Node 系統中定時任務的演化
01 背景
北斗前端監控系統是 58 內部的一個線上質量監控排查解決方案,用於幫助使用者大幅提升定位問題和最佳化專案的效率。系統共分為資料收集(SDK)、資料處理(Java)、資料儲存(Druid、……)、資料分析(Node.js)、資料展示(React) 5 層模型。Node.js 作為系統中的資料分析層,提供各種資料分析和應用的方式。
在一期之後,系統的基礎功能已經完備。平臺可以收集 5 種型別、30 多種指標的資料,已經具備了很強的資料收集能力,資料應用的方式卻很匱乏。
所以在二期開發時,我們計劃在 Node 端加入多種資料應用的方式。實時告警,就是其中之一。
簡單分析需求,服務端需要以一定的頻次(例如每分鐘)監測不同專案中使用者配置關注的指標數值。當數值出現異常時,給使用者傳送郵件、簡訊等告警資訊用於警示。
而其中的重點,就是如何在 Node.js 中設計並實現定時任務系統?
02 定時任務1.0-簡單場景下的快速應用
定時任務 1.0 - 簡單場景下的快速應用
初期的定時任務,是為告警而開發的,所以場景較為簡單。
生產者:定時生成多種告警指標、幾百個專案下的定時任務。
消費者:執行定時任務,進行閾值計算並告警。

由於指標已經固定,且當時沒有告警外的其他應用場景,所以可擴充套件性不是影響系統的重要因素。而集團內部平臺使用者量級較小,安全、成本等其他因素也不會成為瓶頸。系統的複雜度主要來自於對可用性的支援。
作為一個穩定的系統是必須在叢集內多個機器中執行的。分散式必然會帶來額外的系統複雜度。
2.1 分散式
當叢集內有多臺伺服器,我們如何保證定時任務可以由不同的機器不重複的執行呢?
大家可以很容易的想到 MQ(訊息佇列)和分散式鎖。兩者也都有相關的 Node.js 庫,基於 MQ 的 node-kafaka 以及基於鎖的 Redlock
在當時的場景下,我們需要低成本快速的上線告警系統。MQ 雖然功能完備,支援更為複雜的功能,但是相對於搶鎖機制複雜度太高,在簡單的場景下優勢又不是很明顯。所以最終選擇基於 Redlock 的搶鎖機制實現分散式定時任務。
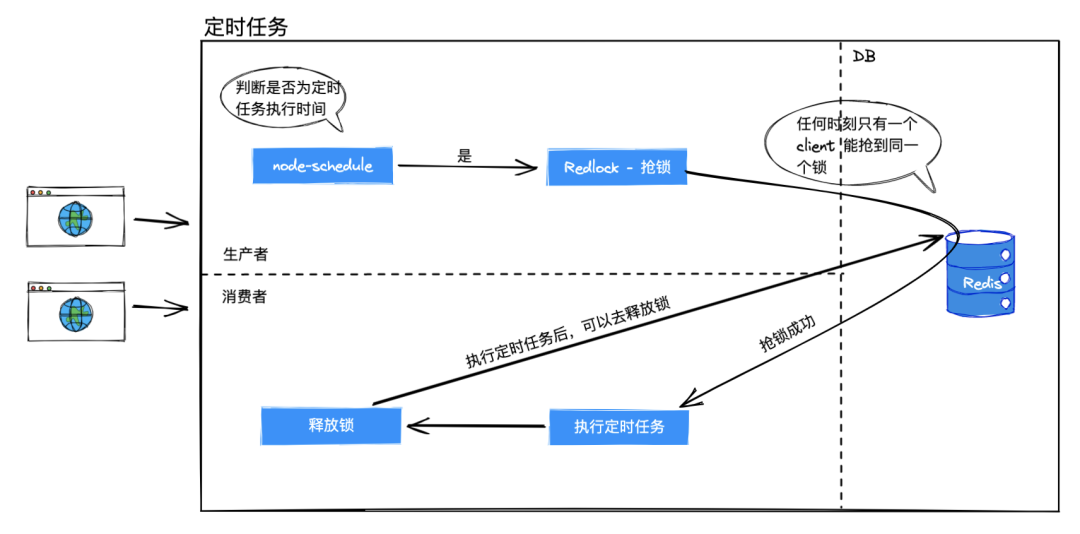
當叢集內的機器使用 node-schedule 判斷到達定時任務的執行時間時(例如每分鐘執行),會同時使用 Redlock 進行搶鎖操作。
多個定時任務,配置不同的 key。同一時間內,如果鎖沒有被釋放它只會被一臺機器獲取。這樣我們就保證了定時任務只被一臺機器執行。
搶鎖成功的機器會執行定時任務,計算資料是否異常並告警。
在適當時時機將鎖釋放即可,只要保證搶鎖的時間段內鎖存活即可。
這樣我們就保證了分散式系統內定時任務只執行一次。
可以看到 1.0 版本的定時任務是單獨為告警而開發的,此時的告警模組流程簡單,且指標數量較少。系統內的生產者和消費者也沒有進行解耦,整體流程是線性的。在當時的場景下,這種基於 Redlock 的定時任務方案完全可以支撐業務穩定執行。
03 定時任務2.0-複雜場景下的架構升級
隨著平臺的擴充套件,告警增加了自定義告警功能。定時任務也增加了取樣分析、定時資料快取、定時週報等大量定時任務的執行。此時,1.0 版本的定時任務系統開始湧現出各種問題。
任務分配不均勻。當定時任務數量增大後,出現了任務分配不平衡的問題,叢集內某些機器搶到了更多的任務,某些機器搶到任務較少,資源利用不平衡。
隨著資料量級增大,生成任務和執行任務時間複雜度相差較大,當定時任務過多時會對系統效能造成負擔。
任務執行順序無法保證,當遇到需要按序下發的定時任務時無法保證。
定時任務可靠性較低,沒有持久化儲存任務列表,執行異常的任務沒有重試機制。
……
隨著系統的擴充套件,單獨為告警而開發的定時任務執行著很多額外的模組。雖然整體流程還沒有被阻塞,但是隨著後續系統的擴充套件,必然會導致系統越來越不穩定。於是我們計劃重構定時任務,使其能夠作為一個通用的子模組,承載多樣的定時任務。
1.0 時沒有引入訊息佇列或任務佇列來處理定時任務,是因為當時的場景下對保序、異常任務重試等特性沒有強需求,接入任務佇列後系統複雜度卻會高很多。而 2.0 時作為通用模組,則需要一定的機制來保證這些特性,於是我們決定引入任務佇列的概念來進行系統重構。
此時的系統結構如下:

生產者生產任務,會將任務推送到任務佇列中,透過任務佇列可以保證任務的有序性。
消費者非同步按需的獲取對應的 Job,也可以選擇在空閒時再繼續獲取執行新的任務,而不是所有的定時任務堆積到系統中一起執行。解決了任務均勻下發,按需執行的問題。
透過任務佇列,可以維護任務的執行狀態。這樣持久化儲存或失敗重試的功能也可以開發相應的功能去做擴充套件。
3.1 業內實現
在業內 Node 端的任務佇列也有很多完整的實現方案,且都經過了大量的場景校驗,不需要我們去重複的造輪子。引用 bull 官方的一張對比表,我們整理部分對比如下。
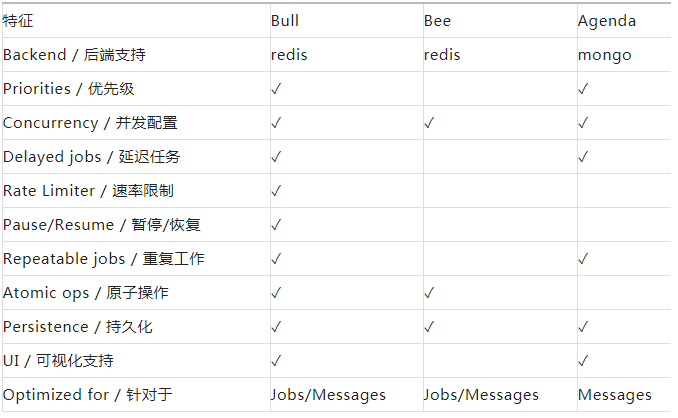
Agenda 是基於 mongo 的任務佇列解決方案,更偏向於定時任務。
Bee 是一個簡單、快速的 Node.js 作業/任務佇列,更專注於小粒度任務的處理,並極大的最佳化此場景下的效能,由 Redis 提供支援。
Bull 提供完整的任務佇列解決方案,有較活躍的受眾及系統更新頻率。
對比其功能及差異,bull 是目前功能最完善的框架,社群也非常活躍,其豐富的事件回撥也能支援我們對流程進行細粒度的把控。
最終在做了技術調研之後,新系統的重構方案就選擇使用 bull 來作為基礎框架,特定的功能場景下單獨進行開發支援。
那麼在 bull 中,任務是如何進行流轉的呢?
bull 中分為生產者和消費者兩種角色,使用 LPUSH/BRPOPLPUSH 命令來維護任務主佇列,同時還加入了多種輔助資料結構,為系統豐富的功能做支援。
當生產者生成一個 Job 後,會嘗試推送到 Redis 對應的任務佇列中(List)。bull 會透過 JobId 區分是否重複推送了一個 Job,以此來實現任務去重功能。
消費者使用 BRPOPLPUSH 命令阻塞式讀取任務列表,而不需要輪詢的讀取。當 List 中有新的 Job 後會將任務分配給消費者。透過配置併發數,也可以控制同一個消費者併發執行任務的數量。
當 Job 執行完成後,消費者給出反饋。此時 bull 更新任務佇列中 Job 的狀態,並觸發對應的事件。
依靠其細粒度的狀態儲存記錄,bull 也支援可靠的任務重試機制,當服務重啟或任務執行失敗時,bull 可以透過 Job 執行記錄來重新執行未完成的任務,極大的提高了系統的可靠性。

可以看到,bull 與 2.0 的系統結構非常契合,我們只需要在此基礎上進行二次開發就可以完成 2.0 定時任務系統的重構。
最終定時任務系統架構的設計如下:

生產者
透過 node-schedule 觸發定時任務。雖然 bull 也支援定時任務,但是其定時任務對 Redis 依賴過高。當 Redis 中資料結構改變時會影響到系統中定時任務的執行,其可用性較低。所以使用 cron 相關的庫手動觸發定時任務,來保證系統的穩定性。
當定時任務觸發後,叢集內的多個機器會構建 JobId,然後使用 bull.add 將任務推送到任務佇列。此處我們使用一定的 JobId 生成演算法來保證同一時間段內,JobId 的一致性。當任務佇列檢測到相同的 JobId 時,只會新增一個。
Redis 使用 List 及其他的資料結構來維護任務佇列的執行及對其持久化儲存。
消費者
消費者會使用 BRPOPLPUSH 命令阻塞式讀取任務佇列中的任務,當佇列中有任務新增時將其彈出並執行。這裡可以透過併發配置同時執行的任務數量。
系統檢測 process 函式是否有對應 name 或 * 的 handler,如果有執行對應的回撥函式。
在不同的事件流節點中,會觸發對應的事件回撥函式。
當任務執行完成時,必定會指向 completed(成功)、failed(失敗)的狀態。在其回撥函式中判斷是否為同一批任務的最後一個任務,如果是最後一個任務則本批次的定時任務全部執行完成,觸發 finished 事件。此處注意讀取狀態及狀態寫入 Redis 需要使用事務保證原子性。
到此,2.0 版本的定時任務系統就已經設計完成了。
縱觀北斗監控系統中定時任務的發展。
初期由於功能簡單,且需要快速上線。所以使用 Redlock 開發了基於搶鎖機制的定時任務。
後續由於系統功能的擴充套件,需要支撐更多的定時任務。原系統中的弊端逐漸顯露並對系統開發維護帶來了困難,此時引入了訊息佇列的概念最佳化系統模型。
在持續的迭代中,系統功能也趨於穩定和完善。在目前的北斗監控系統中,定時任務系統支撐著實時告警、取樣分析、定時資料快取、定時週報等大量任務的穩定執行。
但這不是終點,後續一定會遇到更多的挑戰,系統的架構也可能進一步升級。而我們需要做的就是擁抱變化,適配我們當下的業務場景去做合適的選擇。
來自 “ 58技術 ”, 原文作者:溫佳偉;原文連結:http://server.it168.com/a2022/1130/6778/000006778063.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- Linux系統中延時任務及定時任務Linux
- 定時任務管理系統
- linux系統怎麼新增每天定時任務? linux系統新增定時任務的教程Linux
- Linux系統管理之定時任務Linux
- Laravel使用command在Linux系統中跑定時任務LaravelLinux
- 『學了就忘』Linux系統定時任務 — 88、迴圈執行定時任務Linux
- linux 如何建立定時任務?crontab -e 定時任務使用的時間是系統時間Linux
- 『學了就忘』Linux系統定時任務 — 87、只執行一次的定時任務Linux
- spring boot中的定時任務Spring Boot
- Java 中的定時任務(一)Java
- Android 中的定時任務排程Android
- 定時任務
- 『學了就忘』Linux系統定時任務 — 89、任務排程工具anacronLinux
- 直播系統開發,每日任務定時重新整理
- 直播系統原始碼,實現倒數計時,定時任務原始碼
- 基於 Golang 開發的分散式定時任務管理系統Golang分散式
- ECTS——使用 Golang 開發的分散式定時任務管理系統Golang分散式
- SpringTask定時任務Spring
- Oracle定時任務Oracle
- Navicat定時任務
- schedule 定時任務
- 定時任務scheduler
- 定時任務操作
- @Scheduled 定時任務
- Linux 定時任務Linux
- Linux | 定時任務Linux
- Java 定時任務Java
- At 、Crontabl定時任務
- crontab定時任務
- laravel定時任務Laravel
- SpringBoot定時任務Spring Boot
- springboot:定時任務Spring Boot
- 定時任務管理
- ubuntu定時任務Ubuntu
- Linux中如何實現定時任務Linux
- 定時任務crond服務
- GO的定時器Timer 和定時任務cronGo定時器
- SpringBoot與非同步任務、定時任務、郵件任務Spring Boot非同步