author: 張俊林
谷歌DeepMind開發的人工智慧圍棋程式AlphaGo以5:0的壓倒性優勢擊敗了歐洲圍棋冠軍、專業二段棋手Fan Hui。這是近期一週來最火爆的新聞了。16年3月份AlphaGo會和近期10年平均成績表現最棒的韓國九段、世界冠軍李世石進行對弈,這無疑也是最吸引眼球的一場人機世紀大戰,假設此役AlphaGo獲勝。這意味著人工智慧真正里程碑式的勝利。從此起碼在智力博弈類遊戲範圍內,碳基體人類將無法抵擋矽基類機器的狂風驟雨,不知這是該令人驚恐還是令人興奮呢?
反正我是屬於看了這個新聞像被注射了興奮劑似得那類具備反人類人格犯罪分子的興奮型別@^^@。
當然,本文的標題有點譁眾取寵,可是並非毫無依據的。
如今的問題是:三月份的人機大戰中,李世石的勝率能有多高?是AlphaGo擊敗人類還是李世石力挽狂瀾。維護人類尊嚴?此前眾說紛紜。各種說法都有。
可是看上去都是沒什麼依據的推測。我在深入瞭解了AlphaGo的AI運作機制後,斗膽做出例如以下預測,到時可看是被打臉還是可以成為新世紀的保羅。首先強調一點,我這個預測是有科學依據的。至於依據是什麼,後文會談。
假設是5番棋。預測例如以下:
假設李世石首局輸掉。那麼AlphaGo非常可能獲得壓倒性勝利,我預估AlphaGo會以4:1甚至5:0獲勝;
假設李世石首局贏,可是第二局輸掉,那麼AlphaGo可能會以3:2甚至4:1勝出;
假設李世石首局和第二局都贏,那麼AlphaGo可能會碾壓性失敗。局面可能是0:5或者1:4。
也就是說,局面非常可能是一方壓倒性勝利,要麼是AlphaGo要麼是李世石。並且首局勝敗可能起到關鍵作用。為什麼這麼說呢?我們要了解AlphaGo是怎麼下棋的。
|下圍棋的本質是什麼?
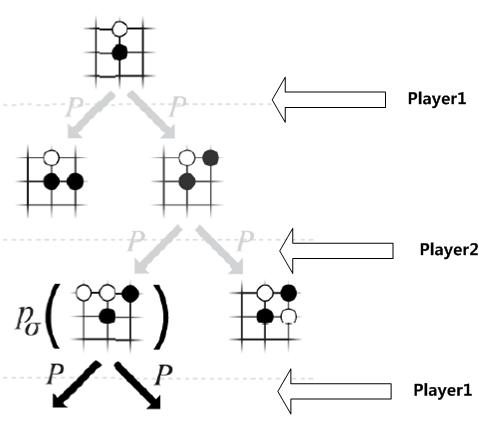
圖1 下圍棋是在幹什麼
下圍棋的本質是在幹什麼?圖1事實上基本就說明了問題了。兩個棋手(這兩個棋手可能當中一個人類一個AI。或許兩個都是人類或者兩個都是AI,這不重要)剛開始都是面對一個19*19的空棋盤,執黑先下子,下子是什麼意思?就是在當前棋局S下(剛開始S就是空棋盤),推斷下個子應該放在哪裡更好,全部合法的落子位置都在考慮範圍。比方開局第一子,不論什麼一個棋盤位置落子都是可以的。可是這裡面有些是好的落子位置,有些是不好的落子範圍,至於究竟好不好,由於棋還沒下完,臨時不知道,僅僅有最後決出輸贏才幹說這個子落得好不好。
假設黑方選定了一個落子位置。則棋局局面從S進入到S1,此時該白方下。一樣的。白方面對非常多可能的落子選擇,然後選擇一個他覺得最好的…..就這麼依次下下去,直到決出輸贏為止。
從這裡可以看出。從落第一個子到下完。整個下子的決策空間形成了一個非常巨大的樹形結構。之所以我們說圍棋難,就是由於這顆樹的寬度(就是應該落哪個子)和深度(就是一步一步輪著下子)都太大了,組合出的可能空間巨大無比。基本靠搜尋遍整個空間是不可能做到的。
所以你看到下圍棋本質是什麼。就是在這顆超大的樹搜尋空間裡面,從樹的根節點。也就是空棋盤。順著樹一路下行,走出一條路徑,路徑的末尾就是已經決出勝負的棋局狀態。
由於搜尋空間太大。所以圍棋AI不可能遍歷全部可能的下棋路徑,那麼僅僅能學習一些策略或者評估函式,依據這些策略可以大量降低搜尋空間,包含樹的寬度和深度。
有了這個基礎。我們可以講AlphaGo了。
AlphaGo的技術整體架構假設一句話總結的話就是:採用深層CNN神經網路架構結合蒙特卡洛搜尋樹。
深度學習神經網路訓練出兩個落子策略和一個局面評估策略。這三個策略的神經網路架構基本同樣,僅僅是學習完後網路引數不同而已。並且這三個策略是環環相扣的:落子策略SL是通過學習人類對弈棋局,來模擬給定當前棋局局面。人怎樣落子的思路。這是純粹的學習人類下棋經驗,它的學習目標是:給定某個棋局形式,人會怎麼落子?那麼AlphaGo通過人類對弈棋局來學習這些落子策略,也就是說SL策略學習到的是像人一樣來下下一步棋;
落子策略RL是通過AlphaGo自己和自己下棋來學習的,是在SL落子策略基礎上的改進模型。RL策略的初始引數就是SL落子策略學習到的引數,就是它是以SL落子策略作為學習起點的,然後通過自己和自己下棋,要進化出更好的自己,它的學習目標是:不像SL落子策略那樣僅僅是學習下一步怎麼走,而是要兩個AlphaGo不斷落子,直到決出某盤棋局的勝負。然後依據勝負情況調整RL策略的引數,使得RL學習到怎樣可以找到贏棋的一系列前後聯絡的當前棋局及相應落子,就是它的學習目標是贏得整盤棋,而不是像SL策略那樣僅僅預測下一個落子。
局面評估網路Value Network採用相似的深度學習網路結構,僅僅只是它不是學習怎麼落子,而是給定某個棋局盤面,學習從這個盤面出發。最後可以贏棋的勝率有多高,所以它的輸入是某個棋局盤面,通過學習輸出一個分值。這個分值越高代表從這個棋盤出發。那麼贏棋的可能性有多大;
有了上面的三個深度學習策略。AlphaGo把這三個策略引入到蒙特卡洛搜尋樹中,所以它的整體架構還是蒙特卡洛搜尋樹。僅僅是在應用蒙特卡洛搜尋樹的時候在幾個步驟整合了深度學習學到的落子策略及盤面評估。
AlphaGo的整體技術思路就是上面說的。那麼我們從這些技術原理可以得出什麼結論呢?我對各個部分的分析和結論例如以下,這也是為何本文開頭作出那個人機大戰預測的科學依據所在。
|SL落子策略
首先,我們看落子策略SL,就是那個依據人類對弈過程來學習像人一樣落子的策略。這個策略重要嗎?重要,可是僅僅靠這個策略可以戰勝人類世界冠軍嗎?我的結論是不可能,靠這個策略一萬年也贏不了人類。
為什麼呢?你要考慮到非常關鍵的一點:AlphaGo這個策略是通過看了16萬局人類對弈棋局來學習的。可是問題的關鍵是,這些下棋的人素養整體有多高?假設以職業棋手水平來衡量。平均下來整體素養事實上是不高的,裡面大量棋局是業餘選手下的。即使有不少專業選手下。高段位選手肯定不會太多。那麼AlphaGo從這些二流選手下棋落子可以學到每步棋都達到九段水平嗎?這不太可能。
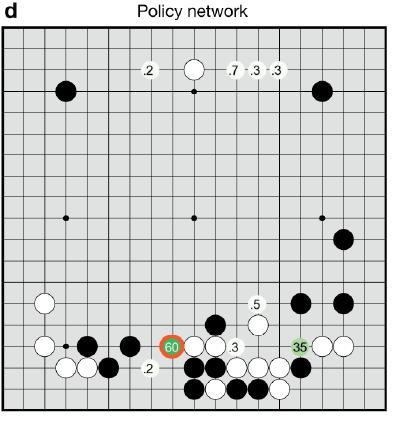
圖2 AlphaGo和fan hui對弈過程中的SL落子策略得分。圖中某些位置的得分代表AlphaGo覺得落子位置有多像人會選擇的落子位置
所以我的結論是:假設人工智慧程式僅僅能從人類棋手下的盤面學習。依照眼下的學習方式,機器永遠也無法戰勝最好的人類,由於它學習的物件平凡者居多,三流師父永遠教不出一流的徒弟。這個道理非常easy。假設僅僅用這種方法。就算AlphaGo看到再多人類的比賽也無法戰勝人類。除非它看到的都是超一流選手的盤面,那麼它可以成為超一流選手。可是面對人類最強手,並沒有必勝的把握。
那麼豈不是說三月的對決中,AlphaGo必敗無疑了?事實上不然,上面這點說的是SL策略的弱點,可是AlphaGo的論文給出了資料,SL策略比傳統單純使用蒙特卡洛搜尋樹的策略下子準確率從44%提升到了55%左右。這個55%是什麼意思?意思是SL策略做了100次落子,當中55個落子是和人落子位置同樣的。
看上去55%好像也不太高麼,沒什麼可怕的。你肯定這麼想,是吧?你錯了!
你要看44%到55%的提升幅度,由於SL策略僅僅是決定了單步落子。而單步落子小幅度的準確率提升。會極大提升終於贏棋的勝率,由於你想啊,一個棋局是由幾百個落子構成的,每一步的小幅度準確率提升。經過幾百次不斷累積,那終於結果差異是非常大的,這就是所謂的“積小勝為大勝”的道理。這是機器對人非常大的一個優勢,由於它穩定。假設準確率達到一定程度。就不easy出昏招,僅僅要依靠每一步的小優勢不斷積累就能獲得巨大的累積優勢。
人類事實上相對機器另一個非常大的劣勢:人的理性決策太easy受到情緒影響,一旦自己局面處於不利地位,或者自己下了一步臭棋,預計後面連續若干落子都會受到影響,並且下到後面人預計比較疲勞了,算棋能力下降難免,可是機器全然沒有這兩個問題,可以非常冷血非常冷靜的跟你下,下了好棋也沒見AlphaGo笑,下了臭棋也沒見AlphaGo哭。體力無敵,僅僅要你不拔它的電源插頭,它就面無表情地跟你死磕究竟,是不是這個道理?
所以說,即使AlphaGo僅僅有SL落子策略,假設它的落子水平是5段,那麼事實上考慮到這些優勢,它基本上是能穩贏人類5段這樣的同樣段位棋手的。這也是為何本文開頭預測三月人機大戰可能是如此結果的一個重要參考因素。
李世石肩上擔著這麼個重擔,並且這是世界矚目的一場比賽,他全然沒有心理負擔是不可能的,或許他看了AlphaGo和Fan Hui的棋局,如今心理上同一時候蔑視AlphaGo和Fan Hui棋力渣。可是假設初賽不利。非常可能會被冷血的機器打崩潰。
|RL落子策略
然後。我們再來看落子策略RL。
前面提到。它學習的目的和落子策略SL不一樣,落子策略SL就是學習單步怎樣像人一樣落子。至於後面這局棋是輸掉還是贏了它事實上沒學到什麼東西,它僅僅要保證說面對眼下的棋盤佈局。像人一樣落下下一個子就行了。而落子策略RL學習目標則是以贏棋為目的,是說經過若干輪博弈。終於贏棋那麼它就覺得在這個對弈過程中的相應的棋局和落子就是值得鼓舞的,並把這些鼓舞體現到深度學習模型引數裡面,意思是以後看到相似的局面,更傾向於這麼去落子,由於這麼落子非常可能終於會贏棋。它自己和自己下完一局棋。假設勝利了,那麼在這條通向勝利結果過程中的全部棋局相應的落子都會得到鼓舞。
事實上對於人類來說。這樣的自己和自己下棋的RL落子策略才是真正可怕的,由於它可以通過這樣的方式不斷自我進化。它自己和自己下了一盤棋等於幹了個什麼事情?等於說在下棋落子巨大的樹組合空間中,搜尋找到了當中一條從空棋盤開始到終於勝負已分通向勝利的一條落子路徑,而依據這個路徑是贏了還是輸了調整模型引數,使得模型以後更傾向於選擇這條路徑。意思是假設以後和人下棋。一旦有一局中某個落子方式在它的這個學習路徑中,那麼它就傾向於走出那一系列讓它贏的策略。
由於它的核心目的等於是在全部樹空間裡搜尋,然後學習找到那些easy贏的路徑,學習的結果是更傾向找到那些導致終於贏旗的路徑,這個僅僅要不斷地自己和自己下理論上能力是可以不斷提高的,由於圍棋組合出的樹空間儘管巨大無比。畢竟還是有限的,自己和自己對戰等於在不斷找出並記住那些可以贏棋的落子路徑,對戰次數越多,窮舉出這些路徑的可能性越大,也就意味著它棋力在不斷提升。
從這個角度看,這也是為何說它可怕在此處的一個原因。
當然,這個左右互搏的自閉症兒童式的自我下棋,它也不是沒有弱點,它的弱點是:AlphaGo是依據一個贏旗的路徑走的。傾向於學習這個路徑上的落子策略,可是在真實下棋過程中,或許對手不會選擇這條路徑,那麼後面學到的看似就沒用了,可是這個弱點事實上在現實場景中問題也不大:由於AlphaGo的自我下棋的對手(也是它自己)也是有一定水平的,所以對手選擇的落子也會非常高概率落在真正人類選手選擇的落子位置,即是說它選擇的這個路徑是在再次和其他對手下非常可能走的一條路,假設再全然重走這條路徑,那麼計算機必贏。
綜上分析,落子策略RL通過這樣的自我對戰來在巨大的樹搜尋空間中找到贏棋路徑的方法是比較可怕的,由於理論上它僅僅要不斷自我對弈。是可以不斷提高下棋水平的。這是人機對決中人類不樂觀的的一個方面,由於就像上面說的,僅僅要你不拔機器的電門。它就行不眠不休地去玩自閉症遊戲,事實上人工智慧不可怕,可怕的是可以不斷自我學習自我進化的人工智慧。
|棋局評估Value Network
Value Network也是通過3000萬盤AlphaGo自我對戰來進行學習的,它是建立在RL落子策略之上的,由於此刻RL落子策略已經代表了一個棋力比較高的棋手了。只是這個棋手就是AlphaGo自身而已。Value Network它要學習什麼東西?它要學的是:給定當前棋局佈局,也就是AlphaGo看到的當前棋盤情況。那麼這個棋盤佈局有多大可能會導致最後贏棋?這就是它學習的目標。Value Netwok的本質思想是:假設當前棋局處於局面S,那麼假設這時候有兩個眼下最強的棋手,就是兩個採取RL策略的棋手從局面S開始繼續往下下棋。那麼從局面S出發。終於贏旗的可能性有多大;由於這兩個RL棋手會盡可能走那些局面S出發產生的子樹裡面,它們各自覺得可以導致勝利的路徑,所以通常是樹搜尋子空間裡面easy被棋手選擇到的路徑,評估了這些路徑後綜合出這樣的棋局S終於可能勝利的可能性,獲勝可能性越大。意味著從棋局S出發的這個搜尋個子樹空間裡面通向勝利局面的路徑越多,所以它是個“大面積搜尋路徑覆蓋”的策略;
事實上綜合上面三個策略。可以看出:SL落子策略相似於點覆蓋。由於它僅僅考慮下步旗子怎麼走。僅僅覆蓋了一步棋。RL落子策略相似於線覆蓋。由於它事實上在找一條可以贏棋的走棋路徑;而Value Network相似於面覆蓋。由於它評估的是當前棋局S出發,全部可能走的搜尋路徑中綜合看通向勝利的下棋路徑有多少,越多越好。AlphaGo就是這麼利用深度學習來進行搜尋空間點線面結合來提升棋力的。
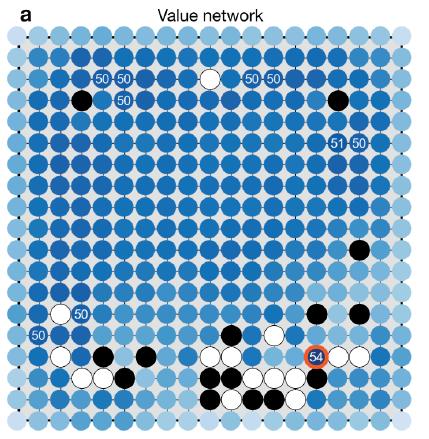
圖3 AlphaGo和Fan Hui對弈過程中,對棋局的評估,相應位置的得分意味著假設把旗子落子這個位置,那麼這個落子後的棋局最後贏棋的可能性
|蒙特卡洛搜尋樹
蒙特卡洛搜尋樹可以說是一項導致圍棋人機對戰過程中突破性的技術進展,有了蒙特卡洛搜尋樹,就把機器選手從沒資格和人類對戰帶到了有資格和業餘選手進行對戰的境界,可是僅僅靠蒙特卡洛樹是不夠的。由於樹搜尋空間太大,假設蒙特卡洛取樣太多。固然easy找到下棋的最優路徑,可是速度會太慢。跟它下人類選手會掀桌子的,所以在實戰中取樣不可能太多,那麼非常可能就找不到最優下棋路徑,這也是為何在獲得能和業餘選手對戰後,難以再獲得大的突破的主要原因。
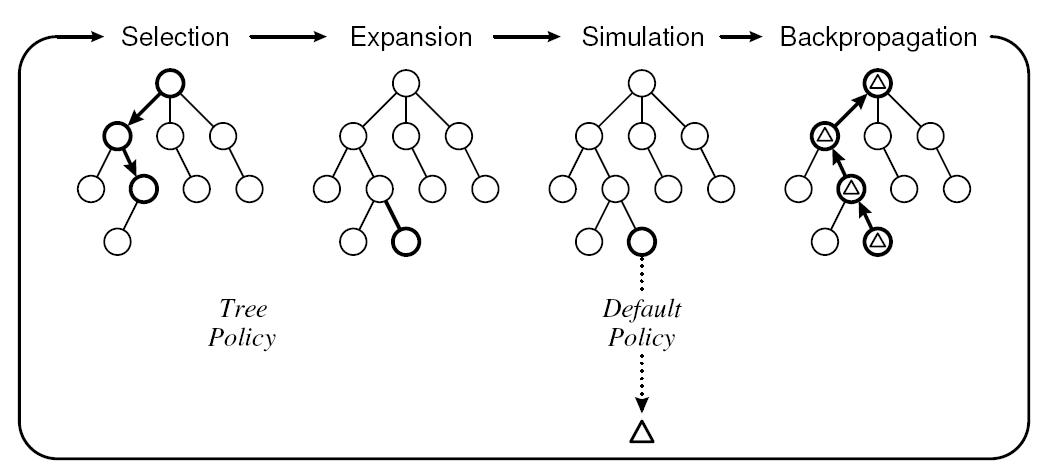
圖4. 蒙特卡洛搜尋樹
AlphaGo本質上大的技術框架還是蒙特卡洛樹。可是根本的不同在於把上面講的兩個落子策略和一個局面評估神經網路引到蒙特卡洛樹搜尋過程中。蒙特卡洛搜尋樹也須要對棋局盤面進行評估,AlphaGo採用了上面講的Value Network和傳統的取樣評估相結合的思路來做。在取樣進行過程中,要模擬兩個棋手對弈。AlphaGo採用了落子策略SL來模擬兩個對戰棋手;而落子策略RL則用在了Value Network網路中,我們講過Value Network是在RL策略基礎之上的,其作用也是相似兩個採取RL策略的棋手去下棋。
決定蒙特卡洛搜尋樹效果的事實上主要有兩個因素,一個就是上面講的取樣數量,數量越大效果越好,可是速度會比較慢,在這點上AlphaGo事實上並沒太在意。第二點是模擬兩個棋手對弈,那麼這個棋手棋力越強,那麼高速探索出優秀路徑的可能性越大,AlphaGo事實上把工作重心放在這裡了,也就是那兩個落子策略和Value Network棋局評估策略。這也是為何說AlphaGo有技術突破的地方,由於它的重心不在暴力搜尋上,而是尋找好的下棋策略。
前一陣子網上討論Facebook圍棋AI “暗黑森林”和AlphaGo誰先誰後問題。事實上你看過他們各自發的論文就明確這樣的爭論全然沒有必要。之前有幾項工作都是結合深度學習學習落子策略和蒙特卡洛搜尋樹方法結合的文獻,可是效果應該仍然徘徊在和業餘棋手對弈的階段,包含Facebook的圍棋AI,本質上並沒有跳出這個思路。導致AlphaGo和其他工作最大的不同事實上是那個通過3000萬局自我對戰產生的RL落子策略和Value Network。而這兩者在當中發揮的作用也是最大的,所以AlphaGo對圍棋AI產生質的飛越是無可置疑的。而沒有疑問的一個壞訊息是,即使3月份AlphaGo輸掉比賽,從機制上講,AI勝過人類選手是必定的,這僅僅是時間問題而已。
AlphaGo的意義不僅僅在於圍棋領域,由於DeepMind採用通用的AI技術來研發AlphaGo,其關鍵演算法可以平滑遷移到非常多其他領域。並有望在非常多其他領域獲得突破性進展。另外,我的個人意見,DeepMind是個令人尊敬的技術團隊,他們關注的都是深度學習中重大的問題並不斷有突破性成果出來,搞研究事實上就應該以這樣的團隊作為模範。
上面這段看上去好像是要結尾的意思,事實上並非,我們最後再附上一小段技術流。
|深度學習網路架構
上面講過兩個落子策略以及棋局評估神經網路,其架構都是相似的,當中兩個落子策略的架構如圖5所看到的,棋局評估神經網路的架構如圖6所看到的。
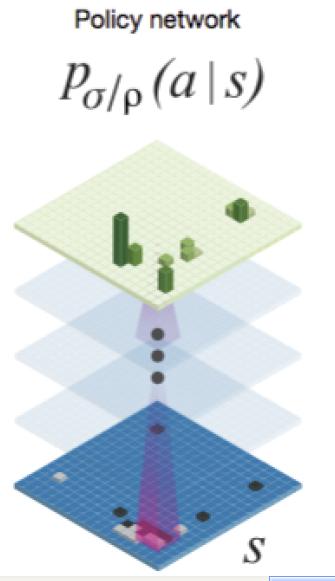
圖5 Policy Network網路結構
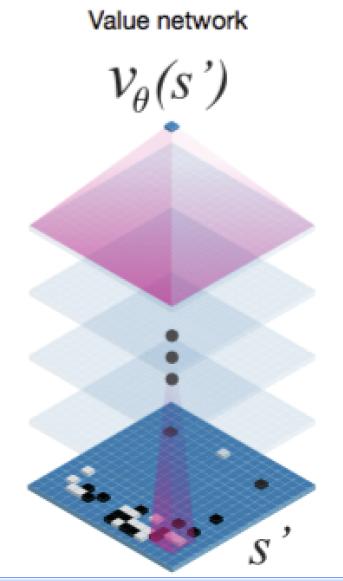
圖6 Value Network網路結構
對於兩個落子策略來說,其神經網路的輸入是19*19*48的三維資料,19*19是一個棋盤的畫面,48是由於選擇了48類特徵來從不同角度描寫敘述這個棋盤,所以輸入是三維結構。經過12層CNN的卷積層。然後最後套上一個SoftMax分類層。
輸入是棋盤局面S,輸出是針對這個棋盤局面。以下應該怎樣落子,所以SoftMax分類層給出的是各種合法落子位置的分類概率。
AlphaGo就選擇概率最高的那個位置去落子。
對於SL落子策略來說,訓練資料就是3000萬<S,a>集合,就是人下棋的過程。S是面對的某種棋局,a是人接下來把旗子放到哪裡。這樣通過CNN網路,依據輸入棋局,就能學會人大概率會把旗子落在哪個位置,所以說它學的是人怎樣單步落子。3000萬看上去多,事實上並不多。這是落子數量,真正的對弈棋局數量也就16萬局對弈過程,由於每一個對弈過程包含非常多落子步驟。所以總數看上去多而已。
對於RL落子策略來說,它學的是怎樣贏得一局,這裡用到了增強學習的Q函式。
可是學習過程跟SL是相似的,無非是兩個AlphaGo先下一盤。然後看看是輸了贏了,並把輸贏的分數賦給整個過程中的每一個棋局及其相應的落子步驟,這樣每一個棋局及其落子步驟都會有個輸贏得分,依據這個得分調整之前學到的SL落子策略學習到的引數,這樣就通過自我對弈來學會怎樣贏得一局棋。
對於局面評估Value Network來說,其網路架構如圖6所看到的,這裡和圖5的結構略微有不同。就是輸出層不是SoftMax分類。而是一個迴歸函式,學習到一個數值。而不是分類。這個正常,由於它的目的是給當前棋局一個估分,而不是學習落子策略。它的輸入是從自我對戰的3000萬局比賽中隨機抽取某個時間的棋局狀態,並賦予這個棋局狀態一個贏棋得分,然後把這些資料當成訓練資料。交給這個神經網路去學習給定一個局面,怎樣給出一個贏棋可能的打分。
好了,整個過程感覺已經說清楚了,就到這吧,覺得寫得還算不錯的話....你看著辦吧,要知道,寫東西事實上是個挺消耗時間和體力的事情,尤其是相似本文這樣的精品@^^@。
