Kaggle—So Easy!百行程式碼實現排名Top 5%的影象分類比賽
Kaggle—So Easy!百行程式碼實現排名Top 5%的影象分類比賽
作者:七月線上彭老師
說明:本文最初由彭老師授權翟惠良釋出在公眾號“七月線上實驗室”上,現再由July重新編輯釋出到本blog上。
Github: https://github.com/pengpaiSH/Kaggle_NCFM
前言
根據我個人的經驗,學好AI,有五個必修:數學、資料結構、Python資料分析、ML、DL,必修之外,有五個選修可供選擇:NLP、CV、DM、量化、Spark,然後配套七月線上的這些必修和選修課程刷leetcode、kaggle,最後做做相關開源實驗。今天,我們們就來看一看:如何用百行程式碼實現Kaggle排名Top 5%的影象分類比賽。
1. NCFM影象分類任務簡介
為了保護和監控海洋環境及生態平衡,大自然保護協會(The Nature Conservancy)邀請Kaggle[1]社群的參賽者們開發能夠出機器學習演算法,自動分類和識別遠洋捕撈船上的攝像頭拍攝到的圖片中魚類的品種,例如不同種類的吞拿魚和鯊魚。大自然保護協會一共提供了3777張標註的圖片作為訓練集,這些圖片被分為了8類,其中7類是不同種類的海魚,剩餘1類則是不含有魚的圖片,每張圖片只屬於8類中的某一類別。
圖1給出了資料集中的幾張圖片樣例,可以看到,有些圖片中待識別的海魚所佔整張圖片的一小部分,這就給識別帶來了很大的挑戰性。此外,為了衡量演算法的有效性,還提供了額外的1000張圖片作為測試集,參賽者們需要設計出一種影象識別的演算法,儘可能地識別出這1000張測試圖片屬於8類中的哪一類別。Kaggle平臺為每一個競賽都提供了一個榜單(Leaderboard),識別的準確率越高的競賽者在榜單上的排名越靠前。

圖1. NCFM影象分類比賽
2. 問題分析與求解思路
2.1卷積神經網路(ConvNets)
從問題的描述我們可以發現,NCFM競賽是一個典型的“單標籤影象分類”問題,即給定一張圖片,系統需要預測出影象屬於預先定義類別中的哪一類。在計算機視覺領域,目前解決這類問題的核心技術框架是深度學習(Deep Learning),特別地,針對影象型別的資料,是深度學習中的卷積神經網路(Convolutional Neural Networks, ConvNets)架構(關於卷積神經網路的介紹和演算法,這裡有個視訊教程可以看下:CNN之卷積計算層,本部落格也寫過:CNN筆記)。
總的來說,卷積神經網路是一種特殊的神經網路結構,即通過卷積操作可以實現對影象特徵的自動學習,選取那些有用的視覺特徵以最大化影象分類的準確率。
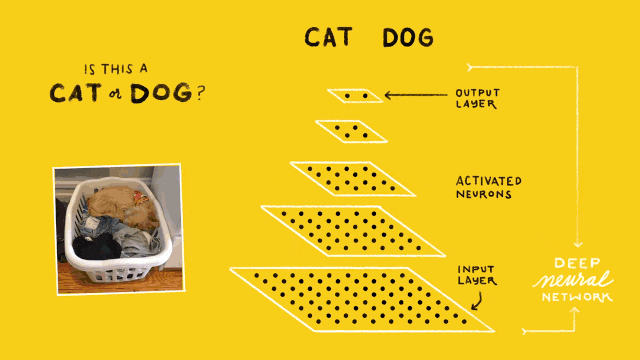
圖2. 卷積神經網路架構
圖2給出了一個簡單的貓狗識別的卷積神經網路結構,在最底下(同時也是最大的)的點塊表示的是網路的輸入層(Input Layer),通常這一層作用是讀入影象作為網路的資料輸入。在最上面的點塊是網路的輸出層(Output Layer),其作用是預測並輸出讀入影象的類別,在這裡由於只需要區分貓和狗,因此輸出層只有2個神經計算單元。而位於輸入和輸出層的,都稱之為隱含層(Hidden Layer),圖中有3個隱含層,正如前文提到的,影象分類的隱含層都是由卷積操作完成的,因此這樣的隱含層也成為卷積層(Convolutional Layer)。
因此,輸入層、卷積層、輸出層的結構及其對應的引數就構成了一個典型的卷積神經網路。當然,我們在實際中使用的卷積神經網路要比這個示例的結構更加複雜,自2012年的ImageNet比賽起,幾乎每一年都會有新的網路結構誕生,已經被大家認可的常見網路有AlexNet[5], VGG-Net[6], GoogLeNet[7], Inception V2-V4[8, 9], ResNet[10]等等。
2.2 一種有效的網路訓練技巧—微調(Fine-tune)
我們沒有必要從頭開始一個一個的引數去試驗來構造一個深度網路,因為已經有很多公開發表的論文已經幫我們做了這些驗證,我們只需要站在前人的肩膀上,去選擇一個合適的網路結構就好了。且選擇已經公認的網路結構另一個重要的原因是,這些網路幾乎都提供了在大規模資料集ImageNet[11]上預先訓練好的引數權重(Pre-trained Weights)。這一點非常重要!因為我們只有數千張訓練樣本,而深度網路的引數非常多,這就意味著訓練圖片的數量要遠遠小於引數搜尋的空間,因此,如果只是隨機初始化深度網路然後用這數千張圖片進行訓練,非常容易產生“過擬合”(Overfitting)的現象。
所謂過擬合,就是深度網路只看過了少量的樣本,因而“坐井觀天”,導致只能識別這小部分的圖片,喪失了“泛化”(Generalization)能力,不能夠識別其它沒見過、但是也是相似的圖片。為了解決這樣的問題,我們一般都會使用那些已經在數百萬甚至上千萬上訓練好的網路引數作為初始化引數,可以想象這樣一組引數的網路已經“看過”了大量的圖片,因此泛化能力大大提高了,提取出來的視覺特徵也更加的魯棒和有效。
接下來我們就可以使用已經標註的三千多張海魚圖片接著進行訓練,注意為了防止錯過了最優解,此時的訓練節奏(其實應該稱為“學習速率”)應該比較緩慢,因此這樣的訓練策略我們稱為“微調技術”(Fine-tune)。
當我們使用自己的標註資料微調某個預先訓練的網路時候,有一些經驗值得借鑑。以總圖3為例,假設我們的網路結構是類似AlexNet這樣的7層結構,其中前5層是卷積層,後2層是全連線層。
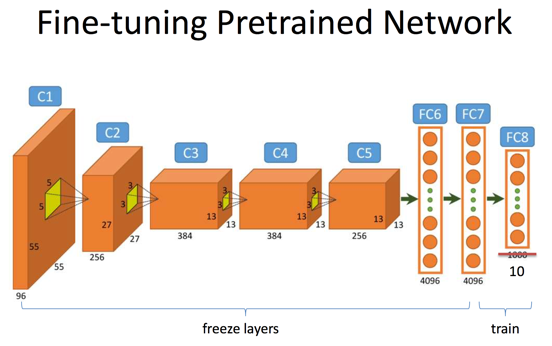
(1)
- (1)我們首先微調最後一層Softmax分類器,假設原來的網路是用來分類1000類物體的(例如ImageNet的目標),而現在我們的資料只有10個類別標籤,因此我們最後一層輸出層(FC8)的神經元個數變為10。我們使用很小的學習率來學習層FC7與FC8之間的權重矩陣而固定這之前所有層的權重;
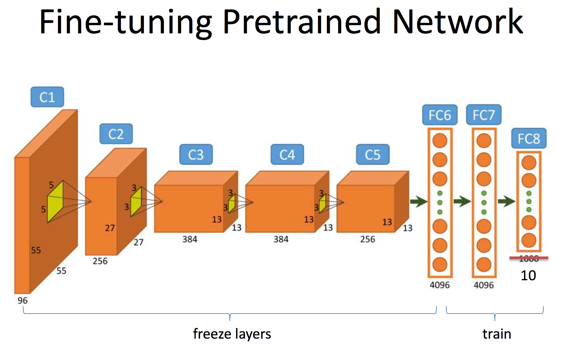
(2)
- (2)一旦網路趨於收斂,我們進一步擴大微調的範圍,這時微調兩個全連線層,即FC6與FC7,以及FC7與FC8之間的權重,與此同時固定FC6之前的所有卷積層權重不變;
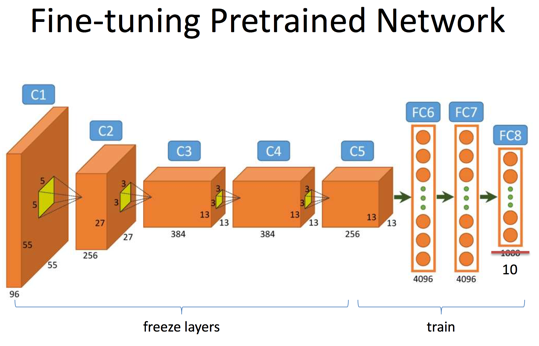
(3)
- (3)我們將微調的範圍擴大至倒數第一個卷積層C5;
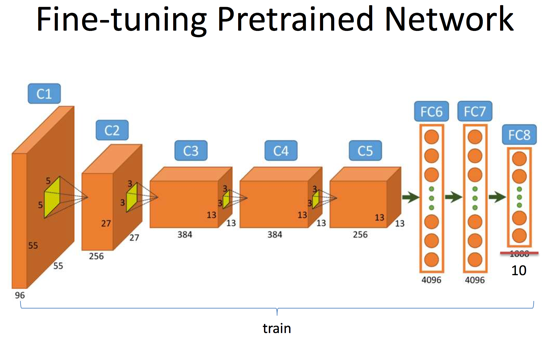
- (4)我們將微調的範圍擴大至更多的卷積層。不過事實上,我們會認為位置相對靠前的卷積層提取出來的特徵更加的底層和具有通用性,而位置相對靠後的卷積層以及全連線層更加與資料集的相關性大一些,因此有時候我們並不會微調前幾個卷積層。
總圖3. 網路Finetune的基本步驟
3. 演算法實現和分析
在NCFM這個比賽的論壇裡已經有開源的實現供大家參考(https://www.kaggle.com/c/the-nature-conservancy-fisheries-monitoring/discussion/26202),
在這裡分析一下模型訓練檔案train.py的邏輯結構。
- ü Import相關的模組以及引數的設定——圖4;
- ü 構建Inception_V3深度卷及網路,使用在ImageNet大規模圖片資料集上已經訓練好的引數作為初始化,定義回撥函式儲存訓練中在驗證集合上最好的模型——圖5;
- ü 使用資料擴增(Data Augmentation)技術載入訓練圖片,資料擴增技術是控制過擬合現象的一種常見的技巧,其思想很簡單,同樣是一張圖片,如果把它水平翻轉一下,或者邊角裁剪一下,或者色調再調暗淡或者明亮一些,都不會改變這張圖片的類別——圖6;
- ü Inception_V3網路模型訓練;
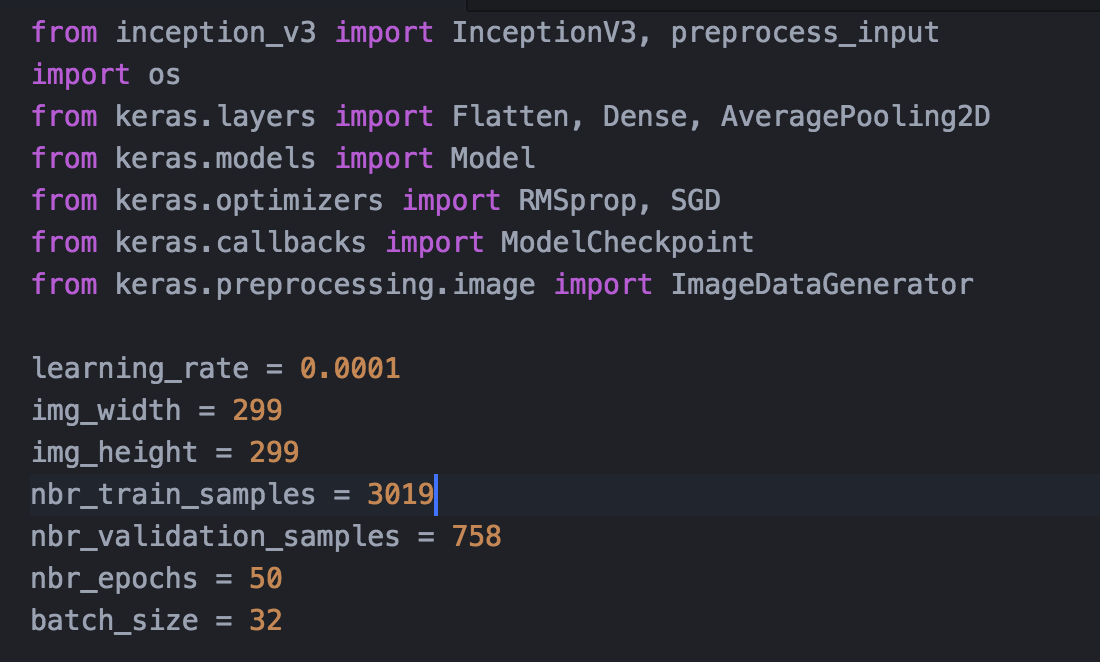
圖4. Import和引數設定
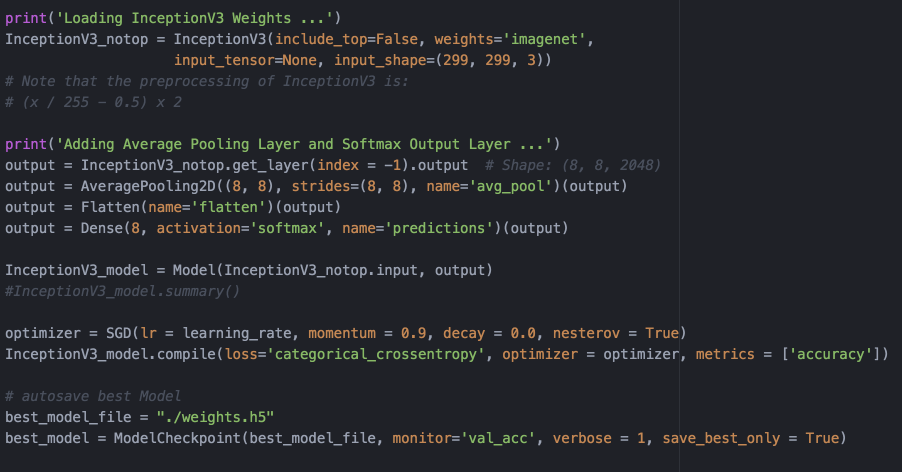
圖5. 構建Inception_V3網路並載入預訓練引數
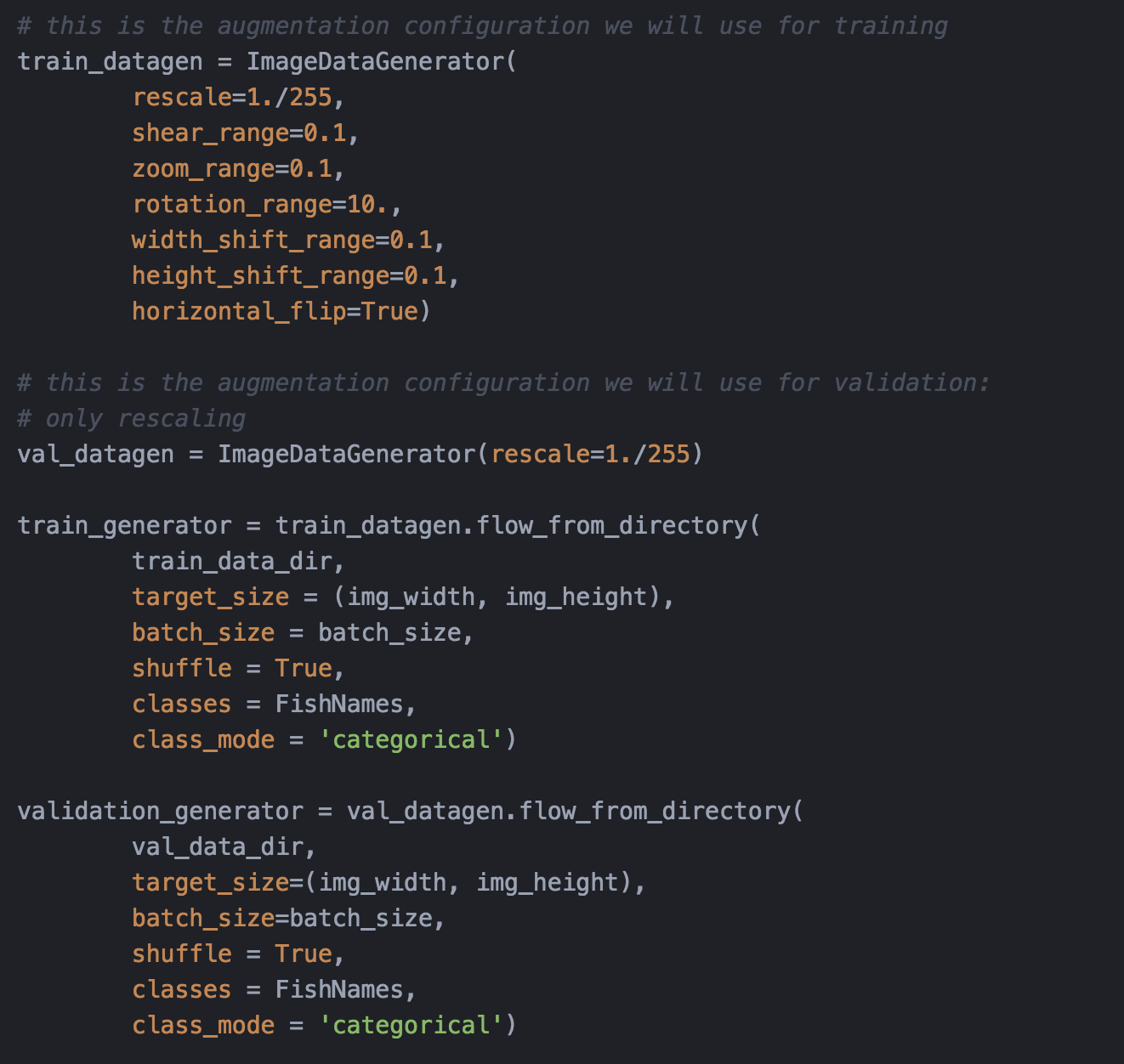
圖6. 使用資料擴增技術載入訓練和驗證圖片集

圖7. 模型訓練
4. 提升排名的若干技巧
一旦我們訓練好了模型,我們就用這個模型預測那些測試圖片的類別了,論壇中predict.py中的程式碼就是預測魚類的並且生成提交檔案。這裡我們給大家分享一下在機器學習和影象識別類競賽中常見的兩個技巧,簡單而有效。它們的思想都是基於平均和投票思想。其背後的原理用一句話總結就是:群眾的眼睛是雪亮的!
技巧1:同一個模型,平均多個測試樣例
這個技巧指的是,當我們訓練好某個模型後,對於某張測試圖片,我們可以使用類似資料擴增的技巧生成與改張圖片相類似的多張圖片,並把這些圖片送進我們訓練好的網路中去預測,我們取那些投票數最高的類別為最終的結果。Github倉庫中的predict_average_augmentation.py實現的就是這個想法,其效果也非常明顯。
技巧2:交叉驗證訓練多個模型
還記得我們之前說到要把三千多張圖片分為訓練集和驗證集嗎?這種劃分其實有很多種。一種常見的劃分是打亂圖片的順序,把所有的圖片平均分為K份,那麼我們就可以有K種<訓練集,驗證集>的組合,即每次取1份作為驗證集,剩餘的K-1份作為訓練集。因此,我們總共可以訓練K個模型,那麼對於每張測試圖片,我們就可以把它送入K個模型中去預測,最後選投票數最高的類別作為預測的最終結果。我們把這種方式成為“K折交叉驗證”(K-Fold Cross-Validation)。圖9表示的就是一種5折交叉驗證的資料劃分方式。
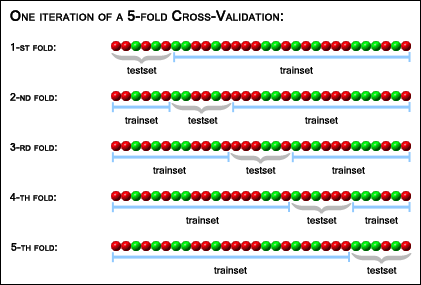
圖9. 五折交叉驗證
當然,技巧1和2也可以聯合在一起使用。假設我們做了5折交叉驗證,並且對於每一張測試圖片都用5次資料擴增,那麼不難計算,每一張測試圖片的投票數目就是25個。採用這種方式,我們的排名可以更進一步。
5. 後記
我們回顧了深度學習中的深度卷積網路的典型結構和特點,並且知道了如何使用梯度下降演算法來訓練一個深度網路。我們展示瞭如何用微調技術,使用Inception_V3網路來解決Kaggle的NCFM海魚分類比,並且通過兩個簡單而有效的小技巧,使得我們的排名能夠進入Top 5%。
如果讀者對該比賽有興趣,想進一步提升名次,那麼一種值得嘗試的方法是:物體檢測(Object Detection)技術。試想一下,其實我們只要區分海魚的品種,由於攝像頭遠近等關係,圖片中海魚的區域其實只佔據一小部分畫素點,更多的區域都是船體、桅杆或是海洋等噪音。如果有一種演算法能夠幫我們把海魚從照片中“扣”(檢測)出來,那麼可以想象,深度網路的準確率就能夠進一步提升了,這部分的工作就留給有興趣的同學自己做進一步研究了。
七月線上彭老師、二零一七年五月十日。
參考文獻
- [1] https://www.kaggle.com/
- [2] http://cs231n.github.io/neural-networks-3/
- [3] https://github.com/tensorflow/tensorflow
- [4] https://github.com/fchollet/keras
- [5] Image Classification with Deep Convolutional Neural Networks. NIPS 2012.
- [6] Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015.
- [7] Going Deep with Convolutions. CVPR 2015.
- [8] Rethinking the Inception Architecture for Computer Vision. CVPR 2016.
- [9] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. ICLR 2016.
- [10] Deep Residual Learning for Image Recognition. CVPR 2016.
- [11] http://www.image-net.org/
- 七月線上《kaggle案例實戰班》
- kaggle實戰公開課《模型分析與模型融合》
相關文章
- 【Kaggle入門級競賽top5%排名經驗分享】— 建模篇
- 【Kaggle入門級競賽top5%排名經驗分享】— 分析篇
- so easy 前端實現多語言前端
- 6次Kaggle計算機視覺類比賽賽後感計算機視覺
- Kaggle 自行車租賃預測比賽專案實現
- Android實現多語言so easyAndroid
- 排名Top 16的Java實用類庫Java
- kaggle季軍新手筆記:利用fast.ai對油棕人工林影象進行快速分類(附程式碼)筆記ASTAI
- 排球比賽計分程式的故事
- 【機器學習】--xgboost初始之程式碼實現分類機器學習
- 通俗理解kaggle比賽大殺器xgboost
- 這個輪子讓SpringBoot實現api加密So EasySpring BootAPI加密
- Redis實現排名功能的示例程式碼CRKCRedis
- 【機器學習PAI實踐十】深度學習Caffe框架實現影象分類的模型訓練機器學習AI深度學習框架模型
- 低程式碼無程式碼開發工具:TOP10排名
- 【比賽回顧】廣工2020程式設計初賽D-好人easy程式設計
- Kaggle樹葉分類Leaves Classify總結
- bert分類的程式碼
- so easy! 10行程式碼寫個"狗屁不通"文章生成器行程
- 用最少的程式碼手工實現一個Promise,5分鐘看懂Promise
- [SWPUCTF 2021 新生賽]easy_md5
- HDU4565 So Easy! (矩陣)矩陣
- TF2.keras 實現基於卷積神經網路的影象分類模型TF2Keras卷積神經網路模型
- 使用自己的資料集訓練MobileNet、ResNet實現影象分類(TensorFlow)
- 超優惠:程式設計師的第一個一百萬,So easy!程式設計師
- Kaggle座頭鯨識別賽,TOP10團隊的解決方案分享
- 前端註釋那些事兒:看懂這篇,提高程式碼質量So easy前端
- 簡單介紹一些關於 Kaggle 比賽的知識
- 《排球比賽記分程式》的使用者願景
- 亞馬遜:用CNN進行影象分類的Tricks亞馬遜CNN
- Asp.Net 5分鐘實現網頁實時監控程式碼ASP.NET網頁
- 機器學習程式碼實現 SVM (5)機器學習
- metarank: 推薦排名類的低程式碼機器學習工具機器學習
- TF2.keras 實現基於深度可分離卷積網路的影象分類模型TF2Keras卷積模型
- 穆迪:2017年全球現金儲備公司排名TOP 5
- HDU 4565 So Easy!(矩陣快速冪)矩陣
- Docker容器:將帶UI的程式直接轉為Web應用,so easyDockerUIWeb
- IDOC實現同一Client不同公司程式碼的PO產生SOclient