1. 認識正規表示式
1.1 什麼是正規表示式?
正規表示式就用某種模式去驗證一類字串是否匹配的公式。通俗講,就是用一個字串來描述一個特徵,用其去驗證另一個字串是否符合該特徵的公式
1.2 正規表示式的組成
正規表示式由:分隔符、表示式、修飾符三部分組成。
分隔符:除字母、數字、反斜線、空白字元的任意字元
表示式:由特殊字元或配特殊字元組成的字串
修飾符:開啟/關閉某些功能/模式
2. 元字元
2.1 什麼是元字元?
元字元屬於1.2中的表示式的組成部分。
元字元是有特殊作用或者說意義的特殊字元。
2.2 常用的元字元
| 元字元 | 描述 | 示例 |
|---|---|---|
| . | 匹配除了換行符以外的任何字元 | . 示例 |
| \w | 匹配字元、數字、下劃線、漢字 | \w 示例 |
| \d | 匹配數字 | \d 示例 |
| \b | 匹配一個單詞的開始和結束 | \b 示例 |
| \s | 匹配任意空白字元 | \s 示例 |
| ^ | 匹配一個字串的開始 | ^ 示例 |
| $ | 匹配一個字串的結束 | $ 示例 |
| - | 表示範圍 | - 示例 |
| [] | 匹配括號中的任意一個字元 | [] 示例 |
| *、+、? | 量詞 |
2.3 常用量詞
2.2很清晰的告訴了我們量詞也屬於元字元的一部分,量詞和其他元字元的區別在於其代表的是數量。
| 元字元 | 描述 |
|---|---|
| * | 重複0次或更多次 |
| + | 重複1次或更多次 |
| ? | 重複0次或一次 |
| {n} | 重複n次 |
| {n,} | 重複n次或更多次(最少n次) |
| {n,m} | 重複n-m次(最少n次,最多m次) |
2.4 注意
- 在正規表示式中單詞的定義為一個字母或數字的後面為空格或其他特殊字元
3. 匹配規則
3.1 字元組
字元組即我們在一個字串中需要匹配某個單字元(注意是單字元)時需要用到的匹配規則;
例如:需要匹配一個單詞是否為cat、cut,我們可以這樣寫:
c[au]t這樣當出現cat或cut時則會匹配,但如果出現的是acut/cabt之類格式的單詞時則不會匹配。[au]就是字元組,字元組僅可以匹配一個單字元,需要注意的是字元組中需要匹配的字元有可能出現元字元。這時候就需要轉義了。
3.2 轉義
轉義的含義即我們程式語言中的轉義。正規表示式中的轉義符為\
例如:需要匹配”{xxx}”時只需要將{和}轉義就好了
\{.*\}3.3 反義
反義可以理解為與上述元字元的含義相反的元字元;
3.3.1常用的反義符
| 元字元 | 描述 |
|---|---|
| \W | 匹配不是字元、數字、下劃線、漢字的字元 |
| \D | 匹配不是數字的字元 |
| \B | 匹配不是一個單詞的開始和結束的字元 |
| \S | 匹配不是任意空白字元的字元 |
| [^x] | 匹配不是x的字元 |
| [^abcd] | 匹配不是a/b/c/d的字元 |
3.3.2 反義符注意
[^x]中的^不要和匹配字串開頭的^搞混了。可以簡單理解為只要^沒有出現在表示式的開頭就是取反的作用在實際運用中儘量不要使用反義,因為反義會在無形中了範圍。例如想要匹配一個變數的開頭時可以使用 [a-zA-Z],而不會使用\D,因為變數的命名還有其他的規則,例如不能使用
#等特殊字元,使用\D會擴大範圍,無形中增加了隱患
3.4 分支
分支可以理解為我們程式中if(x==n)的x==n(即表示式)
例如:我們如果需要匹配cat/hat的開頭可以這麼寫:
[ch]at但如果需要匹配toat時,字元組就不能滿足我們的需求了,這時就需要使用分支了
(c|h|to)at正規表示式將()內的內容視作一個整體,|代表分支,即可能存在的多種情況。
3.5 分組
當我們需要單個字元重複多次的時候只需要在字元後面加上限定字元就可以a{3},當我們需要多個字元重複多次時怎麼辦呢?這個時候就需要分組來實現了
| 類別 | 語法 | 描述 |
|---|---|---|
| 捕獲 | (exp) | 匹配exp,並將捕獲的內容分配到自動命名的組裡 |
| 捕獲 | (?< Word>exp) | 匹配exp,並將捕獲的內容分配到名為Word的組裡,也可以(?’Word’exp) |
| 捕獲 | (?:exp) | 匹配exp,不分配組名、不捕獲內容 |
| 零寬斷言 | (?=exp) | 捕獲exp後面的位置 |
| 零寬斷言 | (?<=exp) | 捕獲exp前面的位置 |
| 零寬斷言 | (?!exp) | 捕獲後面跟的不是exp的位置 |
| 零寬斷言 | (?<!exp) | 捕獲前面不是exp的位置 |
| 註釋 | (?#content) | 註釋內容 |
例如:我們需要簡單的匹配一個IP地址,不使用分組的話需要這樣寫:
\d{3}.\d{3}.\d{3}如果使用分組就可以這樣寫:
(?:\d{3}.){2}\d{3} // 將\d{3}.設定為一個分組匹配2次,最後匹配一個\d{3}是不是優雅了好多
預設情況下,每個組會擁有一個組號,規則是從左向右開始遇到(為標識,組號從1開始,0為整個正規表示式。
組號的分配會從左到右的掃描兩遍,第一遍給未命名組分配,第二遍給已命名組分配
3.6 反向引用
反向引用就是將組中捕獲到的文字拿出來作為表示式的一部分。(重複匹配組中捕獲到的文字)
例如:我們需要匹配重疊字如hello hello,我們可以這麼做:
(?<Word>\w+)\s+\k<Word>
或者
(\w+)\s+\13.7 環視(零寬斷言)
環視/斷言並不是用於捕獲字串,而是用來宣告一個應該為真的事實,當斷言為真事表示式才會繼續匹配。下述四種斷言將匹配的是一個表示式之前或之後的位置是否為真。
3.7.1 順序肯定環視 (?=exp)
(?=exp) 捕獲exp後面的位置
例如我們需要匹配ing結尾的單詞的前面的內容,可以這樣做:
匹配字串:reading a book
正規表示式:\b\w+(?=ing\b)
匹配結果: read
斷言並不是用於捕獲字串,而是用來宣告一個應該為真的事實,當斷言為真事表示式才會繼續匹配3.7.2 逆序肯定環視 (?<=exp)
(?<=exp) 捕獲exp前面的位置
例如我們需要匹配re開頭的單詞的後面的內容,可以這樣做:
匹配字串:reading a book
正規表示式:(?<=\bre)\w+\b
匹配結果: ading
斷言並不是用於捕獲字串,而是用來宣告一個應該為真的事實,當斷言為真事表示式才會繼續匹配3.7.3 順序否定環視 (?!exp)
(?!exp) 捕獲後面跟的不是exp前面的位置
即此斷言後面的內容不匹配exp的內容
例如我們需要匹配三個數字並且這3位數字後面不能是數字,可以這樣做:
匹配字串:123abc
正規表示式:\d\w{3}(?!\d)
匹配結果: 1233.7.4 逆序否定環視 (?<!exp)
捕獲前面不是exp的位置
即此斷言前面的內容不匹配exp的內容
例如我們需要匹配前面不是小寫字母的3位數字,可以這樣做:
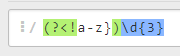
匹配字串:abc123
正規表示式:https://regex101.com/r/CVTzzc/1
匹配結果:1233.8 貪婪/懶惰匹配模式
3.8.1 懶惰限定符
| 限定符 | 描述 |
|---|---|
| *? | 重複任意次,但儘可能少重複 |
| +? | 重複1次或更多次,但儘可能少重複 |
| ?? | 重複0次或1次,但儘可能少重複 |
| {n,m}? | 重複n到m次,但儘可能少重複 |
| {n,}? | 最少重複n次,但儘可能少重複 |
3.8.2 貪婪模式(預設)
在整個表示式能得到匹配的前提下,儘可能的匹配更多字元
例如用a.*?b匹配aabab匹配出的內容為aabab
3.8.3 懶惰模式
在整個表示式能得到匹配的前提下,儘可能的匹配更少字元
例如用a.*?b匹配aabab匹配出的內容為aab、ab,為什麼會匹配出aab的原因是正規表示式有一條優先順序更高的匹配規則:最先開始的匹配擁有最高的優先權
4. 構造正規表示式
4.1 正規表示式的邏輯關係
弄清楚正規表示式中之間的邏輯關係有助於更清晰的理解正規表示式。
| 關係 | 描述 | 示例 |
|---|---|---|
| 與 | 在某個位置,某個元素(字元、字元組、子表示式)必須出現 | abc、(?=exp) |
| 或 | 在某個位置,某個元素可以出現,也可以不出現,或者出現的次數不確定,或者長度不確定 | *、?、{n,m} |
| 非 | 在某個位置,某個元素不出現 | ^、\D、(?!exp) |
4.1.1 與
與是正規表示式中最普遍對關係,如果正規表示式中沒有任何量詞出現,那麼其就是與關係。最能代表與關係的就是abc三個字元。
順/逆序肯定環視也是與關係。
// 同時出現a、b、c三個字元
abc
// 匹配以ing結尾的單詞
(?=ing\d)4.1.2 或
或是正規表示式中最常見的關係,意思是出現的可能出現,可能不出現、次數不確定、出現的長度不確定。
例如?、*、|等
4.1.3 非
最能代表非關係的就是^、(?!exp)、(?<!exp)順逆序否定環視了。
4.2 運算子優先順序
正規表示式的運算子優先順序其含義就像數學中的運算子優先順序一樣。
4.2.1 運算子優先順序圖表
以下表格按照優先順序由高到低排序
| 運算子 | 描述 |
|---|---|
| |轉義符 | |
| ()、(?:)、(?=)、[] | 括號和中括號 |
| *、+、?、{n}、{n,}、{n,m}、 | 限定符 |
| ^、$、\any、any | 定位點和序列 |
| l | 替換(反斜線鍵,makdown表格打不出來,用小寫的L代替) |
4.3 常用模式
4.3.1 多行模式(m)
開啟後將從換行符位置視作一行的結尾
4.3.2 懶惰模式(U)
開啟後預設為懶惰模式
4.3.3 utf-8轉義表達(u)
開啟後可支援使用utf-8字元匹配中文,例如:你等價於你
4.3.4 點號通配模式(S)
開啟後點好.將支援匹配換行符
本作品採用《CC 協議》,轉載必須註明作者和本文連結