
分支的衍合
把一個分支中的修改整合到另一個分支的辦法有兩種:merge 和 rebase(譯註:rebase 的翻譯暫定為“衍合”,大家知道就可以了。)。在本章我們會學習什麼是衍合,如何使用衍合,為什麼衍合操作如此富有魅力,以及我們應該在什麼情況下使用衍合。
基本的衍合操作
請回顧之前有關合並的一節(見圖 3-27),你會看到開發程式分叉到兩個不同分支,又各自提交了更新。
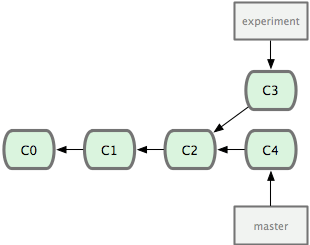
圖 3-27. 最初分叉的提交歷史。
之前介紹過,最容易的整合分支的方法是 merge 命令,它會把兩個分支最新的快照(C3 和 C4)以及二者最新的共同祖先(C2)進行三方合併,合併的結果是產生一個新的提交物件(C5)。如圖 3-28 所示:
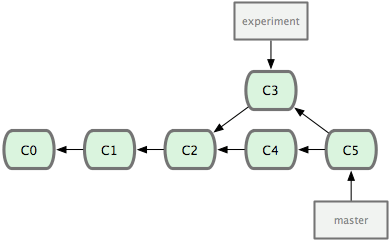
圖 3-28. 通過合併一個分支來整合分叉了的歷史。
其實,還有另外一個選擇:你可以把在 C3 裡產生的變化補丁在 C4 的基礎上重新打一遍。在 Git 裡,這種操作叫做衍合(rebase)。有了 rebase 命令,就可以把在一個分支裡提交的改變移到另一個分支裡重放一遍。
在上面這個例子中,執行:
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command它的原理是回到兩個分支最近的共同祖先,根據當前分支(也就是要進行衍合的分支 experiment)後續的歷次提交物件(這裡只有一個 C3),生成一系列檔案補丁,然後以基底分支(也就是主幹分支master)最後一個提交物件(C4)為新的出發點,逐個應用之前準備好的補丁檔案,最後會生成一個新的合併提交物件(C3'),從而改寫 experiment 的提交歷史,使它成為 master 分支的直接下游,如圖 3-29 所示:
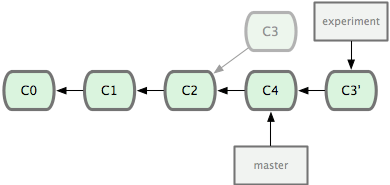
圖 3-29. 把 C3 裡產生的改變到 C4 上重演一遍。
現在回到 master 分支,進行一次快進合併(見圖 3-30):
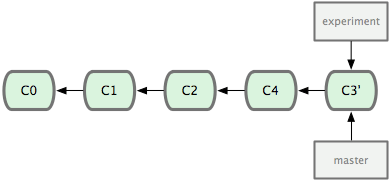
圖 3-30. master 分支的快進。
現在的 C3' 對應的快照,其實和普通的三方合併,即上個例子中的 C5 對應的快照內容一模一樣了。雖然最後整合得到的結果沒有任何區別,但衍合能產生一個更為整潔的提交歷史。如果視察一個衍合過的分支的歷史記錄,看起來會更清楚:彷彿所有修改都是在一根線上先後進行的,儘管實際上它們原本是同時並行發生的。
一般我們使用衍合的目的,是想要得到一個能在遠端分支上乾淨應用的補丁 — 比如某些專案你不是維護者,但想幫點忙的話,最好用衍合:先在自己的一個分支裡進行開發,當準備向主專案提交補丁的時候,根據最新的 origin/master 進行一次衍合操作然後再提交,這樣維護者就不需要做任何整合工作(譯註:實際上是把解決分支補丁同最新主幹程式碼之間衝突的責任,化轉為由提交補丁的人來解決。),只需根據你提供的倉庫地址作一次快進合併,或者直接採納你提交的補丁。
請注意,合併結果中最後一次提交所指向的快照,無論是通過衍合,還是三方合併,都會得到相同的快照內容,只不過提交歷史不同罷了。衍合是按照每行的修改次序重演一遍修改,而合併是把最終結果合在一起。
有趣的衍合
衍合也可以放到其他分支進行,並不一定非得根據分化之前的分支。以圖 3-31 的歷史為例,我們為了給伺服器端程式碼新增一些功能而建立了特性分支 server,然後提交 C3 和 C4。然後又從 C3 的地方再增加一個client 分支來對客戶端程式碼進行一些相應修改,所以提交了 C8 和 C9。最後,又回到 server 分支提交了 C10。
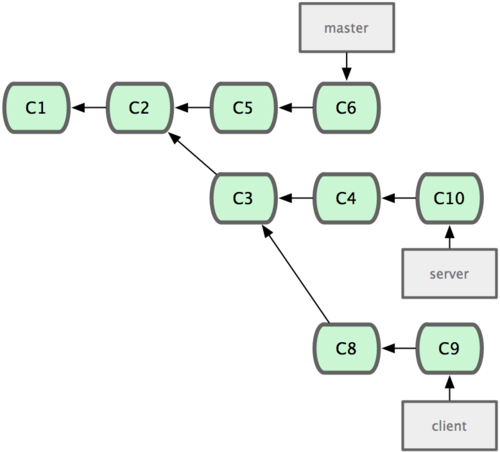
圖 3-31. 從一個特性分支裡再分出一個特性分支的歷史。
假設在接下來的一次軟體釋出中,我們決定先把客戶端的修改併到主線中,而暫緩併入服務端軟體的修改(因為還需要進一步測試)。這個時候,我們就可以把基於 server 分支而非 master 分支的改變(即 C8 和 C9),跳過 server 直接放到 master 分支中重演一遍,但這需要用 git rebase 的 --onto 選項指定新的基底分支 master:
$ git rebase --onto master server client這好比在說:“取出 client 分支,找出 client 分支和 server 分支的共同祖先之後的變化,然後把它們在 master 上重演一遍”。是不是有點複雜?不過它的結果如圖 3-32 所示,非常酷(譯註:雖然 client裡的 C8, C9 在 C3 之後,但這僅表明時間上的先後,而非在 C3 修改的基礎上進一步改動,因為 server 和client 這兩個分支對應的程式碼應該是兩套檔案,雖然這麼說不是很嚴格,但應理解為在 C3 時間點之後,對另外的檔案所做的 C8,C9 修改,放到主幹重演。):
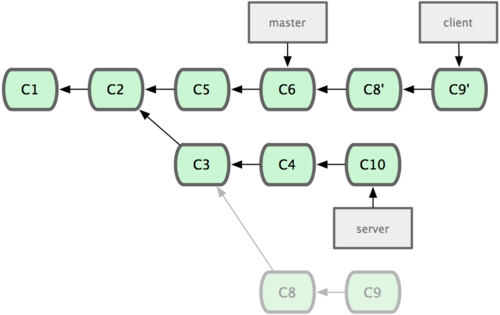
圖 3-32. 將特性分支上的另一個特性分支衍合到其他分支。
現在可以快進 master 分支了(見圖 3-33):
$ git checkout master
$ git merge client
圖 3-33. 快進 master 分支,使之包含 client 分支的變化。
現在我們決定把 server 分支的變化也包含進來。我們可以直接把 server 分支衍合到 master,而不用手工切換到 server 分支後再執行衍合操作 — git rebase [主分支] [特性分支] 命令會先取出特性分支 server,然後在主分支 master 上重演:
$ git rebase master server於是,server 的進度應用到 master 的基礎上,如圖 3-34 所示:
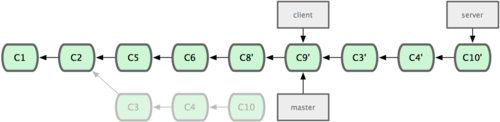
圖 3-34. 在 master 分支上衍合 server 分支。
然後就可以快進主幹分支 master 了:
$ git checkout master
$ git merge server現在 client 和 server 分支的變化都已經整合到主幹分支來了,可以刪掉它們了。最終我們的提交歷史會變成圖 3-35 的樣子:
$ git branch -d client
$ git branch -d server
圖 3-35. 最終的提交歷史
衍合的風險
呃,奇妙的衍合也並非完美無缺,要用它得遵守一條準則:
一旦分支中的提交物件釋出到公共倉庫,就千萬不要對該分支進行衍合操作。
如果你遵循這條金科玉律,就不會出差錯。否則,人民群眾會仇恨你,你的朋友和家人也會嘲笑你,唾棄你。
在進行衍合的時候,實際上拋棄了一些現存的提交物件而創造了一些類似但不同的新的提交物件。如果你把原來分支中的提交物件釋出出去,並且其他人更新下載後在其基礎上開展工作,而稍後你又用 git rebase 拋棄這些提交物件,把新的重演後的提交物件釋出出去的話,你的合作者就不得不重新合併他們的工作,這樣當你再次從他們那裡獲取內容時,提交歷史就會變得一團糟。
下面我們用一個實際例子來說明為什麼公開的衍合會帶來問題。假設你從一箇中央伺服器克隆然後在它的基礎上搞了一些開發,提交歷史類似圖 3-36 所示:

圖 3-36. 克隆一個倉庫,在其基礎上工作一番。
現在,某人在 C1 的基礎上做了些改變,併合並他自己的分支得到結果 C6,推送到中央伺服器。當你抓取併合並這些資料到你本地的開發分支中後,會得到合併結果 C7,歷史提交會變成圖 3-37 這樣:

圖 3-37. 抓取他人提交,併入自己主幹。
接下來,那個推送 C6 上來的人決定用衍合取代之前的合併操作;繼而又用 git push --force 覆蓋了伺服器上的歷史,得到 C4'。而之後當你再從伺服器上下載最新提交後,會得到:

圖 3-38. 有人推送了衍合後得到的 C4',丟棄了你作為開發基礎的 C4 和 C6。
下載更新後需要合併,但此時衍合產生的提交物件 C4' 的 SHA-1 校驗值和之前 C4 完全不同,所以 Git 會把它們當作新的提交物件處理,而實際上此刻你的提交歷史 C7 中早已經包含了 C4 的修改內容,於是合併操作會把 C7 和 C4' 合併為 C8(見圖 3-39):

圖 3-39. 你把相同的內容又合併了一遍,生成一個新的提交 C8。
C8 這一步的合併是遲早會發生的,因為只有這樣你才能和其他協作者提交的內容保持同步。而在 C8 之後,你的提交歷史裡就會同時包含 C4 和 C4',兩者有著不同的 SHA-1 校驗值,如果用 git log 檢視歷史,會看到兩個提交擁有相同的作者日期與說明,令人費解。而更糟的是,當你把這樣的歷史推送到伺服器後,會再次把這些衍合後的提交引入到中央伺服器,進一步困擾其他人(譯註:這個例子中,出問題的責任方是那個釋出了 C6 後又用衍合發布 C4' 的人,其他人會因此反饋雙重歷史到共享主幹,從而混淆大家的視聽。)。
如果把衍合當成一種在推送之前清理提交歷史的手段,而且僅僅衍合那些尚未公開的提交物件,就沒問題。如果衍合那些已經公開的提交物件,並且已經有人基於這些提交物件開展了後續開發工作的話,就會出現叫人沮喪的麻煩。