階段一:連線
主從連線(slave連線master)
方式一:客戶端傳送命令
slaveof <masterip> <masterport>方式二:啟動伺服器引數
redis-server -slaveof <masterip> <masterport>方式三:伺服器配置
slaveof <masterip> <masterport>slave系統資訊
- master_link_down_since_seconds
- masterhost
- masterport
mater系統訊息
- slave_listening_port(多個)
主從斷開連線(從)
- 客戶端傳送命令
slaveof no one
授權訪問
master配置檔案設定密碼
requirepass <password>master客戶端傳送命令設定密碼
config set requirepass <password> config get requirepassslave客戶端傳送命令設定密碼
auth <password>slave配置檔案設定密碼
masterauth <password>啟動客戶端設定密碼
redis-cli -a <password>
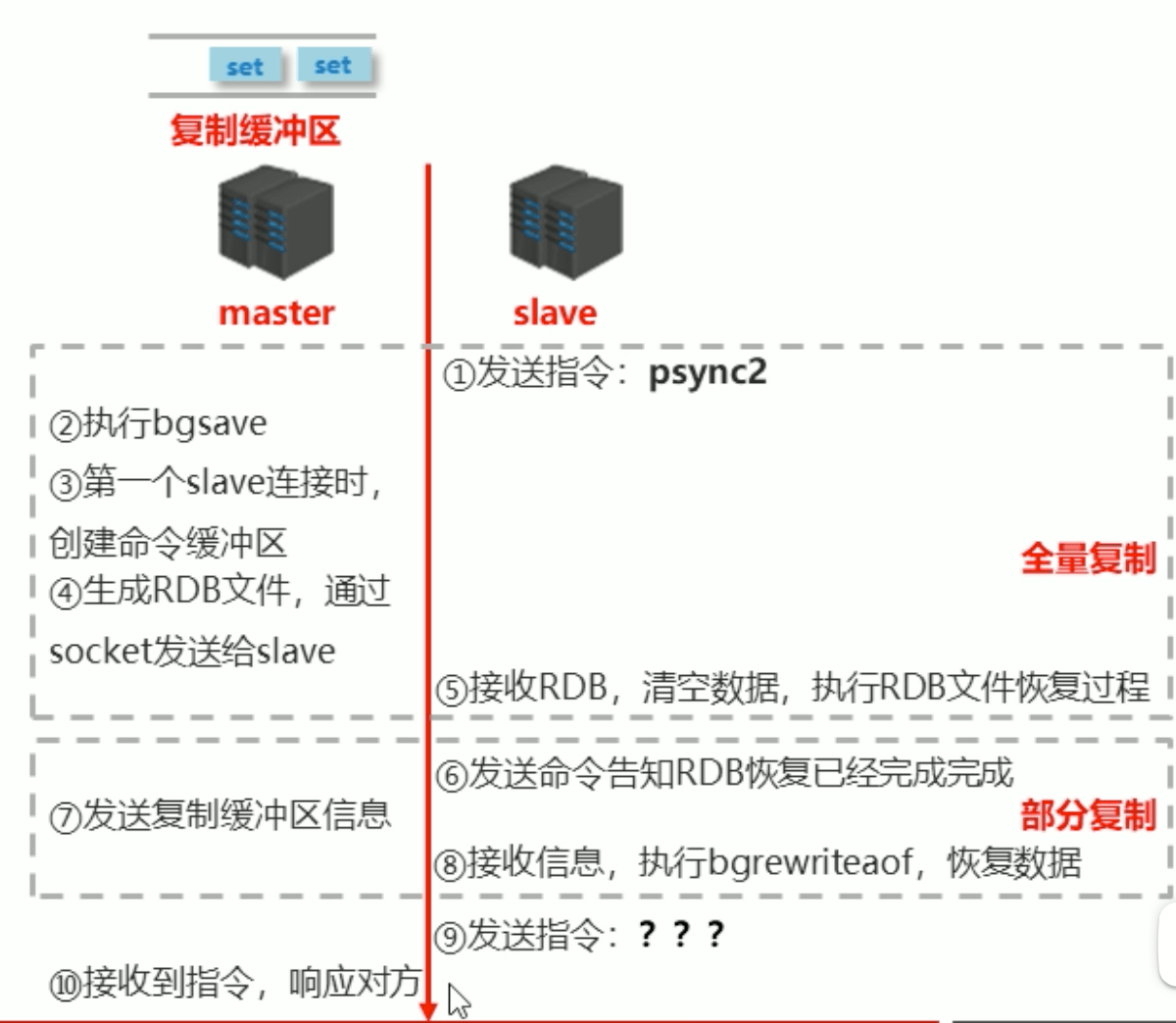
階段二:資料同步階段工作流程
- 在slave初次連線master後,複製master中的所有資料到slave
- 將slave的資料庫狀態更新成master當前的資料庫狀態
資料同步階段工作流程
- 請求同步資料
- 建立RDB同步資料
- 恢復RDB同步資料
- 請求部分同步資料
- 恢復部分同步資料
至此,資料同步工作完成
狀態:
slave:具有master端全部資料,包含RDB過程接收的資料
master:保持slave當前資料同步的位置
總體:之間完成了資料克隆
資料同步階段master說明
- 如果master資料量巨大,資料同步階段應避開流量高峰期,避免造成master阻塞,影響業務正常執行。
- 複製緩衝區大小設定不合理,會導致資料溢位。如進行全量複製週期太長,進行部分複製時發現資料已經存在丟失的情況,必須進行第二次全量複製,致使slave陷入死迴圈狀態。
repl-backlog-size 1mb - master單機記憶體佔用主機記憶體的比例不應過大,建議使用50%-70%的記憶體,留下30%-50%的記憶體用於執行bgsave命令和建立複製緩衝區。
資料同步階段slave說明
- 為避免slave進行全量複製、部分複製時伺服器響應阻塞或資料不同步,建議關閉此期間的對外服務
slave-serve-stale-data yes | no - 資料同步階段,master傳送給slave資訊可以理解master是slave的一個客戶端,主動向slave傳送命令
- 多個slave同時對master請求資料同步,master傳送的RDB檔案增多,會對頻寬造成巨大沖擊,如果master頻寬不足,因此資料同步需要根據業務需求,適量錯峰
- slave過多時,建議調整拓撲結構,由一主多從結構變為樹狀結構,中間的節點既是master,也是slave。注意使用樹狀結構時,由於層級深度,導致深度越高的slave與最頂層master間資料同步延遲較大,資料一致性變差,應謹慎選擇
階段三:命令傳播階段
- 當master資料庫狀態被修改後,導致主從伺服器資料庫狀態不一致,此時需要讓主從資料同步到一致狀態,同步的動作稱為命令傳播
- master將接收到的資料變更命令傳送給slave,slave接收命令後執行命令
命令傳播階段的部分複製
命令傳播階段出現了斷網現象
- 網路閃斷閃連 忽略
- 短時間網路中斷 部分複製
- 長時間網路中斷 全量複製
部分複製的三個核心要素
- 伺服器的執行id(run id)
- 主伺服器的複製積壓緩衝區
- 主從伺服器的複製偏移量
伺服器執行ID(runid)
- 概念:伺服器執行ID是每一臺伺服器每次執行的身份識別碼,一臺伺服器多次執行可以生成多個執行id
- 組成:執行id由40位字元組成,是一個隨機的十六進位制字元
- 作用:執行id被用於在伺服器間進行傳輸,識別身份。如果想兩次操作均同一臺伺服器進行,必須每次操作攜帶對應的執行id,用於對方識別
- 實現方式:執行id在每臺伺服器啟動時自動生成的,master在首次連線slave時,會將自己的執行id發給slave,slave儲存此id,透過info server命令,可以檢視節點的runid
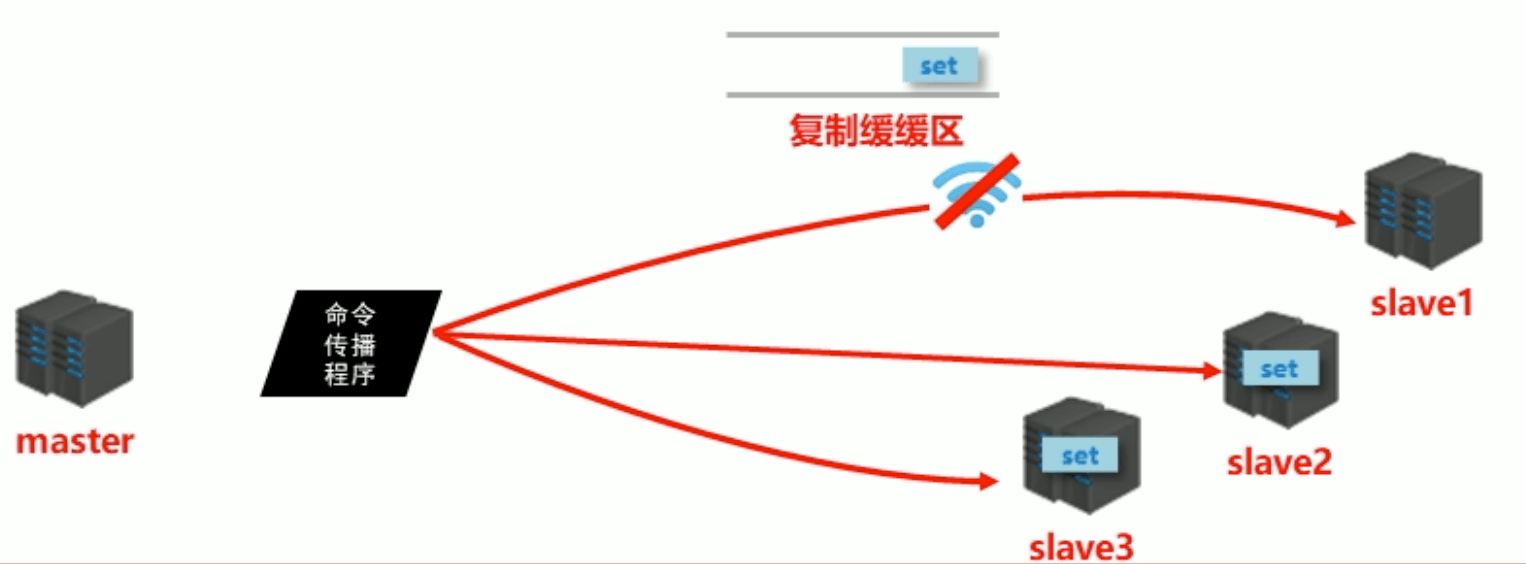
複製緩衝區
概念:複製緩衝區,又名複製積壓緩衝區,是一個先進先出(FIFO)的佇列,用於儲存伺服器執行過的命令,每次傳播命令,master都會將傳播的命令記錄下來,並儲存在複製緩衝區
複製緩衝區內部工作原理
組成
- 偏移量
- 位元組值
工作原理
- 透過offset區分不同的slave當前資料傳播的差異
- master記錄已傳送的資訊對應的offset
- slave記錄已接收的資訊對應的offset

概念:複製緩衝區,又名複製積壓緩衝區,是一個先進先出(FIFO)的佇列,用於儲存伺服器執行過的命令,每次傳播命令,master都會將傳播的命令記錄下來,並儲存在複製緩衝區。
- 複製緩衝區預設資料儲存空間大小是1M,由於儲存空間大小是固定的,當入隊元素的數量大於佇列長度是,最先入隊的元素會被彈出,而新元素會被放入佇列。
由來:每臺伺服器啟動時,如果開啟是AOF或被連線成為master節點,即建立複製緩衝區。
作用:用於儲存master收到的所有指令(僅影響資料變更的指令,例如set,select)。
資料來源:當master接收到主客戶端的指令時,除了將指令執行,會將該指令儲存到緩衝區中。
主從伺服器複製偏移量(offset)
- 概念:一個數字,描述複製緩衝區中的指令位元組位置。
- 分類:
- master複製偏移量:記錄傳送給所有slave的指令位元組對應的位置(多個)。
- slave複製偏移量:記錄slave接收master傳送過來的指令位元組對應的位置(一個)。
- 資料來源:
- master端:傳送一次記錄一次
- slave端:接收一次記錄一次
- 作用:同步資訊,比對master與slave的差異,當slave斷線後,恢復資料使用。
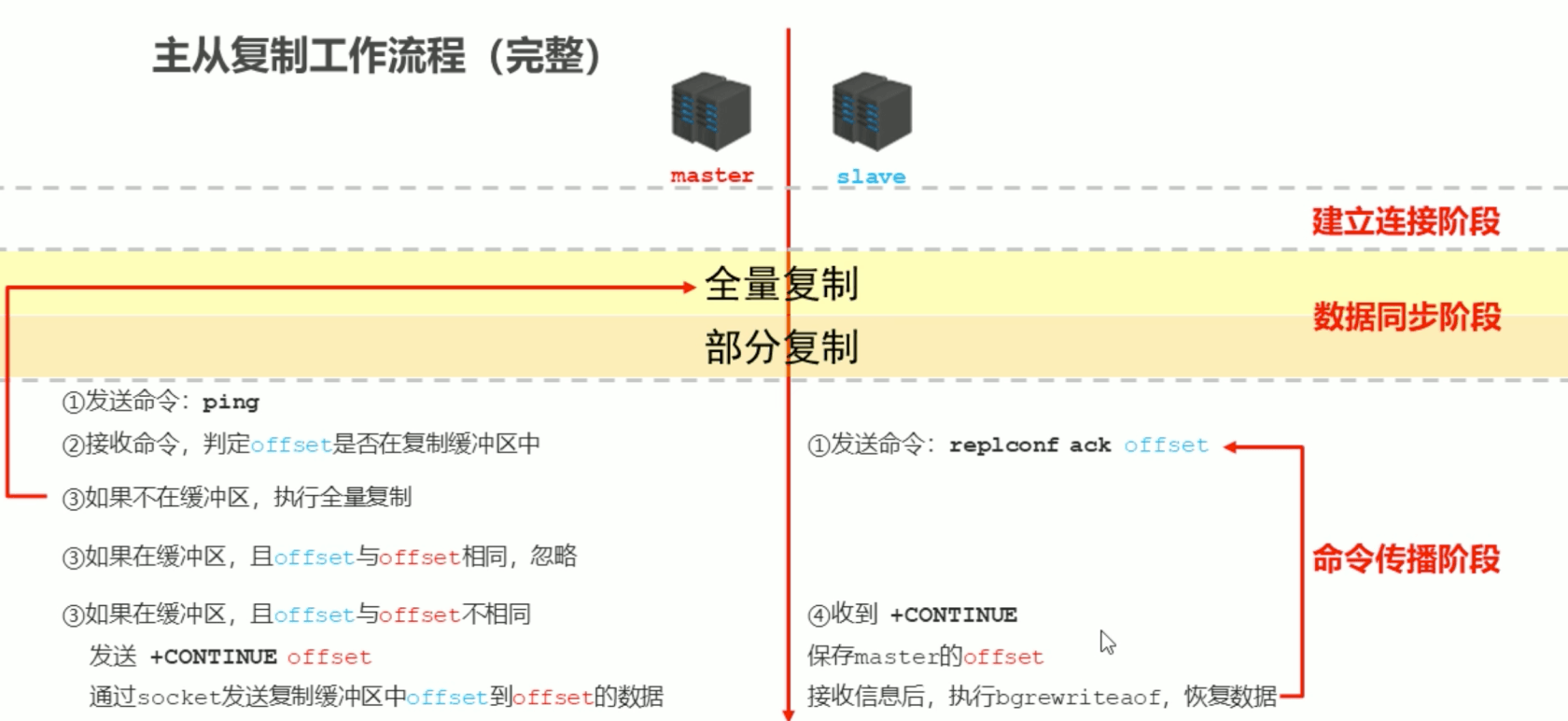
資料同步+命令傳播階段工作流程

心跳機制
- 進入命令傳播階段候,master與slave間需要進行資訊交換,使用心跳機制進行維護,實現對方連線保持線上
- master心跳:
- 指令:PING
- 週期:由repl-ping-slave-period決定,預設10秒
- 作用:判斷slave是否線上
- 查詢:INFO replication 獲取slave最後一次連線時間間隔,lag項維持在0或1視為正常
- slave心跳任務
- 指令:REPLCONF ACK{offset}
- 週期:1秒
- 作用1:回報slave自己的複製偏移量,獲取最新的資料變更指令
- 作用2:判斷master是否線上
心跳階段注意事項
- 當slave多數掉線,或延遲過高時,master位保障資料穩定性,將拒絕所有資訊同步操作
slave數量少於2個,或者所有slave的延遲都大於等於8秒時,強制關閉master寫功能,停止資料同步min-slaves-to-write 2 min-slaves-max-lag 8 - slave數量由slave傳送REPLCONF ACF命令做確定
- slave延遲由slave傳送REPLCONF ACF命令做確定
主從複製工作流程(完整)
本作品採用《CC 協議》,轉載必須註明作者和本文連結