實現高可用的兩種方案與實戰
我之前在一片文章 用Nginx+Redis實現session共享的均衡負載 中做了一個負載均衡的實驗,其主要架構如下:
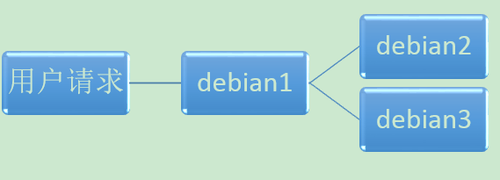
把debian1作為排程伺服器承擔請求分發的任務,即使用者訪問的是debian1,然後debain1把請求按照一定的策略傳送給應用伺服器:debian2或者debain3,甚至更多的debain4、5、6......
狀態和資料可以放在外部的分散式快取服務和分散式資料庫服務中,這樣應用服務本身就是無狀態的,所以機器增減都是很容易的,應用的高可用是有保證的(對於有狀態的高可用不僅要注意機器增減與切換、還要注意備份冗餘、資料一致性等問題)。但是當時忽略了一個地方,那就是排程伺服器debian1本身的高可用性沒有考慮到,存在單點問題。
高可用的首要想法就是雙機熱備,故障時自動切換,所以我們要給debian1加一個備機debain1'。我現在按照自己的知識粗淺的把解決方案分為兩類:客戶端有感知的高可用、對客戶端透明的高可用,並分別挑選一個示例做一下實驗。
注:下面實現高可用都用的是雙機熱備,為了方便,把排程伺服器debian1簡稱為主機,把排程伺服器debian1的備機debian1'簡稱為備機。
客戶端有感知的高可用
客戶端有感知的高可用,也就是需要客戶端的配合,客戶端自己去確認伺服器的變更並切換訪問的目標。比如說我們的主機、備機都在ZooKeeper(或者其他類似的註冊中心比如redis)中進行註冊,客戶端監聽ZooKeeper中伺服器的資訊,發現主機下線自己就切換訪問備機即可。
ZooKeeper偽叢集搭建
首先在本機搭建包含3個節點的ZooKeeper偽叢集。在官網下載版本3.5.4-beta,解壓,然後複製3份,每一份都要做如下操作:
進入conf資料夾 建立一個配置檔案zoo.cfg。程式碼如下:
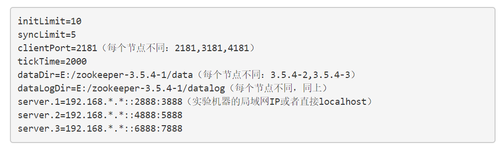
建立上面的dataDir和dataLogDir,並在dataDir目錄下必須建立myid檔案,寫入不同的整數ID,也就是上面的server.x的x,比如1
分別進入bin目錄,在zkServer.cmd中call之前加入set ZOOCFG=../conf/zoo.cfg 並用其啟動。
順帶一提,程式碼開發我就使用我之前的專案CHKV了,因為這個專案中的NameNode或者DataNode也可以用ZooKeeper實現高可用,歡迎和我一起完善這個專案,一塊進步。
排程服務端開發
排程伺服器主要向ZooKeeper註冊自己,並向客戶端提供服務。我們使用curator框架來和ZooKeeper互動,特別要注意版本問題。
主要程式碼如下:
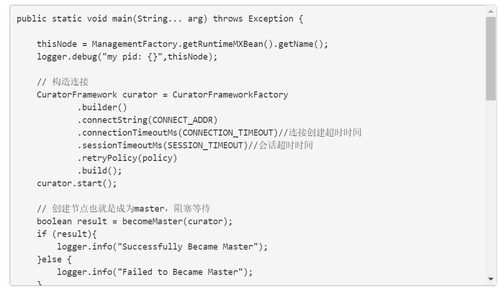
完整程式碼在GitHub上。
客戶端開發
客戶端主要向ZooKeeper監聽排程伺服器變更事件,並向其發起應用請求。實際上應用伺服器也可以使用這部分程式碼來監聽排程伺服器的變化。
主要程式碼如下:

完整程式碼在GitHub上。
對客戶端透明的高可用
對客戶端透明的高可用,也就是客戶端不需要做什麼工作,伺服器切換不切換客戶端根本不知道也不關心。主要實現方式有兩種,一種是客戶端透過域名訪問主機,那麼監控主機下線後就把域名重新分配給備機,當然這個切換會有時間成本,視定義的DNS快取時間而定;第二種就是客戶端透過IP訪問主機,監控到主機下線後就透過IP漂移技術把對外的IP(或者說虛擬IP)分配給備機,這樣就能做到及時的切換。
實際環境中常常使用keepalived來實現IP漂移。
搭建過程參考了The keepalived solution for LVS和官網文件
首先主機、備機都要安裝keepalived,然後配置主機/etc/keepalived/keepalived.conf:
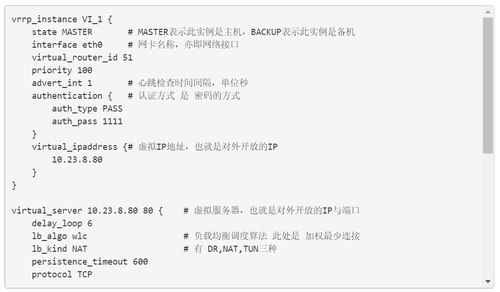
配置備機/etc/keepalived/keepalived.conf,與主機類似,但是state是backup,且權重較低即可:

反思
說白了,這兩種高可用的實現方式前者是在應用層實現的,而後者是在傳輸層實現的,那麼我們就可以想到,計算機網路的每一層其實都是可以做負載均衡和高可用的。
本文轉自mageekchiu 作者:mageek
原文連結:
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/31137683/viewspace-2213165/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- PowerJob 的自實現高可用方案,妙妙妙!
- MongoDB高階應用之高可用方案實戰(4)MongoDB
- 官方工具|MySQL Router 高可用原理與實戰MySql
- MySQL資料庫實現高可用架構之MHA的實戰MySql資料庫架構
- 高可用系列文章之三 - NGINX 高可用實施方案Nginx
- nginx實現keepalived高可用Nginx
- keepalived + nginx 實現高可用Nginx
- Redis高可用方案:使用Keepalived實現主備雙活Redis
- 一文了解資料庫高可用容災方案的設計與實現資料庫
- 使用keepalived實現nginx的高可用Nginx
- 高可用延遲佇列設計與實現佇列
- Spring實現IOC容器的兩種實現方式Spring
- Oracle的三種高可用叢集方案Oracle
- Nginx&Keepalived 實現高可用Nginx
- keepalived+MySQL實現高可用MySql
- Keepalived實現服務高可用
- HBase可用性分析與高可用實踐
- MHA高可用架構的實現方式架構
- Apache Kyuubi 高可用的雲原生實現Apache
- Spring Cloud 實戰二:Client的建立和高可用SpringCloudclient
- Kubernetes實戰:高可用叢集的搭建和部署
- 實現固定寬高比盒子的幾種方案的總結
- API閘道器實現高可用性7種技術API
- 常見的五種MySQL高可用方案分析MySql
- 雜湊表的兩種實現
- RabbitMQ實戰:可用性分析和實現MQ
- Keepalived 實現 Ambari-Server 高可用Server
- 7. Nginx實現高可用配置Nginx
- 如何設計和實現高可用的MySQLMySql
- 使用KeepAlived來實現高可用的DR模型模型
- Kubernetes-5-2:Harbor倉庫的幾種高可用方案與搭建
- Nginx實現請求的負載均衡 + keepalived實現Nginx的高可用Nginx負載
- 服務發現與配置管理高可用最佳實踐
- 4 種高可用 RocketMQ 叢集搭建方案!MQ
- 用Wikidata做實體搜尋的兩種方案
- 單利模式的兩種最佳實現模式
- python 程式池的兩種不同實現Python
- 如何設計和實現高可用MySQLMySql