程式碼審查“查”什麼?
讓我們來談談程式碼審查(Code Review)。如果花幾秒鐘去搜尋有關內容,你會發現許多論述程式碼審查好處的文章(例如,Jeff Atwood的這篇文章)。你還會發現許多介紹如何使用程式碼審查工具的文件,比如我們常用的Upsource。但能夠在你審查他人程式碼時指導查什麼的內容卻很少見。
或許沒有明確審查條目的原因是:有太多不同的因素需要考慮。就像對任何(功能性或非功能性)需求,個體組織對各個方面的優先順序都有不同的考慮。
由於文章主題覆蓋面廣,本文旨在概述了程式碼審查者在程式碼審查時可以關注的一些方面。各方面優先順序的分配和持續檢查是一個非常複雜課題,具有研究價值。
審查他人程式碼時,查什麼?
無論是使用 Upsource 類似工具審查程式碼,還是在同事查他們程式碼期間,不管哪種情況,相比較而言評審有些內容要更容易。例如:
格式:在什麼地方放置空格和斷行符?使用製表符還是空格?大括號如何放置?
風格:變數、引數是否宣告為final?函式變數的定義是否與呼叫程式碼或函式開始程式碼太相似?
命名:域、常量、變數、引數、類的名稱是否符合標準?命名是否太短?
覆蓋測試:這段程式碼是否進行了測試?
這些檢查都是有意義的——你希望儘可能減少不同程式碼間的上下文切換並減少認知負荷,那麼程式碼看上去越一致越好。(譯者注:認知負荷(Cognitive Load)是指人在完成任務過程中進行資訊加工所需要的認知資源的總量。)
但是,人工審查這些內容可能沒有充分利用團隊的時間和資源,因為其中大部分檢查可以自動化。許多工具都能確保程式碼格式一致,包括命名和 final 關鍵字的使用規範,而且能發現簡單程式設計錯誤造成的常見bug。例如,你在命令列中執行IntelliJ IDEA的檢查,那麼就不需要所有團隊成員在他們的整合開發環境中進行相同的檢查。
你應該審查什麼?
哪些事情適合程式碼審查者做?在程式碼審查時,哪些事情是工具不能代勞的?
事實上,程式碼審查者可以做的事情很多。當然,下面給出的不是一份詳盡的列表,這裡也不會深入探討其中的任何一項。相反,這應該是團隊交流的起點,現在你們在程式碼審查中關注什麼,也許正是你們需要審查的內容。
設計
新程式碼是否與整體架構匹配?
程式碼是否遵循SOLID原則、領域驅動設計以及團隊喜愛的其它設計模式。
新程式碼採用哪些設計模式?這些模式合適嗎?
如果程式碼庫採用混合標準或設計風格,新程式碼是否符合當前風格?程式碼遷移是按正確的方向進行,還是效仿即將被淘汰的陳舊程式碼?
程式碼是否處於正確的位置?例如,如果程式碼執行與順序有關,它是否能按順序執行?
新程式碼能否複用部分已存在程式碼?新程式碼能否給已存在程式碼提供複用部分?
新程式碼是否包含冗餘程式碼?如果包含,是應該重構成更加可複用部分,還是在這個階段能接受這種冗餘?
程式碼是否超出設計標準?這種複用構造現在是不是不需要?團隊如何根據YAGNI權衡複用?
可讀性與可維護性
命名(欄位、變數、引數、函式以及類)能否反映它們代表的事物?
通過閱讀程式碼,我能否理解程式碼的目的?
我能否理解測試的目的?
測試是否覆蓋了絕大部分情況?是否覆蓋常見情況和異常情況?是否存在沒考慮到的情況?
異常錯誤訊息是否易於理解?
難以理解的程式碼段是否進行了備註、評論或者使用易懂的測試案例進行覆蓋(符合團隊的偏好)?
功能
程式碼的實際工作是否符合預期?如果有自動化測試來確保程式碼的正確,測試能否測出程式碼滿足約定要求?
程式碼看上去是否含有細微錯誤,比如使用錯誤變數進行檢查,或者把 or 誤用為 and?
你是否考慮過……?
程式碼中是否存在潛在的安全問題?
是否需要滿足規範要求?
對於沒有覆蓋自動化效能測試的程式碼段,新程式碼是否引入了不可避免的效能問題,比如不必要的資料呼叫或遠端服務?
作者是否需要建立公共文件,或者修改現有的幫助文件。
展示給使用者的訊息是否檢查無誤?
是否存在導致產品崩潰的明顯錯誤?程式碼是否會意外指向測試資料庫,或者是否有應該替換成真正服務的硬編碼存根程式碼?
請關注本部落格中詳細探究這些主題的文章。
如何編寫“良好”程式碼是每個開發者都能各抒己見的主題。如果你有一些可以加入我們列表的內容,希望能在評論中收到你的回覆。
在上一篇我們談了很多可以在程式碼審查時留意的事情。現在我們會聚焦這個關注點:在測試程式碼中找什麼。
本文假定:
你的團隊已經為程式碼寫過自動化測試。
測試在持續整合(CI)環境下定期執行。
審查的程式碼已經經過自動編譯和測試流程,結果也通過了。
這篇中我們會將介紹審查者在檢視測試時需要考慮的事情。
新的或修改的程式碼有測試嗎?
無論是修改 bug 還是新功能開發,幾乎沒有新程式碼不需要一個新的或更新過的測試去覆蓋它。甚至類似效能這樣的非功能性修改,也被證明往往需要經過測試驗證。如果在程式碼審查中沒有測試,作為審查者你應該問的第一個問題是“為什麼沒有測試?”。
測試有覆蓋到程式碼中令人困惑或者複雜的部分嗎?
比提出“有測試嗎?”這個問題更進一步是要回答這個問題,“重要的程式碼是否被至少一個測試覆蓋?”。
檢查測試覆蓋率無疑是應該自動化的。但我們不僅僅可以檢查覆蓋率的明確百分比,還可以使用覆蓋率檢測工具來確保被覆蓋到的程式碼位於正確的位置。
考慮下面這個例子:
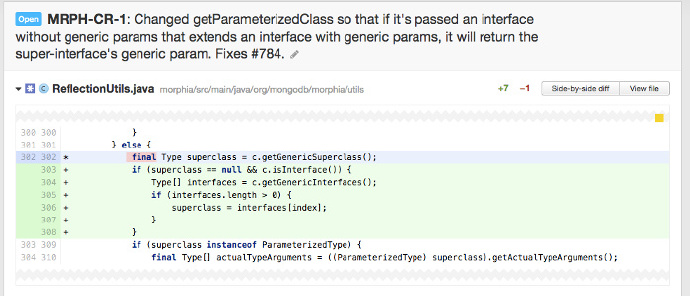
你可以檢查新程式碼(應該容易識別,特別是當你使用類似 Upsource工具)的測試覆蓋率報告以確保充分覆蓋。

上面這個例子,審查者可以讓作者增加一個測試去覆蓋 303 行 if 判斷為真的情況,因為測試工具標記304-306 行為紅色,說明他們沒有被測試到。
對於任何團隊而言,100 % 的測試覆蓋都是不現實的目標,深入瞭解哪些程式碼需要被覆蓋到,比工具得出的數字更有用。
你特別想檢查所有的邏輯分支和複雜的程式碼都有被覆蓋到。
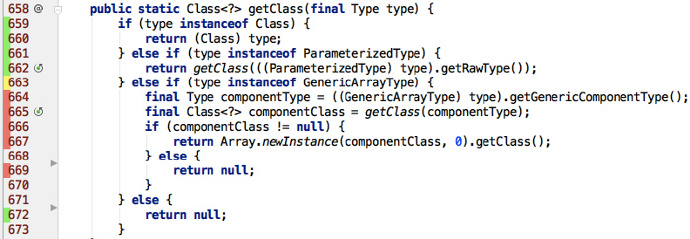
我能理解這些測試麼?
進行測試,提供滿意的測試覆蓋率是一件事,但如果我這個人無法理解這些測試,那它們的使用就被限制了。當它們出了問題該怎麼辦?很難知道要如何修復它們。
考慮下面這個測試:
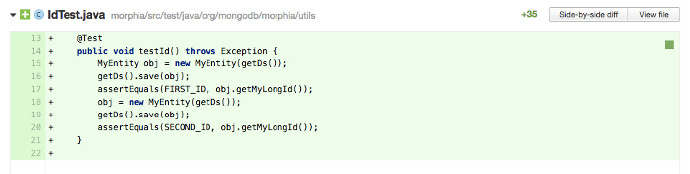
這是一個很簡單的測試,但是我並不完全確定它測試什麼。它是測試 save 方法?還是 getMyLongID ?而且為什麼同樣的事需要做兩遍?
下面測試的意圖可能更清楚:
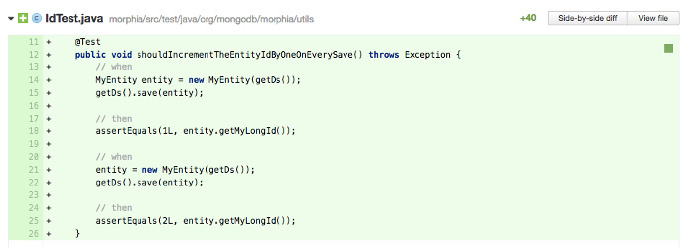
闡述測試目的所採取的特定步驟,取決於你使用的語言、庫、所在團隊和個人喜好。這個例子證明通過選擇清楚的名字、內聯常量和增加註釋,作者可以讓一個測試對於開發者而言更容易閱讀,而不僅是他(她)自己。
這些測試需要滿足什麼要求?
這是一個需要專門知識的領域。無論這些稽核的程式碼需要滿足的需求是在正式文件裡,或許在一張使用者故事卡中,還是在使用者提交的 bug裡,被審查的程式碼都需要滿足一些基本要求。(譯者注:在scrum開發流程中,使用者故事 User-Story 是從使用者的角度來描述使用者渴望得到的功能,通常寫在一張卡片上)
審查者應該找到最初的需求來確認:
無論是單元測試、端對端測試、還是其它的測試,這些測試是否滿足這些要求。比如,如果要求是“允許特殊字元‘#’,‘!’ 和 ‘&’ 出現在密碼欄位”,就應該有一個在密碼欄位使用這些值的測試。如果測試使用其它的特殊字元,則不能證明程式碼符合要求。
測試需要覆蓋所有的要求。在我們特殊字元的例子中,要求可能繼續“……如果輸入了其它特殊字元,給使用者提示一個錯誤資訊”。審查者在這裡應該檢查是否有一個測試來確認當使用一個錯誤字元會發生什麼。
我可以考慮沒有被現有測試覆蓋到的用例嗎?
通常我們的要求不是清晰明確。在這種情形下,審查者應該考慮最初的 bug、問題、用例中沒有考慮到的邊界條件。
例如,我們有一個新功能,即“讓使用者可以登入系統”,審查者應該想:“如果使用者輸入的使用者名稱為空會發生什麼?”。或者“如果系統中不存在該使用者,會發生什麼錯誤?”。如果被審查程式碼有這些測試,審查者就比較有信心程式碼本身會處理這種情況。反之,如果這些異常用例不存在,審查者就不得不仔細檢查程式碼,看它們是否有正確處理。
如果程式碼裡有但沒有相應的測試,要由團隊決定你們的策略 —— 是否需要讓作者加上這些測試?或者你覺得通過程式碼審查保證邊界條件被覆蓋到就好了?
這些測試是否有說明程式碼的限制條件?
審查者經常會看到審查程式碼中的限制條件。這些限制條件有時是故意設計的 —— 例如,一個批處理最多隻能處理 1000 個條目。
一種說明這些刻意限制條件的方法就是明確地測試他們。在上個例子,我們可以用一個測試來證明當批處理大小超過 1000,會有某種異常發生。
自動化測試中,不必表明這些限制條件,但如果作者寫了一個測試表明他們實現中的這個限制,這就意味著這些限制是有意的(有文件說明的)而不是疏忽造成的。
審查程式碼中的測試型別、測試級別正確嗎?
例如,如果單元測試就足夠了,作者還需要做昂貴的整合測試麼?他們寫的效能微基準能不能在 CI 環境下以一致方式有效地執行呢?
理想情況下自動化測試會盡可能快地執行,這樣就不需要用昂貴的端對端測試去檢查所有型別的功能。用一個數學運算或者布林邏輯檢查的函式,可以很好地替代方法級單元測試。
有沒有針對安全性的測試?
程式碼安全性可以從程式碼審查中受益。我們後續將有一篇安全方面的文章,但就測試而言,我們可以編寫測試覆蓋一些常見問題。例如,我們上面提到的登入程式碼,我們可以寫一個測試,看如果沒有授權我們是否無法進入網站中被保護的區域(或稱為保護 API 方法)。
效能測試
在上篇中我談到效能是審查者需要檢查的部分。自動化效能測試是另外一類測試,我本可以在本篇探討,但後面會寫一篇在程式碼審查中具體看效能方面的文章,我們在那裡再討論這種型別的測試。
審查者也可以寫測試
不同組織有不同的程式碼審查方法 —— 有時非常明確地要求作者負責所有的程式碼改動,有時會和審查者協作由審查者自己提交程式碼的評審建議。
無論採取哪種方法,作為審查者你會發現,寫一些額外的測試去玩一下審查的程式碼,對於理解程式碼是很有幫助的。類似地,你也可以啟動UI介面嘗試一下新功能,同樣也是很有意義的。有些方法和工具可以很容易被用來試驗程式碼。從團隊的利益出發,在程式碼審查中要讓程式碼和玩程式碼變得儘可能容易。
提交額外的測試作為審查的一部分當然很好,但也不是必須的,例如這個實驗已經給我這個審查者滿意的答案。
總結
無論你在組織中如何執行,做程式碼審查有很大好處。程式碼審查可以在程式碼整合到主線之前,就發現程式碼中可能出現的問題。這個階段,開發者還記得來龍去脈,修正問題的成本也不高。
作為一個程式碼審查者,你應該要檢查最初的開發者放在他(她)程式碼中的想法,哪些情況下會變壞,處理邊界條件,用自動化測試“記錄”預期的行為(正常條件和異常情況)。
如果審查者查詢已有的測試,檢查測試的正確性,那麼你們團隊對程式碼會很有信心。而且,如果這些測試在 CI 環境下被定期執行,你可以看到這些程式碼一直可以工作 —— 他們提供了自動化迴歸檢查。如果程式碼審查者很看重他們審查的程式碼,要求高質量的測試,那麼這個程式碼審查的價值在審查者按下“接受”按鈕後,還會延續下去。
在程式碼審查系列的第三篇,我們將涉及就效能而言審查程式碼時需要留意什麼。
和所有的架構或設計領域一樣,一個系統效能的非功能性要求應該在前期就確定下來。無論你是工作在一個響應要求在納秒級別的低延遲交易系統上,還是在建立一個需要響應客戶的線上商店,或者正在編寫一個電話應用去管理 “待辦事項”列表,對“太慢”都要有相應的認識(譯者注:環境不同,含義不同)。
讓我們來討論一些影響效能的事情,審查者可以在程式碼審查時留意。
首先
這部分功能有硬性的效能需求嗎?
這部分審查的程式碼是否屬於一個以前釋出的服務層級協議(Service Level Agreement SLA)?或者在需求中有規定必需的效能指標嗎?
如果最初的需求來自於一個bug —— “登入介面載入太慢”,最初的開發者應該搞清楚一個合理的載入時間是多少 —— 否則審查者或者作者如何相信這個優化後的速度滿足需求?
如果有,有測試去檢查嗎?
任何對效能敏感的系統都應該有自動化測試,來保證可以滿足公佈的 SLA(在 10 ms 內為所有訂單需求提供服務)。如果沒有這些,你就只有等到客戶投訴時才知道你沒有滿足 SLA。 這不僅讓使用者感覺很糟,而且還會導致了不必要的罰款和費用。在這系列的上一篇裡,已經詳細討論了程式碼審查的測試部分。
功能修改或新功能對已有效能測試結果有不良影響嗎?
如果你會定期執行效能測試(或者你有一套可以按需要執行的測試集),應該檢查對效能有嚴格要求部分的新程式碼,確保它不會造成系統效能下降。 這可以是一個自動化的流程,但效能測試通常不像單元測試那麼普遍地被整合到 CI 環境中,所以值得強調這一審查步驟。
程式碼審查中沒有硬性的效能需求要怎麼做?
如果經過數小時的痛苦,只節省了一點點 CPU 週期,這樣的優化實在划不來。但有些事情如果審查者檢查了,就可以保證程式碼不會存在常見的效能缺陷 (完全可以避免)。檢查列表的其他部分,看是不是有簡單的方法可以防止未來可能出現的效能問題。
服務或應用外的呼叫開銷很大
在自己的應用之外使用需要跨網路躍點的系統和使用一個優化很差的 equals() 方法相比,前者開銷更大。請考慮這些:(譯者注:網路躍點 network hop 即路由。一個路由為一個躍點。傳輸過程中需要經過多個網路,每個被經過的網路裝置點(有能力路由的)叫做一個躍點,地址就是它的 IP)
資料庫呼叫
最大的麻煩可能躲在抽象後面,比如 ORM(Object Relational Mapping,物件關係對映)。但在程式碼審查時,你應該能夠找到效能問題的常見原因,就像一個迴圈裡的多次資料庫呼叫 —— 例如 ,載入一個 ID 列表,然後基於每個 ID 查詢資料庫裡的對應專案。
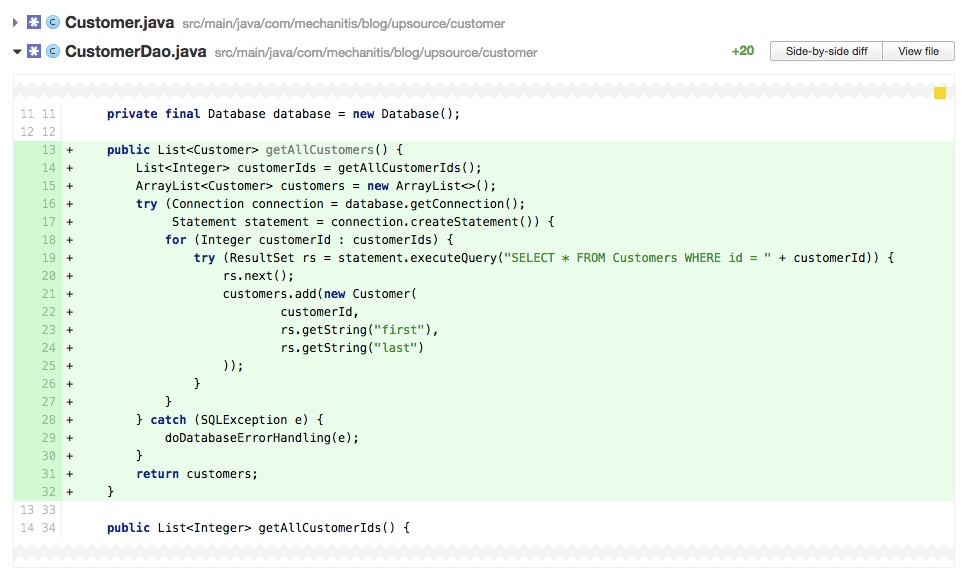
(↑↑↑ 點選可檢視大圖,下同)
例如 ,19 行看起來沒有什麼問題(無辜的),但它在一個 for 迴圈裡 —— 你不知道這行程式碼會導致多少次資料庫呼叫。
不必要的網路呼叫
如同資料庫,有時遠端服務也被過度使用。就像有些地方使用了多次遠端呼叫,其實一次就足夠了,或者可以用批處理或快取避免開銷巨大的網路呼叫。另一個和資料庫類似的是,一個抽象有時候會隱藏一個實際在呼叫遠端 API的方法呼叫。
移動程式、可穿戴程式過於頻繁地呼叫後端
這基本上和“不必要的網路呼叫”類似,但在移動裝置上還增加了一個問題,不必要的呼叫不僅降低效能,而且還很耗電。
高效且有效果地使用資源
除了注意如何使用網路資源外,審查者還可以檢視其他的資源使用,來確定可能的效能問題。
程式碼通過鎖來訪問共享程式碼嗎?這樣會導致效能下降和死鎖嗎?
鎖是效能的殺手,特別是在多執行緒環境下。考慮這樣的方式:僅有一個執行緒寫入或改變數值,而其他執行緒可以任意讀取;或者使用無鎖演算法。
程式碼會造成記憶體洩漏嗎?
一些 Java 中的常見原因是:可變靜態欄位,使用 ThreadLocal 和 ClassLoader。
應用程式的記憶體會無限增加嗎?
這和記憶體洩漏不同 —— 記憶體洩漏是由於垃圾收集器不能回收不再使用的物件。但任何語言,包含那些沒有垃圾收集機制的語言,都可以建立無限增長的資料結構。作為審查者,如果你看到新的值不斷被加入一個列表或者對映表(Map) ,問一下這個列表或者對映表是否或者何時被釋放或者減少。
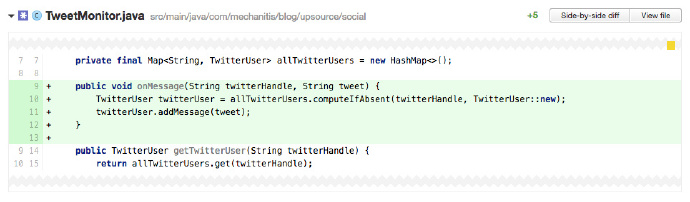
上面的程式碼中我們可以看到,所有來自 Twitter 的訊息都被加入一個對映表。如果我們仔細檢查這個類,我們發現 allTwitterUsers 對映表從來沒有減少過,TwitterUser中的 tweets 列表也沒有。這個對映表可能很快就變得很大,這取決於我們監控使用者的數量和我們新增 tweets 的頻率。
程式碼有關閉連線或流嗎?
一不小心就會忘記關閉連線、檔案或網路流。當你審查其他人(無論什麼語言)的程式碼時,確保每個使用的檔案、網路或資料庫連線都有被正確地關閉。
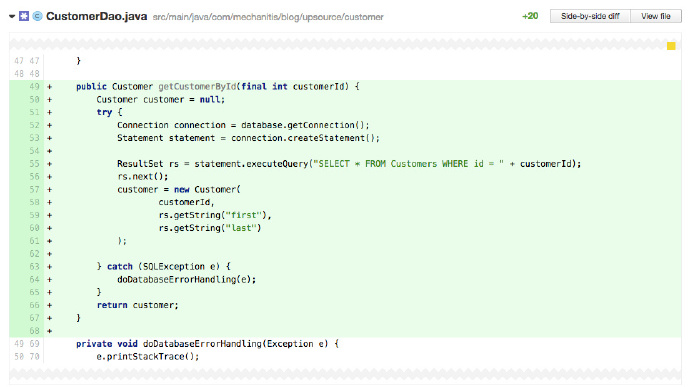
上面程式碼很幸運地編譯通過,最初的作者很容易忽視這個問題。作為審查者你應該注意 Connection、Statement 和 ResultSet 這些物件在方法退出前都要關閉。在 Java 7 中通過 try-with-resources 可以很容易做到這一點。下面的截圖顯示了作者利用 try-with-resources 修改程式碼後程式碼審查的結果。
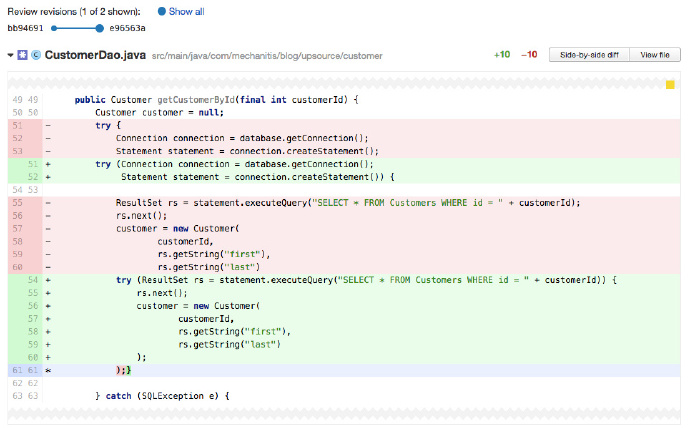
資源池配置正確嗎?
一個環境的最優配置受很多因素的影響,作為審查者你不可能馬上知道,就好像一個資料庫連線池的大小是否合適。但是有些事情你可以很容易判斷,比如這個池子太小(大小為1)或者太大(數以百萬計的執行緒)。優化這些值需要經過測試,測試環境越接近真實環境越好,但如果池子(例如執行緒池或者連線池)真的太大,在程式碼審查時可以抓出這個常見問題。邏輯表明越大越好,但每個物件都會消耗資源,物件太多通常會造成管理的開銷比帶來的好處大很多。如果有疑問,最好先使用預設設定。沒有使用預設設定的程式碼需要通過某些測試或計算,來驗證數值是合理的 。
審查者容易發現警告標誌
某些型別的程式碼可以立即顯示一個可能的效能問題。這取決於使用的語言和函式庫(請讓我們知道,在你們環境下對“程式碼異味”的評價)。
(譯者注:程式碼異味 code smells,程式碼中的任何可能導致深層次問題的症狀都可以叫做程式碼異味。程式碼異味包括重複程式碼、巨型類、方法過長等。)
反射
在Java中使用反射比不使用要慢很多。如果你檢查包含反射的程式碼,問一下反射是不是一定需要。
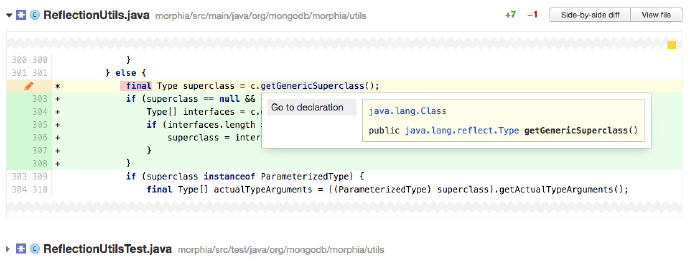
上面的截圖顯示了一個審查者在 Upsource 裡點選一個方法確認它來自哪裡,可以看到這個方法來自 java.lang.reflect 包,這就應該是一個警告標誌。
超時
當你審查程式碼時,你可能不知道一個操作的正常超時應該是多少,但應該這樣考慮“如果超時,系統中的其他部分會受到什麼影響?”。作為審查者你應該考慮最壞的情況 —— 如果 5 分鐘超時到了,應用程式會卡住嗎?如果超時被設定為1秒,最壞會發生什麼?如果程式碼的作者無法判斷超時的大小,而你作為審查者也不知道如何選擇一個值,這時最好讓懂行的人蔘與進來。不要等到你的使用者向你抱怨效能問題。
並行性
程式碼中有使用多個執行緒來執行一個簡單的操作嗎?除了增加時間和複雜性外,卻沒有帶來效能的提高?現代Java中,並行性比直接建立執行緒更加微妙:程式碼有使用Java 8 炫酷的並行流機制,但是卻沒有從並行性中受益嗎?例如在並行流中處理非常簡單的操作,可能會比在一個順序流上執行慢很多。
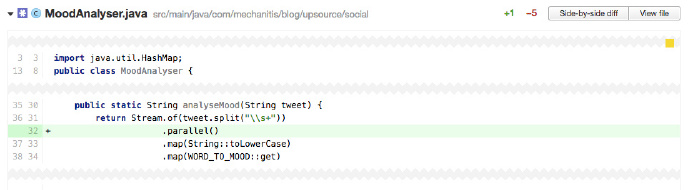
上面程式碼中增加的並行性沒有給我們帶來任何好處 —— 這個流作用在 Tweet 上,上面一個字串不會超過140個字元。就把那麼幾句話的操作並行化,也許不會改善效能,反而拆分成並行執行緒的開銷會更大。
正確性
這些事情不一定會影響系統的效能,但它們就會影響到正確性,因為它們很大程度上和執行在多執行緒環境有關。
多執行緒環境下的程式碼使用了正確的資料結構嗎?
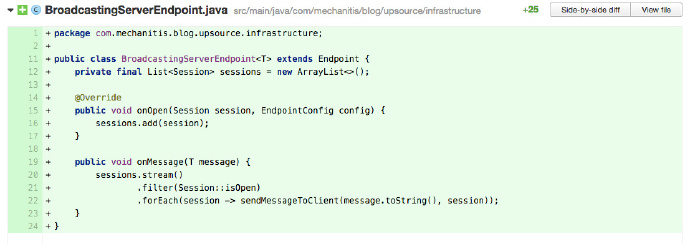
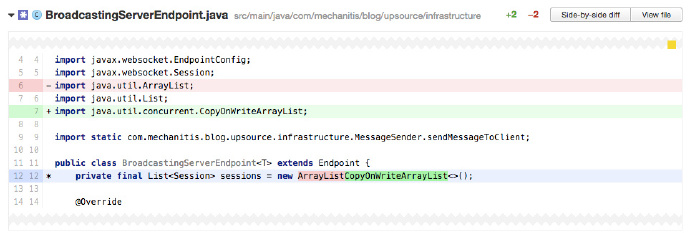
上面的程式碼中,作者在第 12 行用一個 ArrayList 儲存所有的會話(session)。但這程式碼特別是 onOpen 方法會被多個執行緒呼叫,sessions 欄位就必須是一個執行緒安全的資料結構。這種情況下有多種選擇:可以使用Vector,也可以用 Collections.synchronizedList()建立一個執行緒安全列表(List),但最好的選擇是用CopyOnWriteArrayList,因為對這個列表的修改通常遠低於對它的讀取。
程式碼容易出現競態條件嗎?
多執行緒環境下,編寫程式碼很容易造成微妙的競爭問題。例如:

雖然遞增程式碼只有一行(第16 行),但從程式碼讀取值到設定新值的這段時間裡,另一個執行緒很可能已經增加了 orders 的值。作為審查者,要注意 get 和 set 組合都不是原子操作。
程式碼中對鎖的使用正確嗎?
對於競態條件,作為審查者你應該要檢查程式碼,不允許多個執行緒用可能會引發衝突的方式修改數值。應該要使用同步、鎖或者原子變數來控制修改的程式碼塊。
程式碼的效能測試有價值嗎?
例如,一不小心就會寫出糟糕的微基準測試。或者如果測試使用的資料和量產資料不一樣,也會得到一個錯誤的結果。
快取
雖然快取可以避免過多的外部請求,它也會面臨自己的挑戰。如果審查的程式碼使用了快取,你應該注意一些常見的問題,例如不正確的快取項失效。
程式碼級優化
如果你在審查程式碼,同時你也是一名開發者,下面的內容中可能會有你想建議的優化方法。作為團隊,你們應該很清楚效能對你們有多重要,這些優化方法對你們的程式碼是否有幫助。
大部分公司不會開發低延遲的應用程式,這些優化很可能都屬於過早的優化。
程式碼中是否使用了不必要的同步、鎖?如果程式碼總是執行在單執行緒下,加鎖只會帶來額外開銷。
程式碼中是否使用了不必要的執行緒安全資料結構?例如,可以用ArrayList 替換 Vector 嗎?
程式碼中是否使用了在常見操作上效能很差的資料結構?例如,使用了連結串列結構,卻經常搜尋其中的一項。
程式碼是否使用了鎖或者同步機制,而實際上可以用原子變數替代?
程式碼可以得益於延遲載入嗎?
if 語句或其他邏輯語句能通過短路機制進行優化嗎?比如把最快的計算放在條件的開始?
有很多的字串格式嗎?可以更有效率嗎?
log 語句有使用字串格式化嗎?有用檢查log級別的 if 語句包起來或者使用的日誌提供者可以進行延遲操作?

上面程式碼只會在 logger 被設定為 FINSET 時才會記錄訊息。但無論這條訊息是否真的被記錄下來,每次都會執行這個開銷很大的String.format 操作。
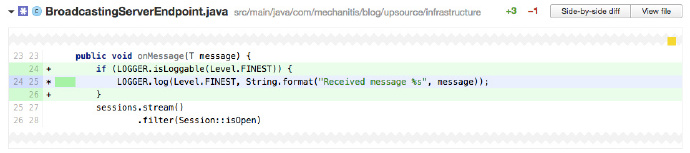
可以像上面程式碼那樣優化效能,即確保只在 log 級別等於某一數值時,才把訊息被寫入在 log。

Java 8中,可以使用 lambda 表示式來提高效能,而不是使用 if。由於使用到 lambda,除非訊息真的被記錄下來,String.format 不會執行。這應該是Java 8推薦的方法。
涉及到效能有很多要考慮的事情……
正如我在第一篇中列出程式碼審查需要留意的事情,本文強調了其中的一些關注點,可能是你們團隊在審查時會持續檢查的。這取決於你們專案的效能需求。
雖然本文是面向所有的開發人員,但大部分例子都是使用Java或 JVM。我最後介紹一些簡單的事情,是在審查 Java程式碼時需要留意的,這樣可以讓JVM 而不是你自己去優化程式碼:
編寫小的方法和類。
保持邏輯簡單 —— 不要使用深入巢狀的 if 或 迴圈。
程式碼越容易讓人閱讀,JIT 編譯器越有可能理解你的程式碼從而去優化它 。 如果程式碼看上去容易理解和整潔,它的效能也可能很好 —— 這應該很容易在程式碼審查時發現。
總結
談到效能,你要理解通過程式碼審查,某些方面可以快速得到改善(比如,沒有必要的資料庫呼叫),有些方面也很誘人(就像程式碼級優化)但很可能不會給你們的系統帶來很大的改善。
這是程式碼審查“查”什麼系列第5篇。 檢視該系列以前的文章。
在今天的文章中,我們將更多地關注程式碼本身的設計,專門檢查程式碼是否遵循了良好的物件導向設計實踐。與所有我們討論的其他方面一樣,並不是所有的團隊將它作為最高準則來優先檢查,但是如果你嘗試遵循SOLID原則,或嘗試將你的程式碼往這個方向上努力,這裡的一些建議可能會對你有所幫助。
什麼是SOLID?
SOLID原則 是物件導向程式設計和程式設計的五個核心原則。這篇文章的目的並不是教會你這些原則是什麼或者深入探討為什麼要遵循它們,而是指出那些程式碼評審中發現的程式碼異味,它們可能是沒有遵循這些原則的結果。

SOLID代表:
S – 單一職責原則
O – 開放封閉原則
L – 里氏替換原則
I – 介面分離原則
D – 依賴倒置原則
單一職責原則(SRP)
不應該有多種情況需要修改某個類的物件。
僅僅通過程式碼評審有時會很難發現上述情況。根據定義,作者是(或應該是)由一個獨立的要求去改變程式碼庫——修復一個bug,新增一個新功能,或一次專門的重構。
你應該看看在一個類中哪些方法在同一時間會改變,以及哪些方法幾乎是不可能受其他方法變化影響而被改變。例如:
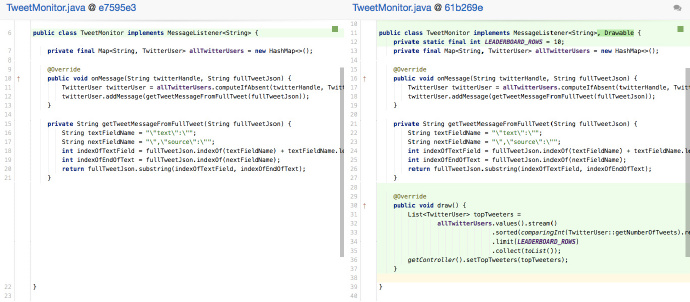
上面Upsource工具排展示的diff中,一個新功能被新增到TweetMonitor,能夠基於user介面的某種排序畫出Tweeter的十大排行榜。雖然這似乎是合理的, 因為它使用了onMessage方法收集的資料,但有跡象顯示這違反了SRP。onMessage和 getTweetMessageFromFullTweet方法都是和接收或解析一個Twitter訊息相關,而draw用來組織資料並在UI上顯示。
程式碼審查者應該標記這兩個職責,然後和作者研究出一個分離這些特性的更好方法:也許通過移動Twitter字串解析方法到不同的類,或者建立一個不同的類負責來渲染排行榜。
開放封閉原則(OCP)
軟體實體應該對擴充套件開放,對修改封閉。
作為一個程式碼審查者,如果你看到一系列的if語句檢查物件的特殊型別,可能這就是違反該原則的跡象:
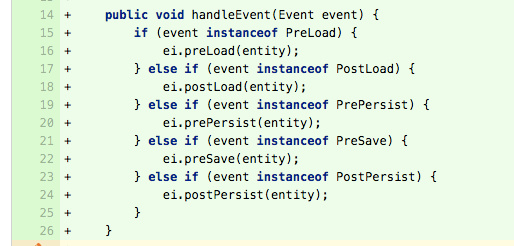
如果你審查上面的程式碼應該很清楚,當一個新的Event型別新增到系統,新建立的Event型別可能要新增另一個else到這個方法中來處理它。
最好使用多型來移除這個if:
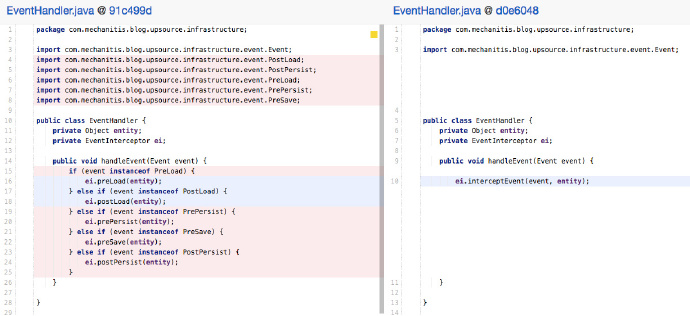
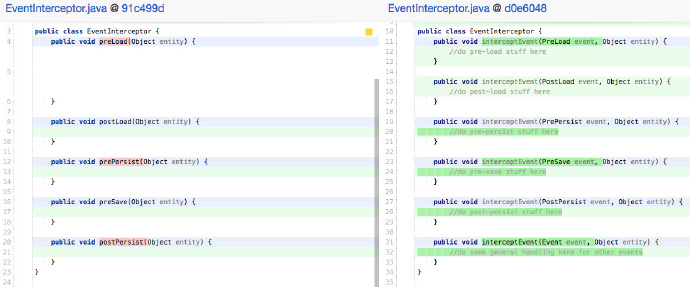
像往常一樣,這個問題的解決方案不止一個,但關鍵是把複雜的if/else和instanceof判斷移除。
里氏替換原則(LSP)
函式使用基類的引用,必須能夠在不知不覺的情況下使用派生類的物件。
發現違反這一原則的一個簡單的方法是尋找顯示的型別轉換。如果你不得不把一個物件轉換為某種型別,你就沒有做到不知不覺地使用繼承了基類的子類物件。
檢查以下兩條時可以找到更細微的衝突:
先決條件不能在子型別加強。
後置條件不能在子型別減弱。
例如,想象我們有一個抽象類Order和一些子類——BookOrder、ElectronicsOrder等等。placeOrder方法可能需要一個Warehouse,可以用這個方法來改變倉庫中的實物產品的庫存水平:

現在想象一下,我們引入電子禮品卡,只需簡單地為錢包新增餘額,但不需要物理盤點。如果實現為GiftCardOrder,placeOrder方法就不必使用warehouse引數:

這可能在邏輯上看起來像繼承,但事實上你可以說使用GiftCardOrder應該期望這個類和其他類有類似的行為,例如,你應該期望這個引數傳遞給所有子類:

但這不會傳遞,作為GiftCardOrders有不同型別的order行為。如果你審查這樣的程式碼,應該質疑這裡繼承的使用,也許order行為可以通過使用組合替代繼承的方式插入。
介面分離原則(ISP)
多個客戶端特定的介面比使用一個通用的介面要好。
可以很容易識別某些程式碼違反這一原則,因為介面上具有很多方法。這一原則與SRP呼應,正如你可能看到一個介面具有許多方法,實際上它是負責了多個功能。
但有時甚至一個介面只有兩個方法也可以拆分成兩個介面:

在這個例子中,有些時候可能不需要decode方法,並且一個編解碼器根據使用要求可能被視為一個編碼器或解碼器,把SimpleCodec介面分割成一個編碼器和解碼器可能會更好。一些類可以選擇兩個都實現,但不必去過載不需要的方法,或者某些類只需要編碼器,同時他們的編碼器例項也實現解碼。
依賴倒置原則(DIP)
依賴抽象。不要依賴於具體實現。
雖然想要在試圖尋找違反該原則的簡單例子時,類似到處使用new關鍵字(而不是使用依賴注入或工廠模式)和濫用集合型別(例如宣告ArrayList變數或引數而不是List),作為一個程式碼審查者你在程式碼審查時,應該確保程式碼作者已經使用或建立了正確的抽象。
例如,服務級的程式碼直接連線到一個資料庫讀寫資料:
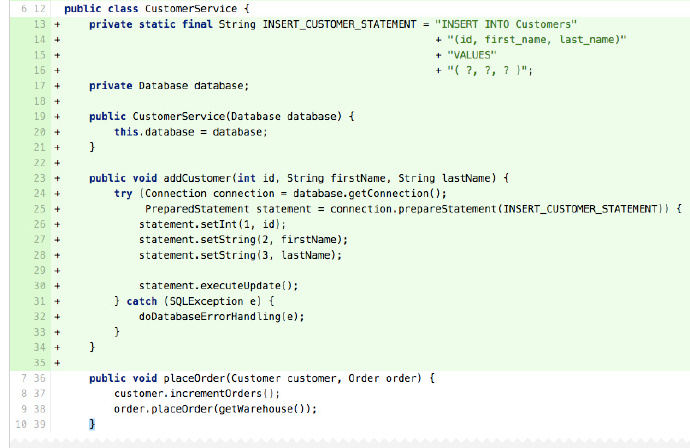
這段程式碼依賴於大量的具體的實現細節:連線到一個(關係)資料庫的JDBC,基於具體資料庫的SQL,需要知道資料庫結構,等等。這段程式碼來自你的系統的某處,但是不應該出現在這裡。這裡還有其他方法不需要知道具體的資料庫。更好的方式是,提取出一個DAO或使用Repository模式,將DAO或repository注入到這個服務中。
總結
一些程式碼異味可能意味著可能已經違反了一個或多個SOLID原則:
很長的if/else語句
強制轉換成一個子型別
很多公共方法
實現的方法丟擲UnsupportedOperationException異常
與所有的設計問題一樣,在遵循這些原則和故意迴避這些原則間需要找到一個平衡,這個平衡取決於你的團隊的喜好。但是如果你在程式碼審查中看到複雜的程式碼,會發現應用這些原則將提供一個更簡單、更容易理解的解決方案。
相關文章
- 程式碼審查“查”什麼?(1)
- 程式碼審查“查”什麼(3):效能
- 程式碼審查“查”什麼(2):測試
- 程式碼審查“查”什麼?(5):SOLID原則Solid
- 程式碼審查
- 程式碼審查工具
- 中國新成立”網路安全審查委員會”審查些什麼?
- 程式碼審查過程
- 敏捷程式碼審查指南敏捷
- python程式碼檢查工具(靜態程式碼審查)Python
- 我從 1000 份程式碼審查中學到了什麼
- Go 程式碼審查建議Go
- 程式碼審查不是用來……
- 程式碼審查:好事?壞事?
- 程式碼審查最佳實踐
- 程式碼安全審查CxEnterprise
- 不做程式碼審查又怎樣?
- 自上而下做好安全程式碼審查
- 程式碼審查的重要性
- 漫畫:Code Review 程式碼審查View
- 程式碼審查(Code Review)清單View
- 開發者眼中的程式碼審查“真相”
- 什麼是程式碼審計?程式碼審計有什麼好處?
- Reviewbot 開源 | 為什麼我們要打造自己的程式碼審查服務?View
- [譯] 程式碼審查之最佳實踐
- 同行程式碼審查實戰分析行程
- 你們公司做程式碼審查嗎?
- 程式碼審查的實踐經驗
- 【翻譯】程式碼審查經驗談
- 17款最佳的程式碼審查工具
- 程式碼審查中的暴力衝突
- 程式碼審查和不良程式設計習慣程式設計
- 五個程式碼審查反模式 - Trisha Gee模式
- Code Review 程式碼審查 不完全整理View
- Jupiter程式碼審查工具使用參考
- 高效程式碼審查的十個經驗
- Google是如何做程式碼審查的?Go
- ThoughtBot的程式碼審查指導原則