- 原文地址:Scaling Node.js Applications
- 原文作者:Samer Buna
- 譯文出自:掘金翻譯計劃
- 本文永久連結:github.com/xitu/gold-m…
- 譯者:mnikn
- 校對者:shawnchenxmu,reid3290
擴充套件 Node.js 應用
你應該知道的在 Node.js 內建模組的應用於擴充套件的工具

來自 Pluralsight 課程中的截圖 - Node.js 進階
可擴充套件性在 Node.js 並不是事後新增的概念,這一概念在前期就已經體現出其核心地位。Node 之所以被命名為 Node 的原因就是強調一個想法:每一個 Node 應用應該由多個小型的分散 Node 應用相互聯絡來構成。
你曾經在你的 Node 應用上執行多個 Node 應用嗎?你曾經試過讓生產環境上的機器的每個 CPU 執行一個 Node 程式,並且對所有的請求進行負載均衡處理嗎?你知道 Node 有一個內建模組能做上述事情嗎?
Node 的 cluster 模組不只是提供一個黑箱的解決方案來充分利用機器中的 CPU,同時它也能幫助你提高 Node 應用的可用性,提供一個瞬時重啟整個應用的選項,這篇文章將闡述其中的所有好處。
這篇文章是 Pluralsight Node.js 課程 中的一部分,我從視訊中整理出了相關的內容。
實現擴充套件的策略
我們擴充套件一個應用的最主要的原因是應用的負載,但是不只是這一個原因。我們同時通過讓應用具備可擴充套件性來提高應用的可用性和容錯性。
我們可以通過三種主流的方式來擴充應用:
1 — 克隆
擴充套件一個大型應用最簡單的方法就是多次克隆它,並讓每一個克隆例項處理一部分工作(例如,使用負載均衡器)。這種做法不會佔用開發週期太多時間,並且真的很管用。想要在最低限度上實現擴充套件,你可以使用這種方法,Node.js 有個內建模組 cluster 來讓你在一個單一的伺服器上更簡單地實現克隆方法。
2 — 分解
同時我們也可以通過 分解 來擴充套件一個應用,這種方法取決於應用的函式和服務。這意味著我們有多個不同的應用,各有著不同的基架程式碼,有時還會有其獨自的資料庫和使用者介面。
這個策略一般和微服務聯絡在一起,其中的微是指每個服務應該越小越好,但實際上,服務的規模無關緊要,為的是強迫人們解耦和讓服務之間高內聚。實現這個策略並不容易,並有可能帶來一系列預想不到的問題,但是其益處也是很顯著的。
3 — 分離
我們同時也可以把應用分成多個例項,每個例項只負責應用的一部分資料。這個方法在資料庫領域內通常被稱為橫向分割或碎片化。資料分割要求每一步操作前都需要查詢當前在使用哪一個例項。例如,我們也許想要根據使用者所在的國家或者所用的語言進行分割槽,首先我們需要查詢相關資訊。
成功擴充套件一個大型應用最終應該實現這三個策略。Node.js 讓這一切變得簡單,因此這篇文章我將會把注意力集中在克隆策略上,看看 Node.js 有什麼可用的內建工具來實現這個策略。
請注意到在讀這篇文章前你需要理解好 Node.js 的子程式。如果你不太瞭解,我建議你可以先讀這篇文章:
cluster 模組
想要在同一環境下多個 CPU 的情況開啟負載均衡,我們可以使用 cluster 模組。這基於子程式模組的 fork 方法,基本上它允許我們多次 fork 主應用並用在多個 CPU 上。然後它接管所有的子程式,並將所有對主程式的請求負載均衡到子程式中去。
Node.js 的 cluster 模組幫助我們實現可擴充性克隆策略,但是這隻適用於在只有一臺伺服器上的情況。如果你有一臺可以儲存著大量的資源的伺服器,或者在一臺伺服器上新增資源比增添新伺服器更容易和便宜時,採用 cluster 模組來快速執行克隆策略是一個不錯的選擇。
即使是一個小型的伺服器通常也會有多個核心,甚至如果你不擔心 Node 伺服器負載過重的話,可以任意開啟 cluster 模組來提高伺服器的可用性和容錯性。執行這一步操作很簡單,當你使用像 PM2 這樣的程式管理器,你要做的就只是簡單地給啟動命令提供一個引數而已!
接著讓我來跟你講講該如何使用原生的 cluster 模組,並且我會解釋它是怎麼工作的。
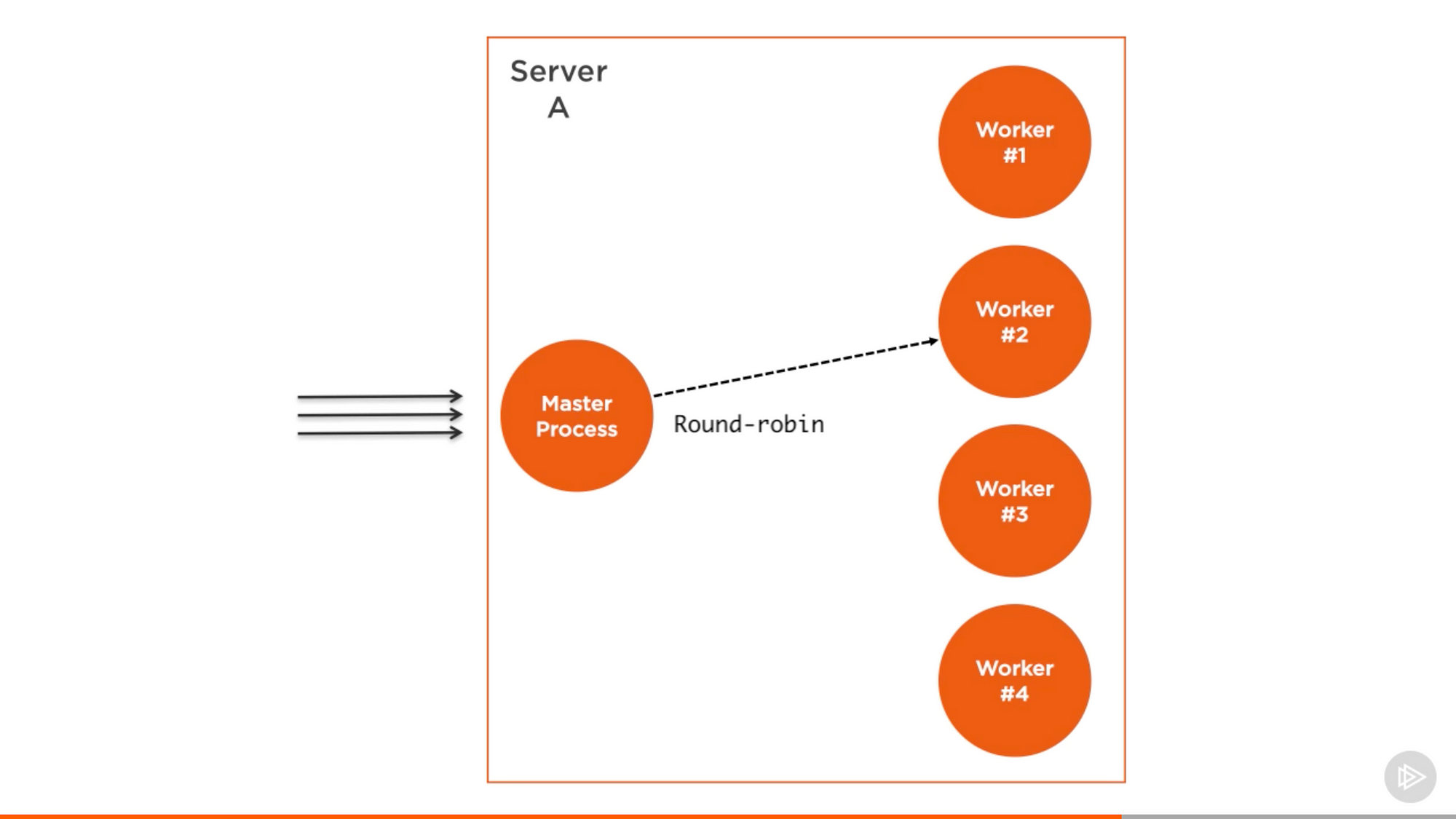
cluster 模組的結構很簡單,我們建立一個 master 程式,並且讓這個 master 程式 fork 多個 worker 程式並管理它們,每一個 worker 程式代表需要可擴充的應用的例項。所有請求都由 master 程式處理,這個程式會給每個 worker 程式分配其中一部分需要處理的請求。
Pluralsight 課程上的截圖 — Node.js 進階
master 程式的工作很簡單,實際上它只是使用輪替演算法來挑選 worker 程式。除了 Windows 以外的作業系統都預設開啟了這個演算法,並且它能通過全域性修改來讓作業系統本身來處理負載均衡。
輪替演算法讓負載輪流地均勻分佈在可用程式。第一個請求會指向第一個 worker 程式,第二個請求指向列表上的下一個程式,以此類推。當列表已經遍歷完,演算法會從頭開始。
這是其中一種最簡易並且也是最常用的負載均衡演算法,但是並不是只有這一個。還有很多各具特色的演算法能分配優先順序和抽選負載最小或者響應速度最快的伺服器。
HTTP 伺服器上的負載均衡
讓我們克隆一個簡單的 HTTP 伺服器並通過 cluster 模組實現負載均衡。這是一個簡單的 Node hello-word 例子,我們修改一下讓它模擬響應前的 CPU 工作。
// server.js
const http = require('http');
const pid = process.pid;
http.createServer((req, res) => {
for (let i=0; i<1e7; i++); // simulate CPU work
res.end(`Handled by process ${pid}`);
}).listen(8080, () => {
console.log(`Started process ${pid}`);
});複製程式碼為了檢驗負載均衡器我們需要建立一些東西來讓它工作,我已經在 HTTP 響應中引進了程式 pid 來識別目前正在處理請求的應用的例項。
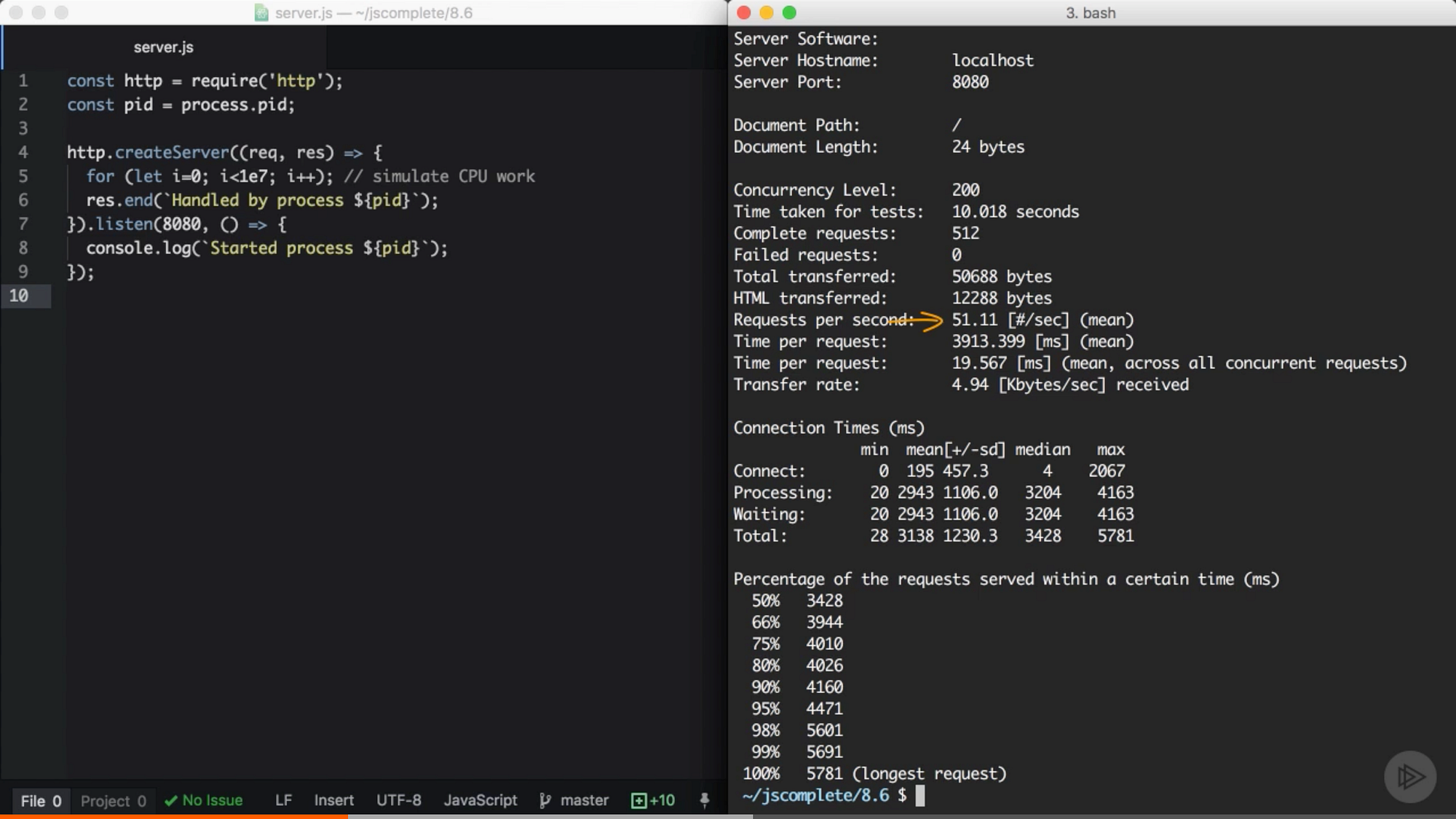
在我們使用 cluster 模組把伺服器中的主程式克隆成多個 worker 程式之前,我們應該先調查下伺服器每秒能夠處理多少個請求。我們可以用 Apache 基準測試工具 來做這件事。在執行 server.js 之前,我們先執行 ab 命令:
ab -c200 -t10 http://localhost:8080/複製程式碼這個命令會在 10 秒內發起 200 個併發連線來測試伺服器的負載效能。
來自 Pluralsight 課程中的截圖 — Node.js 進階
在我的伺服器上,單獨一個 node 伺服器每秒可以處理 51 個請求。當然,結果會隨著平臺的不同而有所變化,這只是一個非常簡化的效能測試,並不能保證結果 100% 準確,但是它將會清晰地顯示 cluster 模組給多核的應用環境所帶來的不同。
既然我們有了一個參照的基準,我們就可以通過 cluster 模組來實現克隆策略,以此來擴充一個應用的規模。
在 server.js 的同級目錄上,我們可以建立一個名叫 cluster.js 的新檔案,用來提供 master 程式:
// cluster.js
const cluster = require('cluster');
const os = require('os');
if (cluster.isMaster) {
const cpus = os.cpus().length;
console.log(`Forking for ${cpus} CPUs`);
for (let i = 0; i<cpus; i++) {
cluster.fork();
}
} else {
require('./server');
}複製程式碼在 cluster.js 檔案裡,我們首先引入 cluster 和 os 模組,我們需要 os 模組裡的 os.cpus() 方法來得到 CPU 的數量。
cluster 模組給了我們一個便利的 Boolean 引數 isMaster 來確定 cluster.js 是否正在被 master 程式讀取。當我們第一次執行這個檔案時,我們會執行在 master 程式上,因此 isMaster 為 true。在這種情況下,我們讓 master 程式多次 fork 我們的伺服器,直到 fork 的次數達到 CPU 的數量。
現在我們只是通過 os 模組來讀取 CPU 的數量,然後對這個數字進行一個 for 迴圈,在迴圈內部呼叫 cluster.fork 方法。for 迴圈將會簡單地建立和 CPU 數量一樣多的 worker 程式,以此來充分利用伺服器可用的計算能力。
當 cluster.fork 這一行在 master 程式中被執行時,當前的 cluster.js 檔案會再執行一次,但是這一次是在 worker 程式,其中的 isMaster 引數為 false。實際上在這種情況下,另外一個引數將為 true,這個引數是 isWorker 引數。
當應用執行在 worker 程式上,它開始做實際的工作。我們就在這裡定義伺服器的業務邏輯,例如,我們可以通過請求已經有的 server.js 檔案來實現業務邏輯。
基本就是這樣了。這樣就能簡單地充分利用伺服器的計算能力。想要測試 cluster,執行 cluster.js 檔案: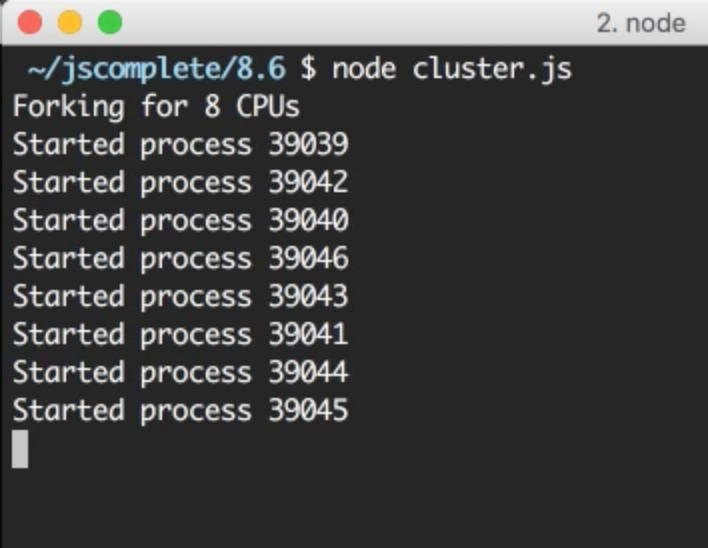
來自 Pluralsight 課程中的截圖 — Node.js 進階
我的伺服器有 8 核因此我要開啟 8 個程式。其中重要的是要理解它們和 Node.js 裡的程式完全不同。每個 worker 程式有其獨自的事件迴圈和記憶體空間。
當我們多次請求網路伺服器,這些請求將會由不同的 worker 程式處理,worker 程式的 id 也各不相同。序列裡的 worker 程式不會準確地進行輪換,因為 cluster 模組在挑選下一個處理請求的 worker 程式時進行了一些優化,負載會分佈在不同的 worker 程式中。
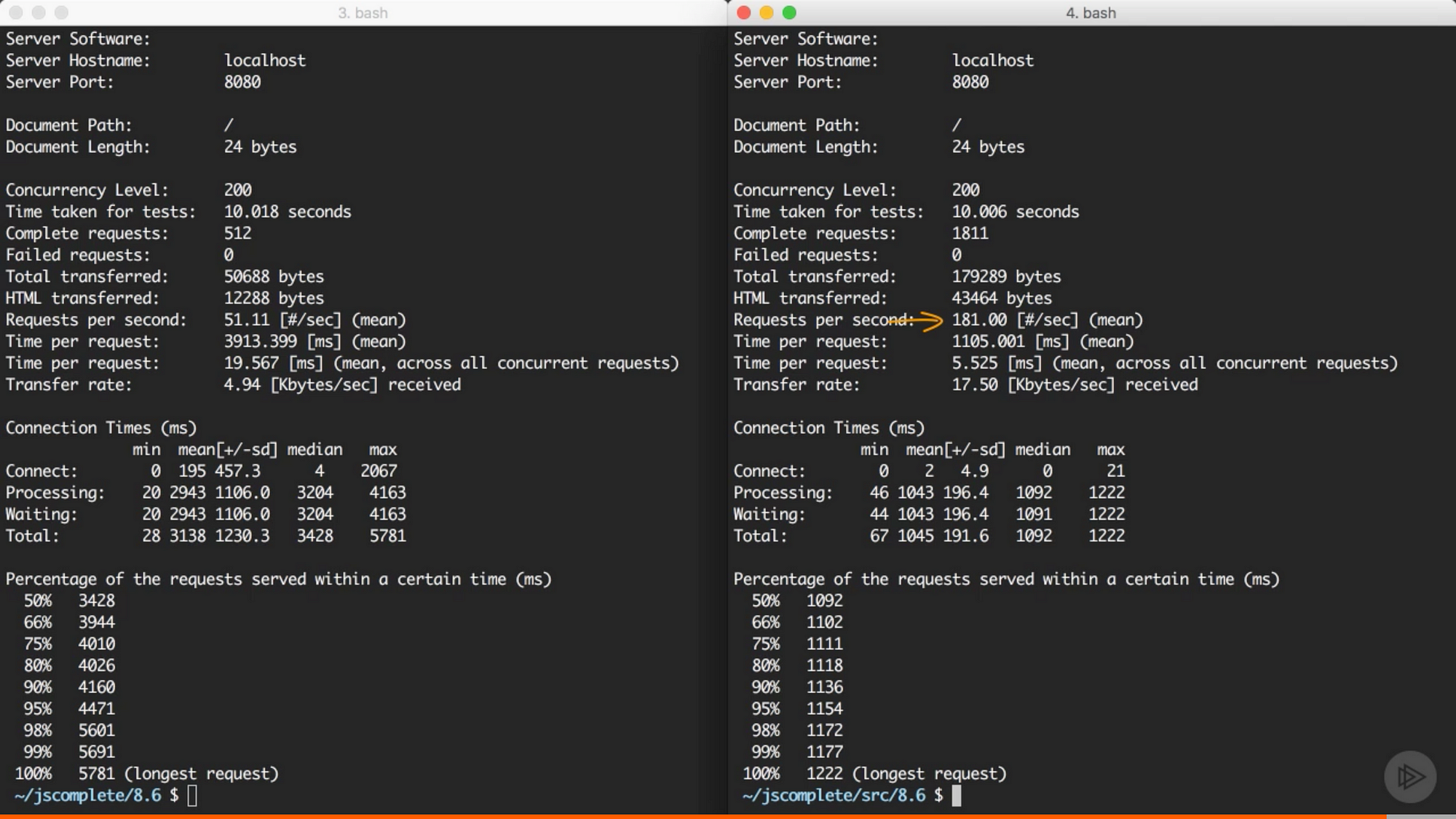
我們同樣可以使用先前的 ab 命令來測試 cluster 中的程式的負載:
來自 Pluralsight 課程中的截圖 — Node.js 進階
同樣是單獨的 node 伺服器,建立 cluster 後伺服器每秒能夠處理 181 個請求,沒用 cluster 模組之前每秒只能處理 51 個請求。我們只是增加了幾行程式碼,應用的效能就提高了 3 倍。
廣播所有 Worker 程式
master 程式與 worker 程式之間能夠簡單地進行通訊,因為 cluster 模組有個 child_process.fork 的 api,這意味著 master 程式與每個 worker 程式之間進行通訊是可能的。
基於 server.js/cluster.js 的例子,我們可以用 cluster.workers 獲取一個包含所有 worker 物件的列表,該列表持有所有 worker 的引用,並可以通過這個引用來讀取 worker 的資訊。有了讓 master 程式和 worker 程式通訊的方法後,想要廣播每個 worker 程式,我們只需要簡單地遍歷所有的 worker。例如:
Object.values(cluster.workers).forEach(worker => {
worker.send(`Hello Worker ${worker.id}`);
});複製程式碼通過 Object.values 可以從 cluster.workers 物件裡簡單地來獲取一個包含所有 worker 的陣列。然後對於每個 worker,我們使用 send 函式來傳遞任意我們要傳的值。
在一個 worker 檔案裡,在我們的例子中 server.js 要讀取從 master 程式中收到的訊息,我們可以在全域性 process 物件中給 message 事件註冊一個 handler。
process.on('message', msg => {
console.log(`Message from master: ${msg}`);
});複製程式碼當我在 cluster/server 上測試這兩項新加的東西時所看到:
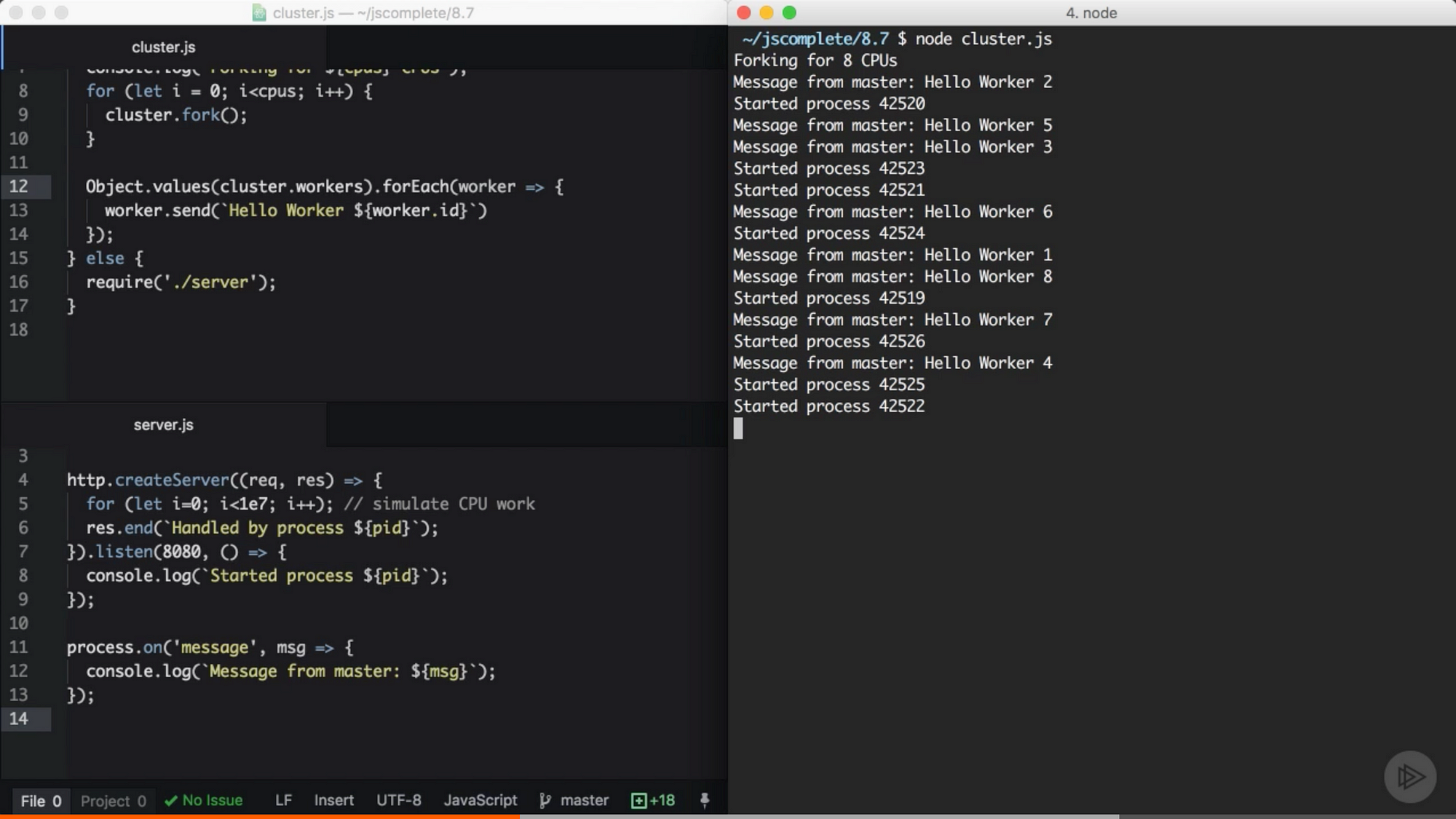
來自 Pluralsight 課程中的截圖 — Node.js 進階
每個 worker 都收到了來自 master 程式的訊息。注意到 worker 的啟動是亂序的。
這次我們讓通訊的內容變得更實際一點。這次我們想要伺服器返回資料庫中使用者的數量。我們將會建立一個 mock 函式來返回資料庫中使用者的數量,並且每次當它被呼叫時對這個值進行平方處理(理想情況下的增長):
// **** 模擬 DB 呼叫
const numberOfUsersInDB = function() {
this.count = this.count || 5;
this.count = this.count * this.count;
return this.count;
}
// ****複製程式碼每次 numberOfUsersInDB 被呼叫,我們會假設已經連線資料庫。我們想要避免多次資料庫的請求,因此我們會根據一定時間對呼叫進行快取,例如每 10 秒快取一次。然而,我們仍然不想讓 8 個 forked worker 使用獨自的資料庫連線和每 10 秒關閉 8 個資料庫連線。我們可以讓 master 程式只請求一次資料庫連線,然後通過通訊介面告訴這 8 個 worker 使用者數量的最新值。
例如,在 master 程式模式中,我們同樣可以遍歷所有 worker 來廣播使用者數量的值:
// 在 isMaster=true 的狀態下進行 fork 迴圈後
const updateWorkers = () => {
const usersCount = numberOfUsersInDB();
Object.values(cluster.workers).forEach(worker => {
worker.send({ usersCount });
});
};
updateWorkers();
setInterval(updateWorkers, 10000);複製程式碼這裡第一次我們呼叫了 updateWorkers,然後通過 setInterval 每 10 秒呼叫這個方法。這樣的話,每 10 秒所有的 worker 會以通訊的形式收到使用者數量的值,並且我們只需要建立一次資料庫連線。
在服務端的程式碼,我們可以從同樣的 message 事件 handler 中拿到 usersCount 的值。我們簡單地用一個模組全域性變數快取這個值,這樣我們在任何地方都能使用它。
例如:
const http = require('http');
const pid = process.pid;
let usersCount;
http.createServer((req, res) => {
for (let i=0; i<1e7; i++); // simulate CPU work
res.write(`Handled by process ${pid}\n`);
res.end(`Users: ${usersCount}`);
}).listen(8080, () => {
console.log(`Started process ${pid}`);
});
process.on('message', msg => {
usersCount = msg.usersCount;
});複製程式碼上面的程式碼讓 worker 的 web 伺服器用快取的 usersCount 進行響應。如果你現在測試 cluster 的程式碼,前 10 秒你會從所有的 worker 裡得到使用者數量為 “25”(同時只建立了一個資料庫連線)。然後 10 秒過後,所有的 worker 開始報告當前的使用者數量,625(同樣只建立了一個資料庫連線)。
得力於 master 程式和 worker 之間通訊的方法的存在,我們能夠做到這一切。
提高伺服器的可用性
我們在執行單獨一個 Node 應用的例項時有一個問題,就是當這個例項崩潰時,我們必須重啟整個應用。這意味著崩潰後的重啟之間會存在一個時間差,即使我們讓這項操作自動執行也是一樣的。
同理當伺服器想要部署新程式碼就必須重啟。只有一個例項,為此所造成的時間差會影響系統的可用性。
而如果我們有多個例項的話,只需新增寥寥數行程式碼就可以提高系統的可用性。
為了在伺服器中模擬隨機崩潰,我們通過一個 timer 來呼叫 process.exit,讓它隨機執行。
// 在 server.js 檔案
setTimeout(() => {
process.exit(1) // 隨時退出程式
}, Math.random() * 10000);複製程式碼當一個 worker 程式因崩潰而退出,cluster 物件裡的 exit 事件會通知 master 程式。我們可以給這個事件註冊一個 handler,並且當其他 worker 程式還存在時讓它 fork 一個新的 worker 程式。
例如:
// 在 isMaster=true 的狀態下進行 fork 迴圈後
cluster.on('exit', (worker, code, signal) => {
if (code !== 0 && !worker.exitedAfterDisconnect) {
console.log(`Worker ${worker.id} crashed. ` +
'Starting a new worker...');
cluster.fork();
}
});複製程式碼這裡我們新增一個 if 條件來保證 worker 程式真的崩潰了而不是手動斷開連線或者被 master 程式殺死了。例如,我們使用了太多的資源超出了負載的上限,因此 master 程式決定殺死一部分 worker。因此我們呼叫 disconnect 方法給任意 worker,這樣 exitedAfterDisconnect flag 就會設為 true。if 語句會保證不會因此而 fork 新的 worker。
如果我們帶著上面的 handler 執行 cluster(同時 server.js 裡有隨機的崩潰的程式碼),在隨機數秒過後,worker 會開始崩潰,master 程式會立刻 fork 新的 worker 來提高系統的可用性。你同樣可以用 ab 命令來衡量可用性,看看伺服器有多少的請求沒有處理(因為有一些請求會不走運地遇到無法避免的崩潰)。
當我測試這段程式碼,10 秒內請求 1800 次,其中有 200 次併發請求,最後只有 17 次請求失敗。
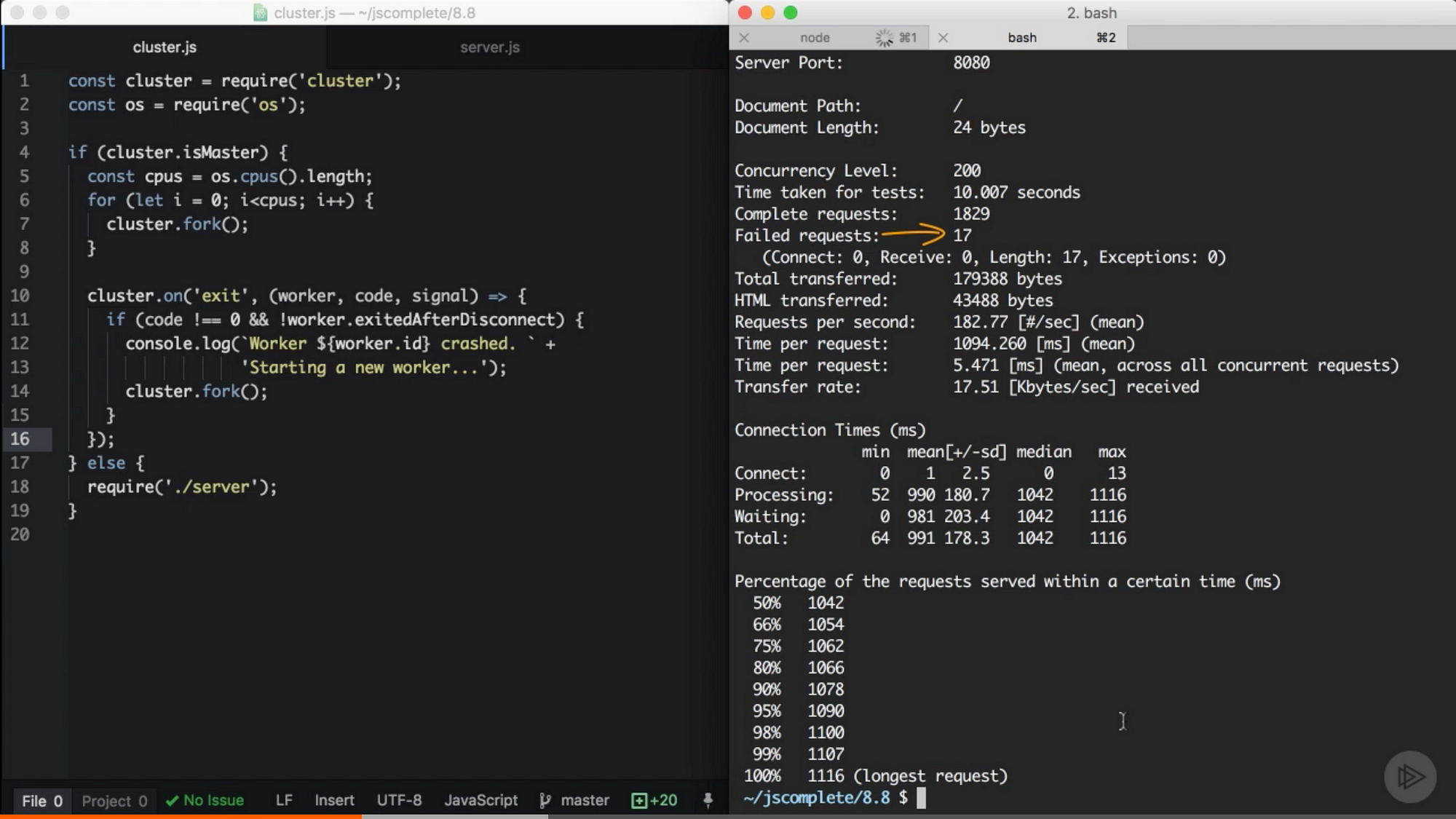
來自 Pluralsight 課程中的截圖 — Node.js 進階
這有 99% 以上的可用性。只是新增數行程式碼,現在我們不再擔心程式崩潰了。master 守護將會替我們關注這些程式的情況。
瞬時重啟
那當我們想要部署新程式碼,而不得不重啟所有的 worker 程式時該怎麼辦呢?
我們有多個例項在執行,所以與其讓它們一起重啟,不如每次只重啟一個,這樣的話即使重啟也能保證其他的 worker 程式能夠繼續處理請求。
用 cluster 模組能簡單地實現這一想法。當 master 程式開始執行之後我們就不想重啟它,我們需要想辦法傳遞重啟 worker 的指令給 master 程式。在 Linux 系統上這樣做很容易因為我們能監聽一個程式的訊號像 SIGUSR2,當 kill 命令裡面帶有程式 id 和訊號時這個監聽事件將會觸發:
// 在 Node 裡面
process.on('SIGUSR2', () => { ... });
// 觸發訊號
$ kill -SIGUSR2 PID複製程式碼這樣,master 程式不會被殺死,我們就能夠在裡面進行一系列操作了。SIGUSR2 訊號適合這種情況,因為我們要執行使用者指令。如果你想知道為什麼不用 SIGUSR1,那是因為這個訊號用在 Node 的偵錯程式上,我們為了避免衝突所以不用它。
不幸的是,在 Windows 裡面的程式不支援這個訊號,我們要找其他方法讓 master 程式做這件事。有幾種代替方案。例如,我們可以用標準輸入或者 socket 輸入。或者我們可以監控 process.id 檔案的刪除事件。但是為了讓這個教程更容易,我們還是假定伺服器執行在 Linux 平臺上。
在 Windows 上 Node 執行良好,但是我認為讓作為產品的 Node 應用在 Linux 平臺上執行會更安全。這和 Node 本身無關,只是因為在 Linux 上有更多穩定的生產工具。這只是我的個人見解,最好還是根據自己的情況選擇平臺。
順帶一提,在最近的 Windows 版本里,實際上你可以在裡面使用 Linux 子系統。我自己測試過了,沒有什麼特別明顯的缺點。如果你在 Windows 上開發 Node 應用,可以看看 [Bash on Windows](msdn.microsoft.com/en-us/comma…) 並嘗試一下。
在我們的例子中,當 master 程式收到 SIGUSR2 訊號,就意味著是時候重啟 worker 了,但是我們想要每次只重啟一個 worker。因此 master 程式應該等到當前的 worker 已經重啟完後再重啟下一個 worker。
我們需要用 cluster.workers 物件來得到當前所有 worker 的引用,然後我們簡單地把它存進一個陣列中:
const workers = Object.values(cluster.workers);複製程式碼然後,我們建立 restartWorker 函式來接受要重啟的 worker 的 index。這樣當下一個 worker 可以重啟時,我們讓函式呼叫當前 worker,直到最後重啟整個序列裡的 worker。這是需要呼叫的 restartWorker 函式(解釋在後面):
const restartWorker = (workerIndex) => {
const worker = workers[workerIndex];
if (!worker) return;
worker.on('exit', () => {
if (!worker.exitedAfterDisconnect) return;
console.log(`Exited process ${worker.process.pid}`);
cluster.fork().on('listening', () => {
restartWorker(workerIndex + 1);
});
});
worker.disconnect();
};
restartWorker(0);複製程式碼在 restartWorker 函式裡面,我們得到了要重啟的 worker 的引用,然後我們會根據序列遞迴呼叫這個函式,我們需要一個結束遞迴的條件。當沒有 worker 需要重啟,我們就直接 return。基本上我們想讓這個 worker 斷開連線(使用 worker.disconnect),但是在重啟下一個 worker 之前,我們需要 fork 一個新的 worker 來代替當前斷開連線的 worker。
當目前要斷開連線的 worker 還存在時,我們可以用 worker 本身的 exit 事件來 fork 一個新的 worker,但是我們要確保在平常的斷開連線呼叫後 exit 動作就會被觸發。我們可以用 exitedAfetrDisconnect flag,如果 flag 不為 true,那麼是因為其他原因而導致的 exit,這種情況下我們什麼都不做就直接 return。但是如果 flag 為 true,我們就繼續執行下去,fork 一個新的 worker 來代替當前要斷開連線的那個。
當新的 fork worker 程式準備好了,我們就要重啟下一個。然而,記住 fork 的過程不是同步的,所以我們不能在呼叫完 fork 後就直接重啟下個 worker。我們要在新的 fork worker 上監聽 listening 事件,這個事件告訴我們這個 worker 已經連線並準備好了。當我們觸發這個事件,我們就可以安全地重啟下個在序列裡 worker 了。
這就是我們為了實現瞬時重啟要做的東西。要測試它,你要知道需要傳送 SIGUSR2 訊號的 master 程式的 id:
console.log(`Master PID: ${process.pid}`);複製程式碼開啟 cluster,複製 master 程式的 id,然後用 kill -SIGUSR2 PID 命令重啟 cluster。同樣你可以在重啟 cluster 時用 ab 命令來看看重啟時的可用性。劇透一下,沒有請求失敗:
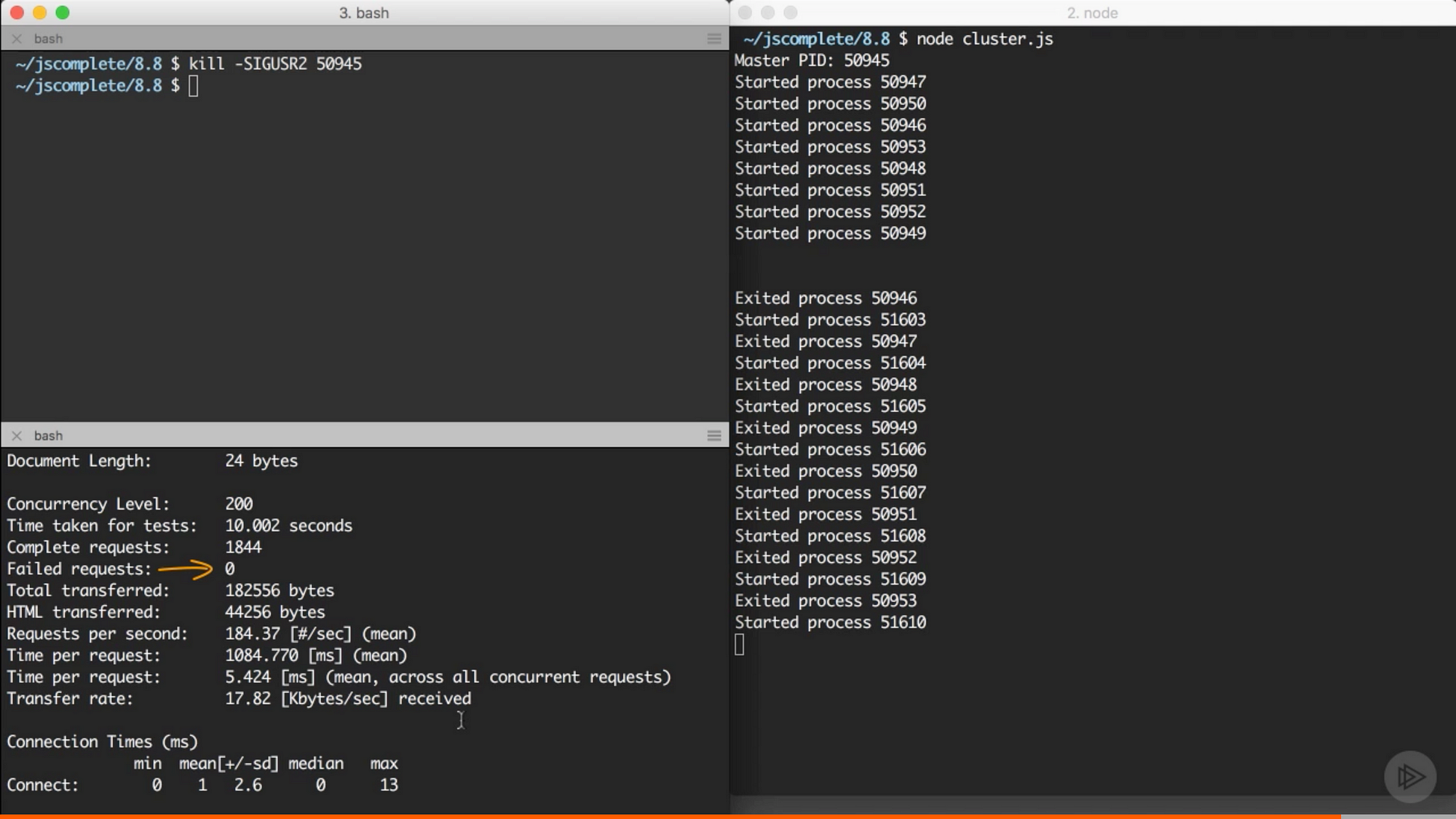
來自 Pluralsight 課程中的截圖 — Node.js 進階
像 PM2 這樣的程式監控器,我個人把它用在生產環境上,它讓我們實現上述工作變得異常簡單,同時它還有許多功能來監控 Node.js 應用的健壯度。例如,用 PM2,想要在任意應用上啟動 cluster,你只需要用 -i 引數:
pm2 start server.js -i max複製程式碼想要瞬時重啟你只需要使用這個神奇的命令:
pm2 reload all複製程式碼然而,我覺得在使用這些命令之前先理解其背後的實現是有幫助的。
共享狀態和粘性負載均衡
好東西總是需要付出代價。當我們對一個 Node 應用進行負載均衡,我們也失去了一些只能在單程式適用的功能。這個問題在其他語言上被稱為執行緒安全,它和線上程之間共享資料有關。在我們的案例中,問題則在於如何在 worker 程式之間共享資料。
例如,設立了 cluster 後,我們就不能在記憶體上快取東西了,因為每個 worker 有其獨立的記憶體空間,如果我們在其中一個 worker 的記憶體裡快取東西,其他的 worker 就沒辦法拿到它。
如果我們需要在 cluster 裡快取東西,我們要從所有 worker 那裡分離實體和讀取/寫入實體的 API。實體要存放在資料庫伺服器,或者如果你想用記憶體來快取,你可以使用像 Redis 這樣的伺服器,或者建立一個專注於讀取/寫入 API 的 Node 程式供所有 worker 使用。
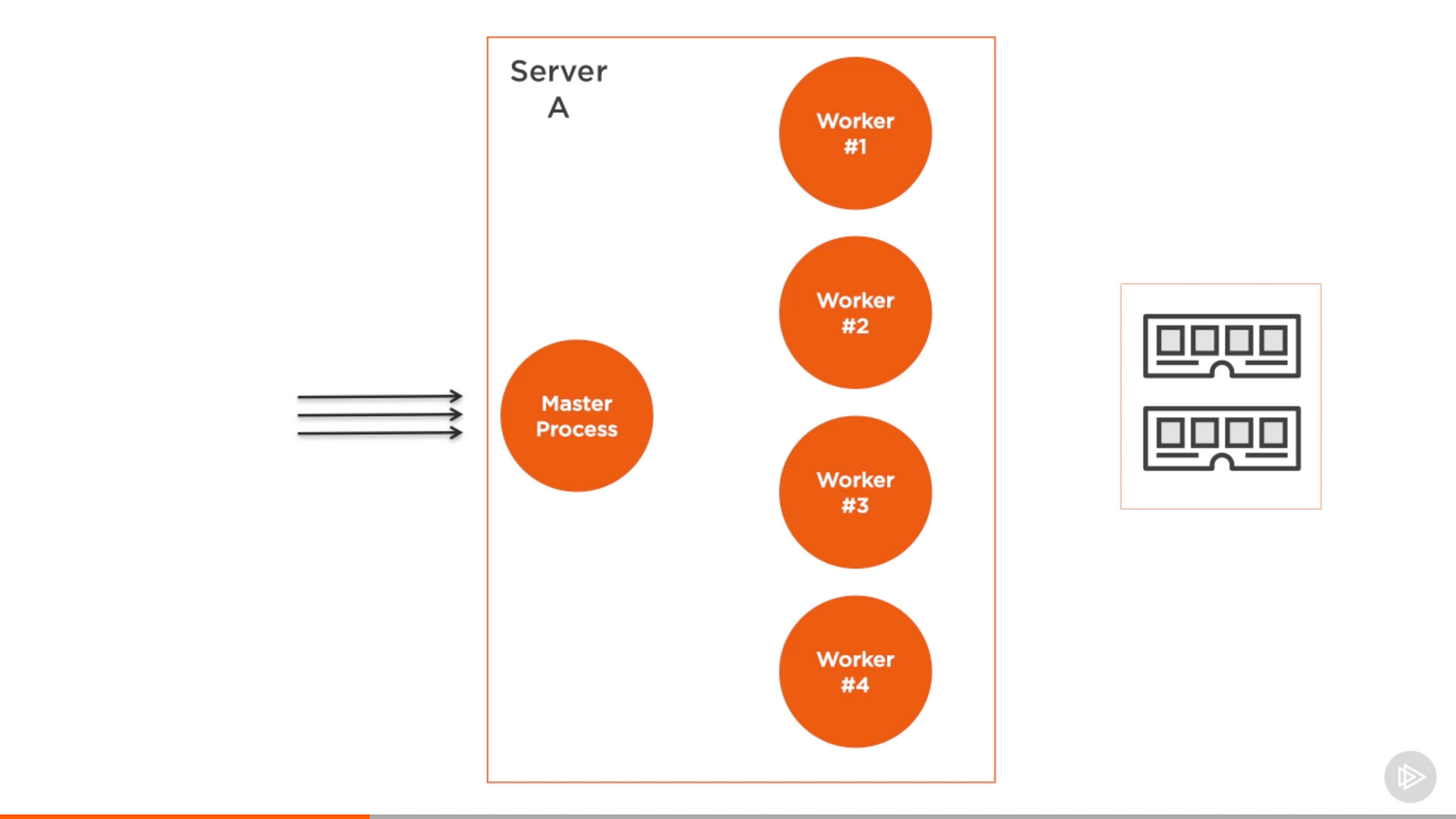
來自 Pluralsight 課程中的截圖 — Node.js 進階
這個做法有個好處,當你的應用為了快取而分離了實體,實際上這是分解的一部分,能讓你的應用更具可擴充性。即使你執行在一個單核伺服器,你也應該這樣做。
除了快取外,當我們執行 cluster,總體來說狀態之間的交流成為了一個問題。我們不能確保交流發生在同一個 worker 上,因此不能在任何一個 worker 上建立一個狀態相關的交流通道。
一個最常見的例子是使用者認證。
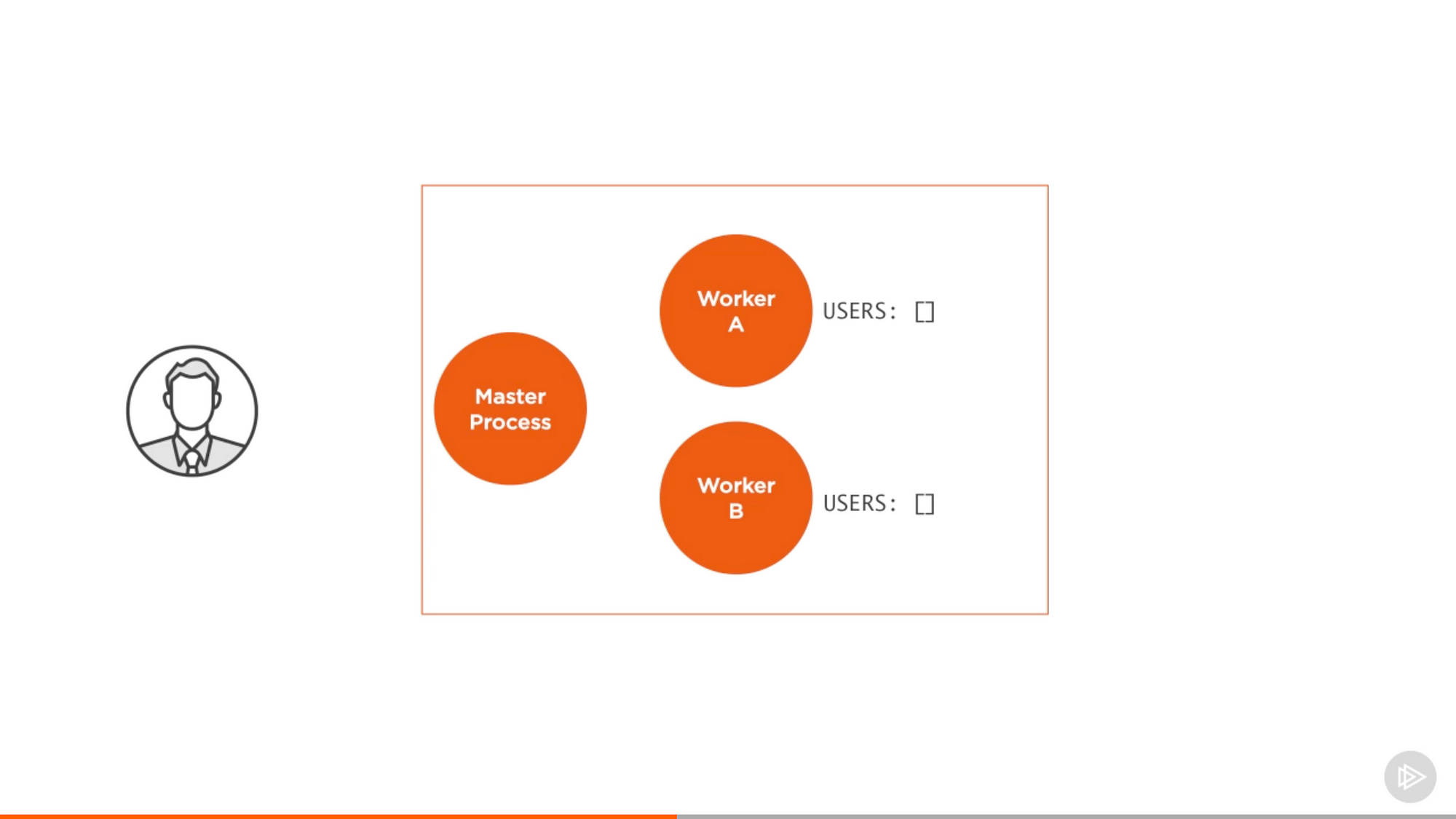
來自 Pluralsight 課程中的截圖 — Node.js 進階
用 cluster,驗證的請求分配到 master 程式,而這個程式把請求分配給一個 worker,假定分配給 A。
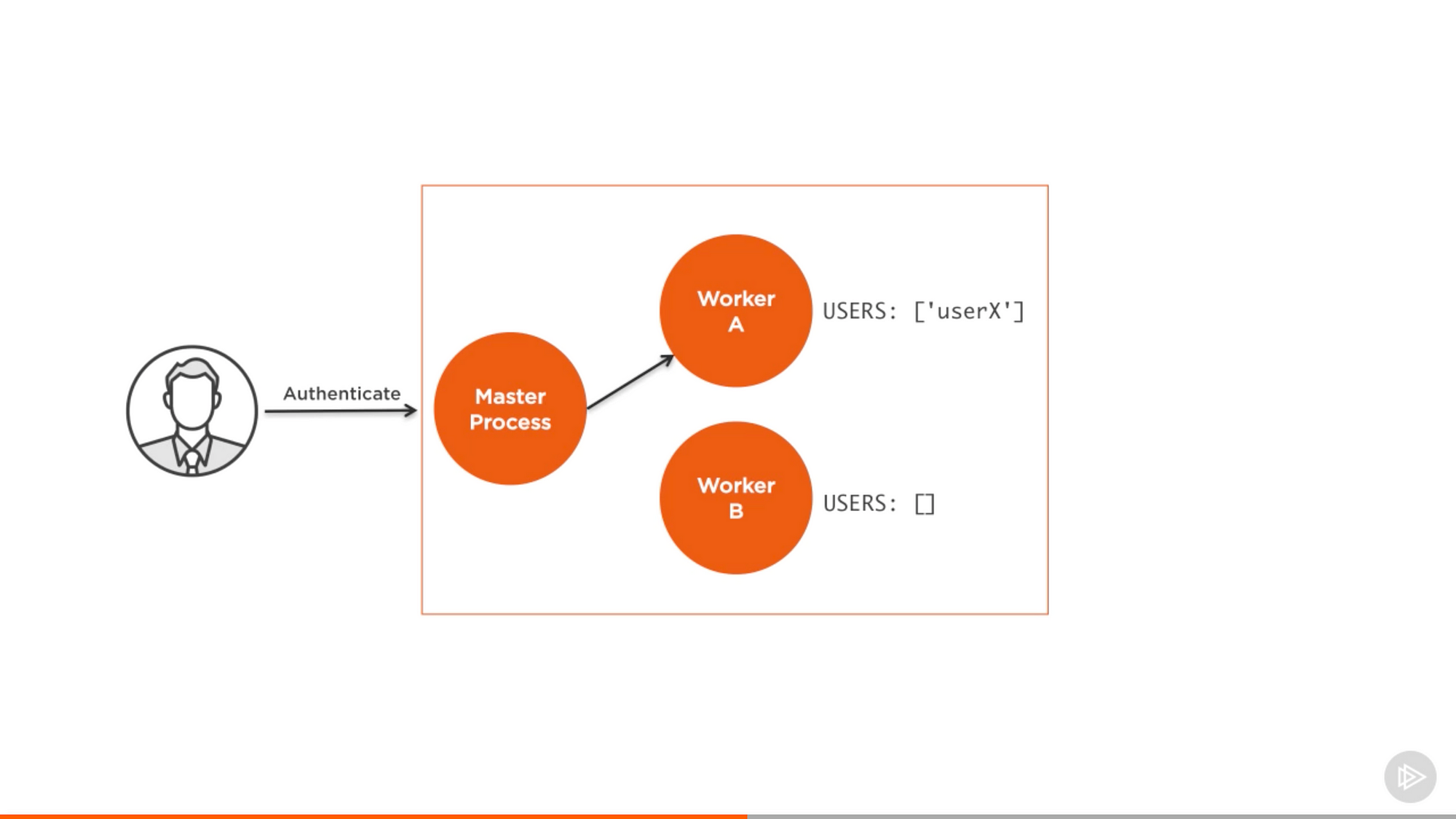
來自 Pluralsight 課程中的截圖 — Node.js 進階
現在 Worker A 認出了使用者的狀態。但是,當同樣的使用者進行另外一個請求,最終負載均衡器會把它分配給其他 worker,而這些 worker 還沒有驗證這個使用者。在單獨一個例項的記憶體上持有驗證使用者的引用並不管用。
有很多方法處理這個問題。通過在共享資料庫或者 Redis node 上對會話資訊進行排序,我們可以在 worker 之間共享狀態。然而,實現這個策略需要改變一些程式碼,這不是最好的方法。
如果你不想修改程式碼就實現一個會話的共享儲存倉庫,有個入侵性低但效率不高的策略。你可以用粘性負載均衡。和讓普通的負載均衡器實現上述策略相比,它更為簡單。想法很簡單,當 worker 的例項要驗證使用者,我們在負載均衡器上記錄相關的關係。
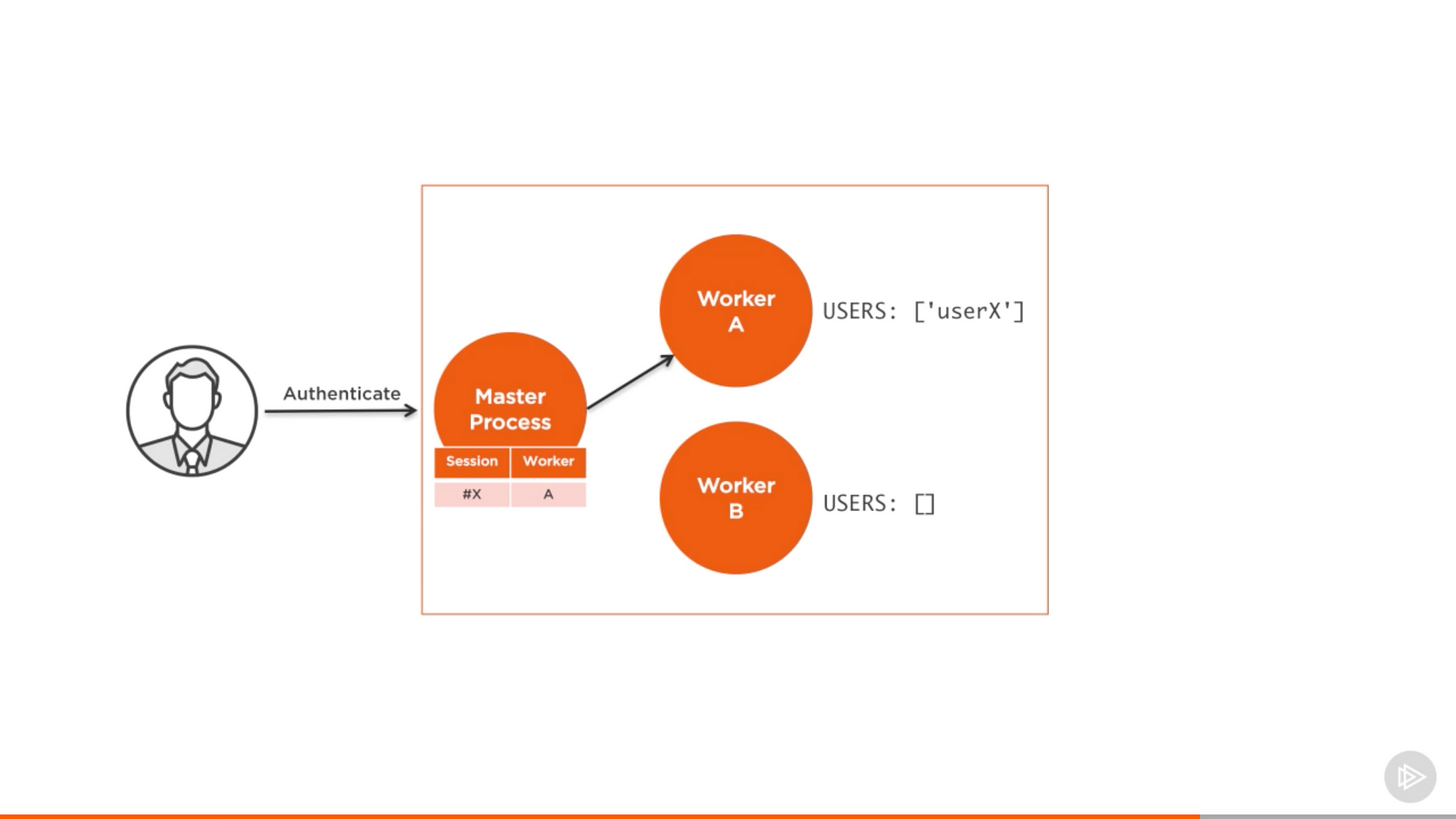
來自 Pluralsight 課程中的截圖 — Node.js 進階
然後,當同樣的使用者傳送新的請求,我們就檢查記錄,發現伺服器裡已經有驗證的會話,然後把這個會話傳送給伺服器,而不是執行普通的驗證操作。用這個方法不需要改變伺服器裡的程式碼,但同時我們不會得到用負載均衡器來驗證使用者的好處,所以只有別無選擇時才用粘性負載均衡。
實際上 cluster 模組並不支援粘性負載均衡,但是大多數負載均衡器可以預設設定為粘性負載均衡。
感謝閱讀。如果你覺得這篇文章對你有幫助,請點選下面的 ?。關注我來得到更多有關 Node.js 和 JavaScript 的文章。
我為 Pluralsight 和 Lynda 建立了網路課程。最近我的課程是 Advanced React.js,Advanced Node.js 和 Learning Full-stack JavaScript。
同時我也為 JavaScript,Node.js,React.js,和 GraphQL 的水平在初級與進階之間的人們建立了線上 training。如果你想要找一位導師,可以 發郵件給我。如對這篇文章或者其他我寫的文章有任何疑問,請在 這個 slack 使用者 上找到我並且在 #question 空間上提問。
掘金翻譯計劃 是一個翻譯優質網際網路技術文章的社群,文章來源為 掘金 上的英文分享文章。內容覆蓋 Android、iOS、React、前端、後端、產品、設計 等領域,想要檢視更多優質譯文請持續關注 掘金翻譯計劃、官方微博、知乎專欄。