1.首先。我們用surf演算法生成影象庫中每幅圖的特徵點及描寫敘述符。
2.再用k-means演算法對影象庫中的特徵點進行訓練,生成類心。
3.生成每幅影象的BOF。詳細方法為:推斷影象的每一個特徵點與哪個類心近期。近期則放入該類心,最後將生成一列頻數表。即初步的無權BOF。
4.通過tf-idf對頻數表加上權重,生成終於的bof。(因為每一個類心對影象的影響不同。比方超市裡條形碼中的第一位總是6,它對辨別產品毫無作用。因此權重要減小)。
5.對query進來的影象也進行3.4步操作,生成一列query圖的BOF。
6.將query的Bof向量與影象庫中每幅圖的Bof向量求夾角,夾角最小的即為匹配物件。
影象檢索中應用LSH實現高速搜尋。其在一定概率的保證下攻克了高維特徵查詢的問題,但筆者在應用LSH結合SIFT特徵實踐影象檢索實驗時,因為每張影象涉及上百個特徵,那麼在查詢一張圖片時,須要進行上而次的特徵查詢,即便是將查詢圖片的特徵點數篩選至50%的量,一次圖片查詢須要進行的特徵查詢次數亦不容小窺。那麼有沒有方法能夠將隨意圖片的全部特徵向量用一個固定維數的向量表出,且這個維數並不因圖片特徵點數不同而變化?本篇要講到的方法能夠解決問題,雖然它並非因這個問題而生的。
Bag-of-Words模型源於文字分類技術,在資訊檢索中,它假定對於一個文字,忽略其詞序和語法、句法。

將其只看作是一個詞集合,或者說是詞的一個組合。文字中每一個詞的出現都是獨立的,不依賴於其它詞是否出現,或者說這篇文章的作者在隨意一個位置選擇詞彙都不受前面句子的影響而獨立選擇的。
影象能夠視為一種文件物件,影象中不同的區域性區域或其特徵可看做構成影象的詞彙,當中相近的區域或其特徵能夠視作為一個詞。這樣,就能夠把文字檢索及分類的方法用到影象分類及檢索中去。
Accelerating Bag-of-Features SIFT Algorithm for 3D Model Retrieval
Bag-of-Features模型仿照文字檢索領域的Bag-of-Words方法,把每幅影象描寫敘述為一個區域性區域/關鍵點(Patches/Key Points)特徵的無序集合。使用某種聚類演算法(如K-means)將區域性特徵進行聚類。每一個聚類中心被看作是詞典中的一個視覺詞彙(Visual Word)。相當於文字檢索中的詞。視覺詞彙由聚類中心相應特徵形成的碼字(code word)來表示(可看當為一種特徵量化過程)。全部視覺詞彙形成一個視覺詞典(Visual Vocabulary),相應一個碼書(code book),即碼字的集合,詞典中所含詞的個數反映了詞典的大小。影象中的每一個特徵都將被對映到視覺詞典的某個詞上,這樣的對映能夠通過計算特徵間的距離去實現,然後統計每一個視覺詞的出現與否或次數。影象可描寫敘述為一個維數相同的直方圖向量,即Bag-of-Features。


https://img-blog.csdn.net/20131002212031828?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvY2hsZWxlMDEwNQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center
Bag of Features Codebook Generation by Self-Organisation
Bag-of-Features很多其它地是用於影象分類或物件識別。在上述思路下對訓練集提取Bag-of-Features特徵,在某種監督學習(如:SVM)的策略下。對訓練集的Bag-of-Features特徵向量進行訓練,獲得物件或場景的分類模型。對於待測影象,提取區域性特徵,計算區域性特徵與詞典中每一個碼字的特徵距離。選取近期距離的碼字代表該特徵。建立一個統計直方圖。統計屬於每一個碼字的特徵個數,即為待測影象之Bag-of-Features特徵。在分類模型下,對該特徵進行預測從實現對待測影象的分類。
Classification Process
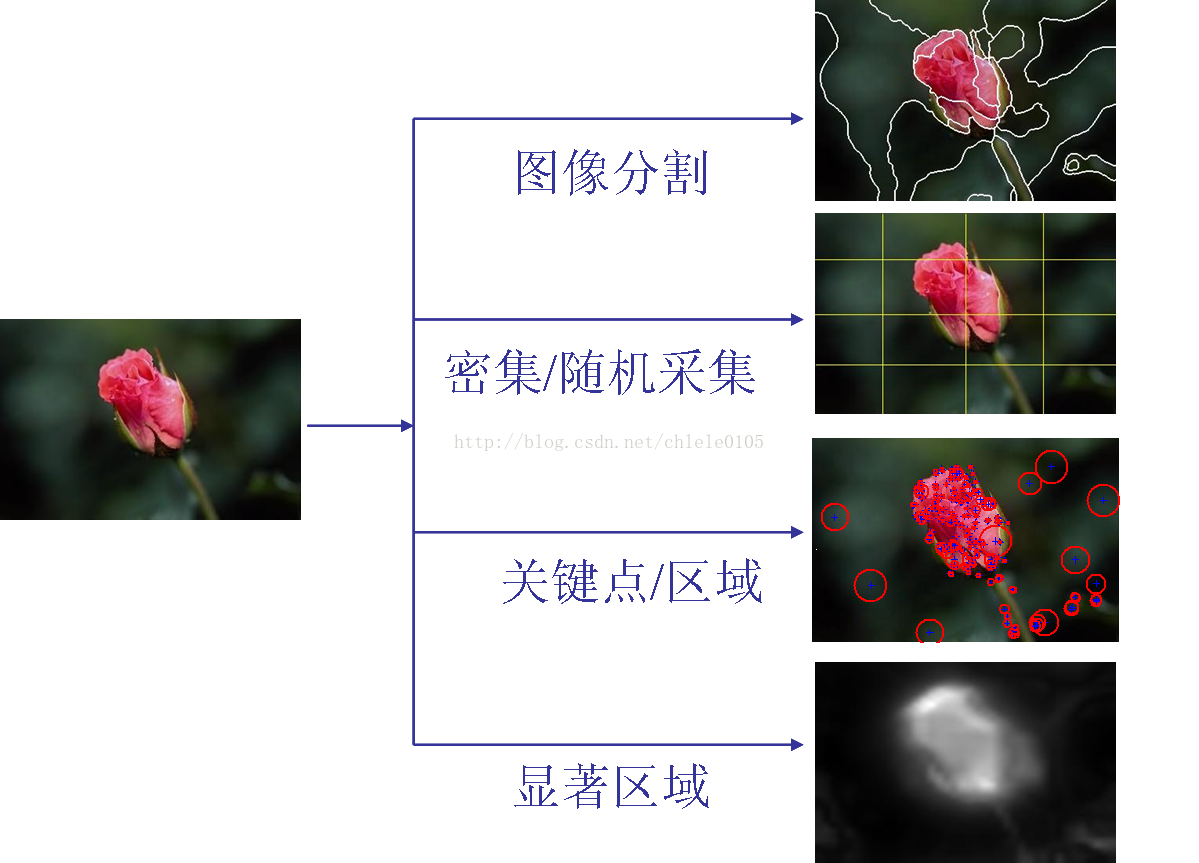
1、區域性特徵提取:通過切割、密集或隨機採集、關鍵點或穩定區域、顯著區域等方式使影象形成不同的patches。並獲得各patches處的特徵。
當中,SIFT特徵較為流行。
2、構建視覺詞典:
由聚類中心代表的視覺詞彙形成視覺詞典:
3、生成碼書。即構造Bag-of-Features特徵,也即區域性特徵投影過程:
4、SVM訓練BOF特徵得分類模型,對待測影象BOF特徵預測:
Retrieval Process
Bag-of-words在CV中的應用首先出如今Andrew Zisserman[6]中為解決對視訊場景的搜尋,其提出了使用Bag-of-words關鍵點投影的方法來表示影象資訊。



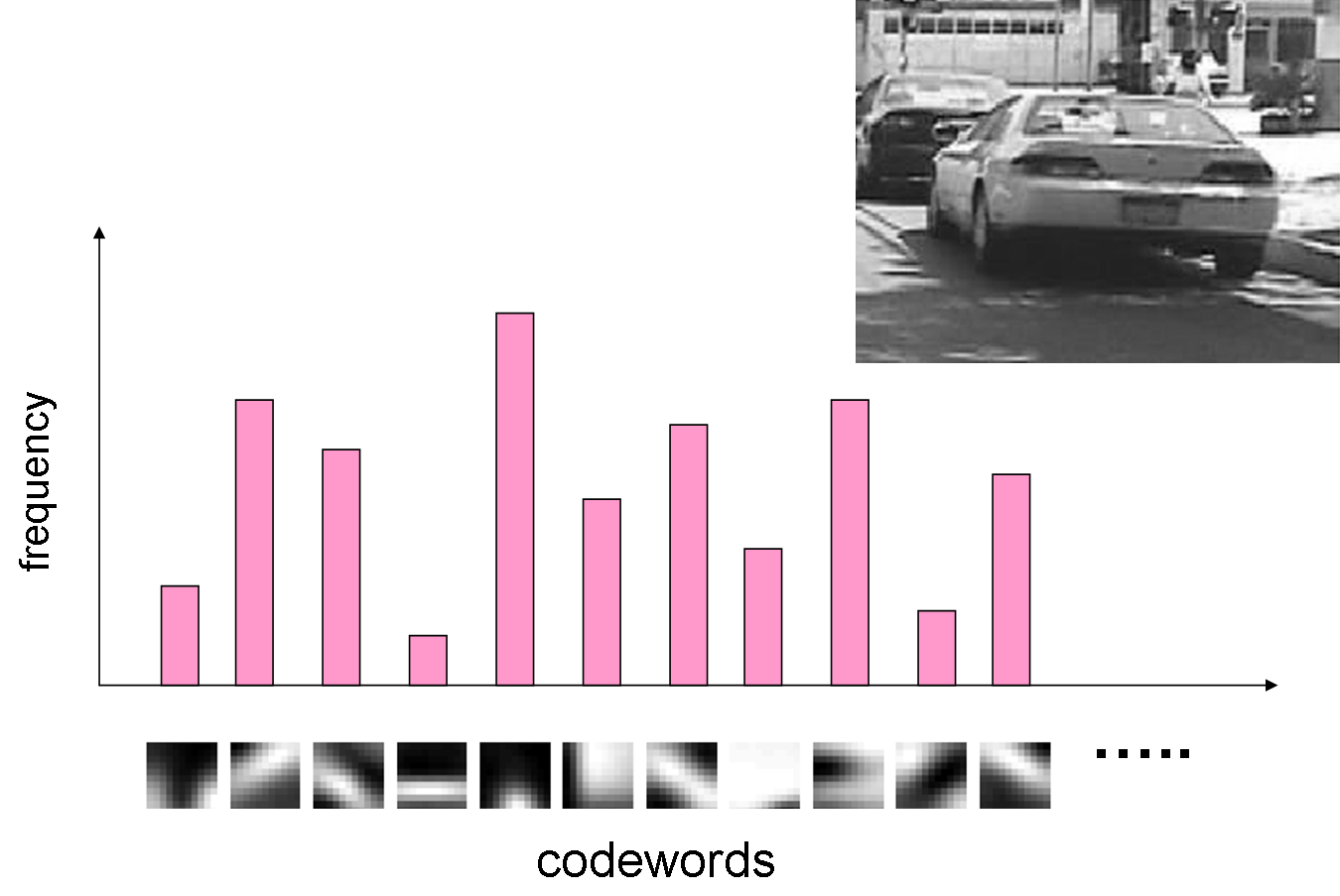
興許很多其它的研究者歸結此方法為Bag-of-Features。並用於影象分類、目標識別和影象檢索。
在Bag-of-Features方法的基礎上,Andrew Zisserman進一步借鑑文字檢索中TF-IDF模型(Term Frequency一Inverse Document Frequency)來計算Bag-of-Features特徵向量。
接下來便能夠使用文字搜尋引擎中的反向索引技術對影象建立索引,高效的進行影象檢索。
Hamming embedding and weak geometric consistency for large scale image search
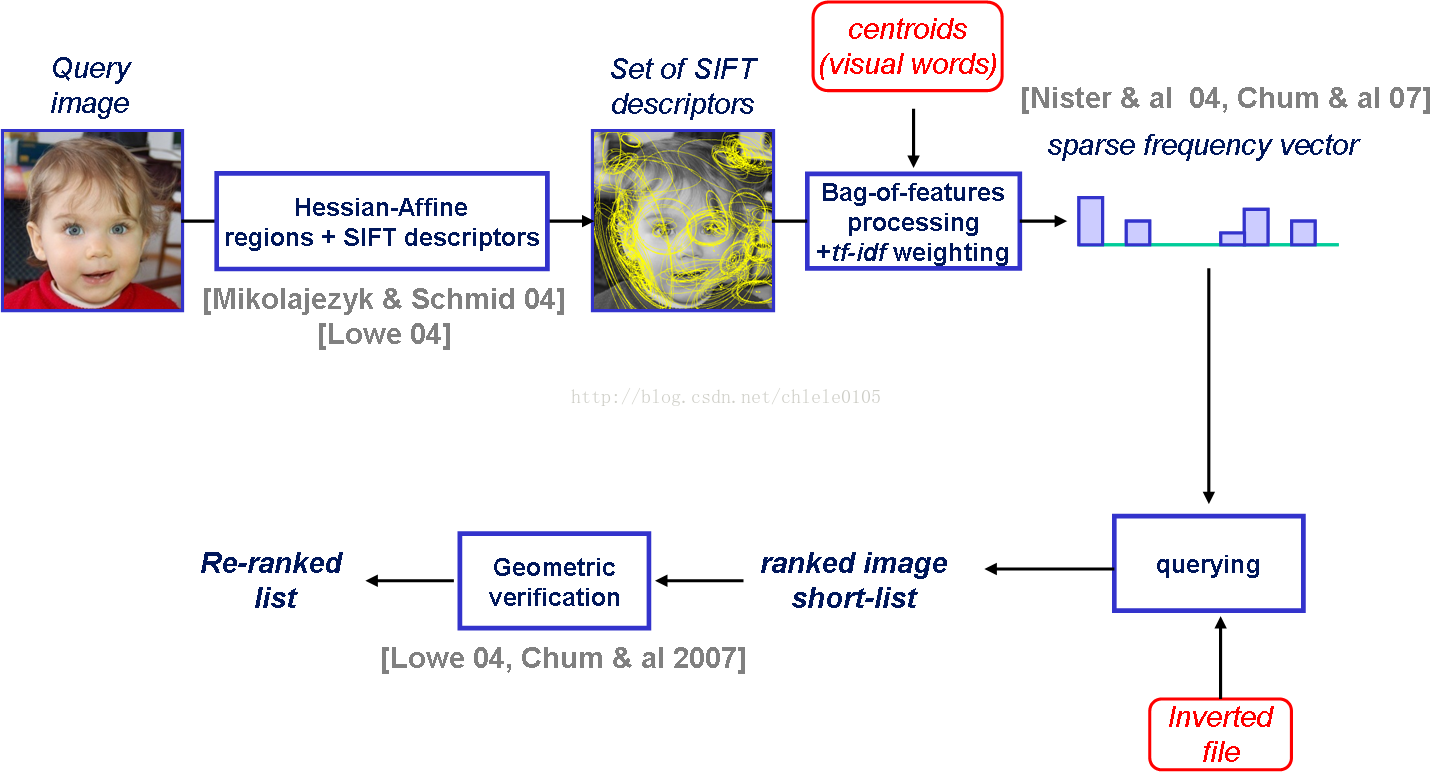
實現檢索的過程同分類的過程無本質的差異,很多其它的是細節處理上的差異:
1、區域性特徵提取。
2、構建視覺詞典。
3、生成原始BOF特徵;
4、引入TF-IDF權值:
TF-IDF是一種用於資訊檢索的經常使用加權技術,在文字檢索中。用以評估詞語對於一個檔案資料庫中的當中一份檔案的重要程度。詞語的重要性隨著它在檔案裡出現的頻率成正比新增,但同一時候會隨著它在檔案資料庫中出現的頻率成反比下降。TF的主要思想是:假設某個關鍵詞在一篇文章中出現的頻率高。說明該詞語能夠表徵文章的內容。該關鍵詞在其它文章中非常少出現,則覺得此詞語具有非常好的類別區分度,對分類有非常大的貢獻。IDF的主要思想是:假設檔案資料庫中包括詞語A的檔案越少。則IDF越大,則說明詞語A具有非常好的類別區分能力。
詞頻(Term Frequency。TF)指的是一個給定的詞語在該檔案裡出現的次數。如:tf = 0.030 ( 3/100 )表示在包括100個詞語的文件中, 詞語’A’出現了3次。
逆文件頻率(Inverse Document Frequency。IDF)是描寫敘述了某一個特定詞語的普遍重要性。假設某詞語在很多文件中都出現過,表明它對文件的區分力不強,則賦予較小的權重;反之亦然。如:idf = 13.287 ( log (10,000,000/1,000) )表示在總的10,000,000個文件中,有1,000個包括詞語’A’。
終於的TF-IDF權值為詞頻與逆文件頻率的乘積。
5、對查詢影象生成相同的帶權BOF特徵;
6、查詢:初步是通過餘弦距離衡量,至於建立索引的方法還未學習到,望看客指點。
Issues
1、使用k-means聚類。除了其K和初始聚類中心選擇的問題外。對於海量資料,輸入矩陣的巨大將使得記憶體溢位及效率低下。有方法是在海量圖片中抽取部分訓練集分類,使用樸素貝葉斯分類的方法對相簿中其餘圖片進行自己主動分類。另外,因為圖片爬蟲在不斷更新後臺影象集。又一次聚類的代價顯而易見。
2、字典大小的選擇也是問題,字典過大,單詞缺乏一般性,對噪聲敏感,計算量大,關鍵是圖象投影后的維數高;字典太小。單詞區分效能差,對類似的目標特徵無法表示。
3、類似性測度函式用來將圖象特徵分類到單詞本的相應單詞上,其涉及線型核。塌方距離測度核。直方圖交叉核等的選擇。
4、將影象表示成一個無序區域性特徵集的特徵包方法,丟掉了全部的關於空間特徵佈局的資訊。在描寫敘述性上具有一定的有限性。為此。 Schmid[2]提出了基於空間金字塔的Bag-of-Features。
5、Jégou[7]提出VLAD(vector of locally aggregated descriptors),其方法是如同BOF先建立出含有k個visual word的codebook。而不同於BOF將一個local descriptor用NN分類到近期的visual word中。VLAD所採用的是計算出local descriptor和每一個visual word(ci)在每一個分量上的差距,將每一個分量的差距形成一個新的向量來代表圖片。
Resources
Two bag-of-words classifiers(Matlab)
Bag of Words/Bag of Features的Matlab原始碼
一個用BoW|Pyramid BoW+SVM進行影象分類的Matlab Demo