作業1:Selenium 爬取資料任務
1. 作業思路與步驟
Gitee資料夾連結:https://gitee.com/nongchenc/crawl_project/blob/master/作業四/4.1.py
本次作業的任務是使用 Selenium 框架爬取 “滬深A股”、“上證A股” 和 “深證A股” 三個板塊的股票資料,並儲存到 MySQL 資料庫中。以下為具體實現步驟:
(1)功能實現
- URL與板塊設定:為每個股票板塊指定其 URL。
- Selenium 頁面載入與等待:
- 透過 WebDriverWait等待頁面資料載入完成。
- 確保股票列表表格元素可見。
- 資料提取:
- 使用 CSS 選擇器定位表格行和各列,逐行讀取資料。
- 提取的欄位包括:股票程式碼、名稱、最新報價、漲跌幅等。
- 資料儲存:
- 將爬取的股票資料插入到 MySQL 資料庫表 stocks 中,避免重複插入。
- 翻頁處理:
- 模擬點選下一頁按鈕,爬取每個板塊的前 4 頁資料。
- 遇到無下一頁的情況,自動停止。
(2)關鍵點與最佳化
- 異常處理:處理頁面載入超時、元素找不到等情況。
- 資料轉換:處理帶單位的數字(如“萬”“億”)及特殊字元。
- 延時策略:在翻頁和滾動操作間加入隨機延時,避免被封。
(3)執行結果
成功爬取了三個板塊的股票資料並儲存到資料庫中。
2. 部分程式碼展示與執行截圖
以下為部分關鍵程式碼及執行截圖:
(1)定義轉換函式
def convert_to_float(value):
try:
if isinstance(value, str):
value = value.strip()
if value in ['-', '']: # 處理 `-` 或空值
return None
if '萬' in value:
return float(value.replace('萬', '').replace(',', '').strip()) * 10000
if '億' in value:
return float(value.replace('億', '').replace(',', '').strip()) * 100000000
if '%' in value:
return float(value.replace('%', '').strip()) / 100
return float(value) if value else None
except (ValueError, TypeError):
return None
(2)資料提取程式碼
# 爬取前 4 頁的資料
page = 1
while page <= 4:
print(f"正在載入 {board_name} 板塊第 {page} 頁資料...")
# 遍歷每行股票資料
rows = driver.find_elements(By.CSS_SELECTOR, "#table_wrapper-table > tbody > tr")
for row in rows:
try:
data = {
'sequence': convert_to_float(row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text), # 獲取序號
'bStockNo': row.find_element(By.CSS_SELECTOR, "td:nth-child(2) a").text,
'name': row.find_element(By.CSS_SELECTOR, "td:nth-child(3) a").text,
#其他資料省略
}
print(data)
save_to_database(data)
(3)執行結果截圖
-
控制檯輸出:

-
資料庫資料:

3. 作業心得
透過此次作業,學會了使用 Selenium 爬取動態資料,體會到以下幾點:
- 爬取前分析網站結構非常重要:瞭解表格 HTML 結構和動態載入方式是關鍵。
- 異常處理與最佳化:透過處理超時、滾動載入等問題,提升了程式碼的穩定性。
- 結合資料庫儲存:不僅實現了資料抓取,還鞏固了資料庫的操作技能。
作業2:中國MOOC網課程資訊爬取
1. 作業思路與步驟
Gitee資料夾連結:https://gitee.com/nongchenc/crawl_project/blob/master/作業四/4.2.py
任務目標是爬取中國MOOC網的課程資訊,包括課程名稱、學校名稱、主講教師、課程簡介等,並儲存到 MySQL 資料庫。
(1)主要步驟
- 網站分析:
- 使用瀏覽器開發者工具,分析課程列表的 HTML 結構。
- 確定動態資料載入方式,使用 Selenium 模擬使用者操作。
- 資料提取與處理:
- 對無法直接獲取的欄位(如團隊成員),新增條件處理。
- 資料庫設計:
- 建立 mooc 資料表,欄位包括:課程名稱、學校名稱、主講教師、團隊成員、參加人數等。
- 翻頁邏輯:
- 模擬翻頁,爬取多個頁面的資料。
- 異常與最佳化:
- 加入滾動載入、隨機延時,模擬真實使用者行為,避免觸發反爬機制。
(2)執行結果
爬取了指定頁數的課程資訊,併成功存入資料庫。
2. 部分程式碼展示與執行截圖
(1)課程資料提取程式碼
for link in browser.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
try:
course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
m_teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').text
process = link.find_element(By.XPATH, './/span[@class="txt"]').text
introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
save_to_database(course_name, school_name, m_teacher, process, introduction)
except Exception as e:
print("資料提取出錯:", e)
(2)資料庫儲存程式碼
def save_to_database(course_name, school_name, m_teacher, process, introduction):
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
cursor.execute(
"INSERT INTO mooc (`course`, `college`, `teacher`, `process`, `brief`) "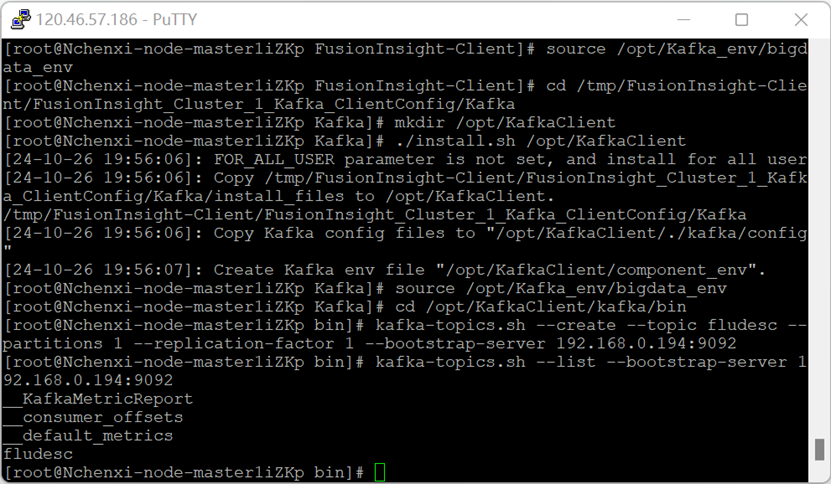
"VALUES (%s, %s, %s, %s, %s)",
(course_name, school_name, m_teacher, process, introduction)
)
conn.commit()
conn.close()
(3)執行結果截圖
-
控制檯輸出:

-
資料庫資料:

3. 作業心得
完成中國MOOC網的爬取任務,收穫如下:
- 爬取動態內容的技巧:掌握了透過 Selenium 處理滾動載入和翻頁的策略。
- 爬取多欄位資料的精細化處理:針對每個欄位,使用不同的解析方式,保證資料準確性。
- 最佳化與防反爬:透過延時、禁用圖片等方式,減少了被封的風險。
作業3:大資料實驗總結
1. 實驗內容回顧
本次實驗在華為雲上完成了以下任務:
登入MRS的master節點伺服器

編寫Python指令碼
建立存放測試資料的目錄
執行指令碼測試

校驗下載的客戶端檔案包


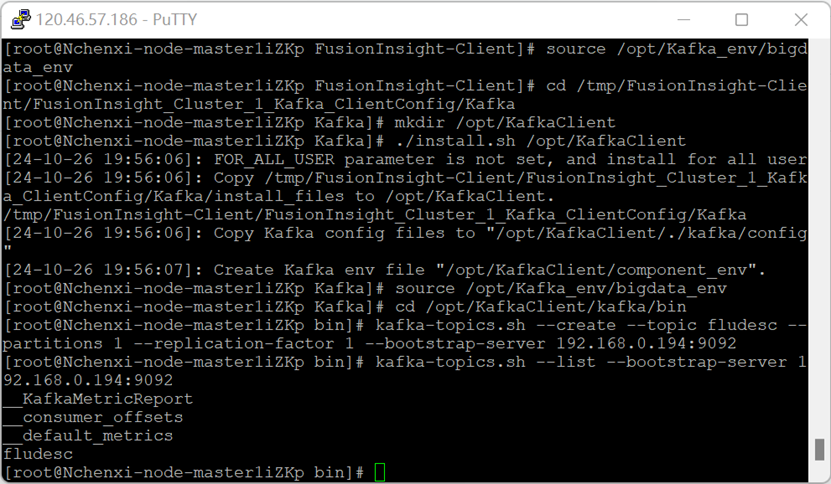
安裝Kafka執行環境


安裝Kafka客戶端

在kafka中建立topic


安裝Flume執行環境

配置Flume採集資料
有資料產生

2. 實驗心得
透過實驗,深刻理解了大資料日誌採集的流程,尤其是 Flume 與 Kafka 的互動。在實踐中增強了對實時資料處理架構的理解,同時熟悉了華為雲的環境配置流程。