Spark 叢集搭建從零開始之2 Spark單機偽分散式安裝與配置
1、下載並解壓spark-1.6.0-bin-hadoop2.6.tgz 我的在/chenjie下
2、vim /etc/profile增加環境變數
exprot SPARK_HOME=/chenjie/spark-1.6.0-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
3、使用scp /chenjie/spark-1.6.0-bin-hadoop2.6 root@pc2:/chenjie命令將目錄傳送到pc2 ,pc3同理
scp /etc/profile root@pc2:/etc/profile將環境變數檔案傳送的pc2 pc3同理
4.使用source /etc/profile使其生效
5、進入chenjie/spark-1.6.0-bin-hadoop2.6/conf
使用cp spark-env.sh.template spark-env.sh新建一個配置
配置spark-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export SCALA_HOME=/chenjie/scala-2.10.4
export HADOOP_HOME=/chenjie/hadoop-2.6.5
export HADOOP_CONF_DIR=/chenjie/hadoop-2.6.5/etc/hadoop
export SPARK_MASTER_IP=pc1
export SPARK_LOCAL_IP=pc1
儲存退出
6、切換到chenjie/spark-1.6.0-bin-hadoop2.6/sbin
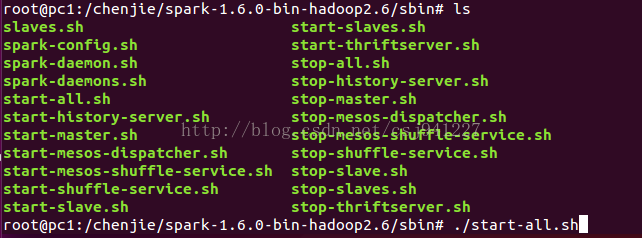
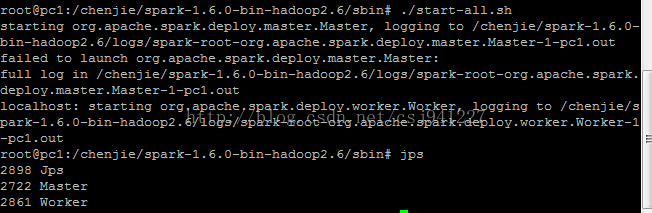
7../start-all.sh啟動
8.輸入jps檢視程式
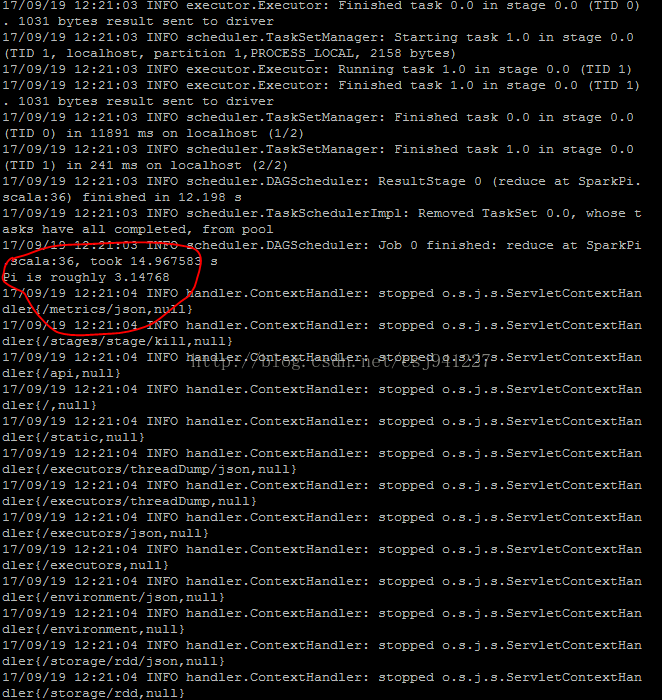
9.使用求圓周率例項測試是否成功
相關文章
- Spark 叢集搭建從零開始之1 Scala的安裝與配置Spark
- Spark 叢集搭建從零開始之3 Spark Standalone叢集安裝、配置與測試Spark
- Hadoop 2.6 叢集搭建從零開始之3 Hadoop的安裝與配置(偽分散式環境)Hadoop分散式
- Hadoop 2.6 叢集搭建從零開始之4 Hadoop的安裝與配置(完全分散式環境)Hadoop分散式
- Hadoop 2.6 叢集搭建從零開始之2 JDK1.8安裝HadoopJDK
- hadoop偽分散式叢集的安裝(不是單機版)Hadoop分散式
- Spark新手入門——2.Hadoop叢集(偽分佈模式)安裝SparkHadoop模式
- 從0到1搭建spark叢集---企業叢集搭建Spark
- 從零開始認識 SparkSpark
- 搭建spark on yarn 叢集SparkYarn
- hadoop叢集搭建——單節點(偽分散式)Hadoop分散式
- Spark安裝與配置Spark
- CentOS6.5 安裝Spark叢集CentOSSpark
- 本地windows搭建spark環境,安裝與詳細配置(jdk安裝與配置,scala安裝與配置,hadoop安裝與配置,spark安裝與配置)WindowsSparkJDKHadoop
- Spark3.0.0叢集搭建Spark
- hadoop+spark偽分散式HadoopSpark分散式
- Hadoop 2.6 叢集搭建從零開始之1 Ubuntu虛擬機器搭建HadoopUbuntu虛擬機
- Cassandra安裝及分散式叢集搭建分散式
- centos7 (阿里雲、linux) 單機spark的安裝與配置詳解(jdk安裝與配置,scala安裝與配置,hadoop安裝與配置,spark安裝與配置)CentOS阿里LinuxSparkJDKHadoop
- CentOS 7上搭建Spark 3.0.1 + Hadoop 3.2.1分散式叢集CentOSSparkHadoop分散式
- Pulsar本地單機(偽)叢集 (裸機安裝與docker方式安裝) 2.2.0Docker
- spark叢集的配置檔案Spark
- HADOOP SPARK 叢集環境搭建HadoopSpark
- CentOS 7上搭建Spark3.0.1+ Hadoop3.2.1分散式叢集CentOSSparkHadoop分散式
- docker下,極速搭建spark叢集(含hdfs叢集)DockerSpark
- 大資料Spark叢集模式配置大資料Spark模式
- Redis 偽分散式安裝部署配置Redis分散式
- 基於 ZooKeeper 搭建 Spark 高可用叢集Spark
- Spark3.0.1各種叢集模式搭建Spark模式
- 從零開始搭建高可用的k8s叢集K8S
- Spark 從零到開發(五)初識Spark SQLSparkSQL
- 安裝配置 zookeeper (單機非叢集模式)模式
- spark之 spark 2.2.0 Standalone安裝、wordCount演示Spark
- CentOS7 hadoop3.3.1安裝(單機分散式、偽分散式、分散式)CentOSHadoop分散式
- SPARK 安裝之scala 安裝Spark
- 實時計算框架:Spark叢集搭建與入門案例框架Spark
- 億級Web系統搭建——單機到分散式叢集Web分散式
- 億級Web系統搭建:單機到分散式叢集Web分散式