redis主從叢集搭建及容災部署(哨兵sentinel)
Redis也用了一段時間了,記錄一下相關叢集搭建及配置詳解,方便後續使用查閱。
提綱
l Redis安裝
l 整體架構
l Redis主從結構搭建
l Redis容災部署(哨兵sentinel)
l Redis常見問題
Redis安裝
發行版:CentOS-6.6 64bit
核心:2.6.32-504.el6.x86_64
CPU:intel-i7 3.6G
記憶體:2G
下載redis,選擇合適的版本
[root@rocket software]# wget http://download.redis.io/releases/redis-2.8.17.tar.gz
[root@rocket software]# cd redis-2.8.17
[root@rocket redis-2.8.17]# make
[root@rocket redis-2.8.17]# make test
cd src && make test
make[1]: Entering directory `/home/software/redis-2.8.17/src'
You need tcl 8.5 or newer in order to run the Redis test
make[1]: *** [test] Error 1
make[1]: Leaving directory `/home/software/redis-2.8.17/src'
make: *** [test] Error 2
make test報錯,安裝tcl
[root@rocket software]# wget http://prdownloads.sourceforge.net/tcl/tcl8.5.18-src.tar.gz
[root@rocket software]# tar -zxvf tcl8.5.18-src.tar.gz
[root@rocket software]# cd tcl8.5.18
[root@rocket tcl8.5.18]# cd unix/
[root@rocket unix]# ./configure;make;make test;make install
tcl安裝成功,繼續測試redis的安裝情況
[root@rocket redis-2.8.17]# make test
……
Cleanup: may take some time... OK
make[1]: Leaving directory `/home/software/redis-2.8.17/src'
說明redis安裝正常
整體架構
整體架構圖
這裡是本文所搭建叢集的整體架構,使用主從結構+哨兵(sentinel)來進行容災。

目錄結構
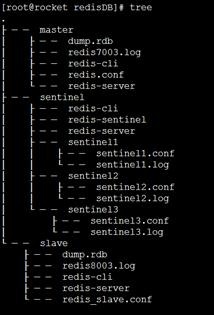
Redis主從結構搭建
搭建redis master
拷貝可執行檔案
[root@rocket master]# pwd
/usr/local/redisDB/master
[root@rocket master]# cp /home/software/redis-2.8.17/src/redis-cli .
[root@rocket master]# cp /home/software/redis-2.8.17/src/redis-server .
配置檔案redis.conf
# 守護程式模式
daemonize yes
# pid file
pidfile /var/run/redis.pid
# 監聽埠
port 7003
# TCP接收佇列長度,受/proc/sys/net/core/somaxconn和tcp_max_syn_backlog這兩個核心引數的影響
tcp-backlog 511
# 一個客戶端空閒多少秒後關閉連線(0代表禁用,永不關閉)
timeout 0
# 如果非零,則設定SO_KEEPALIVE選項來向空閒連線的客戶端傳送ACK
tcp-keepalive 60
# 指定伺服器除錯等級
# 可能值:
# debug (大量資訊,對開發/測試有用)
# verbose (很多精簡的有用資訊,但是不像debug等級那麼多)
# notice (適量的資訊,基本上是你生產環境中需要的)
# warning (只有很重要/嚴重的資訊會記錄下來)
loglevel notice
# 指明日誌檔名
logfile "./redis7003.log"
# 設定資料庫個數
databases 16
# 會在指定秒數和資料變化次數之後把資料庫寫到磁碟上
# 900秒(15分鐘)之後,且至少1次變更
# 300秒(5分鐘)之後,且至少10次變更
# 60秒之後,且至少10000次變更
save 900 1
save 300 10
save 60 10000
# 預設如果開啟RDB快照(至少一條save指令)並且最新的後臺儲存失敗,Redis將會停止接受寫操作
# 這將使使用者知道資料沒有正確的持久化到硬碟,否則可能沒人注意到並且造成一些災難
stop-writes-on-bgsave-error yes
# 當匯出到 .rdb 資料庫時是否用LZF壓縮字串物件
rdbcompression yes
# 版本5的RDB有一個CRC64演算法的校驗和放在了檔案的最後。這將使檔案格式更加可靠。
rdbchecksum yes
# 持久化資料庫的檔名
dbfilename dump.rdb
# 工作目錄
dir ./
# 當master服務設定了密碼保護時,slav服務連線master的密碼
masterauth 0234kz9*l
# 當一個slave失去和master的連線,或者同步正在進行中,slave的行為可以有兩種:
#
# 1) 如果 slave-serve-stale-data 設定為 "yes" (預設值),slave會繼續響應客戶端請求,
# 可能是正常資料,或者是過時了的資料,也可能是還沒獲得值的空資料。
# 2) 如果 slave-serve-stale-data 設定為 "no",slave會回覆"正在從master同步
# (SYNC with master in progress)"來處理各種請求,除了 INFO 和 SLAVEOF 命令。
slave-serve-stale-data yes
# 你可以配置salve例項是否接受寫操作。可寫的slave例項可能對儲存臨時資料比較有用(因為寫入salve
# 的資料在同master同步之後將很容易被刪除
slave-read-only yes
# 是否在slave套接字傳送SYNC之後禁用 TCP_NODELAY?
# 如果你選擇“yes”Redis將使用更少的TCP包和頻寬來向slaves傳送資料。但是這將使資料傳輸到slave
# 上有延遲,Linux核心的預設配置會達到40毫秒
# 如果你選擇了 "no" 資料傳輸到salve的延遲將會減少但要使用更多的頻寬
repl-disable-tcp-nodelay no
# slave的優先順序是一個整數展示在Redis的Info輸出中。如果master不再正常工作了,哨兵將用它來
# 選擇一個slave提升=升為master。
# 優先順序數字小的salve會優先考慮提升為master,所以例如有三個slave優先順序分別為10,100,25,
# 哨兵將挑選優先順序最小數字為10的slave。
# 0作為一個特殊的優先順序,標識這個slave不能作為master,所以一個優先順序為0的slave永遠不會被
# 哨兵挑選提升為master
slave-priority 100
# 密碼驗證
# 警告:因為Redis太快了,所以外面的人可以嘗試每秒150k的密碼來試圖破解密碼。這意味著你需要
# 一個高強度的密碼,否則破解太容易了
requirepass 0234kz9*l
# redis例項最大佔用記憶體,不要用比設定的上限更多的記憶體。一旦記憶體使用達到上限,Redis會根據選定的回收策略(參見:
# maxmemmory-policy)刪除key
maxmemory 3gb
# 最大記憶體策略:如果達到記憶體限制了,Redis如何選擇刪除key。你可以在下面五個行為裡選:
# volatile-lru -> 根據LRU演算法刪除帶有過期時間的key。
# allkeys-lru -> 根據LRU演算法刪除任何key。
# volatile-random -> 根據過期設定來隨機刪除key, 具備過期時間的key。
# allkeys->random -> 無差別隨機刪, 任何一個key。
# volatile-ttl -> 根據最近過期時間來刪除(輔以TTL), 這是對於有過期時間的key
# noeviction -> 誰也不刪,直接在寫操作時返回錯誤。
maxmemory-policy volatile-lru
# 預設情況下,Redis是非同步的把資料匯出到磁碟上。這種模式在很多應用裡已經足夠好,但Redis程式
# 出問題或斷電時可能造成一段時間的寫操作丟失(這取決於配置的save指令)。
#
# AOF是一種提供了更可靠的替代持久化模式,例如使用預設的資料寫入檔案策略(參見後面的配置)
# 在遇到像伺服器斷電或單寫情況下Redis自身程式出問題但作業系統仍正常執行等突發事件時,Redis
# 能只丟失1秒的寫操作。
#
# AOF和RDB持久化能同時啟動並且不會有問題。
# 如果AOF開啟,那麼在啟動時Redis將載入AOF檔案,它更能保證資料的可靠性。
appendonly no
# aof檔名
appendfilename "appendonly.aof"
# fsync() 系統呼叫告訴作業系統把資料寫到磁碟上,而不是等更多的資料進入輸出緩衝區。
# 有些作業系統會真的把資料馬上刷到磁碟上;有些則會盡快去嘗試這麼做。
#
# Redis支援三種不同的模式:
#
# no:不要立刻刷,只有在作業系統需要刷的時候再刷。比較快。
# always:每次寫操作都立刻寫入到aof檔案。慢,但是最安全。
# everysec:每秒寫一次。折中方案。
appendfsync everysec
# 如果AOF的同步策略設定成 "always" 或者 "everysec",並且後臺的儲存程式(後臺儲存或寫入AOF
# 日誌)會產生很多磁碟I/O開銷。某些Linux的配置下會使Redis因為 fsync()系統呼叫而阻塞很久。
# 注意,目前對這個情況還沒有完美修正,甚至不同執行緒的 fsync() 會阻塞我們同步的write(2)呼叫。
#
# 為了緩解這個問題,可以用下面這個選項。它可以在 BGSAVE 或 BGREWRITEAOF 處理時阻止主程式進行fsync()。
#
# 這就意味著如果有子程式在進行儲存操作,那麼Redis就處於"不可同步"的狀態。
# 這實際上是說,在最差的情況下可能會丟掉30秒鐘的日誌資料。(預設Linux設定)
#
# 如果你有延時問題把這個設定成"yes",否則就保持"no",這是儲存持久資料的最安全的方式。
no-appendfsync-on-rewrite yes
# 自動重寫AOF檔案
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# AOF檔案可能在尾部是不完整的(這跟system關閉有問題,尤其是mount ext4檔案系統時
# 沒有加上data=ordered選項。只會發生在os死時,redis自己死不會不完整)。
# 那redis重啟時load進記憶體的時候就有問題了。
# 發生的時候,可以選擇redis啟動報錯,並且通知使用者和寫日誌,或者load儘量多正常的資料。
# 如果aof-load-truncated是yes,會自動釋出一個log給客戶端然後load(預設)。
# 如果是no,使用者必須手動redis-check-aof修復AOF檔案才可以。
# 注意,如果在讀取的過程中,發現這個aof是損壞的,伺服器也是會退出的,
# 這個選項僅僅用於當伺服器嘗試讀取更多的資料但又找不到相應的資料時。
aof-load-truncated yes
# Lua 指令碼的最大執行時間,毫秒為單位
lua-time-limit 5000
# Redis慢查詢日誌可以記錄超過指定時間的查詢
slowlog-log-slower-than 10000
# 這個長度沒有限制。只是要主要會消耗記憶體。你可以通過 SLOWLOG RESET 來回收記憶體。
slowlog-max-len 128
# redis延時監控系統在執行時會取樣一些操作,以便收集可能導致延時的資料根源。
# 通過 LATENCY命令 可以列印一些圖樣和獲取一些報告,方便監控
# 這個系統僅僅記錄那個執行時間大於或等於預定時間(毫秒)的操作,
# 這個預定時間是通過latency-monitor-threshold配置來指定的,
# 當設定為0時,這個監控系統處於停止狀態
latency-monitor-threshold 0
# Redis能通知 Pub/Sub 客戶端關於鍵空間發生的事件,預設關閉
notify-keyspace-events ""
# 當hash只有少量的entry時,並且最大的entry所佔空間沒有超過指定的限制時,會用一種節省記憶體的
# 資料結構來編碼。可以通過下面的指令來設定限制
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
# 與hash似,資料元素較少的list,可以用另一種方式來編碼從而節省大量空間。
# 這種特殊的方式只有在符合下面限制時才可以用
list-max-ziplist-entries 512
list-max-ziplist-value 64
# set有一種特殊編碼的情況:當set資料全是十進位制64位有符號整型數字構成的字串時。
# 下面這個配置項就是用來設定set使用這種編碼來節省記憶體的最大長度。
set-max-intset-entries 512
# 與hash和list相似,有序集合也可以用一種特別的編碼方式來節省大量空間。
# 這種編碼只適合長度和元素都小於下面限制的有序集合
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
# HyperLogLog稀疏結構表示位元組的限制。該限制包括
# 16個位元組的頭。當HyperLogLog使用稀疏結構表示
# 這些限制,它會被轉換成密度表示。
# 值大於16000是完全沒用的,因為在該點
# 密集的表示是更多的記憶體效率。
# 建議值是3000左右,以便具有的記憶體好處, 減少記憶體的消耗
hll-sparse-max-bytes 3000
# 啟用雜湊重新整理,每100個CPU毫秒會拿出1個毫秒來重新整理Redis的主雜湊表(頂級鍵值對映表)
activerehashing yes
# 客戶端的輸出緩衝區的限制,可用於強制斷開那些因為某種原因從伺服器讀取資料的速度不夠快的客戶端
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
# 預設情況下,“hz”的被設定為10。提高該值將在Redis空閒時使用更多的CPU時,但同時當有多個key
# 同時到期會使Redis的反應更靈敏,以及超時可以更精確地處理
hz 10
# 當一個子程式重寫AOF檔案時,如果啟用下面的選項,則檔案每生成32M資料會被同步
aof-rewrite-incremental-fsync yes啟動master
[root@rocket master]# ./redis-server ./redis.conf
[root@rocket master]# ps axu|grep redis
root 24000 0.1 0.7 137356 7440 ? Ssl 23:28 0:00 ./redis-server *:7003
使用客戶端連線測試
[root@rocket master]# ./redis-cli -a 0234kz9*l -p 7003
127.0.0.1:7003> select 1
OK
127.0.0.1:7003[1]> set name zhangsan
OK
127.0.0.1:7003[1]> get name
"zhangsan"
127.0.0.1:7003[1]> quit
可以看到,redis啟動成功並且可以開始讀寫資料。
搭建redis slave
slave的配置和master基本一致,只需要修改相應的pidfile,埠,日誌檔名,並配上master的地址和認證密碼。
配置檔案redis_slave.conf(和redis master差異的地方)
# pid file
pidfile /var/run/redis_slave.pid
# 監聽埠
port 8003
# 指明日誌檔名
logfile "./redis8003.log"
# 設定當本機為slav服務時,設定master服務的IP地址及埠,在Redis啟動時,它會自動從master進行資料同步
slaveof 127.0.0.1 7003
# 當master服務設定了密碼保護時,slav服務連線master的密碼
masterauth 0234kz9*l
啟動slave並檢視資料同步情況
[root@rocket slave]# ./redis-server ./redis_slave.conf
[root@rocket slave]# ./redis-cli -a 0234kz9*l -p 8003
127.0.0.1:8003> select 1
OK
127.0.0.1:8003[1]> get name
"zhangsan"
可以看到,master中設定的key-value已經成功同步過來。
Redis容災部署(哨兵Sentinel)
哨兵的作用
1. 監控:監控主從是否正常
2. 通知:出現問題時,可以通知相關人員
3. 故障遷移:自動主從切換
4. 統一的配置管理:連線者詢問sentinel取得主從的地址
Raft分散式演算法
1. 主要用途:用於分散式系統,系統容錯,以及選出領頭羊
2. 作者:Diego Ongaro,畢業於哈佛
3. 目前用到這個演算法的專案有:
a. CoreOS : 見下面
b. ectd : a distributed, consistent shared configuration
c. LogCabin : 分散式儲存系統
d. redis sentinel : redis 的監控系統
Sentinel使用的Raft演算法核心: 原則
1. 所有sentinel都有選舉的領頭羊的權利
2. 每個sentinel都會要求其他sentinel選舉自己為領頭羊(主要由發現redis客觀下線的sentinel先發起選舉)
3. 每個sentinel只有一次選舉的機會
4. 採用先到先得的原則
5. 一旦加入到系統了,則不會自動清除(這一點很重要, why?)
6. 每個sentinel都有唯一的uid,不會因為重啟而變更
7. 達到領頭羊的條件是 N/2 + 1個sentinel選擇了自己
8. 採用配置紀元,如果一次選舉出現腦裂,則配置紀元會遞增,進入下一次選舉,所有sentinel都會處於統一配置紀元,以最新的為標準。
Raft演算法核心: 可檢視
Raft Visualization (演算法演示)
Raft分散式演算法的應用
coreos:雲端計算新星 Docker 正在以火箭般的速度發展,與它相關的生態圈也漸入佳境,CoreOS 就是其中之一。CoreOS 是一個全新的、面向資料中心設計的 Linux 作業系統,在2014年7月釋出了首個穩定版本,目前已經完成了800萬美元的A輪融資。
Sentinel實現Redis容災部署
三哨兵架構
[root@rocket sentinel]# tree
.
├── redis-cli
├── redis-sentinel
├── redis-server
├── sentinel1
│ ├── sentinel1.conf
│ └── sentinel1.log
├── sentinel2
│ ├── sentinel2.conf
│ └── sentinel2.log
└── sentinel3
├── sentinel3.conf
└── sentinel3.log
哨兵一配置sentinel1.conf
# Example sentinel.conf
# port <sentinel-port>
port 26371
# 守護程式模式
daemonize yes
# 指明日誌檔名
logfile "./sentinel1.log"
# 工作路徑,sentinel一般指定/tmp比較簡單
dir ./
# 哨兵監控這個master,在至少quorum個哨兵例項都認為master down後把master標記為odown
# (objective down客觀down;相對應的存在sdown,subjective down,主觀down)狀態。
# slaves是自動發現,所以你沒必要明確指定slaves。
sentinel monitor TestMaster 127.0.0.1 7003 1
# master或slave多長時間(預設30秒)不能使用後標記為s_down狀態。
sentinel down-after-milliseconds TestMaster 1500
# 若sentinel在該配置值內未能完成failover操作(即故障時master/slave自動切換),則認為本次failover失敗。
sentinel failover-timeout TestMaster 10000
# 設定master和slaves驗證密碼
sentinel auth-pass TestMaster 0234kz9*l
sentinel config-epoch TestMaster 15
sentinel leader-epoch TestMaster 8394
# #除了當前哨兵, 還有哪些在監控這個master的哨兵
sentinel known-sentinel TestMaster 127.0.0.1 26372 0aca3a57038e2907c8a07be2b3c0d15171e44da5
sentinel known-sentinel TestMaster 127.0.0.1 26373 ac1ef015411583d4b9f3d81cee830060b2f29862
sentinel current-epoch 8394
哨兵二配置sentinel2.conf
# Example sentinel.conf
# port <sentinel-port>
port 26372
# 守護程式模式
daemonize yes
# 指明日誌檔名
logfile "./sentinel2.log"
# 工作路徑,sentinel一般指定/tmp比較簡單
dir ./
# 哨兵監控這個master,在至少quorum個哨兵例項都認為master down後把master標記為odown
# (objective down客觀down;相對應的存在sdown,subjective down,主觀down)狀態。
# slaves是自動發現,所以你沒必要明確指定slaves。
sentinel monitor TestMaster 127.0.0.1 7003 1
# master或slave多長時間(預設30秒)不能使用後標記為s_down狀態。
sentinel down-after-milliseconds TestMaster 1500
# 若sentinel在該配置值內未能完成failover操作(即故障時master/slave自動切換),則認為本次failover失敗。
sentinel failover-timeout TestMaster 10000
# 設定master和slaves驗證密碼
sentinel auth-pass TestMaster 0234kz9*l
sentinel config-epoch TestMaster 15
sentinel leader-epoch TestMaster 8394
# #除了當前哨兵, 還有哪些在監控這個master的哨兵
sentinel known-sentinel TestMaster 127.0.0.1 26371 b780bbc20fdea6d3789637053600c5fc58dd0690
sentinel known-sentinel TestMaster 127.0.0.1 26373 ac1ef015411583d4b9f3d81cee830060b2f29862
sentinel current-epoch 8394
哨兵三配置sentinel3.conf
# Example sentinel.conf
# port <sentinel-port>
port 26373
# 守護程式模式
daemonize yes
# 指明日誌檔名
logfile "./sentinel3.log"
# 工作路徑,sentinel一般指定/tmp比較簡單
dir ./
# 哨兵監控這個master,在至少quorum個哨兵例項都認為master down後把master標記為odown
# (objective down客觀down;相對應的存在sdown,subjective down,主觀down)狀態。
# slaves是自動發現,所以你沒必要明確指定slaves。
sentinel monitor TestMaster 127.0.0.1 7003 1
# master或slave多長時間(預設30秒)不能使用後標記為s_down狀態。
sentinel down-after-milliseconds TestMaster 1500
# 若sentinel在該配置值內未能完成failover操作(即故障時master/slave自動切換),則認為本次failover失敗。
sentinel failover-timeout TestMaster 10000
# 設定master和slaves驗證密碼
sentinel auth-pass TestMaster 0234kz9*l
sentinel config-epoch TestMaster 15
sentinel leader-epoch TestMaster 8394
# #除了當前哨兵, 還有哪些在監控這個master的哨兵
sentinel known-sentinel TestMaster 127.0.0.1 26371 b780bbc20fdea6d3789637053600c5fc58dd0690
sentinel known-sentinel TestMaster 127.0.0.1 26372 0aca3a57038e2907c8a07be2b3c0d15171e44da5
sentinel current-epoch 8394
在sentinel中檢視所監控的master和slave
[root@rocket sentinel]# ./redis-cli -p 26371
127.0.0.1:26371> SENTINEL masters
1) 1) "name"
2) "TestMaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "7003"
7) "runid"
8) "de0896e3799706bda49cb92048776e233841e25d"
9) "flags"
10) "master"
127.0.0.1:26371> SENTINEL slaves TestMaster
1) 1) "name"
2) "127.0.0.1:8003"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "8003"
7) "runid"
8) "9b2a75596c828d6d605cc8529e96edcf951de25d"
9) "flags"
10) "slave"
檢視當前的master
127.0.0.1:26371> SENTINEL get-master-addr-by-name TestMaster
1) "127.0.0.1"
2) "7003"
停掉master,檢視容災切換情況
[root@rocket master]# ps axu|grep redis
root 24000 0.2 0.9 137356 9556 ? Ssl Jan12 0:30 ./redis-server *:7003
root 24240 0.2 0.7 137356 7504 ? Ssl Jan12 0:26 ./redis-server *:8003
root 24873 0.3 0.7 137356 7524 ? Ssl 01:31 0:25 ../redis-sentinel *:26371
root 24971 0.3 0.7 137356 7524 ? Ssl 01:33 0:25 ../redis-sentinel *:26372
root 24981 0.3 0.7 137356 7520 ? Ssl 01:33 0:25 ../redis-sentinel *:26373
root 24995 0.0 0.5 19404 5080 pts/2 S+ 01:34 0:00 ./redis-cli -p 26371
root 25969 0.0 0.0 103252 844 pts/0 S+ 03:33 0:00 grep redis
[root@rocket master]# kill -QUIT 24000
再檢視master,發現已經master已經切換為原來的slave
127.0.0.1:26371> SENTINEL get-master-addr-by-name TestMaster
1) "127.0.0.1"
2) "8003"
檢視sentinel日誌
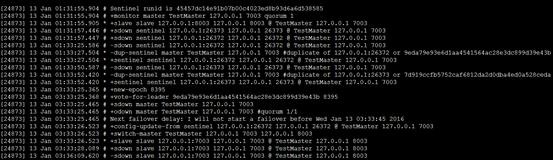
啟動原來的master,發現變成了slave
[root@rocket master]# ./redis-server ./redis.conf
127.0.0.1:26371> SENTINEL slaves TestMaster
1) 1) "name"
2) "127.0.0.1:7003"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "7003"
發現主從發生了對調。
sentinel自動發現
每個Sentinel 都訂閱了被它監視的所有主伺服器和從伺服器的__sentinel__:hello 頻道,查詢之前未出現過的sentinel(looking for unknown sentinels)。當一個Sentinel 發現一個新的Sentinel 時,它會將新的Sentinel 新增到一個列表中,這個列表儲存了Sentinel 已知的,監視同一個主伺服器的所有其他Sentinel。
127.0.0.1:7003[1]> SUBSCRIBE __sentinel__:hello
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "__sentinel__:hello"
3) (integer) 1
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26373,7d919ccfb5752caf6812da2d0dba4ed0a528ceda,8436,TestMaster,127.0.0.1,7003,8436"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26372,9eda79e93e6d1aa4541564ac28e3dc899d39e43b,8436,TestMaster,127.0.0.1,7003,8436"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26371,8d63bebfbca9e1205a43bc13b52079de6015758e,8436,TestMaster,127.0.0.1,7003,8436"Redis常見問題
最大記憶體問題:要設定好最大記憶體,以防不停的申請記憶體,造成系統記憶體都被用完。
Fork程式問題:'vm.overcommit_memory = 1'這一個選項要加到系統的配置中,防止fork因記憶體不足而失敗。
密碼問題:需要設定複雜一些,防止暴力破解。
相關文章
- Redis搭建主從複製、哨兵叢集Redis
- linux系統——Redis叢集搭建(主從+哨兵模式)LinuxRedis模式
- Redis高可用-主從,哨兵,叢集Redis
- Redis for linux原始碼&叢集(cluster)&主從(master-slave)&哨兵(sentinel)安裝配置RedisLinux原始碼AST
- 【Redis學習專題】- Redis主從+哨兵叢集部署Redis
- Redis docker 主從模式與哨兵sentinelRedisDocker模式
- Redis主從同步叢集搭建Redis主從同步
- Redis Sentinel哨兵模式部署Redis模式
- Redis安裝之叢集-哨兵模式(sentinel)模式Redis模式
- Redis的主從複製,哨兵和Cluster叢集Redis
- Redis三種高可用模式:主從、哨兵、叢集Redis模式
- 三千字介紹Redis主從+哨兵+叢集Redis
- 基於Dokcer搭建Redis叢集(主從叢集)Redis
- Redis叢集搭建 三主三從Redis
- Redis叢集搭建(三主三從)Redis
- Redis哨兵叢集:哨兵掛了,主從庫還能切換嗎?Redis
- redis安裝,主從複製,哨兵機制,叢集Redis
- redis原理及叢集主從配置Redis
- Redis哨兵模式(sentinel)學習總結及部署記錄(主從複製、讀寫分離、主從切換)Redis模式
- Redis資料型別, Redis主從哨兵和叢集(將資料匯入叢集) ubuntu使用Redis資料型別Ubuntu
- 詳解Redis主從及哨兵模式Redis模式
- Redis Sentinel哨兵模式原理及配置Redis模式
- Redis哨兵sentinelRedis
- 用 docker 學習 redis 主從複製3 redis-sentinel(哨兵模式)DockerRedis模式
- 輕鬆掌握元件啟動之Redis單機、主從、哨兵、叢集配置元件Redis
- 一文掌握Redis主從複製、哨兵、Cluster三種叢集模式Redis模式
- 實踐 - 搭建Redis一主兩從三哨兵Redis
- 基於docker環境下搭建redis主從叢集DockerRedis
- Redis Cluster 叢集搭建與擴容、縮容Redis
- 【Redis】Sentinel 哨兵模式Redis模式
- Redis-cluster叢集搭建部署Redis
- Redis 主從複製與哨兵優化部署解析Redis優化
- 一文讀懂Redis的四種模式,單機、主從、哨兵、叢集Redis模式
- 11.03:Redis持久化、主從、哨兵、叢集、常見問題重點回顧Redis持久化
- redis哨兵,叢集和運維Redis運維
- 10、redis哨兵叢集高可用Redis
- redis sentinel哨兵模式安裝部署和切換Redis模式
- 深入淺出Redis-redis哨兵叢集Redis