scala筆記
scala中object檔案編譯後對應java中的靜態成員,非靜態成員放在class檔案中
1、變數
scala資料型別
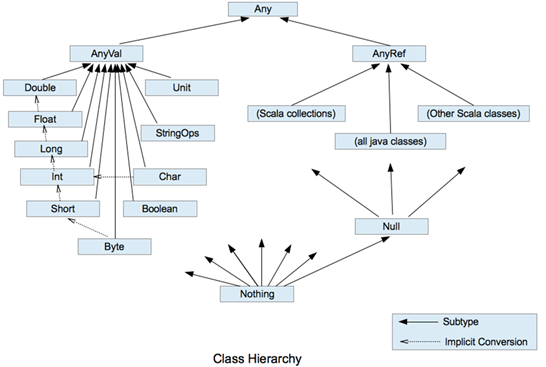
char的值
var c1:Char = 'a' + 1 //型別不匹配
var c2:Char = 97 + 1 //型別不匹配
var c3:Char = 98 //對
var c4:Char = 999 //超範圍
//分析:
//1.當把一個計算的結果複製給一個變數,編譯器會進行型別轉換和判斷
//2.當把一個字面量賦給變數,編譯器只會進行範圍的判斷
//3.(byte,short) 和 char之間不會自動轉換
val c5:Byte = 5
val c6 = c4+c5 //c6為int
//4.byte short char 計算時先轉換為int
2、方法
宣告格式
def 函式名(引數1:引數型別,...): 返回值型別 = {
方法體
}
-
簡寫:
-
引數列表為空,若定義時省略
(),則呼叫時也必須省略,否則可省可不省def fo(): Unit = { println("fo...")} fo() //fo... fo //fo... ======================= def fo: Unit = { println("fo...")} fo() //error fo //fo... -
除以下3之情況外,
: 返回值型別可省,函式返回值型別有編譯器自動推斷def fo(a: Int) = { println(s"a= $a")} -
寫
return或使用遞迴函式時,返回值型別必須手動宣告,編譯器不會自動推斷 -
如果省略
=則始終返回Unit,不建議省略= -
方法體只有一行,
{}可以省
-
-
方法傳入的形參其屬性為val,不可重新賦值
-
方法可以有多個引數列表(柯里化),函式不可以
3、物件導向
主構造
class Dog(var name: String, val age: Int, sex: String) {
...
}
屬性變數宣告可以為var、val或無,scala編譯後屬性均以private修飾
為var時屬性以private修飾,scala編譯後生成public的name()和name_$eq(String name)方法(即getter和setter);
為val時屬性以private final修飾,scala編譯後僅生成public的name()方法;
無時,若主構造內部使用了該屬性,則屬性以private final修飾同時生成private的name()和name_$eq(String name)方法;否則連屬性都不生成。
抽象類
scala的抽象類關鍵字依然為abstract,抽象類中依然可以有屬性、程式碼塊、抽象和非抽象方法,但scala中 abstract不可修飾方法
trait(特質)
-
特質可類比為java中的介面,一個類可
with混入(實現)多個特質,但其特點更像scala中的抽象類 -
scala中無
implements關鍵字,實現使用extends和with關鍵字,實現多個特質時第一個用extends,其後均用with -
類的構造順序:父類構造 --> 特質構造(先父特質後子特質)從左到右 --> 子類構造
繼承
-
trait可以繼承trait
-
trait可以繼承class,如果trait A繼承了class B,那麼混入A的class C必須是B的子類
-
如果trait A指定了自身型別B,那麼混入A的class C必須是B的子類
trait logger{ this:Exception => //指定自身型別為Exception def log()={ println(getMessage) } } class console extends Exception with logger{ //想要with logger則必須extends Exception }
覆寫
-
java覆寫父類欄位,父類欄位依然隱藏的存在,scala中覆寫父類欄位則該欄位真的被覆蓋,案例
-
val可以覆寫val和沒有()的def,var只能覆寫abstract var
隱式函式隱式類
-
增加現有函式的功能,如引數為A型別,返回值為B型別的函式
-
scala會自己去尋找符合輸入輸出的隱式函式,而不關心函式的內容,所以一個作用域裡的隱式函式的輸入輸出不能完全相同
implicit def douhle2Int(num:Double): Int = num.toInt val a: Int = 10.1 println(a) //10 -
隱式類是隱式函式的升級版,隱式類只能是內部類而且主構造只能接受一個引數
-
隱式引數和隱式值:
- 一個函式裡只可以有一個隱式引數,且呼叫該函式時如果不傳入該引數值,則該隱式引數所在的小括號必須捨去
- 隱式值應定義在使用隱式值之前
4、元組(Tuple)
元組的主要用處:使方法返回多個值(型別可以不一樣)
//建立元組的兩種方法
val a1: (Int, String) = Tuple2(1, "hello") //最多為Tuple22
val a2: (Int, String) = (1,"hello")
訪問元組元素
val b = a1._2 //"hello"
Tuple2也被稱為對偶
5、陣列(Array)
-
陣列可分為定長陣列(Array)和變長陣列(ArrayBuffer,嚴格來講屬於collection)
-
建立Array物件
val a1: Array[Int] = new Array[Int](10) val a2: Array[Nothing] = new Array(10) //若不指定泛型則為Nothing val a3: Array[Array[Int]] = Array.ofDim[Int](3, 2) //生成2*3的二維陣列 for(i <- 0 until a3.length ; j <- 0 until a3(i).length) a3(i)(j) = j for(i <- 0 until a3.length) println(a3(i).mkString(",")) //呼叫a3(i)每一個元素的toString,元素間以","間隔後拼接 -
陣列的常用操作方法
:的說明//:影響符號的結合方向,貼近:的是呼叫該方法的物件 //*符號的結合方向: + - * /等為左邊物件呼叫的方法 //!a 中!則為右邊物件a呼叫的方法-
定長與變長共有
++ //連線兩個陣列 ++: //連線兩個陣列 :+ //一個陣列連線一個元素,eg: arr1 :+ 10 +: //一個陣列連線一個元素,eg: 10 :+ arr1 /: //左摺疊 :\ //右摺疊 head //第一個元素 tail //除第一個元素外的其他元素組成的陣列 last //最後一個元素 -
變長獨有
++= //將右陣列的所有元素新增到左陣列中 ++=: //將左...右... += //新增右元素至左陣列中 +=: //..左...右... - //返回左陣列去掉第一個右元素後的 新 陣列 -- //返回左陣列去掉右陣列後的 新 陣列 -= //左陣列去掉第一個右元素 --= //左陣列去掉右陣列 -
經驗小總結:
- 沒有
=參與的方法不改變原陣列,只返回新陣列 :基本只改變方法的結合方向,不改變其作用
- 沒有
-
6、容器(collection)
分為可變(mutable)容器和不可變(immutable)容器,對應包含所有陣列的操作方法,對不可變容器進行增刪操作將返回新的物件
-
總覽
-
說明
-
scala.collection包中的高階抽象類或triat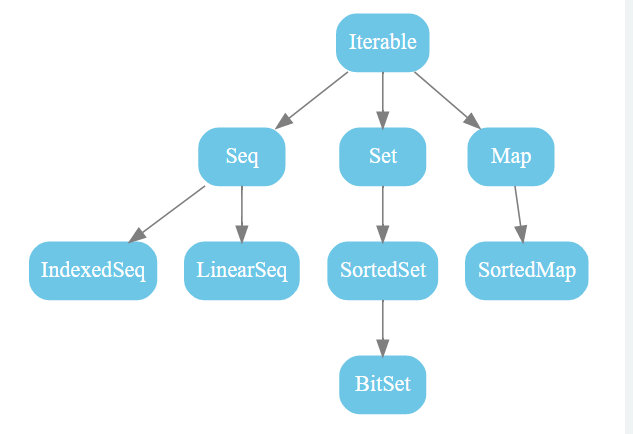
-
scala.collection.immutable包中的父子樹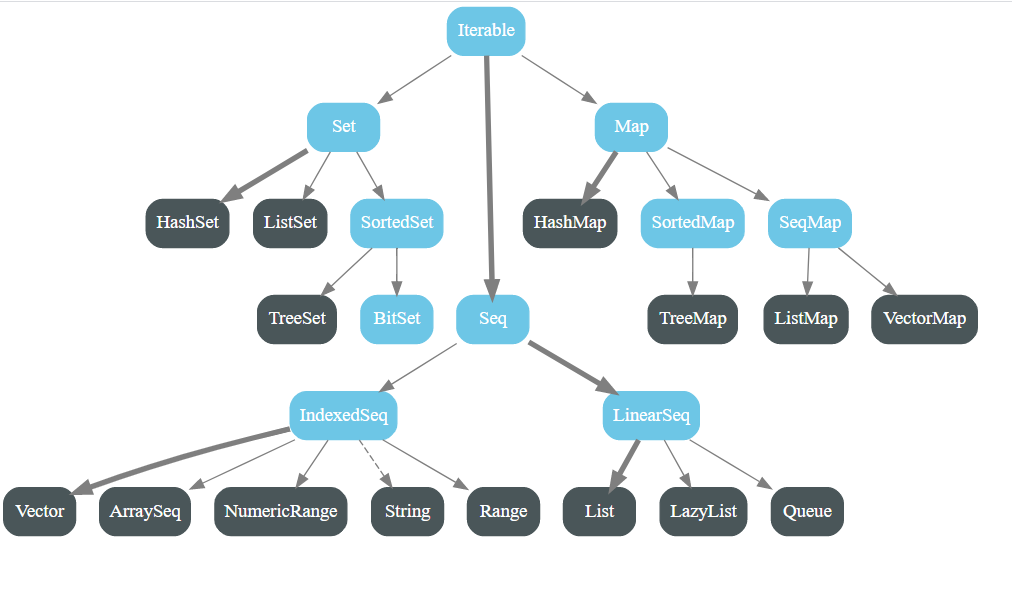
-
scala.collection.mutable包中的父子樹
-
建立容器物件
scala中不指明的情況時建立的Set、Map、Seq都是Immutable包下,為以示區分建立可變容器物件的推薦方式(set為例)
import scala.collection.mutable
import scala.collection.immutable
object SetDemo {
def main(args: Array[String]): Unit = {
val set1: mutable.Set[Int] = mutable.Set(20, 50) //加上包名方便直接區分
val set2: Set[Int] = immutable.Set(20, 40)
println(set1) //Set(20, 50)
println(set2) //Set(20, 40)
}
}
List和ListBuffer
java中的List是介面,scala中List可以直接存放資料,預設情況下List不可變,ListBuffer為可變,ListBuffer比List少了以下的操作方法
- List的操作方法
//::
val list1 = List(10, 20, 30)
val list2 = List(100, 200)
println(list1 :: list2)//List(List(10, 20, 30), 100, 200)
println(10 :: list1)//List(10, 10, 20, 30)
println(list1)//List(10, 20, 30)
println(list2)//List(100, 200)
//即 :: 自右向左運算 為右邊list物件呼叫,將左list或元素當成第一個元素放到右list的頭部形成的新lsit返回
//:::
//自右向左運算 返回兩個list拼接後的新list
println(Nil) //List(),Nil即為空list
// :: 、 ::: 不能與 +: 在同一式子中
list常用方法
集合(Set)
Set無序不重複,但immutable.Set和mutable.Set的內部排序機制並不相同
set常用方法
對映(Map)
Map儲存k-v對,也可以認為儲存的是對偶,Map同樣是無序不重複(key)
-
建立Map物件
val map1: Map[Int, String] = Map(1 -> "hello", 2 -> "scala") val map2: mutable.Map[Int, String] = mutable.Map((1, "hello"), (2, "world")) -
Map獲取和更新Value的方法
println(map1(1)) //hello println(map1(3)) //key not found: 3 println(map1.get(1)) //Some(hello) println(map1.get(3)) //None println(map1.getOrElse(1, "defaultValue")) //hello println(map1.getOrElse(3, "defaultValue")) //defaultValue println(map2.getOrElseUpdate(3, "scalaWorld")) //scalaWorld println(map2) //Map(2 -> world, 1 -> hello, 3 -> scalaWorld)-
Scala Option(選項)型別用來表示一個值是可選的(有值或無值)。
Option[T] 是一個型別為 T 的可選值的容器: 如果值存在, Option[T] 就是一個 Some[T] ,如果不存在, Option[T] 就是物件 None 。
-
map常用方法
其他
佇列(queue)
FIFO 先進先出
val queue: mutable.Queue[Int] = mutable.Queue(20, 50)
queue.enqueue(30,70) //入隊操作
println(queue) //Queue(20, 50, 30, 70)
queue.dequeue() //第一個元素出隊
println(queue) //Queue(50, 30, 70)
immutable.Queue很少使用,不變佇列幾乎沒有價值,而且似乎無法使用enquequ()、dequeue()
棧(Stack)
FILO 先進後出
val stack: mutable.Stack[Int] = mutable.Stack(40, 50, 70)
println(stack.pop()) //出棧 40
println(stack.push(90)) //入棧 Stack(90, 50, 70)
println(stack.push(1, 3)) //Stack(3, 1, 90, 50, 70)
並行容器
普通容器物件呼叫par方法可得到並行容器
//Demo
val parList: ParSeq[Int] = List(20, 30, 4).par
val parSet: ParSet[Int] = Set(20, 30, 4).par
val parArr: ParArray[Int] = Array(20, 30, 4).par
val parMap: ParMap[Int, String] = Map(1 -> "hello").par
parList.foreach(x => println(x +": "+ Thread.currentThread().getName))
//30: ForkJoinPool-1-worker-9
//20: ForkJoinPool-1-worker-13
//4: ForkJoinPool-1-worker-3
7、高階運算元(List、Set、Map可用)
演示用集合如下:
val list: List[Int] = List(2, 3, 5, 4, 1, 6)
val set: mutable.Set[Int] = mutable.Set(2, 3, 5, 4, 1, 6)
val map: immutable.Map[String, Int] = immutable.Map("hello" -> 1, "scala" -> 2, "why" -> 5, "you" -> 3, "soHard" -> 2)
foreach(遍歷)
final def foreach(f: (A) ⇒ Unit): Unit
//f:為無返回值的函式
foreach無返回值,它將呼叫方法的collection中每一個元素依次交給f函式處理
filter(一進至多一出)
def filter(p: (A) ⇒ Boolean): List[A] //以List舉例
filter返回值與呼叫方法的容器及容器泛型型別完全一致。容器中的每一個元素都被交給p函式處理,返回ture的才會被保留。
map(一進一出)
final def map[B](f: (A) ⇒ B): List[B] //通過遍歷將容器中的元素轉換為任意型別
map返回值與呼叫方法的collection型別、元素數量都一致,但內部元素型別可以不同,其主要也用於型別轉換,如:
val set: Set[Int] = Set(1, 2, 3)
println(set.map(x => List(x, x * x, x * x * x)))
//Set(List(1, 1, 1), List(2, 4, 8), List(3, 9, 27))
flatten
將容器中的容器元素拍平,甚至會將String拍成Char。返回值型別與呼叫方法的容器型別一致
val xs = List(
Set(1, 2, 3),
Set(1, 2, 3)
).flatten
// xs == List(1, 2, 3, 1, 2, 3)
val ys = Set(
List(1, 2, 3),
List(3, 2, 1)
).flatten
// ys == Set(1, 2, 3)
flatMap
等價於先map再flatten
val list3 = List(1, 2, 3)
println(list3.flatMap(x => List(x, x * x, x * x * x)))
//List(1, 1, 1, 2, 4, 8, 3, 9, 27)
groupBy
def groupBy[K](f: (A) ⇒ K): Map[K, List[A]]
返回值型別為 Map[K, List[A]] ,以f函式的返回值K為分組依據,K為key、返回值K相同的元素組成的List[A]為value,作為對偶放入返回的Map中
val list1 = List(3, 6, 5, 4, 13)
val list2 = List(3, 5, 13)
println(list1.groupBy(x => x % 2))
//Map(1 -> List(3, 5, 13), 0 -> List(6, 4))
println(list2.groupBy(x => x % 2))
//Map(1 -> List(3, 5, 13))
reduce(多進一出)
def reduce[A1 >: A](op: (A1, A1) ⇒ A1): A1
聚合,將呼叫reduce方法容器的頭兩個元素交給op函式處理,得到的返回值再和第三個元素一起被交給op函式,如此迴圈至最後一個元素,最終reduce的返回值必然與容器中元素的型別一致
foldLeft \ foldRight
def foldLeft[B](z: B)(op: (B, A) ⇒ B): B
聚合,方法的第一個引數列表只有一個引數z,z的型別為B,第二個引數列表為op函式,op函式接收兩個引數(型別為B和容器元素型別A)。op對z和容器的第一個元素進行處理,返回型別為B的返回值,返回值再和容器的下一個元素一起被交給op函式,如此迴圈至最後一個元素,最終foldLeft的返回值必然為B型別。
foldRight方法與foldLeft 只在作用方向上不同,fold方法則較少使用
reduce和foldLeft方法的比較:
//舉例:對於List[int],reduce後結果為int,而使用foldLeft若第一個引數列表給set[String]最終即可得到set[String]
val list = List(3, 6, 5, 4, 13)
println(list.reduce((x, y) => x + y))
//31
println(list.foldLeft(Set("hello"))((x, y) => x + y.toString))
//Set(4, 13, 5, 6, hello, 3)
scanLeft \ scanRight
scanLeft \ scanRight 和 foldLeft \ foldRight 機制相同,只不過scanLeft會將每次的結果都進行輸出
val list = List(3, 6)
println(list.scanLeft(Set("hello"))((x, y) => x + y.toString))
//List(Set(hello), Set(hello, 3), Set(hello, 3, 6)...
排序
物件的可比性
java中要想實現類的不同物件間比較主要有兩種,一種是類實現Comparable介面 覆寫compareTo(),另一種是提供類的比較器Comparator。
//假如compareTo方法返回值為x,如果想要升序則This > Other時,x > 0
在scala中同樣可以使用這兩種方法。同時對於自定義型別A,scala中還可以通過以下方法實現比較:
-
混入Ordered[A]特質,覆寫其中的compare()方法,使物件具有可比性
trait Ordered[A] extends scala.Any with java.lang.Comparable[A] { def compare(that : A) : scala.Int def <(that : A) : scala.Boolean = { /* compiled code */ } def >(that : A) : scala.Boolean = { /* compiled code */ } def <=(that : A) : scala.Boolean = { /* compiled code */ } def >=(that : A) : scala.Boolean = { /* compiled code */ } def compareTo(that : A) : scala.Int = { /* compiled code */ } } -
提供Ordering[A]的實現類作為比較器,對兩個物件進行比較
trait Ordering[A] extends java.lang.Object with java.util.Comparator[A] ...{ def compare(x : T, y : T) : scala.Int ... //Ordering已經提供了AnyVal、Option和Tuple2~Tuple9的隱式物件 } -
總結:
Ordered和Ordering分別混入了Comparable和Comparator,他們相當於增強版,在原先的基礎上提供了<、>等預設方法。
Seq的排序運算元
scala的Seq類有三個運算元,幫助實現Seq類內元素的排序
-
sorted()
def sorted[B >: A](implicit ord: math.Ordering[B]): List[A]sorted排序是穩定的,預設為升序,可使用sorted.reverse降序,使用sorted需要Seq中的元素具有前述的可比性,常見的用法之一是在呼叫方法前定義隱式值ord://Demo val user2s: List[User2] = List(new User2("bob2", 17), new User2("jack2", 15)) implicit val odr:Ordering[User2] = new Ordering[User2]{ override def compare(x: User2, y: User2): Int = x.age - y.age } println(user2s.sorted) -
sortBy()
def sortBy[B](f: (A) ⇒ B)(implicit ord: math.Ordering[B]): List[A]呼叫sortBy方法時:第一個引數列表是函式f(通常是匿名函式),f接收Seq元素型別A返回Ordering實現型別B;第二個引數列表是隱式引數,是Ordering的實現類。
val words = "The quick brown fox jumped over the lazy dog".split(" ") // this works because scala.Ordering will implicitly provide an Ordering[Tuple2[Int, Char]] //按照長度升序,首字母降序排序 words.sortBy(x => (x.length, x.head))(Ordering.Tuple2(Ordering.Int.reverse,Ordering.Char)) res0: Array[String] = Array(jumped, brown, quick, lazy, over, The, dog, fox, the) -
sortWith()
def sortWith(lt: (A, A) ⇒ Boolean): List[A]
sortWith排序是穩定的,呼叫sortWith方法的時候僅需要傳入函式lt,lt依次接收Seq裡相鄰的兩元素,返回Boolean值。如果需要升序排序,則當前一個元素小於後一個元素時返回truescala> List("Steve", "Tom", "John", "Bob").sortWith(_.compareTo(_) < 0) res2: List[String] = List(Bob, John, Steve, Tom)
8、模式匹配
是對java中的switch的升級, 功能遠遠大於switch
-
模式匹配的時候, 如果匹配不到, 則會拋異常
-
匹配所有
case aa => // 可以使用匹配到值 case _ => // 用來兜底,匹配到的值用不了 本質一樣(所有)!!! -
關於匹配常量還是變數
case Baaaa => // Baaaa是常量 case baaaa => // baaaa新定義的變數
注意:
case後面首字母是大寫,表示常量, 首字母是小寫表示變數
-
任何的語法結構都有值
模式匹配也有值. 值就是匹配成功的那個
case的最後一行程式碼的值 -
匹配型別(簡單)
val a: Any = 99 a match { // 只匹配[100,110]的整數. 守衛 case a: Int if a >= 100 && a <= 110 => println(a to 110) //指定b的自身型別為boolean case b: Boolean => println("是一個boolean: " + b) }//所有都匹配不上,報錯-
匹配型別(複雜)
在模式匹配中無法對除陣列以外的其他容器的泛型做限制,案例
其原因是:scala的陣列本質仍是java的陣列,只是寫法有變化,Array[Int]()、Array[Double]()本質仍是new int[0]、new double[0],本來就不是同一型別,故而可以限制;而其他容器由於泛型擦除(泛型出現的目的, 是為了在寫程式碼的時候型別更安全,但是泛型只是出現在編譯時, 編譯成位元組碼之後, 泛型就不存在!),在執行時List[Double]()和List[Double]()並不能被識別出不同。
-
匹配內容
本質是匹配物件!!!
-
匹配陣列的內容
-
匹配List的內容
-
匹配元組的內容
-
val arr = Array(10, 20, 100, 200, 300) arr match { /*case Array(a, b, c, d) => println(a) println(d)*/ /*case Array(10, a, b, c) => println(a)*/ /*case Array(10, a, _, 40) if a > 15 => println(a)*/ /*case Array(a, b, _*) => println(a) println(b)*/ case Array(a, b, rest@_*) => println(rest) }- 匹配物件
解釋清楚前面的內容匹配的原理
物件匹配的本質:
1. 是去呼叫這個物件的 unapply 方法, 把需要匹配的值傳給這個方法
2. unapply方法, 返回值必須是 Option, 如果返回的Some,則表示匹配成功, 然後把
Some中封裝的值賦值 case語句中
如果返回的是None, 表示匹配失敗, 繼續下一個case語句 -
9、 樣例類
物件匹配, 必須要手動在伴生物件中去實現一個def unapply方法.
樣例他主要就是為模式匹配而生.
case class
其實就是scala, 替我們實現很多方法, 這些方法大部分可以直接使用.
apply
unapply
hashCode
equals
...
case class User(age: Int, name:String)
1. 寫在主構造中的屬性預設都是val. 如果有需要可以改成var的
2. 預設實現了很多方法
apply
unapply
hashCode
equals
3. 使用場景
- 模式匹配
- 替代 java bean
- 作為程式間通訊的通訊協議
10、偏函式
val list = List(10, "a", false, 20, 30)
// List(20, 40, 60)
// filter + map
val f: PartialFunction[Any, Double] = new PartialFunction[Any, Double] {
// 如果這個函式返回true, 則會對這個x進行處理(交給apply進行處理)
override def isDefinedAt(x: Any): Boolean = x match {
case _: Int => true
case _ => false
}
override def apply(v1: Any): Double = v1 match {
case a:Int => a * 2
}
}
val list2 = list.collect(f) // 等價於了 filter + map
println(list2)
定義方式2:
用一對大括號括起來的case語句, 就是一個偏函式
{ case ...=>}
11、異常處理
java中:
都是繼承自Exception
特點: 程式碼會變的比較健壯
-
執行時異常
只有在執行的時候才有可能產生, 在原始碼中,可以處理, 也可以不處理
-
編譯時異常(受檢異常)
在原始碼的時候,必須處理.
IO, 網路
在scala中, 所有的異常, 都可以處理, 也可以不處理.
用法:
-
處理
-
使用
try catch finally -
丟擲異常型別(
java: throwsscala: 註解)@throws(classOf[RuntimeException]) @throws(classOf[IllegalArgumentException])
-
-
主動丟擲
throw new IllegalArgumentExceptionscalac: 編譯scala原始碼
scala: 進行執行
scala 原始碼.scala
當指令碼用來(內部會先編譯, 再執行)
12、泛型
| 符號 | 作用 |
|---|---|
| [T <: UpperBound] | 上界 |
| [T >: LowerBound] | 下界 |
| [T <% ViewBound] | 視界 |
| [T : ContextBound] | 上下文界 |
| [+T] | 協變 |
| [-T] | 逆變 |
表格內容摘自:https://blog.csdn.net/datadev_sh/article/details/79854273
泛型的上限界定和下限界定
[T <: Ordered[T]] // 上限
[T >: Pet] // 下限. 推導的時候,不能和上限一樣
三變
class MyList[T]
class Father
class Son extends Father
不變
MyList[Son] 和 MyList[Father] 沒有任何的"父子關係"
錯誤: val fs: MyList[Father] = new MyList[Son]
預設情況下, 所有泛型都是不變的!!!
class MyList[T]
協變
val fs: MyList[Father] = new MyList[Son] // 正確的
class MyList[+T]
逆變
val fs: MyList[Son] = new MyList[Father] // 正確的
class MyList[-T]
scala中list和map的value已經使用了協變
上下文界定(泛型)
def max[T](x: T,y:T)(implicit ord: Ordering[T]) = {
if(ord.gt(x, y)) x
else y
}
[T:Ordering]
這就是泛型上下文.
表示: 一定有一個隱式值 Ordering[T] 型別的隱式值
上下文泛型的本質其實是對隱式引數和隱式值的封裝!!!
檢視界定
檢視界定是物件隱式轉換函式的封裝!!!
def max[T <% Ordered[T]](x: T, y: T) :T = {
if(x > y) x
else y
}
/*def max[T](x: T, y: T)(implicit f: T => Ordered[T]) :T = {
if(x > y) x
else y
}*/
/*
1. 中置運算子
1 + 2
2. 一元運算子
後置
1 toString
前置
+5
-5
!false 取反
~2 按位取反
3. apply方法
任何物件都可以 呼叫
物件(...) // 物件.apply(...)
伴生物件
普通的物件
函式物件
4. update方法
user(0) = 100 // user.update(0, 100)
N-1、scala符號的使用
-
<-- for迴圈中賦值
-
->- map中key-value分隔符
-
=>- 分割匿名函式及函式體
- 導包時對類重新命名
-
--
1. 導包, 萬用字元 _ import java.util.Math._ 2. 遮蔽類 import java.util.{HashMap => _, _} 3. 給可變引數傳值的時候, 展開 foo(arr:_*) 4. 元組元素訪問 t._1 5. 函式引數的佔位符 def compter(f:(Int) => Int) = f(3) println(computer((a: Int) => 2 * a)) //6 println(computer(2*_)) //與上一行等價 6. 方法轉函式 val f = foo _ 7. 給屬性設定預設值 class A{ var a: Int = _ // 給a賦值預設的0 } 8. 模式匹配的萬用字元 case _ => // 匹配所有 9. 模式匹配集合 Array(a, b, rest@_*) 10. 部分應用函式 math.pow(_, 2) 11. 在定義識別符號的時候, 把字元和運算子隔開 val a_+ = 10 a+ // 錯誤 12. List[_] 泛型萬用字元 13. 自身型別 _: Exception =>
-
-
括號
scala原生支援xml, 標籤都是用尖括號<user>所以- 泛型使用
[] - 訪問陣列或list的元素使用
()
- 泛型使用
N、較長的程式碼案例
類的構造順序
trait A {
println("trait A的構造器....")
}
trait AA extends A {
println("trait AA的構造器....")
}
trait B {
println("trait B的構造器....")
}
trait BB extends B {
println("trait BB的構造器....")
}
class C {
println("class C的構造器....")
}
class CC1 extends C with AA with BB {
println("class CC1的構造器....")
}
class CC2 extends C {
println("class CC2的構造器....")
}
object Test {
def main(args: Array[String]): Unit = {
val cc1 = new CC1 //非動態混入
//class C的構造器....
//trait A的構造器....
//trait AA的構造器....
//trait B的構造器....
//trait BB的構造器....
//class CC1的構造器....
val cc2 = new CC2 with AA with BB //動態混入
//class C的構造器....
//class CC2的構造器....
//trait A的構造器....
//trait AA的構造器....
//trait B的構造器....
//trait BB的構造器....
}
}
java和scala的覆寫區別
//java***
class Son extends Father{
int age = 10;
public int getAge(){
return this.age;
}
}
public class Father {
int age = 20;
public int getAge(){
return this.age;
}
public static void main(String[] args) {
Son s = new Son();
Father f = s;
System.out.println(f.age); //20
System.out.println(s.age); //10
System.out.println(f.getAge()); //10
System.out.println(s.getAge()); //10
}
}
//scala***
class Son extends Father {
override val age: Int = 10
override def getAge: Int = this.age
}
class Father {
val age: Int = 20
def getAge: Int = {
return this.age
}
}
object Father {
def main(args: Array[String]): Unit = {
val s: Son = new Son
val f: Father = s
System.out.println(f.age) //10
System.out.println(s.age) //10
System.out.println(f.getAge) //10
System.out.println(s.getAge) //10
}
}
對容器的泛型做模式匹配
def main(args: Array[String]): Unit = {
val a: Any = Array[Double](1.1, 2, 3)
val b: Any = List[Double](10.1, 20, 30)
val c: Any = Map(1->2)
// matchTest(a) 元素型別不一致,匹配報錯
matchTest(b) //List[_]....
matchTest(c) //Map[_, _]...
}
def matchTest(a:Any): Unit = {
a match {
case a: Array[Int] =>
println("Array[Int]...")
case a: List[Int] =>
println("List[_]....")
case m: Map[Double, Boolean] =>
println("Map[_, _]...")
}
}