標籤:SQL SERVER/MSSQL SERVER/資料庫/DBA/索引體系結構/堆/聚集索引
概述
最近要分享一個課件就重新把這塊知識整理了一遍出來,篇幅有點長,想要理解的透徹還是要上機實踐。
聚集索引
--建立測試資料庫 CREATE DATABASE Ixdata GO USE [Ixdata] GO ---建立測試表 CREATE TABLE Orders (ID INT PRIMARY KEY IDENTITY(1,1), NAME CHAR(80)NOT NULL, IDATE DATETIME NOT NULL DEFAULT(GETDATE()) ); GO ---插入1000條測試資料 DECLARE @ID INT=1 WHILE(@ID<=1000) BEGIN INSERT INTO Orders(NAME)VALUES('商品'+CONVERT(NVARCHAR(20),@ID)) SET @ID=@ID+1 END GO SELECT * FROM Orders GO
分析新建立的表的頁的資訊
---顯示跟蹤標誌的狀態 DBCC TRACESTATUS ---開啟跟蹤標誌 DBCC TRACEON(3604,2588) --DBCC TRACEOFF(3604,2588) ---獲取物件的資料頁,結構:資料庫、物件、顯示 DBCC IND(Ixdata,Orders,-1)
/*
1:顯示所有分頁的資訊,包括IAM分頁,資料分頁,所有存在的LOB分頁和行溢位頁,索引分頁
-1: 顯示所有IAM、資料分頁、及指定物件上全部索引的索引分頁.
-2: 顯示指定物件的所有IAM分頁
0:顯示所有IAM、資料分頁.
*/
DBCC IND的表結構

還可以通過另一種方法來測試:
SELECT DISTINCT so.name, so.object_id,i.name AS index_name,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page FROM sys.objects so INNER JOIN sys.partitions sp ON so.object_id = sp.object_id INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id LEFT JOIN sys.indexes i ON so.object_id=i.object_id AND sp.index_id=i.index_id WHERE so.object_id = object_id('orders')

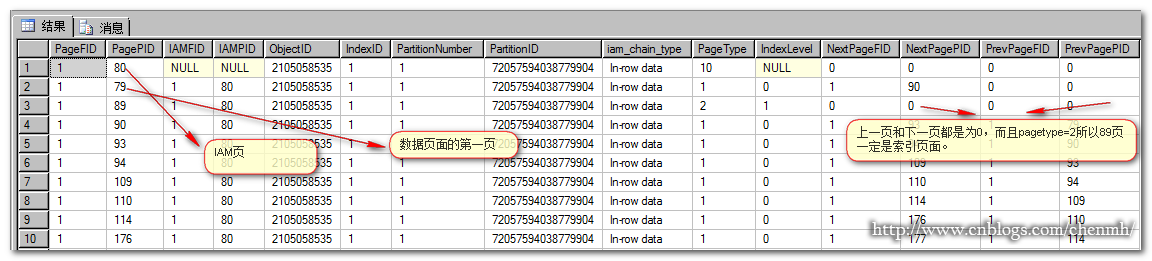
最後三個欄位分別是IAM頁,根頁,和第一個資料頁;它們分別用16進位制來表示,拿first_iam_page來分析,首先將編碼從右往左一個位元組接著一個位元組反過來排行(0X代表16進位制),結果就是0X,00 01,00 00 00 50;前兩個位元組代表檔案組號,最後4個位元組代表頁號。16進位制的0001轉換成10進位制就是1;16進位制的00 00 00 50轉換成10進位制就是5*16的1次方=5*16=80,所以第一個資料頁是4*16+15=79,根頁是5*16+9=89 結果和前面的查詢出來的結果是一樣的。從表格的otal_pages,used_pages,data_pages得到的結果也和前面查詢出來的結果是一致的,總分配了17個頁,使用了15個頁包括13個資料頁+1個IAM頁+1個索引頁。
手繪一張當前表格的聚集索引體系結構圖:

分析索引頁
---DBCC page的格式為(資料庫,檔案id,頁號,顯示) DBCC page(Ixdata,1,89,3)

分析結果89頁下面的子頁總共有13頁,每頁80條記錄,89索引頁記錄了每頁的的鍵值的最小值,第一頁就是id為1-80,第二頁81-160,所以當你要找ID為150的資料的時候直接就可以去第90頁裡面找了。
PAGE HEADER

分析資料頁

通過這些資料我們基本上可以知道90頁的基本情況了,包括它的欄位長度,上一頁、下一頁,還有該頁的所以記錄(這裡沒有截圖出來).
插入20萬條記錄分析索引結構
--插入20萬條記錄分析索引結構 DECLARE @ID INT=1 WHILE(@ID<=200000) BEGIN INSERT INTO Orders(NAME)VALUES('商品'+CONVERT(NVARCHAR(20),@ID)) SET @ID=@ID+1 END CREATE TABLE Page ( PageFID TINYINT, PagePID INT, IAMFID TINYINT, IAMPID INT, ObjectID INT, IndexID TINYINT, PartitionNumber TINYINT, PartitionID BIGINT, iam_chain_type VARCHAR(30), PageType TINYINT, IndexLevel TINYINT, NextPageFID TINYINT, NextPagePID INT, PrevPageFID TINYINT, PrevPagePID INT ); GO INSERT INTO Page EXEC('DBCC IND(Ixdata,Orders,-1)') ---查詢索引頁 SELECT [PageFID] ,[PagePID] ,[IAMFID] ,[IAMPID] ,[ObjectID] ,[IndexID] ,[PartitionNumber] ,[PartitionID] ,[iam_chain_type] ,[PageType] ,[IndexLevel] ,[NextPageFID] ,[NextPagePID] ,[PrevPageFID] ,[PrevPagePID] FROM [Ixdata].[dbo].[Page] WHERE PageType=2 go select so.name, so.object_id, sp.index_id, internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page from sys.objects so inner join sys.partitions sp on so.object_id = sp.object_id inner join sys.allocation_units sa on sa.container_id = sp.hobt_id inner join sys.system_internals_allocation_units internals on internals.container_id = sa.container_id where so.object_id = object_id('orders')
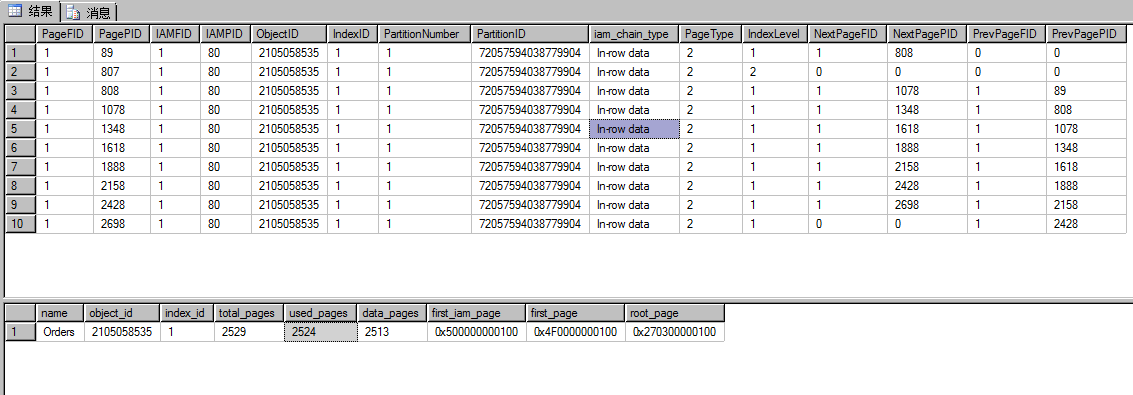
通過兩種方法查詢到的索引頁的數量是一樣的,下面的這種計算方法是2524-2513-1(IAM頁)=10,其中807頁是root_page頁它在第二級,其它的是中間級索引頁頁就是第一級;頁可以通過下面的16進位制計算出來,IAM=5*16=80,ROOT_PAGE=3*16*16+2*16+7=807
再分析89頁
---DBCC page的格式為(資料庫,檔案id,頁號,顯示) DBCC page(Ixdata,1,89,3)
查詢結果總共有269行,頁就是269個資料頁,orders表總共插入了201000條記錄,一個頁面存80條記錄,就需要2513個頁面和上面查詢到的data_page是一樣的。每個索引頁儲存269個資料頁面就需要(‘select 2513*1.0/269’除不盡加1)10個索引頁,查詢最後一個索引頁2698發現它還沒分頁共儲存了361條記錄,總共8*269+361=2513
手繪儲存結構

手繪的有點難看,但是意思差不多表達出來了。
大型物件 (LOB) 列
根據聚集索引中的資料型別,每個聚集索引結構將有一個或多個分配單元,將在這些單元中儲存和管理特定分割槽的相關資料。每個聚集索引的每個分割槽中至少有一個 IN_ROW_DATA 分配單元。如果聚集索引包含大型物件 (LOB) 列,則它的每個分割槽中還會有一個 LOB_DATA 分配單元。如果聚集索引包含的變數長度列超過 8,060 位元組的行大小限制,則它的每個分割槽中還會有一個 ROW_OVERFLOW_DATA 分配單元。
---建立測試表 CREATE TABLE Orderslob (ID INT PRIMARY KEY IDENTITY(1,1), NAME CHAR(80)NOT NULL, Product NVARCHAR(MAX) NOT NULL, IDATE DATETIME NOT NULL DEFAULT(GETDATE()) ); GO ---插入1000條測試資料 DECLARE @ID INT=1 WHILE(@ID<=1000) BEGIN INSERT INTO Orderslob(NAME,Product)VALUES(CONVERT(NVARCHAR(20),@ID)+'商品',REPLICATE(@ID,2)) SET @ID=@ID+1 END --REPLICATE(@ID,200) GO DBCC IND(Ixdata,Orderslob,1)

--檢視2719資料頁的資訊 DBCC page(Ixdata,1,2719,1)

結果記錄了每一條記錄的偏移量。
每個人在自己的電腦上面測試頁面id會不一樣,但是反應的結果是一樣的。
|
備註: 作者:pursuer.chen 部落格:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結,否則保留追究責任的權利。 《歡迎交流討論》 |