依據Spark官方文件中的描寫敘述。在Spark Streaming應用中,一個DStream物件能夠呼叫多種操作。主要分為以下幾類
- Transformations
- Window Operations
- Join Operations
- Output Operations
一、Transformations
1、map(func)
map操作須要傳入一個函式當做引數,詳細呼叫形式為
val b = a.map(func) 主要作用是,對DStream物件a,將func函式作用到a中的每個元素上並生成新的元素,得到的DStream物件b中包括這些新的元素。
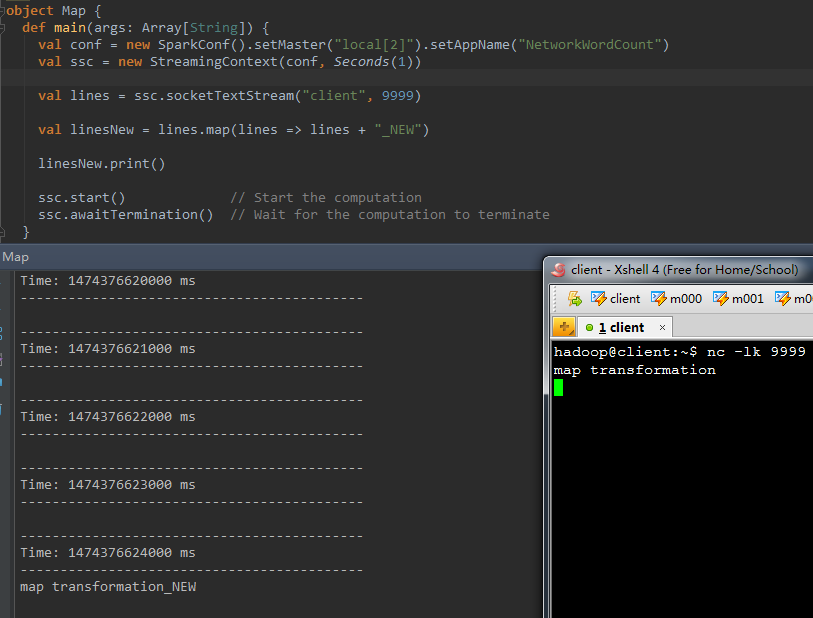
以下演示樣例程式碼的作用是。在接收到的一行訊息後面拼接一個”_NEW”字串
val linesNew = lines.map(lines => lines + "_NEW" ) 程式執行結果例如以下:
注意與接下來的flatMap操作進行比較。
2、flatMap(func)
相似於上面的map操作,詳細呼叫形式為
val b = a.flatMap(func)主要作用是,對DStream物件a,將func函式作用到a中的每個元素上並生成0個或多個新的元素。得到的DStream物件b中包括這些新的元素。
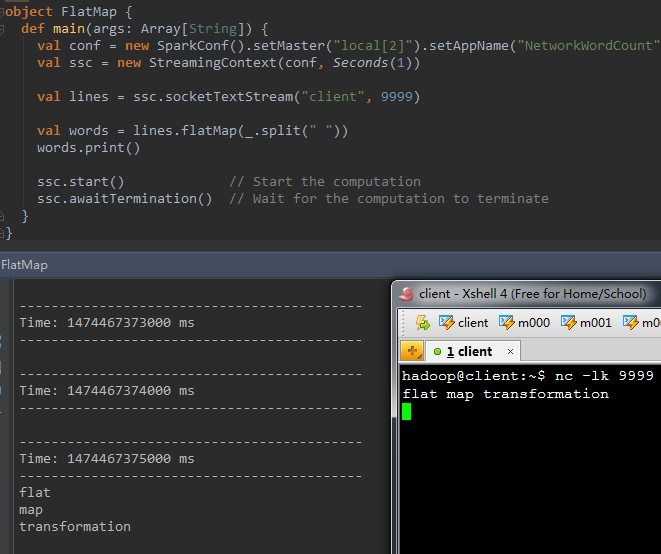
以下演示樣例程式碼的作用是,在接收到的一行訊息lines後,將lines依據空格進行切割,切割成若干個單詞
val words = lines.flatMap(_.split( " " )) 結果例如以下:
3、 filter(func)
filter傳入一個func函式,詳細呼叫形式為
val b = a.filter(func)對DStream a中的每個元素,應用func方法進行計算。假設func函式返回結果為true。則保留該元素,否則丟棄該元素,返回一個新的DStream b。
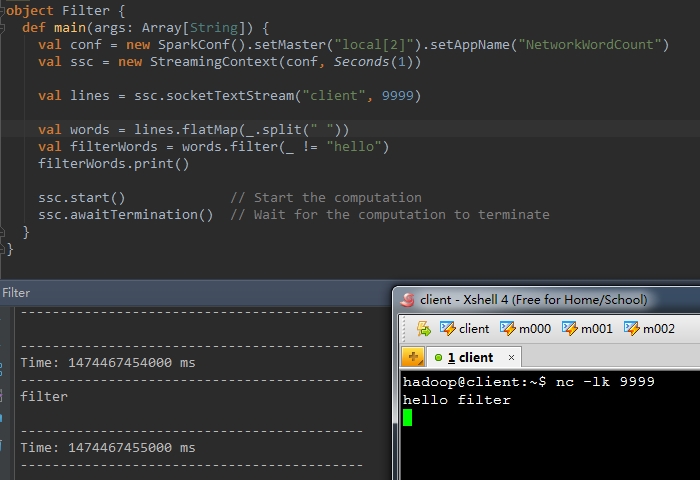
以下演示樣例程式碼中,對words進行推斷。去除hello這個單詞。
val filterWords = words.filter(_ != "hello" ) 結果例如以下:
4、union(otherStream)
這個操作將兩個DStream進行合併,生成一個包括著兩個DStream中全部元素的新DStream物件。
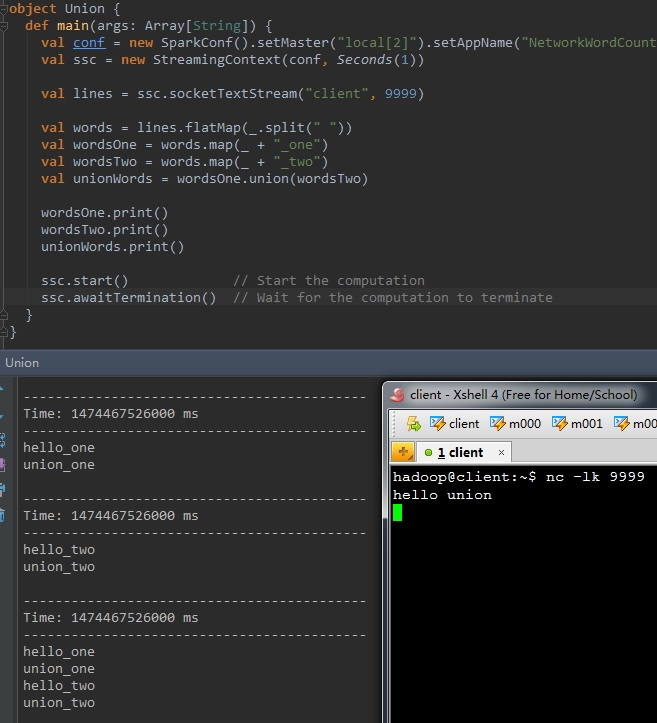
以下程式碼,首先將輸入的每個單詞後面分別拼接“_one”和“_two”。最後將這兩個DStream合併成一個新的DStream
val wordsOne = words.map(_ + "_one" )
val wordsTwo = words.map(_ + "_two" )
val unionWords = wordsOne.union(wordsTwo)
wordsOne.print()
wordsTwo.print()
unionWords.print() 執行結果例如以下:
5、count()
統計DStream中每個RDD包括的元素的個數。得到一個新的DStream,這個DStream中僅僅包括一個元素。這個元素是相應語句單詞統計數值。
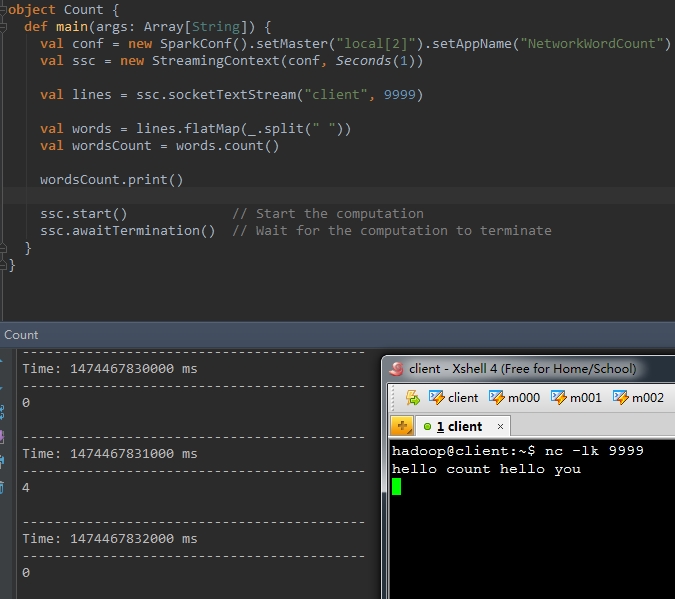
以下程式碼。統計每一行中的單詞數
val wordsCount = words.count() 執行結果例如以下,一行輸入4個單詞,列印的結果也為4。
6、reduce(func)
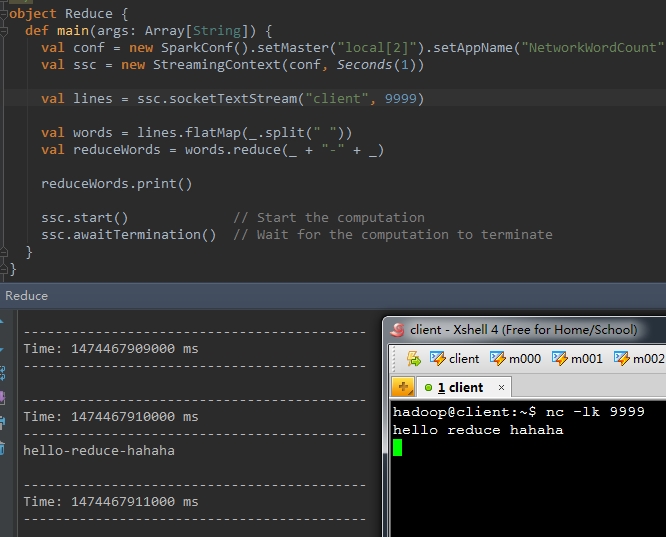
返回一個包括一個元素的DStream。傳入的func方法會作用在呼叫者的每個元素上。將當中的元素順次的兩兩進行計算。
以下的程式碼,將每個單詞用"-"符號進行拼接
val reduceWords = words.reduce(_ + "-" + _) 執行結果例如以下:
7、countByValue()
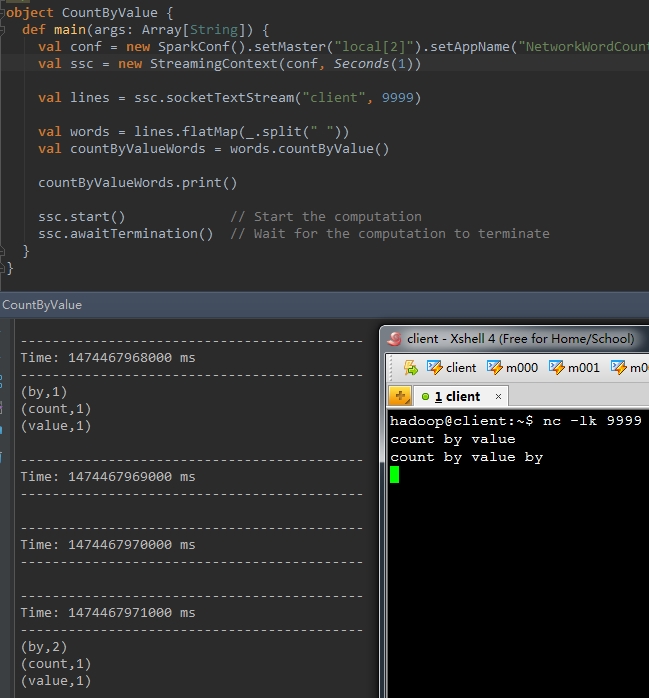
某個DStream中的元素型別為K,呼叫這種方法後,返回的DStream的元素為(K, Long)對,後面這個Long值是原DStream中每個RDD元素key出現的頻率。
以下程式碼統計words中不同單詞的個數
val countByValueWords = words.countByValue() 結果例如以下:
8、reduceByKey(func, [numTasks])
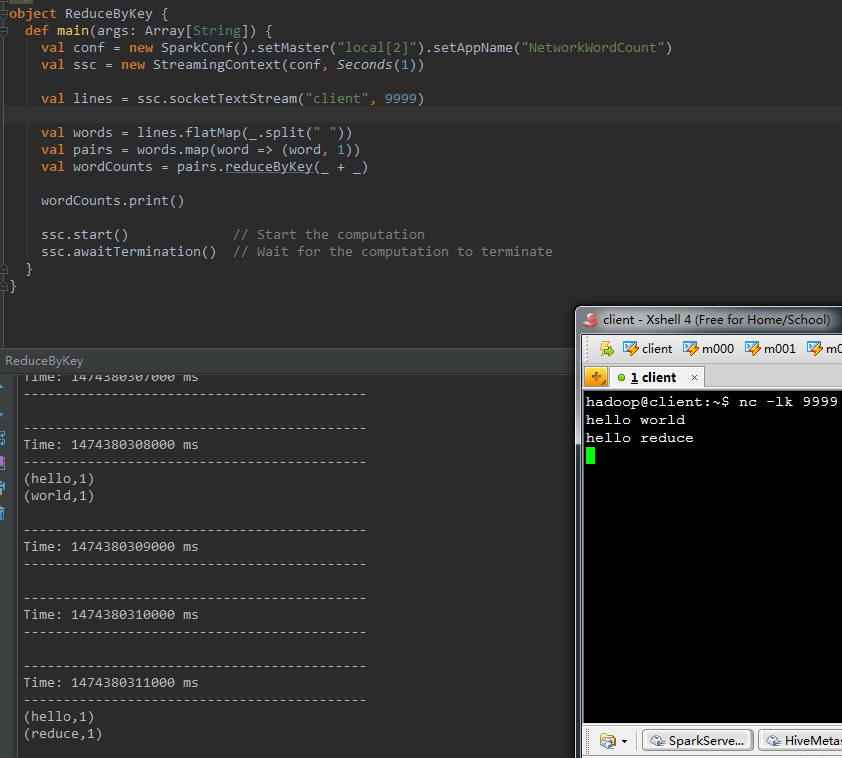
呼叫這個操作的DStream是以(K, V)的形式出現,返回一個新的元素格式為(K, V)的DStream。返回結果中,K為原來的K,V是由K經過傳入func計算得到的。還能夠傳入一個平行計算的引數,在local模式下。默覺得2。在其它模式下,預設值由引數spark.default.parallelism確定。
以下程式碼將words轉化成(word, 1)的形式,再以單詞為key,個數為value。進行word count。
val pairs = words.map(word => (word , 1))
val wordCounts = pairs.reduceByKey(_ + _) 結果例如以下。
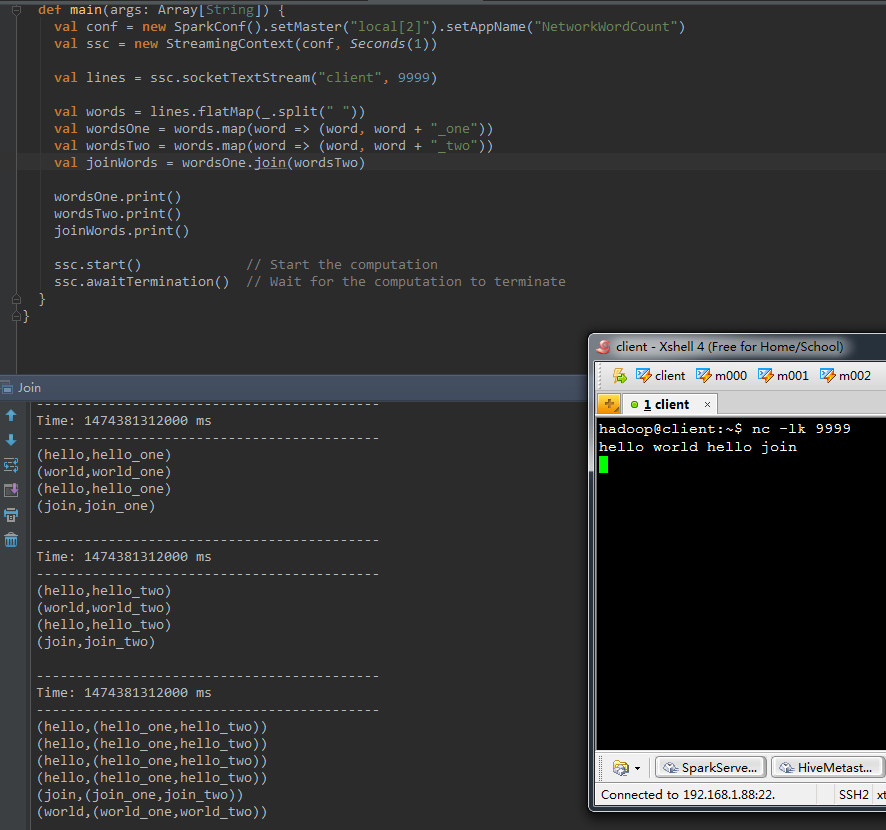
9、join(otherStream, [numTasks])
由一個DStream物件呼叫該方法,元素內容為(k, V),傳入還有一個DStream物件。元素內容為(k, W),返回的DStream中包括的內容是(k, (V, W))。這種方法也能夠傳入一個平行計算的引數,該引數與reduceByKey中是同樣的。
以下程式碼中,首先將words轉化成(word, (word + "_one"))和(word, (word + "_two"))的形式。再以word為key,將後面的value合併到一起。
val wordsOne = words.map(word => (word , word + "_one" ))
val wordsTwo = words.map(word => (word , word + "_two" ))
val joinWords = wordsOne.join(wordsTwo) 執行結果例如以下:
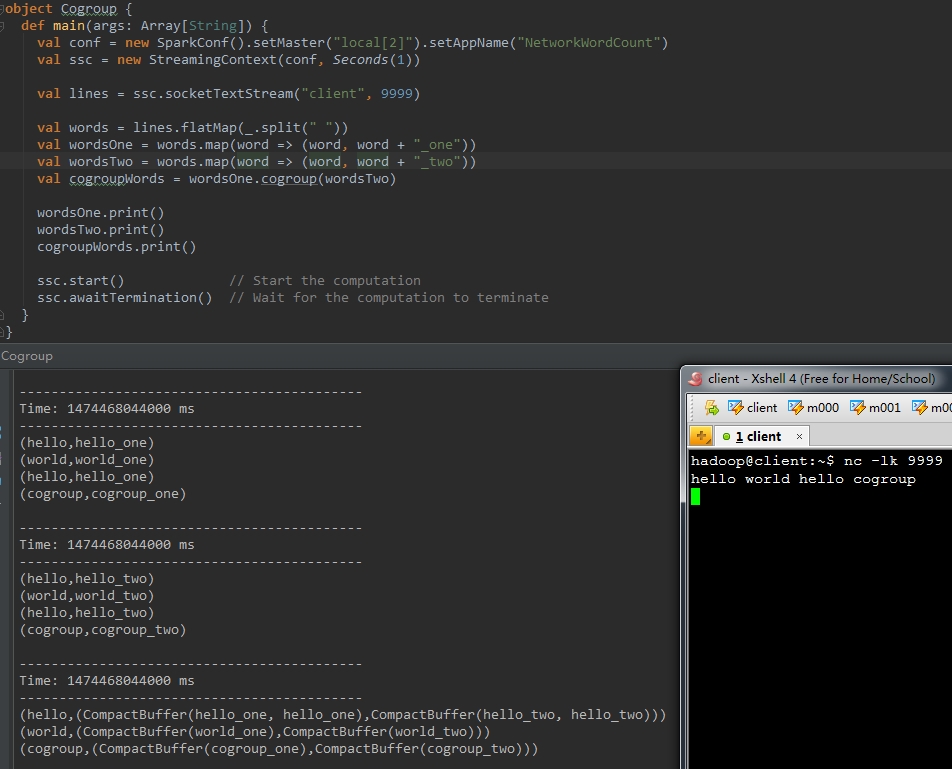
10、cogroup(otherStream, [numTasks])
由一個DStream物件呼叫該方法。元素內容為(k, V)。傳入還有一個DStream物件,元素內容為(k, W)。返回的DStream中包括的內容是(k, (Seq[V], Seq[W]))。這種方法也能夠傳入一個平行計算的引數。該引數與reduceByKey中是同樣的。
以下程式碼首先將words轉化成(word, (word + "_one"))和(word, (word + "_two"))的形式,再以word為key,將後面的value合併到一起。
結果例如以下:
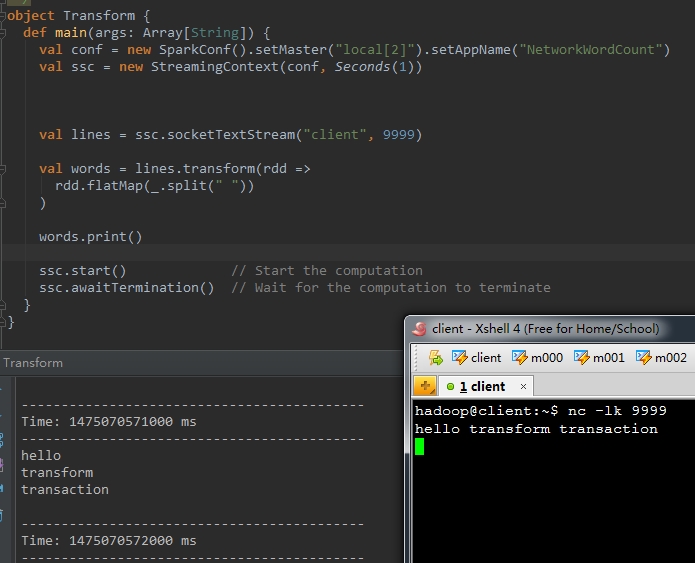
11、transform(func)
在Spark-Streaming官方文件中提到,DStream的transform操作極大的豐富了DStream上能夠進行的操作內容。使用transform操作後。除了能夠使用DStream提供的一些轉換方法之外。還能夠直接呼叫隨意的呼叫RDD上的操作函式。
比方以下的程式碼中,使用transform完畢將一行語句切割成單詞的功能。
val words = lines.transform(rdd =>
rdd.flatMap(_.split(" "))
) 執行結果例如以下:
12、updateStateByKey(func)
二、Window Operations
我覺得用一個成語。管中窺豹,基本上就能夠非常形象的解釋什麼是窗體函式了。DStream資料流就是那僅僅豹子,窗體就是那個管。以一個固定的速率平移,就能夠每次看到豹的一部分。
窗體函式,就是在DStream流上。以一個可配置的長度為窗體,以一個可配置的速率向前移動窗體,依據窗體函式的詳細內容,分別對當前窗體中的這一波資料採取某個相應的操作運算元。
須要注意的是窗體長度,和窗體移動速率須要是batch time的整數倍。
接下來演示Spark Streaming中提供的主要窗體函式。
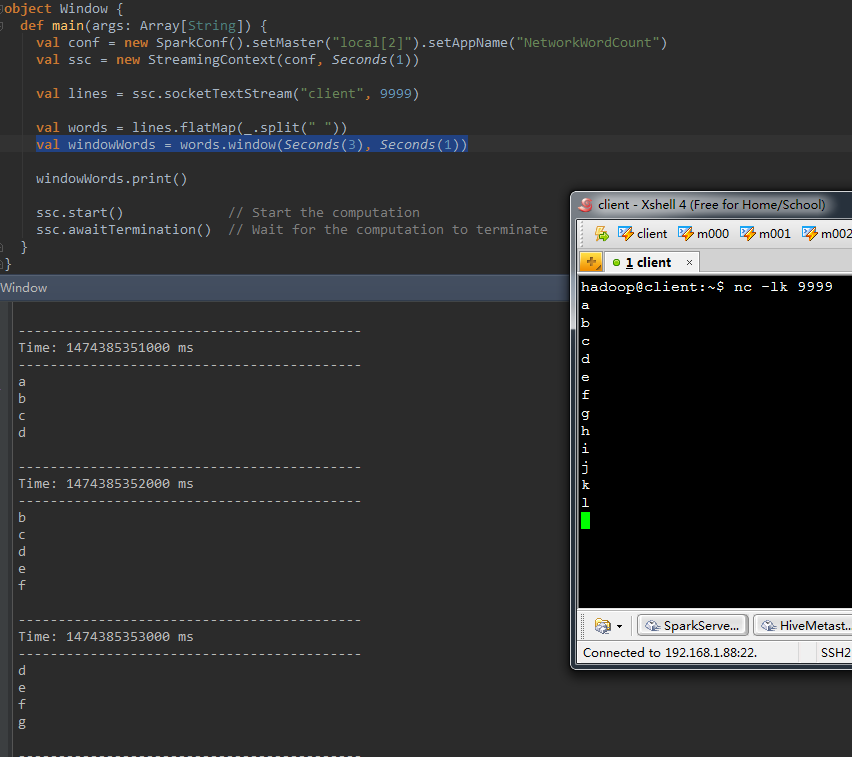
1、window(windowLength, slideInterval)
該操作由一個DStream物件呼叫,傳入一個窗體長度引數,一個窗體移動速率引數,然後將當前時刻當前長度窗體中的元素取出形成一個新的DStream。
以下的程式碼以長度為3,移動速率為1擷取源DStream中的元素形成新的DStream。
val windowWords = words.window(Seconds( 3 ), Seconds( 1)) 執行結果例如以下:
基本上每秒輸入一個字母,然後取出當前時刻3秒這個長度中的全部元素,列印出來。從上面的截圖中能夠看到,下一秒時已經看不到a了,再下一秒,已經看不到b和c了。表示a, b, c已經不在當前的窗體中。
2、 countByWindow(windowLength,slideInterval)
返回指定長度窗體中的元素個數。
程式碼例如以下。統計當前3秒長度的時間窗體的DStream中元素的個數:
val windowWords = words.countByWindow(Seconds( 3 ), Seconds( 1)) 結果例如以下:
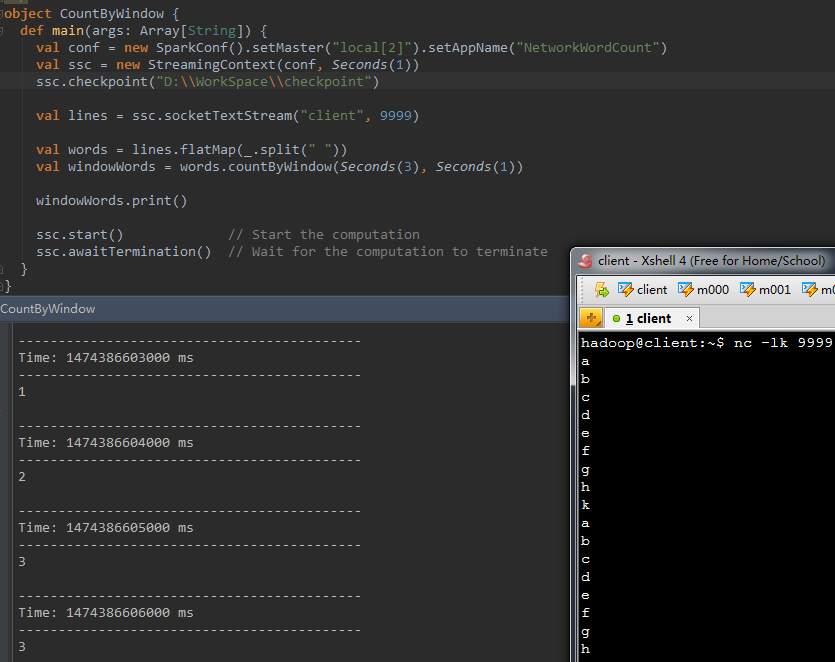
3、 reduceByWindow(func, windowLength,slideInterval)
相似於上面的reduce操作,僅僅只是這裡不再是對整個呼叫DStream進行reduce操作,而是在呼叫DStream上首先取窗體函式的元素形成新的DStream,然後在窗體元素形成的DStream上進行reduce。
程式碼例如以下:
val windowWords = words.reduceByWindow(_ + "-" + _, Seconds( 3) , Seconds( 1 )) 結果例如以下:
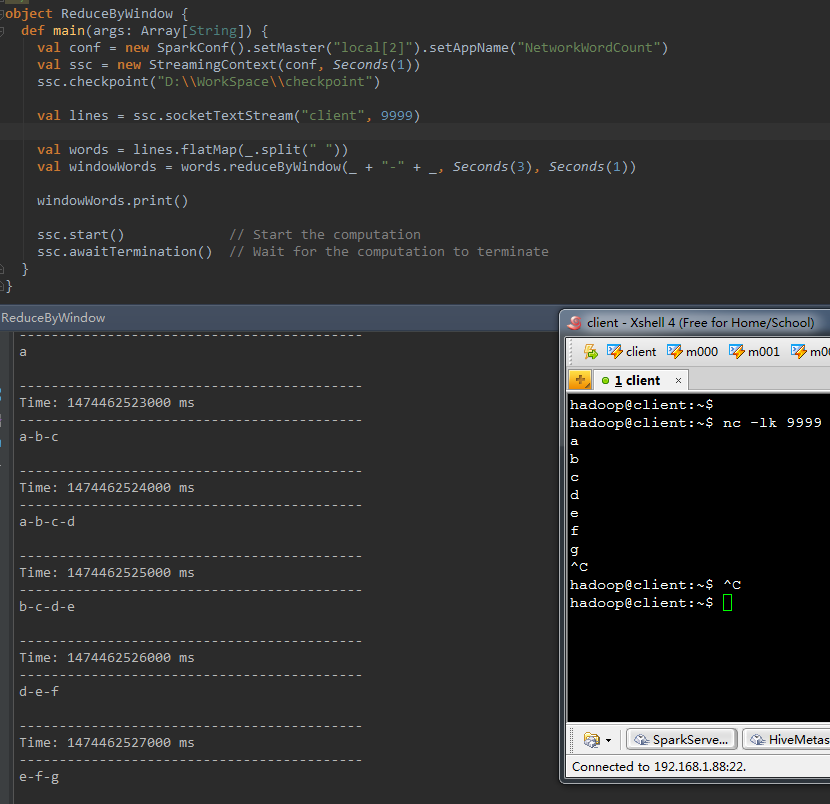
4、 reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
呼叫該操作的DStream中的元素格式為(k, v),整個操作相似於前面的reduceByKey。僅僅只是相應的資料來源不同,reduceByKeyAndWindow的資料來源是基於該DStream的窗體長度中的全部資料。該操作也有一個可選的併發數引數。
以下程式碼中,將當前長度為3的時間窗體中的全部資料元素依據key進行合併。統計當前3秒中內不同單詞出現的次數。
val windowWords = pairs.reduceByKeyAndWindow((a:Int , b:Int) => (a + b) , Seconds(3 ) , Seconds( 1 )) 結果例如以下:
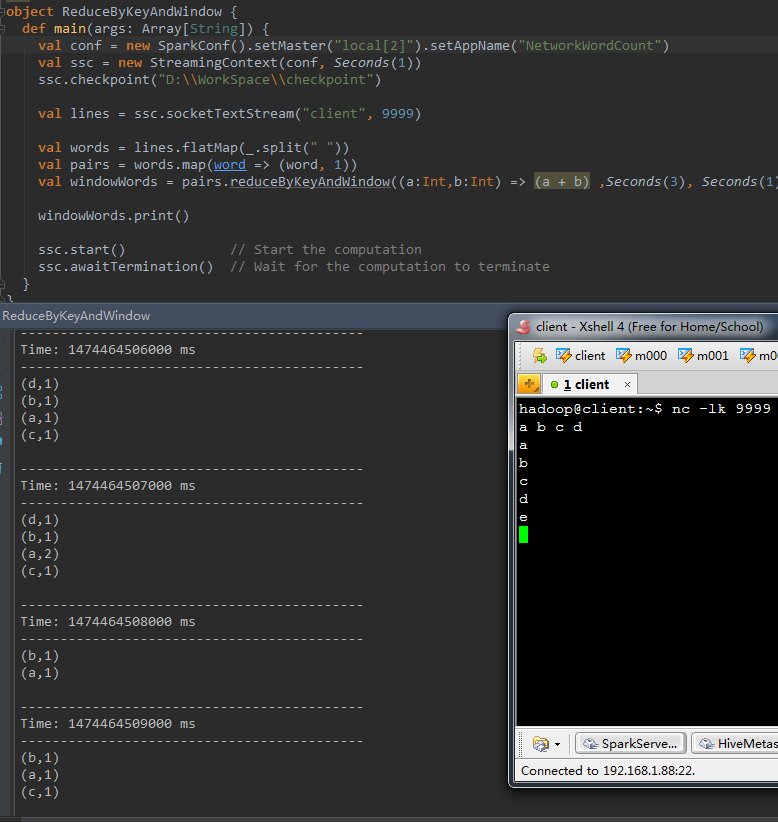
5、 reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
這個窗體操作和上一個的差別是多傳入一個函式invFunc。
前面的func作用和上一個reduceByKeyAndWindow同樣,後面的invFunc是用於處理流出rdd的。
在以下這個樣例中,假設把3秒的時間窗體當成一個池塘。池塘每一秒都會有魚遊進或者游出,那麼第一個函式表示每由進來一條魚,就在該類魚的數量上累加。
而第二個函式是,每由出去一條魚,就將該魚的總數減去一。
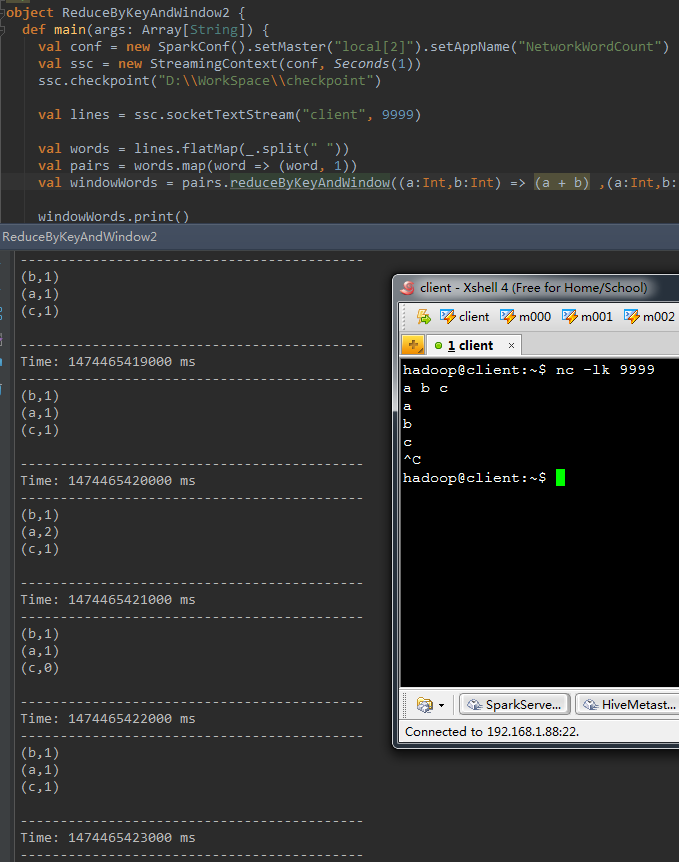
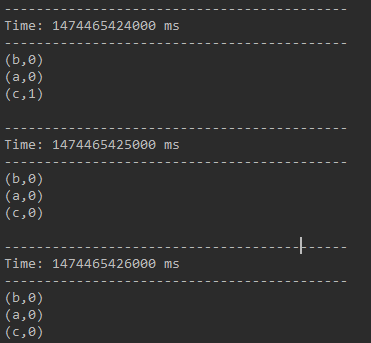
val windowWords = pairs.reduceByKeyAndWindow((a: Int, b:Int ) => (a + b) , (a:Int, b: Int) => (a - b) , Seconds( 3 ), Seconds( 1 ))以下是演示結果,終於的結果是該3秒長度的窗體中歷史上出現過的全部不同單詞個數都為0。
一段時間不輸入不論什麼資訊,看一下終於結果
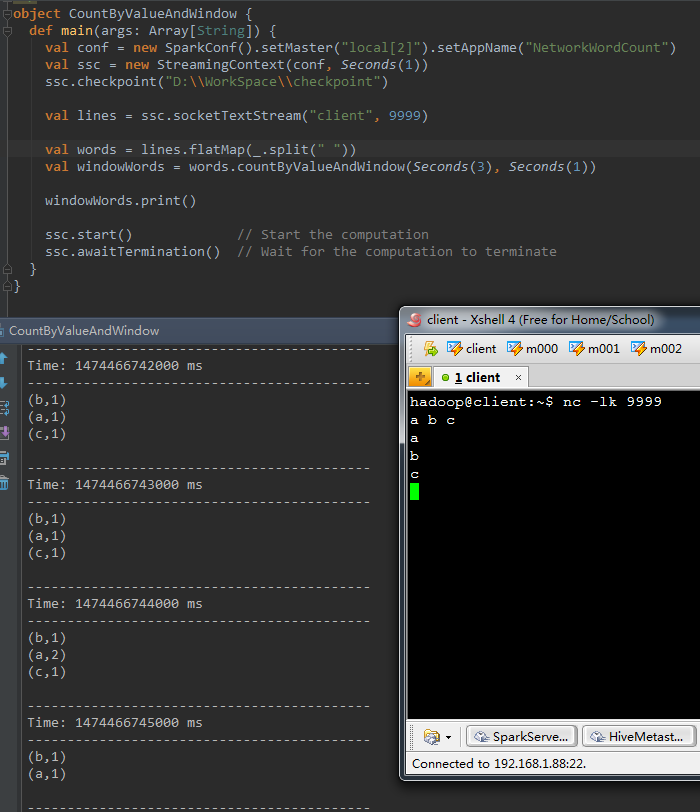
6、 countByValueAndWindow(windowLength,slideInterval, [numTasks])
相似於前面的countByValue操作。呼叫該操作的DStream資料格式為(K, v)。返回的DStream格式為(K, Long)。
統計當前時間窗體中元素值同樣的元素的個數。
程式碼例如以下
val windowWords = words.countByValueAndWindow(Seconds( 3 ), Seconds( 1)) 結果例如以下
三、Join Operations
Join主要可分為兩種,
1、DStream物件之間的Join
這樣的join一般應用於窗體函式形成的DStream物件之間,詳細能夠參考第一部分中的join操作,除了簡單的join之外。還有leftOuterJoin, rightOuterJoin和fullOuterJoin。
2、DStream和dataset之間的join
這一種join,能夠參考前面transform操作中的演示樣例。
四、Output Operations
在Spark Streaming中,DStream的輸出操作才是DStream上全部transformations的真正觸發計算點。這個相似於RDD中的action操作。經過輸出操作DStream中的資料才幹與外部進行互動。比方將資料寫入檔案系統、資料庫,或其它應用中。
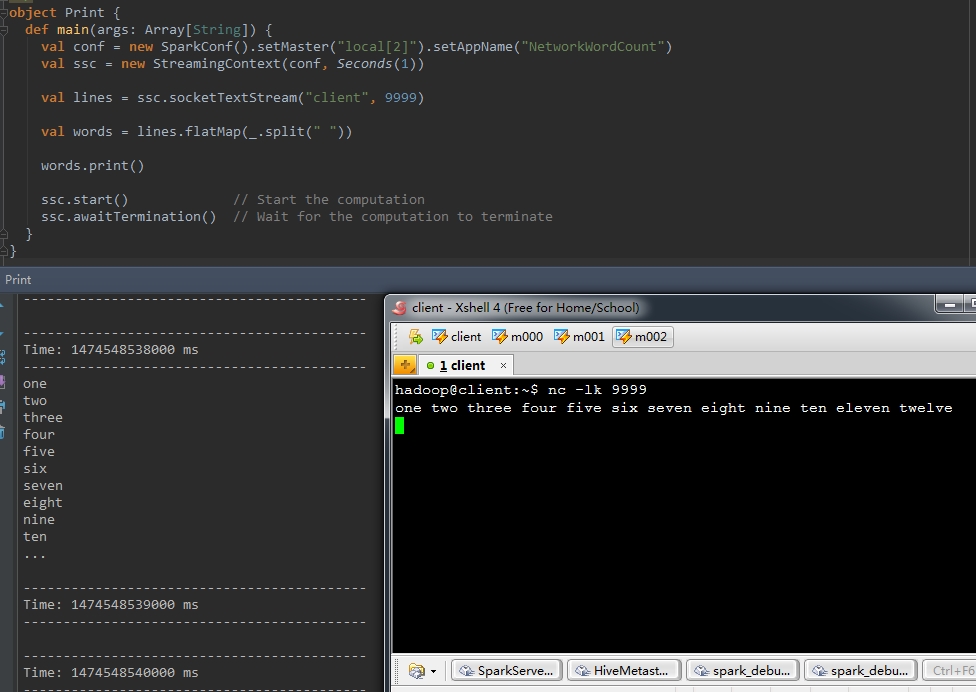
1、print()
print操作會將DStream每個batch中的前10個元素在driver節點列印出來。
看以下這個演示樣例。一行輸入超過10個單詞,然後將這行語句切割成單個單詞的DStream。
val words = lines.flatMap(_.split(" "))
words.print()看看print後的效果。
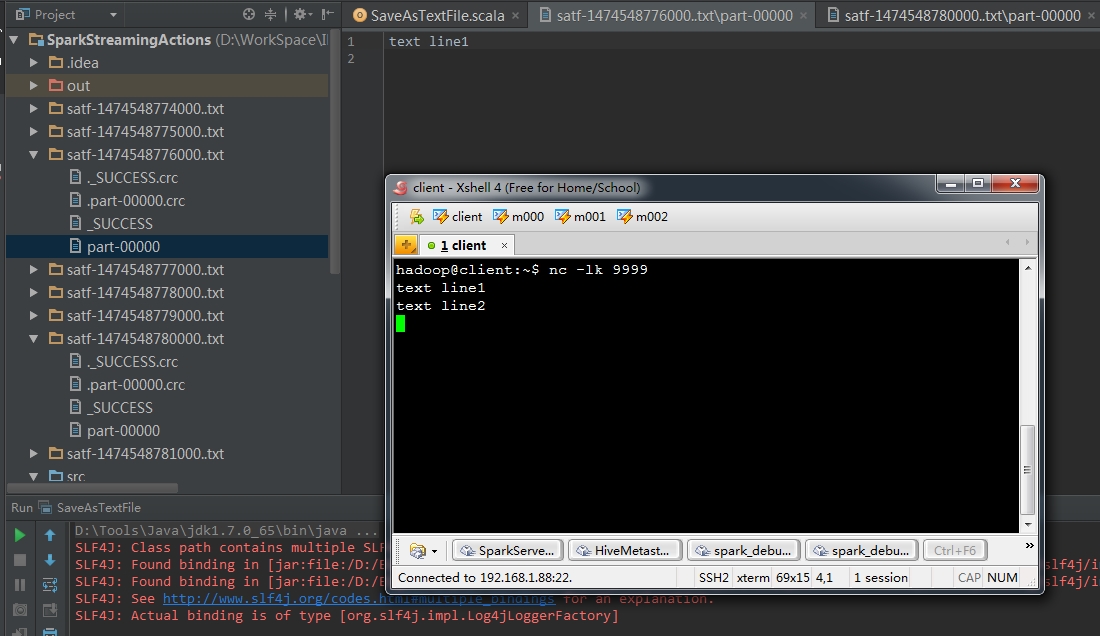
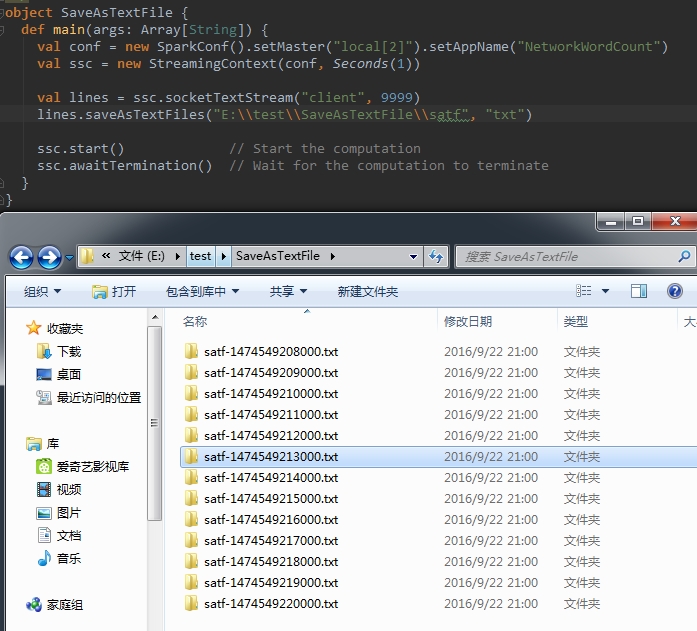
2、saveAsTextFiles(prefix, [suffix])
這個操作能夠將DStream中的內容儲存為text檔案,每個batch的資料單獨儲存為一個文夾,目錄名字首引數必須傳入,目錄名字尾引數可選,終於目錄名稱的完整形式為prefix-TIME_IN_MS[.suffix]
比方以下這一行程式碼
lines.saveAsTextFiles("satf", ".txt") 看一下執行結果。在當前專案路徑下。每秒鐘生成一個目錄。開啟的兩個窗體中的內容各自是nc窗體中的輸入。
另外,假設字首中包括檔案完整路徑。則該text目錄會建在指定路徑下,例如以下圖所看到的
3、saveAsObjectFiles(prefix, [suffix])
這個操作和前面一個相似,僅僅只是這裡將DStream中的內容儲存為SequenceFile檔案型別,這個檔案裡儲存的資料都是經過序列化後的Java物件。
實驗略過。可參考前面一個操作。
4、saveAsHadoopFiles(prefix, [suffix])
這個操作和前兩個相似,將DStream每一batch中的內容儲存到HDFS上,同樣能夠指定檔案的字首和字尾。