在我的之前的一些部落格中,我提到了生成認知的必要性和重要性,並提供了一個認知應用的例子。我始終認為認知應用是對於希望透過挖掘大資料從而改進決策和解決重要問題的公司的關鍵所在。為了更好的理解和領會開發這類應用的必要性,考慮在大資料領域正在發生什麼,並且評估我們在商業智慧系統上的經驗,及它應該如何驅動我們理解認知應用是十分重要的。
由於我認為認知應用是大資料發展的下一個轉折(參見最近使用IBM Watson平臺建立的這類應用舉例),我將要在一系列部落格中進一步探討這個話題。在這篇部落格中,我對於資料分析在過去25年的演變進行了觀察,特別是當我們來到大資料時代,開發認知應用是必然之舉。在第二篇部落格中,我將更為詳細地描述這類應用,並且提供一些例子。在第最後的第三篇部落格中,我將討論投資者對認知應用的興趣,並描述我最近對這一領域的創業公司的投資。在這些部落格中,我的分析和理解均基於本人作為三十多年的企業家、量兩分析應用創業公司的創始人以及在這一領域進行了15年投資的風險投資人的經驗。
資料分析在過去25年
隨著過去25年中資料量的大幅增加,針對決策制定的資料理解都由兩個步驟組成:建立資料倉儲以及理解資料倉儲的內容。
資料倉儲以及它的前身—企業資料倉儲、資料市場等,是構造專業資料庫所必須的基礎架構。這些資料可能來自於一個單獨的資料來源(例如客戶關係管理應用的資料庫)或者來自整合過的一系列不同的資料來源(例如將一個客戶關係管理應用的資料庫和一個包含每個客戶的社交媒體互動資料的資料庫整合起來)。這些資料可能是結構化的(例如貨幣被描述為每個使用者支付的數量)、非結構化的(例如一個客戶和一個服務專員之間以文字形式的互動內容)。專業化資料是那些一旦被抓取,就是乾淨的、有標籤的、並且自動地或被(比人們認為更頻繁地進行)人工描述的。
在過去幾年裡,我們已經透過大量使用開源軟體、雲端計算、商用硬體等來降低資料倉儲的開銷,並進一步改進我們管理更多樣、大量和高速產生的資料的能力。我們已經從只有諸如金融服務的花旗銀行以及零售業的沃爾瑪之類的大公司才能負擔的、千萬美元開銷的資料倉儲轉向對於中小型企業可以負擔得起的資料倉儲。最近,低開銷的服務提供方,諸如亞馬遜的Redshift,谷歌的BigQuery,甚至是微軟的Azure,已經把資料倉儲移到雲上。最終,資料倉儲對於普通企業來說都是可用的。
隨著資料倉儲的崛起,資料分析報告的交付已從列印轉向數字化
資料理解的第二步涉及到透過資料分析來理解資料倉儲的內容。在商業環境中,這往往是透過報告和關聯的視覺化來完成,有時候也會使用更加定製化的視覺化和諸如神經網路的機器學習演算法(機器學習雖然並不是新概念,但幾乎從資料倉儲作為資料儲存和管理工具出現開始就被使用)。
隨著資料倉儲被更多的各行各業的公司所採用,我們見證了可以建立的報告的形式的逐漸改變,報告被展現給分析師和決策者,以及準備報告的人。在早期(80年代末90年代早期),商務智慧報告由技術專員建立,他們也是透過向資料倉儲提供函式和查詢來得到報告。這些報告被封裝(例如,它們可以被修改,但是有很大難度,且只能被同一個建立報告的技術專員所修改),並在計算機列印紙上呈現。後來,儘管這些報告仍然被封裝,它們可以在電腦上透過專門的報告程式來呈現,再後來,可以呈現在包括智慧電話和手持終端執行的網路瀏覽器上。近年來,查詢建立和報告撰寫的任務從技術專員轉交給了商業使用者。然而,儘管查詢和關聯的報告變得更快、更靈活、被更廣泛的使用,這些報告的主要使用者——商業分析師們,仍然困擾於在大量資訊中發現在報告中存在的最簡單的模式。最重要的是,這些使用者糾結於基於報告所包含的資訊應該決定採取什麼行動(參見圖1的例子)。
圖1 關於複雜的資料模式和視覺化的一些常見的例子
隨著更多資料的產生,我們已經可以更有效地管理資料所帶來的開銷,但是仍然掙扎於進行有效的資料分析
受到全球因特網的普及,它所帶來的網路連通性的驅動,物聯網之類的新領域產生的前所未見的海量資料,以及基於這些所建立的大量應用,使得我們被資料所淹沒。快速資料和慢資料,簡單資料和複雜資料,所有這些資料都是前所未有的大量。資料的量變的多大了呢?我們已經從在2014年產生大約5澤位元組的非結構化資料到2020年將增加到大約40澤位元組的非結構化(參見圖2)。
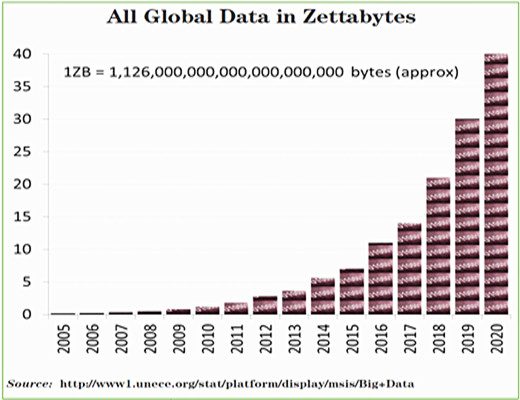
圖2 非結構化資料在2005至2020年的實際和預期增長對比
特別是在上一個十年間,隨著資料量變得更大,企業的IT策略核心變為用很少的資源做更多的事。公司的資料倉儲開始面臨兩大問題。第一,其中的一些系統不能有效地管理所獲取的海量資料,因而資料不能被應用有效的利用。第二,開銷變得不能承受的高,成為資料管理方面另一大挑戰。
與此同時,當新一代的資料管理軟體(例如Hadoop)被谷歌、雅虎等重量級科技公司開發出來,一些“部分”解決方案開始出現。一開始,這些軟體在商用硬體上執行,並且很快開源,從而使得企業可以以較低的開銷來解決它們的大資料問題。Cloudera, Hortonworks以及一些其他提供開源軟體服務的公司在大資料基礎設施領域扮演了重要角色。我將這些解決方案稱為“部分”是因為在管理資料的同時,這些系統並不包含企業所使用資料倉儲系統的那些複雜的、專用的功能。但是這些新系統擅於構建資料湖泊,適用於多樣化的大資料環境,並旨在透過更低的開銷替代或增強某些型別的資料倉儲。
儘管我們有效管理大資料開銷的能力得到了改進,但是我們分析資料的能力,不計開銷的情況下,仍然沒有提升。儘管大眾媒體宣稱從資料中得來的認知結果將是新的石油(或金子,挑選你喜歡的隱喻),但市場研究公司IDC預測,到2020只有很少一部分採集的資料會被分析。我們需要分析更多抓取的資料,並從中提取更多的資訊。
我們正在致力於改進我們分析資料的能力,但是面臨著資料專業人員的短缺
為了收集和分析更多的資料,同時不放棄報告的生成,我們開始廣泛採用機器學習和其他基於人工智慧資料分析技術的自動化的資訊抽取方法。然而,這些方法要求使用一類新的專業人員——資料科學家。儘管我們看到資料科學家的數量潮湧般增加,但是我們需要更多,並且,與正在產生的資料相比我們永遠不能提供足夠的資料科學家。麥肯錫曾估計,到2018年,美國將面臨(大約14萬至19萬缺口)人才缺口,這些人擁有可以從收集的資料中提取認知結果的深度分析技能。我們還將缺少大約150萬擁有量化分析技能的、可以基於資料科學家生成的大資料分析來做出重要商業決策的經理。
機器學習改進了我們發現資料中關聯性的能力,但做出決策的要求的時間變短了,而資料產生的速度增加了
商業智慧是一個出現了近40年的領域。統計分析和機器學習技術被使用的時間則更長。在這一時期,我們已經提升了我們從資料集中識別關聯性的能力,但是做出決策的時間要求正在變短,而資料產生的速度不斷增加。舉例來說,公司的首席金融官們可能有一個月的時間來建立金融預報,然而一個自動的線上廣告平臺只有僅僅10毫秒的時間來決定把哪一個數字廣告展現給特定的使用者(參見圖3)。此外,一個首席金融官僅需要參考幾十億位元組的資料就可以得出決策,而線上廣告系統不得不分析萬億兆位元組的資料,大部分的資料還是近實時生成的。
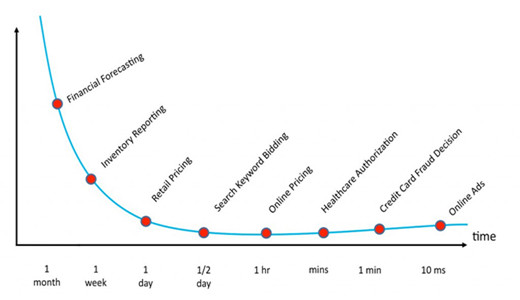
圖3 各行業做出決策需要的平均時間示意
在一些應用領域,簡單地識別出資料集中的關聯性對做出決策來說已經足夠。在其中一些高價值高投資回報的領域,透過資料科學家和其他專業人員來從大量資料中抽取資訊是合理且必要的。電腦保安威脅檢測以及信用卡欺詐檢測就是兩個這樣的領域。在這些領域裡,作出決策的時間是非常短的,做出錯誤決定(過度保守)的代價,至少最初並不是非常高。將一個交易視作欺詐或者將一個行為視為安全入侵的代價也很低(例如持卡人的不便或是對於系統管理員的一些網路取證)。但是,沒有檢測到在已建立的行為模式中的異常的代價將會更高。
為了跟上大資料的節奏和改善我們對資訊的使用,我們需要能快速而廉價地抽取相關性並將其與行動關聯起來的應用
考慮到預期的資料科學家和具有量化分析能力的商業使用者的短缺,以及我們迫切的繼續挖掘已經收集到的海量資料的需求,我們要能更好地開發分析應用,使其能夠生成認知並關聯到行動上。這類應用,被我稱為認知應用,將超遠勝於從資料中抽取相關性。
我們已經在資料理解上取得了很大進展。我們已經降低了管理大資料的開銷,與此同時改進了我們分析和提取關鍵資訊的能力。但是,大資料的增量過快以至於我們不能透過更快或者更靈活的查詢以及報告來緊跟步伐。我們需要能夠建立廉價快速的可執行認知能力,特別是透過使用認知應用。我將在下一篇部落格中更加完整地討論這一主題。

Evangelos Simoudis,加州理工學院資訊科學與技術顧問委員會成員,布蘭迪斯大學科學委員會成員,布蘭迪斯大學國際商業學院的諮詢委員會成員,紐約城市科學中心和規劃諮詢委員會成員。在布蘭迪斯大學獲得電腦科學博士學位以及在加州理工學院獲得電子工程碩士學位。
來源:Oreilly