1. 網路爬蟲技能總覽圖
如圖2-1所示,我們總結了網路爬蟲的常用功能。
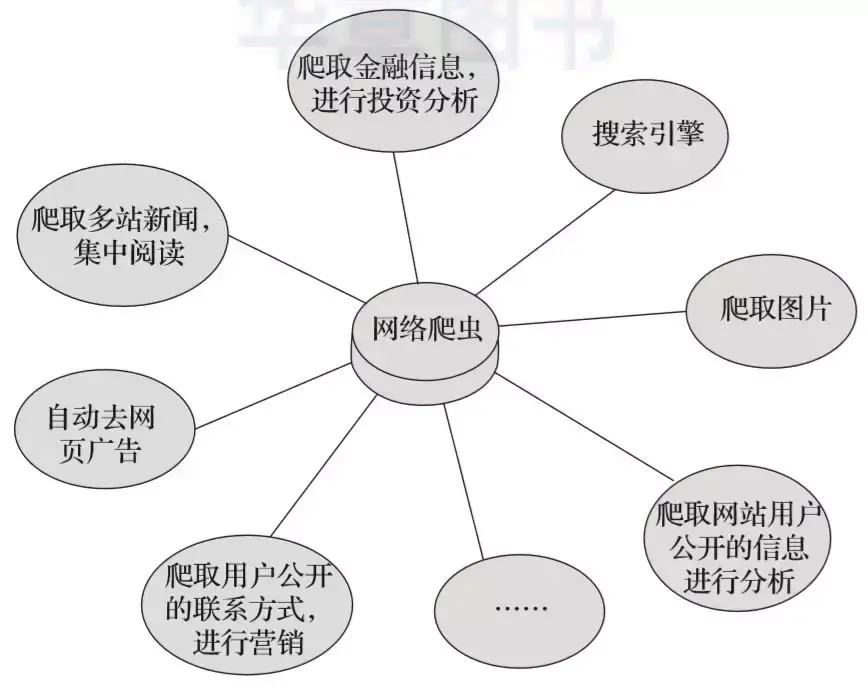
▲圖2-1 網路爬蟲技能示意圖
在圖2-1中可以看到,網路爬蟲可以代替手工做很多事情,比如可以用於做搜尋引擎,也可以爬取網站上面的圖片,比如有些朋友將某些網站上的圖片全部爬取下來,集中進行瀏覽,同時,網路爬蟲也可以用於金融投資領域,比如可以自動爬取一些金融資訊,並進行投資分析等。
有時,我們比較喜歡的新聞網站可能有幾個,每次都要分別開啟這些新聞網站進行瀏覽,比較麻煩。此時可以利用網路爬蟲,將這多個新聞網站中的新聞資訊爬取下來,集中進行閱讀。
有時,我們在瀏覽網頁上的資訊的時候,會發現有很多廣告。此時同樣可以利用爬蟲將對應網頁上的資訊爬取過來,這樣就可以自動的過濾掉這些廣告,方便對資訊的閱讀與使用。
有時,我們需要進行營銷,那麼如何找到目標客戶以及目標客戶的聯絡方式是一個關鍵問題。我們可以手動地在網際網路中尋找,但是這樣的效率會很低。此時,我們利用爬蟲,可以設定對應的規則,自動地從網際網路中採集目標使用者的聯絡方式等資料,供我們進行營銷使用。
有時,我們想對某個網站的使用者資訊進行分析,比如分析該網站的使用者活躍度、發言數、熱門文章等資訊,如果我們不是網站管理員,手工統計將是一個非常龐大的工程。此時,可以利用爬蟲輕鬆將這些資料採集到,以便進行進一步分析,而這一切爬取的操作,都是自動進行的,我們只需要編寫好對應的爬蟲,並設計好對應的規則即可。
除此之外,爬蟲還可以實現很多強大的功能。總之,爬蟲的出現,可以在一定程度上代替手工訪問網頁,從而,原先我們需要人工去訪問網際網路資訊的操作,現在都可以用爬蟲自動化實現,這樣可以更高效率地利用好網際網路中的有效資訊。

2. 搜尋引擎核心
爬蟲與搜尋引擎的關係是密不可分的,既然提到了網路爬蟲,就免不了提到搜尋引擎,在此,我們將對搜尋引擎的核心技術進行一個簡單的講解。
圖2-2所示為搜尋引擎的核心工作流程。首先,搜尋引擎會利用爬蟲模組去爬取網際網路中的網頁,然後將爬取到的網頁儲存在原始資料庫中。爬蟲模組主要包括控制器和爬行器,控制器主要進行爬行的控制,爬行器則負責具體的爬行任務。
然後,會對原始資料庫中的資料進行索引,並儲存到索引資料庫中。
當使用者檢索資訊的時候,會透過使用者互動介面輸入對應的資訊,使用者互動介面相當於搜尋引擎的輸入框,輸入完成之後,由檢索器進行分詞等操作,檢索器會從索引資料庫中獲取資料進行相應的檢索處理。
使用者輸入對應資訊的同時,會將使用者的行為儲存到使用者日誌資料庫中,比如使用者的IP地址、使用者所輸入的關鍵詞等等。隨後,使用者日誌資料庫中的資料會交由日誌分析器進行處理。日誌分析器會根據大量的使用者資料去調整原始資料庫和索引資料庫,改變排名結果或進行其他操作。
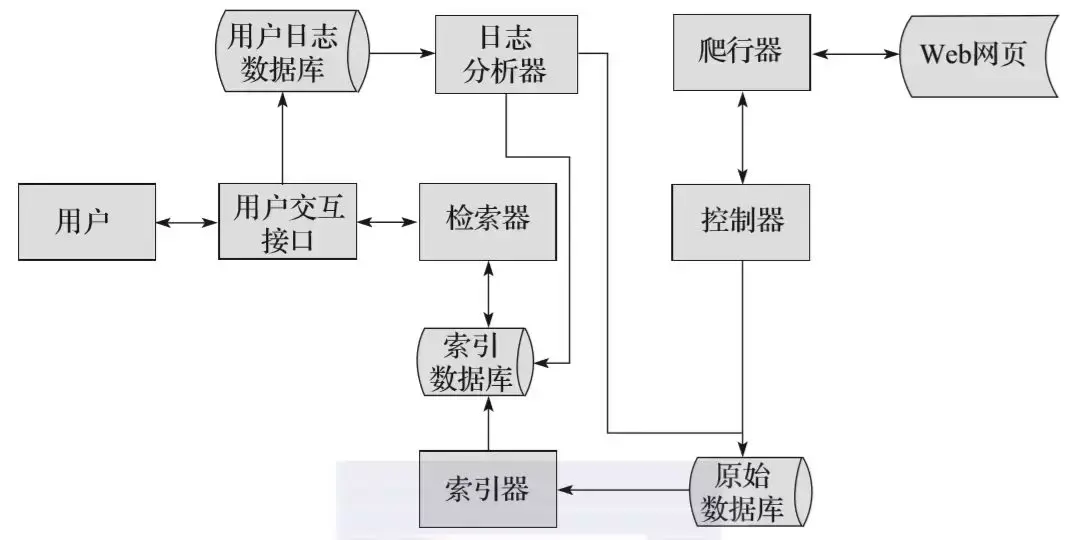
▲圖2-2 搜尋引擎的核心工作流程
以上就是搜尋引擎核心工作流程的簡要概述,可能大家對索引和檢索的概念還不太能區分,在此我為大家詳細講一下。
簡單來說,檢索是一種行為,而索引是一種屬性。比如一家超市,裡面有大量的商品,為了能夠快速地找到這些商品,我們會將這些商品進行分組,比如有日常用品類商品、飲料類商品、服裝類商品等組別,此時,這些商品的組名我們稱之為索引,索引由索引器控制。
如果,有一個使用者想要找到某一個商品,那麼需要在超市的大量商品中尋找,這個過程,我們稱之為檢索。如果有一個好的索引,則可以提高檢索的效率;若沒有索引,則檢索的效率會很低。
比如,一個超市裡面的商品如果沒有進行分類,那麼使用者要在海量的商品中尋找某一種商品,則會比較費力。
3. 使用者爬蟲的那些事兒
使用者爬蟲是網路爬蟲中的一種型別。所謂使用者爬蟲,指的是專門用來爬取網際網路中使用者資料的一種爬蟲。由於網際網路中的使用者資料資訊,相對來說是比較敏感的資料資訊,所以,使用者爬蟲的利用價值也相對較高。
利用使用者爬蟲可以做大量的事情,接下來我們一起來看一下利用使用者爬蟲所做的一些有趣的事情吧。
2015年,有知乎網友對知乎的使用者資料進行了爬取,然後進行對應的資料分析,便得到了知乎上大量的潛在資料,比如:
- 知乎上註冊使用者的男女比例:男生佔例多於60%。
- 知乎上註冊使用者的地區:北京的人口占據比重最大,多於30%。
- 知乎上註冊使用者從事的行業:從事網際網路行業的使用者佔據比重最大,同樣多於30%。
除此之外,只要我們細心發掘,還可以挖掘出更多的潛在資料,而要分析這些資料,則必須要獲取到這些使用者資料,此時,我們可以使用網路爬蟲技術輕鬆爬取到這些有用的使用者資訊。
同樣,在2015年,有網友爬取了3000萬QQ空間的使用者資訊,並同樣從中獲得了大量潛在資料,比如:
- QQ空間使用者發說說的時間規律:晚上22點左右,平均發說說的數量是一天中最多的時候。
- QQ空間使用者的出生月份分佈:1月份和10月份出生的使用者較多。
- QQ空間使用者的年齡階段分佈:出生於1990年到1995年的使用者相對來說較多。
- QQ空間使用者的性別分佈:男生佔比多於50%,女生佔比多於30%,未填性別的佔10%左右。
除了以上兩個例子之外,使用者爬蟲還可以做很多事情,比如爬取淘寶的使用者資訊,可以分析淘寶使用者喜歡什麼商品,從而更有利於我們對商品的定位等。
由此可見,利用使用者爬蟲可以獲得很多有趣的潛在資訊,那麼這些爬蟲難嗎?其實不難,相信你也能寫出這樣的爬蟲。

03 小結
- 網路爬蟲也叫作網路蜘蛛、網路螞蟻、網路機器人等,可以自動地瀏覽網路中的資訊,當然瀏覽資訊的時候需要按照我們制定的規則去瀏覽,這些規則我們將其稱為網路爬蟲演算法。使用Python可以很方便地編寫出爬蟲程式,進行網際網路資訊的自動化檢索。
- 學習爬蟲,可以:①私人訂製一個搜尋引擎,並且可以對搜尋引擎的資料採集工作原理,進行更深層次地理解;②為大資料分析提供更多高質量的資料來源;③更好地研究搜尋引擎最佳化;④解決就業或跳槽的問題。
- 網路爬蟲由控制節點、爬蟲節點、資源庫構成。
- 網路爬蟲按照實現的技術和結構可以分為通用網路爬蟲、聚焦網路爬蟲、增量式網路爬蟲、深層網路爬蟲等型別。在實際的網路爬蟲中,通常是這幾類爬蟲的組合體。
- 聚焦網路爬蟲主要由初始URL集合、URL佇列、頁面爬行模組、頁面分析模組、頁面資料庫、連結過濾模組、內容評價模組、連結評價模組等構成。
- 爬蟲的出現,可以在一定程度上代替手工訪問網頁,所以,原先我們需要人工去訪問網際網路資訊的操作,現在都可以用爬蟲自動化實現,這樣可以更高效率地利用好網際網路中的有效資訊。
- 檢索是一種行為,而索引是一種屬性。如果有一個好的索引,則可以提高檢索的效率,若沒有索引,則檢索的效率會很低。
- 使用者爬蟲是網路爬蟲的其中一種型別。所謂使用者爬蟲,即專門用來爬取網際網路中使用者資料的一種爬蟲。由於網際網路中的使用者資料資訊,相對來說是比較敏感的資料資訊,所以,使用者爬蟲的利用價值也相對較高。
轉自:什麼是網路爬蟲?有什麼用?怎麼爬?終於有人講明白了 - 知乎 (zhihu.com)