輕鬆保障萬級例項,vivo服務端監控體系建設實踐
經過幾年的平臺建設,vivo監控平臺產品矩陣日趨完善,在vivo終端龐大的使用者群體下,承載業務執行的服務數量眾多,監控服務體系是業務可用性保障的重要一環,監控產品全場景覆蓋生產環境各個環節。從事前發現,事中告警、定位、恢復,事後覆盤總結,監控服務平臺都提供了豐富的工具包。從以前的水平拆分,按場景建設,到後來的垂直劃分,整合統一,降低平臺割裂感。同時從可觀測性、AIOps、雲原生等方向,監控平臺也進行了建設實踐。未來vivo監控平臺將會向著全場景、一站式、全鏈路、智慧化方向不斷探索前行。
監控服務平臺是自研的、覆蓋全場景的可用性保障系統。經過多年深耕,vivo監控團隊已經成體系構築起一整套穩定性保障系統,隨著雲原生可觀測技術變革不斷深化,監控團隊如何掌舵前行?下面就平臺的建設歷程、思考、探索,做一下簡單介紹。
一、監控體系建設之道
1.1 監控建設歷程

回顧監控建設歷程,最初採用Zabbix,與告警中心的組合實現簡易監控。隨著業務的發展在複雜監控場景和資料量不斷增長的情況下,這種簡易的組合就顯的捉襟見肘。所以從2018年開始我們開啟了自研之路,最開始我們建設了應用監控、日誌監控、撥測監控解決了很大一部分監控場景沒有覆蓋的問題;2019年我們建設了基礎監控、自定義監控等,完成了主要監控場景的基本覆蓋;2020年我們在完善前期監控產品的同時,進一步對周邊產品進行了建設;隨著AI技術的不斷成熟,我們從2021年開始也進行了轉型升級,先後建設了故障定位平臺、統一告警平臺有了這些平臺後我們發現,要想進一步提升平臺價值,資料和平臺的統一至關重要;所以從2022年開始建設了統一監控平臺,也就是將基礎監控、應用監控和自定義監控進行了統一,統一監控包含了統一配置服務和統一檢測服務。從監控的建設歷程來看,我們一路覆蓋了IaaS、PaaS、DaaS、CaaS等平臺。我們的職能也從DevOps向AIOps邁進。
1.2 監控能力矩陣
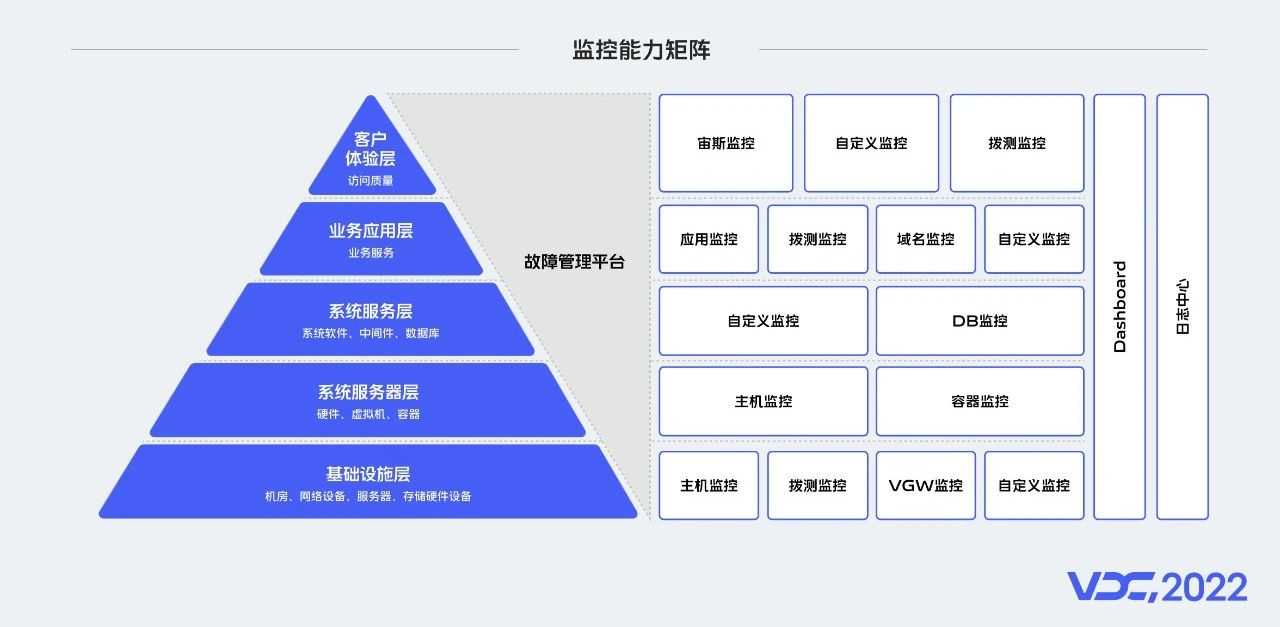
講了監控的發展歷程,那麼這些監控產品在我們的生產環境中是如何分佈的呢?要想支撐數以萬計的業務執行,需要龐雜的系統支撐,伺服器、網路環境、基礎元件等,都需要監控系統保障它的穩定性。我們將監控的物件分為五層,在基礎設施層,包含了網路裝置、伺服器、儲存硬體等,這一層我們透過VGW監控對網路裝置進行監控,VGW是Vivo Gateway的縮寫,類似於LVS;透過自定義監控,對機房進行監控;系統伺服器層,我們定義的監控物件是服務執行依賴的環境,透過主機監控對物理機、虛擬機器等監控,當前容器在雲原生技術體系中,已然成為微服務執行的優秀載體,所以對容器的監控必不可少;系統服務層,包含了各種資料庫產品、大資料元件等,在這一層主要透過自定義監控檢測、告警;業務應用層,主要有應用服務,我們透過應用監控對業務鏈路資訊進行監控;客戶體驗層,我們定義了端上的訪問質量,由宙斯平臺實現監控。前面我們講了監控能力矩陣,下面我們具體介紹一下監控的範圍和整個平臺的能力。
1.3 監控物件範圍
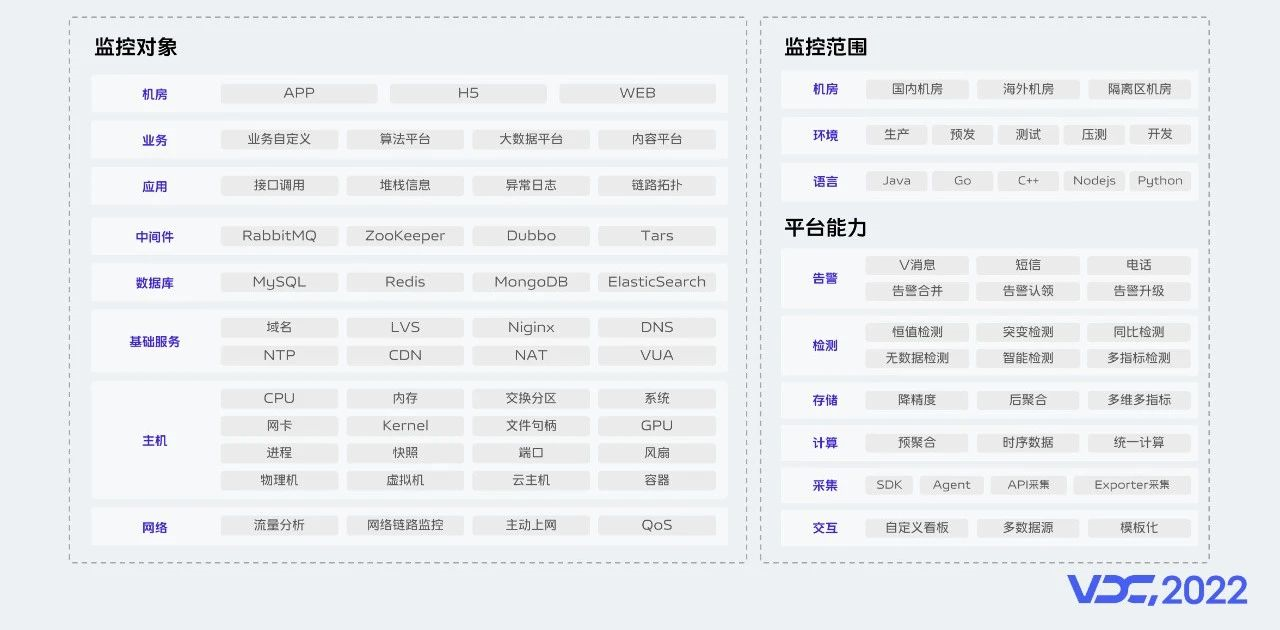
監控物件涉及網路、主機、基礎服務等。面對各地機房我們做到了監控全覆蓋,為滿足各類環境部署訴求,我們可以做到針對不同環境的監控。我們支援多種採集方式,SDK和API採集主要應用在自定義監控場景,Agent主要採集主機類指標,採集上來的時序資料經過預聚合、統一的資料清洗,然後儲存在TSDB資料庫。針對海量資料儲存我們採用了資料降精,寬表多維多指標等方案。我們常用的檢測演算法有恆值檢測、突變檢測、同比檢測等,同時還支援了無資料檢測、多指標組合檢測,檢測出現的異常我們會形成一個問題,問題在經過一系列的收斂後發出告警,我們有多種告警通道,支援告警合併、認領、升級等,需要展示的指標資料我們提供了豐富的自定義指標看板,對使用頻率高 固化場景,我們提供了模板化配置方案。有了完備的監控體系,那麼系統的關鍵指標和監控物件體量如何?
1.4 監控系統體量

當前監控服務體系保障著x萬+的主機例項,x萬+的DB例項,每天處理x千億條各類指標和日誌,對x千+的域名做到秒級監控,對x萬+的容器例項監控,每天從統一告警發出的各類告警達到x十萬+ ,對主機例項的監控覆蓋率達到x %,監控平臺透過不斷的探索實踐,實現了對海量資料計算儲存,當前對核心業務的告警延遲在x秒以內,告警召回率大於x %。
1.5 監控系統面臨挑戰
雖然現階段取得了一些成果,但是目前仍然面臨很多挑戰,主要分為三大類:
部署環境複雜
對數以萬計的主機和容器,實時採集 計算是一項困難的事情;面對各地機房監控,部署過程中依賴項多,維護工作複雜;對海量資料計算儲存,保障監控服務穩定性、可用性難度大。
平臺系統繁多
當前系統還存在割裂,使用者體驗不強;資料割裂,沒有從底層融合在一起,對於資料組合使用形成挑戰。
新技術挑戰
首先基於容器的監控方案,對傳統監控方案形成挑戰,當前對Prometheus指標儲存處在探索階段,暫時沒有標準的解決方案,但是面對快速增長的資料量,新元件的探索試錯成本相對較高。
二、監控服務體系架構
2.1 產品架構

產品架構的能力服務層,我們定義了採集能力、檢測能力、告警能力等;功能層我們對這些能力做了具體實現,我們將監控分為主機、容器、DB等9類場景,展示層主要由Dashboard提供靈活的圖表配置能力,日誌中心負責日誌查詢,移動端可以對告警資訊進行認領、遮蔽。
2.2 技術架構

技術架構層分為採集、計算、儲存、視覺化幾大塊,首先在採集層我們透過各種採集方式進行指標採集;上報的資料主要透過Bees-Bus進行傳輸,Bees-Bus是一款公司自研的分散式、高可用的資料收集系統,指標經過Bees-Bus之後寫入Kafka,隨著Pulsar的受關注度與使用量的顯著增加,我們也在這方面進行了一定的探索;計算層我們經歷了Spark、Flink、KafkaStream幾個階段的探索,基本實現了計算層技術棧收歸到KafkaStream;資料主要儲存在Druid,當前有190+節點的Druid叢集。Opentsdb和Hive早期應用在主機監控場景,隨著業務發展其效能已經不能勝任當前的寫入和查詢需求,所以逐步被捨棄。
當前我們選用了VictoriaMetrics作為Prometheus的遠端儲存,日誌資訊儲存在ES中,目前我們有250+的ES節點。服務層中各類監控場景的後設資料,都由統一後設資料服務提供;各類檢測規則、告警規則都由統一配置服務維護,統一告警服務則負責告警的收斂、合併、傳送等。Grafana則主要用作自監控告警。
2.3 互動流程
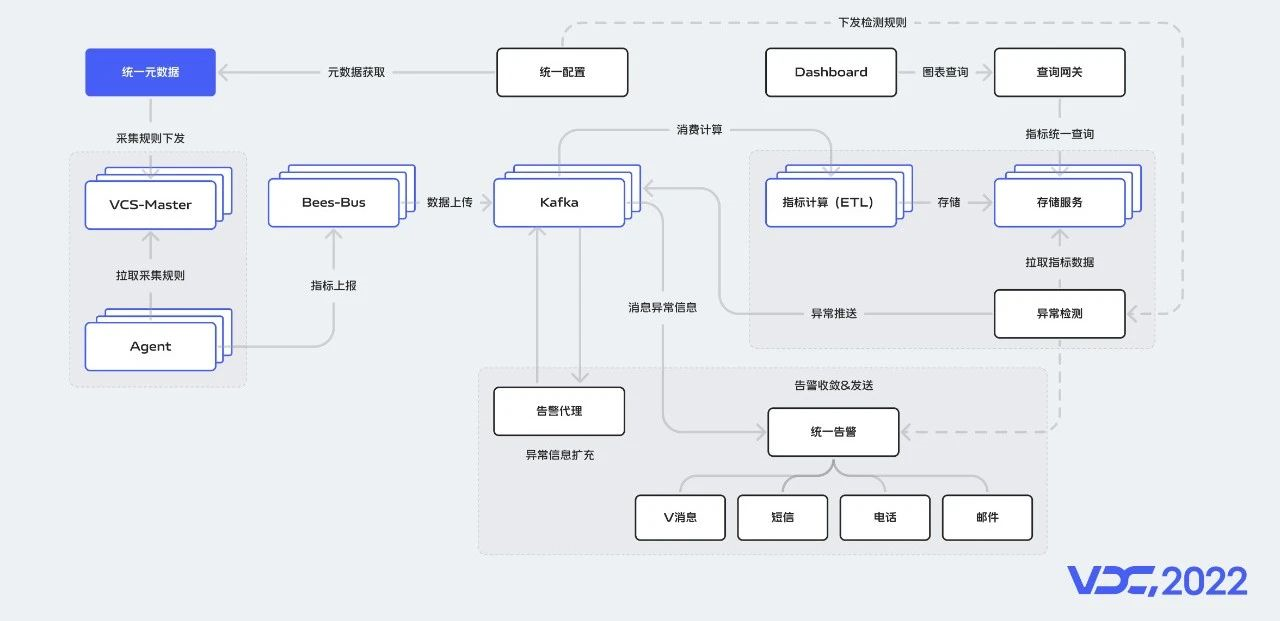
在監控架構的基礎上,我們介紹一下整體互動流程,採集規則由統一後設資料服務管理,並主動下發到VCS-Master,VCS-Master主要用來任務下發,Agent執行結果資料接收,任務查詢和配置管理等,Agent會定期從VCS-Master拉取快取的採集規則,指標經過Bees-Bus雙寫到Kafka,由ETL程式對指標資料消費,然後做清洗和計算,最後統一寫入到儲存服務中,統一配置服務下發檢測規則到異常檢測服務,檢測出的異常資訊推送到Kafka,由告警代理服務對異常資訊進行富化,處理好的資料推到Kafka,然後由統一告警服務消費處理。在儲存服務之上,我們做了一層查詢閘道器,所有的查詢會經過閘道器代理。
三、可用性體系構建與保障
3.1 可用性體系構建

前面說了監控服務體系整體架構,那麼監控產品如何服務於業務可用性。我們將業務穩定性在時間軸上進行分割,不同的時段有不同的系統保障業務可用性,當前我們主要關注MTTD和MTTR,告警延遲越小發現故障的速度也就越快,系統維修時間越短說明系統恢復速度越快,我們將MTTR指標拆解細化然後各個擊破,最終達成可用性保障要求。vivo監控服務體系提供了,涵蓋在穩定性建設中需要的故障預防、故障發現等全場景工具包,監控平臺提供了產品工具,那麼與運維人員,研發人員是怎樣協作配合的?
3.2 系統可用性保障

當監控物件有問題時,監控系統就會傳送告警給運維人員或業務開發,他們透過檢視相關指標修復問題。使用過程中運維人員的訴求和疑問,由監控平臺產品和開發協同配合解決,我們透過運營指標,定期梳理出不合理的告警,將對應的檢測規則同步給運維同學,然後制定調整計劃,後期我們計劃結合智慧檢測,做到零配置就能檢測出異常指標。透過監控開發、運維人員和業務開發一起協同配合,保障業務的可用性。
3.3 監控系統可用性

除了保障業務可用性外,監控系統自身的可用性保障也是一個重要的課題。為了保障Agent存活,我們構建了多種維活機制,保障端上指標採集正常。資料經過Bees-Bus之後,會雙寫到兩個機房,當有一個機房出現故障,會快速切到另一個機房,保障核心業務不受損。資料鏈路的每一層都有自監控。監控平臺透過Grafana監控告警。
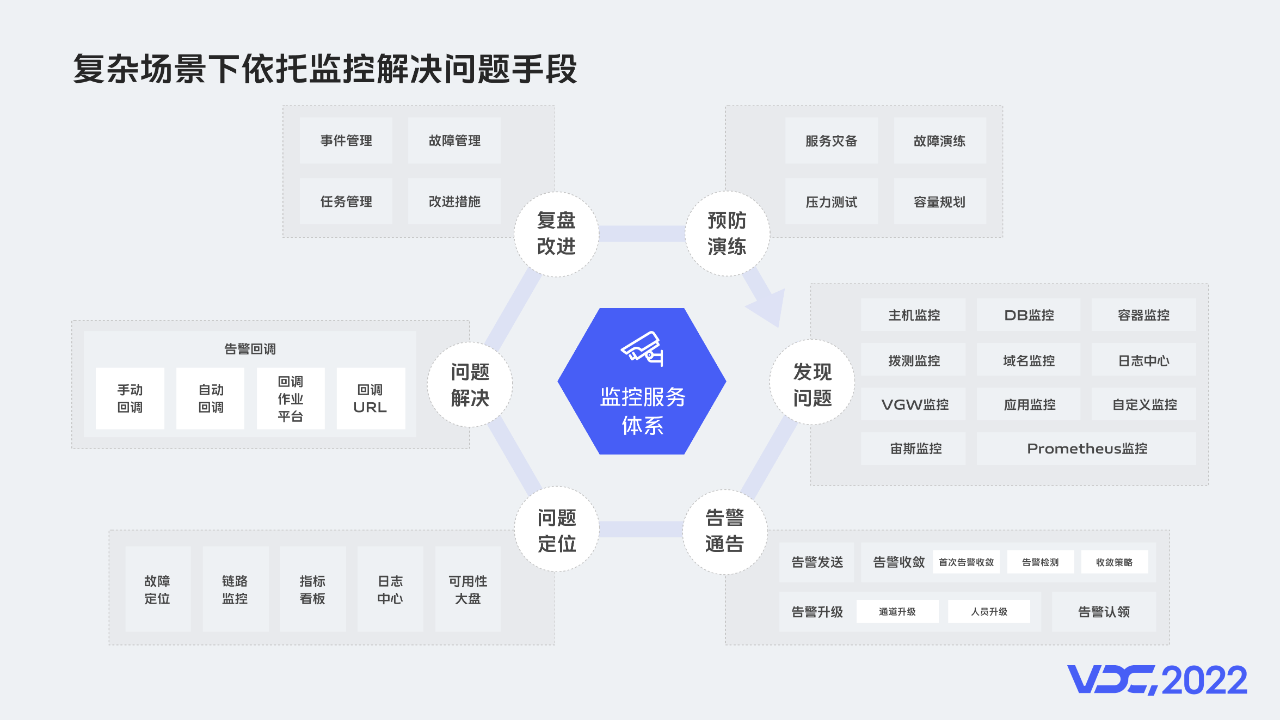
3.4 複雜場景下依託監控解決問題手段 監控能力矩陣

隨著公司業務發展,業務模型、部署架構越來越複雜,讓故障定位很困難,定位問題成本高。而監控系統在面對複雜、異構、呼叫關係冗長的系統時就起到了重要作用。在問題發現階段,例如多服務串聯呼叫,如果某個階段,出現耗時比較大的情況,可以透過應用監控,降低問題排查難度。在告警通知階段,可以透過統一告警對異常統一收斂,然後根據告警策略,通知給運維或者開發。問題定位時,可以利用故障定位服務找到最可能出現問題的服務。解決問題時,類似磁碟打滿這種比較常見的故障,可以透過回撥作業快速排障。覆盤改進階段,故障管理平臺可以統一管理,全流程覆盤,使解決過程可追溯。預防演練階段,在服務上線前,可以對服務進行壓力測試,根據指標設定容量。
四、行業變革下的監控探索實踐及未來規劃
4.1 雲原生:Prometheus監控

當前行業正迎來快速變革,我們在雲原生、AIOps、可觀性等方向均進行了探索實踐。未來我們也想緊跟行業熱點,繼續深挖產品價值。隨著Kubernetes成為容器編排領域的事實標準,Prometheus因為對容器監控良好的適配,使其成為雲原生時代,容器監控的事實標準。下面我們介紹一下整體架構,我們將容器監控分為容器叢集監控和容器業務監控,首先對於容器叢集監控,每個生產叢集都有獨立的監控節點,用於部署監控元件,Prometheus按照採集目標服務劃分為多組,資料儲存採用VictoriaMetrics,我們簡稱VM,同一機房的Prometheus叢集,均將監控資料Remote-Write到VM中,VM配置為多副本儲存。透過撥測監控,實現對Prometheus自監控,保障Prometheus異常時能收到告警資訊。容器業務監控方面,Agent部署在宿主機,並從Cadvisor拉取指標資料,上報到Bees-Bus,Bees-Bus將資料雙寫到兩個Kafka叢集,統一檢測服務非同步檢測指標資料,業務監控指標資料採用VM做遠端儲存,Dashboard透過Promql語句查詢展示指標資料。
4.2 AIOps:故障定位
當前業界對AIOps的探索,大部分在一些細分場景,我們也在故障定位這個方向進行了探索。分析過程中首先透過CMDB節點樹,選定需要分析的專案節點,然後選擇需要分析的時段,就可以按元件和服務下鑽分析,透過計算得出每個下游服務的波動方差,再利用K-Means聚類,過濾掉波動較小的聚類,找到可能出現異常的服務或元件。分析過程會形成一張原因鏈路圖,方便使用者快速找到異常服務,分析結果會推薦給使用者,告知使用者最可能出現異常的原因。詳情檢視功能可以看到被呼叫的下游服務、介面名、耗時等資訊。
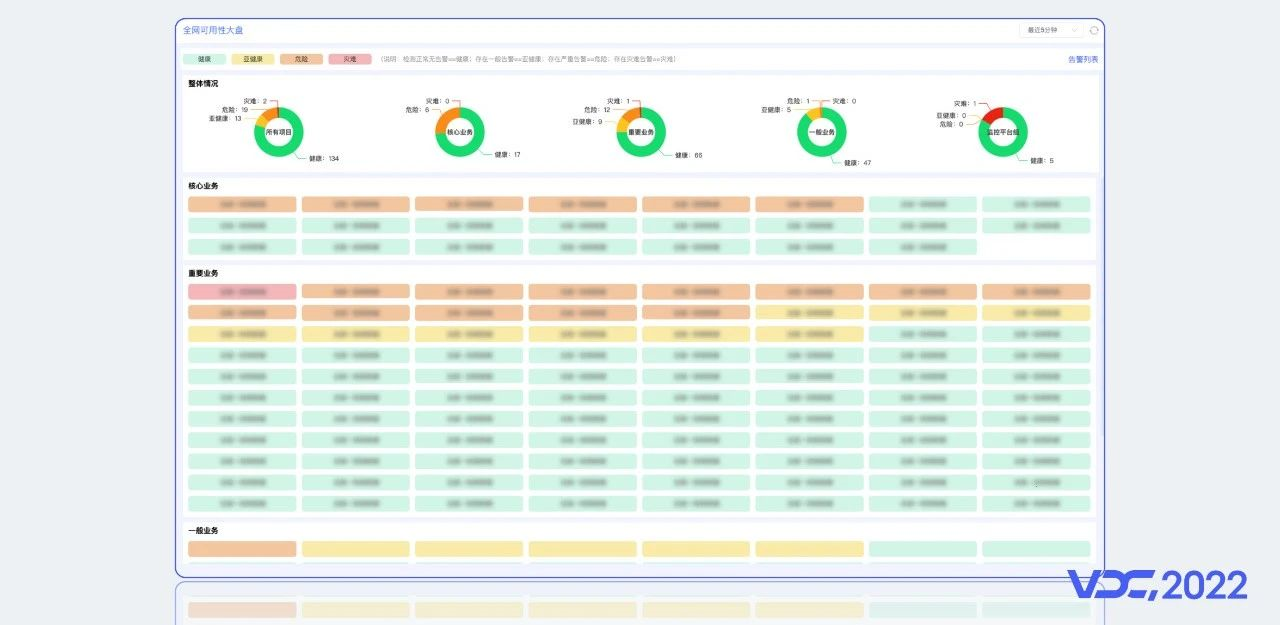
4.3 可觀測性:可用性大盤

由於CNCF在雲原生的定義中提到了Observerbility,所以近兩年可觀性,成了技術圈很火熱的關鍵詞。當前業界基於Metrics、Logs、Traces對可觀測性形成了一定共識。谷歌也給出了可觀測的核心價值就是快速排障。我們認為指標、日誌、追蹤是實現可觀測性的基礎,在此基礎上將三者有機融合,針對不同的場景將他們串聯在一起,實現方便快捷的查詢故障根因,綜上我們建設了可用性大盤,它能檢視服務的健康狀況,透過下鑽,可以看到上下游服務依賴關係、域名健康狀況、後端服務分佈等。透過串聯跳轉等方式可以看到對應服務的日誌和指標資訊。
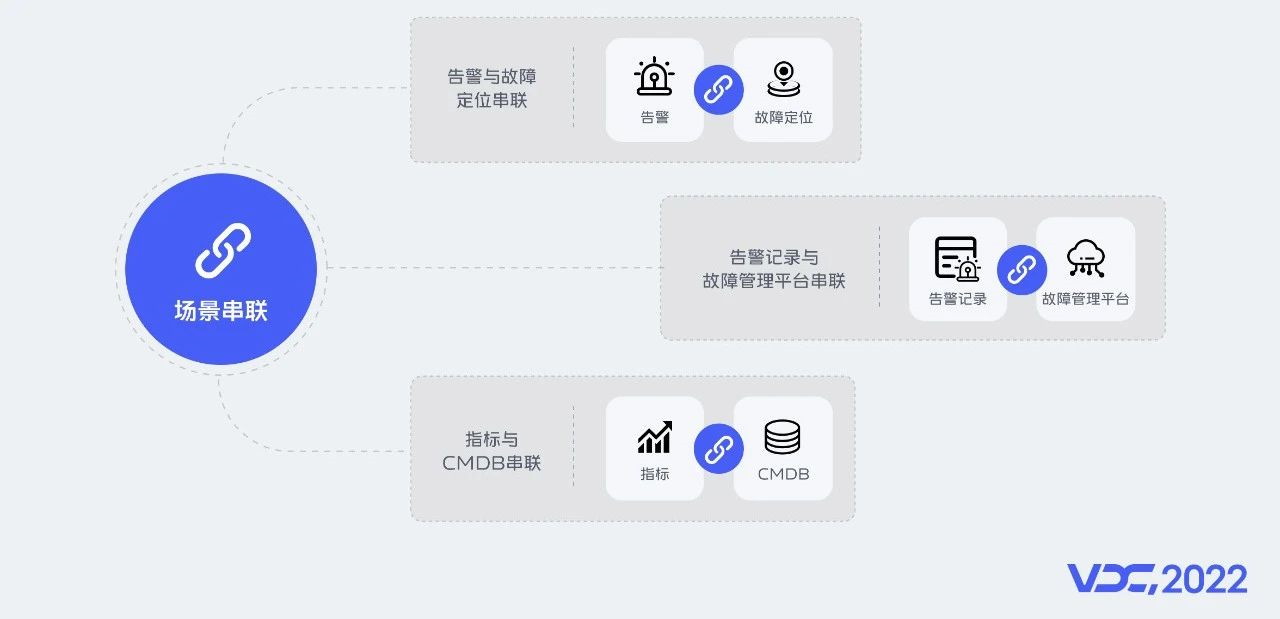
4.4 場景串聯

未來我們希望在場景串聯、可觀測性、服務能力化進一步探索,深挖產品價值。場景串聯上:
首先我們希望告警能夠與故障定位平臺串聯,幫助使用者快速找到故障根因,縮短排查時間 ;
告警記錄能夠一鍵轉為事件,減少資料鏈路中人為操作的環節,保障資料的真實性;
我們希望能與CMDB等平臺打通,將資料價值最大化。
4.5 統一可觀測
現在,vivo監控服務體系的可觀測產品沒有完全融合在一起,所以後續我們希望構建統一可觀測平臺:
在一元場景中,可以單獨檢視指標、日誌、追蹤資訊;
在轉化場景中,能夠透過日誌獲得指標資料,對日誌的聚合和轉化得到追蹤,利用呼叫鏈的分析,獲得呼叫範圍內的指標。透過指標、日誌、追蹤多個維度找到故障的源頭;
在二元場景,我們希望日誌和指標、日誌和追蹤、追蹤和指標能夠相互結合,聚合分析。
4.6 能力服務化
目前監控有很多服務,在公司構建混合雲平臺的大背景下,監控系統的服務應該具備以能力化的方式提供出去。未來我們希望指標、圖表、告警等,以API或者獨立服務的方式提供能力,例如在CICD服務部署過程中,就可以透過監控提供的圖表能力,看到服務部署時關鍵指標變化情況,而不需要跳轉到監控服務檢視指標資訊。
最後,我們希望監控能更好的保障業務可用性,在此基礎上,我們也希望透過監控系統提升業務服務質量。
來自 “ dbaplus社群 ”, 原文作者:陳寧寧;原文連結:http://server.it168.com/a2023/0207/6788/000006788453.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- vivo 服務端監控體系建設實踐服務端
- vivo 服務端監控架構設計與實踐服務端架構
- vivo服務端監控老版本架構設計服務端架構
- vivo服務端監控系統架構及演進之路服務端架構
- prometheus監控golang服務實踐PrometheusGolang
- Python實現遠端埠監控例項Python
- 阿里雲 ACK 容器服務生產級可觀測體系建設實踐阿里
- vivo 容器叢集監控系統架構與實踐架構
- 帶你十天輕鬆搞定 Go 微服務系列(八、服務監控)Go微服務
- oracle監聽不到例項服務Oracle
- 「服務端」node服務的監控預警系統架構服務端架構
- Grafana監控系統的構建與實踐Grafana
- 輕量級網站建設jsonp跨域簡單例項網站JSON跨域單例
- vivo 推送系統的容災建設與實踐
- vivo 手機雲服務建設之路
- 信創雲安全建設實踐|構建更加智慧、安全的政務雲服務體系
- 快速構建業務監控體系,觀grafana監控的藝術Grafana
- T 沙龍移動實踐日總結 —— 蜂鳥團隊移動端異常監控體系建設
- 安全建設實踐案例四連發(一)如何讓安全建設更輕鬆?
- 打造立體化監控體系的最佳實踐
- 宜信智慧監控平臺建設實踐|分享實錄
- 搭建服務端效能監控系統 Prometheus 詳細指南服務端Prometheus
- 架構設計 | 分散式體系下,服務分層監控策略架構分散式
- vivo 實時計算平臺建設實踐
- Oracle輕量級實時監控工具-oratopOracle
- APM效能監控軟體的監控型別服務及監控流程型別
- 得物技術 NOC—SLA C 端業務監控實踐
- 例項程式碼分享Python實現Linux監控PythonLinux
- vivo 短視訊推薦去重服務的設計實踐
- 面向智算服務,構建可觀測體系最佳實踐
- 蘑菇街SRE體系建設實踐
- python3.10監控redis例項PythonRedis
- 監控神器:Prometheus 輕鬆入門,真香!(上篇)Prometheus
- 監控神器:Prometheus 輕鬆入門,真香!(下篇)Prometheus
- 服務監控工具
- Java後端分散式系統的服務監控:Zabbix與NagiosJava後端分散式iOS
- Apollo GraphQL 服務端實踐服務端
- 服務端思維指南 | 常用效能監控指南服務端