標籤:SQL SERVER/MSSQL SERVER/資料庫/DBA/索引體系結構/非聚集索引
概述
非聚集索引與聚集索引具有相同的 B 樹結構,它們之間的顯著差別在於以下兩點:
- 基礎表的資料行不按非聚集鍵的順序排序和儲存。
- 非聚集索引的葉層是由索引頁而不是由資料頁組成。
既可以使用聚集索引來為表或檢視定義非聚集索引,也可以根據堆來定義非聚集索引。非聚集索引中的每個索引行都包含非聚集鍵值和行定位符。此定位符指向聚集索引或堆中包含該鍵值的資料行。
非聚集索引行中的行定位器或是指向行的指標,或是行的聚集索引鍵,如下所述:
- 如果表是堆(意味著該表沒有聚集索引),則行定位器是指向行的指標。該指標由檔案識別符號 (ID)、頁碼和頁上的行數生成。整個指標稱為行 ID
(RID)。
- 如果表有聚集索引或索引檢視上有聚集索引,則行定位器是行的聚集索引鍵。如果聚集索引不是唯一的索引,SQL Server 將新增在內部生成的值(稱為唯一值)以使所有重複鍵唯一。此四位元組的值對於使用者不可見。僅當需要使聚集鍵唯一以用於非聚集索引中時,才新增該值。SQL Server 通過使用儲存在非聚集索引的葉行內的聚集索引鍵搜尋聚集索引來檢索資料行。
對於索引使用的每個分割槽,非聚集索引在 index_id >0 的 sys.partitions 中都有對應的一行。預設情況下,一個非聚集索引有單個分割槽。如果一個非聚集索引有多個分割槽,則每個分割槽都有一個包含該特定分割槽的索引行的 B 樹結構。例如,如果一個非聚集索引有四個分割槽,那麼就有四個 B 樹結構,每個分割槽中一個。
根據非聚集索引中資料型別的不同,每個非聚集索引結構會有一個或多個分配單元,在其中儲存和管理特定分割槽的資料。每個非聚集索引至少有一個針對每個分割槽的 IN_ROW_DATA 分配單元(儲存索引 B 樹頁)。如果非聚集索引包含大型物件 (LOB) 列,則還有一個針對每個分割槽的 LOB_DATA 分配單元。此外,如果非聚集索引包含的可變長度列超過 8,060 位元組行大小限制,則還有一個針對每個分割槽的 ROW_OVERFLOW_DATA 分配單元。有關分配單元的詳細資訊,請參閱表組織和索引組織。B 樹的頁集合由 sys.system_internals_allocation_units 系統檢視中的 root_page 指標定位。
要很好的理解這篇文章的內容之前需要先閱讀我前面寫的上中部分的兩篇文章:
正文
非聚集索引結構

生成測試資料
CREATE TABLE Torder (ID INT IDENTITY(1,1) NOT NULL, NAME CHAR(100) NOT NULL, pro VARCHAR(8000) NULL, Statu INT NOT NULL, IDATE DATETIME DEFAULT(GETDATE()) ) GO ---插入1000條測試資料 DECLARE @ID INT=1 WHILE(@ID<=1000) BEGIN INSERT INTO Torder(NAME,pro,Statu)VALUES('商品'+CONVERT(CHAR(20),@ID),REPLICATE(1,8000),LEFT(@ID,1)) SET @ID=@ID+1 END GO ---建立非聚集索引 CREATE INDEX IX_Torder ON Torder (NAME,Statu ) INCLUDE(IDATE) SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page FROM sys.objects so INNER JOIN sys.partitions sp ON so.object_id = sp.object_id INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id WHERE so.object_id = object_id('Torder')

由於建立的表只有非聚集索引,所以整個表的頁儲存中有三部分資料:堆頁面、溢位頁面、索引頁面;
堆中共有20個資料頁和一個IAM頁;
溢位單元有1001個頁面包括一個IAM頁;
索引中共有20個頁其中18個資料頁一個ROOT頁和一個IAM頁.
一個堆頁對應多個溢位頁,因為Pro有8000個位元組所以一行佔一頁,而表的其它欄位只有116個位元組一個堆頁可以存50條記錄,所以並不是一個溢位頁就唯一對應一個堆頁
分析頁的儲存資訊
---開啟跟蹤標誌 DBCC TRACEON(3604,2588) --DBCC TRACEOFF(3604,2588) ---獲取物件的資料頁,結構:資料庫、物件、顯示 DBCC IND(Ixdata,Torder,-1)
上一章中已經講過了堆頁面和溢位頁面,所以現在就講非聚集索引頁
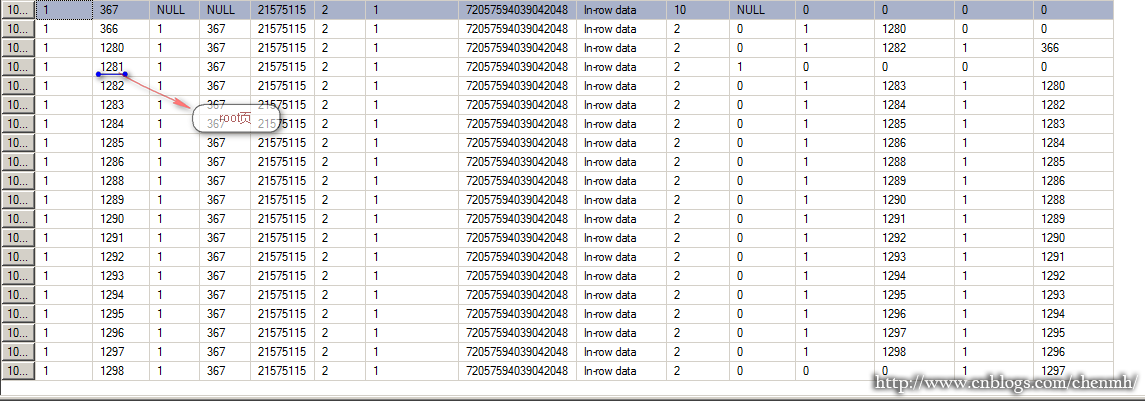
看過前面的文章應該一眼就能看出1281頁是ROOT頁,現在就分析1281頁
分析非聚集索引根頁
DBCC page(Ixdata,1,1281,3)

現在來分析行定位指標是怎樣的:0x6801000001002F00
除去開頭的16進位制標示,剩下總共8個位元組,從右往左其中行號2個位元組,檔案標示ID2個位元組,剩下的4個位元組就是頁號了,所以
行號(002f)=47
檔案頁(0001)=1
頁號(00000168)=360頁
現在檢視360頁的資訊
DBCC page(Ixdata,1,360,3)

47行的記錄正好是“商品150”
分析非聚集索引索引頁
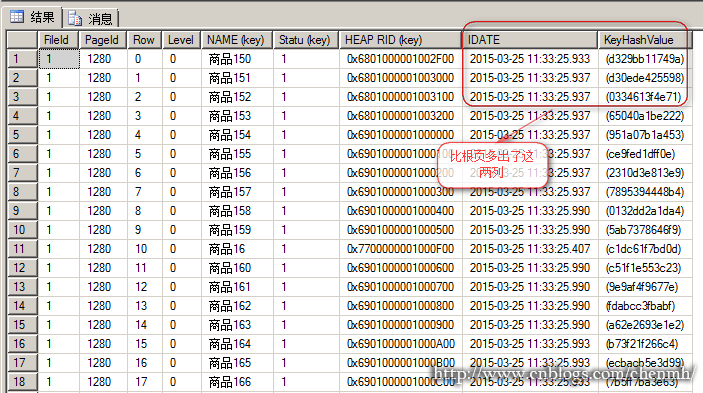
通過對比會發現索引頁比根頁多出了索引包含列值和鍵的雜湊值,這個裡面的keyhashvalue應該是NAME和statu欄位的值通過某種方法算出來的,這裡只是猜測通過平時的查詢你會產生這樣的猜測。
測試簡單的查詢
這裡的'商品150'和'商品153'都是1280頁中的記錄,1280頁是索引頁,其中'商品150'是該頁的第一條記錄
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品153' --COMMIT 另開一個視窗 SELECT [request_session_id], c.[program_name], DB_NAME(c.[dbid]) AS dbname, [resource_type], [request_status], [request_mode], [resource_description],OBJECT_NAME(p.[object_id]) AS objectname, p.[index_id] FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p ON a.[resource_associated_entity_id]=p.[hobt_id] LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查詢申請鎖的資料庫 ORDER BY [request_session_id],[resource_type]



從上面的查詢過程可以知道頁面總共讀取了三次(索引葉一次堆頁一次溢位頁一次)。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ GO BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品150'



通過對比查詢'商品150'和'商品153'可以看到如果查詢的頁面的第一條記錄,它需要再讀取該索引頁的前一個頁面,如果該索引頁是第一頁就無需再讀除本身的其他索引頁了,文章寫到後面反過來思考才知道為什麼非聚集索引還需要多查詢一個頁面了。因為非聚集索引是允許存在重複值所以才需要再往前查詢,如果前面一個頁查詢不到則結束,如果前面一個頁還沒查完會再往前一個頁進行查,當然查詢商品153的時候就已經判斷了前一條記錄的鍵值是不一樣的否則也是要再查詢前一個頁,這也是非聚集索引的一個特殊情況吧!
索引掃描
update Torder set statu=100 where id=1 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ GO BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE [Statu]=100
該查詢總共掃描了18個索引頁+1個堆頁+1個溢位頁.
建立聚集索引
ALTER TABLE dbo.Torder ADD CONSTRAINT PK_Torder PRIMARY KEY CLUSTERED ( ID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page FROM sys.objects so INNER JOIN sys.partitions sp ON so.object_id = sp.object_id INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id WHERE so.object_id = object_id('Torder')

非聚集索引資料頁比之前少了一頁

由於現在的指標比之前的16進位制指標要所佔有的位元組要少,所以只需要17個頁面就可以存下。
分析索引頁148
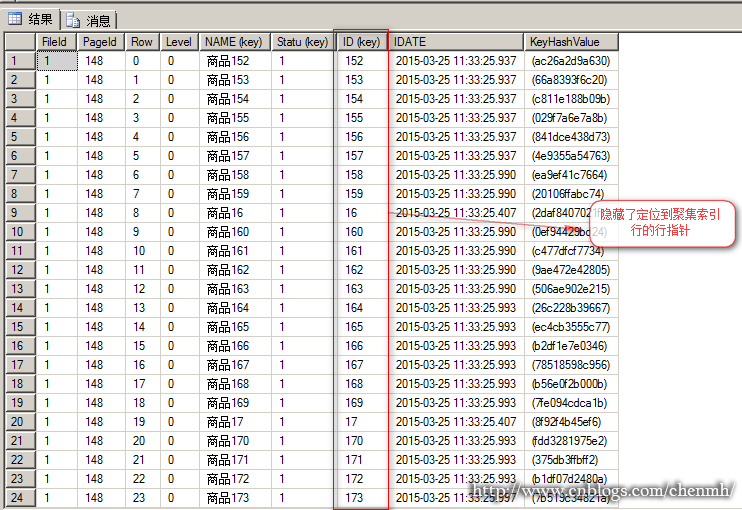
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品152' 在另一個視窗開啟 SELECT [request_session_id], c.[program_name], DB_NAME(c.[dbid]) AS dbname, [resource_type], [request_status], [request_mode], [resource_description],OBJECT_NAME(p.[object_id]) AS objectname, p.[index_id] FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p ON a.[resource_associated_entity_id]=p.[hobt_id] LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查詢申請鎖的資料庫 ORDER BY [request_session_id],[resource_type]
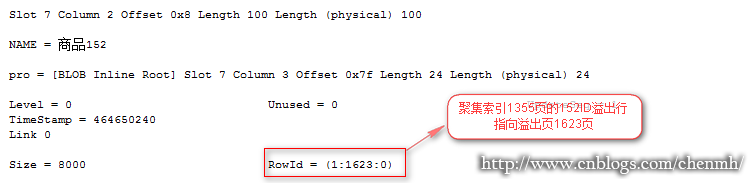


從上面的邏輯讀取和查詢步驟可以證實前面的猜測,應該是隱藏了一張行定位表。
如果表有聚集索引或索引檢視上有聚集索引,則行定位器是行的聚集索引鍵。如果聚集索引不是唯一的索引,SQL Server 將新增在內部生成的值(稱為唯一值)以使所有重複鍵唯一。此四位元組的值對於使用者不可見。僅當需要使聚集鍵唯一以用於非聚集索引中時,才新增該值。SQL Server 通過使用儲存在非聚集索引的葉行內的聚集索引鍵搜尋聚集索引來檢索資料行。
檢視索引統計資訊
DBCC SHOW_STATISTICS ("dbo.Torder", IX_Torder);

前面建的包含索引有這三種組合方式,所以組合索引的第二個欄位不被用來單獨做查詢。
總結
非聚集索引和聚集索引不一樣,聚集索引索引頁的鍵值指向資料頁的具體行;而非聚集索引不存在資料頁,非聚集索引的索引頁中的記錄行指向聚集索引或者堆的具體資料頁的資料行然後來獲取記錄,如果堆或聚集索引還存在溢位的話,從堆或者聚集索引的資料記錄還有指向溢位頁面的指標。
補充一下在非聚集索引中存在聚集索引與堆的優點,看完上文你會發現非聚集索引的資料頁記錄的行定位指標分別指向聚集索引或堆的行,但是指向聚集索引的行定位是邏輯值而指向堆的是實際的rid值,邏輯值的好處就是在聚集索引發生分頁的情況下,邏輯值不用改變也就無需更新非聚集索引的指標。
花了四天時間終於把這個系列的寫完了,重新去理解一遍把以前的一些不理解的知識點給弄明白了,還是收穫很多。
如果文章對大家有幫助,希望大家能給個推薦,謝謝!!!
|
備註: 作者:pursuer.chen 部落格:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結,否則保留追究責任的權利。 《歡迎交流討論》 |