linux環境常用的效能監控和協助開發除錯工具
linux有諸多優秀的工具幫助我們分析伺服器各項效能指標和協助開發除錯工作。下面只列舉比較基礎的命令,且一般是整合在linux環境中而不需再次安裝的命令。更多更詳細的命令可以參考 https://github.com/brendangregg/perf-tools
A、CPU程式相關 常用工具列舉下:uptime、ps、top、mpstat、pidstat等
uptime: 檢視系統執行時間,平均負載等。
ps:可檢視某個程式佔用CPU資源百分比;檢視執行緒資訊 ps -eLf
top/htop/atop:顯示的資訊同ps接近,但是top可以瞭解到CPU消耗,可以根據使用者指定的時間來更新顯示;
top -Hp pid(主執行緒id) 可以看到多執行緒程式中所有執行緒的狀態。
mpstat: 可以檢視所有CPU的平均資訊,還能檢視指定CPU的資訊;
pidstat: 對於顯示某個程式的狀態,耗費時間等非常有用。
可通過以下命令檢視缺頁中斷資訊
ps -o majflt,minflt -C <program_name>
ps -o majflt,minflt -p <pid>
其中, majflt 代表 major fault ,指大錯誤, minflt 代表 minor fault ,指小錯誤。這兩個數值表示一個程式自啟動以來所發生的缺頁中斷的次數。其中 majflt 與 minflt 的不同是, majflt 表示需要讀寫磁碟,可能是記憶體對應頁面在磁碟中需要 load 到實體記憶體中,也可能是此時實體記憶體不足,需要淘汰部分物理頁面至磁碟中。
例如,下面是 mysqld 的一個例子。
mysql@ TLOG_590_591:~> ps -o majflt,minflt -C mysqld
MAJFLT MINFLT
144856 15296294
如果程式的核心態 CPU 使用過多,其中一個原因就可能是單位時間的缺頁中斷次數多個,可通過以上命令來檢視。
如果 MAJFLT 過大,很可能是記憶體不足。
如果 MINFLT 過大,很可能是頻繁分配 / 釋放大塊記憶體 (128k) , malloc 使用 mmap 來分配。對於這種情況,可通過 mallopt(M_MMAP_THRESHOLD, <SIZE>) 增大臨界值,或程式實現記憶體池。
ps -o majflt,minflt -C <program_name>
ps -o majflt,minflt -p <pid>
其中, majflt 代表 major fault ,指大錯誤, minflt 代表 minor fault ,指小錯誤。這兩個數值表示一個程式自啟動以來所發生的缺頁中斷的次數。其中 majflt 與 minflt 的不同是, majflt 表示需要讀寫磁碟,可能是記憶體對應頁面在磁碟中需要 load 到實體記憶體中,也可能是此時實體記憶體不足,需要淘汰部分物理頁面至磁碟中。
例如,下面是 mysqld 的一個例子。
mysql@ TLOG_590_591:~> ps -o majflt,minflt -C mysqld
MAJFLT MINFLT
144856 15296294
如果程式的核心態 CPU 使用過多,其中一個原因就可能是單位時間的缺頁中斷次數多個,可通過以上命令來檢視。
如果 MAJFLT 過大,很可能是記憶體不足。
如果 MINFLT 過大,很可能是頻繁分配 / 釋放大塊記憶體 (128k) , malloc 使用 mmap 來分配。對於這種情況,可通過 mallopt(M_MMAP_THRESHOLD, <SIZE>) 增大臨界值,或程式實現記憶體池。
B、記憶體相關 常用工具:free、vmstat
free:可檢視記憶體的總數、已使用、空閒記憶體數,swap使用(當系統沒有足夠實體記憶體來應付所有請求的時候就會用到swap裝置,swap裝置可以是一個檔案,也可以是一個磁碟分割槽。不過要小心的是,使用swap的代價非常大。如果系統沒有實體記憶體可用,就會頻繁swapping,如果swap裝置和程式正要訪問的資料在同一個檔案系統上,那會碰到嚴重的IO問題,最終導致整個系統遲緩,甚至崩潰)情況等,特別提醒,如果swap使用較多,說明伺服器記憶體不怎麼夠用了;
Linux系統記憶體中的cache(free 輸出中的cached)並不是在所有情況下都能被釋放當做空閒空間用的,即使可以釋放cache,也並不是對系統來說沒有成本的。總結一下要點,我們應該記得這樣幾點:
1).當cache作為檔案快取被釋放的時候會引發IO變高,這是cache加快檔案訪問速度所要付出的成本。
2).tmpfs中儲存的檔案會佔用cache空間,除非檔案刪除否則這個cache不會被自動釋放。
3).使用shmget方式申請的共享記憶體會佔用cache空間,除非共享記憶體被ipcrm或者使用shmctl去IPC_RMID,否則相關的cache空間都不會被自動釋放。
4).使用mmap方法申請的MAP_SHARED標誌的記憶體會佔用cache空間,除非程式將這段記憶體munmap,否則相關的cache空間都不會被自動釋放。
5).實際上shmget、mmap的共享記憶體,在核心層都是通過tmpfs實現的,tmpfs實現的儲存用的都是cache。
2).tmpfs中儲存的檔案會佔用cache空間,除非檔案刪除否則這個cache不會被自動釋放。
3).使用shmget方式申請的共享記憶體會佔用cache空間,除非共享記憶體被ipcrm或者使用shmctl去IPC_RMID,否則相關的cache空間都不會被自動釋放。
4).使用mmap方法申請的MAP_SHARED標誌的記憶體會佔用cache空間,除非程式將這段記憶體munmap,否則相關的cache空間都不會被自動釋放。
5).實際上shmget、mmap的共享記憶體,在核心層都是通過tmpfs實現的,tmpfs實現的儲存用的都是cache。
vmstat:可監控虛擬記憶體使用情況、空閒記憶體、緩衝、cache等指標,和free工具類似。伺服器是否發生swap 可以通過 vmstat 1 檢視。
C、磁碟I/O相關 常用工具:iostat、fio、swapon
iostat:可獲取每秒讀寫的資料塊數、所有讀寫塊數等,可對磁碟讀寫效能有個大體瞭解,並可以模擬順序以及隨機讀寫磁碟操作;
fio:另一款強大的io壓力測試工具,這個工具最大的特點是使用簡單,支援的檔案操作非常多, 可以覆蓋到我們能見到的檔案使用方式。
swapon: 顯示swap裝置的使用情況,如果你啟動了swap裝置的話。
badblocks 檢測磁碟是否故障 --> time dd if=/dev/zero of=/test.dbf count=100000 bs=10k oflag=direct 檢測IO 速度 -->
iostat -x -d -k 1 檢視IO讀寫效能, %util 是否過高 --> iotop -o 找出機器上io較高的程式 --> 對cgi頻繁IO寫操作的目錄/usr/local/stat/log/掛載到tmpfs格式的磁碟下,mount -t tmpfs -o size=20m tmpfs /tmpfs; mount -o bind /tmpfs/ /usr/local/stat/log/ 看io 是否能降下來(注:tmpfs格式的磁碟,就是將資料IO操作都在記憶體進行,可以大大提高IO速度,對某些操作頻繁且屬於小檔案的IO操作很有加速效果)--> strace -p 跟蹤io高的程式,看執行什麼操作,或者有什麼錯誤產生。
一個例項:cgi需要通過logagent上報資料,上報的前提是需要讀取logagent的配置檔案:/usr/local/stat/bin/msglog.conf。但是,由於這個這批機器沒有安裝logagent,所以導致了讀取配置檔案失敗。讀取配置檔案失敗之後,cgi頻繁對檔案/usr/local/stat/log/logapi_syserr.bin 以trunc方式重新整理覆蓋寫入。雖然是直接的trunc重新整理,但是由於磁碟扇區一般是512。同時,linux page cache的大小是4KB,在non-direct IO 的情況下,IO都是先寫到linux的page cache裡。所以io操作一般情況最少要修改512位元組(一般是修改4KB)。再乘以cgi程式每秒的讀寫次數(次/秒),所以即使只寫4個位元組,io上看起來幾十上百k是正常的。
D、網路I/O相關 常用工具:netstat、tcpdump、route、iptarf、netperf、nicstat、ping/traceroute
netstat:是一個監控TCP/IP網路的非常有用的工具,它可以顯示路由表、實際的網路連線以及每一個網路介面裝置的狀態資訊;
tcpdump:用於監視TCP/IP連線並直接讀取資料鏈路層的資料包頭。可以指定哪些資料包被監視、哪些控制要顯示格式;
-w xx.pcap 寫入到檔案,可以使用 wireshark 開啟再用 wireshark 語法過濾下。收包發包都在本機的話記得 -i lo
Tcpdump有一個-A引數,可以以ASCII方式列印出包內容,並用web伺服器上的特有url特徵字串如”cgi-bin/”來分割,再把?號後的引數丟棄後排序,即可即時得到伺服器上的物件請求的頻次排序.不需要修改配置重啟http伺服器。 tcpdump -c 10000 -i eth0 port 80 -A 2>&1|awk -F "cgi-bin/" '{print $2}'|awk -F '?' '{print $1}'|sort|uniq -c|sort -rk 1
route:可以為ifconfig命令配置的網路卡設定靜態路由,在本地 IP 路由表中顯示和修改條目網路命令;
iptarf:可用於檢視本機網路的吞吐量,獲得網路傳輸速率;
netperf:可以模擬伺服器和客戶端網路收發,測試網路吞吐量大小;
iperf:類似於netperf,模擬伺服器和客戶端網路收發,測試最大TCP和UDP頻寬效能,能夠提供網路吞吐率資訊, 以及震動、丟包率、最大段和最大傳輸單元大小等統計。
nicstat: 監控網路介面的狀態如吞吐量等,類似iostat的輸出格式。
ping/traceroute:比較常見,檢視網路是否暢通。
網路頻寬使用情況可以自行通過/proc/net/dev檔案進行統計。
E、開發測試相關 常用工具:readelf、hexdump/xxd、od、objdump、nm、telnet/nc
readelf:以可讀方式展示elf檔案格式,包括(目標檔案/可執行檔案/共享庫)
hexdump/xxd:將檔案內容以16進位制列印
od:可選進位制列印檔案內容
objdump:將機器指令反彙編
nm:列出目標檔案的symbols
strings:即列印檔案中的可列印字串(print the strings of printable characters in files),常用來在二進位制檔案中查詢字串,與grep配合使用
telnet/nc :測試網路連線客戶端
wget/curl:模擬http請求客戶端,支援代理、cookie等。wget 如果將link用引號括起來,如 wget 'http://baidu.com' -O tmp.down 則url 不能是 http:\/\/baidu.com
curl 正常需要把 [] {} 等用 \ 轉義,否則會出現 [globbing] illegal character in range specification at pos xx 的錯誤,也可以設定引數
-g/--globoff
This option switches off the "URL globbing parser". When you set this option, you can
specify URLs that contain the letters {}[] without having them being interpreted by curl
itself. Note that these letters are not normal legal URL contents but they should be
encoded according to the URI standard.
specify URLs that contain the letters {}[] without having them being interpreted by curl
itself. Note that these letters are not normal legal URL contents but they should be
encoded according to the URI standard.
-k, --insecure Allow connections to SSL sites without certs (H)
valgrind/AddressSanitizer:記憶體洩露檢測,會降低程式效能,asan 比 valg 表現要好。
F、跟蹤除錯相關 常用工具:strace、ltrace、dtrace/ftrace、blktrace
strace: 跟蹤執行程式的系統呼叫耗費時間、出錯資訊、引數傳遞等。
strace -tt -T -p pid(可以是執行緒的pid)
pstack:其實是 gstack 的軟連線,而gstack本身是基於gdb封裝的shell指令碼,重點是輸入thread apply all bt 這個互動命令.
該命令要求輸出所有的執行緒堆疊資訊.對GDB輸出的結果, 通過管道並藉助sed命令進行了替換和過濾。
ltrace:跟蹤執行程式的函式庫呼叫耗費時間、出錯資訊、引數傳遞等。
dtrace/ftrace:上述兩個工具的綜合。dtrace is a tracing tool whichruns at the system level - this means you can trace all processes, into and out of the kernel, rather than selecting a single process to trace.
blktrace:Block I/O event tracer
pt-pmp :is a poor man’s profiler, inspired by http://poormansprofiler.org. It can create and summarize full stack traces of processes on Linux. Summaries of stack traces can be an invaluable tool for diagnosing what a process is waiting for.
pstack {pid of mysqld} > pid.info pt-pmp pid.info
F、效能評測相關常用工具:perf top、perf record、gprof
perf record:可以用來了解程式各函式的實時執行情況。它採用定期取樣的方式,統計各函式出現的比例。排名較高的函式,要麼是耗時長被多次統計到,要麼是頻繁呼叫被多次統計到,無論哪種情況,這些函式都是消耗系統資源的魔頭,是優化的好物件。
perf top:主要用於實時分析各個函式在某個效能事件上的熱度,能夠快速的定位熱點函式,包括應用程式函式、
模組函式與核心函式,甚至能夠定位到熱點指令。預設的效能事件為cpu cycles。perl top -p pid(可以是執行緒的pid)
模組函式與核心函式,甚至能夠定位到熱點指令。預設的效能事件為cpu cycles。perl top -p pid(可以是執行緒的pid)
gprof:可以用來統計程式各函式的真實耗時情況,通過它可以精確地瞭解到各函式的耗時,這樣哪些函式需要優化,也就不言而喻了。
H、大而全的綜合工具:sar/collectl、dstat、檢視/proc/pid/xxx 各種資訊(如 /proc/pid/fd 檢視本程式開啟的檔案描述符,
lsof -p pid)、sysctl、/sys 各種資訊
CPU不行的表現有兩種:1)CPU被耗精光;2)CPU富餘idle,但程式過載了。第一種,CPU都被吃光了,計算資源都沒了,程式效能也就不可能更進一步了。第二種,也是常見的一種,CPU沒被吃光,但程式卻過載了,這種情況主要是因為程式被掛起在等待某些事件,造成等待的原因有兩種:1)同步阻塞,2)記憶體發生swap(記憶體不行了)。
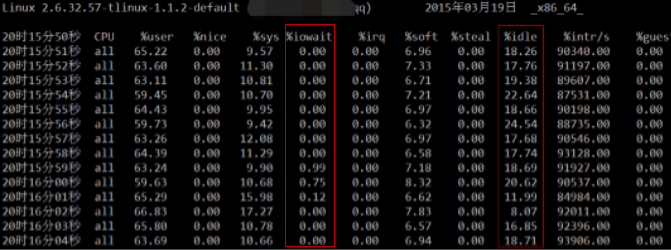
下面的這個例子 sar -u(如下圖),就屬於第二種情況:CPU idle富餘,但程式過載了。由圖可知,idle富餘的同時,基本無iowait,這說明程式自我阻塞不在IO方面(也從側面證明了不是swap引起的阻塞),那麼引起阻塞的最大嫌疑就是互斥鎖了。
下面的這個例子 sar -u(如下圖),就屬於第二種情況:CPU idle富餘,但程式過載了。由圖可知,idle富餘的同時,基本無iowait,這說明程式自我阻塞不在IO方面(也從側面證明了不是swap引起的阻塞),那麼引起阻塞的最大嫌疑就是互斥鎖了。
參考:
https://github.com/brendangregg/perf-tools
http://crtags.blogspot.com/2012/04/dtrace-ftrace-ltrace-strace-so-many-to.html
https://danielmiessler.com/study/tcpdump/
http://ufsdump.org/papers/oscon2009-linux-monitoring.pdf
相關文章
- 前端開發環境(開發,除錯,測試工具)前端開發環境除錯
- linux後臺開發常用除錯工具Linux除錯
- FLEX - 開發環境:除錯Flex開發環境除錯
- Linux下搭建FFmpeg開發除錯環境Linux除錯
- WEB輔助開發、除錯、效能檢測、調優工具集Web除錯
- Linux 效能監控工具Linux
- Node.js環境效能監控Node.js
- [zt] Linux中常用的監控CPU整體效能工具Linux
- PHP開發除錯環境建立PHP除錯
- MAC環境下PHP開發除錯環境搭建MacPHP除錯
- Java生產環境效能監控與調優—基於JDK命令列工具的監控JavaJDK命令列
- 微信開發的本地除錯環境搭建除錯
- linux效能監控工具——NAGIOS和OVOLinuxiOS
- step 1 :搭建開發除錯環境除錯
- Flutter開發環境搭建和除錯Flutter開發環境除錯
- 幾個常用的linux效能監控命令Linux
- 效能監控和分析工具--nmon
- Linux 常用系統效能監控命令Linux
- 網頁開發的6種線上除錯環境網頁除錯
- UNIX和linux系統效能監控工具oswatcherLinux
- IE, FF, Safari前端開發常用除錯工具前端除錯
- 【譯】生產環境下的Node.js——開源監控工具Node.js
- REDHAT環境下使用SYSSTAT監控系統效能Redhat
- AIX常用的效能監控命令AI
- 可提高Java開發效能的5款除錯工具Java除錯
- 監控 Linux 效能的 18 個命令列工具Linux命令列
- 監控Linux效能的18個命令列工具Linux命令列
- 自己開發的MYMON工具監控MYSQL執行狀態幫助文件MySql
- 效能監控工具YourKit
- JVM 效能監控工具JVM
- CentOS效能監控工具CentOS
- linux常用系統監控工具之vmstatLinux
- 常用的 Python 除錯工具,Python開發必讀Python除錯
- Linux下監控流量常用的三大工具!Linux
- 【合集】Linux運維常用的服務監控工具Linux運維
- Linux開發環境必備的工具!Linux學習Linux開發環境
- Linux的IO效能監控工具iostat詳解LinuxiOS
- 10多個 Linux 系統管理員必備的監控工具、常用的網站監控工具Linux網站