前言:
遊戲領域, 特別是移動端的社交類遊戲, 排行榜成為了一種增強體驗互動, 提高使用者粘性的大法寶. 這邊講述在不同使用者規模下, 遊戲服務化/遊戲平臺化趨勢下, 如何去設計和實現遊戲排名榜. 本文側重於傳統關係型Mysql的方案實現, 後續會講解Nosql的作用. 小編(mumuxinfei)對這塊認識較淺, 所述觀點不代表主流(工業界)做法, 望能拋磚引玉.
需求分析
曾幾何時, 微信版飛機大戰紅極一時. 各路英雄刷排名, 曬成績. 不過該排名限制在自己的好友圈中, 而每個使用者的好友圈各不一樣, 因此每個使用者有自己的排名. 且排名按周重置清零. 一些簡單的移動端遊戲(比如2048, 沒有好友概念), 則採用簡單的全域性排名的方式, 且排名採用歷史最高.
綜上的列子, 對於遊戲排行榜, 我們可以依據屬性來進行劃分.
1). 按是否屬於好友圈劃分
* 遊戲全域性的Top N模式.
* 以自身好友圈為界的Top N模式.
2). 按時間週期來劃分
* 按時間週期重置, 比如按周清零
* 歷史最高, 沒有重置清零機制
基礎篇:
社交類遊戲, 在小規模使用者的前提下, 藉助關係型資料庫(mysql)來實現, 採用單庫單表.
定義好友表tb_friend
CREATE TABLE IF NOT EXISTS tb_friend (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id varchar(64),
friend_id varchar(64),
UNIQUE KEY `idx_tb_friend_user_id_friend_id` (`user_id`, `friend_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;使用者得分表tb_score
CREATE TABLE IF NOT EXISTS tb_score (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id varchar(64),
score int,
UNIQUE KEY `idx_tb_score_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; 評註: tb_friend表中user_id/friend_id構成複合索引, 用於維護user_id的好友列表, tb_score用於記錄每個使用者的得分情況
在該兩張表的前提之下, 如何獲取該好友的排行榜呢?
利用兩表join來實現:
SELECT tf.friend_id AS friend_id, ts.score AS score
FROM tb_friend tf JOIN tb_score ts ON tf.friend_id = ts.user_id
WHERE tf.user_id = ?
ORDER BY ts.score DESC 類似的結果如下:
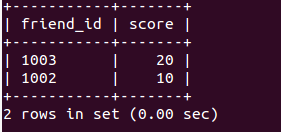
評註: 在sql的join中, 需要注意left join/equal join/right join的區別. 這邊選用等值join.
效能評估和執行分析:
1). 小表+大表模式: 在tb_friend單表9801條(100個小夥伴, 互為好友)/tb_score單表53條(53個小夥伴有得分)記錄下, 進行join分析
執行規劃
EXPLAIN
SELECT tf.friend_id AS friend_id, ts.score AS score
FROM tb_friend tf JOIN tb_score ts ON tf.friend_id = ts.user_id
WHERE tf.user_id = ?
ORDER BY ts.score DESC 
評註: 這邊sql優化器非常的智慧, 藉助了小表驅動大表的join優化方式(小表tb_score驅動大表tb_friend進行join), 小表用到了file sort(總共53行記錄), 大表用了index(等值join對應一行大表記錄).
2). 等表模式: 在tb_friend單表19602條/tb_score單表5092條記錄下, 進行join分析

評註: 這邊tb_friend表驅動tb_score作join, tb_friend藉助複合索引(user_id,friend_id)來加速優化. Mysql的sql優化器還是相當的智慧和強大.
進階篇:
隨著資料規模越來越大, 併發訪問量的增加, mysql的訪問逐漸變成瓶頸. 同時該join的sql語句涉及的filesort非常耗CPU的. 如何破解這種狀況?
*) 引入分散式mysql叢集, 進行分庫分表.
分庫分表作為網際網路的一大神器, 作用立竿見影. 但是有所得,就會有所失, 分庫分表後, 會失去很多特性. 比如事務性, 外來鍵約束關聯. 在業務這層, 會導致涉及使用者的tb_score, tb_friend表資料不在同一庫中, 進而導致join失效. 最終導致, 在應用層做merge, 使得排名操作演變成 1+N sql操作(1 sql 用於獲取好友列表, N sql 用於獲取每個好友的得分). 這需要注意.
1+N的SQL演化, 應用層做得分排序, 效能會演變成一場災難.
(1) 獲取使用者好友列表
SELECT friend_id FROM tb_friend_{N} WHERE user_id = ?
(2) 遍歷獲取每個好友的得分
foreach friend_id in friend_list(?)
SELECT score FROM tb_score_{M} WEHRE user_id = ?
(3) 應用層做得分排序 評註: {N},{M}是指具體的分表數, 當然在同一庫同一表, 可以藉助SELECT * IN (...)來優化,這個得看具體的資料分佈. 不過是種很好的思路.
小編觀點: 由於tb_friend是大表, 而tb_score是小表, 因此tb_friend採用分庫分表(以user_id作為依據)的方式去實現, 而tb_score採用單庫單表(便於批量查詢)的方式實現.
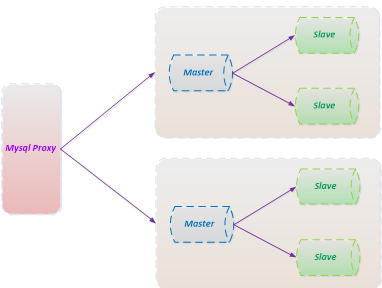
當然在工業界, Mysql的優化方案非常的成熟, 不光是分庫分表,還有主從分離(Master/Slave機制, Master用於寫服務, 多Slave節點提供讀服務).
可以參見如下的圖示:
總結&後續:
這邊主要講述基於傳統關係型資料庫mysql來實現基於好友的遊戲排行榜, 個人的戰績需要實時的去獲取, 而好友列表的戰績能允許有一定的延遲. 而好友戰績的排序實現,就成為了本文的中心議題. Mysql的實現方案在資料量/併發數增加的前提下,還是顯示了一定的疲態. 下文將講解, 如何引入Nosql系統, 在遊戲rank中,扮演重要的角色. 期待你的關注.