存的填充因子值。若要檢視當前索引選項設定,請使用 sys.indexes。
系統目錄中不儲存 ONLINE、MAXDOP 和 SORT_IN_TEMPDB 的值。除非在索引語句中指定,否則,將使用選項的預設值。
在多處理器計算機中,就像其他查詢那樣,ALTER INDEX REBUILD 自動使用更多處理器來執行與修改索引相關聯的掃描和排序操作。執行 ALTER INDEX REORGANIZE 時,無論是否有 LOB_COMPACTION,“max degree of parallelism”值均為單個執行緒化操作。有關詳細資訊,請參閱配置並行索引操作。
如果索引所在的檔案組離線或設定為只讀,則無法重新組織或重新生成索引。如果指定了關鍵字 ALL,但有一個或多個索引位於離線檔案組或只讀檔案組中,該語句將失敗。
重新生成索引
重新生成索引將會刪除並重新建立索引。這將根據指定的或現有的填充因子設定壓縮頁來刪除碎片、回收磁碟空間,然後對連續頁中的索引行重新排序。如果指定 ALL,將刪除表中的所有索引,然後在單個事務中重新生成。不必預先刪除 FOREIGN KEY 約束。重新生成具有 128 個區或更多區的索引時,資料庫引擎延遲實際的頁釋放及其關聯的鎖,直到事務提交。有關詳細資訊,請參閱刪除並重新生成大型物件。
重新生成或重新組織小索引不會減少碎片。小索引的頁面儲存在混合區中。混合區最多可由八個物件共享,因此在重新組織或重新生成小索引之後可能不會減少小索引中的碎片。
在早期版本的 SQL Server 中,您有時可以重新生成非聚集索引來更正由硬體故障導致的不一致。在 SQL Server 2008 中,您仍然可以通過離線重新生成非聚集索引來糾正索引和聚集索引之間的這種不一致。但是,您不能通過聯機重新生成索引來糾正非聚集索引的不一致,因為聯機重新生成機制將會使用現有的非聚集索引作為重新生成的基礎,因此仍存在不一致。相反,離線重新生成索引將會強制掃描聚集索引(或堆),因此會刪除不一致。與早期版本一樣,建議通過從備份還原受影響的資料來從不一致狀態進行恢復;但是,您可以通過離線重新生成非聚集索引來糾正索引的不一致。
重新組織索引
使用最少系統資源重新組織索引。通過對葉級頁以物理方式重新排序,使之與葉節點的從左到右的邏輯順序相匹配,進而對錶和檢視中的聚集索引和非聚集索引的葉級進行碎片整理。重新組織還會壓縮索引頁。壓縮基於現有的填充因子值。
如果指定 ALL,將重新組織表中的關係索引(包括聚集索引和非聚集索引)和 XML 索引。指定 ALL 時應用某些限制,請參閱“引數”部分的 ALL 定義。
禁用索引
禁用索引可防止使用者訪問該索引,對於聚集索引,還可防止使用者訪問基礎表資料。索引定義保留在系統目錄中。對檢視禁用非聚集索引或聚集索引會以物理方式刪除索引資料。禁用聚集索引將阻止對資料的訪問,但在刪除或重新生成索引之前,資料在 B 樹中一直保持未維護的狀態。
如果表位於事務複製釋出中,則無法禁用任何與主鍵列關聯的索引。複製需要使用這些索引。若要禁用索引,必須先從釋出中刪除該表。
使用 ALTER INDEX REBUILD 語句或 CREATE INDEX WITH DROP_EXISTING 語句啟用索引。重新生成已禁用聚集索引不能在 ONLINE 選項設定為 ON 時執行。
設定選項
您可以為指定的索引設定選項 ALLOW_ROW_LOCKS、ALLOW_PAGE_LOCKS、IGNORE_DUP_KEY 和 STATISTICS_NORECOMPUTE,而不重新生成或重新組織該索引。修改的值立即應用於索引。
行鎖和頁鎖選項
如果 ALLOW_ROW_LOCKS = ON 並且 ALLOW_PAGE_LOCK = ON,則當訪問索引時將允許行級別、頁級別和表級別的鎖。資料庫引擎將選擇相應的鎖,並且可以將鎖從行鎖或頁鎖升級到表鎖。
如果 ALLOW_ROW_LOCKS = OFF 並且 ALLOW_PAGE_LOCK = OFF,則當訪問索引時只允許表級鎖。有關為索引配置鎖定粒度的詳細資訊,請參閱自定義索引的鎖定。
設定行鎖或頁鎖選項時,如果指定 ALL,這些設定將應用於所有索引。基礎表為堆時,通過以下方式應用這些設定:

聯機索引操作
重新生成索引且 ONLINE 選項設定為 ON 時,基礎物件、表和關聯的索引均可用於查詢和資料修改。更改過程中,排他表鎖只保留非常短的時間。
重新組織索引始終聯機執行。該程式不長期保留鎖,因此,不阻塞正在執行的查詢或更新。
只有在執行以下操作時,才能對同一個表執行併發聯機索引操作:
- 建立多個非聚集索引。
- 在同一個表中重新組織不同索引。
- 在同一個表中重新生成不重疊的索引時,重新組織不同的索引。
同一時間執行的所有其他聯機索引操作都將失敗。例如,您不能在同一個表中同時重新生成兩個索引或更多索引,也不能在同一個表中重新生成現有索引時建立新的索引。
有關詳細資訊,請參閱聯機執行索引操作。
空間索引限制
重新生成空間索引時,基礎使用者表在索引操作持續期間不可用,因為空間索引持有架構鎖。
對使用者表的某一列定義了空間索引時,無法修改該表中的 PRIMARY KEY 約束。若要更改 PRIMARY KEY 約束,首先要刪除該表的每個空間索引。修改 PRIMARY KEY 約束後,您可以重新建立每個空間索引。
在單個分割槽重新生成操作中,無法指定任何空間索引。但是,您可以在完整的分割槽重新生成過程中指定空間索引。
若要更改特定於某個空間索引的選項(例如 BOUNDING_BOX 或 GRID),您可以使用 CREATE SPATIAL INDEX 語句指定 DROP_EXISTING = ON,或刪除該空間索引並建立一個新的空間索引。有關示例,請參閱 CREATE SPATIAL INDEX (Transact-SQL)。
資料壓縮
若要評估更改壓縮狀態將對錶、索引或分割槽有何影響,請使用 sp_estimate_data_compression_savings 儲存過程。
以下限制適用於已分割槽索引:
- 使用 ALTER INDEX ALL ...
時,如果相應表具有非對齊索引,則無法更改單個分割槽的壓縮設定。
- ALTER INDEX <index> ...REBUILD PARTITION ... 語法可重新生成索引的指定分割槽。
- ALTER INDEX <index> ...REBUILD WITH ... 語法可重新生成索引的所有分割槽。
大型物件資料型別壓縮
重新組織索引時,除了重新組織一個或多個索引外,預設情況下還將壓縮聚集索引或基礎表中包含的大型物件資料型別 (LOB)。資料型別 image、text、ntext、varchar(max)、nvarchar(max)、varbinary(max) 和 xml 都是大型物件資料型別。壓縮此資料可以改善磁碟空間使用情況:
- 重新組織指定的聚集索引將壓縮該聚集索引的葉級別(資料行)包含的所有 LOB 列。
- 重新組織非聚集索引將壓縮該索引中屬於非鍵(包含性)列的所有 LOB 列。
- 如果指定 ALL,將重新組織與指定的表或檢視相關聯的所有索引,並壓縮與聚集索引、基礎表或帶有包含列的非聚集索引相關聯的所有 LOB 列。
- 如果 LOB 列不存在,則忽略 LOB_COMPACTION 子句。
二、語句
SET NOCOUNT ON DECLARE @Objectid INT, @Indexid INT,@schemaname VARCHAR(100),@tablename VARCHAR(300),@ixname VARCHAR(500),@avg_fip float,@command VARCHAR(4000) DECLARE IX_Cursor CURSOR FOR SELECT A.object_id,A.index_id,QUOTENAME(SS.NAME) AS schemaname,QUOTENAME(OBJECT_NAME(B.object_id,B.database_id))as tablename ,QUOTENAME(A.name) AS ixname,B.avg_fragmentation_in_percent AS avg_fip FROM sys.indexes A inner join sys.dm_db_index_physical_stats(DB_ID(),NULL,NULL,NULL,'LIMITED') AS B ON A.object_id=B.object_id and A.index_id=B.index_id INNER JOIN SYS.OBJECTS OS ON A.object_id=OS.object_id INNER JOIN sys.schemas SS ON OS.schema_id=SS.schema_id WHERE B.avg_fragmentation_in_percent>10 and B.page_count>20 AND A.index_id>0 AND A.IS_DISABLED<>1
--AND OS.name='book' ORDER BY tablename,ixname OPEN IX_Cursor FETCH NEXT FROM IX_Cursor INTO @Objectid,@Indexid,@schemaname,@tablename,@ixname,@avg_fip WHILE @@FETCH_STATUS=0 BEGIN IF @avg_fip<30.0 SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REORGANIZE '; IF @avg_fip>=30.0 AND @Indexid=1 BEGIN IF EXISTS (SELECT * FROM SYS.columns WHERE OBJECT_ID=@Objectid AND max_length in(-1,16)) SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '; ELSE SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '+N' WITH (ONLINE = ON)'; END IF @avg_fip>=30.0 AND @Indexid>1 BEGIN IF EXISTS (SELECT * FROM SYS.index_columns IC INNER JOIN SYS.columns CS ON CS.OBJECT_ID=IC.OBJECT_ID AND CS.column_id=IC.column_id
WHERE IC.OBJECT_ID=@Objectid AND IC.index_id=@Indexid AND CS.max_length in(-1,16) ) SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '; ELSE SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '+N' WITH (ONLINE = ON)'; END --PRINT @command EXEC(@command) FETCH NEXT FROM IX_Cursor INTO @Objectid,@Indexid,@schemaname,@tablename,@ixname,@avg_fip END CLOSE IX_Cursor DEALLOCATE IX_Cursor
注意:該語句不適合所有人,大家根據自己的需求進行修改。
|
備註: 作者:pursuer.chen 部落格:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結,否則保留追究責任的權利。 《歡迎交流討論》 |