KMP演算法詳解

前言
這兩天鞏固C基礎的時候,遇到了這個KMP演算法,回想之前學資料結構時就沒完全搞懂它,這次下定決心要搞懂它
什麼時KMP演算法
網上部落格的描述:
KMP演算法又稱看毛片演算法,是用來進行字元匹配的,比如要檢查一個字串S裡是否有字串P,如果用暴力演算法的話,也是可以解的,但是效率特別低,時間複雜度為O(m * n),而如果你用看毛片演算法的話,時間複雜度為O(m + n)。
至於為什麼叫看毛片演算法(🤣),我猜是因為輸入法的事兒,輸入法在中文模式時,輸入kmp,就會出來那三個字。
正經的解釋:
KMP演算法是一種改進的字串匹配演算法,是由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,所以簡稱KMP演算法。其演算法核心是在匹配失敗後利用next陣列記錄的資訊來一定程度上減少匹配次數,以此提高字串匹配的效率。
KMP演算法的執行過程
我想,上來就將原理的話,估計也沒多少人能徹底理解,所以,先看一下它的執行過程
一會兒用到的符號:
i---> 被匹配字串的下標j---> 匹配字串的下標next--->next陣列next[j]---> 下標j對應的值
執行過程
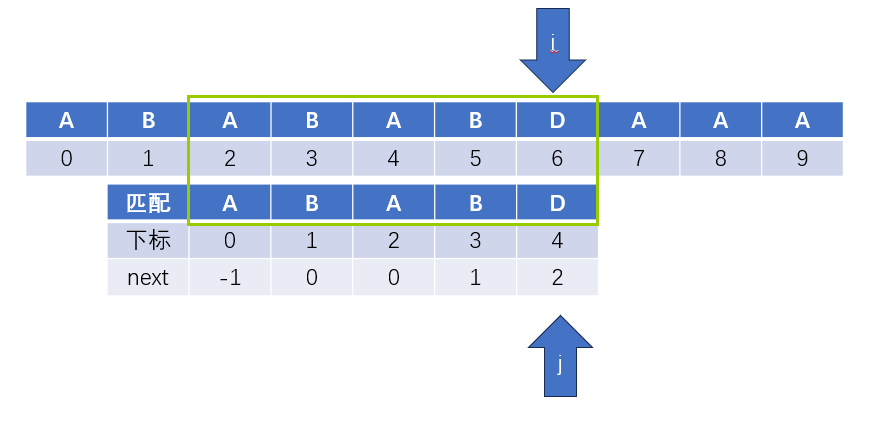
下標i和j指示的字元相等,i和j同時自增後移
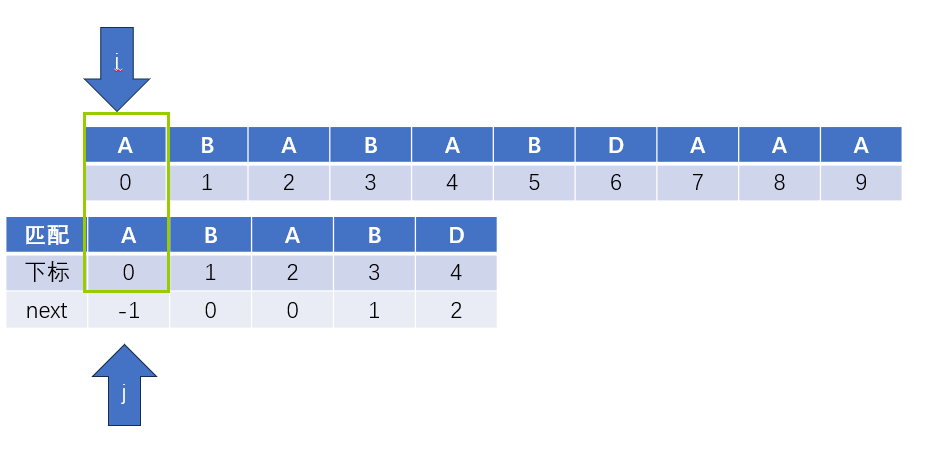
此時i和j指示的字元依舊相等,i和j繼續自增後移,以此類推
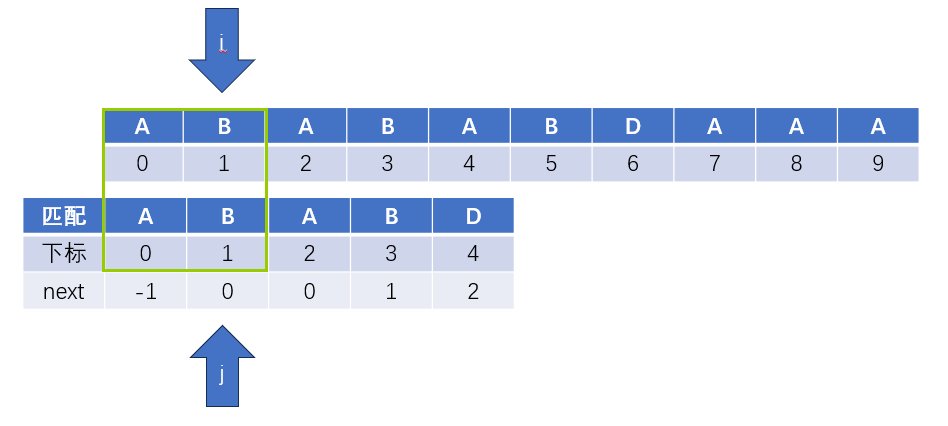
到第五個字元,也就是i=j=4時,我們發現i和j指示的字元不相等,這時該怎麼辦呢?往後看
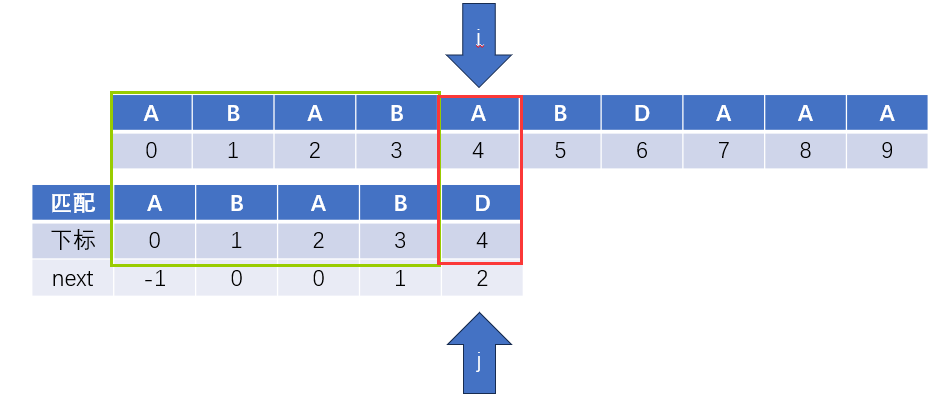
- 第一步,檢視
j指向的字元的下標[4]對應的next陣列裡的值next[4]=2 - 第二步,令
j指向下標為[2]的字元 - 第三步,判斷此時
i和j指向的字元是否一致,不一致,則類似的重複前兩步,直到一致或next值為-1
將匹配字串整體右移,保持i和j對齊,如下圖所示(實際程式執行中並沒有這一步,這裡只是為了方便理解)
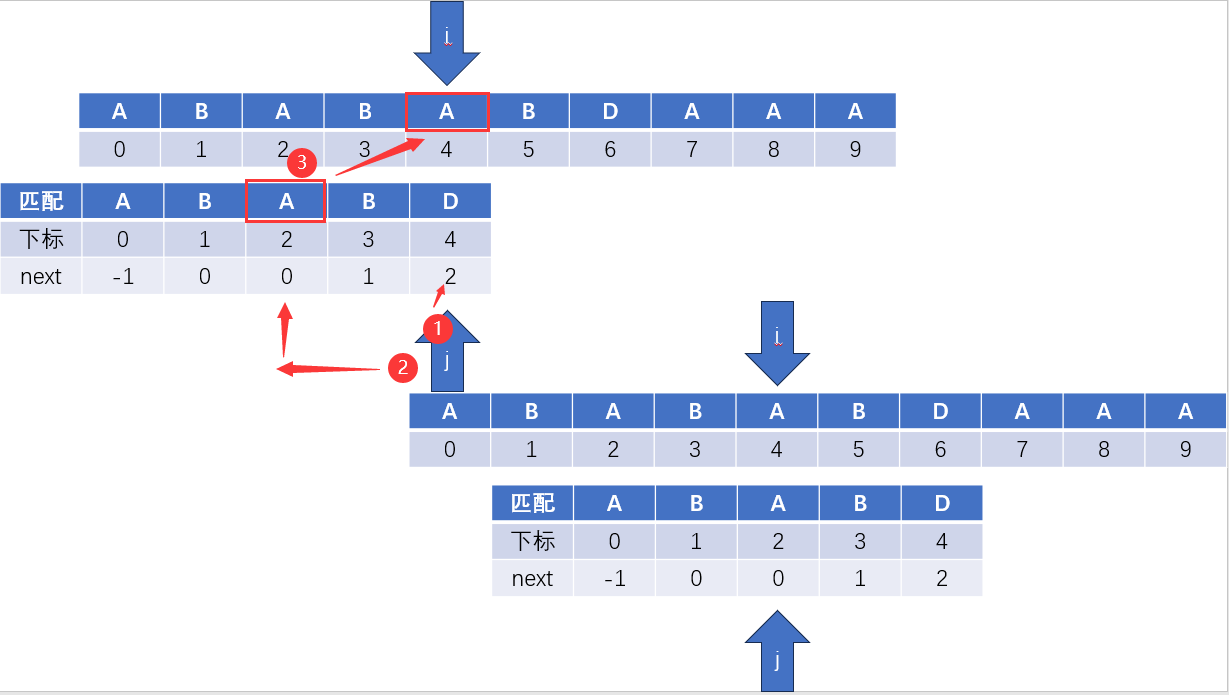
按照上面步驟調整好,我們就可以重新開始對比剩餘字元是否相等
相等:i和j自增後移,繼續對比
不相等:重複上圖所示步驟
終止條件,j>=匹配字串的長度,這裡也就是5
KMP 演算法原理
兩大核心步驟:
- 第一步,求解 next 陣列
- 第二步,進行字串匹配
求解next陣列
最長公共前字尾
在求解next之前,我們先來了解一下什麼是 最長公共前字尾
字串的字首是指不包含最後一個字元的所有以第一個字元(索引為0)開頭的連續子串
例如:字串 "ABABA" 的字首有:A,AB,ABA,ABAB
字串的字尾是指不包含第一個字元的所有以最後一個字元結尾的連續子串
例如:字串 "ABABA" 的字尾有:BABA,ABA,BA,A
公共前字尾:一個字串的 所有字首連續子串 和 所有字尾連續子串 中相等的子串
例如:
比如字串 "ABABA"
字首有:A,AB,ABA,ABAB
字尾有:BABA,ABA,BA,A
因此公共前字尾有:A ,ABA
最長公共前字尾:所有公共前字尾 的 長度最長的 那個子串
例如:
字串 "ABABA" ,公共前字尾有:A ,ABA
由於 ABA 是 三個字元長度,A 是一個字元長度,那麼最長公共前字尾就是 ABA
next陣列
先來看一下next陣列
| 字串 | A | B | A | B | D |
|---|---|---|---|---|---|
| 下標 | 0 | 1 | 2 | 3 | 4 |
| next | -1 | 0 | 0 | 1 | 2 |
next陣列的值的含義:
當i=0時:
next[0]的值固定為-1,這既是規定,也是必須(後面的值在進行計算時會用到它)!表示後面匹配失敗時,回溯的終止符(不一定回溯到next[0]=-1,但回溯到next[0]=-1就終止)
當i>0時:
-
next[i]表示0~i-1個或前i個字元的最長公共前字尾例:
next[4]表示前4個字元也就是ABAB的最長公共前字尾 -
next[i]也表示如果第i個字元匹配失敗,接著i應該指向那個位置例:
next[3]表示前3個字元字元匹配失敗時,i因該指向1 -
next[i]還表示前0~i-1的字元都匹配,但下標為i的字元不匹配時,應該跳過幾個字元的匹配例:
next[2]表示前0~1的字元都匹配,但下標為2的字元不匹配時,應該跳過0個字元的匹配,也就是從下標0開始重新匹配
C語言實現程式碼
這個是比較好的實現程式碼:
void getNext(char *pattern, int *next) {
int len = strlen(pattern);
int j = 0, k = -1;
next[0] = -1;
while (j < len - 1) {
if (k == -1 || pattern[j] == pattern[k]) {
k++;
j++;
next[j] = k;
} else {
k = next[k];
}
}
}
這個是比較差一點的實現程式碼:
void makeNext(char *pattern, int *next) {
int len = strlen(pattern);
next[0] = -1;
for (int i = 1; i < len; ++i) {
int k = next[i - 1];
while (k != -1 && pattern[i - 1] != pattern[k]) {
k = next[k];
}
next[i] = ++k;
}
}
進行字串匹配
匹配過程就是上面的執行過程,實現程式碼如下:
int search(char *str, char *pattern, int *next) {
int len1 = strlen(str);
int len2 = strlen(pattern);
int i = 0;
int j = 0;
while (i < len1 && j < len2) {
if (j == -1 || str[i] == pattern[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j >= len2) {
return i - len2;
} else {
return -1;
}
}
全部程式碼
#include <stdio.h>
#include <string.h>
void makeNext(char *pattern, int *next);
void getNext(char *pattern, int *next);
int search(char *str, char *pattern, int *next);
int main() {
char *str = "ABABABDABAABABAB";
char *pattern="ABABDABAAB";
int next[strlen(pattern)];
getNext(pattern, next);
int result = search(str, pattern, next);
for (int i = 0; i < strlen(pattern); ++i) {
printf("%d ", next[i]);
}
printf("\n");
if(result != -1) {
printf("匹配到相同字串,下標從%d開始", result);
} else{
printf("未匹配到相同字串");
}
return 0;
}
void makeNext(char *pattern, int *next) {
int len = strlen(pattern);
next[0] = -1;
for (int i = 1; i < len; ++i) {
int k = next[i - 1];
while (k != -1 && pattern[i - 1] != pattern[k]) {
k = next[k];
}
next[i] = ++k;
}
}
void getNext(char *pattern, int *next) {
int len = strlen(pattern);
int j = 0, k = -1;
next[0] = -1;
while (j < len - 1) {
if (k == -1 || pattern[j] == pattern[k]) {
k++;
j++;
next[j] = k;
} else {
k = next[k];
}
}
}
int search(char *str, char *pattern, int *next) {
int len1 = strlen(str);
int len2 = strlen(pattern);
int i = 0;
int j = 0;
while (i < len1 && j < len2) {
if (j == -1 || str[i] == pattern[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j >= len2) {
return i - len2;
} else {
return -1;
}
}
結束語
說實話,我寫的不夠好,我推薦看這兩篇文章:
- [KMP演算法圖文詳解(為什麼是next0]=-1、next[j]=k和k=next[k])_kmp演算法的next初始值為-1-CSDN部落格
- 史上最詳細的KMP演算法教程,看這一篇就夠了-CSDN部落格
這裡另外附上洛谷的KMP演算法題和AC程式碼:
- P3375 【模板】KMP - 洛谷 | 電腦科學教育新生態 (luogu.com.cn)
#include <stdio.h>
#include <string.h>
#define VALUE 1000000
void getNext(char *pattern, int *next);
int search(char *str, int i, char *pattern, int *next);
char str[VALUE];
char pattern[VALUE];
int next[VALUE];
int len1;
int len2;
int main() {
scanf("%s", str);
scanf("%s", pattern);
len1 = strlen(str);
len2 = strlen(pattern);
getNext(pattern, next);
int result = search(str, 0, pattern, next);
while (result != -1) {
printf("%d\n", result + 1);
result = search(str, result + 1, pattern, next);
}
for (int i = 1; i <= len2; ++i) {
printf("%d ", next[i]);
}
return 0;
}
void getNext(char *pattern, int *next) {
int j = 0, k = -1;
next[0] = -1;
while (j < len2) {
if (k == -1 || pattern[j] == pattern[k]) {
k++;
j++;
next[j] = k;
} else {
k = next[k];
}
}
}
int search(char *str, int i, char *pattern, int *next) {
int j = 0;
while (i < len1 && j < len2) {
if (j == -1 || str[i] == pattern[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j >= len2) {
return i - len2;
} else {
return -1;
}
}